 Esta es una historia real. Los eventos que se describen en la publicación ocurrieron en un país cálido en el siglo XXI. Por si acaso, los nombres de los personajes han sido cambiados. Por respeto a la profesión, todo se cuenta como realmente fue.
Esta es una historia real. Los eventos que se describen en la publicación ocurrieron en un país cálido en el siglo XXI. Por si acaso, los nombres de los personajes han sido cambiados. Por respeto a la profesión, todo se cuenta como realmente fue.
Hola Habr En esta publicación hablaremos sobre las famosas pruebas A / B, desafortunadamente, incluso en el siglo XXI, no se puede evitar. Las opciones de prueba alternativas han existido y florecido en línea durante mucho tiempo, mientras que las fuera de línea tienen que adaptarse según la situación. Hablaremos sobre una de esas adaptaciones en el comercio minorista fuera de línea masivo, sazonando la experiencia de trabajar con una oficina de consultoría superior, en general, bajo cat.
Desafío
 En el pasado, trabajé en un proyecto en una gran empresa que posee una red de tiendas de abarrotes, más de 500 tiendas. Me temo que no debería nombrar a la compañía, llamaremos a esta organización la Compañía. La conclusión es que las tiendas son de diferentes tamaños, pueden variar en tamaño decenas de veces; las tiendas pueden estar en diferentes ciudades, pueblos y aldeas; Las tiendas pueden estar en diferentes áreas de la ciudad con sus propios datos demográficos. Aquí, en general, tiendo al hecho de que si necesita probar alguna hipótesis, en el paradigma de prueba A / B es casi imposible hacerlo sin causar un daño significativo al negocio. Consideremos todo esto con el ejemplo de la cerveza. Una vez que la Oficina de Consultoría llega a la Compañía, ya sabes, estos son de la parte superior y dicen: "Pero sabes, querida, aquí tienes cerveza que no es de las marcas correctas en las ventanas, y generalmente no en el orden que necesitas, envíanos un par de oro Kamaz y le diremos qué marcas necesita y cómo desplegarlas, de acuerdo con nuestras estimaciones, esto le traerá mil millones de dólares canadienses en el primer año después del piloto ". La oficina es respetada, por lo que no puede haber dudas acerca de mil millones. Además, los métodos de la Oficina no pueden ponerse en duda, ya que no pueden mentir. Simplemente no nosotros. En general, el autor de estas líneas viene con una tarea de la forma "bueno, mira cómo hacen el piloto, ayuda si necesitan algo".
En el pasado, trabajé en un proyecto en una gran empresa que posee una red de tiendas de abarrotes, más de 500 tiendas. Me temo que no debería nombrar a la compañía, llamaremos a esta organización la Compañía. La conclusión es que las tiendas son de diferentes tamaños, pueden variar en tamaño decenas de veces; las tiendas pueden estar en diferentes ciudades, pueblos y aldeas; Las tiendas pueden estar en diferentes áreas de la ciudad con sus propios datos demográficos. Aquí, en general, tiendo al hecho de que si necesita probar alguna hipótesis, en el paradigma de prueba A / B es casi imposible hacerlo sin causar un daño significativo al negocio. Consideremos todo esto con el ejemplo de la cerveza. Una vez que la Oficina de Consultoría llega a la Compañía, ya sabes, estos son de la parte superior y dicen: "Pero sabes, querida, aquí tienes cerveza que no es de las marcas correctas en las ventanas, y generalmente no en el orden que necesitas, envíanos un par de oro Kamaz y le diremos qué marcas necesita y cómo desplegarlas, de acuerdo con nuestras estimaciones, esto le traerá mil millones de dólares canadienses en el primer año después del piloto ". La oficina es respetada, por lo que no puede haber dudas acerca de mil millones. Además, los métodos de la Oficina no pueden ponerse en duda, ya que no pueden mentir. Simplemente no nosotros. En general, el autor de estas líneas viene con una tarea de la forma "bueno, mira cómo hacen el piloto, ayuda si necesitan algo".
Después de escuchar una breve conferencia sobre cómo funciona su metodología para generar la visualización de productos en una ventana de visualización, el deseo de entrar en detalles del algoritmo desapareció por completo. Decidí concentrarme en medir la calidad, que es mucho más interesante desde el punto de vista de la teoría. También le permite a la Compañía no invertir en proyectos deliberadamente no rentables. Al tener acceso a universos paralelos, sería posible realizar una prueba A / B, donde en el universo A todo va como antes, y en el universo B el diseño de los productos ha cambiado. La prueba A / B es un tipo de experimento controlado donde los usuarios se dividen aleatoriamente en grupos de control y prueba. Se realiza una intervención en el grupo de prueba, espera un cierto tiempo, se mide el efecto de dicha intervención en los indicadores objetivo y finalmente se comparan los indicadores de los dos grupos. Sería deseable minimizar el sesgo entre el control y los grupos de prueba entre sí. Por ejemplo, para que no haya tal cosa que en el grupo A solo hay ciudades, y en el grupo B solo pueblos. Con los sitios, parece que el problema de la compensación se resuelve fácilmente: muestre a los usuarios con una ID par una versión y con una ID impar otra versión del sitio. En una situación con una cadena de tiendas, no todo es tan simple, no importa cómo separe a los usuarios o las tiendas, siempre resulta que los grupos A y B no son iguales. Ese grupo A viene a la tienda durante el día y B por la noche. Al alinear el tiempo, resulta que A viene los fines de semana con más frecuencia que B. Al alinear todos esos detalles, resulta que para obtener resultados estadísticamente significativos, tendrá que esperar medio año y cancelar todas las empresas de comercialización. Si golpeas las ciudades, resulta que Moscú está presente en un grupo y ausente en otro. En general, siempre hay un cambio en un grupo en relación con otro. Sobre esto se superponen varias campañas de marketing globales y locales, vacaciones y circunstancias imprevistas en forma de reparación de estacionamientos.
Recuerda que la oficina es de la parte superior de las oficinas mundiales y, naturalmente, tiene una solución al problema de las pruebas. Considere su metodología, con un nombre comercial fuerte: la metodología de triple diferencia.
Metodología de triple diferencia
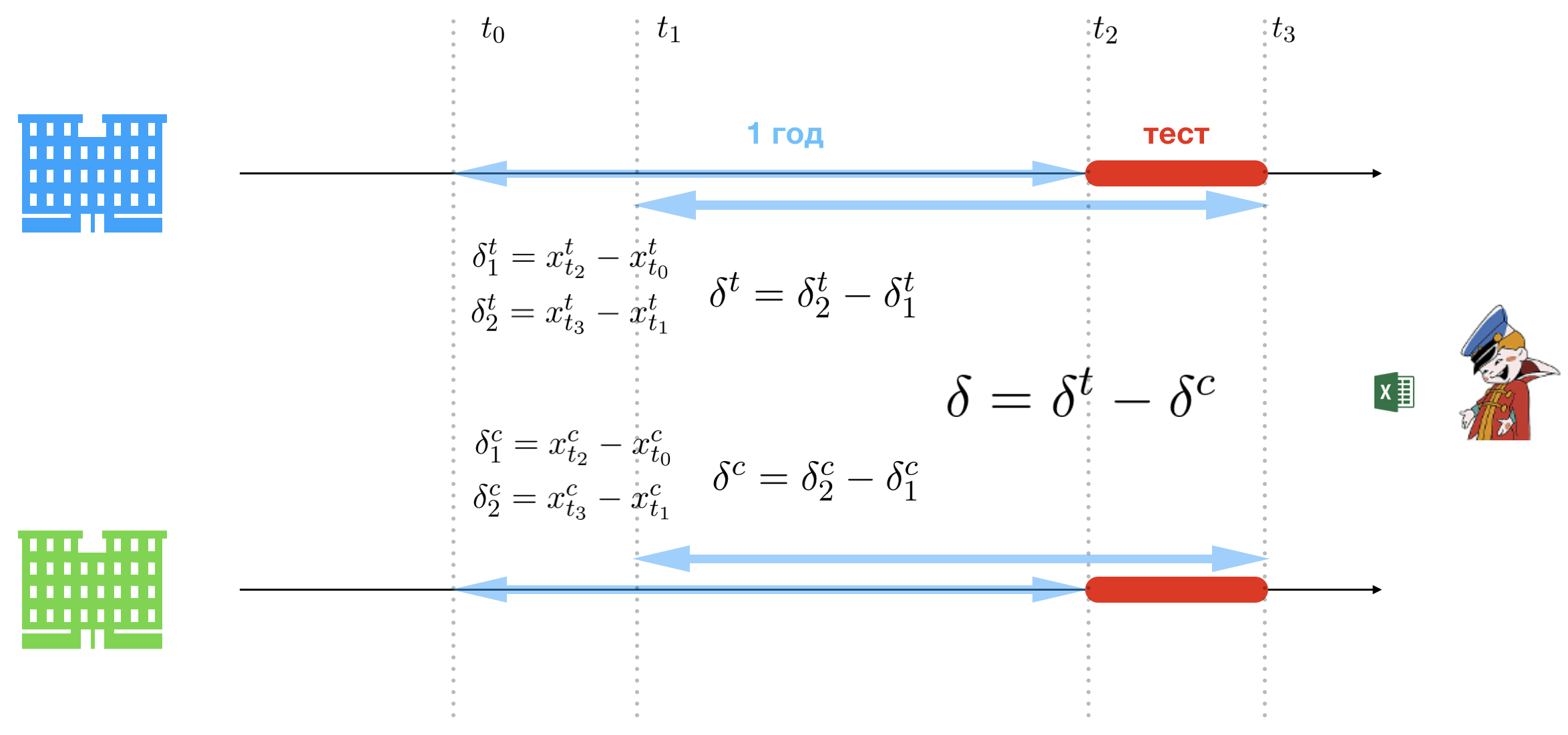
La esencia de la metodología de la triple diferencia es la simplicidad. Y para que las partes superiores de la compañía no se esfuercen al escuchar la presentación, esta presentación será realizada por una dama de apariencia no mala. La simplicidad se logra relajando las limitaciones de la prueba A / B. La única dificultad que queda en el camino de la Oficina es la elección de un grupo de control y prueba, pero omitiremos esta parte del proceso, ya que no hay nada interesante excepto un gran conjunto de suposiciones dudosas. Entonces, como resultado de un análisis exhaustivo de la cadena de tiendas existente, la Oficina selecciona dos: uno para el grupo de control (verde) y otro para el grupo de prueba (azul).
Presentamos la siguiente notación:
- t 2 : fecha de inicio del piloto;
- t 3 : fecha de finalización del piloto;
- t 0 = t 2 - u n a ñ o : fecha correspondiente a la fecha en que el piloto comenzó el año pasado;
- t 1 = t 3 - u n a ñ o : fecha correspondiente al último año del piloto.
Por lo tanto, tenemos dos períodos de tiempo:
- l e f t [ t 2 , t 3 r i g h t ] : período del piloto (período del experimento);
- l e f t [ t 0 , t 1 r i g h t ] : período correspondiente al período del piloto el año pasado.
Se propone comparar los ingresos de la tienda de prueba y el período de control para los períodos del piloto y hace un año. Para hacer esto, necesita contar tres grupos de diferencias. Denota ventas por día t en la tienda de prueba para x T t y x C t - En el control. El primer grupo establece la línea de base a partir de la cual se medirá el crecimiento o la disminución de las ventas en el período piloto:
- deltaT1=xTt2−xTt0 : la diferencia en ventas entre el inicio del piloto y la misma fecha hace un año en la tienda de prueba;
- deltaT2=xTt3−xTt1 : diferencia en las ventas entre el final del piloto y la misma fecha hace un año en la tienda de prueba;
- deltaC1=xCt2−xCt0 : la diferencia en las ventas entre el inicio del piloto y la misma fecha hace un año en la tienda de control;
- deltaC2=xCt3−xCt1 : la diferencia en ventas entre el final del piloto y la misma fecha hace un año en la tienda de control.
El segundo grupo de diferencias establece el crecimiento o la disminución de las ventas en el período piloto:
- deltaT= deltaT2− deltaT1 : diferencia en las ventas entre el final del piloto y el comienzo del piloto en la tienda de prueba (ajustado a las fechas hace un año);
- deltaC= deltaC2− deltaC1 : diferencia en las ventas entre el final del piloto y el comienzo del piloto en la tienda de control (ajustado a las fechas de hace un año).
Y finalmente, la diferencia decisiva determina qué tienda funcionó mejor en el período piloto:
Bueno, la decisión de implementar un proyecto con el costo del oro KAMAZ es muy simple si delta>0 - significa que la tienda de prueba vendió más cerveza, por lo tanto, la metodología de Office funciona y da un efecto positivo, por lo tanto, debe introducirse. Eso es todo.
Prueba A / B con línea base ML
Después de estudiar la metodología de la triple diferencia y descubrir que las autoridades ya habían aprobado este método de medición y el piloto comenzó a planificar, mi mano me golpeó dolorosamente en la cara. Resulta que la oficina nos ofrece invertir oro KAMAZ en el proyecto, incluso si la metodología no funciona, y la diferencia en ventas fue de 1 rublo, por casualidad. Era urgente desarrollar algo que diera al menos algo de confianza en la efectividad de la nueva forma de poner cerveza en el estante. Como recordará, una de las formas de realizar una prueba A / B honesta fuera de línea es la existencia de universos paralelos, luego en uno podemos introducir la metodología de cálculo de la cerveza, en el segundo dejamos todo como está, espere un momento y compare los resultados. Pero, ¿qué pasa si simulamos universos paralelos con aprendizaje automático?

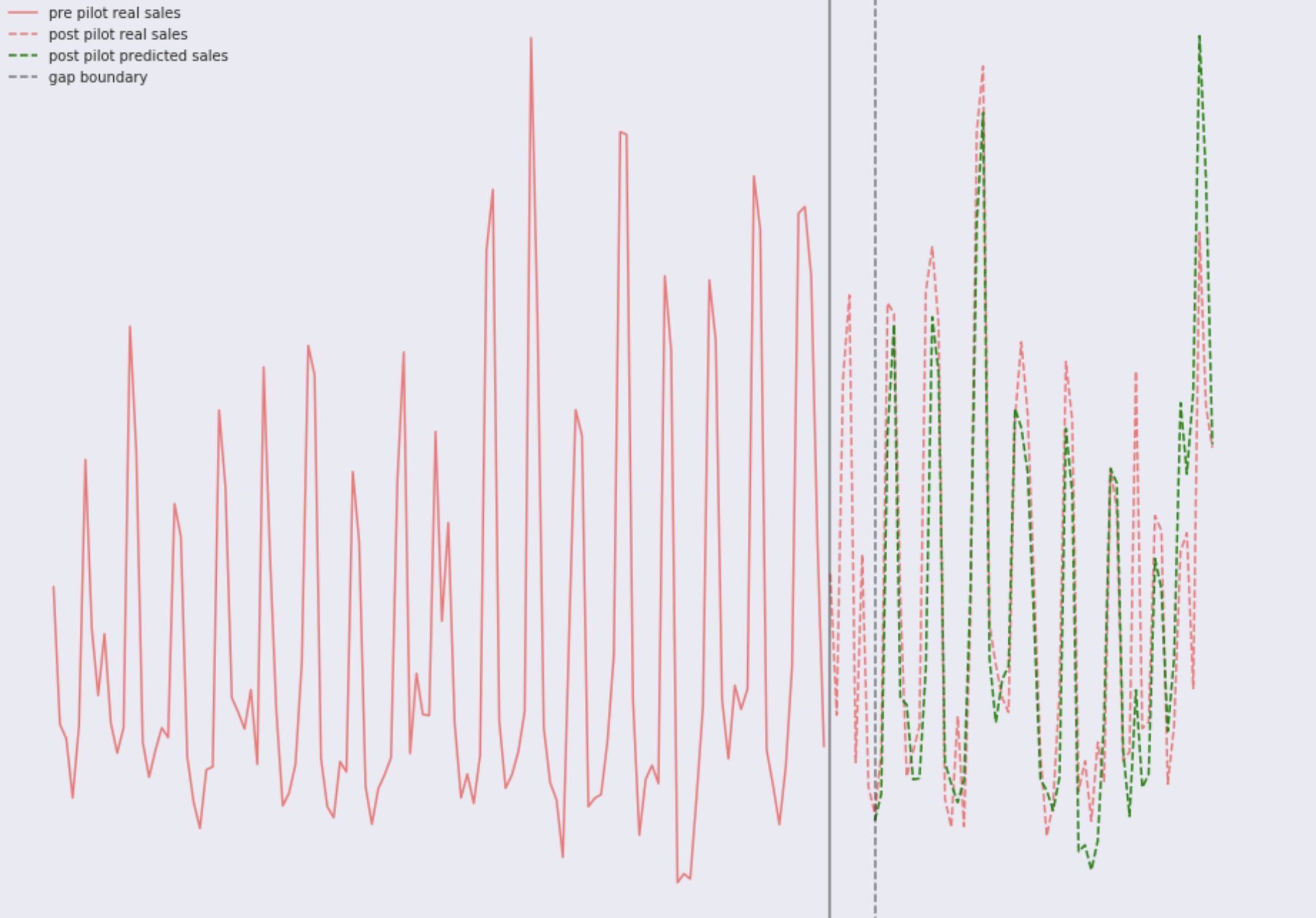
Supongamos que tenemos una serie temporal de ventas diarias para cada tienda. La línea continua gris divide los períodos
antes del piloto y
después del piloto . El área entre la línea gris continua y la línea gris discontinua es el período de compradores que se adaptan a la nueva combinación de productos y nuevas marcas, durante este período, los datos de ventas no afectan el resultado de la prueba y simplemente se ignoran. El rojo sólido es la venta real de cualquier tienda en el período anterior al piloto. En el lado derecho hay una combinación de almacenes de pruebas y control. La línea discontinua verde es el pronóstico para las ventas de cualquier tienda, utilizando solo los datos disponibles en el período anterior al inicio del piloto.
- La línea roja son las ventas reales de la tienda de control en el período posterior al lanzamiento del piloto. Para las tiendas del grupo de control, en el período posterior al inicio del piloto, solo observamos el pronóstico de ventas (intermitente verde) y las ventas reales (intermitente rojo).
- El azul sólido son las ventas reales de la tienda del grupo de prueba en el período posterior al lanzamiento del piloto. En las tiendas de prueba, observamos solo el pronóstico de ventas (verde intermitente) y las ventas reales (azul sólido).
La línea discontinua verde es la línea base en el aprendizaje automático.
Si el piloto tuvo éxito, es decir Dado que la intervención de prueba en forma de un surtido actualizado y un nuevo diseño tiene un efecto positivo en las ventas diarias, las ventas reales en tiendas de prueba (azul sólido) serán más altas en promedio que las ventas reales en tiendas de control (rojo intermitente).
Veamos qué significa en promedio. Para esto tenemos que hacer una suposición, suponemos que los errores de pronóstico del modelo tienen una distribución normal:
Large epsiloni sim mathcalN left(0, sigma2 right)
 Agreguemos una suposición audaz más, digamos que las ventas en la categoría en la que estamos interesados hoy dependen linealmente de las ventas en categorías relacionadas hoy y las ventas en la categoría en la que estamos interesados ayer y en el pasado reciente, y también puede atribuir varios metadatos de la tienda a esto para tener en cuenta los sesgos en demografía y otros atributos.
Agreguemos una suposición audaz más, digamos que las ventas en la categoría en la que estamos interesados hoy dependen linealmente de las ventas en categorías relacionadas hoy y las ventas en la categoría en la que estamos interesados ayer y en el pasado reciente, y también puede atribuir varios metadatos de la tienda a esto para tener en cuenta los sesgos en demografía y otros atributos.
Largeyi= vecwT vecxi+ epsiloni
Resulta ser un modelo muy familiar . Vale la pena señalar que la elección del modelo no es particularmente significativa aquí, es importante que los errores tengan una distribución normal, u otra conocida, para realizar una prueba estadística para la igualdad de los valores promedio. Con tales afirmaciones del problema, siempre se puede llevar a cabo una prueba de normalidad en la etapa de construcción del modelo, y en casi todos los modelos la distribución será normal, de acuerdo con la versión de la prueba de norma , se verifica.
Entonces, como modelo predictivo, utilicé la regresión lineal, aunque este no es un requisito obligatorio, y me guié por la simplicidad del modelo y la interpretabilidad. Vale la pena señalar que el modelo es predictivo, pero lo llamaría explicativo. Como no predecimos el futuro, utilizamos las ventas de categorías relacionadas el mismo día, lo cual es esencialmente un datalik. Más bien, estamos tratando de explicar las ventas de cerveza hoy por las ventas en la tienda en general. Esto crea un nuevo problema para nosotros: es necesario seleccionar cuidadosamente las características utilizadas en el modelo. Las características relacionadas con las categorías de productos relacionados se pueden dividir en tres grupos:
- un grupo de bienes de interés para nosotros (cerveza ligera, cerveza oscura, cerveza cero, kvas, tal vez incluso una ballena amarilla), algunos de estos signos forman la variable objetivo, y algunos están completamente excluidos del modelo;
- grupos de bienes que probablemente estén algo correlacionados con el grupo objetivo, por ejemplo, la historia del acordeón de que las ventas de pañales y cerveza tienen un alto coeficiente de correlación positivo;
- grupos de productos, que ciertamente no tienen una correlación significativa con los grupos objetivo, este es un método de regularización incluso antes de que se construya el modelo, y habrá una gran tentación de agregar todo al segundo grupo, por si acaso.
Como variables explicativas, agregamos características del segundo grupo al modelo. La idea es que supongamos que los cambios en las ventas en el segundo grupo en su conjunto tienen un efecto significativo en el primero, y los cambios en las ventas en el primer grupo no tienen un efecto especial en el segundo en su conjunto (el segundo es mucho más grande y más variado).
Una pregunta popular durante la presentación del método fue esta: ¿qué sucede si en la tienda de prueba / control hay una reparación de estacionamiento, la prueba se romperá? La respuesta es no. El estacionamiento afectará las ventas de la tienda en general, y no específicamente la cerveza, y las ventas de cerveza en nuestro país dependen de las ventas en otras categorías y, en consecuencia, se gastarán junto con todos. Puede realizar convincentemente un par de simulaciones en un retrodato.
También vale la pena señalar que no probamos el cálculo con el Método A contra el cálculo con el Método B, sino que probamos el nuevo comportamiento con el anterior . Esto significa que las tiendas y el grupo en su conjunto no deben cancelar ninguna campaña de marketing planificada que se haya utilizado anteriormente. Por ejemplo, si ha reducido el precio de la cerveza fuerte 2 veces en los últimos 6 meses, incluso en semanas, continúe haciendo esto, si deja de hacerlo, el comportamiento será diferente. Abstenerse de realizar nuevos experimentos en tiendas seleccionadas.
La etapa de construcción del modelo tampoco puede prescindir de las trampas. Los grupos de prueba y control pueden incluir tiendas completamente diferentes, y la tarea de nuestro modelo es alinear todas las tiendas, de modo que para cualquier tienda, un error de pronóstico aleatorio esté centrado en cero (o igualmente compensado desde cero). Al principio, esperaba que tuviera que ordenar todo tipo de hiperparámetros en la validación hasta obtener el resultado deseado. Pero resultó que con un conjunto suficiente de características, esto se logra la primera vez, lo cual es interesante, y la variación del error aleatorio tampoco difería mucho de una tienda a otra. Esta es probablemente una de las debilidades del método, ya que no hay garantía de que se cumplan tales condiciones.  Una revisión de la literatura tampoco dio ningún resultado, parece que mucha gente usa una línea de base en el aprendizaje automático, pero en ninguna parte hay algo sobre garantías teóricas. En general, después de todos estos fraudes, obtenemos un modelo que está capacitado en todos los datos en su totalidad , y podemos hacer pronósticos de ventas diarias para cualquier tienda seleccionada . Y no estamos particularmente preocupados por la precisión, pero solo si la distribución de errores para todas las tiendas fue igualmente sesgada (más agradable, por supuesto, si no es sesgada en relación con cero). Y el hecho de que la varianza puede ser grande, esto solo afectará el tamaño del conjunto de datos requerido para la significación estadística del resultado de la prueba (lo que significa que, dada la significación estadística y el poder estadístico a priori de la prueba, el número de observaciones. La obtención de dichos resultados depende de la varianza )
Una revisión de la literatura tampoco dio ningún resultado, parece que mucha gente usa una línea de base en el aprendizaje automático, pero en ninguna parte hay algo sobre garantías teóricas. En general, después de todos estos fraudes, obtenemos un modelo que está capacitado en todos los datos en su totalidad , y podemos hacer pronósticos de ventas diarias para cualquier tienda seleccionada . Y no estamos particularmente preocupados por la precisión, pero solo si la distribución de errores para todas las tiendas fue igualmente sesgada (más agradable, por supuesto, si no es sesgada en relación con cero). Y el hecho de que la varianza puede ser grande, esto solo afectará el tamaño del conjunto de datos requerido para la significación estadística del resultado de la prueba (lo que significa que, dada la significación estadística y el poder estadístico a priori de la prueba, el número de observaciones. La obtención de dichos resultados depende de la varianza )
Volvamos a la tabla anterior con líneas rojas, verdes y azules, y finalmente introduzcamos el concepto de un promedio más alto o más bajo. Para las tiendas de control, podemos restar de las ventas diarias reales (línea discontinua roja) las ventas diarias predichas por el modelo (línea discontinua verde). Como resultado, obtenemos una distribución normal de errores centrada en cero, por lo que nada ha cambiado en ellos y el modelo coincidirá en promedio con la realidad. Para las tiendas del grupo de prueba, también restamos de las ventas diarias reales (línea continua azul), las ventas del modelo de ventas diarias (verde intermitente), y también obtenemos una distribución normal. Entonces, si nada ha cambiado, entonces el centro estará en algún lugar alrededor de cero; Si las ventas han mejorado, se desplazarán a la derecha; si han empeorado, a la izquierda. Así es como se ve en los datos simulados.

Y aquí nos encontramos en las condiciones de la prueba estadística habitual para la igualdad de la media de dos distribuciones, y nada nos impide realizar esta prueba. Para la prueba estadística necesitamos saber lo siguiente:
- alpha y beta : elígete a ti mismo, o si tienes suerte y hay personas educadas en marketing, nosotros elegimos junto con ellos;
- dispersión: tomada de un retrodato;
- elevador: necesario para probar no solo la igualdad, sino que el crecimiento de las ventas en el grupo de prueba no es inferior a una cierta cantidad de dólares canadienses condicionales; no queremos implementar un proyecto que valga oro kamaz, pero para que sea rentable y no se amortice en cien años, no estamos construyendo un puente hacia Crimea.
Estos datos serán suficientes para calcular la cantidad de días requeridos para el piloto. Otra ventaja de este enfoque es la escalabilidad. En nuestro caso, la prueba dio 60 días, es decir necesitamos observaciones de 60 días para la prueba y observaciones de 60 días para el grupo de control para obtener resultados estadísticamente significativos de la prueba. Podemos elegir una tienda en cada grupo y esperar 2 meses, o dos en cada grupo y esperar 1 mes, y así sucesivamente. Naturalmente, el presupuesto del experimento depende de la adición de nuevas tiendas al grupo de prueba, pero esta es su tarea de cómo elegir ese equilibrio. Le recomiendo que estudie este material para comprender la metodología para calcular el número requerido de observaciones.
Datos reales
Considere dos imágenes con ventas reales, el modelo está capacitado en varios años de retro-venta. Tienda número uno:
Y la tienda número dos:

Como puede ver
, todo es muy bueno
a la vista . Notará fácilmente patrones semanales, así como algo que sucedió claramente recientemente en una de las tiendas, la dinámica ha cambiado. Si observa de cerca, puede ver que el modelo en ambas tiendas comete un error significativo varias veces. En este caso, hay dos opciones:
:
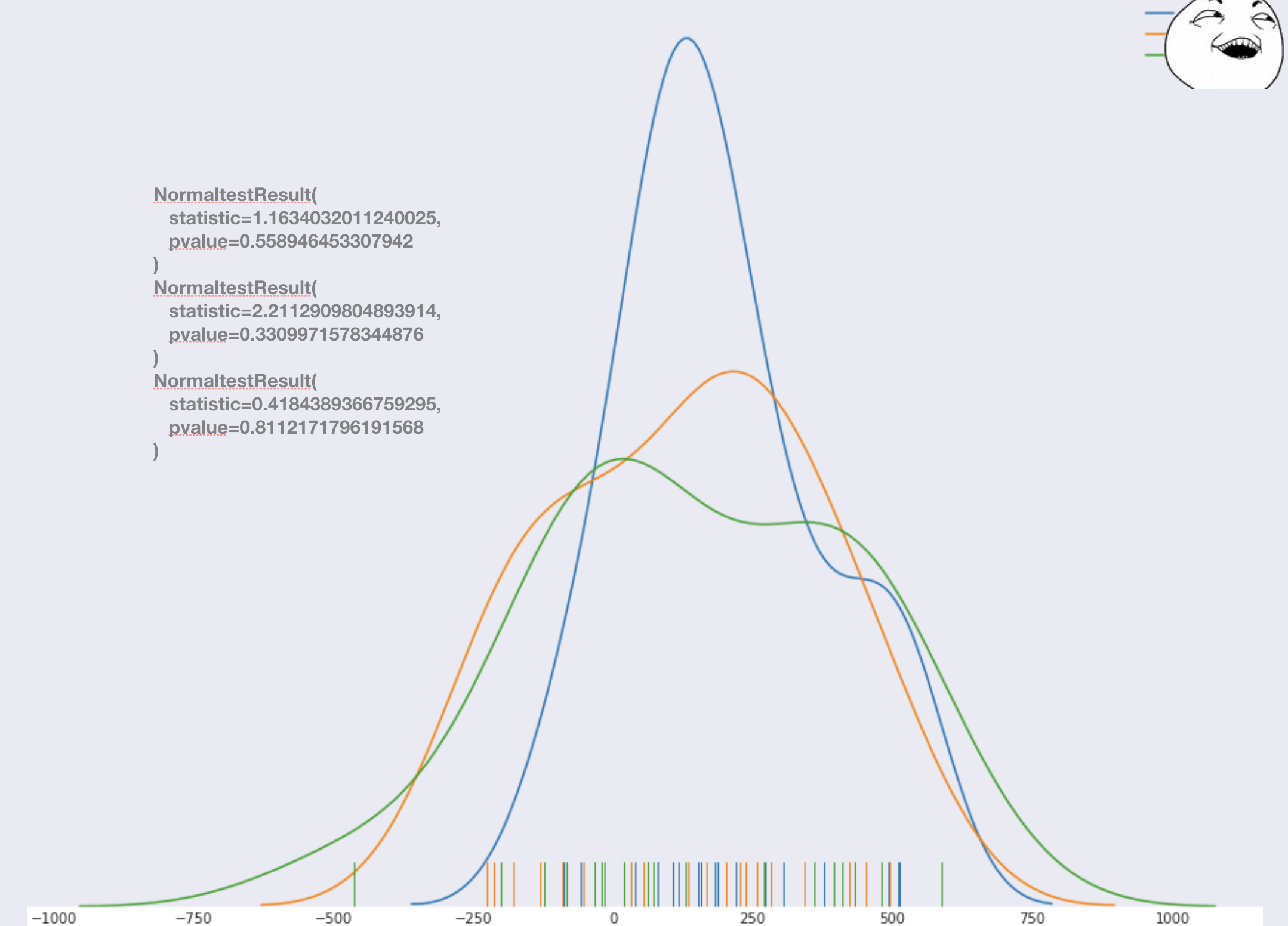 Se ve bien . Para credibilidad, puede realizar una prueba de normalidad y asegurarse de que todo esté bien . Si alguna prueba produce resultados anormales, entonces puntúe o regrese al punto de selección de características. En este caso, no necesitamos reiniciar el piloto, solo reconstruimos el modelo y recalculamos los números (por lo tanto, de antemano puede pensar en incluir un poco más de días piloto en el período de prueba de los que ofrece la primera versión del modelo). En nuestro caso, todo fue como debería.
Se ve bien . Para credibilidad, puede realizar una prueba de normalidad y asegurarse de que todo esté bien . Si alguna prueba produce resultados anormales, entonces puntúe o regrese al punto de selección de características. En este caso, no necesitamos reiniciar el piloto, solo reconstruimos el modelo y recalculamos los números (por lo tanto, de antemano puede pensar en incluir un poco más de días piloto en el período de prueba de los que ofrece la primera versión del modelo). En nuestro caso, todo fue como debería.A continuación, combinamos todas las tiendas del grupo de prueba en un grupo y todas las tiendas del control en un grupo, para que podamos hacerlo, por lo que supusimos anteriormente que el error del modelo está igualmente sesgado para cualquier tienda. Obtenemos dos distribuciones y realizamos una prueba estadística.
 Como habrás adivinado, de acuerdo con mi escepticismo al principio, la nueva metodología única para la exhibición de productos y la selección de marcas no tuvo un efecto estadísticamente significativo en las ventas. Eso, en principio, era de esperar, ya que vi la metodología para elegir nuevas marcas y la forma en que se muestran. Me temo que no puedo hablar sobre estas técnicas únicas, pero uno de los fotógrafos que acudió a la competencia para tomar una foto de un escaparate con una cerveza recibida ... fue expulsado groseramente de las instalaciones.
Como habrás adivinado, de acuerdo con mi escepticismo al principio, la nueva metodología única para la exhibición de productos y la selección de marcas no tuvo un efecto estadísticamente significativo en las ventas. Eso, en principio, era de esperar, ya que vi la metodología para elegir nuevas marcas y la forma en que se muestran. Me temo que no puedo hablar sobre estas técnicas únicas, pero uno de los fotógrafos que acudió a la competencia para tomar una foto de un escaparate con una cerveza recibida ... fue expulsado groseramente de las instalaciones.Conclusión
— ? , , 1-2 . - , — . , , , , . :
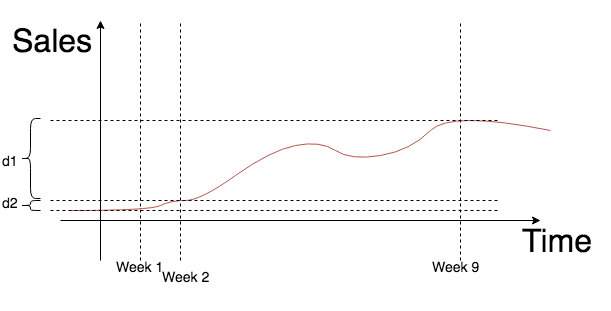
, - , . d2 , , , , d2 . d1+d2 , , , , .
¿Pero qué le pasó al piloto? Y todo está bien, está llegando y floreciendo, están esperando mil millones a cambio del oro dado a Kamaz. Una de las últimas tareas en el proyecto fue solo la introducción de una metodología para probar las promociones, pero cuando dejé el proyecto, la oficina respetada devolvió rápidamente la prueba por la similitud de la triple diferencia. Probablemente el mismo destino sucedió a esta prueba, pero no estoy al tanto.
Por cierto, ahora se está implementando con éxito en otro comercio minorista, se está probando la optimización del surtido, propuesta por otra oficina de consultoría, pero no esta oficina. Los resultados cumplieron con las expectativas del cliente y la oficina, y el cliente planea introducir una nueva optimización de surtido basada en los resultados de dicha prueba.