Hola En este artículo hablaré sobre el clasificador bayesiano como una de las opciones para filtrar correos electrónicos no deseados. Repasemos la teoría, luego la arreglemos con la práctica, y al final daré mi boceto del código en mi querido idioma R. Trataré de exponer lo más levemente posible con expresiones y formulaciones. ¡Empecemos!

No hay fórmulas en ningún lado, bueno, una breve teoría
El clasificador bayesiano pertenece a la categoría de aprendizaje automático. La conclusión es esta: el sistema que se enfrenta a la tarea de determinar si la siguiente letra es spam ha sido entrenado previamente por un cierto número de letras que saben exactamente dónde "spam" y dónde "no spam". Ya ha quedado claro que esto es enseñar con un maestro, donde desempeñamos el papel de un maestro. El clasificador bayesiano presenta un documento (en nuestro caso, una letra) en forma de un conjunto de palabras que supuestamente no dependen entre sí (y esta ingenuidad se deduce de aquí).
Es necesario calcular la calificación para cada clase (spam / no spam) y elegir la que sea máxima. Para hacer esto, use la siguiente fórmula:
- palabra ocurrencia
en el documento de clase
(con suavizado) *
- el número de palabras incluidas en el documento de clase
M - el número de palabras del conjunto de entrenamiento
- el número de ocurrencias de la palabra
en el documento de clase
- parámetro para alisar
Cuando el volumen del texto es muy grande, debe trabajar con números muy pequeños. Para evitar esto, puede convertir la fórmula de acuerdo con la propiedad logaritmo **:
Sustituir y obtener:
* Durante los cálculos, puede encontrar una palabra que no estaba en la etapa de capacitación del sistema. Esto puede llevar a que la evaluación sea igual a cero y el documento no puede asignarse a ninguna de las categorías (spam / no spam). No importa cómo lo desee, no le enseña a su sistema todas las palabras posibles. Para hacer esto, es necesario aplicar suavizado, o más bien, hacer pequeñas correcciones a todas las probabilidades de que las palabras ingresen al documento. Se selecciona el parámetro 0 <α≤1 (si α = 1, este es el suavizado de Laplace)
** El logaritmo es una función monotónicamente creciente. Como se puede ver en la primera fórmula, estamos buscando el máximo. El logaritmo de la función alcanzará su punto máximo en el mismo punto (abscisa) que la función misma. Esto simplifica el cálculo, porque solo cambia el valor numérico.
De la teoría a la práctica.
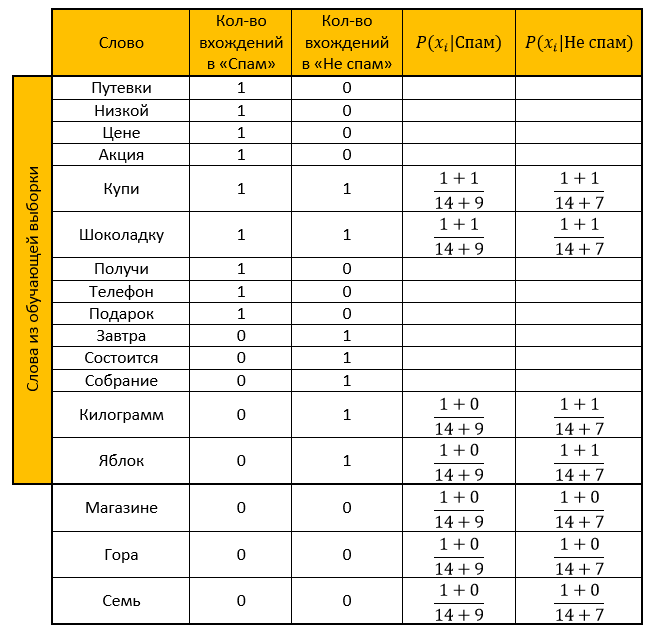
Deje que nuestro sistema aprenda de las siguientes letras, conocidas de antemano dónde “spam” y dónde “no spam” (muestra de capacitación):
Spam- “Vales a bajo precio”
- "Promoción! Compre una barra de chocolate y obtenga un teléfono como regalo »
No es spam:- “La reunión se realizará mañana”
- "Compre un kilogramo de manzanas y una barra de chocolate"
Asignación: determine a qué categoría pertenece la siguiente letra:
- “La tienda tiene una montaña de manzanas. Compre siete kilogramos y una barra de chocolate ”
Solución:Hacemos una mesa. Eliminamos todas las "palabras de detención", calculamos las probabilidades, tomamos el parámetro para suavizar como uno.
Valoración para la categoría Spam:
Clasificación para la categoría "No spam":
Respuesta: La calificación de "No es spam" es más que la calificación de "Spam". ¡Entonces la carta de verificación no es spam!
Calculamos lo mismo con la ayuda de una función transformada por la propiedad del logaritmo:
Valoración para la categoría Spam:
Clasificación para la categoría "No spam":
Respuesta: similar a la respuesta anterior. Correo electrónico de verificación: ¡sin spam!
Implementación del lenguaje de programación R
Comentó sobre casi todas las acciones, porque sé con qué frecuencia no quiero entender el código de otra persona, así que espero que leer el mío no te cause ninguna dificultad. (oh como espero)
Y aquí, de hecho, el código mismolibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
Muchas gracias por tu tiempo leyendo mi artículo. Espero que hayas aprendido algo nuevo para ti, o simplemente arrojes luz sobre momentos que no te quedan claros. Buena suerte
Fuentes:- Un muy buen artículo sobre el ingenuo clasificador de Bayes
- Conocimiento derivado del Wiki: aquí , aquí y aquí
- Conferencias sobre minería de datos Chubukova I.A.