El material, cuya traducción publicamos hoy, se centrará en qué hacer en una situación en la que los datos recibidos del servidor no se parecen a las necesidades del cliente. Es decir, al principio consideraremos un problema típico de este tipo, y luego analizaremos varias formas de resolverlo.

El problema de la API del servidor fallida
Consideremos un ejemplo condicional basado en varios proyectos reales. Supongamos que estamos desarrollando un nuevo sitio web para una organización que existe desde hace algún tiempo. Ella ya tiene puntos finales REST, pero no están diseñados para lo que vamos a crear. Aquí necesitamos acceder al servidor solo para autenticar al usuario, obtener información sobre él y descargar una lista de notificaciones no vistas de este usuario. Como resultado, estamos interesados en los siguientes puntos finales de la API del servidor:
/auth : autoriza al usuario y devuelve un token de acceso./profile : devuelve información básica del usuario./notifications : le permite recibir notificaciones de usuario no leídas.
Imagine que nuestra aplicación siempre necesita recibir todos estos datos en una sola unidad, es decir, idealmente, sería bueno si en lugar de tres puntos finales tuviéramos solo uno.
Sin embargo, nos enfrentamos a muchos más problemas que muchos puntos finales. En particular, estamos hablando del hecho de que los datos que recibimos no se ven de la mejor manera.
Por ejemplo, el punto final
/profile se creó en la antigüedad, no estaba escrito en JavaScript, como resultado, los nombres de las propiedades en los datos devueltos parecen inusuales para una aplicación JS:
{ "Profiles": [ { "id": 1234, "Christian_Name": "David", "Surname": "Gilbertson", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/david.png" ] } ], "Last_Login": "2018-01-01" } ] }
En general, nada bueno.
Es cierto que si observa lo que produce el punto final
/notifications , los datos anteriores de
/profile parecerán bastante agradables:
{ "data": { "msg-1234": { "timestamp": "1529739612", "user": { "Christian_Name": "Alice", "Surname": "Guthbertson", "Enhanced": "True", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/alice.png" ] } ] }, "message_summary": "Hey I like your hair, it re", "message": "Hey I like your hair, it really goes nice with your eyes" }, "msg-5678": { "timestamp": "1529731234", "user": { "Christian_Name": "Bob", "Surname": "Smelthsen", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/smelth.png" ] } ] }, "message_summary": "I'm launching my own cryptocu", "message": "I'm launching my own cryptocurrency soon and many thanks for you to look at and talk about" } } }
Aquí la lista de mensajes es un objeto, no una matriz. Además, aquí hay datos de usuario, que están tan incómodamente organizados como en el caso del punto final
/profile . Y, aquí hay una sorpresa, la propiedad de
timestamp contiene la cantidad de segundos desde principios de 1970.
Si tuviera que dibujar un diagrama de la arquitectura de ese sistema infernalmente inconveniente del que acabamos de hablar, se vería como el que se muestra en la figura a continuación. El color rojo se usa para aquellas partes de este circuito que corresponden a datos mal preparados para trabajos posteriores.
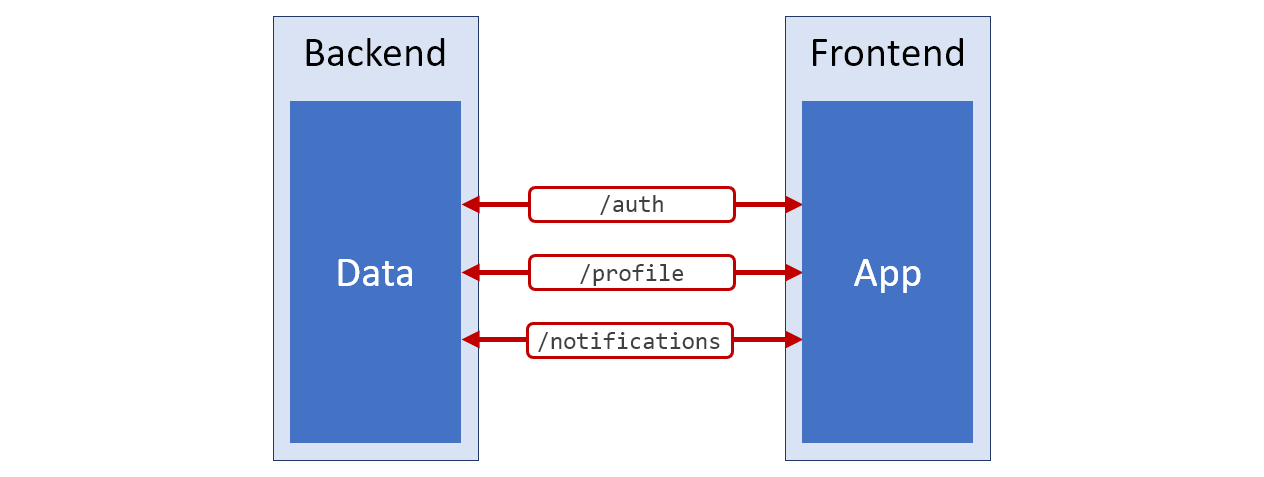 Diagrama del sistema
Diagrama del sistemaEn estas circunstancias, es posible que no nos esforcemos por arreglar la arquitectura de este sistema. Simplemente puede cargar datos de estas tres API y utilizar estos datos en la aplicación. Por ejemplo, si necesita mostrar el nombre de usuario completo en la página, tendremos que combinar las propiedades
Christian_Name y
Surname .
Aquí me gustaría hacer un comentario sobre los nombres. La idea de dividir el nombre completo de una persona en un nombre y apellido personal es característica de los países occidentales. Si está desarrollando algo diseñado para uso internacional, trate de considerar el nombre completo de la persona como una cadena indivisible, y no haga suposiciones sobre cómo dividir esta cadena en partes más pequeñas para usar lo que sucedió en lugares donde necesita brevedad o desea atraer al usuario en un estilo informal.
De vuelta a nuestras estructuras de datos imperfectas. El primer problema obvio que se puede ver aquí se expresa en la necesidad de combinar datos dispares en el código de la interfaz de usuario. Consiste en el hecho de que podemos necesitar repetir esta acción en varios lugares. Si necesita hacer esto solo ocasionalmente, el problema no es tan grave, pero si lo necesita con frecuencia, es mucho peor. Como resultado, hay fenómenos indeseables causados por la falta de coincidencia de cómo se organizan los datos recibidos del servidor y cómo se usan en la aplicación.
El segundo problema es la complejidad del código utilizado para formar la interfaz de usuario. Creo que dicho código debería ser, en primer lugar, lo más simple posible y, en segundo lugar, lo más claro posible. Cuantas más transformaciones internas de datos tenga que hacer en el cliente, mayor será su complejidad, y el código complejo es el lugar donde generalmente se ocultan los errores.
El tercer problema se refiere a los tipos de datos. De los fragmentos de código anteriores, puede ver que, por ejemplo, los identificadores de mensajes son cadenas y los identificadores de usuario son números. Desde un punto de vista técnico, todo está bien, pero tales cosas pueden confundir al programador. Además, mira la presentación de fechas! Pero, ¿qué pasa con el desorden en la parte de los datos que se relaciona con la imagen de perfil? Después de todo, todo lo que necesitamos es una URL que conduzca al archivo correspondiente, y no algo a partir del cual tendremos que crear esta URL nosotros mismos, vadeando la jungla de estructuras de datos anidados.
Si procesamos estos datos, pasándolos al código de la interfaz de usuario, luego, analizando los módulos, no podemos entender inmediatamente exactamente con qué estamos trabajando allí. La conversión de la estructura de datos interna y su tipo al trabajar con ellos crea una carga adicional para el programador. Pero sin todas estas dificultades es muy posible hacerlo.
De hecho, como opción, sería posible implementar un sistema de tipo estático para resolver este problema, pero el tipeo estricto no es capaz, solo por el hecho de su presencia, de hacer que un código incorrecto sea bueno.
Ahora que puede ver la gravedad del problema al que nos enfrentamos, hablemos sobre las formas de resolverlo.
Solución # 1: cambiar la API del servidor
Si el dispositivo inconveniente de la API existente no está dictado por razones importantes, entonces nada le impide crear una nueva versión que se adapte mejor a las necesidades del proyecto y localizar esta nueva versión, por ejemplo, en
/v2 . Quizás este enfoque pueda llamarse la solución más exitosa para los problemas anteriores. El esquema de dicho sistema se presenta en la figura siguiente, la estructura de datos que coincide perfectamente con las necesidades del cliente se resalta en verde.
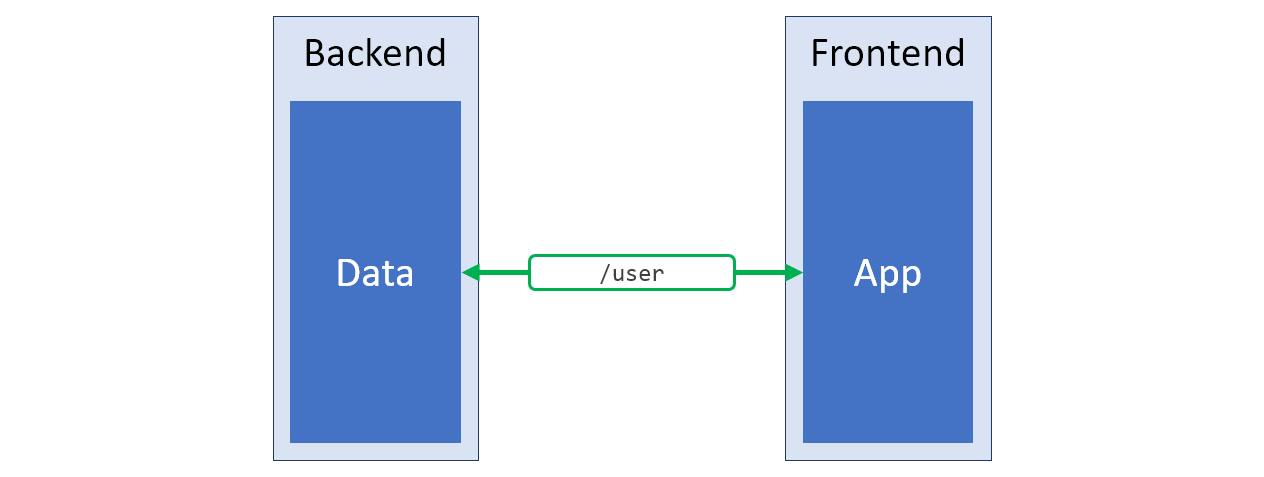 La nueva API del servidor que produce exactamente lo que necesita el lado del cliente del sistema
La nueva API del servidor que produce exactamente lo que necesita el lado del cliente del sistemaComenzando a desarrollar un nuevo proyecto, cuya API deja mucho que desear, siempre estoy interesado en la posibilidad de implementar el enfoque que acabo de describir. Sin embargo, a veces el dispositivo API, aunque sea inconveniente, tiene algunos objetivos importantes, o simplemente no es posible cambiar la API del servidor. En este caso, recurro al siguiente enfoque.
Solución # 2: Patrón BFF
Este es un buen patrón BFF (
Backend-For-the-Frontend ). Con este patrón, puede abstraerse de los intrincados puntos finales REST universales y proporcionar al front-end exactamente lo que necesita. Aquí hay una representación esquemática de tal solución.
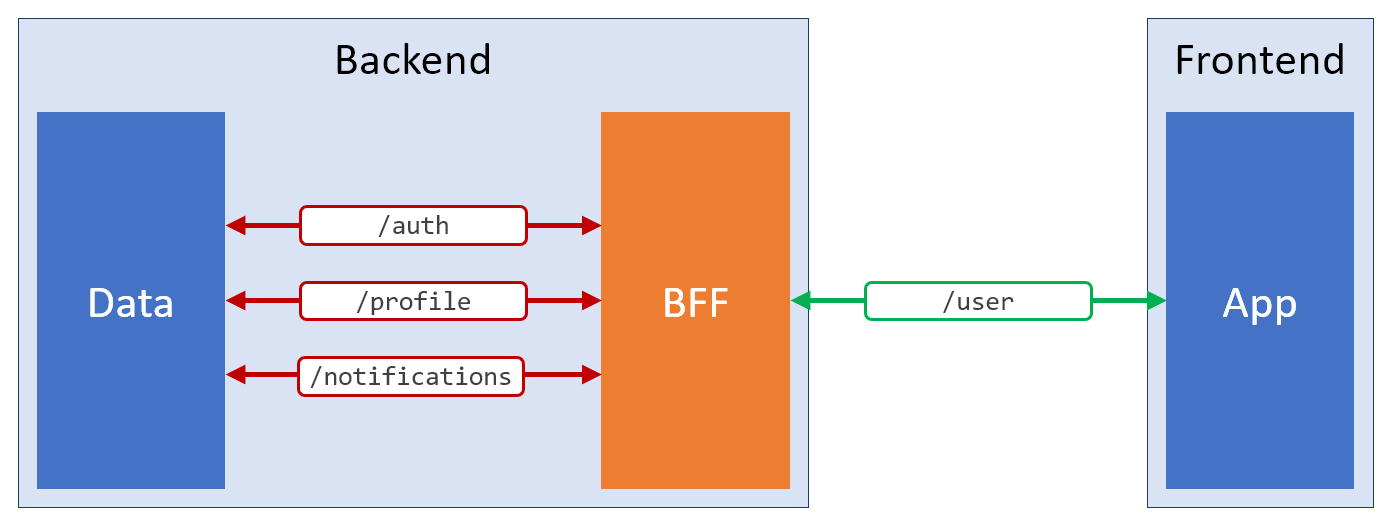 Aplicando el patrón BFF
Aplicando el patrón BFFEl significado de la existencia de la capa BFF es satisfacer las necesidades de la interfaz. Quizás usará puntos finales REST adicionales, o servicios GraphQL, o sockets web, o cualquier otra cosa. Su objetivo principal es hacer todo lo posible para la conveniencia del lado del cliente de la aplicación.
Mi arquitectura favorita es NodeJS BFF, que utiliza los desarrolladores front-end que pueden hacer lo que necesitan, creando excelentes API para las aplicaciones cliente que desarrollan. Idealmente, el código correspondiente está en el mismo repositorio que el código del front-end, lo que simplifica el intercambio de código, por ejemplo, para verificar los datos enviados, tanto en el cliente como en el servidor.
Además, esto significa que las tareas que requieren cambios en la parte del cliente de la aplicación y su API de servidor se realizan en un repositorio. Un poco, como dicen, pero agradable.
Sin embargo, BFF no siempre se puede usar. Y este hecho nos lleva a otra solución al problema del uso conveniente de las API de servidores defectuosos.
Solución # 3: Patrón BIF
El patrón BIF (Backend In the Frontend) usa la misma lógica que se puede aplicar usando BFF (combinando múltiples API y limpieza de datos), pero esta lógica se mueve hacia el lado del cliente. En realidad, esta idea no es nueva, podría haberse visto hace veinte años, pero este enfoque puede ayudar a trabajar con API de servidor mal organizadas, por eso estamos hablando de ello. Así es como se ve.
 Aplicando el patrón BIF
Aplicando el patrón BIF▍ ¿Qué es un BIF?
Como se puede ver en la sección anterior, BIF es un patrón, es decir, un enfoque para comprender el código y su organización. Su uso no conduce a la necesidad de eliminar ninguna lógica del proyecto. Simplemente separa la lógica de un tipo (modificación de estructuras de datos) de la lógica de otro tipo (la formación de la interfaz de usuario). Esto es similar a la idea de una "separación de responsabilidades", que todos están escuchando.
Aquí me gustaría señalar que, aunque esto no se puede llamar un desastre, a menudo tuve que ver implementaciones analfabetas de BIF. Por lo tanto, me parece que muchos estarán interesados en escuchar una historia sobre cómo implementar correctamente este patrón.
El código BIF debe considerarse como un código que una vez puede tomarse y transferirse al servidor Node.js, después de lo cual todo funcionará de la misma manera que antes. O incluso transfiéralo a un paquete privado de NPM, que se usará en varios proyectos front-end en el marco de una compañía, lo cual es simplemente increíble.
Recuerde que discutimos anteriormente los principales problemas que surgen cuando se trabaja con una API de servidor fallida. Entre ellos se encuentra una llamada demasiado frecuente a la API y el hecho de que los datos devueltos por ellos no satisfacen las necesidades de la interfaz.
Dividiremos la solución a cada uno de estos problemas en bloques de código separados, cada uno de los cuales se colocará en su propio archivo. Como resultado, la capa BIF de la parte cliente de la aplicación constará de dos archivos. Además, se les adjuntará un archivo de prueba.
▍ Combinando llamadas API
Hacer muchas llamadas a las API del servidor en nuestro código de cliente no es un problema tan grave. Sin embargo, me gustaría resumirlo, para que sea posible cumplir con una sola "solicitud" (desde el código de la aplicación a la capa BIF), y obtener exactamente lo que se necesita en respuesta.
Por supuesto, en nuestro caso, no hay escapatoria al hacer tres solicitudes HTTP al servidor, pero la aplicación no necesita saberlo.
La API de mi capa BIF se representa como funciones. Por lo tanto, cuando la aplicación necesita algunos datos sobre el usuario, llamará a la función
getUser() , que le devolverá estos datos. Así es como se ve esta función:
import parseUserData from './parseUserData'; import fetchJson from './fetchJson'; export const getUser = async () => { const auth = await fetchJson('/auth'); const [ profile, notifications ] = await Promise.all([ fetchJson(`/profile/${auth.userId}`, auth.jwt), fetchJson(`/notifications/${auth.userId}`, auth.jwt), ]); return parseUserData(auth, profile, notifications); };
Aquí, primero, se realiza una solicitud al servicio de autenticación para obtener un token, que se puede utilizar para autorizar al usuario (no hablaremos de los mecanismos de autenticación aquí, pero nuestro objetivo principal es BIF).
Después de recibir el token, puede ejecutar simultáneamente dos solicitudes que reciben datos de perfil de usuario e información sobre notificaciones no leídas.
Por cierto, mire cuán hermosa se ve la construcción
async/await al trabajar con ella usando
Promise.all y usando la asignación destructiva.
Entonces, este fue el primer paso, aquí extrajimos el hecho de que el acceso al servidor incluye tres solicitudes. Sin embargo, el caso aún no se ha hecho. Es decir, preste atención a la llamada a la función
parseUserData() , que, como puede juzgar por su nombre,
parseUserData() los datos recibidos del servidor. Hablemos de ella.
▍ Limpieza de datos
Quiero dar una recomendación de inmediato, que, creo, puede afectar seriamente un proyecto que anteriormente no tenía una capa BIF, en particular, un nuevo proyecto. Intenta no pensar en lo que obtienes del servidor por un tiempo. En cambio, concéntrese en qué datos necesita su aplicación.
Además, es mejor no intentar, al diseñar la aplicación, tener en cuenta sus posibles necesidades futuras, por ejemplo, relacionadas con 2021. Solo trate de hacer que la aplicación funcione exactamente como debería ser hoy. El hecho es que el entusiasmo excesivo por la planificación y los intentos de predecir el futuro es la razón principal de la complicación injustificada de los proyectos de software.
Entonces, volvamos a nuestro negocio. Ahora sabemos cómo se ven los datos recibidos de las tres API del servidor, y sabemos en qué deberían convertirse después del análisis.
Parece que este es uno de esos casos raros cuando el uso de TDD realmente tiene sentido. Por lo tanto, escribiremos una gran prueba larga para la función
parseUserData() :
import parseUserData from './parseUserData'; it('should parse the data', () => { const authApiData = { userId: 1234, jwt: 'the jwt', }; const profileApiData = { Profiles: [ { id: 1234, Christian_Name: 'David', Surname: 'Gilbertson', Photographs: [ { Size: 'Medium', URLS: [ '/images/david.png', ], }, ], Last_Login: '2018-01-01' }, ], }; const notificationsApiData = { data: { 'msg-1234': { timestamp: '1529739612', user: { Christian_Name: 'Alice', Surname: 'Guthbertson', Enhanced: 'True', Photographs: [ { Size: 'Medium', URLS: [ '/images/alice.png' ] } ] }, message_summary: 'Hey I like your hair, it re', message: 'Hey I like your hair, it really goes nice with your eyes' }, 'msg-5678': { timestamp: '1529731234', user: { Christian_Name: 'Bob', Surname: 'Smelthsen', }, message_summary: 'I\'m launching my own cryptocu', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, }, }; const parsedData = parseUserData(authApiData, profileApiData, notificationsApiData); expect(parsedData).toEqual({ jwt: 'the jwt', id: '1234', name: 'David Gilbertson', photoUrl: '/images/david.png', notifications: [ { id: 'msg-1234', dateTime: expect.any(Date), name: 'Alice Guthbertson', premiumMember: true, photoUrl: '/images/alice.png', message: 'Hey I like your hair, it really goes nice with your eyes' }, { id: 'msg-5678', dateTime: expect.any(Date), name: 'Bob Smelthsen', premiumMember: false, photoUrl: '/images/placeholder.jpg', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, ], }); });
Y aquí está el código de la función en sí:
const getPhotoFromProfile = profile => { try { return profile.Photographs[0].URLS[0]; } catch (err) { return '/images/placeholder.jpg'; // } }; const getFullNameFromProfile = profile => `${profile.Christian_Name} ${profile.Surname}`; export default function parseUserData(authApiData, profileApiData, notificationsApiData) { const profile = profileApiData.Profiles[0]; const result = { jwt: authApiData.jwt, id: authApiData.userId.toString(), // ID name: getFullNameFromProfile(profile), photoUrl: getPhotoFromProfile(profile), notifications: [], // , }; Object.entries(notificationsApiData.data).forEach(([id, notification]) => { result.notifications.push({ id, dateTime: new Date(Number(notification.timestamp) * 1000), // , , , Unix, name: getFullNameFromProfile(notification.user), photoUrl: getPhotoFromProfile(notification.user), message: notification.message, premiumMember: notification.user.Enhanced === 'True', }) }); return result; }
Me gustaría señalar que cuando es posible recopilar en un lugar doscientas líneas de código responsables de modificar los datos dispersos antes de esto en toda la aplicación, causa una sensación maravillosa. Ahora todo esto está en un archivo, las pruebas unitarias se escriben para este código, y todos los momentos ambiguos reciben comentarios.
Dije anteriormente que BFF es mi enfoque favorito para combinar y borrar datos, pero hay un área en la que BIF es superior a BFF. A saber, los datos recibidos del servidor pueden incluir objetos de JavaScript que no son compatibles con JSON, como los objetos de
Date o
Map (tal vez esta es una de las características de JavaScript más infrautilizadas). Por ejemplo, en nuestro caso, tenemos que convertir la fecha que vino del servidor (expresada en segundos, no milisegundos) en un objeto JS de tipo
Date .
Resumen
Si cree que su proyecto tiene algo en común con el que examinamos los problemas de las API fallidas, analice su código haciéndose las siguientes preguntas sobre el uso de datos del servidor en el cliente:
- ¿Tiene que combinar propiedades que nunca se usan por separado (por ejemplo, el nombre y apellido del usuario)?
- ¿El código JS tiene que funcionar con nombres de propiedad formados de una manera que no se acepta en JS (algo así como PascalCase)?
- ¿Cuáles son los tipos de datos de los distintos identificadores? Tal vez a veces estas son cadenas, a veces números?
- ¿Cómo se presentan las fechas en su proyecto? ¿Quizás a veces se trata de objetos
Date JS listos para usar en la interfaz y, a veces, números o incluso cadenas? - ¿A menudo tiene que verificar las propiedades para su existencia, o verificar si una entidad es una matriz antes de comenzar a enumerar los elementos de esta entidad para formar algún fragmento de la interfaz de usuario sobre la base? ¿Podría ser que esta entidad no sea una matriz, incluso si está vacía?
- ¿Tiene que ordenar o filtrar las matrices al formar la interfaz, que, idealmente, ya debería estar ordenada y filtrada correctamente?
- Si resulta que, cuando se verifican las propiedades para su existencia, no se buscan propiedades, ¿tiene que cambiar a usar algunos valores predeterminados (por ejemplo, usar una imagen estándar cuando no hay una foto de usuario en los datos recibidos del servidor)?
- ¿Las propiedades tienen un nombre uniforme? ¿Ocurre que la misma entidad puede tener diferentes nombres, lo que posiblemente sea causado por el uso conjunto de, relativamente hablando, API de servidor "antiguas" y "nuevas"?
- ¿Tiene que, junto con datos útiles, transferir a algún lugar datos que nunca se utilizan, haciendo esto solo porque proviene de la API del servidor? ¿Estos datos no utilizados interfieren con la depuración?
Si puede responder positivamente una o dos preguntas de esta lista, entonces quizás no debería reparar algo que ya funciona correctamente.
Sin embargo, si, al leer estas preguntas, descubre en cada una de ellas los problemas de su proyecto, si el dispositivo de su código es innecesariamente complicado debido a todo esto, si es difícil de percibir y probar, si contiene errores que son difíciles de detectar, eche un vistazo al patrón BIF.
Al final, quiero decir que al introducir la capa BIF en las aplicaciones existentes, las cosas son más fáciles debido al hecho de que esto se puede hacer en etapas, en pequeños pasos. Digamos que la primera versión de la función para preparar datos, llamémosla
parseData() , puede simplemente, sin cambios, devolver lo que viene a su entrada. Luego, puede mover gradualmente la lógica del código responsable de crear la interfaz de usuario para esta función.
Estimados lectores! , BIF?
