Habr, hola! Esta es una transcripción del informe de Artyom ximaera Gavrichenkov, que leyó en BackendConf 2018 como parte del festival RIT ++.

- hola
El título del informe contiene una larga lista de protocolos, lo revisaremos gradualmente, pero comencemos con lo que no está en el título.
Este encabezado (bajo el corte) de uno de los blogs, en Internet se pueden ver muchos de esos encabezados. En esa publicación está escrito que HTTP / 2 no es un futuro lejano, es nuestro presente; Este es un protocolo moderno desarrollado por Google y cientos de profesionales de muchas compañías avanzadas, lanzado por el IETF como RFC en 2015, es decir, hace ya 3 años.
Los estándares IETF son aceptados por la industria, como los documentos de hormigón armado, como una lápida, de hecho.

Está previsto que determinen el desarrollo de Internet y tengan en cuenta todos los posibles escenarios de uso. Es decir, si teníamos una versión anterior del protocolo y luego aparecía una nueva, definitivamente mantiene la compatibilidad con todos los casos de usuarios anteriores y, además, resuelve un montón de problemas, optimiza el trabajo, etc.
HTTP / 2 tuvo que ser adaptado para la web avanzada, listo para su uso en servicios y aplicaciones modernos, de hecho, sería
un reemplazo directo para las versiones anteriores del protocolo HTTP. Se suponía que aumentaría el rendimiento del sitio, al tiempo que reduciría la carga del backend.

Incluso los SEO dijeron que necesitaban HTTP / 2.

Y parecía ser muy fácil de soportar. En particular, Neil Craig de la BBC escribió en su blog que era suficiente para "simplemente habilitarlo" en el servidor. Todavía puede encontrar muchas presentaciones donde dice que HTTP / 2 se incluye de la siguiente manera: si tiene Nginx, entonces puede arreglar la configuración en un solo lugar; si no hay HTTPS, debe colocar un certificado adicionalmente; pero, en principio, se trata de un token en el archivo de configuración.
Y, por supuesto, después de registrar este token, inmediatamente comienza a recibir bonos de mayor productividad, nuevas funciones disponibles, oportunidades, en general, todo se vuelve maravilloso.
 Enlaces de la diapositiva:
Enlaces de la diapositiva:
1. medium.com/@DarkDrag0nite/how-http-2-reduces-server-cpu-and-bandwidth-10dbb8458feb
2.www.cloudflare.com/website-optimization/http2La historia adicional se basa en hechos reales. La compañía tiene algún servicio en línea que procesa entre 500 y 1000 solicitudes HTTP por segundo. Este servicio está bajo la protección DDoS de Cloudflare.
Hay muchos puntos de referencia que confirman que cambiar a HTTP / 2 reduce la carga en el servidor debido al hecho de que al cambiar a HTTP / 2, el navegador establece no 7 conexiones, sino una según el plan. Se esperaba que al cambiar a HTTP / 2 y la memoria utilizada se redujera, y el procesador se cargara menos.
Además, el blog de Cloudflare y el sitio web de Cloudflare sugieren habilitar HTTP / 2 con solo un clic. Pregunta: ¿Por qué no hacer esto?

El 1 de febrero de 2018, la compañía incluye HTTP / 2 con este botón en Cloudflare, y en Nginx local también lo incluye. Se recopilan los datos del mes. El 1 de marzo, se miden los recursos consumidos, y luego los sysops observan la cantidad de solicitudes en los registros que llegan a través de HTTP / 2 al servidor detrás de Cloudflare. La siguiente diapositiva será el porcentaje de solicitudes que llegaron al servidor a través de HTTP / 2. Levanta las manos, ¿quién sabe cuál será este porcentaje?
[De la audiencia: "1-2%!"]
- Cero. ¿Por qué motivo?
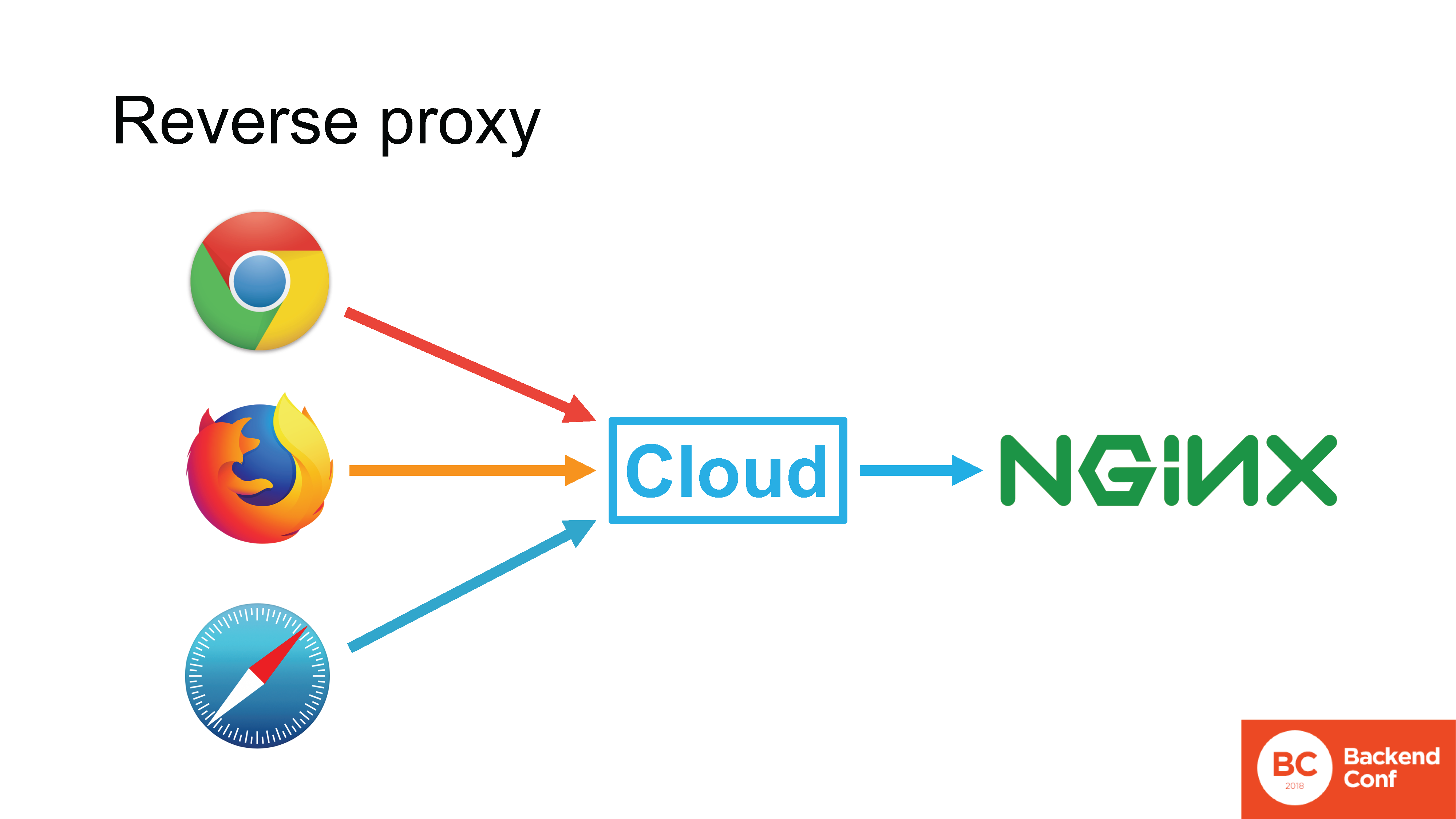
Cloudflare, así como otros servicios de protección contra ataques, MSSP y servicios en la nube, funcionan en modo
proxy inverso . Si en una situación normal el navegador se conecta directamente a su Nginx, es decir, la conexión va directamente del navegador a su servidor HTTP, entonces puede usar el protocolo que el navegador admite.
Si hay una nube entre el navegador y su servidor, la conexión TCP entrante se termina en la nube, TLS también se termina allí, y la solicitud HTTP primero va a la nube, luego la nube realmente procesa esta solicitud.
La nube tiene su propio servidor HTTP, en la mayoría de los casos el mismo Nginx, en casos excepcionales es un servidor "autoescrito". Este servidor analiza la solicitud, de alguna manera la procesa, consulta con cachés y, en última instancia, forma una nueva solicitud y ya la envía a su servidor utilizando el protocolo que admite.
Todas las nubes existentes que afirman ser compatibles con HTTP / 2 son compatibles con HTTP / 2 en el lado del navegador. Pero no lo apoyes de lado mirando hacia ti.
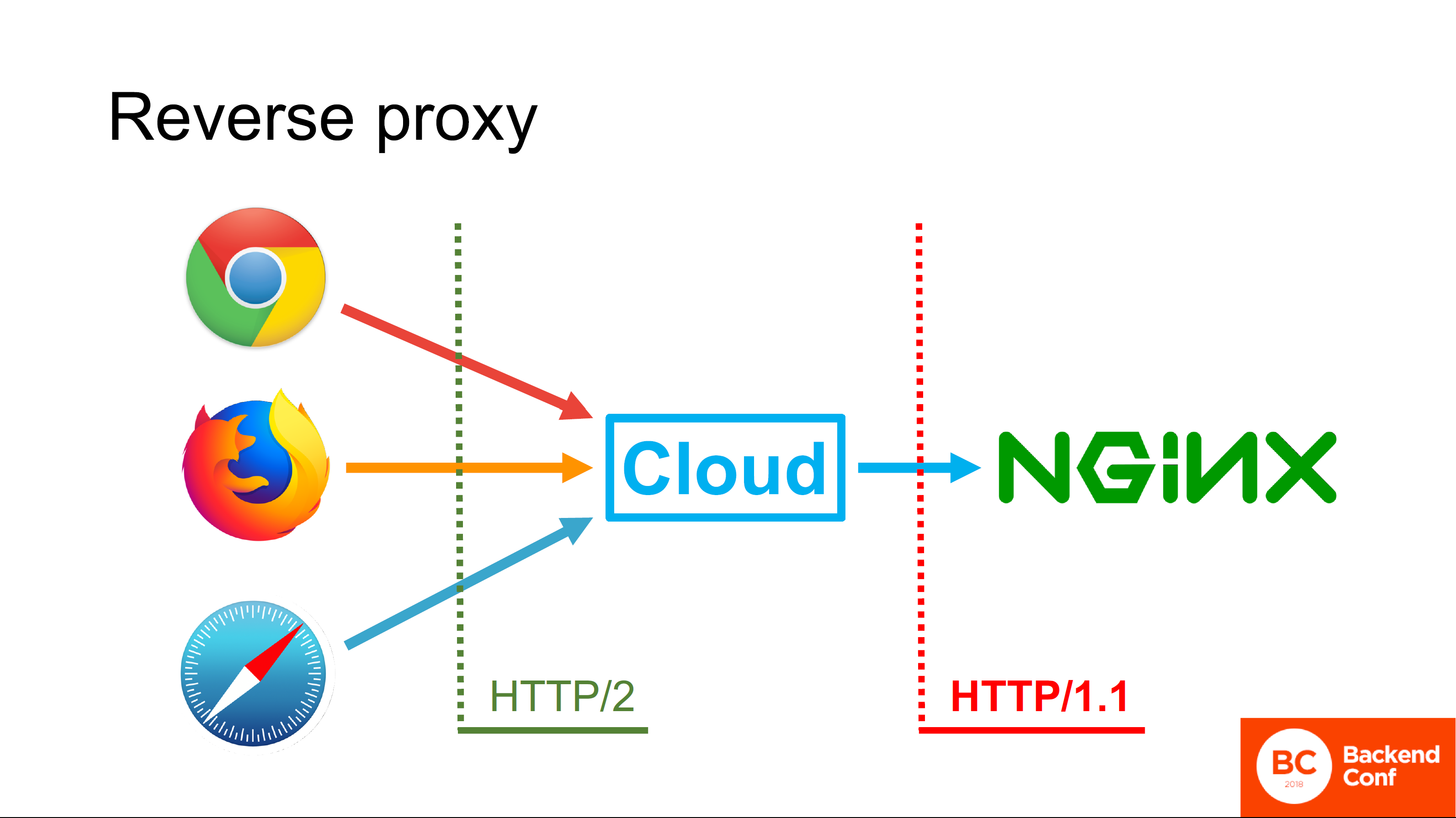
Por qué
Una respuesta simple y no del todo correcta: "Porque en la mayoría de los casos tienen Nginx implementado, y Nginx no puede pasar HTTP / 2 al flujo ascendente". De acuerdo, bueno, esta respuesta es
correcta , pero no
completa .

La respuesta completa nos la dan los ingenieros de Cloudflare. El hecho es que el enfoque de la especificación HTTP / 2, escrito y lanzado en 2015, era aumentar el rendimiento del navegador en casos de uso específicos, por ejemplo, para Google.
Google usa sus propias tecnologías, no usa el proxy inverso frente a sus servidores de producción, por lo que nadie pensó en el proxy inverso, y es por eso que no se usa HTTP / 2 desde la nube hacia arriba. De hecho, hay pocas ganancias, porque en el modo proxy inverso, por ejemplo, según lo descrito en el protocolo HTTP / 2, Server Push no es compatible, porque no está claro cómo debería funcionar si tenemos canalización.
El hecho de que HTTP / 2 guarde las conexiones es genial, pero el proxy inverso solo las guarda porque no abre una conexión por usuario. No tiene mucho sentido admitir HTTP / 2 aquí, y la sobrecarga y los problemas asociados con esto son grandes.

Lo que es importante: el proxy inverso es una tecnología que comenzó a usarse activamente hace unos 13 años. Es decir, esta es la tecnología de mediados de la década de 2000: fui a la escuela mientras ya estaba en uso. No se menciona en la norma emitida en 2015, no se admite, y el trabajo para apoyarla actualmente no se lleva a cabo en el grupo de trabajo httpbis en el IETF.
Este es un ejemplo de los problemas que surgen cuando las personas comienzan a implementar HTTP / 2. De hecho, cuando hablas con personas que se han implementado y que ya tienen algo de experiencia, escuchas constantemente las mismas palabras.

Fueron mejor formulados por Maxim Matyukhin de Badoo
en una publicación en Habré, donde habló sobre cómo funciona HTTP / 2 Server Push. Escribió que estaba muy sorprendido de cuán diferente era la interacción de esta funcionalidad particular con los navegadores,
porque pensó que era una característica completamente desarrollada, lista para usar en la producción . Ya he escuchado esta frase en relación con HTTP / 2 muchas veces: pensamos que era un protocolo de reemplazo directo, es decir, lo enciende y todo está bien, ¿por qué todo es tan complicado en la práctica, de dónde provienen todos estos problemas? y defectos?
Vamos a resolverlo.
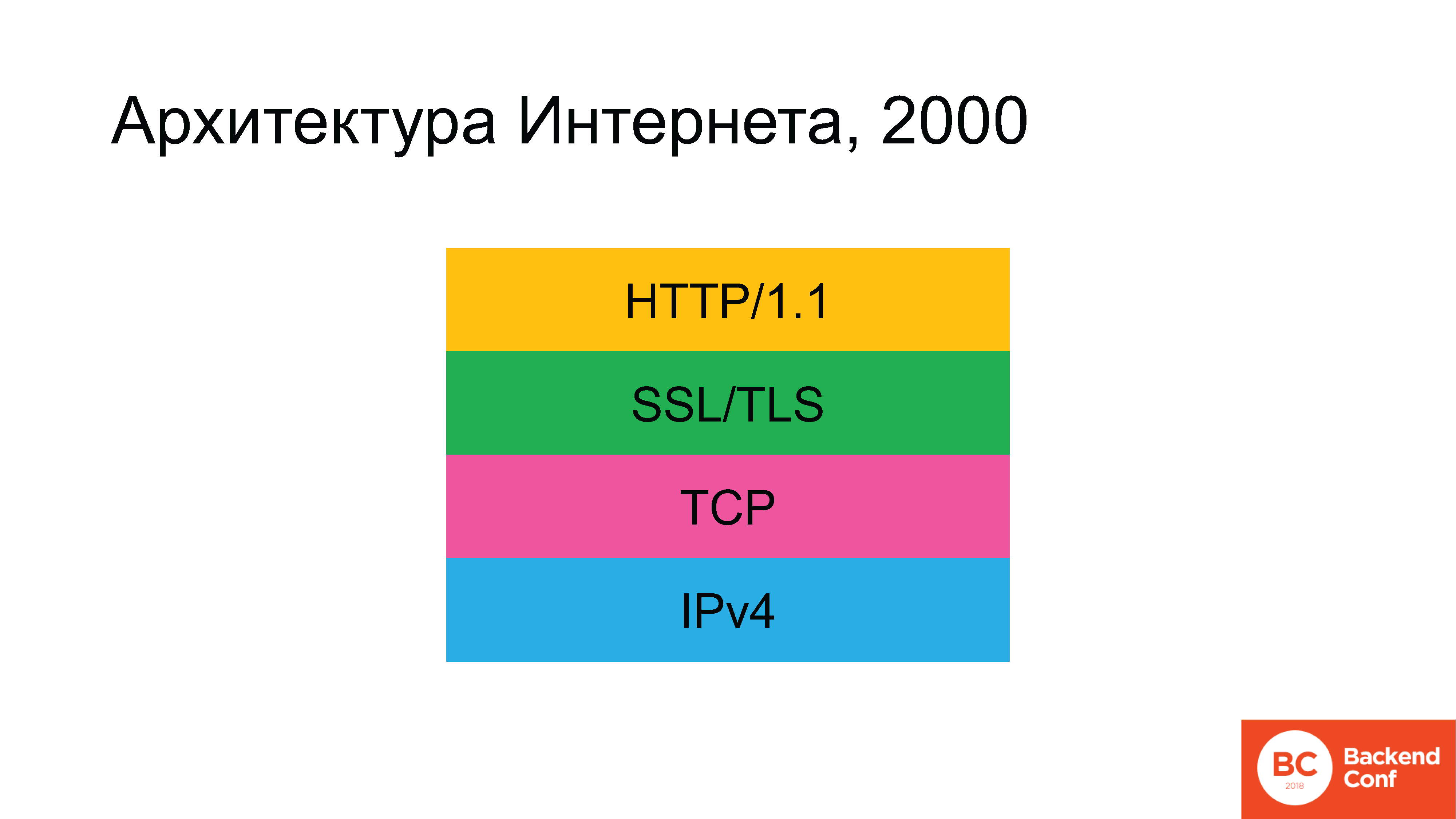
Históricamente, en la antigüedad, la arquitectura de Internet se parecía a esto. No había un rectángulo verde en algún momento, pero luego apareció.
Se utilizaron los siguientes protocolos: dado que estamos hablando de Internet y no de la red local, en el nivel inferior comenzamos con IPv4. Arriba, se usó el protocolo TCP o UDP, pero para el 90% de los casos (dado que el 80-90% del tráfico en Internet es la Web), luego TCP fue el siguiente, luego SSL (que luego fue reemplazado por TLS), y arriba estaba el hipertexto HTTP . Gradualmente, se desarrolló la situación de que, según el plan, para 2020 la arquitectura de Internet debería haber cambiado radicalmente.

IPv6 ha estado con nosotros durante mucho tiempo. TLS ha sido actualizado recientemente, aún discutiremos cómo sucedió esto. Y el protocolo HTTP / 2 también se ha actualizado.
El maravilloso escritor de ciencia ficción nacional Vadim Panov en el ciclo Enclaves tenía una
frase tan
maravillosa : “Estabas esperando el futuro. Quieres un futuro Ha llegado. ¿No lo querías? Ha llegado de todos modos. Lo único que permaneció prácticamente intacto, desde hace un par de años, es el protocolo TCP.
Las personas que se dedican al diseño de Internet, no pudieron pasar por una injusticia tan flagrante y decidieron lanzar el protocolo TCP también.
Bien, esto es, por supuesto, una broma. El problema no es solo que el protocolo es demasiado antiguo. Hay fallas en TCP. Fue especialmente preocupante para muchos que el protocolo HTTP / 2 ya estaba escrito, el estándar de 2015 ya se estaba implementando, pero no siempre funcionaba específicamente con TCP, y sería bueno poner algún otro transporte debajo, más adecuado para lo que una vez llamó a SPDY cuando se iniciaron esas conversaciones y luego a HTTP / 2.

El protocolo decidió llamar a QUIC. QUIC es un protocolo que se está desarrollando actualmente para el transporte. Se basa en UDP, es decir, es un protocolo de
datagrama . El primer borrador del estándar se lanzó en julio de 2016, y la versión borrador actual ...
[El orador revisa el correo en el teléfono]"... sí, todavía el 12".
Por el momento, QUIC aún no es un estándar, está escrito activamente. Si no me equivoco, no escribí en la diapositiva porque tenía miedo de cometer un error, pero en el IETF 101 en Londres se dijo que para noviembre de 2018 estaba previsto lanzarlo como documento final. Es el estándar QUIC en sí mismo, porque hay
ocho documentos
más en el grupo de trabajo de documentos.

Es decir, todavía no hay un estándar, pero el bombo activo ya está en marcha. Enumeré solo aquellas conferencias en las que he estado durante los últimos seis meses, donde hubo al menos una presentación sobre QUIC. Acerca de "lo genial que es", "cómo debemos cambiarlo", "qué hacer para los operadores", "dejar de filtrar UDP - QUIC funcionará ahora". Todo este alboroto ha estado sucediendo durante bastante tiempo: ya he visto muchos artículos que instaron a la industria del juego a cambiar a QUIC en lugar del UDP habitual.
 Enlaces de la diapositiva:
Enlaces de la diapositiva:
1. conferencias.sigcomm.org/imc/2017/papers/imc17-final39.pdf
2. blog.apnic.net/2018/01/29/measuring-quic-vs-tcp-mobile-desktopEn noviembre de 2017, apareció el siguiente enlace en la lista de correo del grupo de trabajo QUIC: el primero para el documento técnico y el inferior para aquellos que tienen dificultades para leer el documento técnico: este es un enlace al blog de APNIC con un resumen.
Los investigadores decidieron comparar el rendimiento de TCP y QUIC en su forma actual. A modo de comparación, para no tratar con quién tiene la culpa y dónde puede tener la culpa Windows, en el lado del cliente tomaron Chrome bajo Ubuntu, y también tomaron 2 dispositivos móviles: uno Nexus y algunos Samsung
(nota del editor: Nexus 6 y MotoG) con versiones de Android 4 y 6, y también lanzaron Chrome.
Del lado del servidor, instalaron Apache para ver cómo funciona el servidor TCP, y para monitorear QUIC, arrancaron una parte del código fuente abierto que está en el proyecto Chromium. Los resultados de referencia mostraron que, si bien en todas las condiciones de invernadero, QUIC realmente supera a TCP, hay algunas piedras angulares que pierde.

Por ejemplo, la implementación de QUIC de Google funciona significativamente peor que TCP si la reordenación de paquetes ocurre en la red, es decir, los paquetes llegan en el orden incorrecto en que fueron enviados por el servidor. En 2017-2018, en la era de las redes móviles e inalámbricas, generalmente no hay garantía de que el paquete vuele en principio, sin mencionar en qué orden. QUIC funciona muy bien en una red cableada, pero ¿quién usa una red cableada ahora?

En general, a los desarrolladores de este código en Google, aparentemente, realmente no les gustan los teléfonos celulares.
QUIC es un protocolo que se implementa sobre UDP en el espacio del usuario. Y en dispositivos móviles también en el espacio de usuario. Según los resultados de la medición, en una situación normal, es decir, cuando se trabaja a través de una red inalámbrica, la implementación del protocolo QUIC pasa el 58% del tiempo en Android en el estado "Application Limited". ¿Cuál es esta condición? Este es el estado en el que enviamos algunos datos y estamos esperando confirmación. En comparación, en las computadoras de escritorio había una cifra de aproximadamente el 7%.
Solo 2 casos de uso: el primero es una red inalámbrica, el segundo es un dispositivo móvil; y QUIC funciona como TCP o sustancialmente peor. Naturalmente, esto resultó estar en el grupo de trabajo IETF dedicado a QUIC y, naturalmente, Google reaccionó a esto. La respuesta de Google fue la siguiente:
 mailarchive.ietf.org/arch/msg/quic/QktVML_qNDfqjIGirj4t5D0JRGE
mailarchive.ietf.org/arch/msg/quic/QktVML_qNDfqjIGirj4t5D0JRGEBueno, nos reímos, pero en realidad es absolutamente lógico.
Por qué Porque el diseño de QUIC, aunque ya estamos hablando de implementación en producción, pero, de hecho, el experimento más salvaje.
Aquí hay, digamos, un modelo ISO / OSI de siete niveles. ¿Quién la recuerda aquí? Recuerde los niveles: físico, canal, red, transporte, algunas tonterías, algunas tonterías y aplicadas, ¿verdad?
Sí, se desarrolló hace mucho tiempo, y de alguna manera vivimos con este modelo de nivel. QUIC es un experimento para eliminar el sistema de niveles de red en sí. Combina cifrado, transporte, entrega de datos confiable. Todo esto no está en la estructura de niveles, sino en la combinación, donde cada componente tiene acceso a la API de otros componentes.
 Citando a uno de los diseñadores del
Citando a uno de los diseñadores del protocolo QUIC, Christian Guitem: "Una de las principales ventajas de QUIC desde el punto de vista arquitectónico es la falta de una estructura de niveles". Tenemos reconocimiento, control de flujo, cifrado y toda la criptografía: todo esto está completamente en un solo transporte, y nuestras innovaciones de transporte implican el acceso de todo esto directamente a la API de red, por lo que no queremos una arquitectura escalonada en QUIC.

La conversación en el grupo de trabajo sobre esto comenzó debido al hecho de que a principios de marzo, otro diseñador de protocolos QUIC, a saber, Eric Rescorla, decidió proponer para discusión una variante en la que todo el cifrado se elimina de QUIC, en general. Todo lo que queda es una función de transporte que se ejecuta sobre DTLS. DTLS, a su vez, es TLS sobre UDP, en total resulta: QUIC sobre TLS sobre UDP.
¿De dónde vino tal oferta? Por cierto, Rescorla escribió un documento extenso, pero no se convirtió en un estándar; fue un tema de discusión porque en el proceso de diseño de la arquitectura QUIC, en el proceso de prueba de interoperabilidad e implementación, surgieron muchos problemas. Principalmente relacionado con la "secuencia 0".
¿Qué es la secuencia 0 en QUIC? Esta es la misma idea que en HTTP / 2: tenemos una conexión, dentro de ella tenemos varias secuencias multiplexadas. Por diseño QUIC, recuerdo, el cifrado es proporcionado por el mismo protocolo. Esto se hizo de la siguiente manera: se abre un flujo 0 "mágico", que es responsable de establecer una conexión, estrechar la mano y el cifrado, después de lo cual este flujo 0 se cifra y todos los demás también se cifran. Con esto han surgido muchos problemas, están listados en la lista de correo, hay 10 artículos, no me detendré en cada uno. Seleccionaré solo uno que realmente me guste.
 www.ietf.org/mail-archive/web/quic/current/msg03498.html
www.ietf.org/mail-archive/web/quic/current/msg03498.htmlEl problema con el hilo 0, uno de los cuales, es que si estamos perdiendo paquetes, necesitamos reenviarlos. Y al mismo tiempo, por ejemplo, en el lado del servidor, la conexión ya se puede marcar como encriptada, y el paquete perdido se remonta a la época en que no estaba encriptado. En este caso, al reenviar, la implementación puede cifrar paquetes al azar.
Una vez más:
 Encriptar paquetes al azar.
Encriptar paquetes al azar.Esto es bastante difícil de comentar, además de decir cómo está diseñado todo esto. El desarrollo de QUIC en realidad utiliza el enfoque ágil ersatz. Es decir, no es que alguien haya escrito un estándar de hormigón armado que pueda ser lanzado oficialmente después de un par de iteraciones. No

El trabajo es el siguiente:
1. El proyecto de norma comienza, por ejemplo, el número 5;
2. En las listas de correo, así como en las reuniones del IETF, tres partes al año, se lleva a cabo una discusión, luego se lleva a cabo la implementación en los hackathons, pruebas de interoperabilidad, se recopilan comentarios;
3. Google implementa algunos de los cambios en Chrome, en su propia infraestructura, analiza las consecuencias y luego se incrementa el contador y aparece el estándar 6.
Ahora, te recuerdo, la versión 12.
Nota Ed .: a partir del 10 de julio de 2018, ya es el 13.¿Qué es lo importante aquí?
En primer lugar, acabamos de ver los contras, pero hay ventajas. De hecho, puedes participar en este proceso. Se recopilan comentarios de todas las partes involucradas: si está involucrado en los juegos, si cree que en la industria de los juegos simplemente puede cambiar y cambiar UDP, establecer QUIC en su lugar, y todo funcionará, no, no funcionará. Pero en el momento en que puede influenciarlo, de alguna manera puede trabajar con él.

Y esta es, de hecho, una historia común. Se esperan comentarios de usted, todos quieren verlo.
Google está desarrollando un protocolo, poniendo algunas ideas en él, para sus propios fines. Las empresas que hacen otras cosas (si esto no es típico de la Web, los juegos o las aplicaciones móviles, el SEO es el mismo), no pueden esperar por defecto que el protocolo tenga en cuenta sus intereses: no solo porque no interesa a nadie, sino porque nadie solo conoce estos intereses.
Esto, por cierto, es una confesión. Por supuesto, la pregunta es para mí por qué nosotros, como
Qrator Labs , en particular, no participamos en el desarrollo del protocolo HTTP / 2 y no le contamos a nadie sobre el proxy inverso. Pero los mismos Cloudflare y Nginx tampoco participaron allí.
Si bien la industria no está involucrada en esto, Google, Facebook, algunas otras compañías y
académicos se están desarrollando. Para hacerle saber, en la fiesta cercana al IETF, la palabra "académico" es, digamos, no loable. Suena como los epítetos "esquizofrénico" e "hipocondríaco". Las personas a menudo vienen sin objetivos prácticos, sin comprender las tareas reales, pero encajan allí, porque es más fácil obtener una tesis doctoral.
Por supuesto, uno debe participar en esto y no hay otras opciones.

Volviendo a QUIC: entonces, el protocolo se implementa en el espacio del usuario, en dispositivos móviles hay ... Bla, bla. "Implementado en el espacio del usuario". Hablemos de eso.
¿Cómo generalmente organizamos el transporte antes de presentar QUIC? ¿Cómo funciona ahora en producción? Hay un protocolo TCP si estamos hablando de la Web.
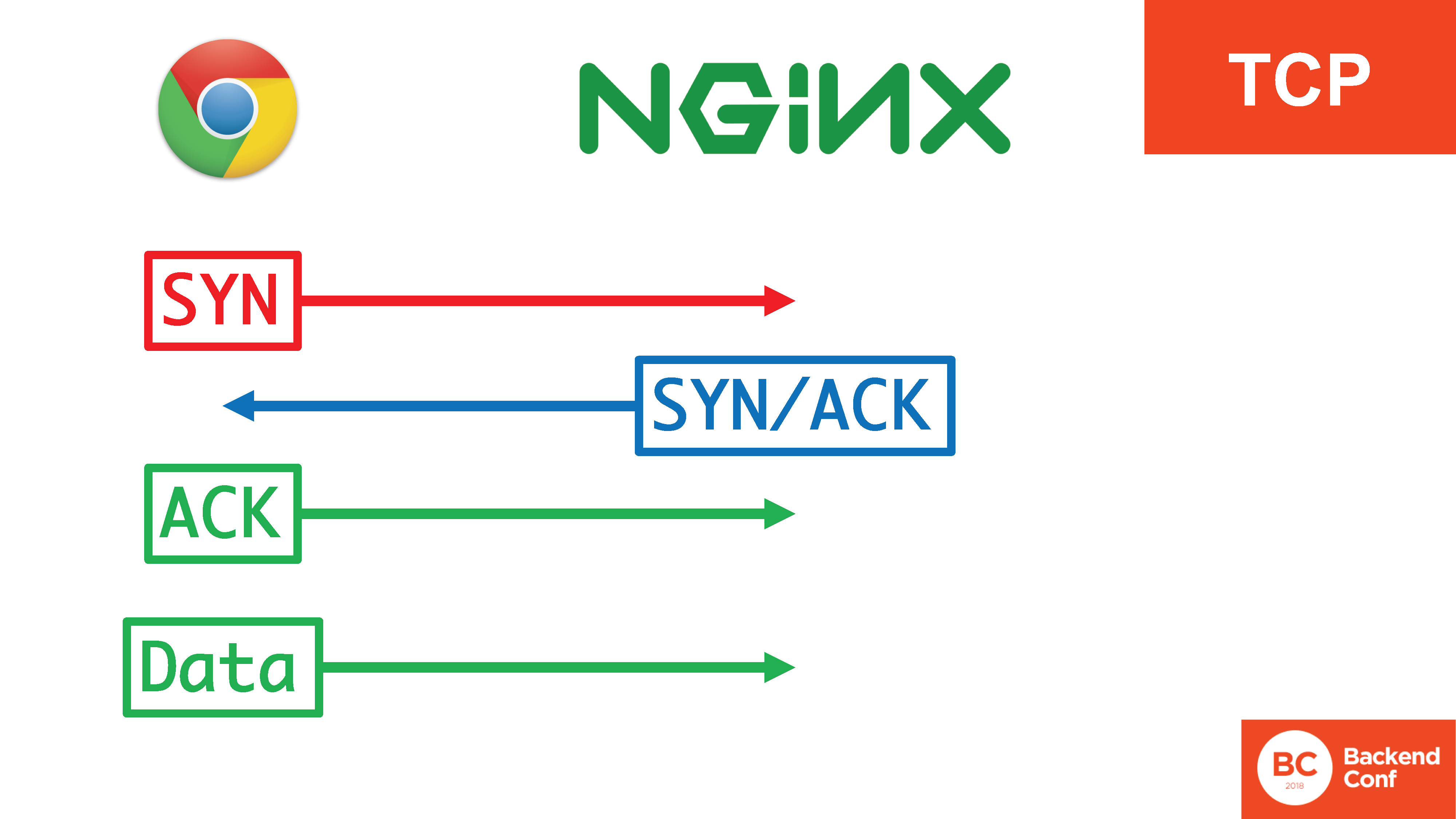
En TCP, existe un
triple apretón de manos : SYN, SYN / ACK, ACK. Se necesita para varias cosas: para evitar que el servidor se use para atacar a otros, para filtrar con éxito ciertos ataques en el protocolo TCP, como la
inundación SYN . Solo después de que hayan pasado 3 segmentos del apretón de manos triple, comenzamos a enviar datos.
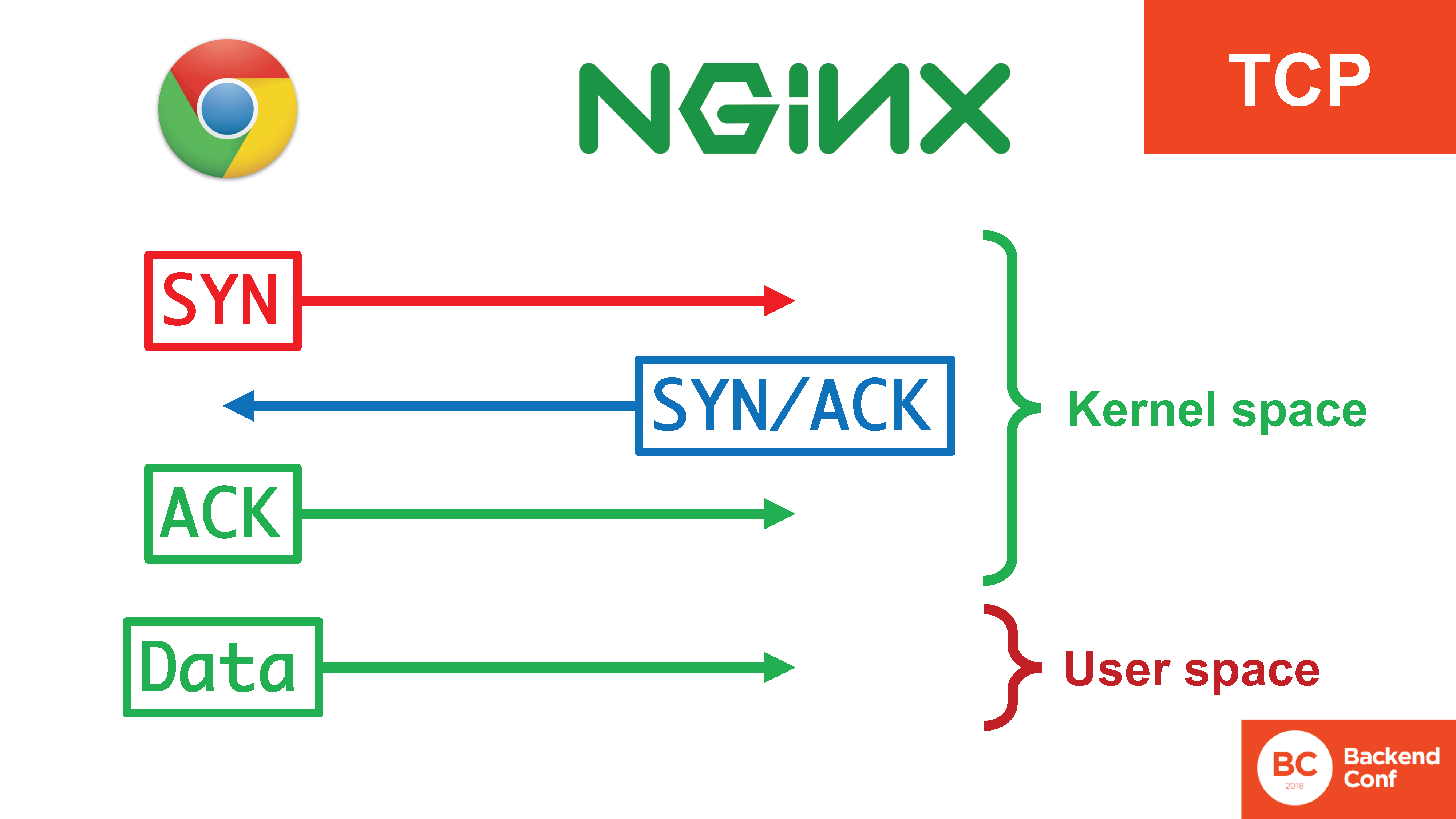
Al mismo tiempo, hay 4 acciones, 3 de las cuales ocurren en el núcleo, ocurren de manera bastante eficiente y los datos ya entran en el espacio del usuario cuando se establece la conexión.
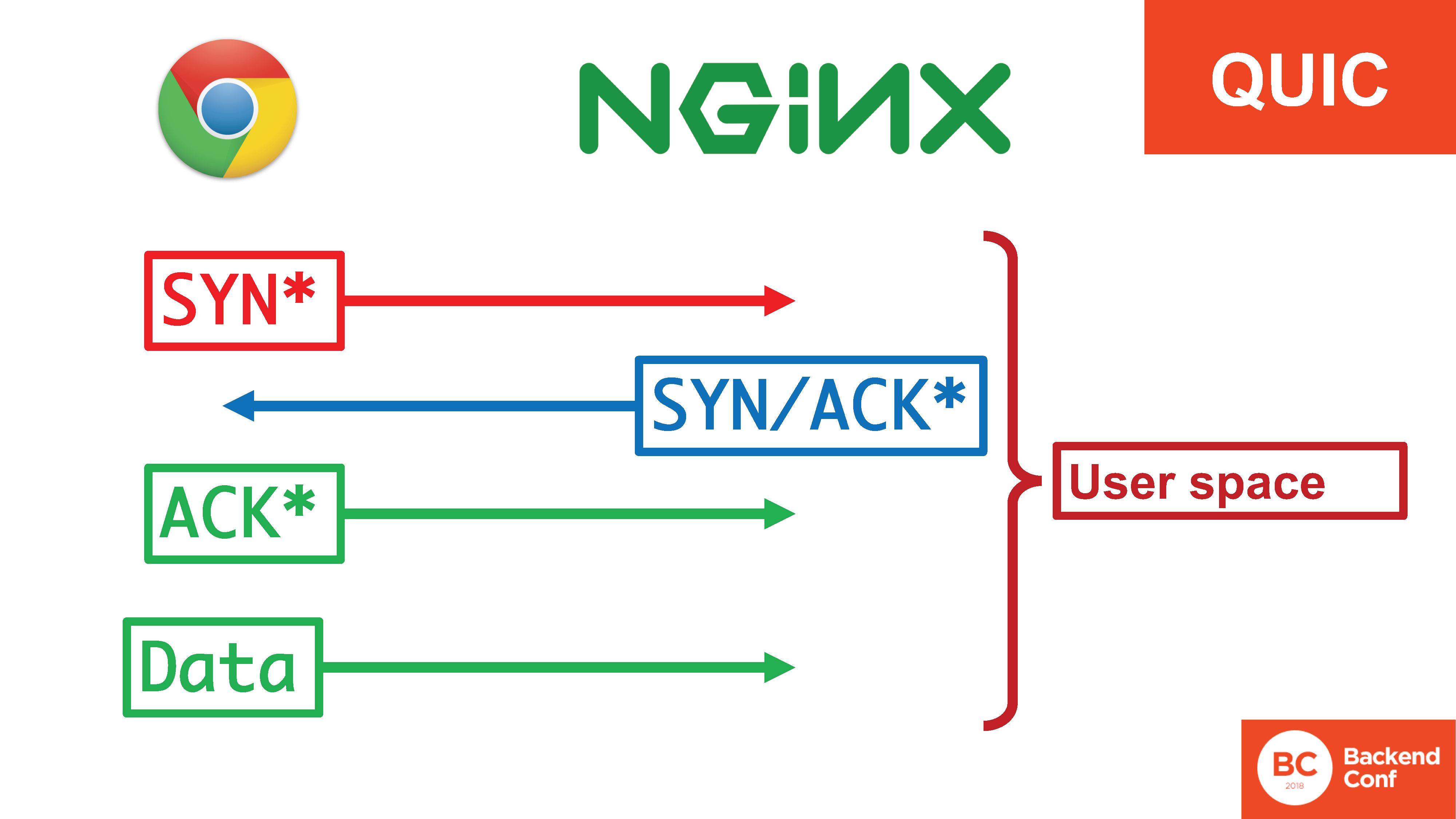
En la situación con QUIC, toda esta felicidad está en el espacio del usuario. , «SYN, SYN/ACK», , , , user space. 20 / TCP
SYN- , user space, c context switch'. - .
? QUIC – user space'? , , - .
 Porque, nuevamente, este es el interés de Google y otros miembros del equipo. Quieren ver el nuevo protocolo implementado, no quieren esperar hasta que se actualicen todos los sistemas operativos del distrito. Si se implementa en el espacio del usuario, se puede usar (en particular, en el navegador, pero no solo) ahora.El hecho de que necesite gastar muchos recursos en el lado del servidor no es un problema para Google. En algún lugar había un buen dicho que para resolver la mayoría de los problemas de rendimiento en el backend de Internet moderno, Google solo necesita confiscar la mitad de los servidores (y preferiblemente las tres cuartas partes). Lo cual no está exento de sentido común, porque Google, de hecho, no se intercambia por tales pequeñeces.
Porque, nuevamente, este es el interés de Google y otros miembros del equipo. Quieren ver el nuevo protocolo implementado, no quieren esperar hasta que se actualicen todos los sistemas operativos del distrito. Si se implementa en el espacio del usuario, se puede usar (en particular, en el navegador, pero no solo) ahora.El hecho de que necesite gastar muchos recursos en el lado del servidor no es un problema para Google. En algún lugar había un buen dicho que para resolver la mayoría de los problemas de rendimiento en el backend de Internet moderno, Google solo necesita confiscar la mitad de los servidores (y preferiblemente las tres cuartas partes). Lo cual no está exento de sentido común, porque Google, de hecho, no se intercambia por tales pequeñeces. www.ietf.org/mail-archive/web/quic/current/msg03736.htmlEn la pantalla hay una cita literal de la lista de correo QUIC, donde se discutió sobre el plan de implementación del protocolo en el espacio del usuario. Esta es una cita literal: “Queremos implementar QUIC en cualquier máquina sin soporte del sistema operativo. Si alguien tiene problemas de rendimiento, lo llevará todo al núcleo ". QUIC ya es tan flexible que da miedo llevar esto al núcleo con cifrado y todo lo demás, pero el grupo de trabajo sobre este tema tampoco está particularmente preocupado.
www.ietf.org/mail-archive/web/quic/current/msg03736.htmlEn la pantalla hay una cita literal de la lista de correo QUIC, donde se discutió sobre el plan de implementación del protocolo en el espacio del usuario. Esta es una cita literal: “Queremos implementar QUIC en cualquier máquina sin soporte del sistema operativo. Si alguien tiene problemas de rendimiento, lo llevará todo al núcleo ". QUIC ya es tan flexible que da miedo llevar esto al núcleo con cifrado y todo lo demás, pero el grupo de trabajo sobre este tema tampoco está particularmente preocupado.
– . . , QUIC , , , , , , . – .
Linux, , QUIC , UDP, , … TCP, .
 vger.kernel.org/netconf2017_files/rx_hardening_and_udp_gso.pdf
vger.kernel.org/netconf2017_files/rx_hardening_and_udp_gso.pdf. , UDP- Linux , TCP-, , . 2 ( , ):
1. UDP-;
2. «large segment offload». TCP , CPU, UDP , . , , , , , TCP , , , UDP, QUIC.
 www.ietf.org/mail-archive/web/quic/current/msg03720.html
www.ietf.org/mail-archive/web/quic/current/msg03720.htmlGoogle, , , . Linux, , Windows, , , . , , Google QUIC, ( ) UDP- TCP-. Linux , .

.
QUIC. . , – , : HTTP/2 HTTP/1.1, QUIC TCP, DNS, IPv6 IPv4… , , production – , , benchmarking.
, , « // » –
! – , , .
, , , , -, , , .
 Por cierto, sobre IPv6. El hecho es que en los días de IPv6, cuando se desarrolló, los protocolos se desarrollaron de una manera algo más directa, es decir, sin tecnologías ágiles. Pero su adaptación en Internet todavía tomó un tiempo sustancial muy grande. Y, por el momento, todavía está en curso, y aún se mantiene en un 10-20% en el caso de IPv6. Además, dependiendo del país, porque en Rusia es aún más bajo.
Por cierto, sobre IPv6. El hecho es que en los días de IPv6, cuando se desarrolló, los protocolos se desarrollaron de una manera algo más directa, es decir, sin tecnologías ágiles. Pero su adaptación en Internet todavía tomó un tiempo sustancial muy grande. Y, por el momento, todavía está en curso, y aún se mantiene en un 10-20% en el caso de IPv6. Además, dependiendo del país, porque en Rusia es aún más bajo.IPv6 . , «Happy Eyeballs»? , , IPv6, , . , , , IPv6, , IPv6 , – , – IPv6, .
«Happy Eyeballs» ( , IETF): 0,3 IPv6-, , IPv4.
, , , , ! . , - - iPad, IPv6 IPv4 , 0,3 : 1 – 1 .
- IETF 99 : « Happy Eyeballs syslog' , , – - ». syslog – , , . , .
– , IPv6 – /64 , , , . - , .
Como resultado, todavía tenemos problemas de implementación, que no solo se expresan en el hecho de que alguien está implementando lentamente IPv6. No, comenzaron a apagarlo de nuevo. Regrese a IPv4. Porque incluso sin problemas fue difícil justificar los beneficios de la transición a la administración, pero si, después de encender, los usuarios también comenzaron a quejarse, eso es todo. Este es un ejemplo cuando incluso un protocolo que se desarrolló con miras a la implementación todavía causa los problemas más salvajes con la implementación, que se expresan en un lavado de cabeza al departamento técnico.Imagine lo que sucederá al implementar protocolos que no fueron diseñados para una implementación a gran escala en sus respectivos casos de uso.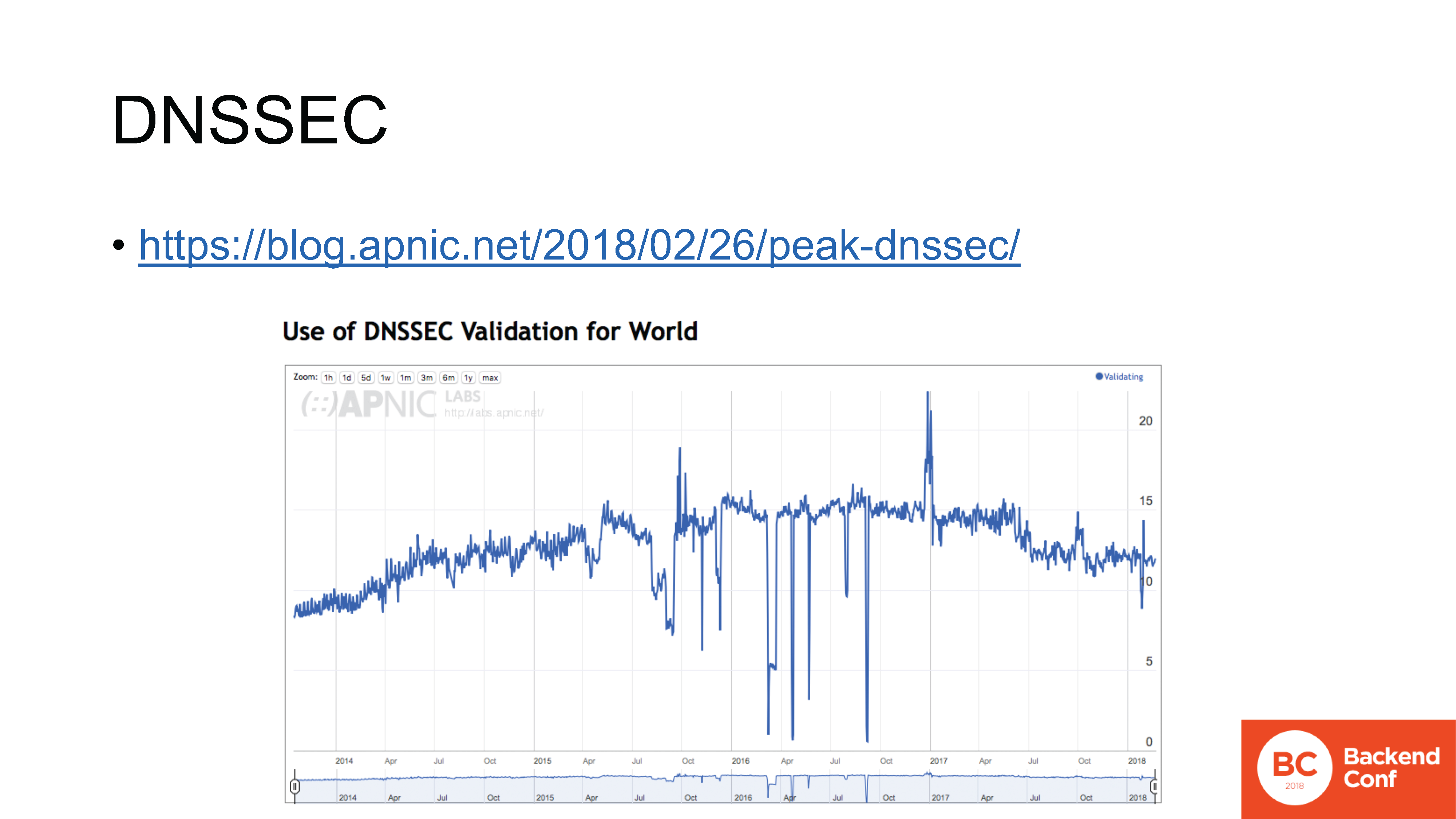 blog.apnic.net/2018/02/26/peak-dnssec
blog.apnic.net/2018/02/26/peak-dnssec– DNSSEC. , , , , .
IPv6, , , , , . , DNSSEC .
- ( APNIC Labs), , DNSSEC. : , , – 2016 .
DNSSEC , , - , , .
 datatracker.ietf.org/meeting/101/materials/slides-101-dnsop-sessa-the-dns-camel-01En general, hay muchos problemas con DNS. El grupo de trabajo dnsop de IETF ahora tiene 3 presidentes, 15 borradores de lo que se llama "en vuelo" : se están preparando para su lanzamiento como RFC.DNS, en particular, aprendió a transferir por encima de todo. Además de TCP, funcionó durante mucho tiempo (pero la gente todavía necesita mostrar cómo hacerlo correctamente ). Ahora comenzaron a ejecutarlo sobre TLS , sobre HTTPS , sobre QUIC .Todo esto parecía absolutamente maravilloso hasta que la gente comenzó a darse cuenta, y no comenzaron a doler en el quinto punto. En marzo de 2017, los desarrolladores de OpenDNS llevaron una presentación llamada "DNS Camel" al IETF, o "camello dns". La presentación se reduce al siguiente pensamiento: ¿cuánto más podemos cargar este camello (también conocido como protocolo DNS) antes de que la próxima ramita rompa su columna vertebral?Este es un enfoque general de cómo vemos el diseño ahora. Se agregan características, hay muchas características, interfieren entre sí de diferentes maneras. Y no siempre de forma predecible, y no siempre los autores de la implementación entienden todos los posibles puntos de interferencia. Implementación de cada nueva característica, implementación, implementación en producción: agregue un conjunto de puntos potenciales de falla en cada lugar donde ocurra dicha interferencia. Sin un punto de referencia, sin monitoreo, en ninguna parte.
datatracker.ietf.org/meeting/101/materials/slides-101-dnsop-sessa-the-dns-camel-01En general, hay muchos problemas con DNS. El grupo de trabajo dnsop de IETF ahora tiene 3 presidentes, 15 borradores de lo que se llama "en vuelo" : se están preparando para su lanzamiento como RFC.DNS, en particular, aprendió a transferir por encima de todo. Además de TCP, funcionó durante mucho tiempo (pero la gente todavía necesita mostrar cómo hacerlo correctamente ). Ahora comenzaron a ejecutarlo sobre TLS , sobre HTTPS , sobre QUIC .Todo esto parecía absolutamente maravilloso hasta que la gente comenzó a darse cuenta, y no comenzaron a doler en el quinto punto. En marzo de 2017, los desarrolladores de OpenDNS llevaron una presentación llamada "DNS Camel" al IETF, o "camello dns". La presentación se reduce al siguiente pensamiento: ¿cuánto más podemos cargar este camello (también conocido como protocolo DNS) antes de que la próxima ramita rompa su columna vertebral?Este es un enfoque general de cómo vemos el diseño ahora. Se agregan características, hay muchas características, interfieren entre sí de diferentes maneras. Y no siempre de forma predecible, y no siempre los autores de la implementación entienden todos los posibles puntos de interferencia. Implementación de cada nueva característica, implementación, implementación en producción: agregue un conjunto de puntos potenciales de falla en cada lugar donde ocurra dicha interferencia. Sin un punto de referencia, sin monitoreo, en ninguna parte.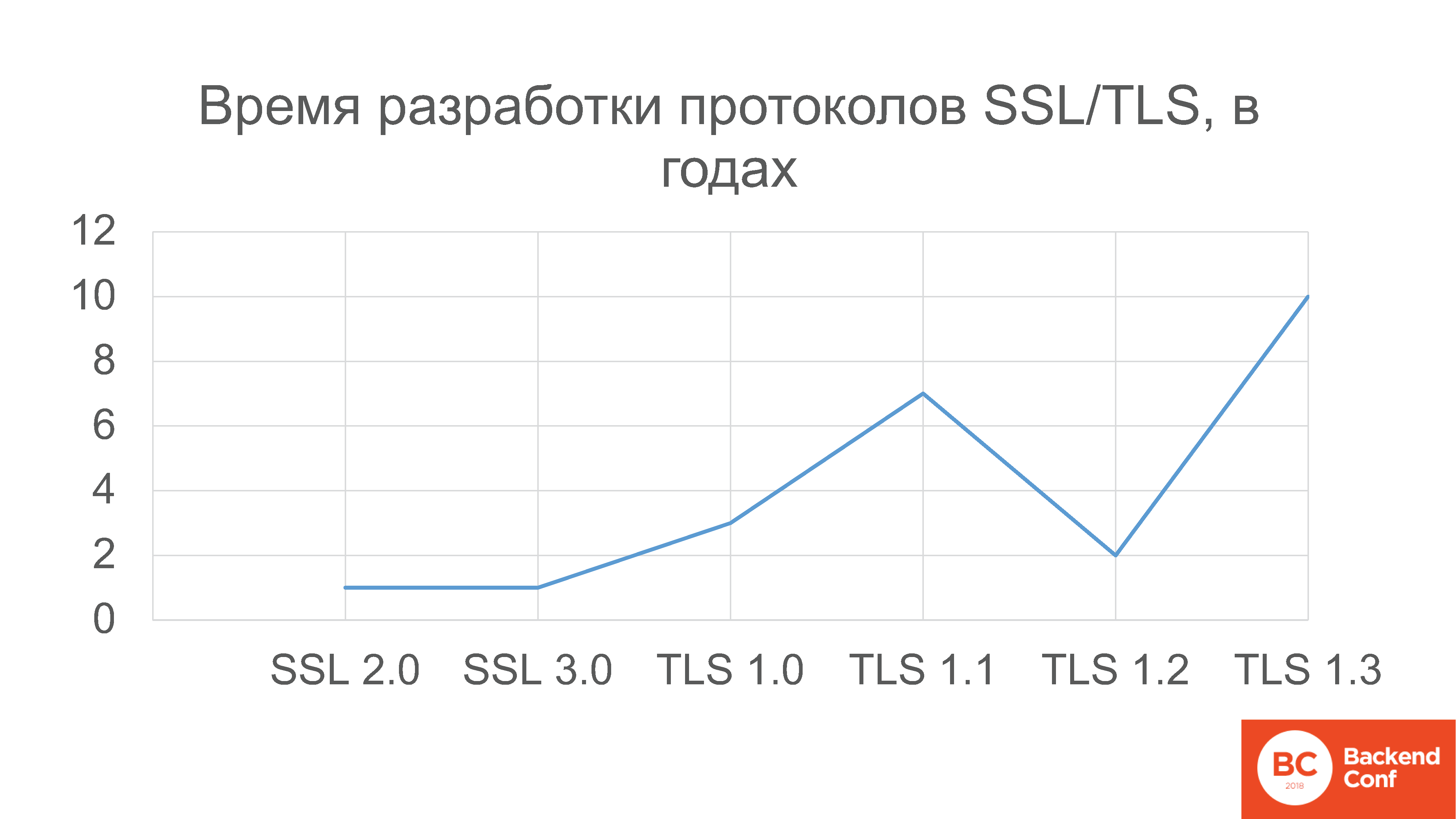 ¿Por qué es importante participar en todo este proceso? Porque el estándar IETF - "RFC" - sigue siendo un estándar. Hay buenas estadísticas: cronogramas de desarrollo para varias versiones de protocolos de encriptación SSL y TLS.Tenga en cuenta que el control de versiones SSL comienza en el número 2, ya que las versiones 0.9 y 1.0 nunca se lanzaron en producción, tenían más fugas de las que Netscape podía permitirse lanzar. Por lo tanto, la historia comenzó con el protocolo SSL 2.0, que se desarrolló un año. Luego SSL 3.0 se desarrolló un año más.Luego se desarrolló TLS 1.0 durante 3 años; versión 1.1 - 7 años; 1.2 se desarrolló solo 2 años, porque no hubo cambios tan grandes; pero la última versión, que se lanzó en marzo de este año, el borrador 27, por cierto, se desarrolló 10 años .
¿Por qué es importante participar en todo este proceso? Porque el estándar IETF - "RFC" - sigue siendo un estándar. Hay buenas estadísticas: cronogramas de desarrollo para varias versiones de protocolos de encriptación SSL y TLS.Tenga en cuenta que el control de versiones SSL comienza en el número 2, ya que las versiones 0.9 y 1.0 nunca se lanzaron en producción, tenían más fugas de las que Netscape podía permitirse lanzar. Por lo tanto, la historia comenzó con el protocolo SSL 2.0, que se desarrolló un año. Luego SSL 3.0 se desarrolló un año más.Luego se desarrolló TLS 1.0 durante 3 años; versión 1.1 - 7 años; 1.2 se desarrolló solo 2 años, porque no hubo cambios tan grandes; pero la última versión, que se lanzó en marzo de este año, el borrador 27, por cierto, se desarrolló 10 años ., , TLS 1.3 use case', , , . , , , US Bank. , , , ,
, .
, - – – // , , , , .

, , .
: , – «- ». , , .
: , , , .
, :
. , Google, , , , .
, , - - , , , , , , , .
Gracias