En los últimos dos artículos, hablamos sobre IIoT, el Internet industrial de las cosas, construyó una arquitectura para recibir datos de los sensores y soldar los sensores. La piedra angular de las arquitecturas IIoT y, de hecho, de cualquier arquitectura que trabaje con BigData es el procesamiento de flujo de datos. Se basa en el concepto de mensajería y colas. El estándar para trabajar con la mensajería se ha convertido en Apache Kafka. Sin embargo, para comprender sus ventajas (y comprender sus desventajas) sería bueno comprender los conceptos básicos de la operación de los sistemas de colas en general, sus mecanismos de operación, patrones de uso y funcionalidad básica.

Encontramos una excelente serie de artículos que compara la funcionalidad de Apache Kafka y otro gigante (inmerecidamente ignorado) entre los sistemas de colas: RabbitMQ. Hemos traducido esta serie de artículos, les hemos proporcionado comentarios y los hemos complementado. Aunque la serie fue escrita en diciembre de 2017, el mundo de los sistemas de mensajería (y especialmente Apache Kafka) está cambiando tan rápidamente que para el verano de 2018, algunas cosas han cambiado.
Fuente
RabbitMQ vs Kafka
La mensajería es la parte central de muchas arquitecturas, y los dos pilares en esta área son RabbitMQ y Apache Kafka. Hasta la fecha, Apache Kafka se ha convertido en un estándar casi industrial en procesamiento de datos y análisis, por lo que en esta serie analizaremos más de cerca a RabbitMQ y Kafka en el contexto de su uso en infraestructuras en tiempo real.
Apache Kafka ahora está en aumento, pero parece que comenzaron a olvidarse de RabbitMQ. Todo el bombo se centró en Kafka, y esto sucede por razones obvias, pero RabbitMQ sigue siendo una gran opción para la mensajería. Una de las razones por las que Kafka ha centrado su atención en sí mismo es su obsesión general con la escalabilidad, y obviamente Kafka es más escalable que RabbitMQ, pero a la mayoría de nosotros no nos preocupa la escala en la que RabbitMQ tiene problemas. La mayoría de nosotros no somos Google o Facebook. La mayoría de nosotros tratamos con volúmenes diarios de mensajes de cientos de miles a cientos de millones, y no con volúmenes de miles de millones a billones (pero, por cierto, hay casos en que las personas escalan RabbitMQ a miles de millones de mensajes diarios).
Por lo tanto, en nuestra serie de artículos no hablaremos de casos en los que se requiere una escalabilidad extrema (y esta es la prerrogativa de Kafka), sino que nos centraremos en las ventajas únicas que ofrece cada uno de los sistemas en consideración. Curiosamente, cada sistema tiene sus propias ventajas, pero al mismo tiempo son bastante diferentes entre sí. Por supuesto, escribí mucho sobre RabbitMQ, pero le aseguro que no le doy ninguna preferencia particular. Me gustan las cosas bien hechas, y RabbitMQ y Kafka son sistemas de mensajería bastante maduros, confiables y, sí, escalables.
Comenzaremos en el nivel superior y luego comenzaremos a estudiar los diversos aspectos de estas dos tecnologías. Esta serie de artículos está dirigida a profesionales involucrados en la organización de sistemas de mensajería o arquitectos / ingenieros que desean comprender los detalles del nivel inferior y su aplicación. No escribiremos código, sino que nos centraremos en la funcionalidad que ofrecen ambos sistemas, las plantillas de proceso de mensajería que ofrece cada uno de ellos y las decisiones que deben tomar los desarrolladores y arquitectos de decisiones.
En esta parte, veremos qué son RabbitMQ y Apache Kafka, y su enfoque para la mensajería. Ambos sistemas abordan la arquitectura de mensajería desde diferentes ángulos, cada uno de los cuales tiene fortalezas y debilidades. En este capítulo, no llegaremos a ninguna conclusión importante; en cambio, proponemos tomar este artículo como un manual de tecnología para principiantes, para que podamos profundizar en los próximos artículos de la serie.
Rabbitmq
RabbitMQ es un sistema de gestión de colas de mensajes distribuidos. Distribuido, porque generalmente funciona como un grupo de nodos, donde las colas se distribuyen entre los nodos y, opcionalmente, se replican para ser resistentes a errores y de alta disponibilidad. Regularmente, implementa AMQP 0.9.1 y ofrece otros protocolos, como STOMP, MQTT y HTTP a través de módulos adicionales.
RabbitMQ utiliza enfoques de mensajería clásicos e innovadores. Clásico en el sentido de que se centra en la cola de mensajes e innovador, en la posibilidad de enrutamiento flexible. Esta característica de enrutamiento es su ventaja única. Crear un sistema de mensajería distribuido rápido, escalable y confiable es un logro en sí mismo, pero la funcionalidad de enrutamiento de mensajería lo hace verdaderamente sobresaliente entre muchas tecnologías de mensajería.
Intercambio y colas
Revisión súper simplificada:
- Los editores (editores) envían mensajes a los intercambios
- Exchange'i envío mensajes en colas y a otros intercambios
- RabbitMQ envía confirmaciones a los editores al recibir un mensaje
- Los destinatarios (consumidores) mantienen conexiones TCP persistentes a RabbitMQ y anuncian qué cola (s) reciben
- RabbitMQ envía mensajes a los destinatarios
- Los destinatarios envían confirmaciones de éxito / error
- Tras la recepción exitosa, los mensajes se eliminan de las colas.
Esta lista contiene una gran cantidad de decisiones que los desarrolladores y administradores deben tomar para obtener las garantías de entrega que necesitan, las características de rendimiento, etc., de las cuales hablaremos más adelante.
Veamos un ejemplo de trabajo con un editor, intercambio, cola y receptor:

Fig. 1. Un editor y un destinatario
Qué hacer si tiene varios editores de la misma
mensajes? ¿Qué pasa si tenemos varios destinatarios, cada uno de los cuales quiere recibir todos los mensajes?

Fig. 2. Varios editores, varios destinatarios independientes
Como puede ver, los editores envían sus mensajes al mismo intercambiador, que envía cada mensaje en tres colas, cada una de las cuales tiene un destinatario. En el caso de RabbitMQ, las colas permiten que diferentes destinatarios reciban todos los mensajes. Compare con el cuadro a continuación:
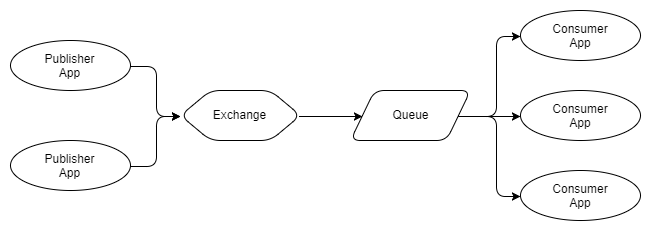
Fig. 3. Múltiples editores, una cola con múltiples destinatarios competidores
En la Figura 3, vemos tres destinatarios que usan la misma cola. Estos son destinatarios competidores, es decir, compiten para recibir mensajes de la cola. Por lo tanto, se puede esperar que, en promedio, cada destinatario reciba un tercio de los mensajes en la cola. Usamos destinatarios competidores para escalar nuestro sistema de procesamiento de mensajes, y usar RabbitMQ es muy simple para hacer esto: agregar o eliminar destinatarios a pedido. No importa cuántos destinatarios competidores tenga, RabbitMQ solo entregará mensajes a un destinatario.
Podemos combinar arroz. 2 y 3 para recibir múltiples conjuntos de destinatarios competidores, donde cada conjunto recibe cada mensaje.

Fig. 4. Varios editores, varias colas con destinatarios competidores.
Las flechas entre intercambiadores y colas se denominan enlaces, y hablaremos más sobre ellos con más detalle.
Garantías
RabbitMQ ofrece garantías de "entrega única" y "al menos una entrega", pero no "exactamente una entrega".
Nota del traductor: antes de la versión 0.11 de Kafka, la entrega del mensaje de entrega exactamente una vez no estaba disponible; actualmente, una funcionalidad similar está presente en Kafka.
Los mensajes se entregan en el orden en que llegan a la cola (después de todo, esta es la definición de la cola). Esto no garantiza que la finalización del procesamiento de mensajes coincida con el mismo pedido cuando tiene destinatarios competidores. Este no es un error de RabbitMQ, sino la realidad fundamental del procesamiento paralelo de un conjunto ordenado de mensajes. Este problema se puede resolver utilizando el intercambio de hash coherente, como verá en el próximo capítulo sobre plantillas y topologías.
Empujar y buscar previamente a los destinatarios
RabbitMQ envía mensajes a los destinatarios (también hay una API para extraer mensajes de RabbitMQ, pero esta funcionalidad está en desuso en este momento). Esto puede abrumar a los destinatarios si los mensajes llegan a la cola más rápido de lo que los destinatarios pueden procesarlos. Para evitar esto, cada destinatario puede establecer un límite de captación previa (también conocido como límite de QoS). De hecho, el límite de QoS es un límite en la cantidad de mensajes que el destinatario no ha reconocido. Actúa como un fusible cuando el receptor comienza a retrasarse.
¿Por qué se decidió que los mensajes en la cola se envían (push) y no se descargan (pull)? En primer lugar, porque hay menos tiempo de retraso. En segundo lugar, idealmente, cuando tenemos destinatarios competidores de la misma cola, queremos distribuir uniformemente la carga entre ellos. Si cada destinatario solicita / descarga mensajes, según la cantidad que solicite, la distribución del trabajo puede volverse bastante desigual. Cuanto más desigual es la distribución de los mensajes, mayor es la demora y una mayor pérdida del orden de los mensajes durante el procesamiento. Estos factores orientan la arquitectura RabbitMQ hacia un mecanismo de inserción de un mensaje a la vez. Esta es una de las limitaciones de escalar RabbitMQ. La limitación se mitiga por el hecho de que las confirmaciones se pueden agrupar.
Enrutamiento
Los intercambios son básicamente enrutadores de mensajes para colas y / u otros intercambios. Para que un mensaje se mueva de un intercambio a una cola o a otro intercambio, es necesario vincularlo. Diferentes intercambios requieren diferentes enlaces. Hay cuatro tipos de intercambios y enlaces asociados:
- Fanout Dirige a todas las colas e intercambiadores obligados a intercambiar el submodelo estándar de Pub.
- Directo (directo). Enruta los mensajes en función de la clave de enrutamiento que lleva el mensaje, establecida por el editor. La clave de enrutamiento es una cadena corta. Los intercambiadores directos envían mensajes a / intercambian colas que tienen una clave de emparejamiento que coincide exactamente con la clave de enrutamiento.
- Tema (temático). Enruta mensajes basados en la clave de enrutamiento, pero permite el uso de coincidencias incompletas (comodines).
- Encabezado (encabezado). RabbitMQ le permite agregar encabezados de destinatario a los mensajes. Los intercambios de encabezado envían mensajes de acuerdo con estos valores de encabezado. Cada enlace incluye una coincidencia exacta de los valores del encabezado. Puede agregar múltiples valores al enlace con CUALQUIERA o TODOS los valores necesarios para coincidir.
- Hashing consistente. Este es un intercambiador que codifica una clave de enrutamiento o un encabezado de mensaje, y envía solo en una cola. Esto es útil cuando necesita cumplir con las garantías de órdenes de procesamiento y aún así poder escalar destinatarios.

Fig. 5. Ejemplo de intercambio de temas
También consideraremos el enrutamiento con más detalle, pero el ejemplo de intercambio de temas se da arriba. En este ejemplo, los editores publican registros de errores utilizando el formato de clave de enrutamiento LEVEL (Nivel de error) .AppName.
La cola 1 recibirá todos los mensajes porque usa un número comodín con varias palabras.
La cola 2 recibirá cualquier nivel de registro de la aplicación ECommerce.WebUI. Utiliza comodines *, capturando así el nivel de un nombre de tema único (ERROR.Ecommerce.WebUI, NOTICE.ECommerce.WebUI, etc.).
La cola 3 mostrará todos los mensajes de ERROR de cualquier aplicación. Utiliza el comodín # para cubrir todas las aplicaciones (ERROR.ECommerce.WebUi, ERROR.SomeApp.SomeSublevel, etc.).
Gracias a cuatro métodos de enrutamiento de mensajes y con la capacidad de intercambiar mensajes para enviar mensajes a otros intercambios, RabbitMQ le permite utilizar un conjunto poderoso y flexible de plantillas de intercambio de mensajes. Además, hablaremos sobre intercambios con intercambios de letras muertas, sobre intercambios y colas sin datos (intercambios y colas efímeras), y RabbitMQ ampliará todo su potencial.
Intercambio no entregado
Nota del traductor: cuando los mensajes de la cola no se pueden recibir por una razón u otra (el poder del consumidor no es suficiente, problemas de red, etc.), se pueden retrasar y procesar por separado.
Podemos configurar colas para que los mensajes se envíen a intercambiar en las siguientes condiciones:
- La cola excede el número especificado de mensajes.
- La cola excede el número especificado de bytes.
- El tiempo de transmisión del mensaje (TTL) ha expirado. El editor puede establecer la duración del mensaje, y la cola también puede tener un TTL especificado para el mensaje. En este caso, se utilizará un TTL más corto de los dos.
Creamos una cola que está destinada a intercambios con mensajes no entregados, y estos mensajes se almacenan allí hasta que se tomen medidas.
Al igual que muchas funciones de RabbitMQ, los intercambios con mensajes que no se pueden entregar hacen posible el uso de plantillas que no se proporcionaron originalmente. Podemos utilizar mensajes TTL e intercambios con mensajes no entregados para implementar colas diferidas y reintentar colas.
Intercambiadores y colas sin datos
Los intercambios y las colas se pueden crear dinámicamente, y puede establecer criterios para su eliminación automática. Esto permite el uso de patrones como los RPC basados en mensajes.
Módulos adicionales
El primer complemento que probablemente desee instalar es el complemento de administración, que proporciona un servidor HTTP con una interfaz web y una API REST. Es muy fácil de instalar y tiene una interfaz fácil de usar. La implementación de scripts a través de la API REST también es muy simple.
Además
- Intercambio de hash constante, intercambio de fragmentación y más
- protocolos como STOMP y MQTT
- ganchos web
- tipos adicionales de intercambiadores
- Integración SMTP
Hay muchas otras cosas que se pueden decir sobre RabbitMQ, pero este es un buen ejemplo que le permite describir lo que RabbitMQ puede hacer. Ahora nos fijamos en Kafka, que utiliza un enfoque completamente diferente para la mensajería y, al mismo tiempo, también tiene su propio conjunto de características distintivas e interesantes.
Apache kafka
Kafka es un registro de confirmación replicado distribuido. Kafka no tiene un concepto de colas, lo que puede parecer extraño al principio, dado que se usa como un sistema de mensajería. Las colas han sido durante mucho tiempo sinónimos de sistemas de mensajería. Primero, veamos qué significa un "registro de confirmación de cambios distribuido y replicado":
- Distribuido porque Kafka se implementa como un grupo de nodos, tanto para tolerancia a errores como para escalado
- Replicado, ya que los mensajes generalmente se replican en múltiples nodos (servidores).
- Un registro de confirmación porque los mensajes se almacenan en registros segmentados de solo apéndice llamados temas. Este concepto de registro es la principal ventaja única de Kafka.
Comprender el diario (y el tema) y las particiones es la clave para entender Kafka. Entonces, ¿cómo difiere un registro particionado de un conjunto de colas? Imaginemos cómo se ve.
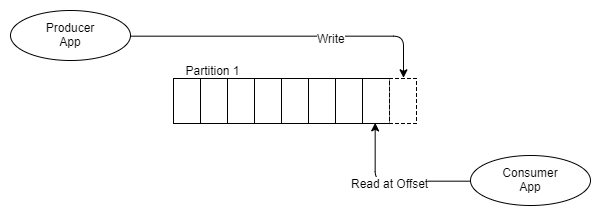
Fig. 6 Un productor, un segmento, un destinatario
En lugar de poner mensajes en la cola FIFO y monitorear el estado de este mensaje en la cola, como lo hace RabbitMQ, Kafka simplemente lo agrega al registro, y eso es todo.
El mensaje permanece, independientemente de si se recibe una o más veces. Se elimina de acuerdo con la política de retención, también llamada período de tiempo de ventana. ¿Cómo se toma la información del tema?
Cada destinatario realiza un seguimiento de dónde se encuentra en el registro: hay un puntero al último mensaje recibido y este puntero se denomina dirección de desplazamiento. Los destinatarios admiten esta dirección a través de las bibliotecas del cliente y, según la versión de Kafka, la dirección se almacena en ZooKeeper o en Kafka.
Una característica distintiva del modelo de registro en diario es que elimina instantáneamente muchas dificultades con respecto al estado de la entrega de mensajes y, lo que es más importante para los destinatarios, les permite rebobinar, devolver y recibir mensajes en la dirección relativa anterior. Por ejemplo, imagine que está implementando un servicio que emite facturas que tienen en cuenta los pedidos realizados por los clientes. El servicio tiene un error y no calcula correctamente todas las facturas en 24 horas. Con RabbitMQ en el mejor de los casos, deberá volver a publicar estos pedidos de alguna manera solo en el servicio de la cuenta. Pero con Kafka, simplemente mueve la dirección relativa de este destinatario hace 24 horas.
Entonces, veamos cómo se ve cuando hay un tema en el que hay una partición y dos destinatarios, cada uno de los cuales debe recibir cada mensaje.

Fig. 7. Un productor, una partición, dos receptores independientes.
Como se puede ver en el diagrama, dos destinatarios independientes reciben la misma partición, pero leen en diferentes direcciones de desplazamiento. Quizás el servicio de facturación tarda más en procesar los mensajes que el servicio de notificaciones push. o tal vez el servicio de facturación no estuvo disponible por algún tiempo e intentó ponerse al día más tarde. O tal vez hubo un error, y la dirección de compensación tuvo que posponerse durante varias horas.
Ahora suponga que el servicio de facturación debe dividirse en tres partes, porque no puede mantenerse al día con la velocidad del mensaje. Con RabbitMQ, simplemente implementamos dos aplicaciones de servicios de facturación más que se obtienen de la cola de facturación. Pero Kafka no admite receptores competidores en la misma partición; el bloque de concurrencia de Kafka es la partición misma. Por lo tanto, si necesitamos tres destinatarios de facturas, necesitamos al menos tres particiones. Entonces ahora tenemos:
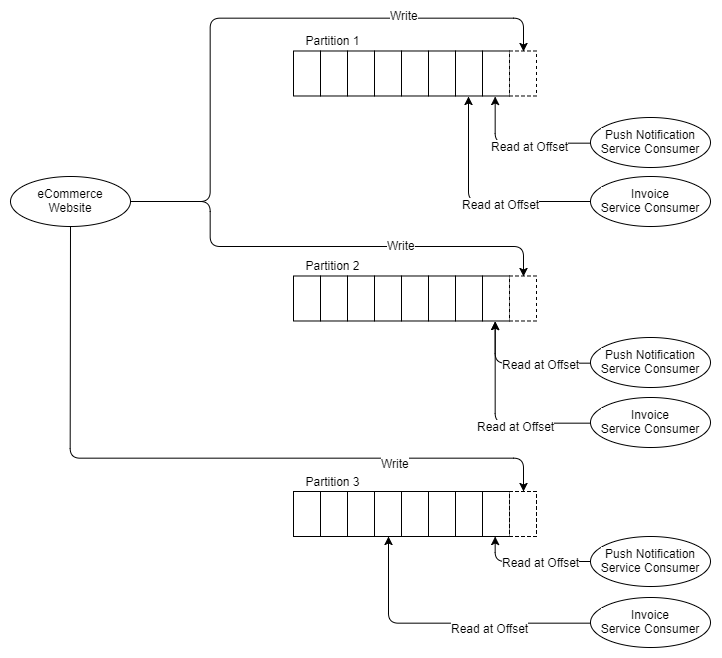
Fig. 8. Tres particiones y dos grupos de tres destinatarios.
Por lo tanto, se entiende que necesita al menos tantas particiones como el destinatario horizontal más escalado. Hablemos un poco sobre las particiones.
Particiones y grupos de destinatarios
Cada partición es un archivo separado en el que se garantiza la secuencia de mensajes. Es importante recordar esto: el orden de los mensajes está garantizado en una sola partición. En el futuro, esto puede llevar a cierta contradicción entre los requisitos para la cola de mensajes y los requisitos de rendimiento, ya que el rendimiento en Kafka también se escala por particiones. La partición no puede admitir destinatarios competidores, por lo que nuestra aplicación de facturación solo puede usar una parte para cada sección.
Los mensajes se pueden redirigir a segmentos mediante un algoritmo cíclico o mediante una función hash: hash (clave de mensaje)% número de particiones. , , , , , , . .
RabbitMQ. . , RabbitMQ , . , .
RabbitMQ . Kafka , .
, , Kafka , RabbitMQ — . RabbitMQ , . Kafka , . , , Kafka , .
, , , ( ). , , . , , , .
RabbitMQ — Consistent Hashing exchange, . Kafka' , Kafka , , , , , -. RabbitMQ , , , .
: , , Id 1000 , Id 1000 . , , . , .
(push) (pull)
RabbitMQ (push) , , . RabbitMQ . , Kafka (pull), . , , Kafka long-polling.
(pull) Kafka - . Kafka , , .
RabbitMQ, , , , . Kafka , .
Kafka /» , , . , .
Fig. 9.
, , Kafka :
. 10. ,

, :

Fig. 11.
, , .
, , , , .

Fig. 12.
. .

:
, . , , .
Kafka – , , , , , . . , . , , .
— . , 50 . – . , , , .
, , . , , . , . , , , .
. , , .
, RabbitMQ, Kafka, Kafka . RabbitMQ , , ZooKeeper Consul.
RabbitMQ , Kafka. RabbitMQ, , . : .
. , . . , . . . , , - .
, Kafka, . . , , .
, . RabbitMQ , Kafka .
Conclusiones
RabbitMQ , . , , . , . , , .
Kafka . , . Kafka , RabbitMQ . , Kafka , RabbitMQ, , .
RabbitMQ.
, , IoT , . : t.me/justiothings