¿Qué es más desagradable que la "prueba roja"? La prueba es verde o roja, y no está claro por qué. En nuestra conferencia Heisenbug 2017 en Moscú,
Andrei Solntsev (Codeborne) habló sobre por qué podrían surgir y cómo reducir su número. Los ejemplos en su informe son tales que siente el dolor directamente en la piel cuando choca con ellos. Y los consejos son útiles, y vale la pena conocer tanto a los evaluadores como a los desarrolladores. Hay algo inesperado: puedes descubrir cómo a veces puedes resolver un problema si te separas de la pantalla y juegas cubos con tu hija.
Como resultado, el público agradeció el informe, y decidimos no solo publicar el video, sino también hacer una versión de texto del informe para Habr.
En mi opinión, las pruebas escamosas son el tema más relevante en el mundo de la automatización. Porque la pregunta "¿qué se está haciendo en el mundo, cómo te va con la automatización?" todos responden: "¡No hay estabilidad! Nuestras pruebas caen periódicamente ".
Hiciste una prueba en tu casa, es verde, otros dos días verde, y luego una vez y de repente cayó sobre Jenkins. Intenta repetirlo, iniciarlo y vuelve a estar verde. Y al final, nunca se sabe: ¿es un error o es solo una prueba de glucano? Y cada vez que necesitas entender.
A menudo, después de un lanzamiento nocturno de pruebas en Jenkins, el probador primero ve "30 pruebas han caído, debe estudiar", pero todos saben lo que sucede después ...

Usted, por supuesto, adivinó qué palabra indecente disfrazó: "Reiniciaré". Como, "hoy no hay renuencia a entender ..." Así es como suele suceder, y es un verdadero desastre.
No hay estadísticas exactas, pero a menudo escuché de diferentes personas que tienen alrededor del 30% de las pruebas, escamosas. En términos generales, lanzan un millar, de los cuales 300 son periódicamente rojos, y luego comprueban con sus manos si realmente cayeron.
Google publicó
un artículo hace un par de años: dice que tienen un 1,5% de pruebas escamosas y cuenta cómo luchan para reducir su número. Puedo presumir un poco y decir que mi proyecto en Codeborne es ahora del 0.1%. Pero, de hecho, todo esto es malo, incluso 0.1%. Por qué
Tome 1.5%, este número parece pequeño, pero ¿qué significa en la práctica? Digamos que hay mil pruebas en un proyecto. Esto puede significar que 15 pruebas cayeron en una construcción, las siguientes 12, luego 18. Y esto es terriblemente malo, porque en este caso casi todas las construcciones son rojas, y debe verificar constantemente con sus manos si es cierto o no.
E incluso nuestra una ppm (0.1%) sigue siendo mala. Supongamos que tenemos 1000 pruebas, entonces 0.1% significa que regularmente una de cada diez caídas con 1-2 pruebas rojas. Aquí está la imagen real de nuestro Jenkins, y resulta: con una carrera, cayó una prueba escamosa, y otra comenzó otra.
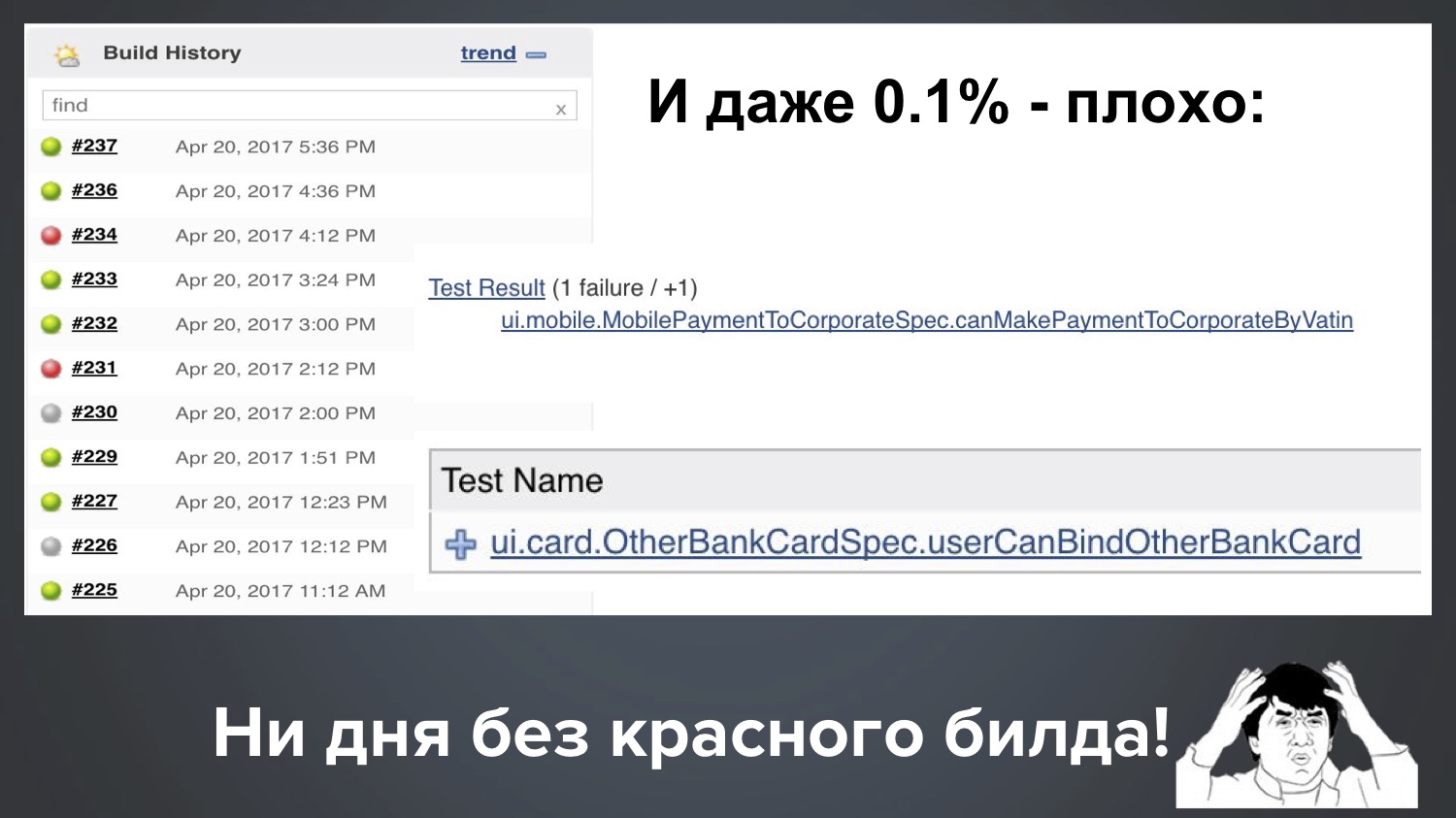
Resulta que no tenemos un día sin una construcción roja. Como hay mucho verde, todo parece estar bien, pero el cliente tiene derecho a preguntarnos: "¡Chicos, le pagamos dinero y siempre nos proporciona rojo!" ¿Qué haces?
No estaría satisfecho en el lugar del cliente, y explicar "en general, esto es normal en la industria, todo es rojo para todos" no es bueno, ¿verdad? Por lo tanto, en mi opinión, este es un problema muy urgente, y comprendamos juntos cómo lidiar con él.
El plan es este:
- Mi colección de pruebas inestables (de mi práctica, casos absolutamente reales, historias de detectives complejas e interesantes)
- Causas de inestabilidad (algunos incluso tardaron años en investigar)
- ¿Cómo lidiar con ellos? (espero que esta sea la parte más útil)
Entonces, comencemos con mi colección, que valoro mucho: me costó muchas horas de vida nocturna y depuración. Comencemos con un ejemplo simple.
Ejemplo 1: clásico
Para semilla: el clásico script Selenium:
driver.navigate().to("https://www.google.com/"); driver.findElement(By.name("q")).sendKeys("selenide"); driver.findElement(By.name("btnK")).click(); assertEquals(9, driver.findElements(By.cssSelector("#ires .g")).size());
- Abrimos WebDriver;
- Encuentre el elemento q, maneje la palabra para buscar allí;
- Encuentre el elemento "Botón" y haga clic;
- Verifique que la respuesta sea nueve resultados.
Pregunta: ¿qué línea puede romperse aquí?
Así es, todos sabemos bien que ninguno! Cualquier línea puede romperse, por razones completamente diferentes:
La primera línea es la Internet lenta, el servicio se bloqueó, los administradores no configuraron algo.
La segunda línea: el elemento aún no ha tenido tiempo de renderizarse si se dibuja dinámicamente.
¿Qué podría romperse en la tercera línea? Aquí fue inesperado para mí: escribí esta prueba para la conferencia, la ejecuté localmente y cayó en la tercera línea con este error:

Esto dice que el elemento en este punto no es cliqueable. Parece un simple formulario básico de Google. El secreto era que en la segunda línea tocamos la palabra, y mientras la ingresábamos, Google ya encontró los primeros resultados, mostró los primeros resultados en una ventana emergente y cerraron el siguiente botón. Y esto no sucede en todos los navegadores y no siempre. Esto me sucedió con este script aproximadamente una vez de cada cinco.
La cuarta línea puede caer, por ejemplo, porque este elemento se dibuja dinámicamente y aún no ha tenido tiempo de dibujar.
En este ejemplo, quiero decir que, en mi experiencia, el 90% de las pruebas escamosas se basan en las mismas razones:
- Velocidad de solicitud de Ajax: a veces corren más lento, a veces más rápido;
- El orden de las solicitudes de Ajax;
- Velocidad js.
¡Afortunadamente, hay una cura por estas razones!
Selenide resuelve estos problemas. ¿Cómo se decide? Reescribimos nuestra prueba de Google en Selenide: casi todo parece, solo se usan los signos $:
@Test public void userCanLogin() { open(“http:
Esta prueba siempre pasa. Debido al hecho de que los métodos setValue (), click () y shouldHave () son inteligentes: si algo no tiene tiempo para pintar, esperan un poco e intentan nuevamente (esto se llama "expectativas inteligentes").
Si observa un poco más en detalle, todos estos métodos * deberían ser inteligentes:

Pueden esperar si es necesario. Por defecto, esperan hasta 4 segundos, y este tiempo de espera, por supuesto, es configurable, puede especificar cualquier otro. Por ejemplo, así: mvn -Dselenide.timeout = 8000.
Ejemplo 2: nbob
Entonces, el 90% de los problemas con las pruebas escamosas se resuelven con Selenide. Pero el 10% de los casos mucho más sofisticados permanecen con razones complejas y confusas. Precisamente de ellos quiero hablar hoy, porque es una "zona gris". Permíteme darte un ejemplo: una prueba escamosa, que inmediatamente encontré en un nuevo proyecto. A primera vista, esto simplemente no puede suceder, pero esto es algo interesante.
Probamos la aplicación de teclado para iniciar sesión en quioscos. La prueba quería iniciar sesión como usuario "bob", es decir, ingresar tres letras en el campo "iniciar sesión": bob. Para hacer esto, se usaron los botones en la pantalla. Como regla, esto funcionó, pero a veces la prueba se bloqueó y el valor "nbob" permaneció en el campo "inicio de sesión":

Naturalmente, tiene dificultades para buscar por el código donde podríamos haber escrito "nbob", pero en todo el proyecto no está en absoluto (ni en la base de datos, ni en el código, ni siquiera en los archivos de Excel). ¿Cómo es esto posible?
Observamos el código con más detalle: parece que todo es simple, sin acertijos:
@Test public void loginKiosk() { open(“http:
Comenzamos a debatir más, a ir paso a paso, y con este método logramos entender: este error a veces aparece después de la línea $ ("cuerpo"). Haga clic en (). Es decir, en este paso, aparece "n" en el campo "inicio de sesión", luego se agrega "bob" en los pasos posteriores. ¿Quién ya ha adivinado de dónde viene "n"?
Dio la casualidad de que la letra N estaba en el medio de la pantalla, y la función click () al menos en Chrome funciona así: calcula la coordenada central de un elemento y hace clic en ella. Como el cuerpo es un elemento grande, hizo clic en el centro de toda la pantalla.
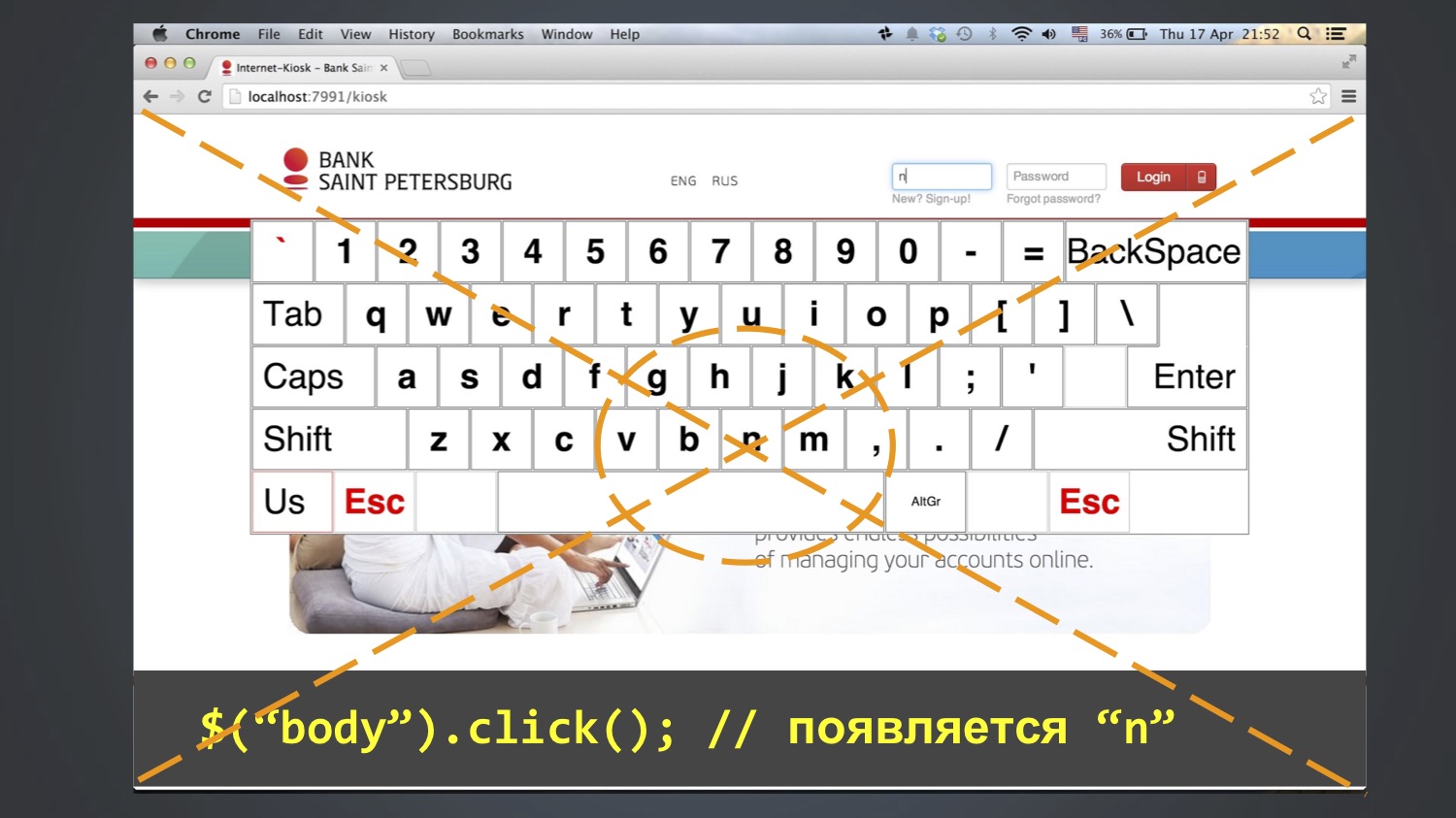
Y esto no siempre cayó. ¿Quién sabe por qué? De hecho, yo mismo no lo sé completamente. Quizás debido al hecho de que la ventana del navegador se abrió todo el tiempo en diferentes tamaños, y esto no siempre cayó en la letra N.
Probablemente tenga una pregunta: ¿por qué alguien ganó $ ("cuerpo")? Haga clic en ()? Tampoco lo sé hasta el final, pero supongo que eliminaré el foco del campo. Hay un problema en Selenium que hace clic () pero no hace clic (). Si hay un foco en el campo, entonces no se puede eliminar de allí, solo puede hacer clic en cualquier otro elemento. Y como no había otros elementos razonables, hicieron clic en el cuerpo y obtuvieron tal efecto.
De ahí la moraleja: no inserte nada que entre en el <cuerpo>. En otras palabras, no necesita hacer ningún movimiento adicional en pánico. De hecho, esto sucede a menudo: como trato con Selenide, a menudo recibo quejas "algo no funciona", y luego resulta que en algún lugar de los métodos de configuración había 15 líneas adicionales que no hacen nada útil e interfieren . No es necesario preocuparse e insertar de todos modos en pruebas como "de repente será más confiable".
Como resultado, ampliamos la lista de razones para las pruebas inestables:
- Ajax solicita velocidad;
- El orden de las solicitudes de Ajax;
- Velocidad js;
- Tamaño de la ventana del navegador;
- Vanidad!
Y al mismo tiempo, mi recomendación es: no ejecute pruebas en maximizado (es decir, no abra el navegador en una ventana completa). Como regla, todos hacen esto, y en Selenide fue por defecto (o aún lo es). En cambio, le aconsejo que siempre inicie un navegador con una resolución de pantalla estrictamente definida, porque entonces se excluye este factor aleatorio. Y le aconsejo que configure el tamaño mínimo que su aplicación admite de acuerdo con las especificaciones.
Ejemplo 3: cuentas fantasmas
Un ejemplo es interesante porque todo lo que solo puede coincidir inmediatamente coincidió.
Hubo una prueba que verificó que debería haber 5 cuentas en esta pantalla.

Como regla general, era verde, pero a veces no estaba claro en qué condiciones cayó y dijo que no había cinco, sino seis cuentas en la pantalla.
Empecé a investigar de dónde viene la factura extra. Absolutamente incomprensible. Surgió la pregunta: ¿quizás tengamos otra prueba, que durante la prueba crea una nueva cuenta? Resultó que sí, hay una prueba de préstamo. Y entre él y la prueba de cuentas que cae (que espera cinco cuentas) puede haber un millón de otras pruebas.
Estamos tratando de entender cómo es esto: ¿no debería el LoansTest, que crea la cuenta, eliminarlo al final? Observamos su código: sí, debería, al final hay una función After para esto. Entonces, en teoría, todo debería estar bien, ¿cuál es el problema?
¿Tal vez la prueba lo elimina, pero permanece en caché en alguna parte? Observamos el código de producción que carga las cuentas: realmente tiene la anotación @CacheFor, almacena en caché las cuentas durante cinco minutos.
Surge la pregunta: ¿pero no debería la prueba borrar este caché? Sería lógico, ¿no puede haber tal jamba? Observamos su código; sí, realmente borra el caché antes de cada prueba. Que pasa Aquí ya está perdido, porque las hipótesis han terminado: se elimina el objeto, se borra el caché, se pegan los árboles, ¿qué más podría ser un problema? Luego comenzó a escalar el código, tomó algo de tiempo, tal vez incluso unos pocos días. Hasta que finalmente miré esta clase y superclase, y encontré una cosa sospechosa allí:

Alguien ya se dio cuenta, ¿verdad? Así es: en el niño y en la clase padre hay un método con el mismo nombre, y no se llama super.
Y en Java es muy fácil de hacer: presiona Alt + Intro o Ctrl + Insertar en IntelliJ IDEA o Eclipse, por defecto crea el método setUp () para usted, y no nota que anula el método en la superclase. Es decir, el caché todavía no fue llamado. Cuando vi esto, estaba muy enojado. Es alegre para mí ahora.
De ahí la moraleja:
- En las pruebas, es muy importante monitorear el código limpio. Si en el código de producción todos están atentos a esto, realizan una revisión del código, luego en las pruebas, no siempre.
- Si el código de producción se verifica mediante pruebas, ¿quién probará las pruebas? Por lo tanto, es especialmente importante utilizar controles en el IDE.
Después de este incidente, encontré en IDEA una inspección, desactivada por defecto, que comprueba: si el método se anula en algún lugar, pero no hay una anotación @ Overrid, entonces marca esto como un error. Ahora siempre marco histéricamente esta casilla.
Resumamos nuevamente: ¿cómo sucedió esto? ¿Por qué la prueba falló no siempre? En primer lugar, dependía del orden de estas dos pruebas; siempre se ejecutan en orden aleatorio. Otra prueba dependió de cuánto tiempo pasó entre ellos. Las cuentas se almacenan en la memoria caché durante cinco minutos, si se pasan más, la prueba fue verde y, si es menos, cayó, y esto rara vez sucedió.
Ampliamos la lista de por qué las pruebas pueden ser inestables:
- Ajax solicita velocidad;
- El orden de las solicitudes de Ajax;
- Velocidad js;
- Tamaño de la ventana del navegador;
- Caché de aplicaciones;
- Datos de pruebas anteriores;
- Tiempo
Ejemplo 4: tiempo de Java
Hubo una prueba que funcionó en todas nuestras computadoras y en nuestro Jenkins, pero que a veces fallaba en un cliente de Jenkins. Miramos la prueba, entendemos por qué. Resulta que estaba cayendo, porque al verificar "la fecha de pago debería ser ahora o en el pasado", resultó ser "en el futuro".
assert payment.time <= new Date();
Observamos el código, de repente, en algunas condiciones, ¿podemos establecer una fecha en el futuro? No podemos: en el único lugar donde se inicializa el tiempo de pago, se usa la nueva Fecha (), y esta es siempre la hora actual (en casos extremos, puede ser en el pasado si la prueba fue muy lenta). ¿Cómo es esto posible? Se golpearon la cabeza durante mucho tiempo, no podían entender.
Y una vez que buscaron en el registro de la aplicación. De ahí la primera moraleja: es muy útil cuando se examinan las pruebas para examinar el registro de la aplicación en sí. Levanta las manos, quién lo hace. En general, no la mayoría, por desgracia. Y hay información útil: por ejemplo, el registro de solicitud, tal y tal URL se ejecutó en ese momento, dio tal y tal respuesta.

¿Hay algo sospechoso aquí, aviso? Observamos la hora: esta solicitud se procesó menos tres segundos. ¿Cómo puede ser esto? Lucharon durante mucho tiempo, no podían entender. Finalmente, cuando se nos acabó la teoría, tomamos una decisión estúpida: Jenkins escribió un guión simple que registra la hora actual en un ciclo una vez por segundo. Lanzado Al día siguiente, cuando esta prueba escamosa cayó una vez por la noche, comenzaron a ver un extracto de este archivo para el momento en que cayó:

Entonces: 34 segundos, 35, 36, 37, 35, 39 ... Es genial que lo hayamos encontrado, pero ¿cómo es eso posible? Las teorías terminaron nuevamente, otros dos días rascándose la cabeza. Este es realmente el caso cuando Matrix está bromeando contigo, ¿verdad?
Hasta que por fin una idea me golpeó ... Y resultó ser. Linux tiene un servicio de sincronización horaria que se ejecuta en un servidor central y pregunta "¿cuántos milisegundos hay ahora?" Y resulta que se lanzaron dos servicios diferentes en este Jenkins en particular. La prueba comenzó a fallar cuando Ubuntu se actualizó en este servidor.
Allí, se configuró previamente un servicio ntp, que accedió a un servidor bancario especial y tomó tiempo desde allí. Y con la nueva versión de Ubuntu, se incluyó un nuevo servicio liviano por defecto, por ejemplo, systemd-timesyncd. Y ambos funcionaron. Nadie se dio cuenta de esto. Por alguna razón, el servidor de la banca central y algún servidor central de Ubuntu emitieron una respuesta con una diferencia de 3 segundos. Naturalmente, estos dos servicios interfieren entre sí. En algún lugar profundo de la documentación de Ubuntu dice que, por supuesto, no permita esta situación ... Bueno, gracias por la información :)
Por cierto, al mismo tiempo aprendí un interesante matiz de Java, que antes de eso, a pesar de mis muchos años de experiencia, no sabía. Uno de los métodos más básicos en Java se llama System.currentTimeMillis (), con la ayuda del cual generalmente se programa para llamar a algo, muchos escribieron ese código:
long start = System.currentTimeMillis();
Dicho código se encuentra en las bibliotecas Apache Commons, Guava. Es decir, si necesita detectar cuántos milisegundos se tardó en llamar a algo, generalmente lo hacen. Y muchos probablemente escucharon que esto no debería hacerse. También escuché, pero no sabía por qué, y demasiado vago para entender. Pensé que la pregunta era exactamente porque System.nanoTime () apareció en alguna versión de Java: es más precisa, produce nanosegundos que son un millón de veces más precisos. Y dado que, por regla general, mis llamadas duran un segundo o medio segundo, esta precisión no es importante para mí, y seguí usando System.currentTimeMillis (), que vimos en el registro donde estaba -3 segundos. Entonces, de hecho, la forma correcta es esta, y ahora descubrí por qué:
long start = System.nanoTime();
En realidad, esto está escrito en la documentación de los métodos, pero nunca lo leí. Toda mi vida he pensado que System.currentTimeMillis () y System.nanoTime () son lo mismo, solo que con un millón de veces de diferencia. Pero resultó que estas son cosas fundamentalmente diferentes.
System.currentTimeMillis () devuelve la fecha actual real: cuántos milisegundos hay ahora desde el 1 de enero de 1970. Y System.nanoTime () es un tipo de contador abstracto que no está vinculado al tiempo real: sí, está garantizado que crecerá cada nanosegundo por unidad, pero no está conectado con el tiempo actual, incluso puede ser negativo. Al comienzo de la JVM, un punto en el tiempo se selecciona de alguna manera al azar, y comienza a crecer. Fue una sorpresa para mi. Para ti tambien Bueno, no en vano llegó.
Ejemplo 5: La maldición del botón verde
Aquí, nuestra prueba llena un formulario determinado, hace clic en el botón verde Confirmar y, a veces, no va más allá. Por qué no funciona es incomprensible.
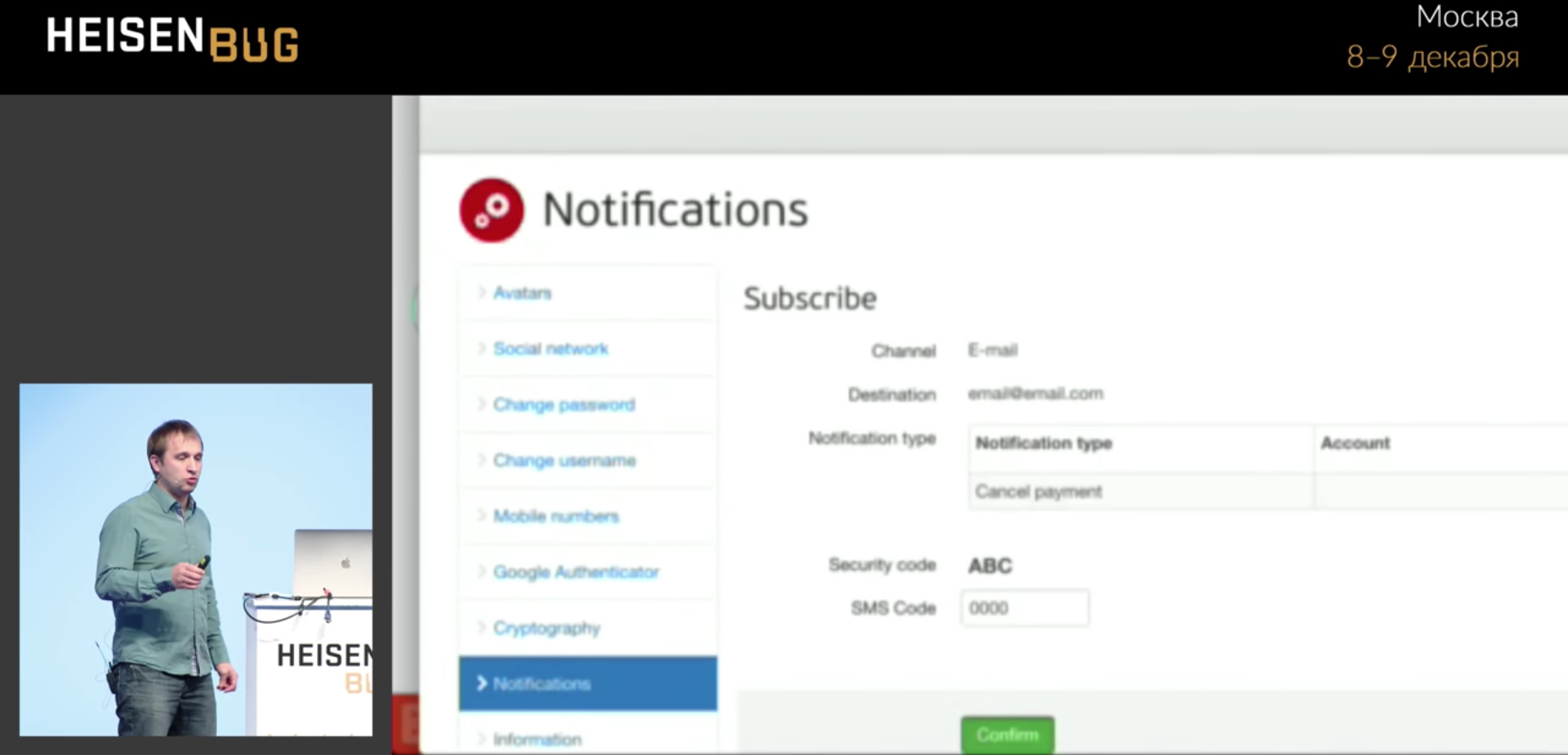
Conducimos en cuatro ceros y colgamos, no pasemos a la página siguiente. Hacer clic ocurre sin errores. Miré todo: solicitudes de Ajax, esperas, tiempos de espera, registros de aplicaciones, caché. No encontré nada. La biblioteca de
Video Recorder escrita por Sergey Pirogov aún no ha aparecido. Permite, agregar una anotación al código, grabar video. Luego pude grabar un
video de esta prueba, verlo en cámara lenta, y esto finalmente aclaró la situación que no pude resolver durante varios meses antes del video.

La barra de progreso bloqueó el botón durante una fracción de segundo, y el clic funcionó exactamente en ese momento y golpeó esta barra de progreso. Es decir, la barra de progreso hizo clic y desapareció. Y no será visible en ninguna captura de pantalla, en ningún registro, nunca sabrá lo que sucedió.
En principio, esto es, en cierto sentido, un error de la aplicación: apareció una barra de progreso porque la aplicación realmente se arrastra fuera del borde de la pantalla, y si se desplaza, resulta ser una gran cantidad de datos útiles. Pero los usuarios no se quejaron, porque todo encajaba en la pantalla grande, no cabía solo en la pequeña.
Ejemplo 6: ¿por que Chrome se congela?
Una investigación de detectives de dos años es un caso absolutamente real. La situación es esta: nuestras pruebas a menudo fueron escamosas y cayeron, y en los rastros de la pila estaba claro que Chrome se congela: no nuestra prueba, es decir, Chrome. En los registros era visible "La compilación se está ejecutando 36 horas ..." Comenzaron a eliminar los volcados de hilos y los rastros de la pila: muestran que todo está bien en las pruebas, la llamada a Chromedriver se cuelga y, como regla, en el momento del cierre (llamamos al método de cierre, y este método no hace nada, se cuelga 36 horas). Si es interesante, el seguimiento de la pila se ve así:

Intentamos hacer todo lo que solo se nos ocurría:
- Configure el tiempo de espera para abrir / cerrar el navegador (si no pudo abrir / cerrar el navegador en 15 segundos, intente nuevamente después de 15 segundos, hasta tres intentos). Abra y cierre el navegador en un hilo separado. Resultado: los tres intentos colgaron de la misma manera.
- Mata viejos procesos de Chrome. Crearon un trabajo separado en 'kill-chrome' de Jenkins, por ejemplo, de esta manera, puede "matar" todos los procesos anteriores a una hora:
killall: más antiguo que 1h chromedriver
killall - más viejo que 1h cromo
Esto al menos liberó memoria, pero no respondió a la pregunta "¿qué está pasando?". De hecho, esto solo nos retrasó el momento de la decisión. - Habilite los registros de la aplicación de depuración.
- Habilite los registros de depuración de WebDriver.
- Vuelva a abrir el navegador después de cada 20 pruebas. Puede parecer ridículo, pero la idea era: "¿Qué pasa si Chrome se congela porque está cansado?" Bueno, una pérdida de memoria o algo más.
El resultado del último intento fue completamente inesperado: ¡el problema comenzó a repetirse más a menudo! Y esperábamos que esto ayudara a estabilizar Chrome para que funcione mejor. Esto generalmente es una conclusión del cerebro. Pero, de hecho, cuando el problema comienza a repetirse con mayor frecuencia, uno no debe estar triste, ¡sino alegrarse! Esto hace posible estudiarlo mejor. Si ella comenzó a repetir más a menudo, uno debería aferrarse a ella: "Sí, sí, ahora agregaré algo más, registros, puntos de interrupción ..."
Estamos tratando de repetir el problema: escribimos un ciclo del 1 al 1000, en el ciclo simplemente abrimos el navegador y cerramos la primera página de nuestra aplicación. Escribimos tal ciclo, y ... ¡bingo! Resultado: ¡el problema comenzó a repetirse de manera estable (aunque aproximadamente cada 80 iteraciones)! Genial! Es cierto que este logro no dio nada durante mucho tiempo. Lo comenzó, esperó la iteración 80, Chrome se estrelló ... ¿y luego qué hacer? Observa los rastros de la pila, los volcados, los registros: allí no hay nada útil. Las herramientas de desarrollador en Chrome pueden ayudar, pero hasta septiembre de 2017 estas herramientas no funcionaron con Selenium (los puertos estaban en conflicto: inicia Chrome desde Selenium y DevTools no se abre). Durante mucho tiempo no pude pensar en qué hacer.
Y aquí en esta historia comienza un momento fabuloso. Una vez, después de un número infinito de intentos, realicé estas pruebas nuevamente, está colgando nuevamente en alguna iteración como la 56, creo que "vamos a cavar algo más" (aunque no sé dónde más poner el punto de interrupción o qué agregar un registro). En este momento, mi hija se ofrece a jugar cubos, pero mi prueba simplemente se cuelga aquí. Le digo: "Espera", ella me dijo: "¡Qué, no entiendes, tengo
un b y un aquí!"
Qué hacer, tristemente dejé la computadora, fui a jugar cubos ... Y de repente, después de unos 20 minutos, accidentalmente miro la pantalla y veo una imagen completamente inesperada:

Qué sucede: hay una cuenta regresiva, después de cuántos minutos expira la sesión, y construyo una torre de cubos, quedan dos, uno ... la sesión expira, la prueba continúa, corre hasta el final y cae (ya no hay ningún elemento, la sesión ha expirado).
Qué sucede: Chrome realmente no se congeló, como pensamos todo este tiempo, ha estado esperando algo todo este tiempo. Cuando la sesión expiró, esperó, continuó. Qué esperaba exactamente Chrome: es completamente incomprensible entender esto, tuve que descifrar todo el código usando el método de búsqueda binario: tirar la mitad de JavaScript y HTML, intentar repetir 80 iteraciones nuevamente; no se bloqueó, oh, eso significa que en algún lugar por ahí ... En general, entendimos experimentalmente que el problema esta aquí:
var timeout = setTimeout(sessionWatcher);
JavaScript — , , . , JavaScript- , : , <script> . , , , , . JavaScript — jQuery, $, function , :
var timeout; $(function() { timeout = setTimeout(...); });
-, , , . , . 1000 , .
, : , , , . , Chrome, . , .
, flaky- , , , . , — , , ( ). , . , : ?
Chrome flaky-: -, , , .
UI- : , . click(), , . , , : click() , . - , ? :)
. , , , . , , , , Docker.
, - , . :
- Ajax-;
- Ajax-;
- JS;
- ;
- ;
- ;
- ;
- ;
- UI-;
- ( ).
flaky- , . , -, : , .
. «» . , flaky- , ID, flaky- . .
, : , , .
, flaky- usability, -, flaky- . .
, , … , , , flaky- security-, . , !
, , flaky-:
— . flaky- , unit- , UI-? , ( ), , flaky.
Selenide .
. (, / ). , « ?». , , .
, .
, . , , , , . : « », , (10 , 20 , — , — ). , flaky - .
, flaky- :
- ;
- ;
- Video
« » , , , : - . «», «» , : flaky-, , flaky. , , . . , Jenkins pipeline, Jenkins :
finally { stage("Reports") { junit 'build/test-results/**/*.xml' artifacts = 'build./reports/**/*,build/test-results/**/*,logs/**/*' archiveArtifacts artifacts: artifacts } }
finally , . : - - . Jenkins , . , Jenkins , . , .
(Selenide , ). flaky-. ,
Video Recorder , :
video — , !
, Docker: TestContainers ( Heisenbug
).
Rule , — Docker , , . .
@Rule public BrowserWebDriverContainer chrome = new BrowserWebDriverContainer() .withRecordingMode(RECORD_ALL, new File("build")) .withDesiredCapabilities(chrome());
.
. , , , , , . flaky- .
, ! , :) . , « , , », , .
— , , , , - . — , … ! :) flaky- — : !
, : 6-7 Heisenbug . , , . (, , ) .