Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3 ¿Me puede decir cuál es la falta de un enfoque de seguridad que utiliza una
página de guardia ?
Audiencia: ¡ lleva más tiempo!
Profesor: exactamente! Entonces, imagine que este montón es muy, muy pequeño, pero seleccioné una página completa para asegurarme de que esta pequeña cosa no fuera atacada por un puntero. Este es un proceso espacialmente intensivo, y las personas en realidad no implementan algo como esto en un entorno de trabajo. Esto puede ser útil para probar "errores", pero nunca lo haría para un programa real. Creo que ahora entiendes lo que es un depurador de memoria de
cerca eléctrica .
Audiencia: ¿Por qué la
página de protección debe ser tan grande?
Profesor: La razón es que generalmente dependen del hardware, como la protección a nivel de página, para determinar los tamaños de página. Para la mayoría de las computadoras, se asignan 2 páginas de 4 KB de tamaño para cada búfer asignado, totalizando 8 KB. Como el montón consiste en objetos, se asigna una página separada para cada función
malloc . En algunos modos, este depurador no devuelve el espacio reservado al programa, por lo que la
cerca eléctrica es muy voraz en términos de memoria y no debe compilarse con código de trabajo.
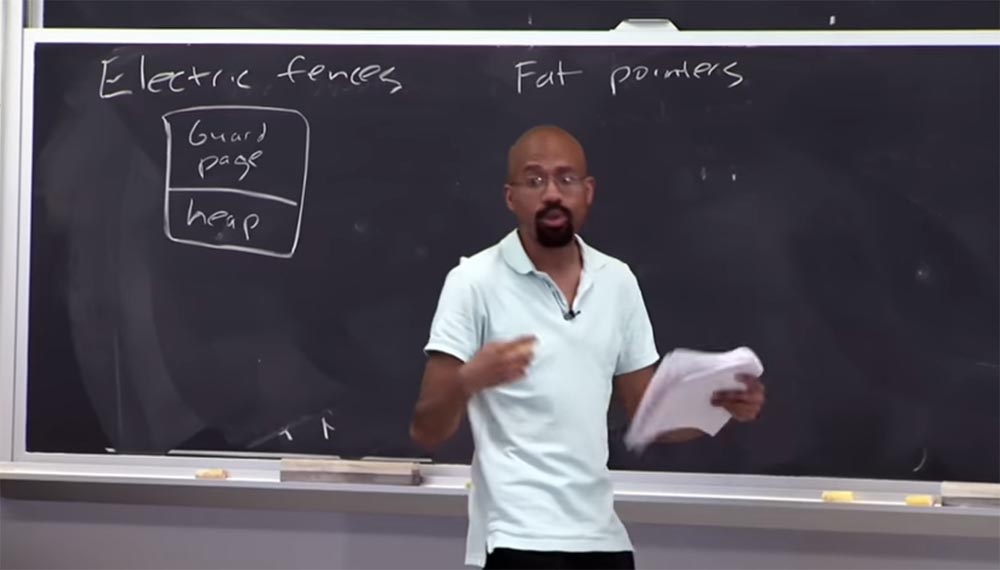
Otro enfoque de seguridad que vale la pena observar se llama
Fat Pointers , o "indicadores gruesos". En este caso, el término "grueso" significa que se adjunta una gran cantidad de datos al puntero. En este caso, la idea es que queremos cambiar la representación misma del puntero para incluir información sobre los límites en su composición.
Un puntero normal de 32 bits consta de 32 bits, y las direcciones se encuentran dentro de él. Si consideramos el "puntero grueso", entonces consta de 3 partes. La primera parte es una base de 4 bytes, a la que también se adjunta un final de 4 bytes. En la primera parte, el objeto comienza, en la segunda termina, y en la tercera, también de 4 bytes,
se encierra la dirección
cur . Y dentro de estos límites comunes hay un puntero.

Por lo tanto, cuando el compilador genera un código de acceso para este "puntero grueso", actualiza el contenido de la última parte de la
dirección cur y simultáneamente verifica el contenido de las dos primeras partes para asegurarse de que no pasó nada malo con el puntero durante el proceso de actualización.
Imagine que tengo este código:
int * ptr = malloc (8) , este es un puntero para el que se asignan 8 bytes. A continuación, tengo un
ciclo while que está a punto de asignar algún valor al puntero y luego sigue el incremento del puntero
ptr ++ . Cada vez que este código se ejecuta en la dirección actual del puntero de
dirección cur , verifica si el puntero se encuentra dentro de los límites especificados en la primera y segunda parte.
Este es el caso en el nuevo código que genera el compilador. Un grupo en línea a menudo plantea la pregunta de qué es el "código de herramienta". Este es el código que genera el compilador. Usted, como programador, solo ve lo que se muestra a la derecha: estas 4 líneas. Pero antes de esta operación, el compilador inserta un código C nuevo en la
dirección cur , asigna un valor al puntero y comprueba los límites cada vez.

Y si, al usar el nuevo código, el valor va más allá de los límites, la función se interrumpe. Esto se llama el "código de herramienta". Esto significa que toma el código fuente usando un programa C, luego agrega el nuevo código fuente C y luego compila el nuevo programa. Entonces, la idea básica detrás de
Fat Pointers es bastante simple.
Hay algunas desventajas en este enfoque. El mayor inconveniente es el gran tamaño del puntero. Y esto significa que no puede simplemente tomar el "puntero grueso" y pasarlo sin cambios, fuera de la biblioteca de shell. Debido a que puede haber una expectativa de que el puntero tiene un tamaño estándar, y el programa le proporcionará este tamaño, que "no encajará", por lo que todo explotará. También hay problemas si desea incluir punteros de este tipo en una
estructura o algo similar, ya que pueden cambiar el tamaño de la
estructura .
Por lo tanto, una cosa muy popular en el código C es tomar algo del tamaño de una
estructura y luego hacer algo basado en este tamaño: reservar espacio en disco para estructuras de este tamaño, y así sucesivamente.
Y una cosa más delicada es que estos punteros, por regla general, no pueden actualizarse de manera atómica. Para arquitecturas de 32 bits, es típico escribir una variable de 32 bits que sea atómica. Pero los "punteros gruesos" contienen 3 tamaños
enteros , por lo que si tiene un código que espera que el puntero tenga un valor atómico, podría tener problemas. Porque para hacer algunas de estas verificaciones, debe mirar la dirección actual y luego ver los tamaños, y luego puede que tenga que aumentarlos, y así sucesivamente. Por lo tanto, esto puede causar errores muy sutiles si usa código que intenta establecer paralelos entre punteros regulares y gruesos. Por lo tanto, puede usar
punteros de grasa en algunos casos, como las
cercas Electroc , pero los efectos secundarios de su uso son tan significativos que en la práctica normal estos enfoques no se usan.
Y ahora hablaremos sobre la verificación de límites en relación con la estructura de los datos en la sombra. La idea principal de la estructura es que sepa qué tan grande es cada objeto que va a colocar, es decir, sabe el tamaño que necesita reservar para este objeto. Entonces, por ejemplo, si tiene un puntero al que llama con la función
malloc , debe especificar el tamaño del objeto:
char xp = malloc (tamaño) .

Si tiene algo así como una variable estática como esta
char p [256] , el compilador puede determinar automáticamente cuáles deberían ser los límites para su ubicación.
Por lo tanto, para cada uno de estos punteros, debe insertar de alguna manera dos operaciones. Esto es principalmente aritmético, como
q = p + 7 , o algo similar. Esta inserción se realiza desreferenciando un enlace de tipo
deref * q = 'q' . Quizás se pregunte por qué no puede confiar en el enlace al pegar. ¿Por qué necesitamos hacer estas operaciones aritméticas? El hecho es que cuando usa C y c ++, tiene un puntero que apunta a una pasada al extremo válido del objeto a la derecha, después de lo cual lo usa como una condición de detención. Entonces, vas al objeto y tan pronto como alcanzas este puntero final, realmente detienes el ciclo o anulas la operación.
Entonces, si ignoramos la aritmética, siempre causamos un error grave, en el que el puntero va más allá de los límites, lo que en realidad puede interrumpir el trabajo de muchas aplicaciones. Entonces, no podemos simplemente insertar el enlace, porque ¿cómo sabes que esto sucede fuera de los límites establecidos? La aritmética nos permite decir si es así o no, y aquí todo será legal y correcto. Debido a que esta combinación con aritmética le permite rastrear dónde se encuentra el puntero en relación con su línea base original.
Entonces, la siguiente pregunta es: ¿cómo implementamos realmente la validación de fronteras? Porque necesitamos de alguna manera hacer coincidir la dirección específica del puntero con algún tipo de información de límite para ese puntero. Y, por lo tanto, muchas de sus decisiones anteriores usan cosas como, por ejemplo, una tabla hash o un árbol, lo que le permite realizar la búsqueda correcta. Entonces, dada la dirección del puntero, busco en esta estructura de datos y descubro qué límites tiene. Dados estos límites, decido si puedo dejar que la acción suceda o no. El problema es que esta es una búsqueda lenta, porque estas estructuras de datos se ramifican, y al examinar un árbol, debe examinar un montón de tales ramas hasta encontrar el valor correcto. E incluso si se trata de una tabla hash, debe seguir las cadenas de código, etc. Por lo tanto, necesitamos definir una estructura de datos muy efectiva que rastree sus límites, una que haga que esta verificación sea muy simple y clara. Así que vamos a hacerlo ahora mismo.
Pero antes de hacer eso, permíteme contarte brevemente cómo funciona el enfoque de
asignación de memoria de amigos . Porque esta es una de las cosas que a menudo se pregunta.
La asignación de memoria de amigos divide la memoria en particiones que son múltiplos de potencia de 2, e intenta asignar solicitudes de memoria en ellas. Veamos como funciona. Al principio, la
asignación de amigos trata la memoria no asignada como un gran bloque: este es el rectángulo superior de 128 bits. Luego, cuando solicita un bloque más pequeño para la asignación dinámica, intenta dividir este espacio de direcciones en partes en incrementos de 2 hasta que encuentre un bloque suficiente para sus necesidades.
Supongamos que llega una solicitud del tipo
a = malloc (28) , es decir, una solicitud para asignar 28 bytes. Tenemos un bloque de 128 bytes que es demasiado derrochador para asignarlo a esta solicitud. Por lo tanto, nuestro bloque se divide en dos bloques de 64 bytes: de 0 a 64 bytes y de 64 a 128 bytes. Y este tamaño también es grande para nuestra solicitud, por lo que
amigo nuevamente divide un bloque de 64 bytes en 2 partes y recibe 2 bloques de 32 bytes.

Menos es imposible, porque 28 bytes no caben, y 32 es el tamaño mínimo más adecuado. Entonces, este bloque de 32 bytes se asignará a nuestra dirección a. Supongamos que tenemos otra consulta para
b = malloc (50) .
Buddy verifica los bloques seleccionados, y dado que 50 es mayor que la mitad de 64, pero menor que 64, coloca el valor b en el bloque de la derecha.
Finalmente, tenemos otra solicitud de 20 bytes:
c = malloc (20) , este valor se coloca en el bloque del medio.
 Buddy
Buddy tiene una propiedad interesante: cuando liberas memoria en un bloque y al lado hay un bloque del mismo tamaño, después de liberar ambos bloques,
buddy combina dos bloques vecinos vacíos en uno.

Por ejemplo, cuando damos el comando
free © ,
liberaremos el bloque
del medio, pero la unión no sucederá, por lo que el bloque al lado seguirá ocupado. Pero después de liberar el primer bloque usando el comando
free (a) , ambos bloques se fusionarán en uno. Luego, si liberamos el valor de b, los bloques vecinos se combinan nuevamente y obtenemos un bloque completo de 128 bytes de tamaño, como era al principio. La ventaja de este enfoque es que puede encontrar fácilmente dónde está su amigo mediante la simple aritmética y determinar los límites de la memoria. Así es como funciona la asignación de memoria con el enfoque de
asignación de memoria de Buddy .
Todas mis conferencias a menudo se hacen la pregunta, ¿no es un enfoque tan derrochador? Imagine que al principio tenía una solicitud de 65 bytes, tendría que asignarle el bloque completo de 128 bytes. Sí, esto es un desperdicio, de hecho, no tiene memoria dinámica y ya no puede asignar recursos en el mismo bloque. Pero, de nuevo, esto es un compromiso, porque es muy fácil hacer un cálculo, cómo hacer una fusión y cosas por el estilo. Entonces, si desea una asignación de memoria más precisa, debe utilizar un enfoque diferente.
Entonces, ¿qué hace el sistema
Buggy Bounce Checking (BBC) ?

Ella realiza varios trucos, uno de los cuales es la separación del bloque de memoria en 2 partes, uno de los cuales contiene un objeto, y el segundo es una adición a él. Por lo tanto, tenemos 2 tipos de límites: los límites del objeto y los límites de la distribución de la memoria. La ventaja es que no es necesario almacenar la dirección base, y es posible una búsqueda rápida usando una tabla de líneas.
Todos nuestros tamaños de distribución son 2 a la potencia de
n , donde
n es un número entero. Este principio
2n se llama
poder de dos . Por lo tanto, no necesitamos muchos bits para imaginar cuán grande es un tamaño de distribución particular. Por ejemplo, si el tamaño del clúster es 16, solo necesita seleccionar 4 bits: este es el concepto de un logaritmo, es decir, 4 es un exponente de
n , en el que necesita elevar el número 2 para obtener 16.
Este es un enfoque bastante económico para la asignación de memoria, porque se usa el número mínimo de bytes, pero debe ser un múltiplo de 2, es decir, puede tener 16 o 32, pero no 33 bytes. Además, la
comprobación de rebote de Buggy le permite almacenar información sobre valores límite en una matriz lineal (1 byte por registro) y le permite asignar memoria en 1 ranura con un tamaño de 16 bytes. asignar memoria con granularidad de ranura. ¿Qué significa esto?

Si tenemos una ranura de 16 bytes donde vamos a poner el valor
p = malloc (16) , entonces el valor en la tabla se verá como
table [p / slot.size] = 4 .

Supongamos que ahora necesitamos colocar un valor de 32 bytes en tamaño
p = malloc (32) . Necesitamos actualizar la tabla de bordes para que coincida con el nuevo tamaño. Y esto se hace dos veces: primero como
tabla [p / slot.size] = 5 , y luego como
tabla [(p / slot.size) + 1] = 5 - la primera vez para la primera ranura, que se asigna para esta memoria, y la segunda veces - para la segunda ranura. Así asignamos 32 bytes de memoria. Así es como se ve el registro de distribución de tamaños. Por lo tanto, para dos ranuras de asignación de memoria, la tabla de límites se actualiza dos veces. ¿Eso está claro? Este ejemplo está destinado a personas que dudan si los registros y las tablas tienen un significado o no. Porque las tablas se multiplican cada vez que ocurre la asignación de memoria.
Veamos qué pasa con la tabla de borde. Supongamos que tenemos un código C que se ve así:
p '= p + i , es decir, el puntero
p' se obtiene de
p agregando alguna variable
i . Entonces, ¿cómo obtenemos el tamaño de memoria asignado para
p ? Para hacer esto, mira la tabla usando las siguientes condiciones lógicas:
size = 1 << table [p >> log of slot_size]
A la derecha tenemos el tamaño de los datos asignados para
p , que debería ser 1. Luego lo mueve hacia la izquierda y mira la tabla, toma este tamaño de puntero, luego se mueve hacia la derecha, donde se encuentra el registro de la tabla de tamaño de ranura. Si la aritmética funciona, entonces vinculamos correctamente el puntero a la tabla de borde. Es decir, el tamaño del puntero debe ser mayor que 1, pero menor que el tamaño de la ranura. A la izquierda tenemos el valor, y a la derecha, el tamaño de la ranura y el valor del puntero se encuentra entre ellos.
Supongamos que el tamaño del puntero es de 32 bytes, luego en la tabla, dentro de los corchetes, tendremos el número 5.
Supongamos que queremos encontrar la palabra clave base de este puntero:
base = p & n (tamaño - 1) . Lo que vamos a hacer nos da una cierta masa, y esta masa nos permitirá restaurar la
base ubicada aquí. Imagine que nuestro tamaño es 16, en binario es 16 = ... 0010000. La elipsis significa que todavía hay muchos ceros, pero estamos interesados en esta unidad y los ceros detrás de ella. Si consideramos (16-1), entonces se ve así: (16-1) = ... 0001111. En código binario, el inverso de esto se verá así: ~ (16-1) ... 1110000.
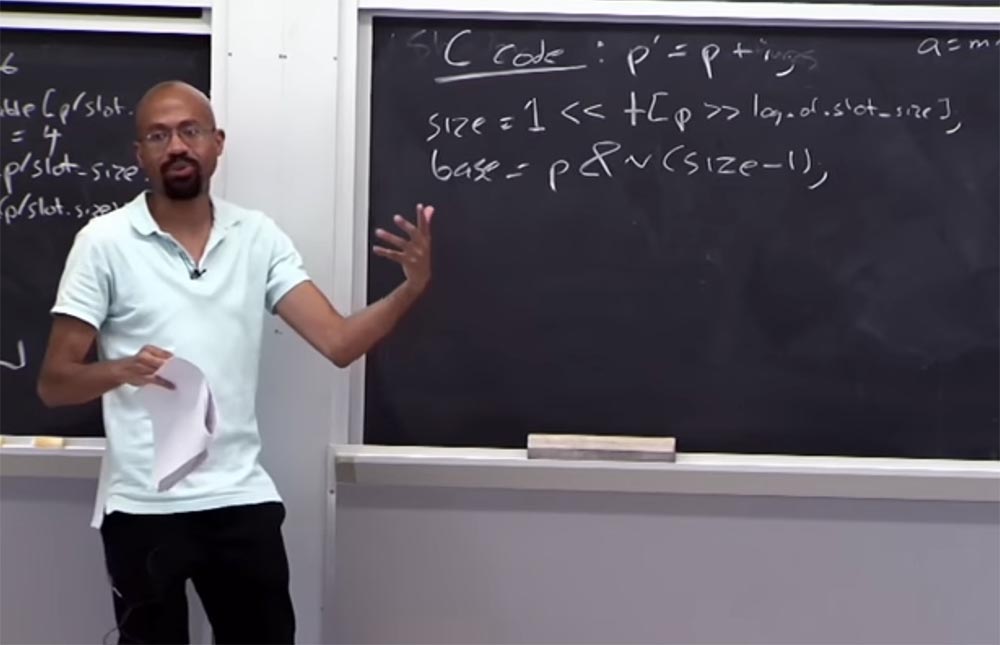

Por lo tanto, esto nos permite borrar básicamente el bit, que se representará esencialmente desde el puntero actual y nos dará su
base . Gracias a esto, será muy simple para nosotros verificar si este puntero está dentro de los límites. Entonces podemos simplemente verificar que
(p ')> = base y si el valor (
p' - base) es más pequeño que el tamaño seleccionado.

Es bastante sencillo averiguar si el puntero está dentro de los límites de la memoria. No voy a entrar en detalles; basta con decir que toda la aritmética binaria se resuelve de la misma manera. Dichos trucos le permiten evitar cálculos más complejos.
Hay una quinta propiedad más de la
comprobación de rebote de
Buggy : utiliza un sistema de memoria virtual para evitar ir más allá de los límites establecidos para el puntero. La idea principal es que si tenemos dicha aritmética para el puntero con el que determinamos la salida, entonces podemos establecer un bit de alto orden para el puntero.

Al hacerlo, garantizamos que desreferenciar el puntero no causará problemas de hardware. Establecer el
bit de alto orden por sí solo no causa problemas; la desreferenciación del puntero puede causar un problema.
La versión completa del curso está disponible
aquí .
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?