Prólogo
La implementación de PHP trie descrita aquí hace que el diccionario sea demasiado pesado hasta ahora, lo que en consecuencia lleva bastante tiempo cargarlo en la memoria, lo que nivela la bastante buena velocidad de su trabajo. La velocidad de búsqueda es de ~ 80 mil palabras por segundo. El diccionario está hecho de la lista de lemas del diccionario opencorpora.org e incluye 389844 palabras. En forma no comprimida, el diccionario pesa ~ 150mb, y gzip comprimido ~ 6mb. Sin embargo, los resultados de rendimiento bastante buenos demuestran que en PHP puro puedes hacer un árbol de prefijos trie completamente funcional.
Les pido a los programadores con anticipación que hagan críticas literarias que no escriban comentarios maliciosos. Este artículo debería ser interesante para principiantes, como yo mismo. Demasiado perezoso para leer, puede ver inmediatamente el código en
github .
Como empezó todo
Durante bastante tiempo, he estado tramando la idea de escribir un analizador morfológico para mis proyectos PHP, que podrá realizar rápidamente un análisis morfológico de palabras dadas, así como transformar palabras en la forma morfológica deseada.
PHP ya tiene una biblioteca similar llamada phpmorhy. Funciona bastante rápido y lo usaría y no inventaría nada, pero el compilador del diccionario está hecho como una aplicación separada que no es PHP, lo que me hace imposible usar esta biblioteca. La biblioteca en sí está construida sobre la base del tan esperado diccionario AOT, lo que reduce aún más su utilidad.
Pasaron semanas y meses, leí
un artículo de Khabrovchanin, luego
un artículo de I. Segalovich sobre un algoritmo morfológico rápido para un motor de búsqueda, y luego un montón de artículos diferentes.
Poco a poco, he madurado para escribir mi propio
lunapark con blackjack y los huesos de un analizador morfológico. Pienso: "
Bueno, el progreso ha avanzado, ¡en PHP ya puedes analizar el genoma humano! "
Tomé el diccionario opencorpora.org, lo puse en mysql y obtuve una velocidad de búsqueda de 2 mil palabras por segundo. Creo que es necesario cargar el diccionario en la memoria. Y aquí resulta que para tener estructuras de datos regulares disponibles en PHP, como una matriz o un objeto, debe almacenar aproximadamente 3 GB de RAM para un diccionario de 3 millones. Todas las implementaciones de php trie que se me ocurrieron solo eran adecuadas como un tutorial para demostrar la lógica del trabajo, ya que ellas mismas se construyeron sobre estructuras de almacenamiento de datos PHP nativas.
Dispositivo de almacenamiento de diccionario y principio de funcionamiento
Siempre que pude leer, escuchar o mirar sobre el árbol de prefijos de trie, no se explica exactamente cómo se almacenarán los datos en la memoria. Aquí tenemos el nodo, y aquí están sus herederos, y aquí está la bandera del final de la palabra, que no se muestra debajo del capó. Por lo tanto, tuve que inventar un método de almacenamiento yo mismo.
Como sabes, el árbol de prefijos trie consta de nodos. Un nodo almacena un prefijo, enlaces a nodos posteriores (descendientes) y un puntero al hecho de que este prefijo es el último en la cadena. El indio dice bastante inteligiblemente sobre trie
aquí .
Los nodos en mi implementación de trie son bloques de datos de una longitud fija de 154 bytes. Los primeros 6 bytes (48 bits) contienen la máscara de bits de los herederos. Los primeros 46 bits son el alfabeto ruso, los números, las comillas, el guión y el apóstrofe. El apóstrofe se agregó porque en el diccionario opencorpora.org existe la palabra "cote d'ivoire", que usa el signo del apóstrofe. El bit 47 se usa para almacenar el indicador de fin de palabra. Los 148 bytes que siguen a la máscara de bits se utilizan para almacenar referencias a los herederos del nodo. 3 bytes por carácter (46 * 3 = 148).
Los nodos se almacenan como datos binarios en una cadena. El acceso a la sección deseada se lleva a cabo utilizando la función substr () y el posterior desempaquetado desempaquetado ().
El uso de nodos de longitud fija simplifica el proceso de direccionamiento. Para cambiar al nodo deseado, es suficiente saber su número de serie (id) y la longitud del nodo. Multiplicamos el número de serie por la longitud y descubrimos el desplazamiento relativo al comienzo de la línea; todo es muy simple.
fig. 1 esquema de almacenamiento
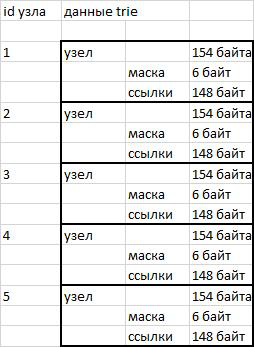
Desventajas
El esquema de almacenamiento utilizado simplifica el direccionamiento, pero consume espacio. El almacenamiento de 380 mil palabras requiere poco más de un millón de nodos. 154 bytes * 1,000,000 nodos = 146.86 megabytes. Es decir aproximadamente 400 bytes por palabra. Si escribe palabras en un archivo de texto simple codificado en utf8, estas mismas 380 mil palabras pueden caber en 16 megabytes.
Planes
Para usar la memoria de manera más racional, quiero cambiar a una longitud variable de nodos, luego, como enlace, tendré que registrar no la identificación del nodo, sino su ubicación en bytes. La ubicación del enlace al nodo deseado se determinará de la siguiente manera. En el ejemplo de la palabra "abv".
La letra "a" es la primera en el alfabeto, por lo tanto, su nodo también es el primer, respectivamente, desplazamiento 0. Lea 6 bytes, comenzando desde 0.
$str = substr($dic, 0, 6);
Descomprima la línea:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Nos fijamos en la máscara del segundo bit (letra "b")
bit_get($mask, 2);
El bit está configurado, ahora contamos el número de bits elevados en la máscara a 2. Digamos que el bit de la letra "a" también se eleva en nuestro nodo, por lo que nuestro bit de la letra "b" será el segundo bit elevado. Cuenta el desplazamiento para leer el enlace
$offset = 6 + 3;
Máscara de 6 bytes + 3 bytes, que ocupa el primer enlace, resulta 9 bytes. Leemos el trozo de cuerda deseado.
$str = substr($dic, $offset, 3);
Descomprima el enlace:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Vaya al siguiente nodo y repita todo nuevamente. En la última carta, verificamos la presencia de 47 bits en la máscara, si está configurada, hay una palabra de búsqueda en nuestro trie.
Espero que sea posible mantener una velocidad de al menos 50 mil palabras por segundo.
Agradecimientos
Quiero agradecer a los participantes del foro nulled.cc y php.ru por su ayuda con las funciones bit a bit.