 Cómo la traducción de IA puede aprender a generar imágenes de gatos
Cómo la traducción de IA puede aprender a generar imágenes de gatos .
La investigación de
Redes Adversarias Generativas (GAN) publicada en 2014 fue un gran avance en el campo de los modelos generativos. El investigador principal, Yann Lekun, calificó las redes adversarias como "la mejor idea en aprendizaje automático en los últimos veinte años". Hoy, gracias a esta arquitectura, podemos crear una IA que genere imágenes realistas de gatos. Genial!
 DCGAN durante el entrenamiento
DCGAN durante el entrenamientoTodo el código de trabajo está en el
repositorio de Github . Será útil para usted si tiene alguna experiencia en programación de Python, aprendizaje profundo, trabajo con Tensorflow y redes neuronales convolucionales.
Y si eres nuevo en el aprendizaje profundo, te recomiendo que te familiarices con la excelente serie de artículos ¡
Machine Learning is Fun!¿Qué es DCGAN?
Deep Convolutional Generative Adverserial Networks (DCGAN) es una arquitectura de aprendizaje profundo que genera datos similares a los datos del conjunto de capacitación.
Este modelo reemplaza con capas convolucionales las capas completamente conectadas de la red generativa de confrontación. Para comprender cómo funciona DCGAN, utilizamos la metáfora de la confrontación entre un crítico de arte experto y un falsificador.
Un falsificador ("generador") está tratando de crear una imagen falsa de Van Gogh y hacerla pasar por una real.
Un crítico de arte ("discriminador") está tratando de condenar a un falsificador, utilizando su conocimiento de los lienzos reales de Van Gogh.
Con el tiempo, el crítico de arte está definiendo cada vez más falsificaciones, y el falsificador las hace más perfectas.
 Como puede ver, los DCGAN se componen de dos redes neuronales de aprendizaje profundo separadas que compiten entre sí.
Como puede ver, los DCGAN se componen de dos redes neuronales de aprendizaje profundo separadas que compiten entre sí.- El generador está tratando de crear datos creíbles. No sabe cuáles son los datos reales, pero aprende de las respuestas de la red neuronal enemiga, cambiando los resultados de su trabajo con cada iteración.
- El discriminador intenta determinar los datos falsos (comparándolos con los reales), evitando falsos positivos en la medida de lo posible en relación con los datos reales. El resultado de este modelo es la retroalimentación para el generador.
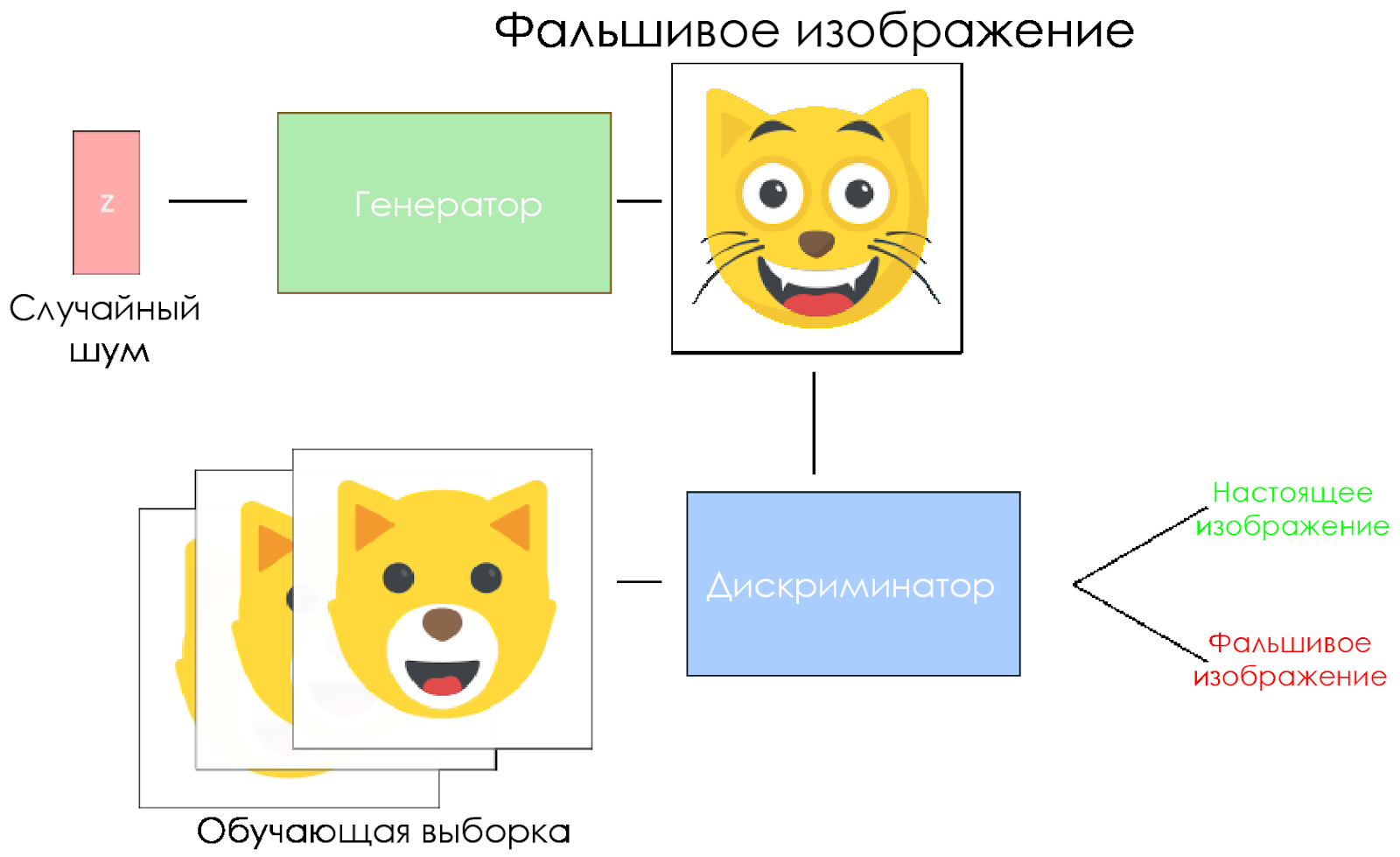 Esquema DCGAN.
Esquema DCGAN.- El generador toma un vector de ruido aleatorio y genera una imagen.
- La imagen se le da al discriminador, él la compara con la muestra de entrenamiento.
- El discriminador devuelve un número: 0 (falso) o 1 (imagen real).
¡Creemos un DCGAN!
Ahora estamos listos para crear nuestra propia IA.
En esta parte, nos centraremos en los componentes principales de nuestro modelo. Si desea ver el código completo, vaya
aquí .
Datos de entrada
Cree apéndices para la entrada:
inputs_real para el discriminador y
inputs_z para el generador. Tenga en cuenta que tendremos dos tasas de aprendizaje, por separado para el generador y el discriminador.
Los DCGAN son muy sensibles a los hiperparámetros, por lo que es muy importante ajustarlos.
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
Discriminador y generador
Usamos
tf.variable_scope por dos razones.
Primero, para asegurarse de que todos los nombres de variables comiencen con generador / discriminador. Más tarde, esto nos ayudará a entrenar dos redes neuronales.
En segundo lugar, reutilizaremos estas redes con diferentes datos de entrada:
- Entrenaremos al generador y luego tomaremos una muestra de las imágenes generadas por él.
- En el discriminador, compartiremos variables para imágenes de entrada falsas y reales.

Creemos un discriminador. Recuerde que, como entrada, toma una imagen real o falsa y devuelve 0 o 1 en respuesta.
Algunas notas
- Necesitamos duplicar el tamaño del filtro en cada capa convolucional.
- No se recomienda el muestreo descendente. En cambio, solo son aplicables las capas convolucionales despojadas.
- En cada capa, utilizamos la normalización por lotes (con la excepción de la capa de entrada), ya que esto reduce el cambio de covarianza. Lea más en este maravilloso artículo .
- Usaremos Leaky ReLU como una función de activación, esto ayudará a evitar el efecto de gradiente de "desaparición".
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
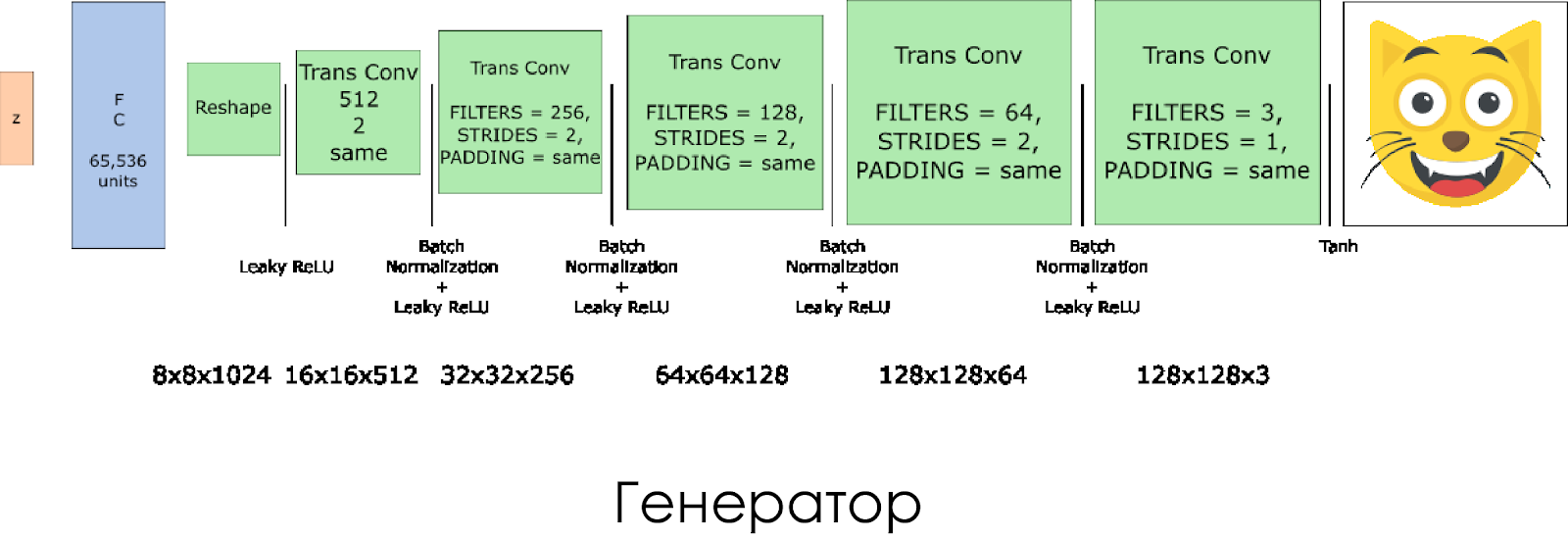
Hemos creado un generador. Recuerde que toma el vector de ruido (z) como entrada y, gracias a las capas de convolución transpuestas, crea una imagen falsa.
En cada capa, reducimos a la mitad el tamaño del filtro y también duplicamos el tamaño de la imagen.
El generador funciona mejor cuando se usa
tanh como la función de activación de salida.
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
Pérdidas en el discriminador y generador.
Como entrenamos tanto al generador como al discriminador, necesitamos calcular las pérdidas para ambas redes neuronales. El discriminador debe dar 1 cuando "considera" que la imagen es real, y 0 si la imagen es falsa. De acuerdo con esto y necesita configurar la pérdida. La pérdida discriminadora se calcula como la suma de las pérdidas para la imagen real y falsa:
d_loss = d_loss_real + d_loss_fakedonde
d_loss_real es la pérdida cuando el discriminador considera que la imagen es falsa, pero de hecho es real. Se calcula de la siguiente manera:
- Usamos
d_logits_real , todas las etiquetas son iguales a 1 (porque todos los datos son reales). labels = tf.ones_like(tensor) * (1 - smooth) . Usemos el suavizado de etiquetas: reduzca los valores de las etiquetas de 1.0 a 0.9 para ayudar al discriminador a generalizar mejor.
d_loss_fake es una pérdida cuando el discriminador considera que la imagen es real, pero de hecho es falsa.
- Usamos
d_logits_fake , todas las etiquetas son 0.
Para perder el generador, se
d_logits_fake del discriminador. Esta vez, todas las etiquetas son 1, porque el generador quiere engañar al discriminador.
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
Optimizadores
Después de calcular las pérdidas, el generador y el discriminador deben actualizarse individualmente. Para hacer esto, use
tf.trainable_variables() crear una lista de todas las variables definidas en nuestro gráfico.
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
Entrenamiento
Ahora implementamos la función de entrenamiento. La idea es bastante simple:
- Guardamos nuestro modelo cada cinco períodos (época).
- Guardamos la imagen en la carpeta con imágenes cada 10 lotes entrenados.
- Cada 15 períodos mostramos
g_loss , d_loss y la imagen generada. Esto se debe a que el portátil Jupyter puede bloquearse cuando se muestran demasiadas imágenes. - O podemos generar imágenes reales directamente cargando un modelo guardado (esto ahorrará 20 horas de entrenamiento).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
Como correr
Todo esto se puede ejecutar directamente en su computadora si está listo para esperar 10 años. Por lo tanto, es mejor usar servicios de GPU basados en la nube como AWS o FloydHub. Personalmente, entrené a este DCGAN durante 20 horas en Microsoft Azure y su
máquina virtual de aprendizaje profundo . No tengo una relación comercial con Azure, simplemente me gusta su servicio al cliente.
Si tiene alguna dificultad para ejecutar en una máquina virtual, consulte este maravilloso
artículo .
Si mejora el modelo, no dude en hacer una solicitud de extracción.
