Hoy hablaremos sobre Kubernetes, sobre el rastrillo que se puede recolectar en su uso práctico, y sobre los desarrollos que ayudaron al autor y que también deberían ayudarlo a usted. Trataremos de demostrar eso sin k8 en el mundo moderno en ningún lado. Para los oponentes de k8, también ofrecemos excelentes razones por las que no debe cambiar a él. Es decir, en la historia no solo defenderemos a Kubernetes, sino que también lo regañaremos. De aquí en el nombre vino esto
[no] .
Este artículo se basa en una
presentación de Ivan Glushkov (
gli ) en la conferencia DevOops 2017. Los dos últimos lugares de trabajo de Ivan estuvieron relacionados de alguna manera con Kubernetes: trabajó en infracomandos tanto en Postmates como en Machine Zone, y afectan a Kubernetes muy estrechamente. Además, Ivan lidera el podcast
DevZen . La presentación adicional será en nombre de Ivan.

Primero, voy a repasar brevemente el área por qué es útil e importante para muchos, por qué surge esta exageración. Luego les contaré sobre nuestra experiencia en el uso de la tecnología. Bueno, entonces las conclusiones.
En este artículo, todas las diapositivas se insertan como imágenes, pero a veces desea copiar algo. Por ejemplo, habrá ejemplos con configuraciones. Las diapositivas en PDF se pueden descargar
aquí .
No se lo diré estrictamente a todos: asegúrese de usar Kubernetes. Hay pros y contras, así que si vienes a buscar contras, los encontrarás. Tienes una opción, mira solo los pros, solo los contras y generalmente mira todo junto.
Simon Cat me ayudará con los profesionales, y el gato negro cruzará la calle cuando haya un signo menos.

Entonces, ¿por qué sucedió esta exageración? ¿Por qué la tecnología X es mejor que Y? Kubernetes es exactamente el mismo sistema, y hay muchos más que uno. Hay Puppet, Chef, Ansible, Bash + SSH, Terraform. Mi SSH favorita me está ayudando ahora, ¿por qué debería ir a algún lado? Creo que hay muchos criterios, pero destaqué los más importantes.
El tiempo desde el compromiso hasta el lanzamiento es una muy buena marca, y los muchachos de Express 42 son grandes expertos en esto. La automatización del ensamblaje, la automatización de toda la tubería es algo muy bueno, no se puede elogiar, en realidad ayuda. Integración continua, implementación continua. Y, por supuesto, cuánto esfuerzo gastará en hacer todo. Todo se puede escribir en Assembler, como digo, un sistema de implementación también, pero no agregará comodidad.

No te diré una breve introducción a Kubernetes, ya sabes lo que es. Tocaré estas áreas un poco más.
¿Por qué es todo esto tan importante para los desarrolladores? La repetibilidad es importante para ellos, es decir, si escribieron algún tipo de aplicación, realizaron una prueba, funcionará para usted, para su vecino y para la producción.
El segundo es un entorno estandarizado: si has estudiado Kubernetes y vas a una empresa vecina donde está Kubernetes, entonces todo será igual. La simplificación del procedimiento de prueba y la integración continua no es un resultado directo del uso de Kubernetes, pero aún así simplifica la tarea, por lo que todo se vuelve más conveniente.

Para los desarrolladores de versiones, hay muchas más ventajas. En primer lugar, es una infraestructura inmutable.
En segundo lugar, la infraestructura es como el código que se almacena en algún lugar. En tercer lugar, la idempotencia, la capacidad de agregar un lanzamiento con un botón. Los retrocesos de liberación ocurren con bastante rapidez, y la introspección del sistema es bastante conveniente. Por supuesto, todo esto se puede hacer en su sistema, escrito en la rodilla, pero no siempre puede hacerlo correctamente, y Kubernetes ya lo ha implementado.
¿Qué no es Kubernetes y qué no permite hacer? Hay muchos conceptos erróneos a este respecto. Comencemos con los contenedores. Kubernetes corre sobre ellos. Los contenedores no son máquinas virtuales livianas, sino una entidad completamente diferente. Son fáciles de explicar con la ayuda de este concepto, pero de hecho está mal. El concepto es completamente diferente, debe entenderse y aceptarse.
En segundo lugar, Kubernetes no hace que la aplicación sea más segura. No lo hace automáticamente escalable.
Debes esforzarte mucho para iniciar Kubernetes, no será así que "presionaste un botón y todo funcionó automáticamente". Dolerá

Nuestra experiencia Queremos que usted y todos los demás no rompan nada. Para hacer esto, debe mirar más a su alrededor, y aquí está nuestro lado.

Primero, Kubernetes no va solo. Cuando está construyendo una estructura que gestionará completamente los lanzamientos y las implementaciones, debe comprender que Kubernetes es un dado, y debe haber 100 dados de ese tipo. Para construir todo esto, debe estudiarlo todo con detenimiento. Los principiantes que ingresarán a su sistema también estudiarán esta pila, una gran cantidad de información.
Kubernetes no es el único bloque importante, hay muchos otros bloques importantes alrededor, sin los cuales el sistema no funcionará. Es decir, debe preocuparse mucho por la tolerancia a fallas.

Debido a esto, Kubernetes es un menos. El sistema es complejo, debes cuidar mucho.

Pero hay ventajas. Si una persona ha estudiado Kubernetes en una compañía, en otra su cabello no se pondrá de punta debido al sistema de liberación. Con el tiempo, cuando Kubernetes tome más espacio, la transición de personas y capacitación será más fácil. Y por eso, una ventaja.


Usamos Helm. Este sistema, construido sobre Kubernetes, se parece a un administrador de paquetes. Puede hacer clic en el botón, decir que desea instalar * Wine * en su sistema. Se puede instalar en Kubernetes. Funciona, se descarga automáticamente, se inicia y todo funcionará. Le permite trabajar con complementos, arquitectura cliente-servidor. Si trabaja con él, le recomendamos que ejecute un Tiller en el espacio de nombres. Esto aísla el espacio de nombres entre sí, y romper uno no rompe el otro.

De hecho, el sistema es muy complejo. Un sistema, que debería ser una abstracción de un nivel superior y más simple y más comprensible, en realidad no lo hace más fácil de entender. Por esto menos.

Comparemos las configuraciones. Lo más probable es que también tenga algunas configuraciones si ejecuta su sistema en producción. Tenemos nuestro propio sistema llamado BOOMer. No sé por qué la llamamos así. Consiste en Puppet, Chef, Ansible, Terraform y todo lo demás, hay una botella grande.

Veamos como funciona. Aquí hay un ejemplo de una configuración real que actualmente está trabajando en producción. ¿Qué vemos aquí?
En primer lugar, vemos dónde iniciar la aplicación, en segundo lugar, qué se debe iniciar y, en tercer lugar, cómo debe prepararse para el lanzamiento. En una botella, los conceptos ya están mezclados.

Si miramos más allá, debido a que agregamos herencia para hacer configuraciones más complejas, deberíamos ver qué hay en la configuración común a la que nos estamos refiriendo. Además, agregamos configuración de red, derechos de acceso, planificación de carga. Todo esto en una configuración que necesitamos para ejecutar una aplicación real en producción, mezclamos un montón de conceptos en un solo lugar.
Esto es muy difícil, está muy mal, y es una gran ventaja para Kubernetes, porque en él simplemente se determina qué ejecutar. La configuración de la red se realizó durante la instalación de Kubernetes, todo el aprovisionamiento se resolvió con la ayuda de la ventana acoplable: tenía encapsulación, todos los problemas se dividieron de alguna manera, y en este caso solo hay su aplicación en la configuración, y esto es una ventaja.

Echemos un vistazo más de cerca. Aquí solo tenemos una aplicación. Para que la implementación funcione, necesita un montón más para trabajar. Primero, debe definir los servicios. Cómo nos llegan los secretos, ConfigMap, el acceso a Load Balancer.

No olvides que tienes varios entornos. Hay Stage / Prod / Dev. Todo esto no es una pequeña pieza que mostré, sino un gran conjunto de configuraciones, lo cual es realmente difícil. Por esto menos.

Plantilla de timón para comparación. Repite completamente las plantillas de Kubernetes, si hay algún archivo en Kubernetes con la definición de implementación, lo mismo será en Helm. En lugar de valores específicos para el entorno, tiene plantillas que se sustituyen de los valores.
Tiene una plantilla separada, valores separados que deben sustituirse en esta plantilla.
Por supuesto, debe definir adicionalmente la infraestructura diferente de Helm, a pesar de que tiene muchos archivos de configuración en Kubernetes que necesita arrastrar y soltar en Helm. Todo esto es muy difícil, por lo que un inconveniente.
Un sistema que debería simplificarse realmente complica. Para mí, este es un claro menos. O necesita agregar algo más, o no usar
Vamos más profundo, no somos lo suficientemente profundos.

Primero, cómo trabajamos con clústeres. Leí el artículo de Google
"Borg, Omega y Kubernetes", que defiende firmemente el concepto de que necesitas tener un gran clúster. También estaba a favor de esta idea, pero, al final, la dejamos. Como resultado de nuestras disputas, utilizamos cuatro grupos diferentes.
El primer clúster e2e que prueba Kubernetes y prueba los scripts que implementan el entorno, los complementos, etc. El segundo, por supuesto, prod y etapa. Estos son conceptos estándar. En tercer lugar, se trata de admin, en el que se carga todo lo demás, en particular, tenemos CI allí, y parece que debido a esto este clúster siempre será el más grande.
Hay muchas pruebas: por commit, por fusión, todos hacen un montón de commits, por lo que los grupos son enormes.

Intentamos mirar CoreOS, pero no lo usamos. Tienen TF o CloudFormation dentro, y ambos muy mal nos permiten entender qué hay dentro del estado. Debido a esto, hay problemas durante la actualización. Cuando desee actualizar la configuración de sus Kubernetes, por ejemplo, su versión, es posible que la actualización no funcione de esta manera, en la secuencia incorrecta. Este es un gran problema de estabilidad. Esto es un menos.

En segundo lugar, cuando usa Kubernetes, necesita descargar imágenes desde algún lugar. Puede ser una fuente interna, repositorio o externa. Si es interno, hay problemas. Recomiendo usar Docker Distribution porque es estable, fue hecho por Docker. Pero el precio de soporte sigue siendo alto. Para que funcione, debe hacer que sea tolerante a fallas, porque este es el único lugar donde sus aplicaciones obtienen datos para trabajar.

Imagine que en el momento crucial, cuando encuentra un error en la producción, su repositorio se cae: no puede actualizar la aplicación. Debe hacer que sea tolerante a fallas, y de todos los posibles problemas que solo pueden ser.
En segundo lugar, si la masa de equipos, cada uno tiene su propia imagen, se acumulan mucho y muy rápidamente. Puedes matar tu distribución Docker. Es necesario hacer la limpieza, eliminar imágenes, hacer información para los usuarios, cuándo y qué va a limpiar.
En tercer lugar, con imágenes grandes, digamos, si tiene un monolito, el tamaño de la imagen será muy grande. Imagine que necesita liberar 30 nodos. 2 gigabytes por 30 nodos: calcule qué flujo, qué tan rápido se descarga a todos los nodos. Me gustaría presionar un botón e inmediatamente volverse verde. Pero no, primero debe esperar hasta que se descargue. Es necesario acelerar de alguna manera esta descarga, y todo funciona desde un punto.

Con los repositorios externos, existen los mismos problemas con el recolector de basura, pero la mayoría de las veces esto se hace automáticamente. Usamos Quay. En el caso de repositorios externos, estos son servicios de terceros en los que la mayoría de las imágenes son públicas. Que no había imágenes públicas, es necesario proporcionar acceso. Necesitamos secretos, derechos de acceso a las imágenes, todo esto está especialmente configurado. Por supuesto, esto puede automatizarse, pero en el caso de un lanzamiento local de Cuba en su sistema, aún debe configurarlo.

Para instalar Kubernetes usamos kops. Este es un sistema muy bueno, somos usuarios tempranos desde el momento en que aún no habían escrito en el blog. No es totalmente compatible con CoreOS, funciona bien con Debian, sabe cómo configurar automáticamente los nodos maestros de Kubernetes, funciona con complementos y tiene la capacidad de hacer cero el tiempo de inactividad durante las actualizaciones de Kubernetes.
Todas estas características están listas para usar, por lo que es una gran ventaja. Gran sistema!


Desde los enlaces puede encontrar muchas opciones para configurar una red en Kubernetes. Realmente hay muchos de ellos, cada uno tiene sus propias ventajas y desventajas. Kops solo admite parte de estas opciones. Por supuesto, puede configurarlo para que funcione a través de CNI, pero es mejor usar los más populares y estándar. Son probados por la comunidad y probablemente sean estables.

Decidimos usar Calico. Funcionó bien desde cero, sin muchos problemas, utiliza BGP, encapsulación más rápida, admite IP en IP, le permite trabajar con nubes múltiples, para nosotros esta es una gran ventaja.
Buena integración con Kubernetes, el uso de etiquetas delimita el tráfico. Por esto es una ventaja.
No esperaba que Calico llegara al estado cuando estaba encendido, y todo funciona sin problemas.

Alta disponibilidad, como dije, lo hacemos a través de kops, puede usar 5-7-9 nodos, usamos tres. Estamos sentados en etcd v2, debido a un error no se actualizaron en v3. Teóricamente, esto acelerará algunos procesos. No lo sé, lo dudo.

Un momento difícil, tenemos un clúster especial para experimentar con secuencias de comandos, transferencia automática a través de CI. Creemos que tenemos protección contra acciones completamente incorrectas, pero para algunas versiones especiales y complejas, en caso de que hagamos instantáneas de todos los discos, no hacemos copias de seguridad todos los días.


La autorización es una pregunta eterna. Nosotros en Kubernetes usamos RBAC, acceso basado en roles. Es mucho mejor que ABAC, y si lo configuró, entonces comprende lo que quiero decir. Mira las configuraciones: sorpréndete.
Utilizamos Dex, un proveedor de OpenID que bombea toda la información de alguna fuente de datos.
Y para iniciar sesión en Kubernetes, hay dos formas. Es necesario registrarse de alguna manera en .kube / config a dónde ir y qué puede hacer. Es necesario obtener de alguna manera esta configuración. O el usuario va a la interfaz de usuario, donde inicia sesión, recibe configuraciones, las copia en / config y funciona. Esto no es muy conveniente. Poco a poco pasamos al hecho de que una persona entra en la consola, hace clic en el botón, inicia sesión, las configuraciones se generan automáticamente y se apilan en el lugar correcto. Mucho más conveniente, decidimos actuar de esta manera.

Como fuente de datos usamos Active Directory. Kubernetes le permite enviar información sobre el grupo a través de toda la estructura de autorización, que se traduce en espacios de nombres y roles. Por lo tanto, distinguimos inmediatamente entre dónde puede ir una persona, dónde no tiene derecho a ir y qué puede liberar.

Muy a menudo, las personas necesitan acceso a AWS. Si no tiene Kubernetes, hay una máquina que ejecuta la aplicación. Parece que todo lo que necesita es obtener los registros, verlos y listo. Esto es conveniente cuando una persona puede ir a su automóvil y ver cómo funciona la aplicación. Desde el punto de vista de Kubernetes, todo funciona en contenedores. Hay un comando `kubectl exec`: ingrese al contenedor en la aplicación y vea qué sucede allí. Por lo tanto, no es necesario ir a instancias de AWS. Hemos denegado el acceso a todos excepto al infracomando.
Además, hemos prohibido las claves administrativas de larga duración, la entrada a través de roles. Si es posible usar el rol de administrador, yo soy el administrador. Además, agregamos rotación de teclas. Esto se configura convenientemente a través del comando awsudo, este es un proyecto en el github, lo recomiendo encarecidamente, le permite trabajar como con un sudo-team.



Cuotas Una cosa muy buena en Kubernetes, trabajando desde el primer momento. Limita cualquier espacio de nombres, por ejemplo, por la cantidad de objetos, memoria o CPU que puede consumir. Creo que esto es importante y útil para todos. Todavía no hemos alcanzado la memoria y la CPU, usamos solo la cantidad de objetos, pero agregaremos todo esto.
Además de grande y gordo, te permite hacer muchas cosas difíciles.


Escalado No puede mezclar la escala dentro de Kubernetes y fuera de Kubernetes. Dentro de Kubernetes hace la escala en sí. Puede aumentar las vainas automáticamente cuando hay una gran carga.
Aquí estoy hablando de escalar instancias de Kubernetes. Esto se puede hacer con AWS Autoscaler, este es un proyecto github. Cuando agrega un nuevo pod y no puede iniciarse porque carece de recursos en todas las instancias, AWS Autoscaler puede agregar nodos automáticamente. Le permite trabajar en instancias de Spot, todavía no lo hemos agregado, pero lo haremos, nos permite ahorrar mucho.


Cuando tiene muchos usuarios y aplicaciones de usuario, debe supervisarlos de alguna manera. Por lo general, esto es telemetría, registros, algunos gráficos hermosos.

Por razones históricas, teníamos Sensu, no era muy adecuado para Kubernetes. Se necesitaba un proyecto más orientado a la métrica. Observamos toda la pila de TICK, especialmente InfluxDB. Buena interfaz de usuario, lenguaje similar a SQL, pero características insuficientes. Nos cambiamos a Prometeo.
El es bueno. Buen lenguaje de consulta, buenas alertas y todo listo para usar.

Para enviar telemetría, utilizamos Cernan. Este es nuestro propio proyecto escrito en Rust. Este es el único proyecto sobre Rust que ha estado trabajando en nuestra producción durante un año. Tiene varios conceptos: hay un concepto de fuente de datos, configura varias fuentes. Configura dónde se fusionarán los datos. Tenemos una configuración de filtros, es decir, los datos que fluyen pueden procesarse de alguna manera. Puede convertir registros en métricas, métricas en registros, lo que quiera.
A pesar del hecho de que tiene varias entradas, varias conclusiones, y muestra que donde va, hay algo así como un gran sistema de gráficos, resulta bastante conveniente.

Ahora nos estamos moviendo sin problemas de la actual pila Statsd / Cernan / Wavefront a Kubernetes. Teóricamente, Prometheus quiere tomar datos de las aplicaciones por sí mismo, por lo que debe agregar un punto final a todas las aplicaciones, de las cuales tomará métricas. Cernan es el enlace de transmisión, debería funcionar en todas partes. Hay dos posibilidades: puede ejecutar Kubernetes en cada instancia, utilizando el concepto Sidecar, cuando otro contenedor funciona en su campo de datos que envía datos. Hacemos esto y aquello.

En este momento, todos los registros se envían a stdout / stderr. Todas las aplicaciones están diseñadas para esto, por lo que uno de los requisitos críticos es que no abandonemos este sistema. Cernan envía datos a ElasticSearch, los eventos de todo el sistema Kubernetes se envían allí usando Heapster. Este es un muy buen sistema, lo recomiendo.
Después de eso, puede ver todos los registros en un solo lugar, por ejemplo, en la consola. Usamos Kibana. Hay un maravilloso producto Stern, solo para los registros. Le permite mirar, pinta diferentes vainas en diferentes colores, sabe cómo ver cuándo una de las partes inferiores ha muerto y la otra se ha reiniciado. Recoge automáticamente todos los registros. Un proyecto ideal, lo recomiendo encarecidamente, es un gordo más Kubernetes, todo está bien aquí.


Secretos Utilizamos S3 y KMS. Estamos pensando en cambiar a Vault o secretos en Kubernetes. Estaban en 1.7 en estado alfa, pero hay que hacer algo con esto.

Llegamos a la parte interesante. El desarrollo de Kubernetes generalmente no se considera mucho. : «Kubernetes — , , , ».
, Kubernetes — .

, , , - . Kubernetes : , , . , , — .
, , . -, Docker Way. , . , , SSH, : « - , ».
, Kubernetes , read only . , , , , , , , . Kubernetes , , , , -, .
: , - , , - , pipeline , : «, », . - , , , . , CI , - , CI . .
, , , , . , - . , . - Kubernetes. , , — , .
.


Kubernetes, , , - . , , Deis, . , , , Deis. , Deis .
, Helm Charts. , — . - How-to, - FAQ, , , , , . , . , , .

Minikube — , , , , , . Kubernetes , , SSH .
MacOS, Mac, , , . . virtualbox, xhyve. , , . xhyve, VirtualBox, , .
, , , - , . , , - , .


CI Kubernetes, , , Kubernetes, , . Concourse CI, , , , , , . Concourse . , . , , , - , .
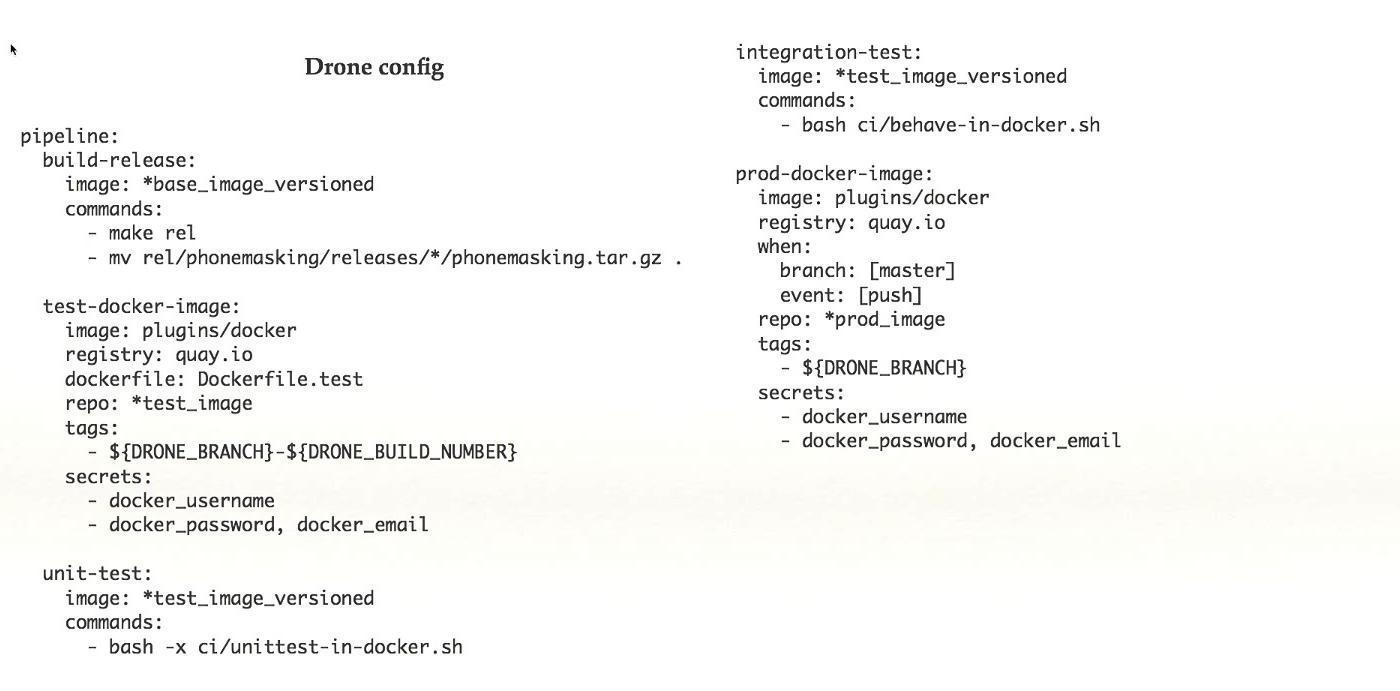
CI, , , , Concourse. Drone.io — , , , , . , — , . , , .
pipeline -, Kubernetes. , , , CI, -, Kubernetes .
admin/stage-, - . .
Drone-. , pipeline, - : , . , Drone, , .

, : . , , - , Kubernetes. Google , , , - .
Google , Kubernetes. , , . , , . , . Service Mesh.

, , , Geodesic. , , . , . , , , .

, Kubernetes .
, . , , , . Kubernetes. , , .

.
, , — , , . : , , . — Kubernetes .
Kubernetes . , Kubernetes, . , , .
Kubernetes — . , Kubernetes . — .
, , .
Kubernetes, — . , , , .
, Minikube, , , . , , , Kubernetes . — , .

— . , , , , 1-2 , , , . Kubernetes .
-, Kubernetes , , . CI, CI , , , . .
— . , , , . Kubernetes , .
, , . , , , . , , .
, , Kubernetes , . . , .

. Kubernetes . -. , Kubernetes, , ( — , ) , .
, , pod, . , . , , , . , , Kubernetes, , .
Error Budget. : , . , , - . , , . — , . — . SLA «» — , , , . , , , , .
, . « », . , , . .
:
@gliush .
, :
- Container-Native Networking — Comparison
- Continuous Delivery by Jez Humble, David Farley.
- Containers are not VMs
- Docker Distribution (image registry)
- Quay — Image Registry as a Service
- etcd-operator — Manager of etcd cluster atop Kubernetes
- Dex - OpenID Connect Identity (OIDC) and OAuth 2.0 Provider with Pluggable Connectors
- awsudo - sudo-like utility to manage AWS credentials
- Autoscaling-related components for Kubernetes
- Simon's cat
- Helm: Kubernetes package manager
- Geodesic: framework to create your own cloud platform
- Calico: Configuring IP-in-IP
- Sensu: Open-core monitoring system
- InfluxDB: Scalable datastore for metrics, events, and real-time analytics
- Cernan: Telemetry and logging aggregation server
- Prometheus: Open Source monitoring solution
- Heapster: Compute Resource Usage Analysis and Monitoring of Container Clusters
- Stern: Multi pod and container log tailing for Kubernetes
- Minikube: tool to run Kubernetes locally
- Docker machine driver fox xhyve native OS X Hypervisor
- Drone: Continuous Delivery platform built on Docker, written in Go
- Borg, Omega and Kubernetes
- Container-Native Networking — Comparison
- Bug in minikube when working with xhyve driver.
Minuto de publicidad. Si le gustó este informe de la conferencia DevOops , tenga en cuenta que el 14 de octubre se llevará a cabo el nuevo DevOops 2018 en San Petersburgo, habrá muchas cosas interesantes en su programa. El sitio ya tiene los primeros oradores e informes.