Desarrollar pruebas de aplicaciones no es una experiencia agradable. Este proceso lleva mucho tiempo, requiere mucha concentración y es extremadamente demandado. El lenguaje Kotlin proporciona un conjunto de herramientas que hacen que sea bastante fácil construir su propio lenguaje orientado a problemas (DSL). Existe experiencia cuando Kotlin DSL reemplazó a los constructores y los métodos estáticos para probar el módulo de planificación de recursos, lo que hizo que agregar nuevas pruebas y respaldar las antiguas de una rutina fuera un proceso divertido.
En el curso del artículo, analizaremos todas las herramientas principales del arsenal del desarrollador y cómo se pueden combinar para resolver problemas de prueba. Iremos desde el diseño de la Prueba Ideal hasta el lanzamiento de la prueba más aproximada, limpia y comprensible para el sistema de planificación de recursos basado en Kotlin.
El artículo será útil para los ingenieros en ejercicio, aquellos que consideran el Kotlin como un lenguaje para escribir cómodamente pruebas compactas y aquellos que desean mejorar el proceso de prueba en su proyecto.
Este artículo se basa en una presentación de Ivan Osipov (
i_osipov ) en la conferencia JPoint. Narración adicional se lleva a cabo en su nombre. Ivan trabaja como programador en Haulmont. El producto principal de la compañía es CUBA, una plataforma para el desarrollo de empresas y diversas aplicaciones web. En particular, se están realizando proyectos de outsourcing en esta plataforma, entre los que recientemente hubo un proyecto en el campo de la educación, en el que Ivan se comprometió a construir un cronograma para una institución educativa. Dio la casualidad de que durante los últimos tres años Ivan ha estado trabajando con los planificadores de una forma u otra, y específicamente en Haulmont han estado probando este planificador durante un año.
Para aquellos que desean ejecutar ejemplos,
mantenga un enlace a GitHub . Debajo del enlace, encontrará todo el código que analizaremos, ejecutaremos y escribiremos hoy. ¡Abre el código y listo!

Hoy discutiremos:
- ¿Qué son los lenguajes orientados a problemas?
- lenguajes orientados a problemas incorporados;
- construir un horario para una institución educativa;
- cómo se prueba todo con Kotlin.
Hoy hablaré en detalle sobre las herramientas que tenemos en el lenguaje, le mostraré algunas demostraciones y redactaremos toda la prueba desde el principio hasta el final. Al mismo tiempo, me gustaría ser más objetivo, por lo que hablaré sobre algunas de las desventajas que identifiqué durante el desarrollo.
Comencemos hablando sobre el módulo de construcción de horarios. Entonces, la construcción del cronograma se lleva a cabo en varias etapas. Cada uno de estos pasos debe probarse por separado. Debe comprender que, a pesar de que los pasos son diferentes, tenemos un modelo de datos común.

Este proceso se puede representar de la siguiente manera: en la entrada hay algunos datos con un modelo común, en la salida hay un cronograma. Los datos se validan, filtran y luego se crean grupos de capacitación. Esto se refiere al área temática del horario de la institución educativa. En base a los grupos construidos y en base a otros datos, colocamos la lección. Hoy hablaremos solo sobre la última etapa, sobre la ubicación de las clases.

Un poco sobre probar el planificador.
En primer lugar, como ya entendió, las diferentes etapas deben probarse por separado. Uno puede seleccionar un proceso más o menos estándar de inicio de pruebas: hay inicialización de datos, hay un inicio del planificador, hay una verificación de los resultados de este planificador en sí. Hay una gran cantidad de casos comerciales diferentes que deben cubrirse y diferentes situaciones que deben tenerse en cuenta para que, al elaborar un cronograma, estas situaciones también persistan.
Un modelo a veces puede ser pesado, y para crear una sola entidad, es necesario inicializar cinco entidades adicionales, o incluso más. Por lo tanto, en total, se obtiene una gran cantidad de código, que escribimos una y otra vez para cada prueba. El soporte para tales pruebas lleva una cantidad considerable de tiempo. Si desea actualizar el modelo, y esto a veces sucede, la escala de los cambios afecta las pruebas.
Escribamos una prueba:

Escribamos la prueba más simple para que generalmente entiendas la imagen.
¿Qué le viene a la mente cuando piensa en las pruebas? Quizás estas son algunas pruebas primitivas de este tipo: crea una clase, crea un método en ella, la marca con la
prueba de anotación. Como resultado, usamos las capacidades de JUnit e inicializamos algunos datos, valores predeterminados, luego valores específicos de prueba, hacemos lo mismo para el resto del modelo y finalmente creamos un objeto de planificador, le transferimos nuestros datos, comenzamos, recibimos resultados y los verificamos. Proceso más o menos estándar. Pero obviamente hay duplicación de código en él. Lo primero que viene a la mente es la capacidad de poner todo en métodos estáticos. Dado que hay un montón de valores predeterminados, ¿por qué no ocultarlo?

Este es un buen primer paso para reducir la duplicación.

Mirando esto, entiendes que me gustaría mantener el modelo más compacto. Aquí tenemos un patrón generador en el que, en algún lugar debajo del capó, se inicializa el valor predeterminado y los valores específicos de la prueba se inicializan allí mismo. Está mejorando, sin embargo, todavía estamos escribiendo el código repetitivo, y lo estamos escribiendo nuevamente cada vez. Imagine 200 pruebas: debe escribir estas tres líneas 200 veces. Obviamente, me gustaría deshacerme de esto de alguna manera. Desarrollando la idea, llegamos a un cierto límite. Entonces, por ejemplo, podemos crear un generador de patrones en general para todo.

Puede crear un planificador desde cero hasta el final, establecer todos los valores que necesitamos, comenzar a programar y todo es genial. Si observa en detalle este ejemplo y lo analiza en detalle, resulta que se está escribiendo una gran cantidad de código innecesario. Me gustaría hacer que las pruebas sean más legibles para que pueda echar un vistazo y comprender de inmediato, sin profundizar en los patrones, etc.
Entonces, tenemos un código innecesario. Las matemáticas simples sugieren que hay un 55% más de letras de las que necesitamos, y de alguna manera me gustaría alejarme de ellas.

Después de un tiempo, el soporte para nuestras pruebas resulta ser más costoso, ya que debe admitir más código. A veces, si no hacemos ningún esfuerzo, la legibilidad deja mucho que desear o resulta aceptable, pero nos gustaría aún más. Quizás más adelante comencemos a agregar algún tipo de marcos, bibliotecas, para que las pruebas sean más fáciles de escribir. Debido a esto, aumentamos el nivel de entrada para probar nuestra aplicación. Aquí tenemos una aplicación ya complicada, el nivel de entrada en sus pruebas es significativo y lo estamos aumentando aún más.
Prueba perfecta
Es genial decir cuán malo es todo, pero pensemos en cómo sería muy bueno. Un ejemplo ideal que nos gustaría obtener como resultado:

Imagine que hay una declaración en la que decimos que esta es una prueba con un nombre específico, y queremos usar un espacio para separar las palabras en el nombre, no CamelCase. Estamos creando un cronograma, tenemos algunos datos y se verifican los resultados del planificador. Dado que trabajamos principalmente con Java, y todo el código de la aplicación principal está escrito en este lenguaje, me gustaría tener capacidades de prueba compatibles. Me gustaría inicializar los datos lo más obvio posible para el lector. Quiero inicializar algunos datos comunes y parte del modelo que necesitamos. Por ejemplo, cree estudiantes, maestros y describa cuándo están disponibles. Este es nuestro ejemplo perfecto.
Lenguaje específico de dominio

Mirándolo todo, parece que parece un lenguaje orientado a problemas. Necesitas entender qué es y cuál es la diferencia. Los idiomas se pueden dividir en dos tipos: lenguajes de propósito general (lo que escribimos constantemente, resolver absolutamente cualquier tarea y hacer frente a absolutamente todo) y lenguajes orientados a problemas. Entonces, por ejemplo, SQL nos ayuda a extraer datos de la base de datos perfectamente, y algunos otros lenguajes también ayudan a resolver otros problemas específicos.

Una forma de implementar lenguajes orientados a problemas es lenguajes integrados, o internos. Dichos idiomas se implementan sobre la base de un lenguaje de propósito general. Es decir, varias construcciones de nuestro lenguaje de propósito general forman algo así como una base: eso es lo que usamos cuando trabajamos con un lenguaje orientado a problemas. En este caso, por supuesto, surge una oportunidad en un lenguaje orientado a problemas para usar todas las características y características que provienen de un lenguaje de propósito general.

Nuevamente, eche un vistazo a nuestro ejemplo perfecto y piense en qué idioma elegir. Tenemos tres opciones.

La primera opción es Groovy. Un lenguaje maravilloso y dinámico que se ha demostrado en la construcción de lenguajes orientados a problemas. Nuevamente, puede dar un ejemplo de un archivo de compilación en Gradle, que muchos de nosotros usamos. También está Scala, que tiene una gran cantidad de oportunidades para la implementación de algo propio. Y finalmente, está Kotlin, que también nos ayuda a construir un lenguaje orientado a los problemas, y hoy se discutirá. No quisiera engendrar guerras y comparar Kotlin con otra cosa, más bien, queda en tu conciencia. Hoy les mostraré lo que Kotlin tiene para desarrollar lenguajes orientados a problemas. Cuando desee comparar esto y decir que un idioma es mejor, puede volver a este artículo y ver fácilmente la diferencia.

¿Qué nos da Kotlin para desarrollar un lenguaje orientado a problemas?
En primer lugar, es un tipeo estático, y todo lo que se deriva de esto. En la etapa de compilación, se detectan una gran cantidad de problemas, y esto ahorra mucho, especialmente en el caso de que no desee tener problemas relacionados con la sintaxis y la escritura en las pruebas.
Entonces, hay un gran sistema de inferencia de tipos que proviene de Kotlin. Esto es maravilloso, porque no hay necesidad de escribir ningún tipo una y otra vez, el compilador muestra todo con una explosión.
En tercer lugar, existe un excelente soporte para el entorno de desarrollo, y esto no es sorprendente, porque la misma compañía crea el entorno de desarrollo principal para hoy, y lo hace Kotlin.
Finalmente, dentro de DSL, obviamente podemos usar Kotlin. En mi opinión subjetiva, admitir DSL es mucho más fácil que admitir clases de utilidad. Como verá más adelante, la legibilidad es ligeramente mejor que la de los constructores. Lo que quiero decir con "mejor": obtienes un poco menos de sintaxis que necesitas escribir; alguien que lea tu lenguaje orientado a problemas lo tomará más rápido. Finalmente, ¡escribir tu bicicleta es mucho más divertido! Pero, de hecho, implementar un lenguaje orientado a problemas es mucho más fácil que aprender un nuevo marco.
Recordaré una vez más el
enlace a GitHub , si desea escribir más demos, puede ingresar y recoger el código del enlace.
Diseñando el ideal en Kotlin
Pasemos a diseñar nuestro ideal, pero ya en Kotlin. Echa un vistazo a nuestro ejemplo:

Y en etapas comenzaremos a reconstruirlo.
Tenemos una prueba que se convierte en una función en Kotlin, que se puede nombrar usando espacios.

Lo marcaremos con la anotación de
prueba , que está disponible para nosotros desde JUnit. En Kotlin, puede usar la forma abreviada para escribir funciones y, a través de
=, deshacerse de llaves extra para la función en sí.
Horario nos convertimos en un bloque. Lo mismo sucede con muchos diseños, ya que todavía trabajamos en Kotlin.

Pasemos al resto. Las llaves aparecen nuevamente, no las eliminaremos, pero al menos tratemos de acercarnos a nuestro ejemplo. Al construir construcciones con espacios, podríamos de alguna manera refinarnos y hacerlos de alguna manera diferentes, pero me parece que es mejor hacer los métodos habituales que encapsularán el procesamiento, pero en general esto será obvio para el usuario .

Nuestro alumno se convierte en un bloque en el que trabajamos con propiedades, con métodos, y continuaremos analizando esto con usted.

Finalmente, los profesores. Aquí tenemos algunos bloques anidados.

En el siguiente código, pasamos a los cheques. Necesitamos verificaciones de compatibilidad con lenguajes Java, y sí, Kotlin es compatible con Java.

Arsenal de desarrollo de DSL en Kotlin

Pasemos a la lista de herramientas que tenemos. Aquí traje una tableta, tal vez enumera todo lo que se necesita para desarrollar lenguajes orientados a problemas en Kotlin. Puede volver a ella de vez en cuando y refrescar su memoria.
La tabla muestra alguna comparación de la sintaxis orientada a problemas y la sintaxis habitual que está disponible en el lenguaje.
Lambdas en Kotlin
val lambda: () -> Unit = { }Comencemos con el ladrillo más básico que tenemos en Kotlin: estas son lambdas.
Hoy, por tipo lambda, me referiré solo a un tipo funcional. Las lambdas se denotan de la siguiente manera:
( ) -> .
Inicializamos el lambda con la ayuda de llaves, dentro de ellas podemos escribir un código que se llamará. Es decir, una lambda, de hecho, solo oculta este código en sí mismo. Ejecutar tal lambda parece una llamada a función, solo paréntesis.

Si queremos pasar algún tipo de parámetro, en primer lugar, debemos describirlo en el tipo.
En segundo lugar, tenemos acceso al identificador predeterminado, que podemos usar, sin embargo, si esto no nos conviene de alguna manera, podemos establecer nuestro propio nombre de parámetro y usarlos.

Al mismo tiempo, podemos omitir el uso de este parámetro y usar el guión bajo para no producir identificadores. En este caso, para ignorar el identificador, sería posible no escribir nada, pero en el caso general de varios parámetros está el mencionado "_".

Si queremos pasar más de un parámetro, necesitamos definir explícitamente sus identificadores.

Finalmente, qué sucederá si intentamos pasar la lambda a alguna función y ejecutarla allí. Se ve en la aproximación inicial de la siguiente manera: tenemos una función a la que pasamos lambda entre llaves, y si en Kotlin lambda se escribe como el último parámetro, podemos sacarlo de estos corchetes.

Si no queda nada entre los corchetes, podemos eliminar los corchetes. Aquellos familiarizados con Groovy deberían estar familiarizados con esto.

¿Dónde se aplica esto? Absolutamente en todas partes. Es decir, las llaves muy rizadas de las que ya hemos hablado, las usamos, estas son las mismas lambdas.

Ahora veamos una de las variedades de lambdas, las llamo lambdas con contexto. Encontrará algunos otros nombres, por ejemplo, lambda con receptor, y difieren de los lambdas ordinarios al declarar un tipo de la siguiente manera: a la izquierda, agregamos alguna clase de contexto, puede ser cualquier clase.

¿Para qué es esto? Esto es necesario para que dentro de la lambda tengamos acceso a esta palabra clave: esta es la palabra clave en sí misma, nos dice nuestro contexto, es decir, a algún objeto que vinculamos a nuestra lambda. Entonces, por ejemplo, podemos crear una lambda que generará alguna cadena, naturalmente, usaremos la clase de cadena para declarar un contexto y la llamada de tal lambda se verá así:



Si desea pasar un contexto como parámetro, también puede hacerlo. Sin embargo, no podemos transmitir completamente el contexto, es decir, ¡una lambda con un contexto requiere atención! - contexto, sí. ¿Qué sucede si comenzamos a pasar una lambda con un contexto a algún método? Aquí miramos nuevamente nuestro método exec:

Cámbiele el nombre al método del alumno; nada ha cambiado:

Por lo tanto, nos movemos gradualmente a nuestra construcción, la construcción del estudiante, que debajo de las llaves oculta toda inicialización.

Vamos a resolverlo. Tenemos algún tipo de función de estudiante que toma una lambda con el contexto del estudiante.

Obviamente, necesitamos contexto.

Aquí creamos un objeto y ejecutamos este lambda en él.

Como resultado, también podemos inicializar algunos valores predeterminados antes de iniciar el lambda, por lo que encapsulamos todo lo que necesitamos para la función.

Debido a esto, dentro de la lambda, tenemos acceso a esta palabra clave, por eso, probablemente, hay lambdas con contexto.

Naturalmente, podemos deshacernos de esta palabra clave y tenemos la oportunidad de escribir tales construcciones.

Nuevamente, si no solo tenemos métodos patentados, sino también algunos, también podemos llamarlos, parece bastante natural.

Solicitud
Todas estas lambdas en el código son lambdas de contexto. Hay una gran cantidad de contextos, se cruzan de una forma u otra y nos permiten construir nuestro lenguaje orientado a los problemas.

Resumiendo las lambdas: tenemos lambdas ordinarias, las tenemos con el contexto, y esas y otras se pueden usar.

Operadores
Kotlin tiene un conjunto limitado de operadores que puede anular mediante convenciones y la palabra clave operador.
Veamos al profesor y su accesibilidad. Supongamos que decimos que el maestro trabaja los lunes a partir de las 8 am durante 1 hora. También queremos decir que, además de esta hora, funciona desde las 13.00 por 1 hora. Me gustaría expresar esto usando el operador
+ . ¿Cómo se puede hacer esto?

Hay algún método de disponibilidad que acepta una lambda con un contexto de tabla de
AvailabilityTable . Esto significa que hay alguna clase que se llama así, y el método del lunes se declara en esta clase. Este método devuelve
DayPointer desde necesita adjuntar nuestro operador a algo.

Veamos qué es DayPointer. Este es un indicador de la tabla de disponibilidad de algunos maestros, y el día está en su horario. También tenemos una función de tiempo que de alguna manera convertirá algunas filas en índices enteros: en Kotlin tenemos una clase
IntRange para esto.
A la izquierda está
DayPointer , a la derecha está el tiempo, y nos gustaría combinarlos con el operador
+ . Para hacer esto, puede crear nuestro operador en la clase
DayPointer . Tomará un rango de valores de tipo Int y devolverá
DayPointer para que podamos encadenar nuestro DSL una y otra vez.
Ahora, echemos un vistazo al diseño clave con el que todo comienza, con el que comienza nuestro DSL. Su implementación es ligeramente diferente, y ahora lo resolveremos.
Kotlin tiene un concepto singleton integrado en el lenguaje. Para hacer esto, en lugar de la palabra clave class, se usa la palabra clave
object . Si creamos un método dentro de un singleton, entonces podemos acceder a él de tal manera que no sea necesario crear una instancia de esta clase nuevamente. Simplemente nos referimos a él como un método estático en una clase.

Si observa el resultado de la descompilación (es decir, en el entorno de desarrollo, haga clic en Herramientas -> Kotlin -> Mostrar código de bytes de Kotlin -> Descompilar), puede ver la siguiente implementación de singleton:

Esta es solo una clase ordinaria, y aquí no sucede nada sobrenatural.
Otra herramienta interesante es la declaración de
invoke . Imagine que tenemos algo de clase A, tenemos su instancia, y nos gustaría ejecutar esta instancia, es decir, poner paréntesis en un objeto de esta clase, y podemos hacerlo gracias al operador de
invoke .

De hecho, los paréntesis nos permiten llamar al método invoke y tiene un modificador de operador. Si pasamos una lambda con contexto a este operador, obtenemos tal construcción.

Crear instancias cada vez es otra actividad, por lo que podemos combinar conocimientos previos y actuales.
Hagamos un singleton, llámelo horario, dentro de él declararemos el operador de invocación, dentro crearemos un contexto y aceptará una lambda con el contexto que creamos aquí. Resulta un único punto de entrada en nuestro DSL y, como resultado, obtenemos la misma construcción: horario con llaves.

Bueno, hablamos sobre el horario, echemos un vistazo a nuestros cheques.
Tenemos maestros, hemos creado algún tipo de horario, y queremos comprobar que en el horario de este maestro en un día determinado en una determinada lección hay algún objeto con el que trabajaremos.

Me gustaría usar corchetes y acceder a nuestro horario de una manera que parezca visualmente el acceso a las matrices.

Esto se puede hacer usando el operador: get / set:

Aquí no estamos haciendo nada nuevo, solo siga las convenciones. En el caso del operador set, necesitamos pasar adicionalmente los valores a nuestro método:

Entonces, los corchetes para leer se convierten en get, y los corchetes a través de los cuales asignamos se convierten en set.
Demostración: objeto, operadores
Puede leer más texto o
ver el video aquí . El video tiene una hora de inicio clara, pero no se especifica una hora de finalización; en principio, una vez iniciado, puede verlo antes del final del artículo.
Por conveniencia, resumiré brevemente la esencia del video directamente en el texto.
Escribamos una prueba. Tenemos algún objeto de programación, y si vamos a su implementación a través de ctrl + b, veremos todo lo que mencioné antes.

Dentro del objeto de programación, queremos inicializar los datos, luego realizar algunas comprobaciones, y dentro de los datos, nos gustaría decir que:
- nuestra escuela está abierta desde las 8 de la mañana;
- hay un cierto conjunto de elementos para los cuales construiremos un cronograma;
- hay algunos maestros que han descrito algún tipo de accesibilidad;
- tener un estudiante
- en principio, para un estudiante solo necesitamos decir que está estudiando un tema específico.

Y aquí uno de los inconvenientes de Kotlin y los lenguajes orientados a problemas se manifiesta en principio: es bastante difícil abordar algunos objetos que creamos anteriormente. En esta demostración, indicaré todo como índices, es decir, rus es el índice 0, las matemáticas son el índice 2. Y el profesor, naturalmente, también lidera algo. No solo va a trabajar, sino que se dedica a algo. Para los lectores de este artículo, me gustaría ofrecer una opción más para el direccionamiento, puede crear etiquetas únicas y almacenar entidades en Map en ellas, y cuando necesite acceder a una de ellas, siempre puede encontrarla por etiqueta. Continúe desmontando el DSL.
Aquí, lo que debe tenerse en cuenta: en primer lugar, tenemos el operador +, a cuya implementación también podemos ir y ver que realmente tenemos la clase DayPointer, que nos ayuda a vincular todo esto con la ayuda del operador.
Y gracias al hecho de que tenemos acceso al contexto, el entorno de desarrollo nos dice que en nuestro contexto a través de esta palabra clave, tenemos acceso a alguna colección y la usaremos.

Es decir, tenemos una colección de eventos. El evento encapsula un conjunto de propiedades, por ejemplo: que hay un estudiante, un maestro, qué día se reúnen en qué lección.

Seguimos escribiendo la prueba aún más.

Aquí, nuevamente, usamos el operador get; no es tan fácil llegar a su implementación, pero podemos hacerlo.

De hecho, solo seguimos el acuerdo, por lo que tenemos acceso a este diseño.
Volvamos a la presentación y continuemos la conversación sobre Kotlin. Queríamos que se implementaran los controles en Kotlin, y pasamos por estos eventos:

Un evento es esencialmente un conjunto encapsulado de 4 propiedades. Me gustaría descomponer este evento en un conjunto de propiedades, como una tupla. En ruso, dicha construcción se llama
declaración múltiple (encontré solo una traducción de este tipo), o
declaración de desestructuración , y funciona de la siguiente manera:

Si alguno de ustedes no está familiarizado con esta característica, funciona así: puede tomar el evento y, en el lugar donde se usa, utilizando paréntesis, descomponerlo en un conjunto de propiedades.

Esto funciona porque tenemos un método de componentes, es decir, es un método generado por el compilador gracias al modificador de datos que escribimos antes de la clase.

Junto con esto, una gran cantidad de otros métodos vuelan hacia nosotros. Estamos interesados en el método componentN, que se genera en función de las propiedades enumeradas en la lista de parámetros del constructor primario.

Si no tuviéramos un modificador de datos, sería necesario escribir manualmente un operador que haga lo mismo.


Entonces, tenemos algunos métodos de componentes, y se descomponen en tal llamada:

En esencia, es el azúcar sintáctico sobre la llamada de varios métodos.
Ya hemos hablado sobre alguna tabla de disponibilidad y, de hecho, te engañé. Sucede No existe ninguna
avaiabilityTable , no está en la naturaleza, pero existe una matriz de valores booleanos.

No se necesita ninguna clase adicional: puede tomar la matriz de valores booleanos y cambiarle el nombre para mayor claridad. Esto se puede hacer usando los llamados
typealias o
type alias . Desafortunadamente, no obtenemos ninguna bonificación adicional de esto, es solo un cambio de nombre. Si toma la disponibilidad y cambia el nombre a la matriz de valores booleanos, nada cambiará en absoluto. El código funcionó y funcionará.
Echemos un vistazo al profesor, esta es exactamente esta accesibilidad y hablemos de él:
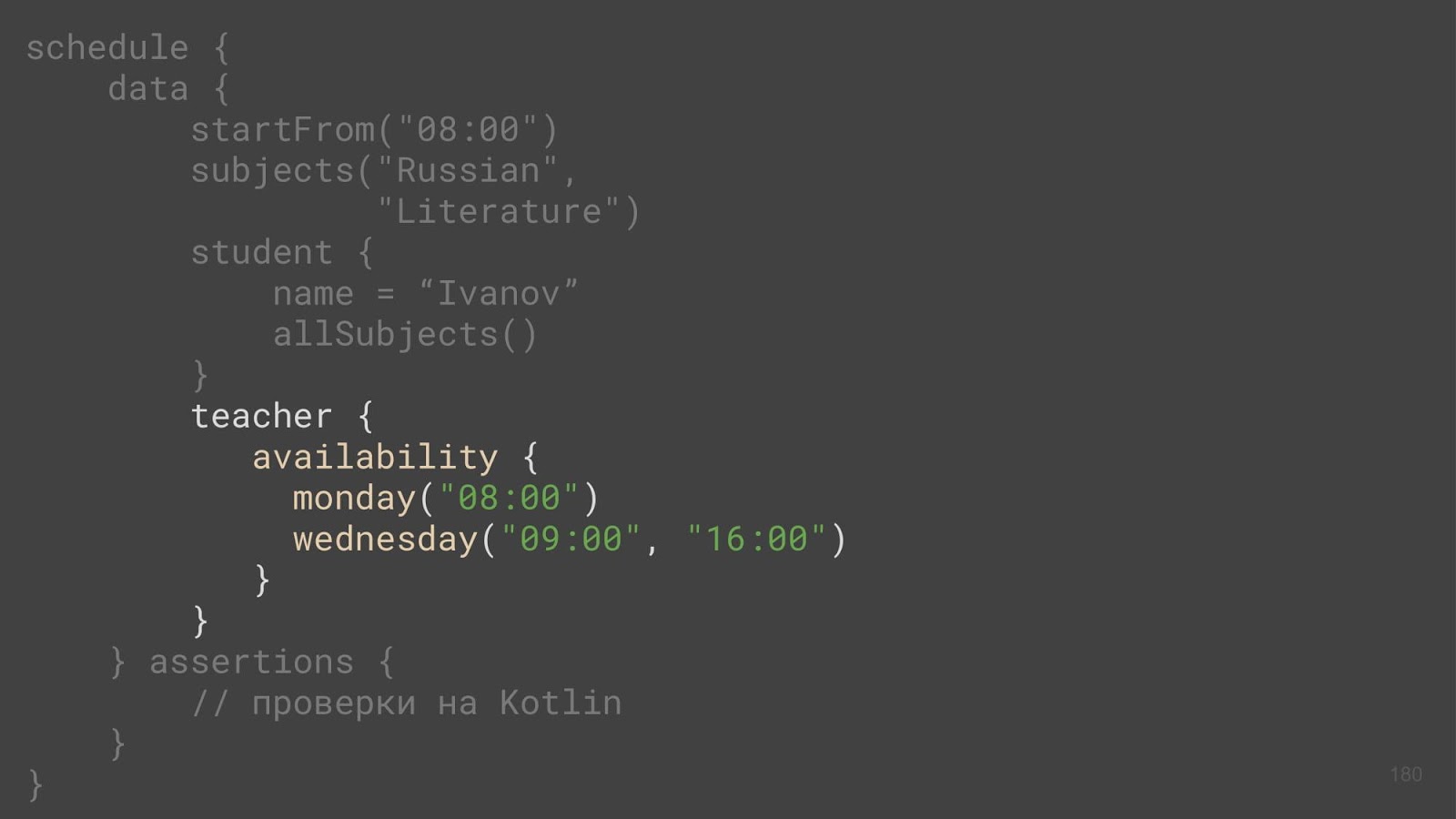
Tenemos un maestro, y el método de disponibilidad se llama (¿aún no has perdido el hilo del razonamiento? :-). ¿De donde vino? Es decir, un maestro es algún tipo de entidad que tiene una clase, y este es un código comercial. Y no puede haber un método adicional.

Este método aparece debido a las funciones de extensión. Tomamos y sujetamos a nuestra clase alguna otra función que podemos ejecutar en objetos de esta clase.
Si pasamos algo de lambda a esta función, y luego lo ejecutamos en una propiedad existente, entonces todo está bien: el método de disponibilidad en su implementación inicializa la propiedad de disponibilidad. Puedes deshacerte de esto. Ya conocemos el operador de invocación, que se puede adjuntar a un tipo y, al mismo tiempo, ser una función de extensión. Si le pasa una lambda a este operador, allí mismo, en la palabra clave this, podemos ejecutar esta lambda. Como resultado, cuando trabajamos con un maestro, la accesibilidad es una propiedad del maestro y no un método adicional, y aquí no ocurre ningún rassynchron.

Como beneficio adicional, se pueden crear funciones de extensión para tipos anulables. Esto es bueno, porque si hay una variable con un tipo anulable que contiene un valor nulo, nuestra función ya está lista para esto y no caerá de NullPointer. Dentro de esta función, esto puede ser nulo y debe manejarse.

Resumiendo las funciones de extensión: debe comprender que solo hay acceso a la API pública de la clase, y que la clase en sí no se modifica de ninguna manera. Una función de extensión está determinada por el tipo de variable y no por el tipo real. Además, un miembro de la clase con la misma firma tendrá prioridad. Puede crear una función de extensión para una clase, pero escríbala en una clase completamente diferente, y dentro de esta función de extensión habrá acceso a dos contextos simultáneamente. Resulta la intersección de contextos. Y finalmente, esta es una gran oportunidad para llevar y sujetar a los operadores en general a cualquier lugar donde queramos.

La siguiente herramienta son las funciones infijadas. Otro martillo peligroso en manos del desarrollador. ¿Por qué peligroso? Lo que ves es código. Tal código se puede escribir en Kotlin, ¡y no lo hagas! Por favor no lo hagas. Sin embargo, el enfoque es bueno. Gracias a esto, es posible deshacerse de puntos, corchetes, de toda esa sintaxis ruidosa, de la que estamos tratando de alejarnos lo más posible y hacer que nuestro código sea un poco más limpio.

Como funciona Tomemos un ejemplo más simple: una variable entera. Creemos una función de extensión para él, llamémosle shouldBeEqual, hará algo, pero esto no es interesante. Si agregamos el modificador infijo a la izquierda, es suficiente. Puede deshacerse de los puntos y corchetes, pero hay algunos matices.

Sobre esta base, solo se implementa la construcción de datos y aserciones, unidas entre sí.

Vamos a resolverlo. Tenemos un SchedulingContext: el contexto general del inicio de la programación. Hay una función de datos que devuelve el resultado de esta planificación. Al mismo tiempo, creamos una función de extensión y al mismo tiempo las aserciones de la función infija, que lanzará una lambda que verifica nuestros valores.

Hay un sujeto, un objeto y una acción, y de alguna manera necesitas conectarlos. En este caso, el resultado de ejecutar datos con llaves es el tema. La lambda que pasamos al método de aserciones es un objeto, y el método de aserciones en sí mismo es una acción. Todo esto parece mantenerse unido.

Hablando de la función infijo, es importante entender que este es un paso para deshacerse de la sintaxis ruidosa. Sin embargo, debemos tener un sujeto y un objeto de esta acción, y debemos usar el modificador infijo. Puede haber exactamente un parámetro, es decir, cero parámetros no pueden ser, dos no pueden ser, tres, bueno, entiendes. Puede pasar, por ejemplo, lambdas a esta función, y de esta manera se obtienen construcciones que no ha visto antes.
Pasemos a la próxima demostración. Es mejor mirar el video y no leer el texto.
Ahora todo parece listo: la función infijo que viste, la extensión de la función que viste, la declaración de desestructuración está lista.
Volvamos a nuestra presentación, y aquí pasaremos a un punto bastante importante al construir lenguajes orientados a problemas: lo que debe pensar es el control de contexto.

Hay situaciones en las que podemos tomar DSL y reutilizarlo dentro de él, pero no queremos hacer esto. Nuestro usuario (posiblemente un usuario inexperto) escribe datos dentro de los datos, y eso no tiene sentido. Nos gustaría de alguna manera prohibirle que haga esto.
Antes de la versión 1.1 de Kotlin, teníamos que hacer lo siguiente: en respuesta al hecho de que tenemos un método de datos en
SchedulingContext , tuvimos que crear otro método de datos en
DataContext , en el que aceptamos un lambda (aunque sin implementación), debemos marcar este método anotación
@Deprecated y decirle al compilador que no compile esto. Verá que este método comienza; no compile. Usando este enfoque, incluso recibimos algún mensaje significativo cuando escribimos código sin sentido.

Después de la versión Kotlin 1.1,
@DslMarker una maravillosa anotación
@DslMarker . Esta anotación es necesaria para marcar anotaciones derivadas. Con ellos, a su vez, marcaremos lenguajes orientados a problemas. Para cada lenguaje orientado a problemas, puede crear una anotación que marque
@DslMarker y colgarla en cada contexto que sea necesario. Ya no es necesario escribir métodos adicionales que se debe prohibir la compilación, todo funciona. No compilado
Sin embargo, existe un caso especial cuando trabajamos con nuestro modelo de negocio. Suele estar escrito en Java. , , . , ?
Student . – -, Kotlin .


- , : . , , .

.
- , . StudentContext. , . – , , , .
- – , , . . StudentContext , IStudent . , Student, IStudent StudentContext. DslMarker , .
- : deprecated . , . , . extension-, . .

, , , .

. . , , , . , . @DslMarker, . , @DslMarker, @Deprecated, , .
, :
 Primero, reutilice las partes DSL. Hoy ya ha visto que las entidades de direccionamiento creadas con DSL pueden ser problemáticas. Hay maneras de evitar esto, pero es aconsejable pensarlo de antemano para tener un plan para esto.
Primero, reutilice las partes DSL. Hoy ya ha visto que las entidades de direccionamiento creadas con DSL pueden ser problemáticas. Hay maneras de evitar esto, pero es aconsejable pensarlo de antemano para tener un plan para esto., - , , , , - , . ? for — . DSL, , , DSL. this it. , Kotlin 1.2.20 , . , it.
. DSL, --, , . , . , , , - , , . . , - , ..
, . , - – DSL. , Kotlin-, . , DSL , , Kotlin- . -? Gradle-, , , , - . - , , – , DSL.

DSL' , . , . , DSL , , . - – . -, - . , - .
, Kotlin. , , , , , , . (, - , ), , DSL , , , . .
«», . , Kotlin . , , . , — , .
, DSL. , - . DSL, , 10 , , - . DSL – , , .
, . , Telegram:
@ivan_osipov , Twitter:
@_osipov_ , :
i_osipov . .
Minuto de publicidad. JPoint — , 19-20 - Joker 2018 — Java-. . , .