
Los "patrones" en el contexto de C ++ generalmente se refieren a construcciones de lenguaje muy específicas. Hay plantillas simples que simplifican el trabajo con el mismo tipo de código; estas son plantillas de clase y función. Si una plantilla tiene uno de los parámetros por sí mismo, entonces se puede decir que son plantillas de segundo orden y generan otras plantillas dependiendo de sus parámetros. Pero, ¿qué pasa si sus capacidades no son suficientes y más fáciles de generar de inmediato el texto fuente? ¿Mucho código fuente?
Los fanáticos de Python y los diseños HTML están familiarizados con una herramienta (motor, biblioteca) para trabajar con plantillas de texto llamada
Jinja2 . En la entrada, este motor recibe un archivo de plantilla en el que el texto se puede mezclar con estructuras de control, la salida es texto claro en el que todas las estructuras de control se reemplazan con texto de acuerdo con los parámetros especificados desde el exterior (o desde el interior). En términos generales, esto es algo así como páginas ASP (o C ++ - preprocesador), solo el lenguaje de marcado es diferente.
Hasta ahora, la implementación de este motor ha sido solo para Python. Ahora es para C ++. Sobre cómo y por qué sucedió, y será discutido en el artículo.
¿Por qué incluso tomé esto?
De hecho, ¿por qué? Después de todo, hay Python, para ello: una excelente implementación, un montón de características, una especificación completa para el lenguaje. ¡Toma y usa! No me gusta Python: puede tomar
Jinja2CppLight o
inja , puertos parciales Jinja2 en C ++. Al final, puede tomar el puerto C ++ {{
Moustache }}. El diablo, como siempre, en los detalles. Entonces, digamos, necesitaba la funcionalidad de los filtros de Jinja2 y las capacidades de la construcción extendida, que le permite crear plantillas extensibles (y también macros e incluir, pero esto más adelante). Y ninguna de las implementaciones mencionadas admite esto. ¿Podría prescindir de todo esto? También una buena pregunta. Juzga por ti mismo. Tengo un
proyecto cuyo objetivo es crear C ++ - a-C ++ generador de código repetitivo. Este generador automático recibe, por ejemplo, un archivo de encabezado escrito manualmente con estructuras o enumeraciones, y genera en función de él funciones de serialización / deserialización o, por ejemplo, convertir elementos de enumeración en cadenas (y viceversa). Puede escuchar más detalles sobre esta utilidad en mis informes
aquí (eng) o
aquí (rus).
Entonces, una tarea típica resuelta en el proceso de trabajar en la utilidad es la creación de archivos de encabezado, cada uno de los cuales tiene un encabezado (con ifdefs e incluye), un cuerpo con los contenidos principales y un pie de página. Además, el contenido principal son las declaraciones generadas repletas de espacio de nombres. En la ejecución de C ++, el código para crear dicho archivo de encabezado se parece a esto (y eso no es todo):
Mucho código C ++void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
Desde aquí Además, este código cambia poco de un archivo a otro. Por supuesto, puede usar el formato clang para formatear. Pero esto no cancela el resto del trabajo manual sobre la generación del texto fuente.
Y luego, un buen momento, me di cuenta de que mi vida debería simplificarse. No consideré la opción de atornillar un lenguaje de script completo debido a la complejidad de apoyar el resultado final. Pero para encontrar un motor de plantillas adecuado, ¿por qué no? Me resultó útil buscar, lo encontré, luego encontré la especificación Jinja2 y me di cuenta de que esto es exactamente lo que necesito. De acuerdo con esta especificación, las plantillas para generar encabezados se verían así:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
Desde aquí
Solo había un problema: ninguno de los motores que encontré admitía todo el conjunto de características que necesitaba. Bueno, por supuesto, todos tenían un
defecto fatal estándar. Pensé un poco y decidí que otro mundo no empeoraría con otra implementación del motor de plantillas. Además, según las estimaciones, la funcionalidad básica no era tan difícil de implementar. Después de todo, ¡ahora en C ++ hay expresiones regulares!
Y así
surgió el proyecto
Jinja2Cpp . A expensas de la complejidad de implementar la funcionalidad básica (muy básica), casi adiviné. En general, omití exactamente el coeficiente de Pi al cuadrado: me llevó un poco menos de tres meses escribir todo lo que necesitaba. Pero cuando todo estuvo terminado, terminado e insertado en el "Programador automático", me di cuenta de que intenté no en vano. De hecho, la utilidad de generación de código recibió un poderoso lenguaje de scripting combinado con plantillas, lo que le abrió nuevas oportunidades de desarrollo.
NB: Tuve una idea para sujetar Python (o Lua). Pero ninguno de los motores de secuencias de comandos existentes resuelve problemas "listos para usar" en la generación de texto a partir de plantillas. Es decir, Python aún tendría que atornillar el mismo Jinja2, pero para Lua, busque algo diferente. ¿Por qué necesitaba este enlace adicional?
Implementación del analizador
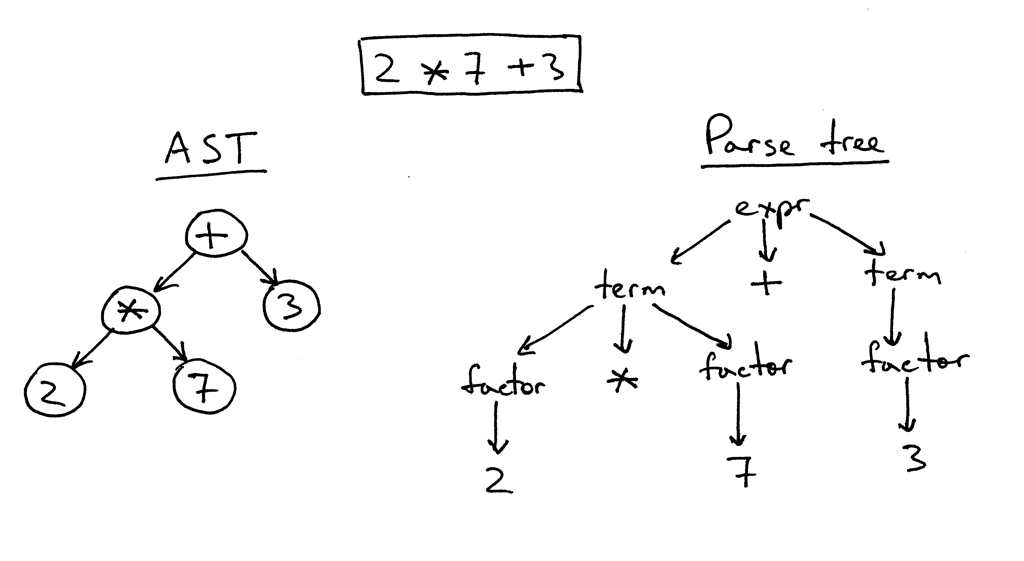
La idea detrás de la estructura de las plantillas Jinja2 es bastante simple. Si hay algo en el texto encerrado en un par de "{{" / "}}", entonces esto es "algo", una expresión que debe evaluarse, convertirse en una representación de texto e insertarse en el resultado final. Dentro del par "{%" / "%}" hay operadores como for, if, set, etc. Bueno, en "{#" / "#}" hay comentarios. Después de estudiar la implementación de Jinja2CppLight, decidí que tratar de encontrar manualmente todas estas estructuras de control en el texto de la plantilla no era una muy buena idea. Por lo tanto, me armé con una expresión regular bastante simple: (((\ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \}) | (\ n)), con la ayuda de la cual partió el texto en los fragmentos necesarios. Y lo llamó la fase aproximada de análisis. En la etapa inicial del trabajo, la idea mostró su efectividad (sí, de hecho, todavía lo muestra), pero, en el buen sentido, tendrá que ser refactorizada en el futuro, ya que ahora se imponen restricciones menores en el texto de la plantilla: escapando pares "{{" y "}}" en el texto se procesa también "frente".
En la segunda fase, solo se analiza en detalle lo que está dentro de los "corchetes". Y aquí tuve que jugar. Con inja, con Jinja2CppLight, el analizador de expresiones es bastante simple. En el primer caso, en la misma expresión regular, en el segundo, escrito a mano, pero solo admite diseños muy simples. El soporte para filtros, probadores, aritmética compleja o indexación está fuera de discusión. Y era precisamente estas características de Jinja2 lo que más quería. Por lo tanto, no tuve otra opción que alterar un analizador LL (1) completo (en algunos lugares, sensible al contexto) que implementa la gramática necesaria. Hace unos diez o quince años, probablemente tomaría Bison o ANTLR para esto e implementaría un analizador con su ayuda. Hace unos siete años, hubiera probado Boost.Spirit. Ahora acabo de implementar el analizador que necesito, trabajando mediante el método de descenso recursivo, sin generar dependencias innecesarias y aumentar significativamente el tiempo de compilación, como sucedería si se utilizaran utilidades externas o Boost.Spirit. En la salida del analizador, obtengo un AST (para expresiones o para operadores), que se guarda como una plantilla, listo para su posterior representación.
Un ejemplo de lógica de análisis ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
Desde aquí Fragmento de clases de árbol de expresión AST class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
Desde aquí Clases de ejemplo de operadores de árbol AST struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
Desde aquí Los nodos AST se asocian solo con el texto de la plantilla y se convierten en valores totales en el momento de la representación, teniendo en cuenta el contexto de representación actual y sus parámetros. Esto nos permitió hacer patrones seguros para subprocesos. Pero más sobre esto en términos de la representación real.
Como el tokenizador principal, elegí la biblioteca
lexertk . Tiene la licencia que necesito y solo encabezado. Es cierto que tuve que cortar todas las campanas y silbatos del cálculo del equilibrio de los corchetes, etc., y dejar solo el tokenizador en sí, que (después de enderezar un poco con un archivo) aprendió a trabajar no solo con caracteres char, sino también con caracteres wchar_t. Además de este tokenizador, incluí otra clase que realiza tres funciones principales: a) abstrae el código del analizador del tipo de caracteres con los que estamos trabajando, b) reconoce las palabras clave específicas de Jinja2 yc) proporciona una interfaz conveniente para trabajar con el flujo de tokens:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
Desde aquí Por lo tanto, a pesar de que el motor puede funcionar con char y wchar_t-templates, el código de análisis principal no depende del tipo de carácter. Pero más sobre esto en la sección sobre aventuras con tipos de personajes.
Por separado, tuve que jugar con las estructuras de control. En Jinja2, muchos de ellos están emparejados. Por ejemplo, for / endfor, if / endif, block / endblock, etc. Cada elemento del par va en sus propios "corchetes", y entre los elementos puede haber un montón de todo: solo texto sin formato y otros bloques de control. Por lo tanto, el algoritmo para analizar la plantilla tenía que hacerse sobre la base de la pila, al elemento superior actual del cual todas las construcciones e instrucciones recién encontradas, así como fragmentos de texto simple entre ellas, "se adhieren". Usando la misma pila, se verifica la ausencia de desequilibrio del tipo if-for-endif-endfor. Como resultado de todo esto, el código resultó no ser tan "compacto" como, por ejemplo, Jinja2CppLight (o inja), donde toda la implementación está en una fuente (o encabezado). Pero la lógica de análisis y, de hecho, la gramática en el código son más claramente visibles, lo que simplifica su soporte y extensión. Al menos eso es lo que buscaba. Todavía no es posible minimizar la cantidad de dependencias o la cantidad de código, por lo que debe hacerlo más comprensible.
En la
siguiente parte, hablaremos sobre el proceso de renderización de plantillas, pero por ahora - enlaces:
Especificación de Jinja2:
http://jinja.pocoo.org/docs/2.10/templates/Implementación de Jinja2Cpp:
https://github.com/flexferrum/Jinja2CppImplementación de Jinja2CppLight:
https://github.com/hughperkins/Jinja2CppLightImplementación lesionada:
https://github.com/pantor/injaUtilidad para generar código basado en plantillas Jinja2:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor