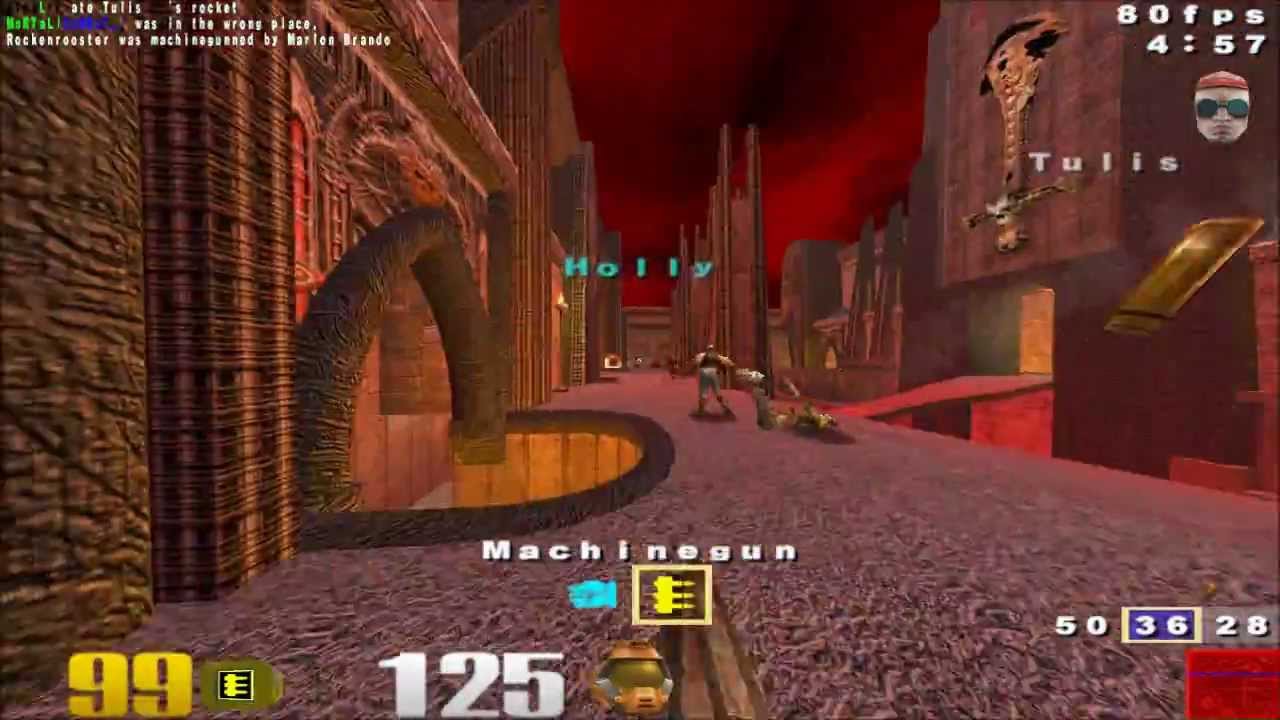
DeepMind, una vez una división de Google Corporation, está desarrollando IA (su forma débil) para varios propósitos. Ahora, el equipo de DeepMind participa activamente en la creación de varias formas de IA, mejoradas para juegos, tanto lógicos, de escritorio y de disparos. Hay muchos juegos, esto es ir, StarCraft y ahora, y Quake III Arena.
Los desarrolladores
dijeron en su blog que entrenaron al sistema de inteligencia artificial para jugar Quake III Arena de la misma manera que lo hace una persona. Es decir, el sistema informático ha aprendido a adaptarse a las condiciones de juego que cambian rápidamente, incluidos los niveles de cambio y sus elementos. Tradicionalmente,
se utilizaba un
sistema reforzado en el entrenamiento.
Durante este tipo de entrenamiento, la computadora recibe una recompensa o una multa, dependiendo de si el pasaje es exitoso o no. Por lo general, el problema de una computadora es que no puede adaptarse a las condiciones cambiantes con bastante rapidez, tal como lo hace una persona. A pesar de que las redes neuronales han podido aprender de sus propios errores, los juegos de computadora son difíciles si el sistema no conoce las condiciones iniciales.
El sistema fue entrenado para jugar en el modo Capturar la bandera. En este caso, el jugador debe intentar capturar la bandera del oponente, pero en ningún caso debe permitir que la suya sea capturada. Si algún equipo puede capturar y sostener la bandera del oponente por la cantidad máxima de veces en cinco minutos, entonces ese equipo será el ganador.
Para evitar que la IA simplemente aprenda las características del nivel, incluida la ubicación de habitaciones, edificios, etc., cada vez que la red neuronal se ve obligada a jugar en un nuevo nivel. En este caso, AI desarrolló su propia estrategia de juego sin abarrotar. La computadora observó las acciones de otros jugadores, estudió la "geografía" del nivel y actuó de acuerdo con la situación.
Además, los desarrolladores de Deepmind entrenaron a AI para jugar con todo el equipo, que consta de diferentes agentes. Todo el sistema se llama For The Win (FTW).
Entonces, For The Win (FTW) aprendió a administrar su equipo, coordinando y dirigiendo las acciones de cada agente. La tarea, como se mencionó anteriormente, es preservar la propia bandera y capturar la de otra persona. Después de que la computadora alcanzó cierto nivel de habilidad, se ofreció a DeepMind jugar con jugadores comunes en un torneo especial.
Las 40 personas participaron en él. Los equipos en el torneo fueron mixtos, es decir, en un equipo podría haber personas y agentes de IA. Según los resultados del juego, quedó claro que la IA en su forma pura obtuvo más victorias que los equipos de personas. En equipos mixtos, la IA mostró un mayor nivel de cooperación de lo que la gente suele demostrar. Entonces, la computadora, si es necesario, sirvió como esclava o estuvo directamente involucrada en el ataque a la base del enemigo.
Según los desarrolladores, los principios de trabajo que se usaron para crear For The Win (FTW) se pueden usar para jugar otros títulos, por ejemplo, StarCraft II o Dota 2.
A principios de este mes, DeepMind
demostró el proceso de aprendizaje de IA para pasar juegos de la vieja escuela, en Atari. El principio del entrenamiento de refuerzo también se usó aquí, y es bastante difícil enseñar a la IA a pasar viejos juegos, ya que muchas acciones del protagonista son muy implícitas.
La base se tomó el juego La venganza de Montezuma. No hay una tarea clara, ni una dirección a dónde ir, ni una comprensión de lo que se debe reunir o contra quién hablar. Se utilizaron dos métodos para enseñar el ejemplo: TDC (clasificación de distancia temporal) y CDC (clasificación de distancia temporal intermodal).
La computadora fue entrenada para jugar usando video tutoriales de YouTube; hay muchos de ellos en el servicio. Durante el pasaje, se compararon los marcos de la grabación de video de pasar los niveles de IA y sus "maestros" de YouTube. Si la comparación mostrara un alto nivel de similitud, AI recibiría una recompensa. Al final resultó que, después de un tiempo, la IA realiza la misma secuencia de acciones que la persona.
En cuanto a StarCraft, que se mencionó anteriormente, en 2017, una persona
todavía derrotó al automóvil y se secó, con un puntaje de 4: 0. Song Byung-gu, profesional de StarCraft, luchó contra cuatro bots diferentes de StarCraft.