
El diseño académico del almacén de datos recomienda mantener todo en una forma normalizada, con conexiones entre ellos. Luego, la reversión de los cambios en las matemáticas relacionales proporcionará un repositorio confiable con soporte de transacciones. Atomicidad, Consistencia, Aislamiento, Durabilidad, eso es todo. En otras palabras, el repositorio está especialmente diseñado para actualizar de forma segura los datos. Pero no es para nada óptimo para la búsqueda, especialmente con un amplio gesto a través de tablas y campos. Necesito índices, muchos índices. Los volúmenes crecen, la grabación se ralentiza. SQL LIKE no está indexado y JOIN GROUP BY lo envía al planificador de consultas para meditar.
La carga creciente en una máquina la obliga a expandirse, ya sea verticalmente hacia el techo u horizontalmente, comprando algunos nodos más. Los requisitos de conmutación por error hacen que los datos se distribuyan entre múltiples nodos. Y el requisito de recuperación inmediata después de una falla, sin una denegación de servicio, lo obliga a configurar el clúster de máquinas para que en cualquier momento cualquiera de ellas pueda realizar tanto la escritura como la lectura. Es decir, ser un maestro o convertirse en él de forma automática e inmediata.
El problema de la búsqueda rápida se resolvió instalando un segundo repositorio optimizado para la indexación cercana. Búsqueda de texto completo, facetado, con stemming y blackjack . El segundo almacenamiento acepta entradas de las tablas del primero como entrada, analiza y construye el índice. Por lo tanto, el clúster de almacenamiento de datos se complementó con otro clúster para su búsqueda. Con una configuración maestra similar para que coincida con el SLA general. Todo está bien, el negocio está encantado, los administradores duermen por la noche ... hasta que haya más de tres máquinas en el clúster maestro-maestro.
Elástico
El movimiento NoSQL ha ampliado enormemente el horizonte de escala para datos pequeños y grandes. Los nodos NoSQL del clúster pueden distribuir datos entre ellos para que la falla de uno o más de ellos no conduzca a una denegación de servicio para todo el clúster. El pago por la alta disponibilidad de datos distribuidos fue la incapacidad de garantizar su completa coherencia para el registro en un momento dado. En cambio, NoSQL habla de una consistencia eventual . Es decir, se cree que algún día todos los datos se dispersarán a los nodos del clúster y se volverán consistentes a largo plazo.
Por lo tanto, el modelo relacional se complementó con el no relacional y generó muchos motores de bases de datos que resolvieron los problemas del triángulo CAP con cierto éxito. Los desarrolladores pusieron en sus manos herramientas de moda para construir su propia capa de persistencia ideal, para todos los gustos, presupuestos y perfiles de carga.
ElasticSearch es un representante de NoSQL agrupado con una API JSON RESTful en el motor Lucene, de código abierto en Java, capaz no solo de crear un índice de búsqueda, sino también de almacenar el documento original. Tal finta ayuda a repensar el papel de un DBMS separado para almacenar originales, o incluso abandonarlo. El final de la introducción.
Mapeo
La asignación en ElasticSearch es algo así como un esquema (estructura de tabla, en términos de SQL) que le dice exactamente cómo indexar los documentos entrantes (registros, en términos de SQL). El mapeo puede ser estático, dinámico o ausente. El mapeo estático no permite que se cambie. Dinámico le permite agregar nuevos campos. Si no se especifica el mapeo, ElasticSearch lo hará solo, después de haber recibido el primer documento para escribir. Analizará la estructura de los campos, hará algunas suposiciones sobre los tipos de datos en ellos, saltará las configuraciones predeterminadas y las escribirá. Tal comportamiento sin circuito a primera vista parece muy conveniente. Pero, de hecho, es más adecuado para la experimentación que para las sorpresas en la producción.
Entonces, los datos están indexados, y este es un proceso unidireccional. Una vez creado, la asignación no se puede cambiar dinámicamente como ALTER TABLE en SQL. Porque la tabla SQL almacena el documento original en el que puede fijar el índice de búsqueda. Pero en ElasticSearch lo contrario. Él mismo es el índice de búsqueda al que puede sujetar el documento original. Es por eso que el esquema de índice es estático. Teóricamente, uno podría crear un campo en el mapeo o eliminarlo. En la práctica, ElasticSearch solo le permite agregar campos. Un intento de eliminar un campo no conduce a nada.
Alias
Alias: este es un nombre adicional para el índice ElasticSearch. Puede haber varios alias para un índice. O un alias para múltiples índices. Luego, los índices se combinan lógicamente como si fueran del exterior y se parecen a uno. Alias es muy conveniente para los servicios que se comunican con el índice a lo largo de su vida. Por ejemplo, los productos de alias pueden ocultar productos_v2 y productos_v25 , sin tener que cambiar los nombres en el servicio. El alias es indispensable para la migración de datos, cuando ya se transfieren del esquema anterior al nuevo, y debe cambiar la aplicación para que funcione con el nuevo índice. Cambiar un alias de índice a índice es una operación atómica. Es decir, se realiza en un solo paso sin pérdida.
Reindex API
El diseño de datos, mapeo, tiende a cambiar de vez en cuando. Se agregan nuevos campos, se eliminan los innecesarios. Si ElasticSearch desempeña el papel del único repositorio, entonces necesita algún tipo de herramienta para cambiar la asignación sobre la marcha. Para hacer esto, hay un comando especial para transferir datos de un índice a otro, la llamada API _reindex . Funciona con el mapeo vacío o listo del índice del destinatario, en el lado del servidor, indexando rápidamente en lotes de 1000 documentos a la vez.
La reindexación puede hacer una conversión de tipo de campo simple. Por ejemplo, largo en texto y de regreso en largo , o booleano en texto y de regreso en booleano . Pero -9.99 en booleano ya no sabe cómo, no es PHP para ti . Por otro lado, la conversión de tipos no es segura. Un servicio escrito en un idioma con mecanografía dinámica puede ser perdonado por tal pecado. Pero si reindex no puede convertir el tipo, entonces el documento simplemente no se escribirá. En general, la migración de datos debe realizarse en 3 etapas: agregar un nuevo campo, liberar un servicio con él, limpiar el antiguo.
Se agrega un campo como este. Se toma el esquema del índice de origen, se ingresa una nueva propiedad, se crea un índice vacío. Entonces comienza la reindexación:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
El campo se elimina de manera similar. Se toma el esquema del índice de origen, se elimina el campo y se crea un índice vacío. Luego, la reindexación se inicia con una lista de los campos que se copiarán:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
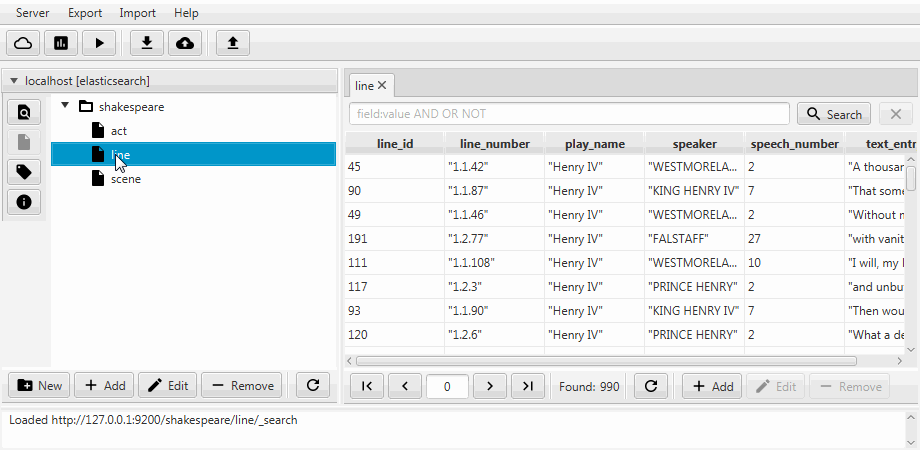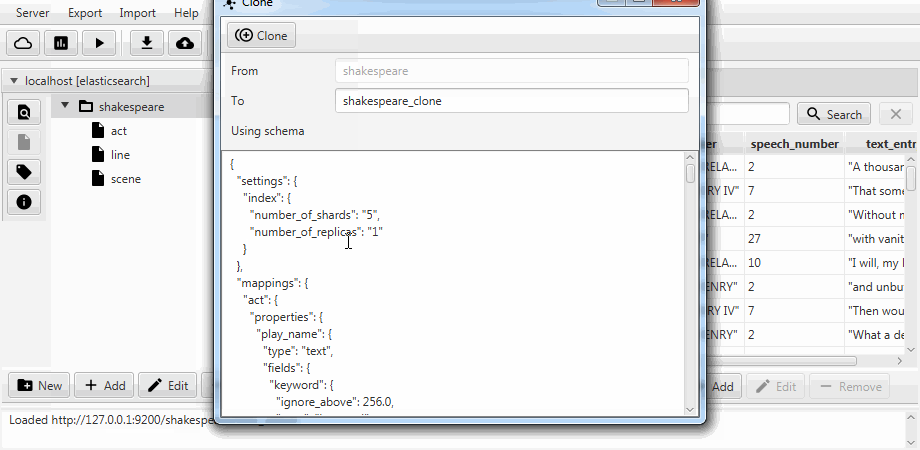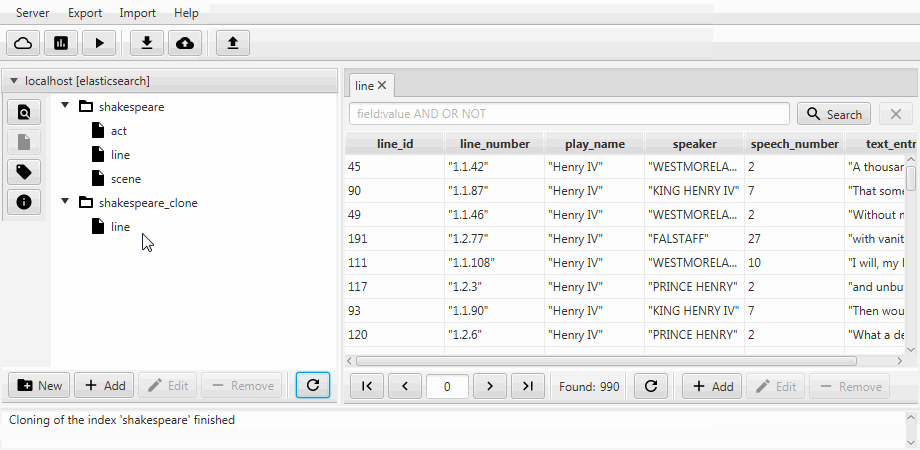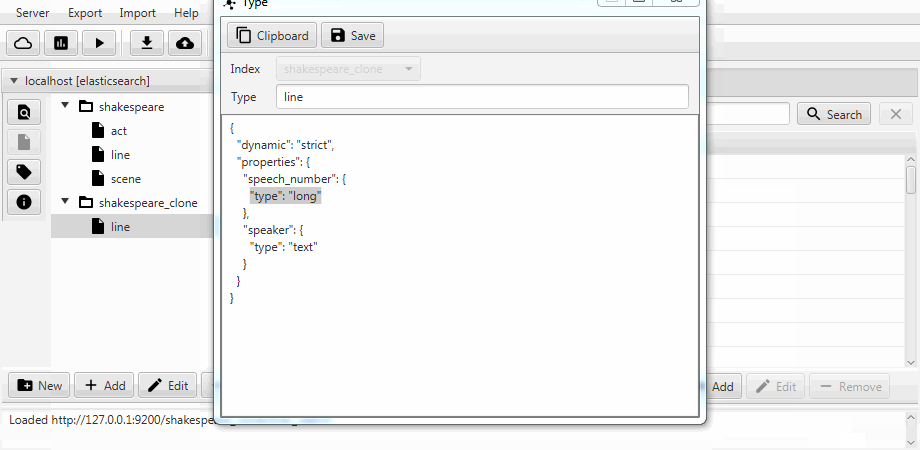
Por conveniencia, ambos casos se combinan en una función de clonación en Kaizen, un cliente de escritorio para ElasticSearch. La clonación puede adaptarse a la asignación del índice de destino. El siguiente ejemplo muestra cómo hacer un clon parcial a partir de un índice con tres colecciones (tipos, en términos de ElasticSearch) acto , línea , escena . Solo queda una línea con dos campos, la asignación estática está habilitada y el campo discurso_número del texto se hace largo .
La migracion
La API reindex tiene una característica desagradable: no sabe cómo monitorear los cambios en el índice de origen. Si algo cambia allí después de que comienza la reindexación, los cambios no se reflejan en el índice del destinatario. Para resolver este problema, se desarrolló ElasticSearch FollowUp Plugin, que agrega comandos de registro. El complemento puede monitorear el índice, devolviendo en formato JSON las acciones realizadas en los documentos en orden cronológico. Se recuerda el índice, el tipo, el identificador de documento y la operación en él: ÍNDICE o SUPRIMIR. FollowUp Plugin se publica en GitHub y se compila para casi todas las versiones de ElasticSearch.
Por lo tanto, para la migración de datos sin pérdida, necesitará FollowUp instalado en el nodo donde comenzará la reindexación. Se supone que el índice ya tiene un alias, y todas las aplicaciones funcionan a través de él. Justo antes de reindexar, el complemento está activado. Cuando se completa la reindexación, el complemento se cierra y el alias se voltea al nuevo índice. Luego, las acciones grabadas se reproducen en el índice del receptor, poniéndose al día con su estado. A pesar de la alta velocidad de reindexación, pueden ocurrir dos tipos de colisiones durante la reproducción:
- ya no hay un documento con tal _id en el nuevo índice. Se las arreglaron para eliminar el documento después de cambiar el alias al nuevo índice.
- en el nuevo índice hay un documento con dicho _id , pero con un número de versión más alto que en el índice de origen. Se las arreglaron para actualizar el documento después de cambiar el alias al nuevo índice.
En estos casos, la acción no debe reproducirse en el índice de destino. Se reproducen otros cambios.
¡Feliz codificación!