
Recientemente terminó
la clasificación de la etapa DataScienceGame2018, que tuvo lugar en el formato Kaggle INCLASS.
DataScienceGame es una competencia internacional de estudiantes que se realiza anualmente. Nuestro equipo logró estar en el 3er lugar entre más de 100 equipos y, al mismo tiempo, NO ir a la etapa final.
Interacción del equipo

En las grandes competiciones de kaggle, los equipos generalmente se forman en el camino a partir de personas con una ventaja cercana en la tabla de clasificación (un
ejemplo típico de un equipo ) y, por lo tanto, representan diferentes ciudades y, a menudo, diferentes países. Inmediatamente, de acuerdo con los términos de la competencia, cada equipo debe estar compuesto por 4 personas de una institución educativa (representamos a MIPT). Y eso significa que la mayoría de los participantes, me parece, todas las discusiones tuvieron lugar fuera de línea. Por ejemplo, teníamos a todo el equipo viviendo en un piso del albergue, así que nos reuníamos por la noche con alguien en la habitación.
No tuvimos separación de tareas, planificación o trabajo en equipo. Al comienzo de la competencia, nos sentamos en círculo, discutimos lo que podemos hacer en el futuro y no lo hicimos. El código fue escrito por una persona, y el resto en ese momento simplemente miró y dio consejos. Realmente no me gusta escribir código, así que me gustó esta interacción, a pesar de que obviamente no era la mejor. Pero dado que la etapa de calificación cayó exactamente en la sesión en la universidad, parte del equipo no pudo dedicar mucho tiempo y aún así tuve que escribir el código yo mismo.
Descripción de la tarea
Según el historial proporcionado por BNP, era necesario predecir si el usuario estaría interesado en algo de seguridad (Isin) la próxima semana o no. Al mismo tiempo, el "interés" fue determinado por la columna TradeStatus, que describía el estado de la transacción y tenía los siguientes valores únicos:
- La transacción se completó (es decir, el usuario compró / vendió papel)
- El usuario miró el documento, pero no completó una transacción.
- El usuario reserva papel para compra / venta futura
- La transacción no se completó debido a razones técnicas.
- Holding
Entonces, si TradeStatus toma el valor 1) -4), entonces se considera que el usuario estaba interesado en este documento y no estaba interesado en todos los demás casos. Al mismo tiempo, el párrafo 4) indicaba que la línea con esta transacción era ficticia y se hizo para facilitar la presentación de informes. Es decir, al final de cada mes, el estado de la cartera de cada usuario se comparó con su estado hace un mes, y si, por ejemplo, el usuario de alguna manera en la cartera, la cantidad de un determinado valor aumentaba en 10k, entonces esta misma línea marcaba "compra" "Y con un valor nominal de 10k. Las líneas marcadas con "espera" tenían una variable objetivo de 0 (el usuario no estaba interesado).
Si lo piensa, puede comprender que el conjunto de datos funcionaba de la siguiente manera: los usuarios estaban activos en el sitio web del banco: buscaban / compraban documentos, y todas estas acciones se registraron en la base de datos. Por ejemplo, un usuario con id = 15 decidió posponer el papel con id = 7 para futuras compras. Inmediatamente en la base de datos apareció la línea correspondiente con el objetivo 1 (el usuario se interesó)
| ID de usuario | ID de seguridad | Tipo de transacción | Estado del trato | Campos adicionales | Target |
|---|
| 15 | 7 7 | Compra | Reservar para el futuro | ... | 1 |
Además, se agregaron registros mensuales con el estado de tenencia y objetivo 0. Por ejemplo, el usuario 15 aumentó el número de acciones 93 por alguna razón (tal vez lo compró en otro sitio), mientras que él mismo no usó este documento en el sitio web de BNP interactuado (no interesado).
| ID de usuario | ID de seguridad | Tipo de transacción | Estado del trato | Campos adicionales | Target |
|---|
| 15 | 93 | Compra | Holding | ... | 0 0 |
Pero, obviamente, para BNP, no tiene sentido predecir estas mismas propiedades, porque pueden restaurarse sin ambigüedades desde la base. Esto significa que hay otro tipo de tokens que no están en la tabla de entrenamiento, a saber, cualquier "transacción de tipo de usuario en papel" que no aparece en la base de datos. Es decir, el usuario NO estaba interesado en una determinada acción, eso significa que no interactuó con ella en el sistema BNP, por lo que la línea correspondiente no apareció en la base de datos, lo que significa que debería tener un objetivo de 0. Y esto sugiere que debe generar esas líneas para entrenarse usted mismo ( vea la sección "Compilación de una muestra de entrenamiento"). Todo esto podría generar cierta confusión, porque muchos participantes probablemente pensaron: hay un conjunto de datos, hay ceros y unos, que se puede predecir. Pero no tan simple.
Por lo tanto, en el tren hay una tabla con el historial de transacciones (es decir, la interacción "usuario - papel - tipo de transacción" y alguna información adicional sobre ellas) y un montón de otras placas con las características del usuario, acciones, condiciones del mercado global. En la prueba solo hay tres veces "usuario - papel - tipo de transacción" y para cada uno de estos triples debe predecir si aparecerá la próxima semana. Por ejemplo, ¿necesita predecir si el id de usuario = 8 estará interesado en la acción id = 46 con el tipo de transacción "venta"?
| ID de usuario | ID de seguridad | Tipo de transacción | Target |
|---|
| 8 | 46 | Para la venta | ? |
Características de construir un conjunto de datos
Como, como ya dije, en la base de datos BNP real no había líneas con ceros "sin retención", los organizadores de alguna manera generaron tales líneas para la prueba. Y donde hay generación de datos artificiales, a menudo hay caras y otra información implícita que puede mejorar significativamente el resultado sin cambiar los modelos / características. Esta sección describe algunas características de la construcción de un conjunto de datos que logramos comprender, pero que, desafortunadamente, no nos ayudaron de ninguna manera.

Si observa que el "tipo de transacción de usuario - papel" se triplica de la tabla de prueba, es fácil notar que el número de transacciones con los tipos de "compra" y "venta" es exactamente el mismo, y la tabla está estrictamente ordenada por este atributo: primero todas las compras, luego todas ventas Obviamente, esto no es un accidente y surge la pregunta: ¿cómo podría suceder esto? Por ejemplo, de esta manera: los organizadores tomaron todos los registros reales de su base de datos para la semana que necesitamos para hacer una predicción (tales líneas tienen un objetivo de 1), de alguna manera generaron nuevas líneas (su objetivo es 0), que no coinciden con las descritas anteriormente. Entonces resultó una tabla en la que los tipos de transacciones (compra / venta) se organizan en orden aleatorio:
| ID de usuario | ID de seguridad | Tipo de transacción | Target |
|---|
| 8 | 46 | Para la venta | 1 |
| 2 | 6 6 | Compra | 1 |
| 158 | 73 | Compra | 1 |
| 3 | 29 | Para la venta | 0 0 |
| 67 | 9 9 | Compra | 0 0 |
| 17 | 465 | Para la venta | 0 0 |
Ahora es posible establecer el tipo de compra en todas las líneas con el tipo de transacción "venta", y si el objetivo era uno, entonces se convertirá en cero (en la mayoría de los casos, el usuario estaba interesado en algún papel con un solo estado: compra o venta). Esto dará como resultado la siguiente tabla:
| ID de usuario | ID de seguridad | Tipo de transacción | Target |
|---|
| 8 | 46 | Compra | 0 0 |
| 2 | 6 6 | Compra | 1 |
| 158 | 73 | Compra | 1 |
| 3 | 29 | Compra | 0 0 |
| 67 | 9 9 | Compra | 0 0 |
| 17 | 465 | Compra | 0 0 |
El último paso sigue siendo: hacer lo mismo, pero reemplazando la "compra para la venta" y organizar los objetivos correctos:
| ID de usuario | ID de seguridad | Tipo de transacción | Target |
|---|
| 8 | 46 | Para la venta | 1 |
| 2 | 6 6 | Para la venta | 0 0 |
| 158 | 73 | Para la venta | 0 0 |
| 3 | 29 | Para la venta | 0 0 |
| 67 | 9 9 | Para la venta | 0 0 |
| 17 | 465 | Para la venta | 0 0 |
Concatenando la mesa con "compras" y la mesa con "ventas" obtenemos (si fuéramos los organizadores) una mesa tal como se nos dio en la prueba. Es fácil entender que las mitades primera y segunda de las tablas construidas de esta manera tienen el mismo orden de pares de papel de usuario, que en realidad resultó ser así en la tabla de prueba.
Otra característica era que había muchas líneas en el conjunto de datos de entrenamiento en las que el índice de usuario se repetía varias veces seguidas, a pesar de que el conjunto de datos no estaba ordenado por ninguno de los signos:
| ID de usuario | ID de seguridad | Tipo de transacción | Target |
|---|
| 8 | 46 | Para la venta | ? |
| 8 | 152 | Para la venta | ? |
| 8 | 73 | Compra | ? |
El compañero de equipo consideró que esto era normal, y el conjunto de datos se ordenó inicialmente por ID de usuario, y los organizadores simplemente lo desordenaron mal (por ejemplo, si la mezcla se organizó en permutaciones aleatorias y no hubo suficientes permutaciones). Intentando asegurarse de esto, pasó por cuatro barajas de diferentes bibliotecas, pero en ninguna parte surgieron repeticiones tan frecuentes. La prueba también tenía esta característica. Hubo una idea de que los organizadores no generaron los ceros, sino que simplemente tomaron los viejos pares del tren. Para comprobarlo, decidí hacer lo siguiente: para cada par de "papel de usuario" de la prueba, compare el número de línea del tren cuando este par se conoció por primera vez y haga un diagrama de esto. Es decir, por ejemplo, miramos la primera línea de la prueba, le damos una identificación de usuario = 8 e id = papel = 15. Ahora revisamos la tabla de entrenamiento de arriba a abajo y buscamos cuándo apareció este par, por ejemplo, Línea 51 Tenemos una comparación: la primera línea de la prueba estaba en el tren 51, por lo que trazamos el punto con coordenadas (1, 51) en el gráfico. Hacemos esto para toda la prueba y obtenemos el siguiente gráfico:
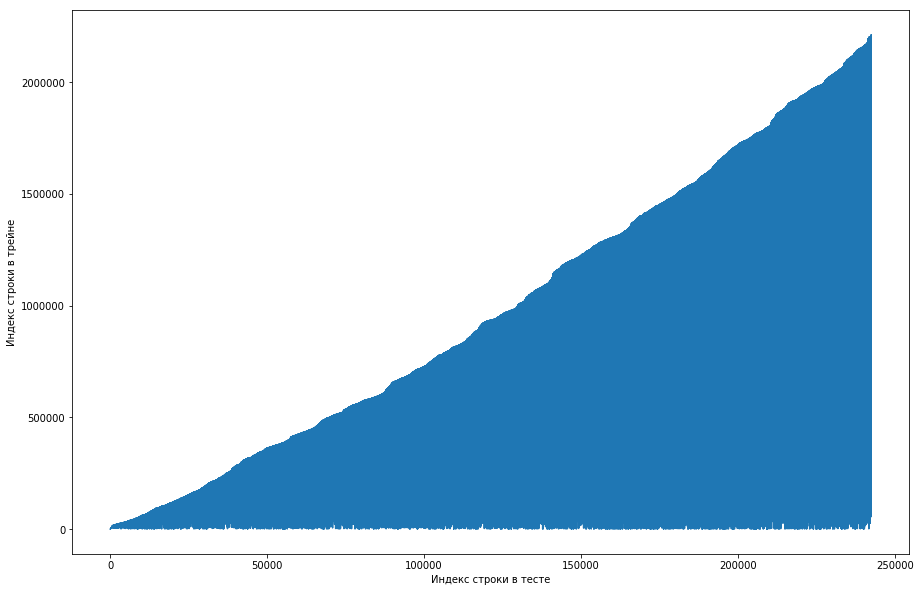
De esto se puede ver que, básicamente, si una pareja se había conocido antes en el tren, entonces en la tabla de prueba su posición será más alta. Pero al mismo tiempo, hay algunas oleadas en el gráfico (en realidad no hay muchas, pero debido a la resolución de las pantallas parece que hay un triángulo sólido). Además, el número de emisiones coincidió aproximadamente con el número esperado de unidades en la prueba. Por supuesto, tratamos de marcar las emisiones como unidades y enviarlas a la tabla de clasificación, pero, desafortunadamente, no funcionó. Pero todavía me parecía que podría haber algún tipo de cara (), y, como capitán del equipo, sugerí pasar más tiempo para entender cómo podría suceder esto, y todavía tenemos tiempo para entrenar a los modelos y generar los signos. Descargo de responsabilidad: pasamos mucho tiempo en esto, pero una semana antes del final de la competencia, los organizadores escribieron en el foro que solo se triplicaron durante los últimos 6 meses en el conjunto de datos de prueba, y no todos. Bueno, si realiza las operaciones descritas anteriormente, pero durante los últimos 6 meses, y no solo el conjunto de datos, obtendrá una curva monótona plana:
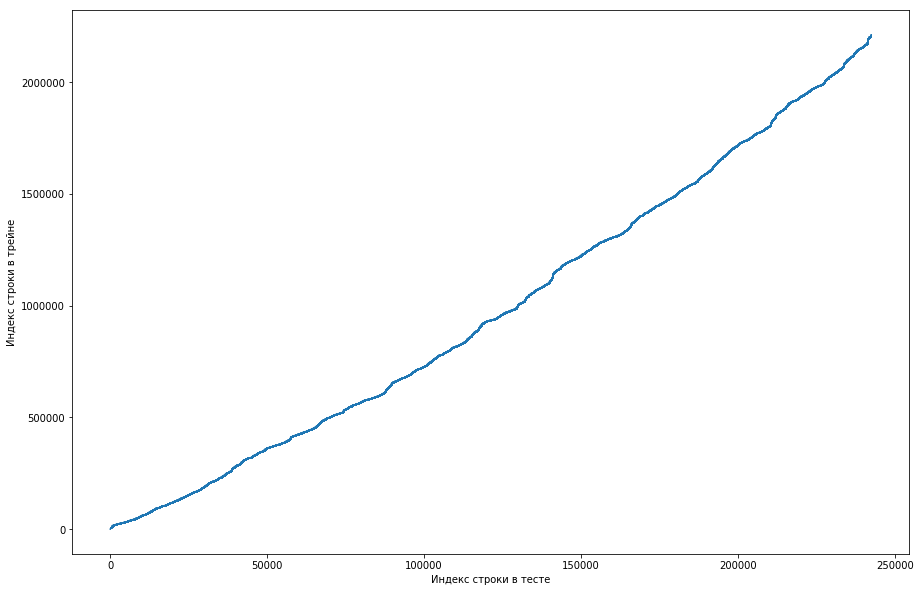
Y esto significa que no hay cara aquí y no puede ser.
Configuración de entrenamiento
Dado que en la prueba debe hacer una predicción de triples durante una semana, dividiremos el conjunto de datos de capacitación en semanas (al mismo tiempo, cada semana hay un promedio de 20k triples de "transacciones de tipo de usuario en papel"). Ahora, para cualquiera de los tres, podemos decir si se conoció en una semana en particular o no. Al mismo tiempo, ya tenemos triples positivos (estas son todas las entradas de esta semana en la tabla del tren), y las negativas deben generarse de alguna manera. Hay muchas opciones sobre cómo hacer esto. Por ejemplo, puede ordenar absolutamente todos los triples que no estuvieron allí durante una semana en particular en el conjunto de datos de entrenamiento. Está claro que la muestra estará altamente desequilibrada, y esto es malo. Primero puede generar usuarios en proporción a la frecuencia de su aparición en el conjunto de datos, y luego agregarles promociones de alguna manera. Pero con este enfoque, habrá un montón de líneas para las que no se pueden calcular estadísticas razonables, lo que también es malo. Como lo hicimos: tomamos todo tipo de triples que se habían encontrado previamente en el tren, lo copiamos, reemplazando compra / venta por el opuesto, y concatenamos estas dos tablas. Está claro que los duplicados podrían haber ocurrido de esta manera (por ejemplo, si el usuario alguna vez hubiera comprado y vendido una acción), pero hubo pocos de ellos, y después de la eliminación se obtuvo una tabla de 500k triples únicos. Eso es todo, ahora por cada semana por cada triple, puedes decir si se conoció o no (¿y cuántas veces?).
Dado que, en esencia, estamos tratando con series de tiempo: un usuario mira un anuncio específico varias veces por semana, construiremos una tabla para entrenar al clasificador de una manera clásica para las series de tiempo. Es decir, tomaremos la última semana disponible del tren, veremos si cada tres "clientes - están - compran o venden" se reunieron esta semana. Será un objetivo. Y contaremos varias estadísticas como características, por ejemplo, durante las últimas 6 semanas (más sobre estadísticas en la sección "Señales"). Ahora olvidemos la existencia de la última semana y hagamos lo mismo, pero para la penúltima semana y concatene las tablas. Esto se puede hacer varias veces, aumentando así el tren de "altura", pero al mismo tiempo, el intervalo durante el cual consideramos que las estadísticas disminuye naturalmente. Repetimos esta operación 10 veces, porque si hiciéramos más, entonces las vacaciones de Año Nuevo y los problemas relacionados se enfocarían, lo que empeoraría la calidad final del modelo. Cuadro explicativo:
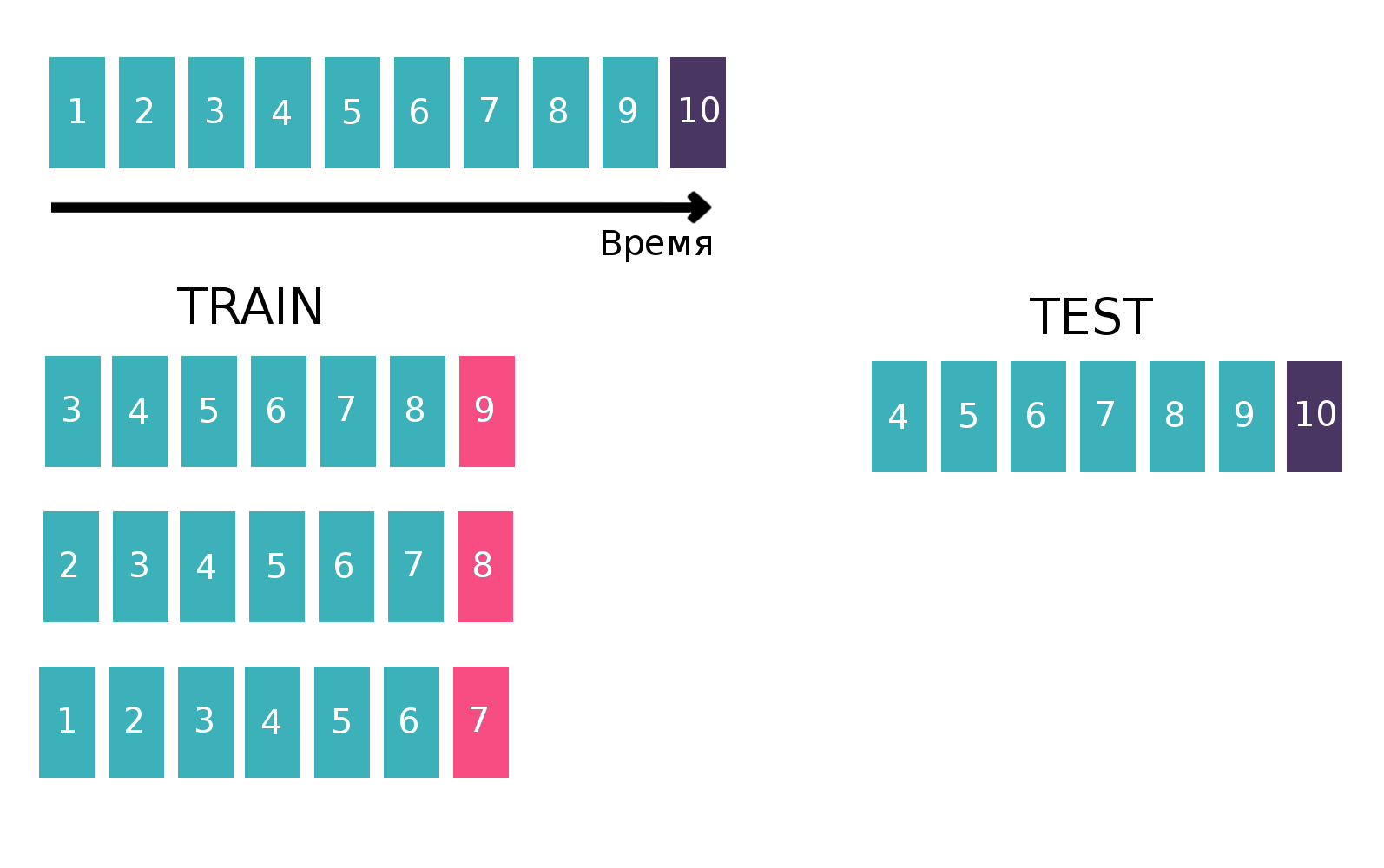
Puede encontrar más información sobre series de tiempo y validación de series de tiempo
aquí .
Signos
Como dije, había muchas tablas que de alguna manera caracterizaban al usuario, a las acciones o a las condiciones del mercado global (monedas principales y algunos indicadores). Pero todos ellos casi no mejoraron la calidad, y los principales signos fueron estadísticas calculadas para los pares "cliente - isin" y triplica "cliente - isin - comprar o vender", por ejemplo, tales como:
- ¿Con qué frecuencia se encontraron una pareja / tres en las últimas 1, 2, 5, 20, 100 semanas?
- Estadísticas sobre intervalos de tiempo entre reuniones de un par / triples en un conjunto de datos (media, estándar, máximo, mínimo)
- La distancia en el tiempo hasta la primera / última vez que una pareja / tres se encontraron
- La proporción de cada valor TradeStatus para un par / triple
- Estadísticas sobre cuántas veces a la semana ocurre una pareja / triple (media, estándar, máxima, mínima)
Además, el último día de la competencia leí en el formulario que para vender una acción, primero debe comprarla. Este conocimiento le permite encontrar muchos más signos útiles, pero, por alguna razón, para mí no era obvio.
En el código, todo esto se expresó mediante una función de 200 líneas de longitud, que generó signos similares para cada uno de los diez pedazos de tren (para la parte donde el objetivo, por ejemplo, la semana 7, no deberíamos usar la información para el 8 y 9). Teniendo en cuenta tablas adicionales, se reclutaron alrededor de 300 signos. Como ya dije, generamos 500k triples únicos y tomamos las últimas 10 semanas como objetivos, por lo tanto, la tabla de entrenamiento "alta" fue de 500k * 10 = 5kk líneas.
Se describieron algunas confesiones más en
la decisión del segundo lugar . Los chicos construyeron una tabla de usuario / papel, donde en cada celda había una unidad si el usuario alguna vez estuvo interesado en este papel y cero en caso contrario. Al calcular la distancia del coseno entre los usuarios en esta tabla, puede obtener la convergencia de los usuarios entre ellos. Si aplica el PCA a la tabla de similitud resultante, obtendrá un conjunto de características que caracterizan al usuario de alguna manera.
Modelos o lucha por milésimas
Vale la pena señalar que durante casi tres semanas nadie pudo superar la línea de base de BNP, que tenía una velocidad de 0.794 (ROC AUC) en la tabla de clasificación, y esto a pesar del hecho de que la decisión de "simplemente contar la cantidad de veces que la pareja se reunió antes" dio 0,71 en la tabla de clasificación, y algunos los participantes recibieron todos los 0,74 sin el uso de aprendizaje automático.
Pero utilizamos el aprendizaje automático, además, el último día de la competencia (que coincidió casualmente con el final de la sesión), decidimos detenernos
si sabes a lo que me refiero y hacer una gran combinación de diferentes modelos entrenados en diferentes subconjuntos de signos con diferentes números de semanas en Tren Como ya dije, nuestra muestra de entrenamiento constaba de 1.5k líneas, con un objetivo entre ellas de aproximadamente 150k. El tamaño de la prueba fue de 400k, mientras que el número estimado de unidades fue de 20k (en promedio, de hecho, hay tantos triples únicos). Es decir, la proporción de unidades en la prueba fue significativamente mayor que en el tren. Por lo tanto, en todos nuestros modelos, ajustamos el parámetro scale_pos_weight, que pone el peso en las clases. Se puede encontrar más información sobre este parámetro en el
análisis de la mejor solución de uno de los DataScienceGame del año pasado. La matriz de correlación de las predicciones de nuestros modelos se muestra en la figura:
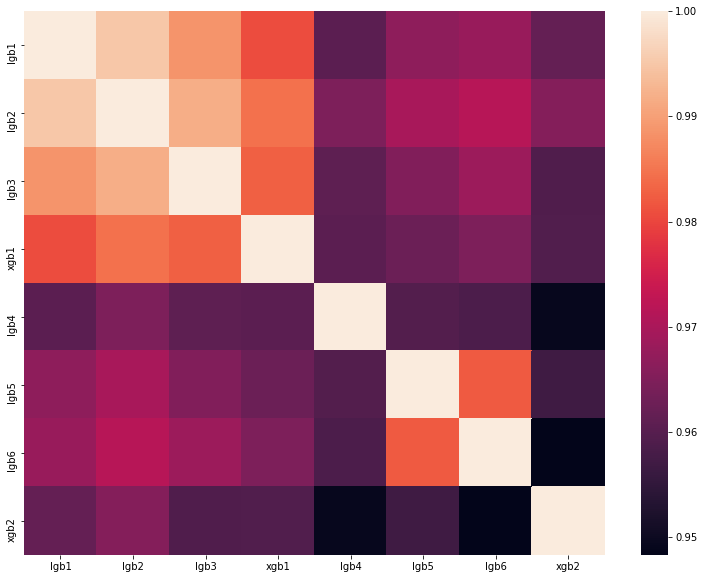
Como puede ver, teníamos muchos modelos bastante diferentes, lo que nos permitió obtener una velocidad de 0.80204 en la clasificación.
¿Por qué no vamos a Francia para la etapa final?
Como resultado, mostramos un buen resultado y tomamos el tercer lugar en la tabla de clasificación. Pero los organizadores establecen las siguientes reglas para la selección de finalistas:
- No más de 20 mejores equipos.
- No más de 5 mejores equipos del país.
- No más de 1 equipo de una institución educativa.
Y todo estaría bien si otro equipo del Instituto de Física y Tecnología de Moscú con una velocidad de 0.80272 no estuviera en segundo lugar. Es decir, solo estamos a 0,00068 detrás. Es una pena, pero no hay nada que hacer. Lo más probable es que los organizadores establecieron tales reglas para que las personas de una universidad no se ayudaran entre sí de ninguna manera, pero en nuestro caso, no sabíamos nada sobre el equipo vecino y no lo contactamos de ninguna manera.
Resumen
Este año, en septiembre, en París, 5 equipos de Rusia, uno de Ucrania y dos equipos de Alemania y Finlandia, compuestos por estudiantes de habla rusa, competirán por el primer lugar. Un total de 8 equipos de la comunidad ru, lo que demuestra una vez más el dominio del segmento ru de datasaens. Y me están
transfiriendo a Sharaga, entreno y trabajo en mí mismo, para que el próximo año aún pueda superar la etapa de calificación.