Hola A continuación se muestra una transcripción del video del discurso en la manifestación comunitaria Apache Ignite en San Petersburgo el 20 de junio. Puedes descargar las diapositivas aquí .
Hay toda una clase de problemas que enfrentan los usuarios novatos. Acaban de descargar Apache Ignite, ejecutan las primeras dos, tres, diez veces y nos hacen preguntas que se resuelven de manera similar. Por lo tanto, propongo crear una lista de verificación que le ahorrará mucho tiempo y nervios cuando realice sus primeras aplicaciones Apache Ignite. Hablaremos sobre los preparativos de lanzamiento; cómo hacer que se agrupe el clúster; cómo comenzar algunos cálculos en Compute Grid; Cómo preparar un modelo y código de datos para que pueda escribir sus datos en Ignite y luego leerlos con éxito. Y lo más importante: cómo no romper nada desde el principio.
Preparación para el lanzamiento: configure el registro
Necesitamos troncos. Si alguna vez hizo una pregunta en la lista de correo de Apache Ignite o en StackOverflow, como "por qué colgó todo", lo más probable es que lo primero que le pidieron enviar fueron todos los registros de todos los nodos.
Naturalmente, el registro de Apache Ignite está habilitado de forma predeterminada. Pero hay matices. En primer lugar, Apache Ignite escribe un poco en stdout . Por defecto, comienza en el llamado modo silencioso. En stdout verá solo los errores más terribles, y todo lo demás se guardará en un archivo, la ruta a la que Apache Ignite se muestra al principio (de forma predeterminada: ${IGNITE_HOME}/work/log ). No lo borra y mantiene los registros por más tiempo, puede ser muy útil.
stdout enciende en el inicio predeterminado
Para que sea más fácil descubrir problemas sin entrar en archivos separados y configurar un monitoreo separado para Apache Ignite, puede ejecutarlo en modo detallado con el comando
ignite.sh -v
y luego el sistema comenzará a escribir sobre todos los eventos en stdout junto con el resto del registro de la aplicación.
¡Revisa los registros! Muy a menudo en ellos puedes encontrar soluciones a tus problemas. Si el clúster se ha colapsado, muy a menudo en el registro puede ver mensajes como "Aumentar tal y tal tiempo de espera en tal y tal configuración". Nos caímos por su culpa. El es muy pequeño. La red no es lo suficientemente buena ".
Ensamblaje de racimo
Invitados no invitados
El primer problema que muchos enfrentan son los invitados no invitados en su clúster. O usted mismo resulta ser un invitado no invitado: inicie un clúster nuevo y de repente verá que en la primera instantánea de topología en lugar de un nodo tiene dos servidores desde el principio. ¿Cómo es eso? Solo lanzaste uno.
Un mensaje que indica que el clúster tiene dos nodos.

El hecho es que, por defecto, Apache Ignite usa Multicast, y al inicio buscará todos los demás Apache Ignite que están en la misma subred, en el mismo grupo de Multicast. Y si lo hace, intentará conectarse. Y en caso de conexión fallida, no se iniciará en absoluto. Por lo tanto, en el clúster de mi computadora portátil de trabajo, los nodos adicionales del clúster en la computadora portátil del colega aparecen regularmente, lo que por supuesto no es muy conveniente.
¿Cómo protegerse de esto? La forma más fácil de configurar IP estática. En lugar de TcpDiscoveryMulticastIpFinder , que se usa de forma predeterminada, hay TcpDiscoveryVmIpFinder . Allí, escriba toda la IP y los puertos a los que se está conectando. Esto es mucho más conveniente y lo protegerá de una gran cantidad de problemas, especialmente en entornos de desarrollo y pruebas.
Demasiadas direcciones
El proximo problema. Deshabilitó la multidifusión, inició el clúster, en una sola configuración, estableció una cantidad decente de IP desde diferentes entornos. Y sucede que inicia el primer nodo en un clúster nuevo durante 5-10 minutos, aunque todos los siguientes se conectan a él en 5-10 segundos.
Tome una lista de tres direcciones IP. Para cada uno, prescribimos rangos de 10 puertos. En total, se obtienen 30 direcciones TCP. Como Apache Ignite debe intentar conectarse a un clúster existente antes de crear un nuevo clúster, verificará cada IP por turno. Es posible que no duela en su computadora portátil, pero la protección de escaneo de puertos a menudo se incluye en algunos entornos nublados. Es decir, al acceder a un puerto privado en alguna dirección IP, no recibirá ninguna respuesta hasta que haya pasado el tiempo de espera. Por defecto, son 10 segundos. Y si tiene 3 direcciones de 10 puertos, obtendrá 3 * 10 * 10 = 300 segundos de espera, esos mismos 5 minutos para conectarse.
La solución es obvia: no registre puertos innecesarios. Si tiene tres IP, entonces realmente no necesita un rango predeterminado de 10 puertos. Esto es conveniente cuando prueba algo en la máquina local y ejecuta 10 nodos. Pero en sistemas reales, un solo puerto suele ser suficiente. O deshabilite la protección contra escaneo de puertos en la red interna, si tiene esa oportunidad.
El tercer problema común es IPv6. Puede ver mensajes de error de red extraños: no se pudo conectar, no se pudo enviar un mensaje, nodo segmentado. Esto significa que te has caído del clúster. Muy a menudo, estos problemas son causados por entornos mixtos de IPv4 e IPv6. Esto no quiere decir que Apache Ignite no sea compatible con IPv6, pero en este momento hay ciertos problemas.
La solución más fácil es pasar la opción a la máquina Java
-Djava.net.preferIPv4Stack=true
Entonces Java y Apache Ignite no usarán IPv6. Esto resuelve una parte importante de los problemas con los clústeres colapsados.
Preparación de la base del código: serializamos correctamente
El clúster se ha reunido, es necesario comenzar algo en él. Uno de los elementos más importantes en la interacción de su código con el código Apache Ignite es Marshaller, o serialización. Para escribir algo en la memoria, para persistir, para enviar a través de la red, Apache Ignite primero serializa sus objetos. Puede ver mensajes que comienzan con las palabras: "no se puede escribir en formato binario" o "no se puede serializar con BinaryMarshaller". Solo habrá una advertencia de este tipo en el registro, pero notable. Esto significa que necesita ajustar su código un poco más para hacer amigos con Apache Ignite.
Apache Ignite utiliza tres mecanismos para la serialización:
JdkMarshaller : serialización regular de Java;OptimizedMarshaller : serialización Java ligeramente optimizada, pero los mecanismos son los mismos;BinaryMarshaller es una serialización escrita específicamente para Apache Ignite, utilizada en todas partes bajo su capó. Ella tiene una serie de ventajas. En algún lugar podemos evitar la serialización y deserialización adicionales, y en algún lugar incluso podemos obtener en la API un objeto no deserializado, trabajar con él directamente en formato binario, como con algo como JSON.
BinaryMarshaller podrá serializar y BinaryMarshaller sus POJO que no tienen más que campos y métodos simples. Pero si tiene una serialización personalizada a través de readObject() y writeObject() , si usa Externalizable , BinaryMarshaller no se las BinaryMarshaller . Verá que su objeto no se puede serializar mediante la grabación habitual de campos no transitorios y se dará por vencido: volverá a OptimizedMarshaller .
Para hacer amigos de tales objetos con Apache Ignite, debe implementar la interfaz Binarylizable . El es muy simple.
Por ejemplo, hay un TreeMap estándar de Java. Tiene serialización y deserialización personalizadas a través de objetos de lectura y escritura. Primero describe algunos campos y luego escribe la longitud y los datos en sí mismos en OutputStream .
Implementación de TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
writeBinary() y readBinary() de Binarylizable funcionan exactamente de la misma manera: BinaryTreeMap envuelve en un TreeMap normal y lo escribe en OutputStream . Este método es fácil de escribir y aumentará enormemente la productividad.
BinaryTreeMap.writeBinary()
public void writeBinary(BinaryWriter writer) throws BinaryObjectException { BinaryRawWriter rewriter = writer. rewrite (); rawWriter.writeObject(map.comparator()); int size = map.size(); rawWriter.writeInt(size); for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) { rawWriter.writeObject(entry.getKey()); rawWriter.writeObject(entry.getValue()); } }
Lanzamiento en Compute Grid
Ignite no solo le permite almacenar datos, sino también ejecutar computación distribuida. ¿Cómo ejecutamos algún tipo de lambda para que disperse todos los servidores y se ejecute?
Para empezar, ¿cuál es el problema con estos ejemplos de código?
Cual es el problema
Foo foo = …; Bar bar = ...; ignite.compute().broadcast( () -> doStuffWithFooAndBar(foo, bar) );
Y si es asi?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast(new IgniteRunnable() { @Override public void run() { doStuffWithFooAndBar(foo, bar); } });
Como puede suponer, muchos familiarizados con las trampas de las lambdas y las clases anónimas, el problema está en capturar variables desde el exterior. Por ejemplo, enviamos lambda. Utiliza un par de variables que se declaran fuera de lambda. Esto significa que estas variables viajarán con ella y volarán a través de la red a todos los servidores. Y entonces surgen las mismas preguntas: ¿son estos objetos amigables con BinaryMarshaller ? ¿De qué tamaño son? ¿Generalmente queremos que se transfieran a algún lugar, o son estos objetos tan grandes que es mejor pasar algún tipo de identificación y recrear los objetos dentro del lambda que ya están en el otro lado?
La clase anónima es aún peor. Si el lambda no puede llevarse esto, tírelo, si no se usa, entonces la clase anónima lo tomará con seguridad, y esto generalmente no conduce a nada bueno.
El siguiente ejemplo. Lambda nuevamente, pero que usa la API Apache Ignite un poco.
Usar el encendido dentro del cierre de cálculo es incorrecto
ignite.compute().broadcast(() -> { IgniteCache foo = ignite.cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
En la versión original, toma el caché y localmente hace algún tipo de consulta SQL. Este es un patrón cuando necesita enviar una tarea que solo funciona con datos locales en nodos remotos.
¿Cuál es el problema aquí? La lambda nuevamente captura el enlace, pero ahora no al objeto, sino al Ignite local en el nodo con el que lo enviamos. E incluso funciona, porque el objeto Ignite tiene un método readResolve() , que permite la deserialización para reemplazar el Ignite que vino a través de la red con el local en el nodo donde lo enviamos. Pero esto también a veces conduce a consecuencias indeseables.
Básicamente, simplemente está transfiriendo más datos de la red de los que desea. Si necesita obtener de algún código que no controla el inicio de Apache Ignite o algunas de sus interfaces, entonces lo más simple es usar el método Ignintion.localIgnite() . Puede llamarlo desde cualquier hilo que Apache Ignite haya creado y obtener un enlace a un objeto local. Si tiene lambdas, servicios, cualquier cosa, y comprende que necesita Ignite aquí, le recomiendo este método.
Usamos Ignite dentro del cierre de cálculo correctamente, a través de localIgnite()
ignite.compute().broadcast(() -> { IgniteCache foo = Ignition.localIgnite().cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Y el último ejemplo en esta parte. Apache Ignite tiene una cuadrícula de servicios que se puede usar para implementar microservicios directamente en un clúster, y Apache Ignite ayudará a mantener en línea la cantidad correcta de instancias. Digamos que en este servicio también necesitamos un enlace a Apache Ignite. ¿Cómo conseguirlo? Podríamos usar localIgnite() , pero luego este enlace tendrá que guardarse manualmente en el campo.
El servicio almacena Ignite en un campo incorrectamente , lo toma como argumento para el constructor
MyService s = new MyService(ignite) ignite.services().deployClusterSingleton("svc", s); ... public class MyService implements Service { private Ignite ignite; public MyService(Ignite ignite) { this.ignite = ignite; } ... }
Hay una manera más simple. Todavía tenemos clases completas, y no lambda, por lo que podemos anotar el campo como @IgniteInstanceResource . Cuando se crea el servicio, Apache Ignite se colocará allí, y puede usarlo con seguridad. Le recomiendo encarecidamente que haga exactamente eso, y no intente pasar Apache Ignite y sus hijos al constructor.
El servicio usa @IgniteInstanceResource
public class MyService implements Service { @IgniteInstanceResource private Ignite ignite; public MyService() { } ... }
Escribir y leer datos
Observando la línea de base
Ahora tenemos un clúster Apache Ignite y un código preparado.
Imaginemos este escenario:
- Una caché
REPLICATED : hay copias de datos disponibles en todos los nodos; - La persistencia nativa está activada: escriba en el disco.
Comenzamos un nodo. Como la persistencia nativa está habilitada, necesitamos activar el clúster antes de trabajar con él. Activar Luego lanzamos algunos nodos más.
Todo parece estar funcionando: escribir y leer están bien. Todos los nodos tienen copias de los datos; puede detener de forma segura un nodo. Pero si detiene el primer nodo desde el que inició el lanzamiento, entonces todo se rompe: los datos desaparecen y las operaciones dejan de pasar.
La razón de esto es la topología de referencia: los muchos nodos que almacenan datos de persistencia en ellos. Todos los demás nodos no tendrán datos persistentes.
Este conjunto de nodos por primera vez se determina en el momento de la activación. Y los nodos que agregó posteriormente ya no se incluyen en el número de nodos de línea de base. Es decir, una gran cantidad de topología de línea de base consiste en un solo nodo, el primer nodo, cuando se detiene, todo se rompe. Para evitar que esto suceda, primero inicie todos los nodos y luego active el clúster. Si necesita agregar o eliminar un nodo con el comando
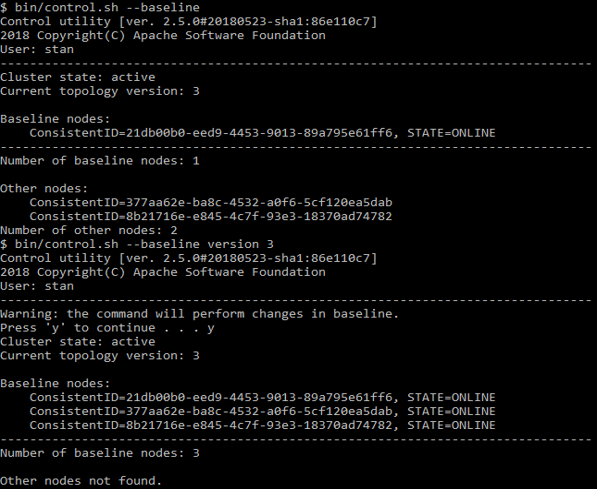
control.sh --baseline
Puede ver qué nodos se enumeran allí. El mismo script puede actualizar la línea base a su estado actual.
Ejemplo de control.sh
Colocación de datos
Ahora que sabemos que los datos están guardados, intente leerlos. Tenemos soporte SQL, puede hacer SELECT , casi como en Oracle. Pero al mismo tiempo, podemos escalar y ejecutar cualquier número de nodos, los datos se almacenan de manera distribuida. Veamos un modelo así:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
Solicitud
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
no devolverá todos los datos. Que esta mal
Persona ( Person ) se refiere a la organización ( Organization ) por ID. Esta es una clave foránea clásica. Pero si intentamos combinar las dos tablas y enviar una consulta SQL, entonces con varios nodos en el clúster no recibiremos todos los datos.
El hecho es que, por defecto, SQL JOIN funciona solo dentro de un solo nodo. Si SQL recorriera constantemente el clúster para recopilar datos y devolver el resultado completo, sería increíblemente lento. Perderíamos todos los beneficios de un sistema distribuido. Entonces, en cambio, Apache Ignite solo mira los datos locales.
Para obtener los resultados correctos, debemos colocar los datos juntos (colocación). Es decir, para la combinación correcta de Persona y Organización, los datos de ambas tablas deben almacenarse en el mismo nodo.
Como hacerlo La solución más fácil es declarar una clave de afinidad. Este es un valor que determina en qué nodo, en qué partición, en qué grupo de registros se ubicará este o ese valor. Si declaramos el ID de la organización en Person como una clave de afinidad, esto significará que las personas con este ID de organización deben estar en el mismo nodo que la organización con el mismo ID.
Si por alguna razón no puede hacer esto, hay otra solución menos efectiva: habilitar las uniones distribuidas. Esto se hace a través de la API, y el procedimiento depende de lo que use: Java, JDBC u otra cosa. Luego, JOIN se ejecutará más lentamente, pero luego devolverá los resultados correctos.
Consideremos cómo trabajar con claves de afinidad. ¿Cómo entendemos que tal y tal identificación, tal y tal campo es adecuado para determinar la afinidad? Si decimos que todas las personas con el mismo orgId se almacenarán juntas, entonces orgId es un grupo indivisible. No podemos distribuirlo entre varios nodos. Si la base de datos contiene 10 organizaciones, habrá 10 grupos indivisibles que se pueden colocar en 10 nodos. Si hay más nodos en el clúster, todos los nodos "extra" permanecerán sin grupos. Esto es muy difícil de definir en tiempo de ejecución, así que piénselo de antemano.
Si tiene una organización grande y 9 pequeñas, el tamaño de los grupos será diferente. Pero Apache Ignite no mira el número de registros en grupos de afinidad cuando los distribuye entre nodos. Por lo tanto, no colocará un grupo en un nodo, sino otros 9 en otro para nivelar de alguna manera la distribución. Más bien, los pondrá 5 y 5 (o 6 y 4, o incluso 7 y 3).
¿Cómo hacer que los datos se distribuyan uniformemente? Podemos tener
- Teclas K
- Una variedad de claves de afinidad;
- Particiones P, es decir, grandes grupos de datos que Apache Ignite distribuirá entre nodos;
- N nodos
Entonces es necesario que la condición
K >> A >> P >> N
donde >> es "mucho más" y los datos se distribuirán de manera relativamente uniforme.
Por cierto, el valor predeterminado es P = 1024.
Lo más probable es que no tenga éxito en una distribución uniforme. Este fue el caso en Apache Ignite 1.x a 1.9. Esto se llamaba FairAffinityFunction y no funcionó muy bien: generó demasiado tráfico entre los nodos. Ahora el algoritmo se llama RendezvousAffinityFunction . No proporciona una distribución absolutamente honesta, el error entre los nodos será más o menos 5-10%.
Lista de verificación para nuevos usuarios de Apache Ignite
- Configurar, leer, almacenar registros
- Desactiva la multidifusión, escribe solo las direcciones y puertos que utilizas
- Deshabilitar IPv6
- Prepare sus clases para
BinaryMarshaller - Lleve un registro de su línea de base
- Configurar colocación de afinidad