Comentarios en una publicación reciente "¿Qué tan bueno es el ecosistema de código abierto de R para resolver problemas comerciales?" En cuanto a las descargas en Excel, llevaron a la idea de que tiene sentido pasar tiempo y describir uno de los posibles enfoques probados que se pueden implementar sin salir de R.
La situación es bastante típica. La compañía siempre tiene N métodos por los cuales los gerentes intentan manualmente generar informes en Excel. Incluso si están automatizados, siempre queda una situación en la que es urgente hacer un nuevo corte arbitrario o hacer una presentación para cierto gerente en una forma específica.
Y hay una serie de diccionarios de Excel soportados manualmente para transformar la presentación de datos en informes y muestras en la terminología correcta.
Debido al hecho de que no se pudo encontrar ninguna herramienta adecuada (la masa de matices adicionales será menor), tuve que apilar el "constructor universal" en Shiny + R. Debido a la universalidad y la parametrización de la configuración, dicho constructor se puede plantar fácilmente en casi cualquier sistema en cualquier área temática.
Es una continuación de publicaciones anteriores .
Breve declaración del problema.
- Como fuente de datos técnicos, hay un almacenamiento principal de tipo OLAP (nos centramos en Clickhouse), varias referencias adicionales (Postgre, MS SQL, REST API) y referencias manuales xml, json, xlsx. Debido al hecho de que se requieren análisis ad-hoc, incluido el cálculo de valores únicos, solo es necesario trabajar con los datos de origen y no con los agregados.
- Entradas en la base de datos: cientos de miles de millones de filas por varios cientos de columnas (eventos de tiempo), es aconsejable hacer el análisis en un modo medido no más de varias decenas de segundos, las consultas pueden ser completamente impredecibles, los datos se almacenan en forma técnica (abreviaturas en inglés, números de entradas de diccionario, etc. ) En el estado de destino, se esperan ~ 200 TB de datos sin procesar.
- Los eventos acumulados tienen detalles de versión, es decir A medida que el Sistema funciona, la información de diferentes versiones y lanzamientos de fuentes que informan sobre sí mismos de diversas maneras se acumula en él.
- Los gerentes trabajan bien en Excel, pero no deben conocer (y físicamente no pueden) el componente técnico del Sistema.
¿Cómo resolver el problema?
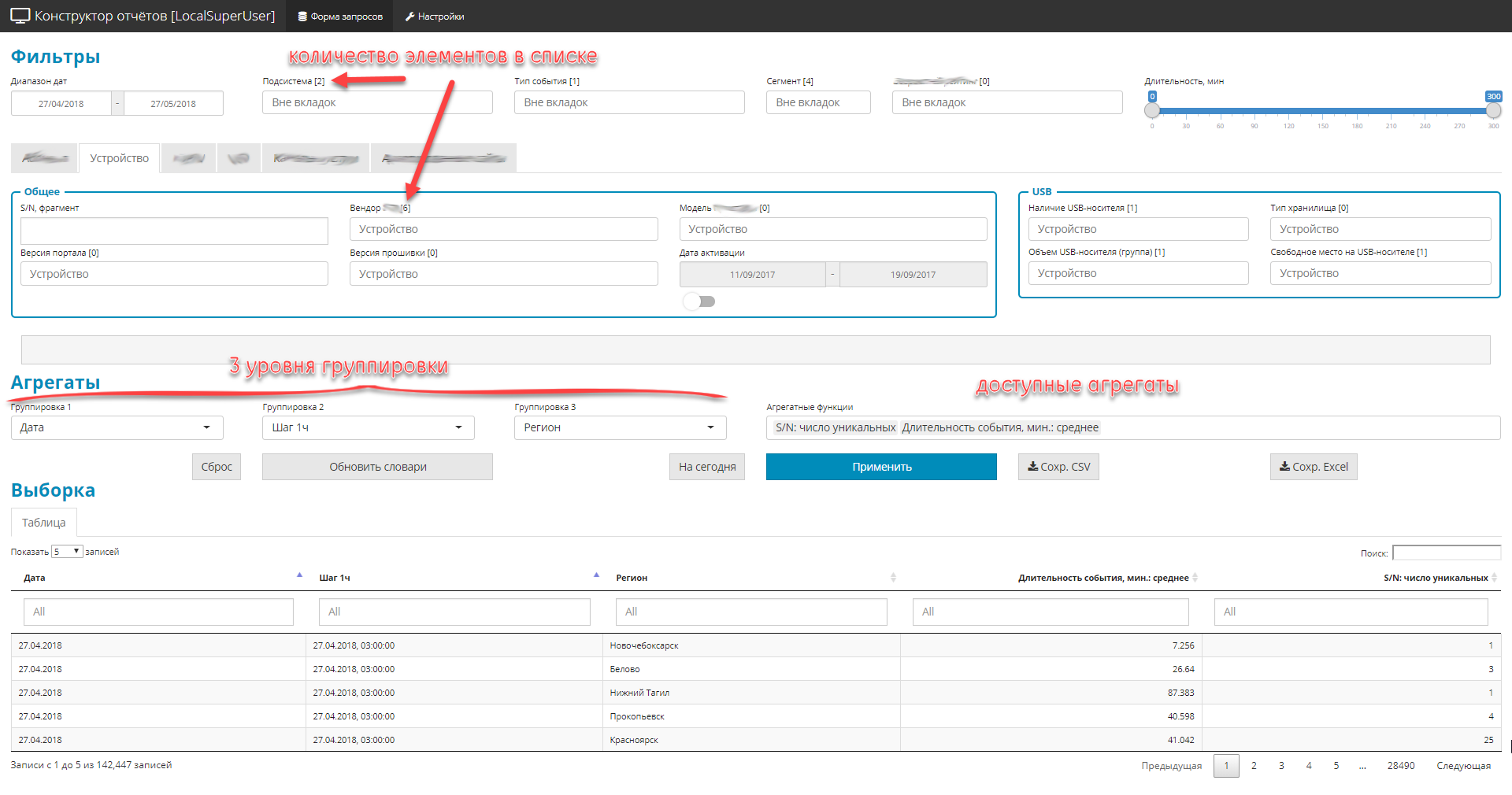
El escenario general del trabajo es bastante simple. El gerente recibió una tarea urgente para la sección analítica: el gerente abre la aplicación, forma muestras arbitrarias en términos del área temática, mira y tuerce el resultado tabular, descarga el resultado acordado en Excel, dibuja una imagen para la administración. La conveniencia y la simplicidad de la interfaz de usuario se eligieron como un punto cero.
- Todo está diseñado como una aplicación Shiny de pantalla única con menús de navegación y marcadores.
- Todos los controles se dividen en 3 partes:
- filtros (globales y privados). Limite el área de selección, hay 4 tipos: lista desplegable-diccionario, fechas, fragmentos de texto, rango digital.
- 3 niveles de anidamiento de grupos de consulta
- lista de cantidades agregadas (a saber, cantidades).
- Debido al hecho de que hay muchos campos en la fuente original (alrededor de 2.500), pero necesita mostrar todo, los elementos de control se agrupan en bloques temáticos.
Ejemplo de interfaz
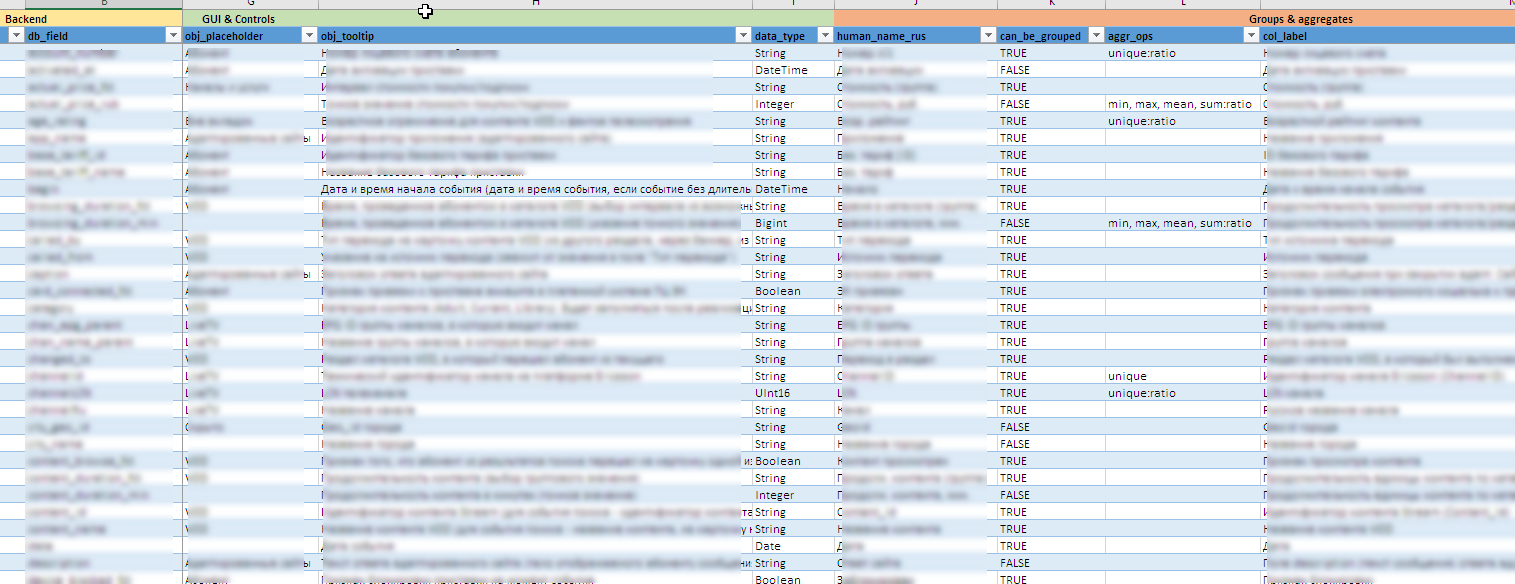
Archivo de ejemplo con metainformación
Útiles "chips" detrás de escena:
- A medida que evolucionan las fuentes de datos, toda la configuración de la interfaz, incluida la creación de controles, información sobre herramientas, el contenido de agrupaciones y agregados disponibles, reglas de exportación en Excel, etc. decorado como un metamodelo en forma de archivo de Excel. Esto le permite modificar rápidamente el "diseñador" para nuevos campos o unidades de cálculo sin cambios significativos (o ningún cambio) en el código fuente.
- Es difícil decir de antemano qué valores pueden ocurrir en un campo en particular, y encontrar uno, no sé qué, es aún más difícil. Mantener manualmente los 90 controles dinámicos es casi imposible. En algunas listas, el vocabulario incluye varios cientos de significados. Por lo tanto, las entradas de diccionario para los controles se actualizan en segundo plano según los datos acumulados en el back-end.
- Los gerentes deben ver todos los campos y contenidos en ruso. Y en las fuentes, estos datos se pueden almacenar de forma oficial. Por lo tanto, se utiliza una combinación de tecnologías de diccionario Clickhouse y postprocesamiento bidireccional de valores de campo en el nivel Brillante. Inmediatamente proporciona el procesamiento de todo tipo de excepciones a las reglas y matices versionados de los contenidos de los campos.
- Para protegerse contra selecciones incorrectas, se realizó una conexión cruzada entre listas para agrupar. El nivel 2 se puede seleccionar solo si se establece el nivel 1, y el nivel 3, solo si se establece el nivel 2. Y las listas de valores disponibles se reducen dinámicamente teniendo en cuenta los valores ya seleccionados.
- Un elemento importante es el control sobre la visualización de la selección tanto en la pantalla como durante la carga posterior para sobresalir. Aquí, también, hay una serie de características en el posprocesamiento destinadas a la conveniencia de la herramienta para el administrador:
- soporte organizado para la "matriz de visibilidad" en forma de un archivo de Excel. Esta matriz determina la visualización u ocultación de ciertos campos en la selección, dependiendo de los filtros instalados.
- modificación dinámica línea por línea del contenido de la muestra. Dependiendo del contenido de varios campos, el contenido de otro campo puede cambiarse (por ejemplo, si se especifica 0 en el campo "cantidad de pedido", se muestra una línea vacía en el campo "tipo de pedido".
- gestión de la visualización de datos personales. dependiendo de la función configurada, los derechos de acceso pers. los datos se pueden mostrar y enmascarar parcialmente con
* . - Gestión de precisión. Solo por mencionar. mostrar 10 decimales: Moveton, pero hay situaciones en las que la precisión de 2 decimales no es suficiente. El 80% de los objetos, por ejemplo, tienen un porcentaje de
0.00% ; debe aumentar los caracteres significativos al redondear, para que la diferencia entre las líneas sea visible. Y la cantidad en la descarga en Excel debe converger (la cantidad en todas las líneas de la columna fraccional se espera razonablemente en la región del 100%). - proporcionando acceso a roles a nivel de controles de contenido disponibles. Los derechos de acceso están controlados por el archivo de configuración json.
- Control dinámico de la profundidad de la solicitud. En el caso de que no se especifiquen agrupaciones y agregados (el estudio está en marcha y solo necesita devolver los datos sin procesar que se encuentran bajo los filtros instalados), se habilita la protección contra la sobrecarga del backend. El usuario puede establecer el rango de tiempo para la búsqueda en 1 año, pero realmente necesita los últimos 1000 registros de la selección. Sabiendo que millones de registros llegan diariamente, primero se realiza una solicitud de prueba de profundidad reducida (hace 3-7 días). Si el número recibido de filas no es suficiente (condiciones de filtrado estrictas), se inicia una consulta completa para todo el período de tiempo.
- Descarga de las muestras recibidas en formato Excel. Todo está formateado, todo en ruso, va acompañado de una hoja separada con la fijación de todos los parámetros de muestra, para que pueda comprender fácilmente cómo se obtuvo este o aquel resultado.
- Se mantiene un registro detallado en la aplicación, para que pueda tener una idea de las acciones del usuario y del funcionamiento de la mecánica del compartimento del motor.
Anticipando posibles comentarios sobre la "bicicleta", si habrá un 100%, sugiero inmediatamente escribirlos con una indicación del producto de código abierto que conoces. Estaré encantado de nuevos descubrimientos.
Naturalmente, se debe proporcionar un enlace al producto teniendo en cuenta toda la gama de requisitos avanzados. Bueno, preferiblemente de inmediato con la evaluación de la infraestructura requerida. Para esta opción, dos o tres servidores de capacidad media (64-128 Gb; 12-20 núcleo de CPU, disco - en función de la cantidad de datos) son suficientes para todo el complejo. ELK no encajaba, porque la tarea principal es el análisis numérico y no funciona con texto.
Conjunto de requisitos detallados
A continuación, para obtener información, se proporciona una lista detallada de los requisitos para la unidad analítica en la parte de las interfaces máquina-máquina y hombre-máquina (el "diseñador de informes" es solo una parte).
Importar \ Exportar \ Medio ambiente
- Los archivos de registro están estandarizados y estructurados solo en términos de marcas de tiempo, módulos y subsistemas. El sistema debe procesar archivos de registro con contenido arbitrario del contenido del mensaje (cuerpo de registro de la grabación), admitiendo tanto el cuerpo de registro estructurado como el no estructurado de la grabación.
- Para enriquecer los datos, el sistema debe tener adaptadores de importación para al menos los siguientes tipos de fuentes de datos:
- archivos planos (csv, txt)
- archivos estructurados xml, json, xlsx
- fuentes compatibles con odbc, en particular MS SQL, MySQL, PostgreSQL
- datos proporcionados a través de la API REST.
- El sistema debe admitir tanto la importación automática como la importación a petición del usuario. Al importar datos de usuario, el Sistema debe proporcionar:
- La posibilidad de validación técnica de los datos importados (la corrección del número de campos, sus tipos, integridad, la presencia de valores
- la posibilidad de validación lógica (contenido de campos, validación, validación cruzada, ...)
- la capacidad de configurar parámetros de validación (en cualquier forma) de acuerdo con la lógica del procedimiento de importación;
- Un informe detallado sobre los errores técnicos y lógicos detectados, lo que permite al operador localizar y eliminar rápidamente el mal funcionamiento de los datos importados.
- El sistema debe admitir la exportación de resultados, al menos, en los siguientes formatos:
- exportación de datos a archivos planos csv, txt
- exportar datos a archivos estructurados xml, json, xlsx
- exportación de datos a fuentes compatibles con odbc, en particular, MS SQL, MySQL, PostgreSQL
- Proporcionar acceso a los datos a través del protocolo REST API
- El sistema debe tener la funcionalidad para generar informes impresos:
- una combinación coherente de texto, representaciones tabulares y representaciones gráficas en un solo documento de acuerdo con una plantilla preformada (narración de cuentos);
- la formación de todos los elementos calculados (tablas, gráficos) en el momento de la generación del formulario de impresión;
- El uso de fuentes externas y directorios necesarios en la preparación de un informe en el modo sobre la marcha de acuerdo con los protocolos mencionados anteriormente, sin integración y duplicación de datos.
- exportación de informes generados en formatos html, docx, pdf
- La formación de representaciones impresas debe ser apoyada tanto a pedido como en segundo plano, de acuerdo con un calendario.
- El sistema debe mantener un registro detallado de los cálculos, las acciones activas del usuario o la interacción con sistemas externos.
- El sistema debe instalarse en el sitio.
- La instalación y la operación posterior deben llevarse a cabo con el aislamiento completo del sistema de Internet.
Cálculos
- El sistema debe admitir el cálculo de métricas agregadas (mínimo, máximo, promedio, mediana, cuartiles) para un intervalo de tiempo arbitrario en un modo cercano al tiempo real.
- El sistema debe admitir el cálculo de métricas básicas (número de valores, número de valores únicos) para un intervalo de tiempo arbitrario en un modo cercano al tiempo real.
- Al calcular los datos agregados, el usuario debe determinar los períodos de agregación a partir de rangos predefinidos: 5 minutos, 10 minutos, 15 minutos, 20 minutos, 30 minutos, 1 hora, 2 horas, 24 horas, 1 semana, 1 mes
- El sistema debe incluir un constructor para formar muestras arbitrarias. La composición de las posibles operaciones debe determinarse mediante un metamodelo de datos predefinido. El constructor debe admitir la siguiente configuración mínima:
- Soporte de filtro para fechas: [inicio del período de informe - final del período de informe]
- Soporte de filtro (listas desplegables) con selección múltiple para campos enumerados (por ejemplo, ciudades: Moscú, San Petersburgo, ...)
- Formación automática del contenido de listas desplegables para filtros de campos enumerables basados en directorios externos dinámicos o datos acumulados.
- soporte para al menos tres niveles de agrupación secuencial de datos en la muestra solicitada; El usuario establece los parámetros para agruparlos a partir de la lista de conjunto de datos disponibles en el nivel de metamodelo.
- restricción de los campos disponibles para la agrupación en uno u otro nivel, teniendo en cuenta los campos seleccionados en los niveles superiores de agrupación (por ejemplo, si se eligió “ciudad” en el 1er nivel, este parámetro no debería estar disponible en el 2º o 3er nivel m niveles de agrupación)
- La posibilidad de agrupar por parámetros de tiempo aumentado: día de la semana, grupo de horas (11-12; 12-13), semana
- soporte para agregados calculados básicos: (mínimo, máximo, promedio, mediana, cantidad, número de únicos);
- soporte para filtros de prueba para proporcionar búsqueda de texto completo en la selección;
- soporte en la etapa de mostrar el enriquecimiento y la transformación de los datos obtenidos a pedido basados en datos de directorios o fuentes externas.
- El sistema debe tener mecanismos para calcular las métricas en coordenadas espaciales (sp = punto espacial) para admitir geoanálisis.
- Para las métricas de tiempo (transacciones, operaciones, consultas, ...), el sistema debe calcular y mostrar la densidad de la distribución del tiempo de ejecución de la consulta.
- Todos los indicadores calculados deben realizarse para todos los objetos en su conjunto, así como para las submuestras establecidas por el usuario utilizando filtros
- El sistema debe realizar todos los cálculos en la memoria.
- Todos los eventos tienen una marca de tiempo, por lo que el sistema debe admitir el trabajo con series de tiempo equidistantes y arbitrarias.
- El sistema debe admitir la capacidad de configurar y habilitar mecanismos para restaurar datos perdidos en series de tiempo (varios algoritmos), determinar anomalías, predecir series de tiempo, clasificación / agrupamiento.
Parte de la interfaz
- Toda la interfaz de usuario, incluidos los contenidos de elementos gráficos y de tabla, deben estar localizados.
- Para los controles y las columnas de representaciones tabulares, debe admitirse la posibilidad de formar información sobre herramientas con una descripción detallada (punta flotante), formada tanto de forma estática como dinámica (por ejemplo, en la información sobre herramientas pueden estar los parámetros utilizados para calcular).
- La interfaz del lugar de trabajo debe construirse solo con el uso de tecnologías HTML, CSS, JS, sin el uso de tecnologías obsoletas, dependientes de la plataforma o no portátiles, como Adobe Flash, MS Silverlight, etc.
- La hora en los gráficos debe mostrarse en un formato de 24 horas.
- Los parámetros para mostrar datos en los ejes deben admitir el escalado automático (frecuencia de etiquetas y formato de visualización) según el rango de valores. Un ejemplo típico es la visualización de horas con un rango de medición dentro de un día, la visualización de días con un rango de medición dentro de una semana.
- El sistema debería, como mínimo, admitir los siguientes formatos de visualización de gráficos atómicos:
- Histograma (barra)
- Spot
- Lineal
- Mapa de calor
- Contornos (contornos)
- Gráficos circulares
- El sistema debe admitir la capacidad de colocar marcadores de forma inteligente (por ejemplo, valores) de un determinado subconjunto de puntos con una superposición mínima de estos marcadores.
- El sistema debe admitir la posibilidad de combinar en una representación gráfica de datos obtenidos de diferentes fuentes de datos. Se debe admitir la capacidad de especificar diferentes formatos de visualización de gráficos atómicos para cada fuente de datos, siempre que los ejes de coordenadas y el tipo de sistema de coordenadas coincidan.
- El sistema debe admitir la distribución facetaria (división de gráficos en la cuadrícula M x N) de gráficos atómicos para una variable de parametrización dada. En la visualización de facetas, para cada gráfico, debe ser posible una escala independiente tanto del eje X como del eje Y.
- Los gráficos deben soportar la parametrización de las siguientes características:
- Color
- Tipo de línea o punto
- El grosor de la línea o el contorno del punto.
- Tamaño del punto
- Transparencia
- Para las tareas de geoanálisis de datos, el sistema debe admitir el trabajo con archivos de forma, incluida la importación, visualización, coloración parametrizada de área y garantizar que varios elementos gráficos e indicadores calculados se superpongan en el geopod generado.
- Los controles de la interfaz de usuario (listas, campos, paneles, etc.) deben admitir el cambio dinámico de su contenido según el estado de otros elementos. Por ejemplo, al elegir una región determinada, el contenido del elemento de selección de ciudad debe limitarse a la lista de ciudades incluidas en la región.
- El modelo a seguir del acceso a las aplicaciones de informes debe ser compatible:
- Soporte para el metamodelo de datos para proporcionar acceso a roles a nivel de URL (posible / imposible)
- soporte para un metamodelo de datos para proporcionar acceso basado en roles en el nivel de contenido de un elemento de control (por ejemplo, la lista de objetos disponibles en las listas desplegables está determinada por la responsabilidad regional del administrador)
- soporte para el metamodelo de datos para garantizar el acceso basado en roles a nivel de visualización de datos personales (por ejemplo, enmascarar "*" de una cierta parte de los números de correo electrónico u otros campos)
Conclusión
El objetivo principal de la publicación es mostrar que las posibilidades de R se extienden bastante más allá de los límites de las estadísticas clásicas. Se verifica prácticamente, no es necesario sacrificar la calidad o la funcionalidad.
Publicación anterior: "¿Qué tan bueno es el ecosistema de código abierto de R para resolver problemas comerciales?" .