Una de las noticias más populares y discutidas en los últimos años es quién agregó inteligencia artificial a dónde y qué piratas informáticos rompieron qué y dónde. Al combinar estos temas, aparecen estudios muy interesantes, y ya había varios artículos en el centro que podían engañar a los modelos de aprendizaje automático, por ejemplo: un artículo sobre las limitaciones del aprendizaje profundo , sobre cómo atraer redes neuronales . Además, me gustaría considerar este tema con más detalle desde el punto de vista de la seguridad informática:

Considere los siguientes problemas:
- Términos importantes
- ¿Qué es el aprendizaje automático? Si de repente aún no lo sabías.
- ¿Qué tiene que ver la seguridad informática?
- ¿Es posible manipular el modelo de aprendizaje automático para realizar un ataque dirigido?
- ¿Se puede degradar el rendimiento del sistema?
- ¿Puedo aprovechar las limitaciones de los modelos de aprendizaje automático?
- Categorización de los ataques.
- Formas de protección.
- Posibles consecuencias.
1. Lo primero con lo que me gustaría comenzar es la terminología.
Esta posible declaración puede causar un gran holivar por parte de las comunidades científicas y profesionales debido a los varios artículos ya escritos en ruso, pero me gustaría señalar que el término "inteligencia de confrontación" se traduce como "inteligencia enemiga". Y la palabra "adversarial" en sí misma debe traducirse no por el término legal "adversarial", sino por un término más adecuado de seguridad "malicioso" (no hay quejas sobre la traducción del nombre de la arquitectura de la red neuronal). Luego, todos los términos relacionados en ruso adquieren un significado mucho más brillante, como "ejemplo de confrontación" - una instancia maliciosa de datos, "configuración de confrontación" - un entorno malicioso. Y el área que consideraremos "aprendizaje automático adversario" es el aprendizaje automático malicioso.
Al menos en el marco de este artículo, se utilizarán dichos términos en ruso. Espero que sea posible demostrar que este tema trata mucho más sobre la seguridad para utilizar de manera justa los términos de esta área, en lugar del primer ejemplo de un traductor.
Entonces, ahora que estamos listos para hablar el mismo idioma, podemos comenzar esencialmente :)
2. Qué es el aprendizaje automático, si de repente aún no sabías
Bueno, todavia estoy en el saberPor métodos de aprendizaje automático, generalmente nos referimos a métodos para construir algoritmos que pueden aprender y actuar sin programar explícitamente su comportamiento en datos preseleccionados. Por datos podemos decir cualquier cosa, si podemos describirlo con algunos signos o medirlo. Si hay algún signo desconocido para algunos de los datos, pero realmente lo necesitamos, utilizamos métodos de aprendizaje automático para restaurar o predecir este signo en función de datos ya conocidos.
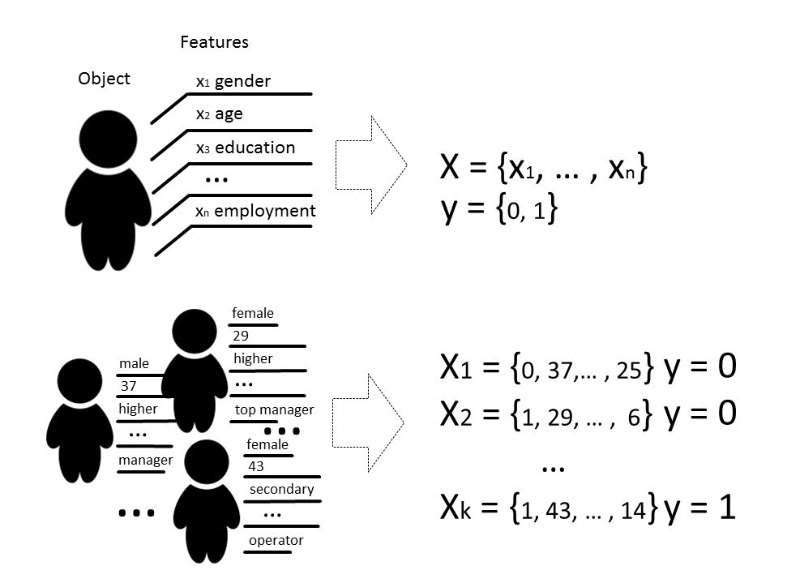
Hay varios tipos de problemas que pueden resolverse con la ayuda del aprendizaje automático, pero hablaremos principalmente sobre el problema de clasificación.
Clásicamente, el propósito de la etapa de entrenamiento del modelo clasificador es seleccionar una relación (función) que muestre la correspondencia entre las características de un objeto en particular y una de las clases conocidas. En un caso más complejo, se requiere una predicción de la probabilidad de pertenecer a una categoría particular.
Es decir, la tarea de clasificación es construir un hiperplano que divida el espacio, donde, por regla general, su dimensión es el tamaño del vector de características, de modo que los objetos de diferentes clases se encuentran en lados opuestos de este hiperplano.
Para un espacio bidimensional, tal hiperplano es una línea. Considere un ejemplo simple:

En la imagen puedes ver dos clases, cuadrados y triángulos. Es imposible encontrar la dependencia y dividirla con mayor precisión por una función lineal. Por lo tanto, con la ayuda del aprendizaje automático, uno puede elegir una función no lineal que distinga mejor entre estos dos conjuntos.
La tarea de clasificación es una tarea de enseñanza bastante típica con un maestro. Para entrenar el modelo, dicho conjunto de datos es necesario para que sea posible distinguir las características del objeto y su clase.
3. ¿Qué tiene que ver la seguridad informática con ella?
En seguridad informática, varios métodos de aprendizaje automático se han utilizado durante mucho tiempo en el filtrado de spam, análisis de tráfico y detección de fraude o malware.
Y en cierto sentido, este es un juego en el que, después de hacer un movimiento, esperas que el enemigo reaccione. Por lo tanto, al jugar a este juego, debes ajustar constantemente los modelos, enseñar sobre nuevos datos o cambiarlos por completo, teniendo en cuenta los últimos logros de la ciencia.
Por ejemplo, si bien los antivirus usan análisis de firmas, heurísticas manuales y reglas que son bastante difíciles de mantener y extender, la industria de la seguridad todavía discute sobre los beneficios reales de los antivirus y muchos consideran que los antivirus son un producto muerto. Los atacantes eluden todas estas reglas, por ejemplo, con la ayuda de la ofuscación y el polimorfismo. Como resultado, se da preferencia a las herramientas que utilizan técnicas más inteligentes, por ejemplo, métodos de aprendizaje automático que seleccionan automáticamente características (incluso aquellas que no son interpretadas por humanos), pueden procesar rápidamente grandes cantidades de información, generalizarlas y tomar decisiones rápidamente.
Es decir, por un lado, el aprendizaje automático se utiliza como herramienta de protección. Por otro lado, esta herramienta también se usa para ataques más inteligentes.
¿Veamos si esta herramienta puede ser vulnerable?
Para cualquier algoritmo, no solo la selección de parámetros es muy importante, sino también los datos sobre los que se entrena el algoritmo. Por supuesto, en una situación ideal, es necesario que haya suficientes datos para el entrenamiento, las clases deben estar equilibradas y el tiempo para el entrenamiento pasar desapercibido, lo cual es prácticamente imposible en la vida real.
La calidad de un modelo entrenado generalmente se entiende como la precisión de la clasificación de los datos que el modelo aún no ha "visto", en el caso general, como una cierta proporción de copias de datos correctamente clasificados a la cantidad total de datos que transmitimos al modelo.
En general, todas las evaluaciones de calidad están directamente relacionadas con suposiciones sobre la distribución esperada de los datos de entrada del sistema y no tienen en cuenta las condiciones ambientales perjudiciales ( entornos adversos ), que a menudo van más allá de la distribución esperada de los datos de entrada. Un entorno malicioso se entiende como un entorno donde es posible confrontar o interactuar con el sistema. Ejemplos típicos de tales entornos son aquellos que usan filtros de spam, algoritmos de detección de fraude y sistemas de análisis de malware.
Por lo tanto, la precisión puede considerarse como una medida del rendimiento promedio del sistema en su uso promedio, mientras que la evaluación de seguridad está interesada en su peor implementación.
Es decir, generalmente los modelos de aprendizaje automático se prueban en un entorno bastante estático donde la precisión depende de la cantidad de datos para cada clase en particular, pero en realidad no se puede garantizar la misma distribución. Y estamos interesados en equivocar el modelo. En consecuencia, nuestra tarea es encontrar tantos vectores como sea posible que den el resultado incorrecto.
Cuando hablan de la seguridad de un sistema o servicio, generalmente significan que es imposible violar una política de seguridad dentro de un modelo de amenaza dado en hardware o software, tratando de verificar el sistema tanto en la etapa de desarrollo como en la etapa de prueba. Pero hoy en día, una gran cantidad de servicios operan sobre la base de algoritmos de análisis de datos, por lo que los riesgos radican no solo en la funcionalidad vulnerable, sino también en los datos en sí mismos, sobre los cuales el sistema puede tomar decisiones.
Nadie se queda quieto, y los hackers también están dominando algo nuevo. Y los métodos que ayudan a estudiar los algoritmos de aprendizaje automático para la posibilidad de un compromiso por parte de un atacante que puede usar el conocimiento de cómo funciona el modelo se denominan aprendizaje automático adversario , o en ruso todavía es aprendizaje automático malicioso .
Si hablamos de la seguridad de los modelos de aprendizaje automático desde el punto de vista de la seguridad de la información, conceptualmente me gustaría considerar varias cuestiones.
4. ¿Es posible manipular el modelo de aprendizaje automático para realizar un ataque dirigido?
Aquí hay un buen ejemplo con la optimización de motores de búsqueda. Las personas estudian cómo funcionan los algoritmos inteligentes de los motores de búsqueda y manipulan los datos en sus sitios para obtener una clasificación más alta. La cuestión de la seguridad de dicho sistema en este caso no es tan aguda hasta que comprometió algunos datos o causó daños graves.
Como ejemplo de dicho sistema, podemos citar servicios que básicamente utilizan la capacitación en línea del modelo, es decir, capacitación en la que el modelo recibe datos en un orden secuencial para actualizar los parámetros actuales. Al saber cómo se entrena el sistema, puede planificar el ataque y proporcionar al sistema datos previamente preparados.
Por ejemplo, de esta manera se engañan los sistemas biométricos, que actualizan gradualmente sus parámetros a medida que ocurren pequeños cambios en la apariencia de una persona, por ejemplo, con un cambio natural en la edad , que es la funcionalidad absolutamente natural y necesaria del servicio en este caso. Con esta propiedad del sistema, puede preparar los datos y enviarlos al sistema biométrico, actualizando el modelo hasta que actualice los parámetros a otra persona. Por lo tanto, el atacante volverá a entrenar al modelo y podrá identificarse a sí mismo en lugar de a la víctima.

Este problema surge de manera natural por el hecho de que el modelo de aprendizaje automático a menudo se prueba en un entorno bastante estático, y su calidad se evalúa mediante la distribución de datos en los que se entrenó el modelo. Al mismo tiempo, a menudo se plantean preguntas muy específicas a especialistas en análisis de datos, que el modelo debe responder:
- ¿Es el archivo malicioso?
- ¿Esta transacción pertenece al fraude?
- ¿Es legítimo el tráfico actual?
Y se espera que el algoritmo no pueda ser 100% exacto, solo puede con cierta probabilidad atribuir el objeto a alguna clase, por lo que debemos encontrar compromisos en el caso de errores del primer y segundo tipo, cuando nuestro algoritmo no puede estar completamente seguro en su elección y todavía está equivocado.
Tome un sistema que muy a menudo produce errores del primer y segundo tipo. Por ejemplo, el antivirus bloqueó su archivo porque lo consideraba malicioso (aunque esto no es así), o el antivirus omitió un archivo que era malicioso. En este caso, el usuario del sistema lo considera ineficaz y la mayoría de las veces simplemente lo apaga, aunque es probable que se haya capturado un conjunto de dichos datos.
Y el conjunto de datos en el que el modelo muestra el peor resultado siempre existe. Y la tarea del atacante es buscar dichos datos para que apague el sistema. Tales situaciones son bastante desagradables y, por supuesto, el modelo debería evitarlas. ¡Y puedes imaginar la magnitud de las consecuencias de las investigaciones de todos los incidentes falsos!
Los errores del primer tipo se perciben como una pérdida de tiempo, mientras que los errores del segundo tipo se perciben como una oportunidad perdida. Aunque, de hecho, el costo de este tipo de errores para cada sistema específico puede ser diferente. Si un antivirus puede ser más barato, se puede cometer un error del primer tipo, porque es mejor hacerlo de forma segura y decir que el archivo es malicioso, y si el cliente apaga el sistema y el archivo realmente resulta ser malicioso, entonces el antivirus "como se advirtió" y la responsabilidad recae en el usuario. Si tomamos, por ejemplo, un sistema de diagnóstico médico, ambos errores serán bastante caros, porque en cualquier caso el paciente corre el riesgo de un tratamiento incorrecto y un riesgo para la salud.
6. ¿Puede un atacante usar las propiedades de un método de aprendizaje automático para interrumpir el sistema? Es decir, sin interferir en el proceso de aprendizaje, encuentre las limitaciones del modelo que obviamente dan predicciones incorrectas.
Parecería que los sistemas de aprendizaje profundo están prácticamente protegidos de la intervención humana en la selección de signos, por lo que sería posible decir que no hay un factor humano al tomar decisiones por el modelo. Todo el encanto del aprendizaje profundo es que es suficiente para alimentar el modelo con datos casi "en bruto", y el modelo en sí, a través de múltiples transformaciones lineales, destaca las características que "considera" más importantes y toma una decisión. Sin embargo, ¿es realmente tan bueno?
Hay trabajos que describen los métodos para preparar tales ejemplos maliciosos en el modelo de aprendizaje profundo, que el sistema clasifica incorrectamente. Uno de los pocos pero populares ejemplos es un artículo sobre ataques físicos efectivos en modelos de aprendizaje profundo.
Los autores realizaron experimentos y propusieron métodos para omitir modelos basados en la restricción del aprendizaje profundo que engaña al sistema de "visión", utilizando el ejemplo de reconocimiento de señales de tráfico. Para obtener un resultado positivo, es suficiente que los atacantes encuentren tales áreas en el objeto que derriben con más fuerza el clasificador, y está equivocado. Los experimentos se llevaron a cabo en la marca "STOP", que, debido a cambios en los investigadores, calificó el modelo como la marca "SPEED LIMIT 45". Pusieron a prueba su enfoque en otros signos y obtuvieron un resultado positivo.
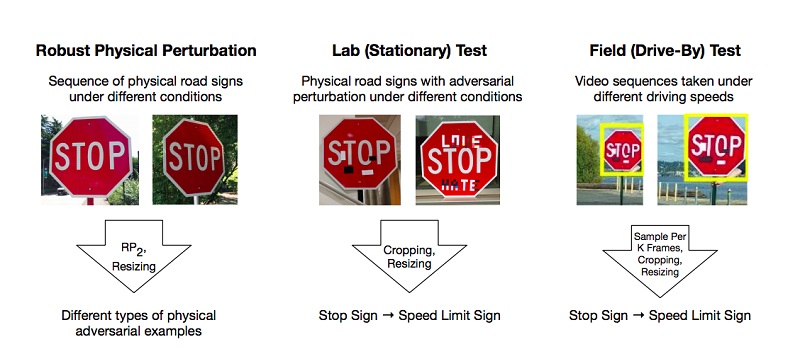
Como resultado, los autores propusieron dos formas de engañar al sistema de aprendizaje automático: el ataque de impresión de carteles, que implica una serie de pequeños cambios en todo el perímetro de la marca llamada camuflaje, y los ataques de adhesivos, cuando se colocaron algunas pegatinas en la marca en ciertas áreas.
Pero estas son situaciones de la vida: cuando el letrero está en la tierra del polvo de la carretera o cuando los jóvenes talentos abandonaron su trabajo en él. Es probable que la inteligencia artificial y el arte no tengan lugar en un mundo.

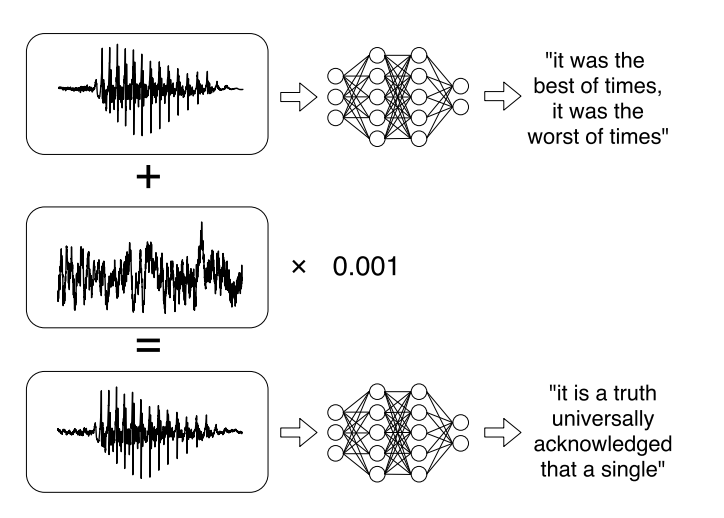
O investigaciones recientes sobre ataques dirigidos a sistemas automáticos de reconocimiento de voz . Los mensajes de voz se han convertido en una tendencia de moda cuando se comunican en las redes sociales, pero escucharlos no siempre es conveniente. Por lo tanto, hay servicios que le permiten transmitir una grabación de audio en texto. Los autores del trabajo aprendieron a analizar el audio original, tomaron en cuenta la señal de sonido y luego aprendieron a crear otra señal de sonido, que es 99% similar al original, agregando un pequeño cambio. Como resultado, el clasificador descifra el registro como quiere el atacante.
7. A este respecto, sería posible clasificar los ataques existentes de varias maneras :
Por el método de exposición (Influencia):
- Los ataques causales afectan el entrenamiento del modelo a través de la interferencia en el conjunto de entrenamiento.
- Los ataques exploratorios usan errores clasificadores sin afectar el conjunto de entrenamiento.
Violación de seguridad:
- Los ataques de integridad comprometen el sistema a través de errores del segundo tipo.
- Los ataques de disponibilidad provocan un apagado del sistema, generalmente basado en errores del primer tipo.
Especificidad:
- El ataque dirigido (ataque dirigido) tiene como objetivo cambiar la predicción del clasificador a una clase específica.
- El ataque masivo (ataque indiscriminado) tiene como objetivo cambiar la respuesta del clasificador a cualquier clase, excepto la correcta.
El propósito de la seguridad es proteger los recursos de un atacante y cumplir con los requisitos, cuyas violaciones conducen a un compromiso parcial o completo de un recurso.
Se utilizan varios modelos de aprendizaje automático para la seguridad. Por ejemplo, los sistemas de detección de virus tienen como objetivo reducir la vulnerabilidad a los virus al detectarlos antes de que el sistema se infecte, o detectar uno existente para su eliminación. Otro ejemplo es el sistema de detección de intrusos (IDS), que detecta que un sistema ha sido comprometido al detectar tráfico malicioso o comportamiento sospechoso en el sistema. Otra tarea cercana es el sistema de prevención de intrusiones (IPS), que detecta los intentos de intrusión y evita la intrusión en el sistema.
En el contexto de los problemas de seguridad, el objetivo de los modelos de aprendizaje automático es, en el caso general, separar los eventos maliciosos y evitar que interfieran con el sistema.
En general, el objetivo se puede dividir en dos:
integridad : evitar que un atacante acceda a los recursos del sistema
Accesibilidad : evitar que un atacante interfiera con el funcionamiento normal.
Existe una conexión clara entre los errores de segundo tipo y las violaciones de integridad: las instancias maliciosas que pasan al sistema pueden ser dañinas. Al igual que los errores del primer tipo generalmente violan la accesibilidad, porque el sistema en sí rechaza copias confiables de los datos.
8. ¿Cuáles son las formas de protegerse contra los ciberdelincuentes que manipulan los modelos de aprendizaje automático?
Por el momento, proteger un modelo de aprendizaje automático de ataques maliciosos es más difícil que atacarlo. Solo porque no importa cuánto entrenemos al modelo, siempre habrá un conjunto de datos en el que funcionará peor.
Y hoy no hay formas suficientemente efectivas de hacer que el modelo funcione con una precisión del 100%. Pero hay algunos consejos que pueden hacer que el modelo sea más resistente a los ejemplos maliciosos.
Este es el principal: si es posible no usar modelos de aprendizaje automático en un entorno malicioso, es mejor no usarlos. No tiene sentido rechazar el aprendizaje automático si se enfrenta a la tarea de clasificar imágenes o generar memes. Es casi imposible infligir un daño significativo que conduzca a consecuencias social o económicamente significativas en caso de un ataque deliberado. , , , , , .
, , , . .
, , . , , , , , , , . , , , , , , .
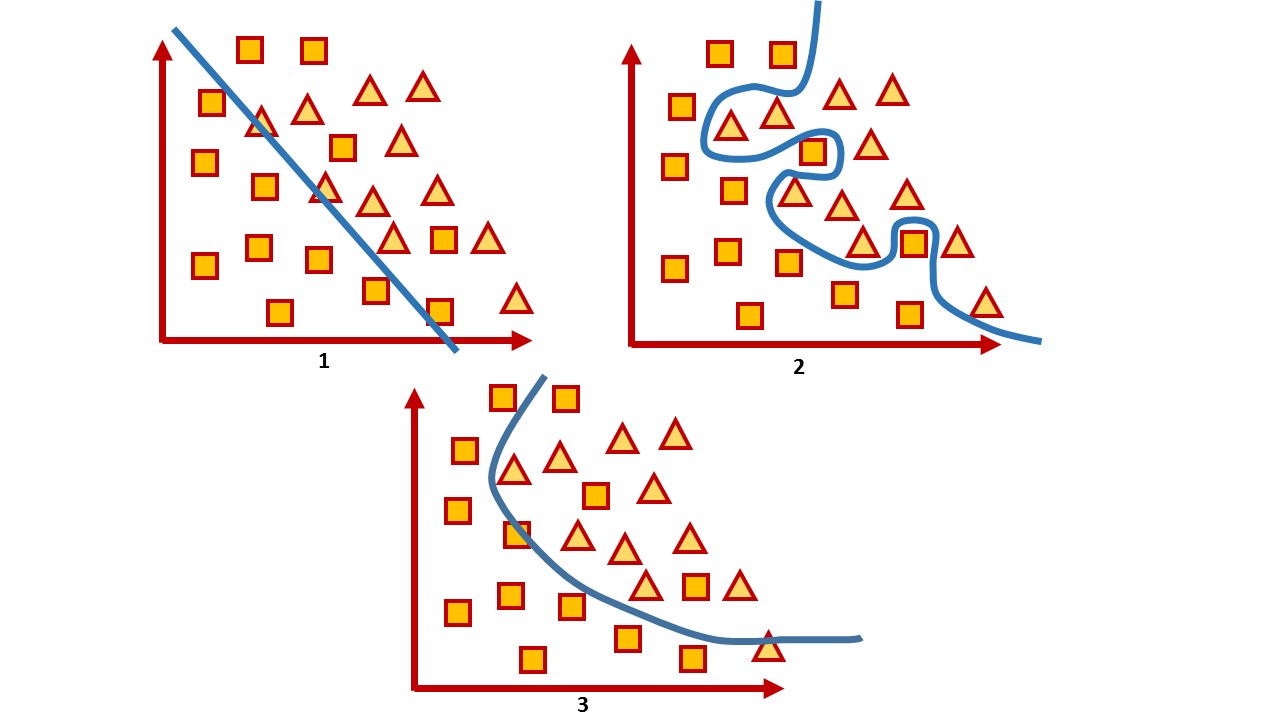
1 — , 2 — , 3 —
, , : . . , .
. , . , . 100%- - , .
- , — . , — , . , .
, , .
9. ?
. : , , , , .
, . . , . , , , «».
, - , . , , . - Twitter, Microsoft, .
? , , — , , . , , , — , , .
, , , « — , »?