En el artículo hablaremos sobre el uso de redes neuronales convolucionales para resolver una tarea empresarial práctica de restaurar un realograma a partir de fotografías de estantes con productos. Usando la API de detección de objetos de Tensorflow, entrenaremos el modelo de búsqueda / localización. Mejoraremos la calidad de la búsqueda de productos pequeños en fotografías de alta resolución utilizando una ventana flotante y un algoritmo de supresión no máxima. En Keras, estamos implementando un clasificador de productos por marca. Paralelamente, compararemos enfoques y resultados con decisiones de hace 4 años. Todos los datos utilizados en el artículo están disponibles para su descarga, y el código que funciona completamente está en
GitHub y está diseñado como un tutorial.

Introduccion
¿Qué es un planograma? El diagrama de diseño de la exhibición de productos en el equipo comercial de concreto de la tienda.
¿Qué es un realograma? El diseño de los productos en un equipo comercial específico existente en la tienda aquí y ahora.
Planograma, como debe ser, realograma, lo que tenemos.

Hasta ahora, en muchas tiendas, administrar el resto de los productos en estantes, estantes, mostradores, estanterías es exclusivamente trabajo manual. Miles de empleados verifican la disponibilidad de productos manualmente, calculan el saldo, verifican la ubicación con los requisitos. Es costoso y los errores son muy probables. La exhibición incorrecta o la falta de productos conduce a menores ventas.
Además, muchos fabricantes celebran acuerdos con minoristas para exhibir sus productos. Y como hay muchos fabricantes, entre ellos comienza la lucha por el mejor lugar en el estante. Todos quieren que su producto se encuentre en el centro frente a los ojos del comprador y que ocupe el área más grande posible. Hay una necesidad de auditoría continua.
Miles de comerciantes se mueven de una tienda a otra para asegurarse de que los productos de su empresa estén en el estante y se presenten de acuerdo con el contrato. A veces son flojos: es mucho más agradable compilar un informe sin salir de su casa que ir a un punto de venta. Existe la necesidad de una auditoría permanente de los auditores.
Naturalmente, la tarea de automatización y simplificación de este proceso se ha resuelto durante mucho tiempo. Una de las partes más difíciles fue el procesamiento de imágenes: encontrar y reconocer productos. Y solo relativamente recientemente, esta tarea se ha simplificado tanto que para un caso particular en una forma simplificada, su solución completa se puede describir en un artículo. Esto es lo que haremos.
El artículo contiene un mínimo de código (solo para los casos en que el código es más claro que el texto). La solución completa está disponible como un tutorial ilustrado en
cuadernos jupyter . El artículo no contiene una descripción de la arquitectura de las redes neuronales, los principios de las neuronas, las fórmulas matemáticas. En el artículo, los usamos como una herramienta de ingeniería, sin entrar demasiado en los detalles de su dispositivo.
Datos y enfoque
Al igual que con cualquier enfoque basado en datos, las soluciones de redes neuronales requieren datos. También puede ensamblarlos manualmente: para capturar varios cientos de contadores y marcarlos usando, por ejemplo,
LabelImg . Puede ordenar el marcado, por ejemplo, en Yandex.Tolok.
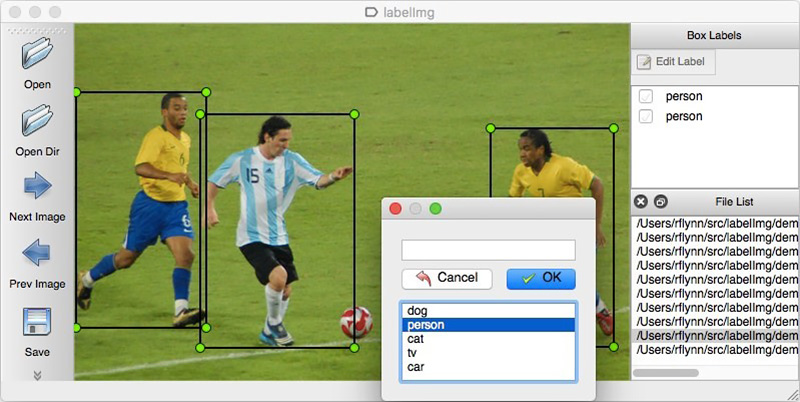
No podemos revelar los detalles de un proyecto real, por lo tanto, explicaremos la tecnología en datos abiertos. Ir de compras y tomar fotografías era demasiado vago (y no nos hubieran entendido allí), y el deseo de hacer el marcado de las fotos encontradas en Internet por mi cuenta terminó después del centésimo objeto clasificado. Afortunadamente, por casualidad me encontré con el archivo
Grocery Dataset .
En 2014, los empleados de Idea Teknoloji, Estambul, Turquía, subieron 354 fotos de 40 tiendas hechas con 4 cámaras. En cada una de estas fotografías, resaltaron con rectángulos un total de varios miles de objetos, algunos de los cuales se clasificaron en 10 categorías.
Estas son fotos de cajetillas de cigarrillos. No promovemos ni promocionamos fumar. Simplemente no había nada más neutral. Prometemos que en todas partes del artículo, donde la situación lo permita, usaremos fotografías de gatos.

Además de las fotos etiquetadas de los estantes, escribieron un artículo
Hacia el reconocimiento de productos minoristas en los estantes de comestibles con una solución al problema de localización y clasificación. Esto establece un tipo de punto de referencia: nuestra solución con nuevos enfoques debería resultar más simple y precisa, de lo contrario no es interesante. Su enfoque consiste en una combinación de algoritmos:
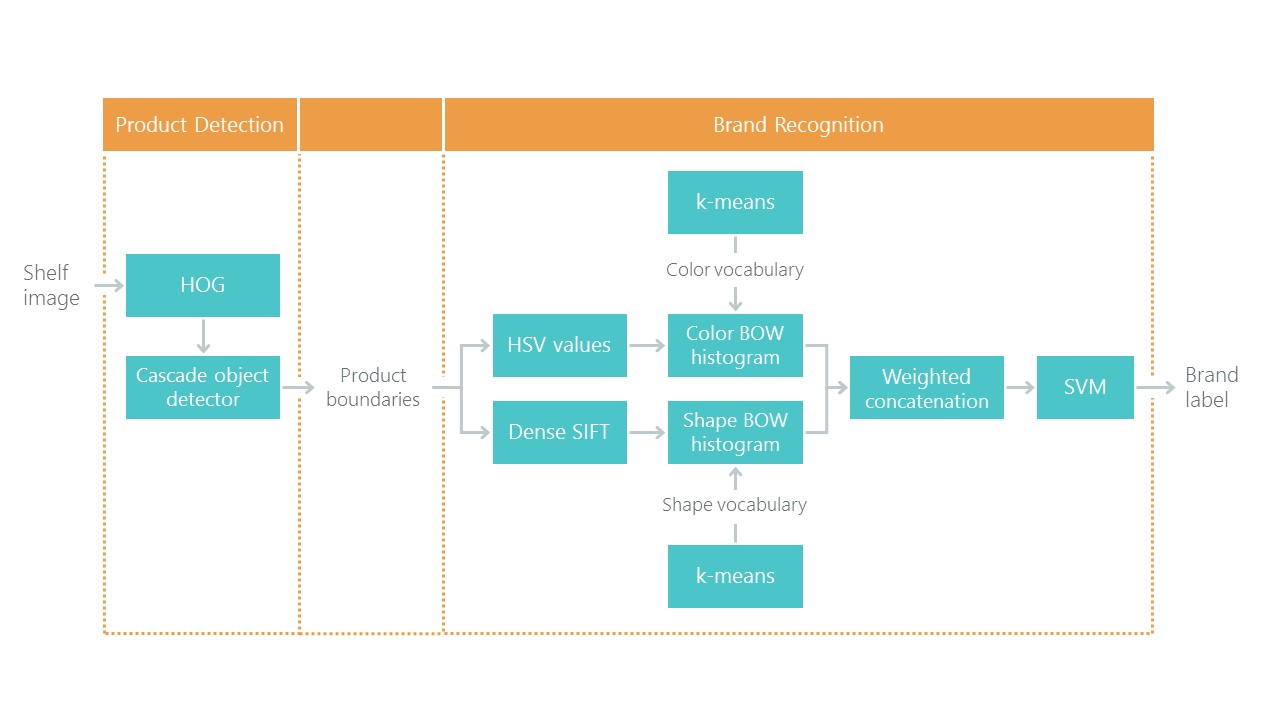
Recientemente, las redes neuronales convolucionales (CNN) han revolucionado el campo de la visión por computadora y han cambiado por completo el enfoque para resolver tales problemas. En los últimos años, estas tecnologías han estado disponibles para una amplia gama de desarrolladores, y las API de alto nivel como Keras han reducido significativamente su umbral de entrada. Ahora, casi cualquier desarrollador puede usar todo el poder de las redes neuronales convolucionales después de unos pocos días de citas. El artículo describe el uso de estas tecnologías utilizando un ejemplo, que muestra cómo una cascada completa de algoritmos se puede reemplazar fácilmente con solo dos redes neuronales sin pérdida de precisión.
Resolveremos el problema en pasos:
- Preparación de datos. Bombeamos los archivos y los transformamos en una vista conveniente para el trabajo.
- Clasificación de marca. Resolvemos el problema de clasificación usando una red neuronal.
- Busca productos en la foto. Entrenamos la red neuronal para buscar bienes.
- Implementación de búsqueda. Mejoraremos la calidad de detección utilizando una ventana flotante y un algoritmo para suprimir los no máximos.
- Conclusión Explique brevemente por qué la vida real es mucho más complicada que este ejemplo.
Tecnología
Las principales tecnologías que utilizaremos: Tensorflow, Keras, Tensorflow Object Detection API, OpenCV. Aunque tanto Windows como Mac OS son adecuados para trabajar con Tensorflow, todavía recomendamos usar Ubuntu. Incluso si nunca antes ha trabajado con este sistema operativo, usarlo le ahorrará un montón de tiempo. La instalación de Tensorflow para trabajar con la GPU es un tema que merece un artículo separado. Afortunadamente, tales artículos ya existen. Por ejemplo,
Instalar TensorFlow en Ubuntu 16.04 con una GPU Nvidia . Algunas instrucciones pueden estar desactualizadas.
Paso 1. Preparar los datos ( enlace github )Este paso, como regla, lleva mucho más tiempo que la simulación misma. Afortunadamente, utilizamos datos listos para usar, que convertimos al formulario que necesitamos.
Puede descargar y descomprimir de esta manera:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
Obtenemos la siguiente estructura de carpetas:
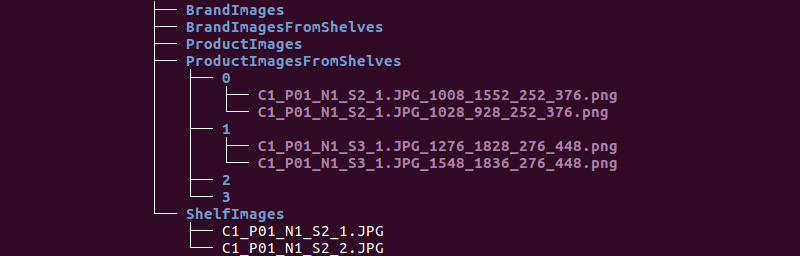
Utilizaremos información de los directorios ShelfImages y ProductImagesFromShelves.
ShelfImages contiene imágenes de los estantes mismos. En el nombre, se codifica el identificador del bastidor con el identificador de la imagen. Puede haber varias imágenes de un estante. Por ejemplo, una fotografía en su totalidad y 5 fotografías en partes con intersecciones.
Archivo C1_P01_N1_S2_2.JPG (bastidor C1_P01, instantánea N1_S2_2):

Revisamos todos los archivos y recopilamos información en el marco de datos de pandas photos_df:
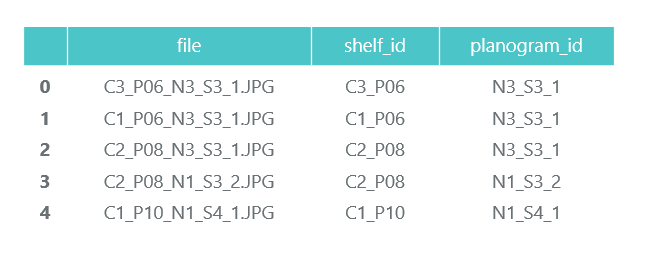
ProductImagesFromShelves contiene fotos recortadas de productos de estanterías en 11 subdirectorios: 0 - no clasificado, 1 - Marlboro, 2 - Kent, etc. Para no publicitarlos, utilizaremos solo números de categoría sin especificar nombres. Los archivos en los nombres contienen información sobre el bastidor, la posición y el tamaño del paquete en él.
Archivo C1_P01_N1_S3_1.JPG_1276_1828_276_448.png del directorio 1 (categoría 1, bastidor C1_P01, imagen N1_S3_1, coordenadas de la esquina superior izquierda (1276, 1828), ancho 276, altura 448):
No necesitamos las fotografías de los paquetes individuales (las recortaremos de las imágenes de los estantes), y recopilamos información sobre su categoría y posición en el marco de datos de pandas products_df:
En el mismo paso, dividimos toda nuestra información en dos secciones: entrenamiento para entrenamiento y validación para monitoreo de entrenamiento. Por supuesto, esto no vale la pena hacerlo en proyectos reales. Y tampoco confíes en los que hacen esto. Al menos debe asignar otra prueba para la prueba final. Pero incluso con este enfoque no muy honesto, es importante que no nos engañemos mucho.
Como ya hemos señalado, puede haber varias fotos de un estante. En consecuencia, el mismo paquete puede caer en varias imágenes. Por lo tanto, le recomendamos que desglose no por imágenes, y más aún no por paquetes, sino por bastidores. Esto es necesario para que no ocurra que el mismo objeto, tomado desde diferentes ángulos, termine tanto en el tren como en la validación.
Hacemos una división de 70/30 (el 30% de los bastidores van para validación, el resto para entrenamiento):
Nos aseguraremos de que cuando nos separemos, haya suficientes representantes de cada clase tanto para la capacitación como para la validación:

El color azul muestra la cantidad de productos en la categoría para validación y el naranja para capacitación. La situación no es muy buena con la categoría 3 para validación, pero en principio hay pocos de sus representantes.
En la etapa de preparación de datos, es importante no cometer errores, ya que todo el trabajo adicional se basa en sus resultados. Todavía cometimos un error y pasamos muchas horas felices tratando de entender por qué la calidad de los modelos es muy mediocre. Ya me sentía como un perdedor de las tecnologías de la "vieja escuela", hasta que notó accidentalmente que algunas de las fotos originales se rotaron 90 grados, y algunas se hicieron boca abajo.
Al mismo tiempo, el marcado se realiza como si las fotos estuvieran orientadas correctamente. Después de una solución rápida, las cosas fueron mucho más divertidas.
Guardaremos nuestros datos en archivos pkl para usar en los siguientes pasos. Total, tenemos:
- Un directorio de fotografías de bastidores y sus partes con paquetes,
- Un marco de datos con una descripción de cada bastidor con una nota sobre si está destinado a capacitación,
- Un marco de datos con información sobre todos los productos en los estantes, indicando su posición, tamaño, categoría y marcando si están destinados a capacitación.
Para la verificación, mostramos un rack de acuerdo con nuestros datos:
 Paso 2. Clasificación por marca ( enlace en github )
Paso 2. Clasificación por marca ( enlace en github )La clasificación de imágenes es la tarea principal en el campo de la visión por computadora. El problema es la "brecha semántica": la fotografía es solo una gran matriz de números [0, 255]. Por ejemplo, 800x600x3 (3 canales RGB).

Por qué esta tarea es difícil:

Como ya hemos dicho, los autores de los datos que utilizamos identificaron 10 marcas. Esta es una tarea extremadamente simplificada, ya que hay muchas más marcas de cigarrillos en los estantes. Pero todo lo que no entraba en estas 10 categorías se envió a 0, no clasificado:

"
Su artículo ofrece un algoritmo de clasificación con una precisión total del 92%:

¿Qué haremos?
- Prepararemos los datos para el entrenamiento,
- Entrenamos una red neuronal convolucional con la arquitectura ResNet v1,
- Verifique las fotos para la validación.
Suena "voluminoso", pero acabamos de usar el ejemplo de Keras "
Entrena una ResNet en el conjunto de datos CIFAR10 " tomando de él la función de crear ResNet v1.
Para comenzar el proceso de capacitación, debe preparar dos matrices: x: fotografías de paquetes con dimensión (número de paquetes, altura, ancho, 3) ey: sus categorías con dimensión (cantidad de paquetes, 10). La matriz y contiene los llamados vectores 1-hot. Si la categoría de un paquete para entrenamiento tiene el número 2 (de 0 a 9), entonces corresponde al vector [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Una pregunta importante es qué hacer con el ancho y la altura, porque todas las fotos fueron tomadas con diferentes resoluciones desde diferentes distancias. Necesitamos elegir un tamaño fijo, al que podamos traer todas nuestras fotos de los paquetes. Este tamaño fijo es un metaparámetro que determina cómo se entrenará y funcionará nuestra red neuronal.
Por un lado, quiero que este tamaño sea lo más grande posible para que ningún detalle de la imagen pase desapercibido. Por otro lado, con nuestra escasa cantidad de datos de entrenamiento, esto puede conducir a una rápida capacitación: el modelo funcionará perfectamente en los datos de entrenamiento, pero mal en los datos de validación. Elegimos el tamaño 120x80, tal vez en un tamaño diferente obtendríamos un mejor resultado. Función de zoom:
Escale y muestre un paquete para verificación. El nombre de la marca es difícil de leer por una persona, veamos cómo la red neuronal hará frente a la tarea de clasificación:

Después de preparar de acuerdo con el indicador obtenido en el paso anterior, dividimos las matrices x e y en x_train / x_validation y y_train / y_validation, obtenemos:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
Los datos están preparados, copiamos la función del constructor de la red neuronal de la arquitectura ResNet v1 del ejemplo de Keras:
def resnet_v1(input_shape, depth, num_classes=10): …
Construimos un modelo:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
Tenemos un conjunto de datos bastante limitado. Por lo tanto, para evitar que el modelo vea la misma foto cada vez durante el entrenamiento, utilizamos el aumento: cambia aleatoriamente la imagen y gírala un poco. Keras proporciona este conjunto de opciones para esto:
Comenzamos el proceso de entrenamiento.
Después del entrenamiento y la evaluación, obtenemos precisión en la región del 92%. Puede obtener una precisión diferente: hay muy pocos datos, por lo que la precisión depende en gran medida del éxito de la partición. En esta partición, no obtuvimos una precisión significativamente mayor que la indicada en el artículo, pero prácticamente no hicimos nada nosotros mismos y escribimos poco código. Además, podemos agregar fácilmente una nueva categoría, y la precisión debería (en teoría) aumentar significativamente si preparamos más datos.
Por interés, compare las matrices de confusión:
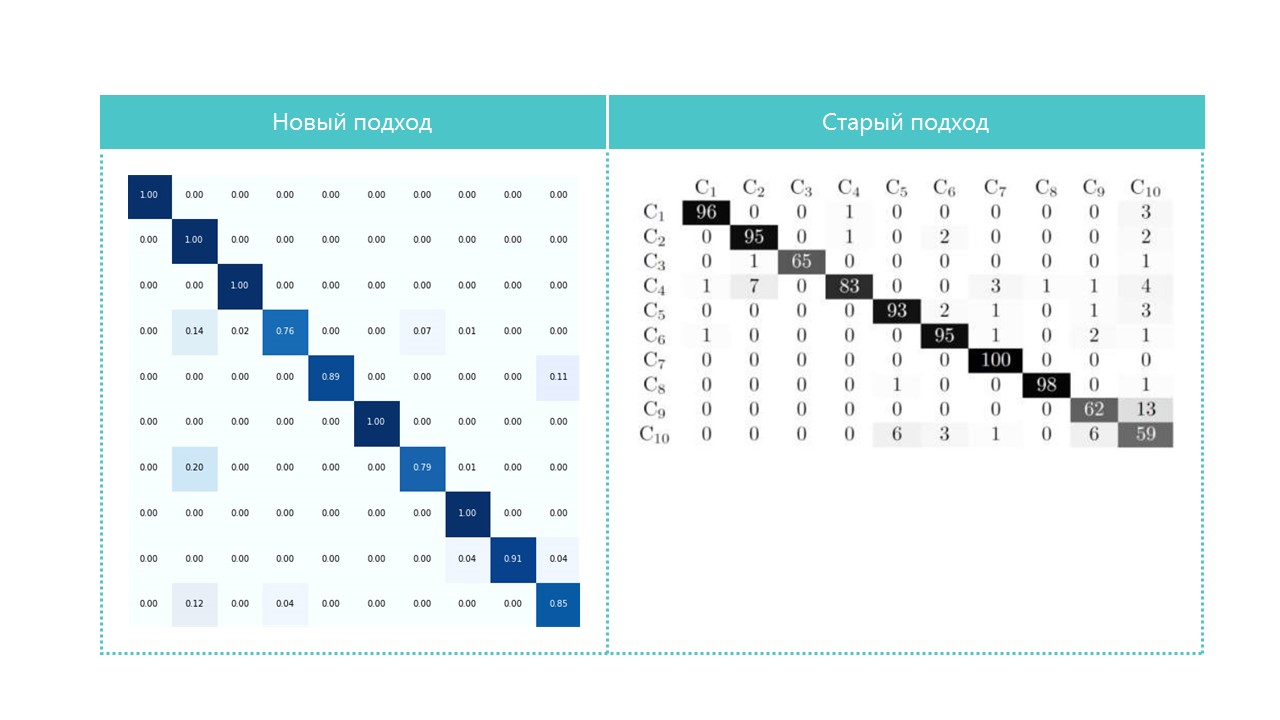
Casi todas las categorías nuestra red neuronal define mejor, excepto las categorías 4 y 7. También es útil observar a los representantes más brillantes de cada celda de matriz de confusión:
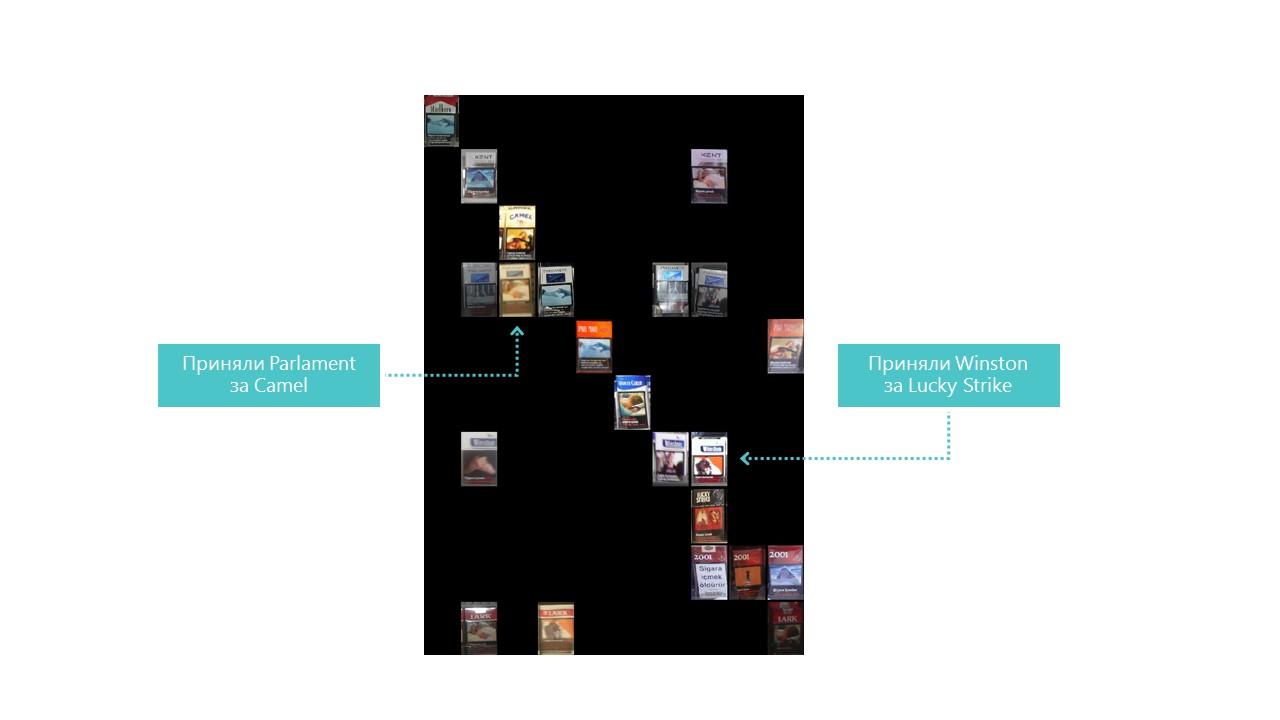
También puedes entender por qué el Parlamento se confundió con Camel, pero por qué Winston se confundió con Lucky Strike es completamente incomprensible, pero no tienen nada en común. Este es el principal problema de las redes neuronales: la opacidad completa de lo que sucede en su interior. Por supuesto, puede visualizar algunas capas, pero para nosotros esta visualización se ve así:

Una oportunidad obvia para mejorar la calidad del reconocimiento en nuestras condiciones es agregar más fotos.
Entonces, el clasificador está listo. Ve al detector.
Paso 3. Busque productos en la foto ( enlace en github )Las siguientes tareas importantes en el campo de la visión por computadora son la segmentación semántica, la localización, la búsqueda de objetos y la segmentación de instancias.
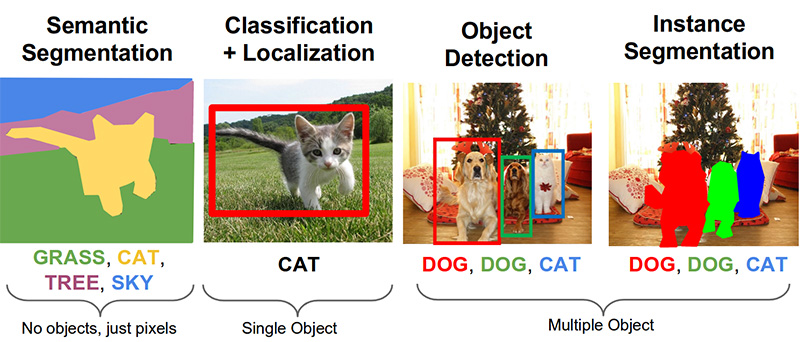
Nuestra tarea necesita detección de objetos. El artículo de 2014 ofrece un enfoque basado en el método Viola-Jones y HOG con precisión visual:

Gracias al uso de restricciones estadísticas adicionales, su precisión es muy buena:

Ahora la tarea de reconocimiento de objetos se resuelve con éxito con la ayuda de redes neuronales. Utilizaremos el sistema API de detección de objetos de Tensorflow y entrenaremos una red neuronal con la arquitectura Mobilenet V1 SSD. La capacitación de un modelo de este tipo desde cero requiere una gran cantidad de datos y puede llevar días, por lo que utilizamos un modelo capacitado en datos COCO de acuerdo con el principio del aprendizaje por transferencia.
El concepto clave de este enfoque es este. ¿Por qué un niño no necesita mostrar millones de objetos para que aprenda a encontrar y distinguir una bola de un cubo? Porque el niño tiene 500 millones de años de desarrollo de la corteza visual. La evolución ha hecho de la visión el sistema sensorial más grande. Casi el 50% (pero esto no es exacto) de las neuronas del cerebro humano son responsables del procesamiento de imágenes. Los padres solo pueden mostrar la pelota y el cubo, y luego corregir al niño varias veces para que encuentre y distinga perfectamente uno del otro.
Desde un punto de vista filosófico (con diferencias técnicas más que generales), el aprendizaje de transferencia en redes neuronales funciona de manera similar. Las redes neuronales convolucionales consisten en niveles, cada uno de los cuales define formas cada vez más complejas: identifica puntos clave, los combina en líneas, que a su vez se combinan en figuras. Y solo en el último nivel de la totalidad de los signos encontrados determina el objeto.
Los objetos del mundo real tienen mucho en común. Al transferir el aprendizaje, utilizamos los niveles de definición de características básicas ya entrenados y entrenamos solo a las capas responsables de identificar objetos. Para hacer esto, un par de cientos de fotos y un par de horas de funcionamiento de una GPU normal son suficientes para nosotros. La red se formó originalmente en el conjunto de datos COCO (Microsoft Common Objects in Context), que tiene 91 categorías y 2,500,000 imágenes. Muchos, aunque no 500 millones de años de evolución.
Mirando un poco hacia adelante, esta animación gif (un poco lenta, no se desplaza inmediatamente) del tablero de tensor visualiza el proceso de aprendizaje. Como puede ver, el modelo comienza a producir un resultado de alta calidad casi de inmediato, y luego viene la molienda:

El "entrenador" del sistema API de detección de objetos de Tensorflow puede realizar aumentos de forma independiente, recortar partes aleatorias de imágenes para el entrenamiento y seleccionar ejemplos "negativos" (secciones de fotos que no contienen ningún objeto). En teoría, no se necesita preprocesamiento de fotos. Sin embargo, en una computadora hogareña con un disco duro y una pequeña cantidad de RAM, se negó a trabajar con imágenes de alta resolución: al principio colgó durante mucho tiempo, crujió con un disco y luego salió volando.
Como resultado, comprimimos las fotos a un tamaño de 1000x1000 píxeles manteniendo la relación de aspecto. Pero dado que al comprimir una foto grande, se pierden muchos signos, primero se cortaron varios cuadrados de un tamaño aleatorio de cada foto del estante y se comprimieron en 1000x1000. Como resultado, los paquetes en alta resolución (pero no suficiente) y en pequeño (pero muchos) cayeron en los datos de entrenamiento. Repetimos: este paso es forzado y, muy probablemente, completamente innecesario y posiblemente dañino.
Las fotos preparadas y comprimidas se guardan en directorios separados (eval y train), y su descripción (con los paquetes contenidos en ellas) se forma en forma de dos marcos de datos de pandas (train_df y eval_df):
El sistema API de detección de objetos de Tensorflow requiere que la entrada se presente como archivos tfrecord. Puede formarlos utilizando la utilidad, pero lo convertiremos en un código:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
Nos queda preparar un directorio especial e iniciar los procesos:
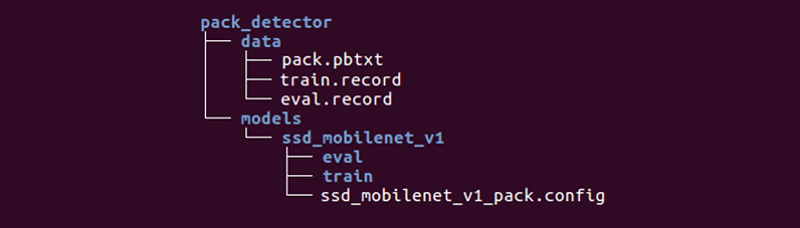
La estructura puede ser diferente, pero nos parece muy conveniente.
El directorio de datos contiene los archivos que hemos creado con tfrecords (train.record y eval.record), así como pack.pbtxt con los tipos de objetos para los que entrenaremos la red neuronal. Solo tenemos que definir un tipo de objeto, por lo que el archivo es muy corto:
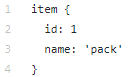
El directorio de modelos (puede haber muchos modelos para resolver un problema) en el directorio secundario ssd_mobilenet_v1 contiene la configuración para el entrenamiento en el archivo .config, así como dos directorios vacíos: train y eval. En el tren, el "entrenador" guardará los puntos de control del modelo, el "evaluador" los recogerá, los ejecutará en los datos para evaluación y los colocará en el directorio eval. Tensorboard hará un seguimiento de estos dos directorios y mostrará información del proceso.
Descripción detallada de la estructura de los archivos de configuración, etc. Se puede encontrar
aquí y
aquí . Las instrucciones de instalación de la API de detección de objetos de Tensorflow se pueden encontrar
aquí .
Entramos en el directorio models / research / object_detection y desinflamos el modelo pre-entrenado:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
Copiamos el directorio pack_detector preparado por nosotros allí.
Primero, comience el proceso de capacitación:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
Iniciamos el proceso de evaluación. No tenemos una segunda tarjeta de video, así que la lanzamos en el procesador (usando la instrucción CUDA_VISIBLE_DEVICES = ""). Debido a esto, llegará muy tarde con respecto al proceso de capacitación, pero esto no es tan malo:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
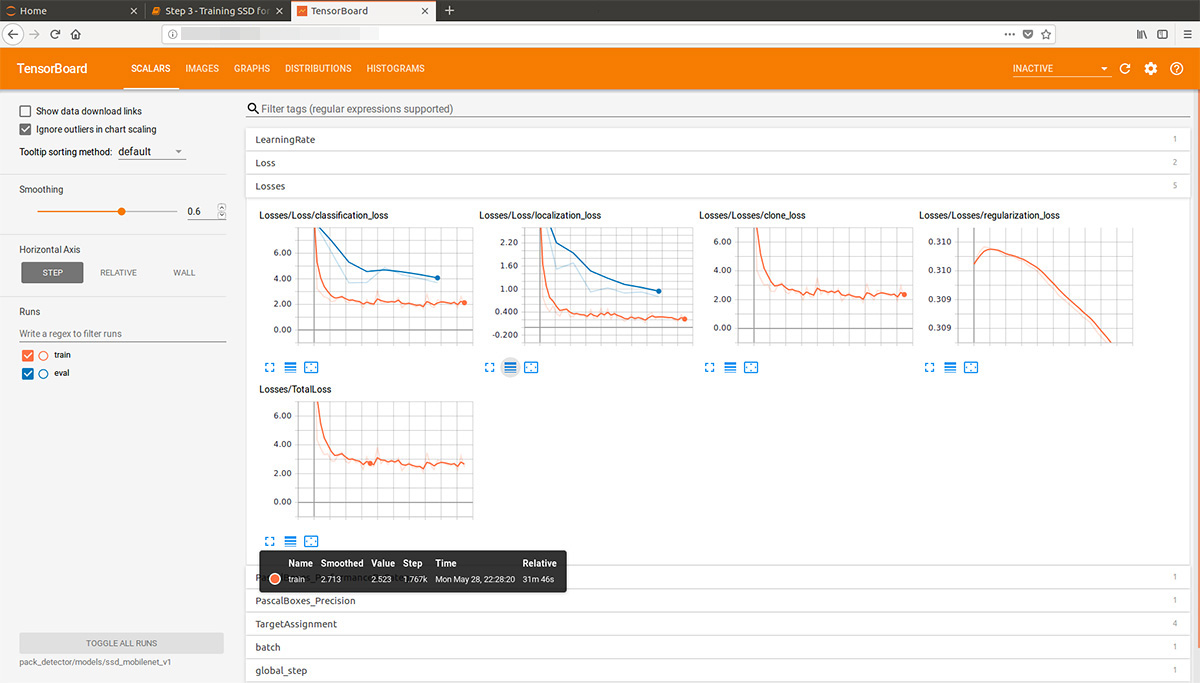
Comenzamos el proceso de tensorboard:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
Después de eso, podemos ver gráficos hermosos, así como el trabajo real del modelo en los datos estimados (gif al principio):
El proceso de capacitación se puede detener y reanudar en cualquier momento. Cuando creemos que el modelo es lo suficientemente bueno, guardamos el punto de control en forma de un gráfico de inferencia:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
Entonces, en este paso tenemos un gráfico de inferencia, que podemos usar para buscar objetos de paquete. Pasamos a su uso.
Paso 4. Implementar la búsqueda ( enlace github )El código de carga e inicialización del gráfico de inferencia se encuentra en el enlace de arriba. Funciones clave de búsqueda:
La función busca cuadros delimitados para paquetes no en toda la foto, sino en su parte. La función también filtra los rectángulos encontrados con una puntuación de detección baja especificada en el parámetro de corte.
Resulta ser un dilema. Por un lado, con un corte alto, perdemos muchos objetos, por otro lado, con un corte bajo, comenzamos a encontrar muchos objetos que no son paquetes. Al mismo tiempo, todavía no encontramos todo y no idealmente:

Sin embargo, tenga en cuenta que si ejecutamos la función para una pequeña parte de la foto, el reconocimiento es casi perfecto con el corte = 0.9:

Esto se debe al hecho de que el modelo SSD MobileNet V1 acepta fotos de 300x300 como entrada. Naturalmente, con tal compresión se pierden muchos signos.
Pero estos signos persisten si cortamos un pequeño cuadrado que contiene varios paquetes. Esto sugiere la idea de usar una ventana flotante: corremos a través de un pequeño rectángulo en una fotografía y recordamos todo lo que encontramos.

: , . . : (detection score), , , overlapTresh ( ):
:

:

, , .
Conclusión
«»: , . , , .. .
, , :
- 150 , , ,
- 3-7 ,
- 100 ,
- ,
- (),
- (, ),
- , «»,
- , , (SSD ),
- , ,
- .
, , .