¿Permítanme agregar las líneas "aprendizaje automático" y "redes neuronales" a su currículum en 5-10 minutos de leer y comprender un breve artículo? Para aquellos que están lejos de programar, disiparé todos los mitos sobre la complejidad de la IA y mostraré que la mayoría de todos los proyectos sobre aprendizaje automático se basan en principios extremadamente simples. Vamos, solo tenemos cinco minutos.
Considere el ejemplo más básico de redes neuronales: perceptrones; Yo solo después de este ejemplo me di cuenta completamente de cómo funcionan las redes neuronales, por lo que si no me equivoco y lo entiendes. Recuerde: aquí no hay magia, matemáticas simples en el quinto grado de la escuela secundaria.
Supongamos que tenemos tres condiciones binarias diferentes (sí o no) y una solución binaria en la salida (sí o no):

Un modelo simple con tres entradas y una salida. Este modelo puede funcionar perfectamente para diferentes personas y darles diferentes resultados, dependiendo de cómo entrenaron a la red neuronal. Pero, ¿qué es una red neuronal? Estos son solo bloques separados: neuronas conectadas entre sí. Creemos una neurona simple a partir de tres neuronas:

Lo que ves entre la entrada y la salida son las neuronas. Hasta ahora no están conectados con nada, pero esto también refleja su característica principal, de la que todos se olvidan decir: son un shnyag completamente abstracto. Es decir, las neuronas en sí mismas no resuelven nada, decide exactamente lo que dibujaremos a continuación. Mientras tanto, recuerde: las neuronas no hacen nada en la neurona, excepto para racionalizar y simplificar el concepto para los humanos. Dibujemos la parte más importante de la neurona: la conexión:
Wow, eso suena como algo súper genial. Ahora agregaremos algo de magia, de alguna manera entrenaremos a la neurona con el talón izquierdo, giraremos en su lugar, reiremos, echaremos pimienta sobre el hombro derecho de nuestro vecino trasero y todo funcionará, ¿verdad? Resulta que todavía es más fácil.
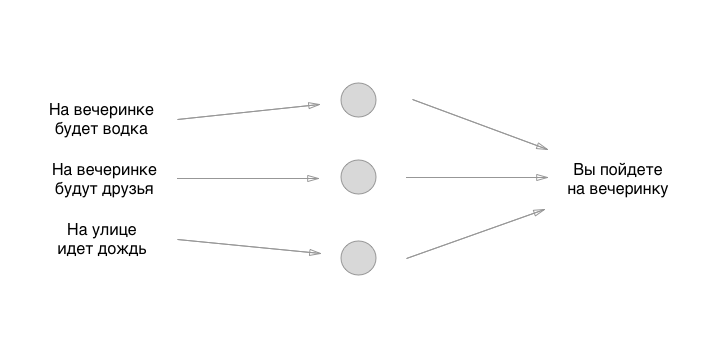
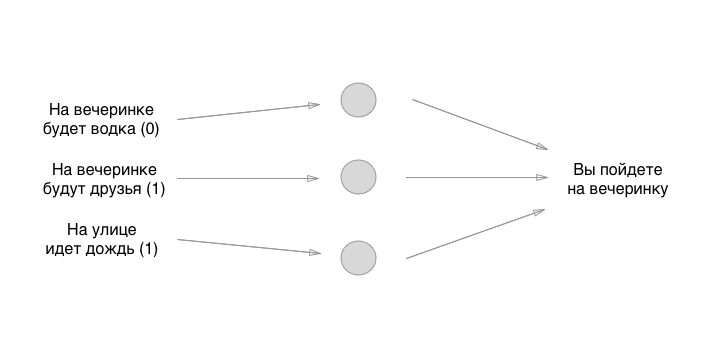
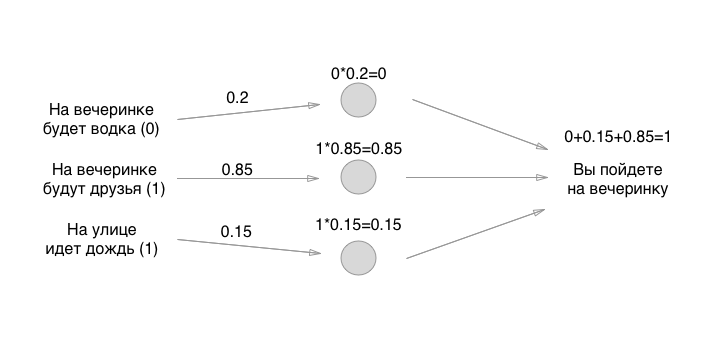
Cada entrada a la izquierda tiene un valor: 0 o 1, sí o no. Agreguemos estos valores a la entrada, supongamos que no habrá vodka en la fiesta, habrá amigos, que llueva:
Entonces, lo descubrimos. ¿Qué hacemos a continuación? Y aquí hay diversión: usemos la forma más antigua para establecer el estado inicial de las neuronas: el gran azar:
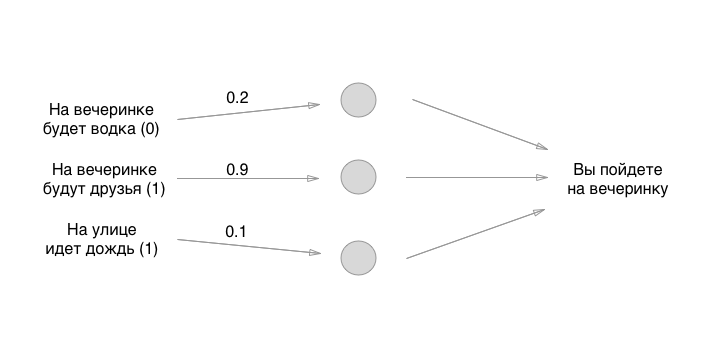
Los números que establecemos son los pesos de los enlaces. ¿Recuerdas que las neuronas están vacías? Entonces, las comunicaciones son exactamente en lo que consiste una red neuronal. Pero, ¿cuáles son los pesos de los bonos? Estas son las cosas por las cuales multiplicamos los valores de entrada y los almacenamos temporalmente en neuronas vacías. En realidad no lo almacenamos, pero por conveniencia imaginaremos que algo se puede poner en las neuronas:
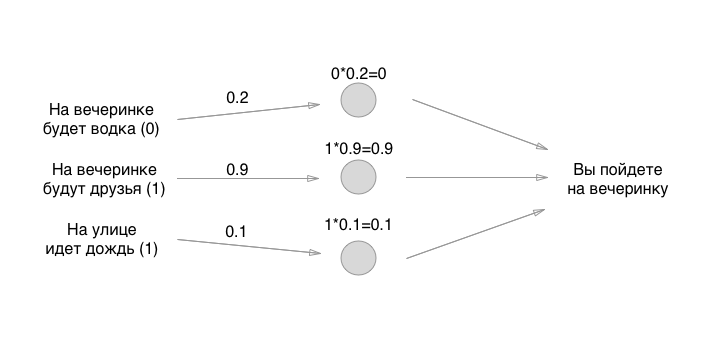
¿Cómo te gustan las matemáticas? Podría multiplicarse? ¡Espera, la parte más difícil acaba de comenzar! A continuación, agregamos los valores (en una de las implementaciones de perceptrón):

Bueno, eso es todo! La neurona se crea y puede usarla para cualquier necesidad. Si la cantidad es más de 0.5, debe ir a la fiesta. Si es menor o igual, no necesitas ir a la fiesta. Gracias por su atencion!
Por supuesto, el modelo anterior tiene pocos beneficios prácticos, necesitamos entrenarlo. La aterradora frase "entrenar las neuronas" no es así? No asi. Todo es torpe y lo más simple posible: toma datos de entrada aleatorios (como lo hicimos nosotros), ejecuta la entrada a través de estas tres neuronas, mira la respuesta, deja que sea positiva (ve a la fiesta) y comprueba si la neurona predijo correctamente la respuesta o no. . Si es correcto, no hagas nada. Si está mal, cambia ligeramente los pesos de las neuronas (una a la vez o todas a la vez) en cualquier dirección. Por ejemplo, así:
Y nuevamente verificas: ¡oh, bueno, otra vez él dice que vayan a la fiesta, cuando no quiero ir allí! Y nuevamente cambia ligeramente los pesos (en la misma dirección, lo más probable) un poco, y nuevamente pasa estos datos de entrada a través de las neuronas, y nuevamente compara el resultado, y deja los pesos solos o los mueve de nuevo. Y así, billones, billones de veces y con todo tipo de datos de entrada diferentes. Aquí, por supuesto, solo tenemos 8 combinaciones de entrada, pero hay diferentes tareas (más sobre ellas a continuación).
Este es el principio principal del trabajo de las redes neuronales: tanto la multiplicación es necesaria para la diferenciación como la comprensión del trabajo del perceptrón para la creación de redes convolucionales, neuronas recursivas e incluso algún juego exótico.
Como resultado, después de haber entrenado a una neurona en las decisiones tomadas por una persona, haberla atropellado miles de millones de veces, haber pasado por todos los pesos posibles de las neuronas, finalmente llegará a un punto medio dorado y óptimo para que una persona ingrese tres valores iniciales, y la máquina lo ejecuta fórmula ya estable y funcional con tres neuronas y da una respuesta.
Las únicas tres incógnitas en la nuestra eran los pesos de las conexiones neuronales, y fueron precisamente a ellas a quienes pasamos. Por lo tanto, digo que las neuronas son tontas que no resuelven nada, y los reyes de un banquete son los pesos de las conexiones.
Entonces todo es simple: en lugar de una capa de neuronas, hacemos dos y nuevamente clasificamos todo de acuerdo con los mismos principios, solo todas las neuronas ya dan valores a otras neuronas. Si al principio solo teníamos 3 conexiones, ahora 3 + 9 conexiones con pesas. Y luego tres capas, cuatro, capas recursivas, fijadas en sí mismas y en el juego similar:
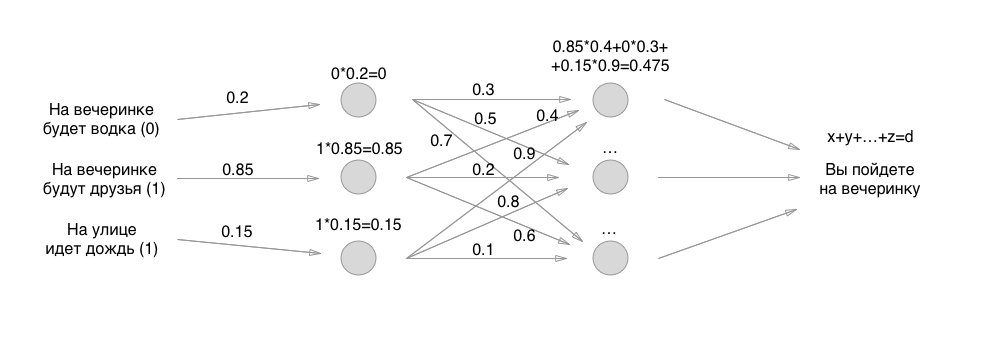
Pero, pregúnteme, dicen, ¿cuál es el resultado de algo complicado en las neuronas? ¿Por qué se paga tanto a los especialistas en aprendizaje automático? Y la cuestión es exactamente cómo implementar los perceptrones anteriores: hay tantos matices diferentes que estás atormentado para enumerarlos.
¿Qué pasa si en la entrada tienes una foto y necesitas clasificar todas las fotos de los perros y gatos? Las imágenes están en tamaños de 512x512, cada píxel es una entrada, entonces, ¿cuántos valores perseguiremos a lo largo de las neuronas? ¡Hay neuronas convolucionales para esto! Esta es una shnyaga que toma 9 píxeles uno al lado del otro, por ejemplo, y promedia sus valores RGB. Resulta que comprime la imagen para un procesamiento más rápido. O, por ejemplo, elimina completamente el color rojo en la imagen, ya que no es importante (estamos buscando, por ejemplo, solo vestidos verde-azul). Estas son redes convolucionales: una capa adicional de “neuronas” en la entrada que procesa la entrada para una vista clara y simplificada para la red.
También debe comprender cuánto y en qué dirección cambiar los pesos: hay todo tipo de algoritmos simples para comprender que consideran el error desde el final, desde la derecha (desde el resultado) hacia la izquierda (hasta la primera capa de neuronas), uno de los algoritmos se llama Back Propagation.
Hay todo tipo de algoritmos muy simples para normalizar valores, de modo que obtenga números no del 0 al 500 000, sino del 0 al 1 en la salida o en el medio al sumar, simplifica enormemente los cálculos y las matemáticas computacionales.
Como ya puede comprender, los especialistas realmente geniales en aprendizaje automático no solo conocen la mayoría de los métodos existentes para construir redes neuronales optimizadas, sino que también presentan sus propios enfoques, comenzando por la comprensión más simple pero profunda de las relaciones de causa y efecto entre cómo construir un perceptrón , y por qué funciona, en términos de matemáticas. No solo pueden hacer que la neurona funcione, sino que también pueden cambiar el algoritmo o utilizar otro algoritmo para funcionar de manera rápida y óptima.
Bueno, eso es todo: te di la base para entender qué son las redes neuronales. Con suerte también te mostré que el diablo no es tan terrible como está pintado: todo resultó ser increíblemente simple, a nivel de multiplicación y suma. Luego te aconsejo que comiences a ver tutoriales en YouTube o Udemy: hay tipos que son increíbles para explicar todo genial.
La próxima vez, cuando te pidan dinero para un proyecto de aprendizaje automático, saca a los mendigos de las redes neuronales: qué capas, cómo están organizadas, por qué y por qué, aquí está, y no es así. Todo esto al nivel de un máximo de 11 clases será (se trata de integrales y diferenciales), y luego ocurrirá en la descripción una vez, tal vez dos. Si bien el proyecto no tiene este modelo (qué capas y cómo se ubican), el proyecto no tiene un producto, porque esta estructura es las primeras 2-4 semanas de un especialista en aprendizaje automático.
PD: un ejemplo de explicación, incansablemente saqué de
un magnífico video sobre redes neuronales. Les recomiendo encarecidamente que busquen, ¡gracias chicos! los suscriptores ayudaron a restaurar el enlace al video original, un ejemplo del cual intenté recuperar de la memoria. Si alguien está interesado en cómo codificar la tarea anterior, te invito a ver este video aquí. Muchas gracias a los autores!