
En el campo del reconocimiento de emociones, la voz es la segunda fuente más importante de datos emocionales después de la cara. La voz puede caracterizarse por varios parámetros. El tono de voz es una de las principales características, sin embargo, en el campo de la tecnología acústica es más correcto llamar a este parámetro la frecuencia fundamental.
La frecuencia del tono fundamental está directamente relacionada con lo que llamamos entonación. Y la entonación, por ejemplo, está asociada con las características emocionalmente expresivas de la voz.
Sin embargo, determinar la frecuencia del tono fundamental no es una tarea completamente trivial con matices interesantes. En este artículo, discutiremos las características de los algoritmos para su determinación y compararemos las soluciones existentes con ejemplos de grabaciones de audio específicas.
IntroduccionPara empezar, recordemos cuál es, en esencia, la frecuencia del tono fundamental y en qué tareas puede ser necesario.
La frecuencia fundamental , que también se conoce como CHOT, Frecuencia fundamental o F0, es la frecuencia de las cuerdas vocales cuando pronuncian sonidos sonoros. Al pronunciar sonidos que no son de tono (sordos), por ejemplo, hablar en voz baja o emitir silbidos y silbidos, los ligamentos no vacilan, lo que significa que esta característica no es relevante para ellos.
* Tenga en cuenta que la división en sonidos tonales y no tonales no es equivalente a la división en vocales y consonantes.
La variabilidad de la frecuencia del tono fundamental es bastante grande, y puede variar mucho no solo entre las personas (para las voces masculinas promedio más bajas, la frecuencia es de 70-200 Hz, y para las voces femeninas puede alcanzar los 400 Hz), sino también para una persona, especialmente en el lenguaje emocional. .
La determinación de la frecuencia del tono fundamental se utiliza para resolver una amplia gama de problemas:
- Reconocimiento de emociones, como dijimos anteriormente;
- Determinación sexual;
- Al resolver el problema de segmentar audio con múltiples voces o dividir el discurso en frases;
- En medicina, para determinar las características patológicas de la voz (por ejemplo, utilizando los parámetros acústicos Jitter y Shimmer). Por ejemplo, la identificación de signos de la enfermedad de Parkinson [ 1 ]. Jitter y Shimmer también pueden usarse para reconocer emociones [ 2 ].
Sin embargo, hay una serie de dificultades para determinar F0. Por ejemplo, a menudo es posible confundir F0 con armónicos, lo que puede conducir a los llamados efectos de duplicación de tono / reducción a la mitad de tono [
3 ]. Y en grabaciones de audio de baja calidad, F0 es bastante difícil de calcular, ya que el pico deseado a bajas frecuencias casi desaparece.
Por cierto, ¿recuerdas la historia de
Laurel y Yanny ? Las diferencias en las palabras que las personas escuchan cuando escuchan la misma grabación de audio, surgieron precisamente debido a la diferencia en la percepción F0, que está influenciada por muchos factores: la edad del oyente, el grado de fatiga y el dispositivo de reproducción. Entonces, cuando escuche grabaciones en parlantes con reproducción de alta calidad de bajas frecuencias, escuchará a Laurel, y en sistemas de audio donde las bajas frecuencias se reproducen mal, Yanny. El efecto de transición se puede ver en un dispositivo, por ejemplo
aquí . Y en este
artículo , la red neuronal actúa como oyente. En otro
artículo, puede leer cómo se explica el fenómeno Yanny / Laurel en términos de formación del habla.
Dado que un análisis detallado de todos los métodos para determinar F0 sería demasiado voluminoso, el artículo es de naturaleza general y puede ayudar a navegar el tema.
Métodos para determinar F0Los métodos para determinar F0 se pueden dividir en tres categorías: en función de la dinámica de tiempo de la señal, o dominio de tiempo; basado en la estructura de frecuencia, o dominio de frecuencia, así como métodos combinados. Sugerimos que se familiarice con el
artículo de revisión sobre el tema, donde se analizan en detalle los métodos indicados para extraer F0.
Tenga en cuenta que cualquiera de los algoritmos discutidos consta de 3 pasos principales:
Preprocesamiento (filtrado de la señal, división en cuadros)
Buscar posibles valores de F0 (candidatos)
El seguimiento es la elección de la trayectoria más probable F0 (dado que para cada momento en el tiempo tenemos varios candidatos en competencia, necesitamos encontrar la pista más probable entre ellos)
Dominio del tiempoEsbozamos algunos puntos generales. Antes de aplicar los métodos en el dominio del tiempo, la señal se filtra previamente, dejando solo bajas frecuencias. Se establecen umbrales: las frecuencias mínimas y máximas, por ejemplo, de 75 a 500 Hz. La determinación de F0 se realiza solo para áreas con voz armónica, ya que para pausas o sonidos de ruido esto no solo no tiene sentido, sino que también puede introducir errores en cuadros adyacentes cuando se aplica la interpolación y / o suavizado. La longitud del cuadro se selecciona de modo que contenga al menos tres períodos.
El método principal, en base al cual apareció posteriormente toda una familia de algoritmos, es la autocorrelación. El enfoque es bastante simple: es necesario calcular la función de autocorrelación y tomar su primer máximo. Mostrará el componente de frecuencia más pronunciado en la señal. ¿Cuál podría ser la dificultad en el caso de utilizar la autocorrelación y por qué está lejos de ser siempre que el primer máximo corresponderá a la frecuencia deseada? Incluso en condiciones cercanas a las ideales en grabaciones de alta calidad, el método puede confundirse debido a la compleja estructura de la señal. En condiciones cercanas a la real, donde, entre otras cosas, podemos encontrar la desaparición del pico deseado en grabaciones ruidosas o grabaciones de baja calidad inicial, el número de errores aumenta considerablemente.
A pesar de los errores, el método de autocorrelación es bastante conveniente y atractivo debido a su simplicidad y lógica básicas, razón por la cual se toma como base en muchos algoritmos, incluido YIN. Incluso el nombre del algoritmo nos remite al equilibrio entre la conveniencia y la inexactitud del método de autocorrelación: "El nombre YIN de" yin "y" yang "de la filosofía oriental alude a la interacción entre la autocorrelación y la cancelación que implica". [
4 ]
Los creadores de YIN intentaron corregir las debilidades del enfoque de autocorrelación. El primer cambio es el uso de la función de diferencia normalizada media acumulativa, que debería reducir la sensibilidad a las modulaciones de amplitud, hacer que los picos sean más pronunciados:
\ begin {ecuación}
d'_t (\ tau) =
\ begin {cases}
1, & \ tau = 0 \\
d_t (\ tau) \ bigg / \ bigg [\ frac {1} {\ tau} \ sum \ limits_ {j = 1} ^ {\ tau} d_t (j) \ bigg], y \ text {de lo contrario}
\ end {casos}
\ end {ecuación}
YIN también trata de evitar errores que ocurren en casos donde la longitud de la función de ventana no está completamente dividida por el período de oscilación. Para esto, se utiliza la interpolación mínima parabólica. En el último paso del procesamiento de la señal de audio, se ejecuta la función Mejor estimación local para evitar saltos bruscos en los valores (ya sea bueno o malo, este es un punto discutible).
Dominio de frecuenciaSi hablamos del dominio de la frecuencia, entonces la estructura armónica de la señal se destaca, es decir, la presencia de picos espectrales en frecuencias que son múltiplos de F0. Puede "colapsar" este patrón periódico en un pico claro utilizando el análisis cepstral. Cepstrum - Transformada de Fourier del logaritmo del espectro de potencia; el pico cepstral corresponde al componente más periódico del espectro (uno puede leer sobre esto
aquí y
aquí ).
Métodos híbridos para determinar F0El siguiente algoritmo, que vale la pena explorar con más detalle, tiene el nombre parlante YAAPT, otro algoritmo de seguimiento de tono, y de hecho es híbrido, ya que utiliza información de frecuencia y tiempo. Una descripción completa está en el
artículo , aquí describimos solo las etapas principales.
 Figura 1. Diagrama del algoritmo YAAPTalgo ( enlace )
Figura 1. Diagrama del algoritmo YAAPTalgo ( enlace ) .
YAAPT consta de varios pasos principales, el primero de los cuales es el preprocesamiento. En esta etapa, los valores de la señal original son al cuadrado y se obtiene una segunda versión de la señal. Este paso persigue el mismo objetivo que la función de diferencia normalizada media acumulada en YIN: amplificación y restauración de picos de autocorrelación "atascados". Ambas versiones de la señal se filtran, por lo general toman el rango de 50-1500 Hz, a veces 50-900 Hz.
Luego, la trayectoria base F0 se calcula a partir del espectro de la señal convertida. Los candidatos para F0 se determinan utilizando la función de correlación de armónicos espectrales (SHC).
\ begin {ecuación}
SHC (t, f) = \ sum \ limits_ {f '= - WL / 2} ^ {WL / 2} \ prod \ limits_ {r = 1} ^ {NH + 1} S (t, rf + f')
\ end {ecuación}
donde S (t, f) es el espectro de magnitud para el cuadro t y la frecuencia f, WL es la longitud de la ventana en Hz, NH es el número de armónicos (los autores recomiendan usar los primeros tres armónicos). La potencia espectral también se usa para determinar los cuadros sonoros y no sonoros, después de lo cual se busca la trayectoria más óptima, y se tiene en cuenta la posibilidad de duplicación de tono / reducción a la mitad de tono [
3 , Sección II, C].
Además, los candidatos para F0 se determinan tanto para la señal inicial como para la convertida, y en lugar de la función de autocorrelación, aquí se utiliza la Correlación cruzada normalizada (NCCF).
\ begin {ecuación}
NCCF (m) = \ frac {\ sum \ limits_ {n = 0} ^ {Nm-1} x (n) * x (n + m)} {\ sqrt {\ sum \ limits_ {n = 0} ^ { Nm-1} x ^ 2 (n) * \ sum \ limits_ {n = 0} ^ {Nm-1} x ^ 2 (n + m)}} \ text {,} \ hspace {0.3cm} 0 <m <M_ {0}
\ end {ecuación}
El siguiente paso es evaluar a todos los posibles candidatos y calcular su importancia o peso (mérito). El peso de los candidatos obtenidos de la señal de audio depende no solo de la amplitud del pico NCCF, sino también de su proximidad a la trayectoria F0 determinada a partir del espectro. Es decir, el dominio de frecuencia se considera grueso en términos de precisión, pero estable [
3 , Sección II, D].
Luego, para todos los pares de los candidatos restantes, se calcula la matriz de Costo de transición: el precio de transición, en el que finalmente encuentran la trayectoria óptima [
3 , Sección II, E].
EjemplosAhora aplicamos todos los algoritmos anteriores a grabaciones de audio específicas. Como punto de partida, utilizaremos
Praat , una herramienta que es fundamental para muchos estudiosos del habla. Y luego, en Python, analizaremos la implementación de YIN y YAAPT y compararemos los resultados recibidos.
Como material de audio, puede usar cualquier audio disponible. Tomamos varios extractos de nuestra
base de datos
RAMAS , un
conjunto de datos multimodal creado con la participación de actores de VGIK. También puede usar material de otras bases de datos abiertas, como
LibriSpeech o
RAVDESS .
Para un ejemplo ilustrativo, tomamos extractos de varias grabaciones con voces masculinas y femeninas, tanto neutrales como emocionalmente coloreadas, y para mayor claridad, los combinamos en una sola
grabación . Veamos nuestra señal, su espectrograma, intensidad (color naranja) y F0 (color azul). En Praat, esto se puede hacer usando Ctrl + O (Abrir - Leer desde archivo) y luego el botón Ver y editar.
 Figura 2. Espectrograma, intensidad (color naranja), F0 (color azul) en Praat.
Figura 2. Espectrograma, intensidad (color naranja), F0 (color azul) en Praat.El audio muestra claramente que en el discurso emocional, el tono aumenta tanto en hombres como en mujeres. Al mismo tiempo, F0 para el discurso emocional masculino puede compararse con F0 de una voz femenina.
SeguimientoSeleccione la pestaña Analizar periodicidad - a Pitch (ac) en el menú Praat, es decir, la definición de F0 usando autocorrelación. Aparecerá una ventana para configurar parámetros en la que es posible establecer 3 parámetros para determinar candidatos para F0 y 6 parámetros más para el algoritmo de buscador de ruta, que construye la ruta F0 más probable entre todos los candidatos.
Muchos parámetros (en Praat, su descripción también está en el botón Ayuda)- Umbral de silencio: el umbral de la amplitud relativa de la señal para determinar el silencio, el valor estándar es 0.03.
- Umbral de sonorización: el peso del candidato sordo, el valor máximo es 1. Cuanto mayor sea este parámetro, más cuadros se definirán como sordos, es decir, que no contienen sonidos de tono. En estos cuadros, F0 no se determinará. El valor de este parámetro es el umbral para los picos de la función de autocorrelación. El valor predeterminado es 0.45.
- Costo de octava: determina cuánto más peso tienen los candidatos de alta frecuencia en relación con los de baja frecuencia. Cuanto mayor sea el valor, más preferencia se le da al candidato de alta frecuencia. El valor predeterminado es 0.01 por octava.
- Costo de salto de octava: con un aumento en este coeficiente, el número de transiciones bruscas como saltos entre valores sucesivos de F0 disminuye. El valor predeterminado es 0.35.
- Costo sonoro / sordo: aumentar este coeficiente disminuye el número de transiciones sonoras / sonoras. El valor predeterminado es 0.14.
- Techo de paso (Hz): no se consideran candidatos por encima de esta frecuencia. El valor predeterminado es 600 Hz.
Se puede encontrar
una descripción detallada del algoritmo en
un artículo de 1993.
Puede verse el resultado del rastreador (buscador de ruta) haciendo clic en Aceptar y luego viendo (Ver y editar) el archivo Pitch resultante. Se puede ver que, además de la trayectoria seleccionada, todavía había candidatos bastante significativos con una frecuencia más baja.
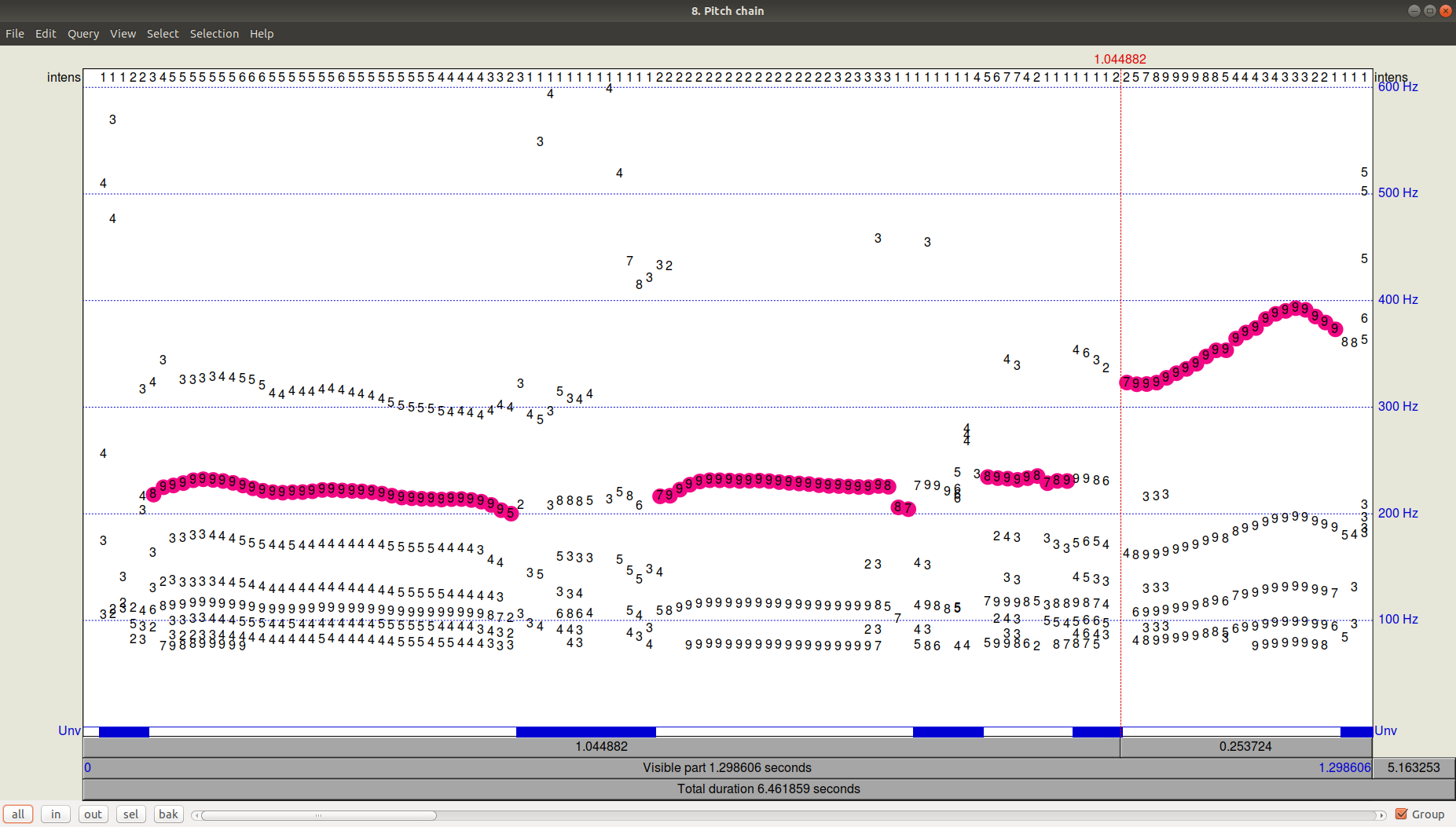 Figura 3. PitchPath durante los primeros 1.3 segundos de grabación de audio.¿Pero qué hay de Python?
Figura 3. PitchPath durante los primeros 1.3 segundos de grabación de audio.¿Pero qué hay de Python?Tomemos dos bibliotecas que ofrecen seguimiento de tono:
aubio , en el que el algoritmo predeterminado es YIN, y la biblioteca
AMFM_decompsition , que tiene una implementación del algoritmo YAAPT. En el archivo separado (archivo
PraatPitch.txt ),
inserte los valores F0 de Praat (esto se puede hacer manualmente: seleccione el archivo de sonido, haga clic en Ver y editar, seleccione el archivo completo y seleccione la lista Pitch-Pitch en el menú superior).
Ahora compare los resultados para los tres algoritmos (YIN, YAAPT, Praat).
Mucho códigoimport amfm_decompy.basic_tools as basic import amfm_decompy.pYAAPT as pYAAPT import matplotlib.pyplot as plt import numpy as np import sys from aubio import source, pitch
 Figura 4. Comparación del funcionamiento de los algoritmos YIN, YAAPT y Praat.
Figura 4. Comparación del funcionamiento de los algoritmos YIN, YAAPT y Praat.Vemos que con los parámetros predeterminados, YIN está bastante noqueado, obteniendo una trayectoria muy plana con valores más bajos que Praat y perdiendo por completo las transiciones entre las voces masculinas y femeninas, así como entre el habla emocional y no emocional.
YAAPT recortó un tono muy alto en el discurso emocional femenino, pero en general se las arregló claramente mejor. Debido a sus características específicas, YAAPT funciona mejor: es imposible responder de inmediato, por supuesto, pero se puede suponer que el papel se juega al obtener candidatos de tres fuentes y un cálculo más meticuloso de su peso que en YIN.
ConclusiónDado que la cuestión de determinar la frecuencia del tono fundamental (F0) de una forma u otra surge antes que casi todos los que trabajan con sonido, hay muchas maneras de resolverlo. La cuestión de la precisión y las características necesarias del material de audio en cada caso determinan cuán cuidadosamente es necesario seleccionar los parámetros, o en otro caso, puede restringirse a una solución básica como YAAPT. Tomando Praat como el estándar del algoritmo para el procesamiento del habla (sin embargo, un gran número de investigadores lo usa), podemos concluir que YAAPT es, en primera aproximación, más confiable y preciso que YIN, aunque nuestro ejemplo resultó ser complicado para él.
Publicado por
Eva Kazimirova , investigadora del laboratorio de Neurodata, especialista en procesamiento del habla.
Offtop : ¿Te gusta el artículo? De hecho, tenemos muchas tareas interesantes en ML, matemáticas y programación, y necesitamos cerebros. ¿Estás interesado en esto? Ven a nosotros! Correo electrónico: hr@neurodatalab.com
Referencias- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Mediciones acústicas cuantitativas para la caracterización de trastornos del habla y la voz en la enfermedad de Parkinson temprana no tratada. The Journal of the Acoustical Society of America, vol. 129, número 1 (2011), pp. 350-367. Acceso
- Farrús, M., Hernando, J., Ejarque, P. Jitter y Shimmer Measurements for Speaker Recognition. Actas de la Conferencia Anual de la International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Acceso
- Zahorian, S., Hu, HA. Método espectral / temporal para un seguimiento de frecuencia fundamental robusto. The Journal of the Acoustical Society of America, vol. 123, número 6 (2008), pp. 4559-4571. Acceso
- De Cheveigné, A., Kawahara, H. YIN, un estimador de frecuencia fundamental para el habla y la música. The Journal of the Acoustical Society of America, vol. 111, número 4 (2002), pp. 1917-1930. Acceso