Esta
noticia (+
investigación ) sobre la invención del generador de memes por científicos de la Universidad de Stanford me llevó a escribir un artículo. En mi artículo, intentaré demostrar que no es necesario ser un científico de Stanford para hacer cosas interesantes con las redes neuronales. En el artículo, describo cómo en 2017 capacitamos a una red neuronal en un cuerpo de aproximadamente 30,000 textos y lo forzamos a generar nuevos memes y memes de Internet (signos de comunicación) en el sentido sociológico de la palabra. Describimos el algoritmo de aprendizaje automático que utilizamos, las dificultades técnicas y administrativas que encontramos.
Un poco de historia sobre cómo llegamos a la idea de un neuro-escritor y en qué consistía exactamente. En 2017, realizamos un proyecto para un sitio web público de Vkontakte, cuyo nombre y capturas de pantalla los moderadores de Habrahabr prohibieron publicar, considerando su mención como "auto" de relaciones públicas. El público existe desde 2013 y une publicaciones con la idea general de descomponer el humor a través de una línea y separar las líneas con el símbolo "@":
@
@
El número de líneas puede variar, la trama puede ser cualquiera. Muy a menudo, esto es humor o notas sociales agudas sobre los hechos rampantes de la realidad. En general, este diseño se llama "buhurt".
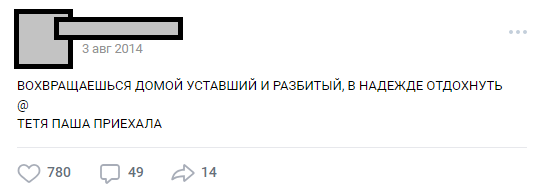 Uno de los buhurts típicos.
Uno de los buhurts típicos.A lo largo de los años, el público se ha convertido en una tradición interna (personajes, tramas, ubicaciones), y el número de publicaciones ha excedido de 30,000. En el momento de su análisis, el número de líneas de origen del texto excedía de medio millón para las necesidades del proyecto.
Parte 0. El surgimiento de ideas y equipos.
A raíz de la popularidad masiva de las redes neuronales, la idea de entrenar a ANN en nuestros textos estuvo en el aire durante unos seis meses, pero finalmente se formuló utilizando E7su en diciembre de 2016. Al mismo tiempo, se inventó el nombre ("Neurobugurt"). En ese momento, el equipo interesado en el proyecto constaba de solo tres personas. Todos éramos estudiantes sin experiencia práctica en algoritmos y redes neuronales. Peor aún, ni siquiera teníamos una sola GPU adecuada para el entrenamiento. Todo lo que teníamos era entusiasmo y confianza en que esta historia podría ser interesante.
Parte 1. La formulación de la hipótesis y las tareas.
Nuestra hipótesis resultó ser la suposición de que si combina todos los textos publicados durante tres años y medio y entrena la red neuronal en este edificio, puede obtener:
a) más creativo que las personas
b) gracioso
Incluso si las palabras o letras en el buhurt resultan ser confusas y ordenadas al azar, creemos que esto podría funcionar como un servicio de fanáticos y que aún complacería a los lectores.
La tarea se simplificó enormemente por el hecho de que el formato de los buhurts es esencialmente textual. Entonces, no necesitábamos sumergirnos en la visión artificial y otras cosas complejas. Otra buena noticia es que todo el cuerpo de textos es muy similar. Esto hizo posible no utilizar el aprendizaje reforzado, al menos en las primeras etapas. Al mismo tiempo, entendimos claramente que crear un escritor de redes neuronales con salida legible más de una vez no es tan fácil. El riesgo de dar a luz a un monstruo que arrojaría letras al azar era muy grande.
Parte 2. Preparación del cuerpo de textos.
Se cree que la fase de preparación puede llevar mucho tiempo, ya que está asociada con la recopilación y limpieza de datos. En nuestro caso, resultó ser bastante corto: se escribió un pequeño
analizador que extrajo unas 30k publicaciones del muro de la comunidad y las colocó en un
archivo txt .
No borramos los datos antes del primer entrenamiento. En el futuro, esto jugó una broma cruel con nosotros, porque debido al error que apareció en esta etapa, no pudimos llevar los resultados a una forma legible durante mucho tiempo. Pero más sobre eso más tarde.
 Archivo de pantalla con hamburguesas
Archivo de pantalla con hamburguesasParte 3. Anuncio, refinamiento de la hipótesis, elección del algoritmo.
Utilizamos un recurso accesible: una gran cantidad de suscriptores públicos. Se suponía que entre 300,000 lectores hay varios entusiastas que poseen redes neuronales en un nivel suficiente para llenar los vacíos en el conocimiento de nuestro equipo. Partimos de la idea de anunciar ampliamente la competencia y atraer a los entusiastas del aprendizaje automático a la discusión del problema formulado. Después de escribir los textos, le contamos a la gente sobre nuestra idea y esperamos una respuesta.
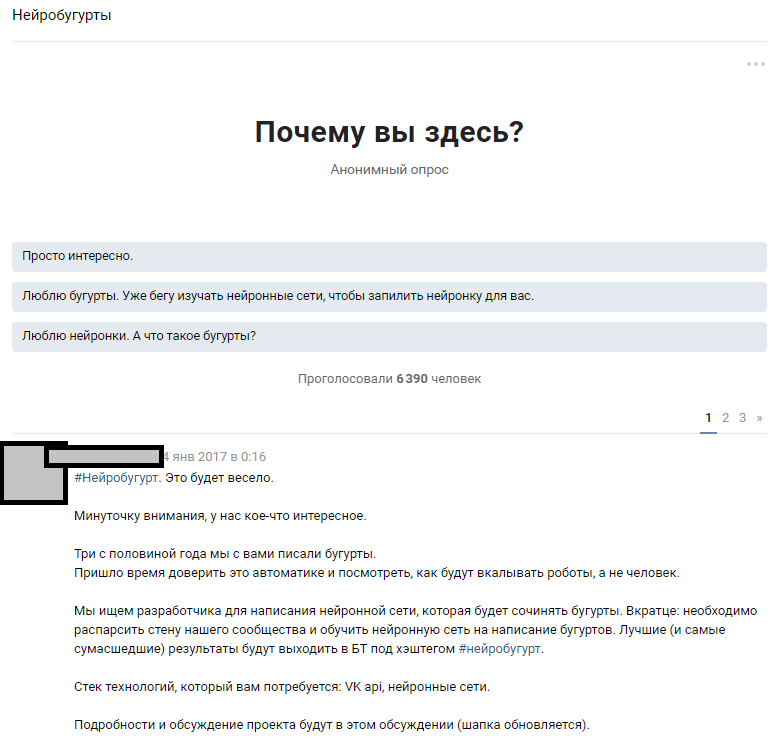 Anuncio de discusión temática
Anuncio de discusión temáticaLa reacción de las personas superó nuestras expectativas más salvajes. La discusión sobre el hecho de que vamos a entrenar una red neuronal extendió el holivar en casi 1000 comentarios. La mayoría de los lectores simplemente se desvanecieron e intentaron imaginar cómo sería el resultado. Alrededor de 6,000 personas se asomaron a la discusión temática, y más de 50 aficionados interesados dejaron comentarios para quienes les dimos un conjunto de prueba de
814 líneas buhurt para realizar pruebas iniciales y capacitación. Cada persona interesada podría tomar un conjunto de datos y aprender el algoritmo que sea más interesante para él, y luego discutirlo con nosotros y otros entusiastas. Anunciamos de antemano que seguiremos trabajando con aquellos participantes cuyos resultados serán más legibles.
El trabajo comenzó: alguien ensambló silenciosamente un generador en las cadenas de Markov, alguien probó varias implementaciones con un github, y la mayoría se volvió loco en la discusión y nos convenció con espuma en la boca de que nada saldría de eso. Esto comenzó la parte técnica del proyecto.
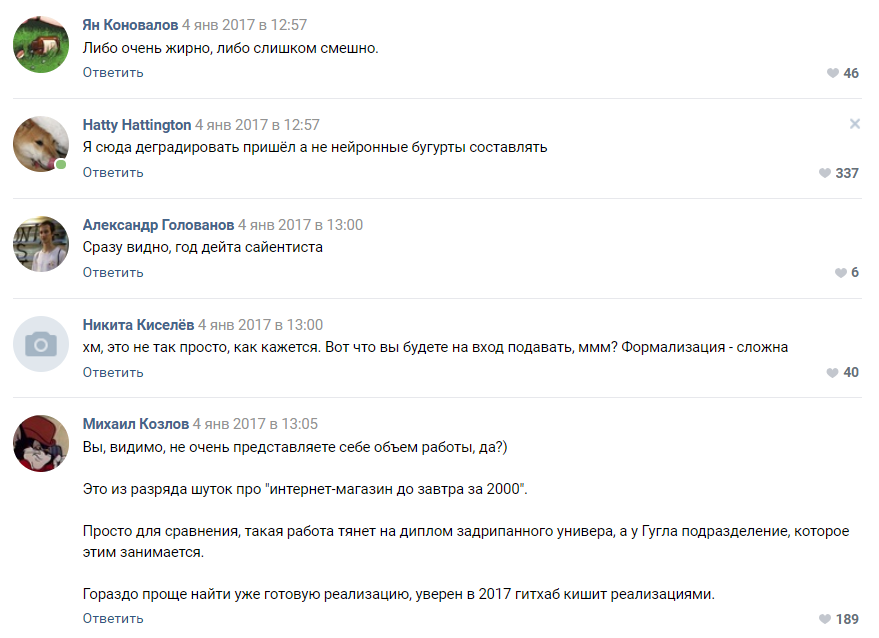
Algunas sugerencias de entusiastas
Las personas ofrecieron docenas de opciones para la implementación:
- Cadenas de Markov.
- Encuentre una implementación lista para usar de algo similar a GitHub y capacítelo.
- Un generador de frases al azar escrito en Pascal.
- Obtenga un negro literario que escriba tonterías aleatorias, y lo pasaremos como una salida de red neuronal.
 Evaluación de la complejidad del proyecto por parte de uno de los suscriptores.
Evaluación de la complejidad del proyecto por parte de uno de los suscriptores.La mayoría de los comentaristas estuvieron de acuerdo en que nuestro proyecto está condenado al fracaso y que ni siquiera llegaremos a la etapa de prototipo. Como entendimos más tarde, la gente todavía está inclinada a percibir las redes neuronales como algún tipo de magia negra que ocurre en la "cabeza de Zuckerberg" y las divisiones secretas de Google.
Parte 4. Selección de algoritmos, capacitación y expansión del equipo.
Después de un tiempo, la campaña que lanzamos para ideas de crowdsourcing para el algoritmo comenzó a dar sus primeros frutos. Obtuvimos unos 30 prototipos de trabajo, la mayoría de los cuales emitieron tonterías completamente ilegibles.
En esta etapa, encontramos por primera vez una desmotivación del equipo. Todos los resultados fueron muy débilmente similares a los buhurts y la mayoría de las veces representaron un abracadabra de letras y símbolos. El trabajo de docenas de entusiastas se convirtió en polvo y esto los desmotivó tanto a ellos como a nosotros.
El algoritmo basado en pyTorch se mostró mejor que otros. Se decidió tomar esta implementación y el algoritmo LSTM como base. Reconocimos al suscriptor que lo propuso como el ganador y comenzamos a trabajar para mejorar el algoritmo junto con él. Nuestro equipo distribuido ha crecido hasta cuatro personas. El hecho curioso aquí es que el
ganador del concurso , como resultó, tenía solo 16 años. La victoria fue su primer premio real en el campo de la ciencia de datos.
Para el primer entrenamiento, se alquiló un grupo de 8 tarjetas gráficas GXT1080.
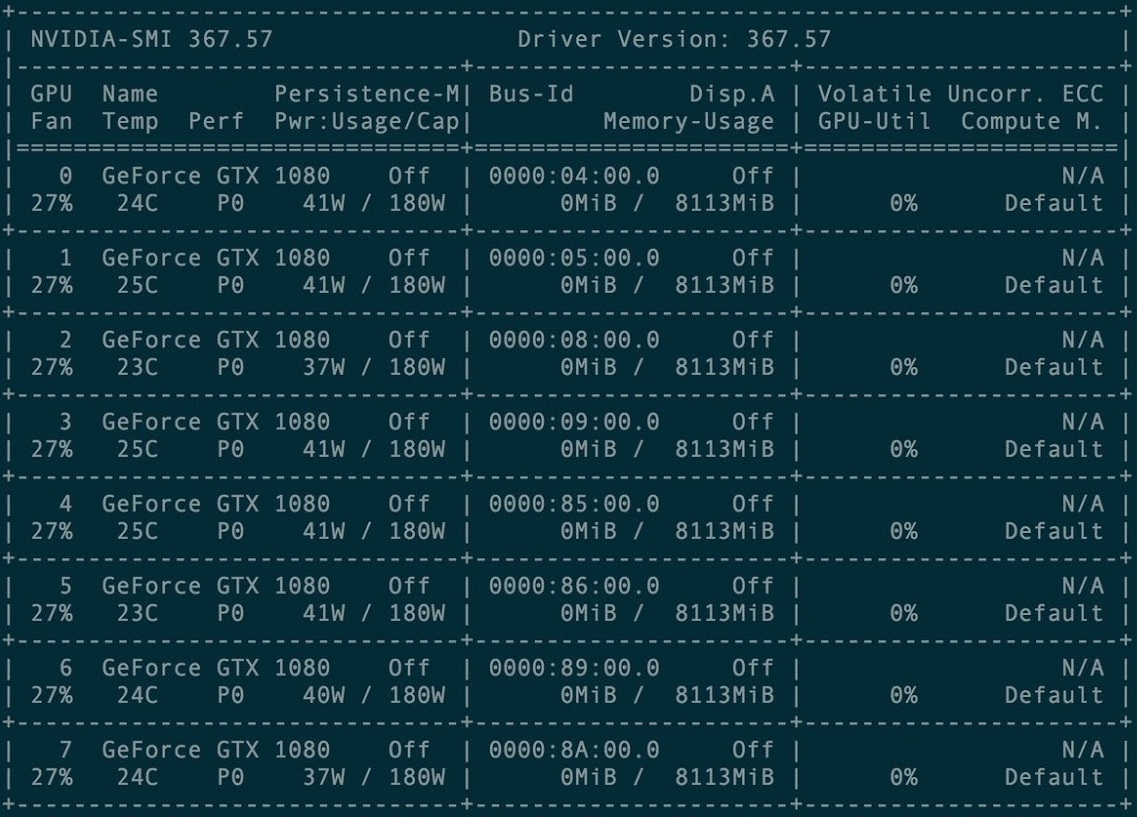 Consola de administración de tarjetas agrupadas
Consola de administración de tarjetas agrupadasEl repositorio original y todos los manuales del proyecto Torch-rnn están aquí:
github.com/jcjohnson/torch-rnn . Más tarde, sobre la base de esto, publicamos
nuestro repositorio , en el que están nuestras fuentes, ReadMe para la instalación, así como los propios neurobugurts terminados.
Las primeras veces que entrenamos usando una configuración preconfigurada en un clúster de GPU pagado. La configuración resultó no ser tan difícil: solo las instrucciones del desarrollador de Torch y la ayuda de la administración de hosting, que está incluida en el pago, son suficientes.
Sin embargo, muy rápidamente tuvimos dificultades: cada capacitación costó el tiempo de alquiler de la GPU, lo que significa que simplemente no había dinero en el proyecto. Debido a esto, en enero-febrero de 2017, realizamos capacitación en las instalaciones compradas e intentamos lanzar la generación en nuestras máquinas locales.
Cualquier texto es adecuado para el entrenamiento modelo. Antes de entrenar, debe preprocesarlo, para lo cual Torch tiene un algoritmo especial preprocess.py que convierte su my_data.txt en dos archivos: HDF5 y JSON:
El script de preprocesamiento se ejecuta así:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
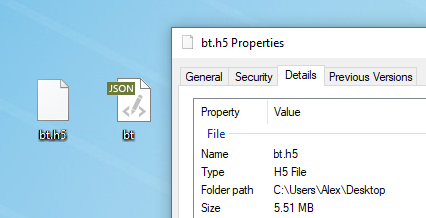 Después del preprocesamiento, aparecen dos archivos en los que se capacitará la red neuronal en el futuroAquí
Después del preprocesamiento, aparecen dos archivos en los que se capacitará la red neuronal en el futuroAquí se describen los diversos indicadores que se pueden cambiar en la etapa de preprocesamiento. También es posible ejecutar
Torch desde Docker , pero el autor del artículo no lo verificó.
Entrenamiento de redes neuronales
Después del preprocesamiento, puede continuar con la capacitación del modelo. En la carpeta con HDF5 y JSON, debe ejecutar la utilidad th, que apareció con usted si instaló Torch correctamente:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
La capacitación lleva una gran cantidad de tiempo y genera archivos de la forma cv / checkpoint_1000.t7, que son los "pesos" de nuestra red neuronal. Estos archivos pesan una cantidad impresionante de megabytes y contienen la fuerza de los enlaces entre letras específicas en su conjunto de datos original.
 Una red neuronal a menudo se compara con el cerebro humano, pero me parece una analogía mucho más clara con una función matemática que toma parámetros en la entrada (su conjunto de datos) y da el resultado (nuevos datos) en la salida.
Una red neuronal a menudo se compara con el cerebro humano, pero me parece una analogía mucho más clara con una función matemática que toma parámetros en la entrada (su conjunto de datos) y da el resultado (nuevos datos) en la salida.En nuestro caso, cada entrenamiento en un clúster de 8 GTX 1080 en un conjunto de datos de 500,000 líneas tomó aproximadamente una hora o dos, y un entrenamiento similar en un tipo de CPU i3-2120 tomó aproximadamente 80-100 horas. En el caso de un entrenamiento más largo, la red neuronal comenzó a volverse a entrenar rígidamente: los símbolos se repetían con demasiada frecuencia, cayendo en largos ciclos de preposiciones, conjunciones y palabras introductorias.
Es conveniente que pueda elegir la frecuencia de los puntos de control y durante un entrenamiento obtendrá inmediatamente muchos modelos: desde el menos entrenado (checkpoint_1000) hasta el reentrenado (checkpoint_1000000). Solo suficiente espacio sería suficiente.
Nueva generación de texto.
Después de haber recibido al menos un archivo listo con pesos (punto de control _ *******), puede pasar a la siguiente etapa más interesante: comenzar a generar textos. Para nosotros, fue un verdadero momento de verdad, porque por primera vez obtuvimos un resultado tangible: un error escrito por una máquina.
En este punto, finalmente dejamos de usar el clúster y todas las generaciones se llevaron a cabo en nuestras máquinas de baja potencia. Sin embargo, al intentar iniciar localmente, simplemente no logramos seguir las instrucciones e instalar Torch. La primera barrera fue el uso de máquinas virtuales. En Ubuntu 16 virtual, el palo no despega, olvídalo. StackOverflow a menudo acudía al rescate, pero algunos errores no eran tan triviales que la respuesta solo se podía encontrar con gran dificultad.
La instalación de Torch en una máquina local detuvo el proyecto por un buen par de semanas: encontramos todo tipo de errores al instalar numerosos paquetes requeridos, también tuvimos problemas con la virtualización (virtualenv .env) y finalmente no la usamos. Varias veces el soporte fue demolido al nivel de sudo rm -rf y simplemente se instaló nuevamente.
Usando el archivo resultante con pesos, pudimos comenzar a generar textos en nuestra máquina local:
 Una de las primeras conclusiones.
Una de las primeras conclusiones.Parte 5. Borrar textos
Otra dificultad obvia fue que el tema de las publicaciones es muy diferente, y nuestro algoritmo no involucra ninguna división y considera todas las 500,000 líneas como un solo texto. Consideramos diferentes opciones para agrupar el conjunto de datos e incluso estábamos listos para dividir manualmente el cuerpo de textos por tema o colocar etiquetas en varios miles de buhurts (había un recurso humano necesario para esto), pero constantemente enfrentamos dificultades técnicas para enviar clústeres al aprender LSTM. Cambiar el algoritmo y realizar la competencia nuevamente no parecía ser la idea más sensata en términos de cronometraje del proyecto y la motivación de los participantes.
Parecía que estábamos en un punto muerto: no podíamos agrupar buhurts, y el entrenamiento en un solo gran conjunto de datos arrojó resultados dudosos. No quería dar un paso atrás y cambiar el algoritmo y la implementación casi disparados: el proyecto simplemente podría caer en coma. El equipo desesperadamente no tenía suficiente conocimiento para resolver la situación normalmente, pero el viejo SME-KAL-OCHK-A vino al rescate. La solución final a la
muleta resultó ser simple: en el conjunto de datos original, separe los buhurts existentes entre sí con líneas vacías y entrene LSTM nuevamente.
Organizamos los latidos en 10 espacios verticales después de cada buhurt, repetimos el entrenamiento y durante la generación establecimos un límite en el volumen de salida de 500 caracteres (la longitud promedio de un buhurt de "trama" en el conjunto de datos original).
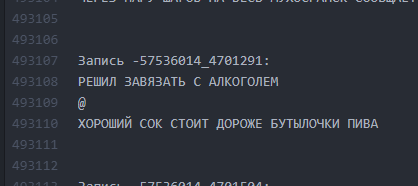 Como era. Los intervalos entre textos son mínimos.
Como era. Los intervalos entre textos son mínimos.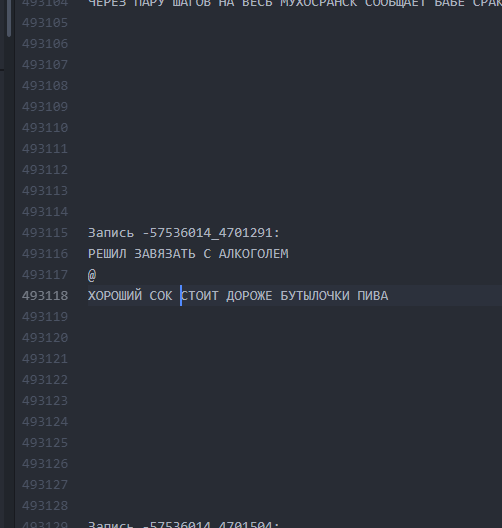 ¿Cómo se hizo? Los intervalos de 10 líneas permiten que LSTM "entienda" que un bogurt ha terminado y que otro ha comenzado.
¿Cómo se hizo? Los intervalos de 10 líneas permiten que LSTM "entienda" que un bogurt ha terminado y que otro ha comenzado.Por lo tanto, fue posible lograr que aproximadamente el 60% de todos los buhurts generados comenzaron a tener una trama legible (aunque a menudo muy delirante) a lo largo de todo el buhurt de principio a fin. La longitud de una parcela fue, en promedio, de 9 a 13 líneas.
Parte 6. Reentrenamiento
Habiendo estimado la economía del proyecto, decidimos no gastar más dinero en alquilar un grupo, sino invertir en comprar nuestras propias tarjetas. El tiempo de aprendizaje aumentaría, pero habiendo comprado una tarjeta una vez, podríamos generar nuevos aumentos constantemente. Al mismo tiempo, a menudo la capacitación ya no era necesaria.
 Configuraciones de lucha en la máquina local
Configuraciones de lucha en la máquina localParte 7. Resultados de equilibrio
A fines de marzo-abril de 2017, volvimos a entrenar la red neuronal, especificando los parámetros de temperatura y la cantidad de eras de entrenamiento. Como resultado, la calidad de la salida ha aumentado ligeramente.
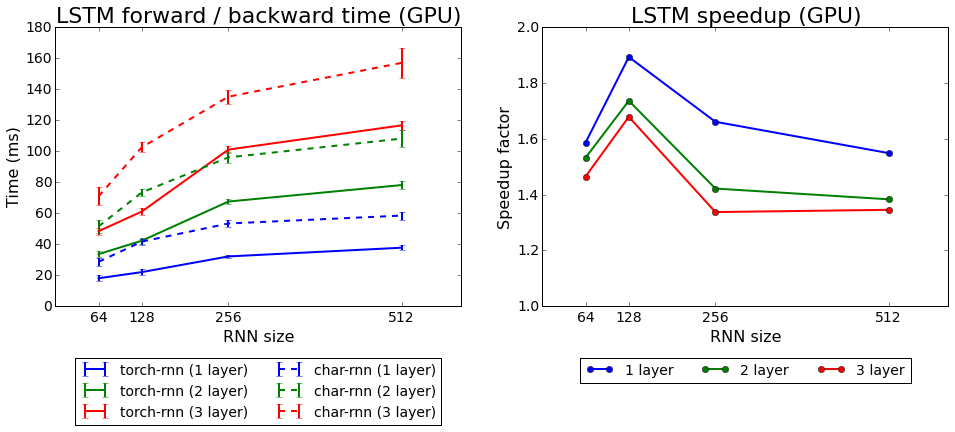 Torch-rnn velocidad de aprendizaje en comparación con char-rnn
Torch-rnn velocidad de aprendizaje en comparación con char-rnnProbamos los dos algoritmos que vienen con Torch: rnn y LSTM. El segundo resultó ser mejor.
Parte 8. ¿Qué hemos logrado?
El primer neurobugurt se publicó el 17 de enero de 2017, inmediatamente después del entrenamiento en el clúster, y el primer día se recopilaron más de 1000 comentarios.
 Uno de los primeros neurobugurts
Uno de los primeros neurobugurtsLos neurobugurts llegaron tan bien a la audiencia que se convirtieron en una sección separada, que durante todo el año salió bajo el hashtag # neurobugurt y suscriptores divertidos. En total, en 2017 y principios de 2018, generamos más de
18,000 neurobugurts , con un promedio de 500 caracteres cada uno. Además, apareció todo un movimiento de parodias públicas, cuyos participantes representaban neurobugurs, reorganizando frases al azar en lugares.

Parte 9. En lugar de una conclusión
Con este artículo, quería mostrar que incluso si no tienes experiencia en redes neuronales, este dolor no es un problema. No necesita trabajar en Stanford para hacer cosas simples pero interesantes con redes neuronales. Todos los participantes en nuestro proyecto eran estudiantes comunes con sus tareas actuales, diplomas, trabajos, pero la causa común nos permitió llevar el proyecto a la final. Gracias a la idea reflexiva, la planificación y la energía de los participantes, pudimos obtener los primeros resultados sanos en menos de un mes después de la formulación final de la idea (la mayor parte del trabajo técnico y organizativo cayó en las vacaciones de invierno de 2017).
 Más de 18,000 buhurts generados por máquina
Más de 18,000 buhurts generados por máquinaEspero que este artículo ayude a alguien a planificar su propio proyecto ambicioso con redes neuronales. Pido no juzgar estrictamente, ya que este es mi primer artículo sobre Habré. Si usted, como yo, entusiasta de ML, seamos
amigos .