Este artículo no cubrirá los conceptos básicos de hibernación (cómo definir una entidad o escribir una consulta de criterios). Aquí trataré de hablar sobre puntos más interesantes que son realmente útiles en el trabajo. Información sobre la cual no me he reunido en un solo lugar.

Haré una reserva de inmediato. Todo lo siguiente es cierto para Hibernate 5.2. Los errores también son posibles debido al hecho de que entendí mal algo. Si lo encuentra, escriba.
Problemas para mapear un modelo de objetos en un modelo relacional
Pero comencemos con los conceptos básicos de ORM. ORM - mapeo objeto-relacional - en consecuencia tenemos modelos relacionales y de objeto. Y cuando se muestran uno a otro, hay problemas que debemos resolver por nuestra cuenta. Vamos a desarmarlos.
Para ilustrar, tomemos el siguiente ejemplo: tenemos la entidad "Usuario", que puede ser un Jedi o un avión de ataque. Los Jedi deben tener fuerza, y la especialización del avión de ataque. A continuación se muestra un diagrama de clase.
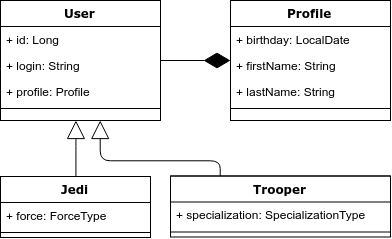
Problema 1. Herencia y consultas polimórficas.
Hay herencia en el modelo de objetos, pero no en el modelo relacional. En consecuencia, este es el primer problema: cómo asignar correctamente la herencia al modelo relacional.
Hibernate ofrece 3 opciones para mostrar dicho modelo de objeto:
- Todos los herederos están en la misma mesa:
@Inheritance (estrategia = InheritanceType.SINGLE_TABLE)

En este caso, los campos comunes y los campos de los herederos se encuentran en una tabla. Con esta estrategia, evitamos las uniones al seleccionar entidades. De los inconvenientes, vale la pena señalar que, en primer lugar, no podemos establecer la restricción "NO NULO" para la columna "fuerza" en el modelo relacional, y en segundo lugar, perdemos la tercera forma normal. (aparece una dependencia transitiva de atributos no clave: fuerza y disco).
Por cierto, incluso por esta razón, hay 2 formas de especificar una restricción de campo no nula: NotNull es responsable de la validación; @Column (nullable = true): responsable de la restricción no nula en la base de datos.
En mi opinión, esta es la mejor manera de asignar un modelo de objeto a un modelo relacional.
- Los campos específicos de la entidad están en una tabla separada.
@Inheritance (estrategia = InheritanceType.JOINED)
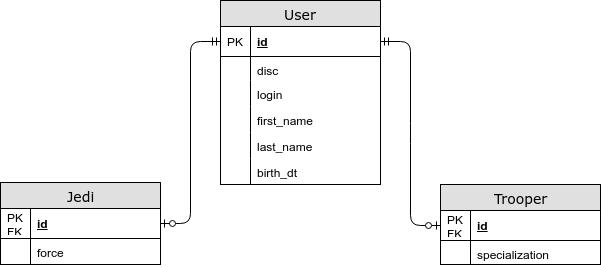
En este caso, los campos comunes se almacenan en una tabla común, y los específicos para entidades secundarias se almacenan en otros. Al usar esta estrategia, obtenemos un JOIN al elegir una entidad, pero ahora guardamos la tercera forma normal, y también podemos especificar una restricción NOT NULL en la base de datos. - Cada entidad tiene su propia tabla.
@ InheritanceType.TABLE_PER_CLASS
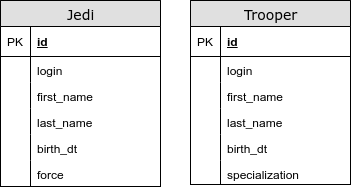
En este caso, no tenemos una tabla común. Usando esta estrategia, usamos UNION para consultas polimórficas. Estamos teniendo problemas con los generadores de claves primarias y otras restricciones de integridad. Este tipo de mapeo de herencia es altamente desaconsejado.
Por si acaso, mencionaré la anotación: @MappedSuperclass. Se utiliza cuando desea "ocultar" campos comunes para varias entidades del modelo de objetos. Además, la clase anotada en sí misma no se considera como una entidad separada.
Problema 2. Relación de composición en POO
Volviendo a nuestro ejemplo, observamos que en el modelo de objetos tomamos el perfil del usuario en una entidad separada: Perfil. Pero en el modelo relacional, no seleccionamos una tabla separada para ello.
La actitud OneToOne es a menudo una mala práctica porque en select tenemos un JOIN injustificado (incluso especificando fetchType = LAZY en la mayoría de los casos tendremos JOIN - discutiremos este problema más adelante).
Hay anotaciones @Embedable y @Embeded para mostrar una composición en una tabla común. El primero se coloca sobre el campo y el segundo sobre la clase. Son intercambiables
Gerente de la entidad
Cada instancia de EntityManager (EM) define una sesión de interacción con la base de datos. Dentro de una instancia de EM, hay un caché de primer nivel. Aquí destacaré los siguientes puntos significativos:
- Capturando la conexión de la base de datos
Este es solo un punto interesante. Hibernate no captura Connection al momento de recibir el EM, sino al primer acceso a la base de datos o al abrir la transacción (aunque este problema puede resolverse ). Esto se hace para reducir el tiempo de conexión ocupada. Durante la recepción de EM-a, se verifica la presencia de una transacción JTA. - Las entidades persistentes siempre tienen id.
- Las entidades que describen una línea en la base de datos son equivalentes por referencia
Como se mencionó anteriormente, EM tiene un caché de primer nivel, los objetos en él se comparan por referencia. En consecuencia, surge la pregunta: ¿qué campos deberían usarse para anular equals y hashcode? Considere las siguientes opciones:
- Cómo funciona la descarga
Flush - ejecuta insert-s, update-s y delete-s acumulados en la base de datos. Por defecto, el vaciado se ejecuta en casos:
- Antes de ejecutar la consulta (con la excepción de em.get), esto es necesario para cumplir con el principio ACID. Por ejemplo: cambiamos la fecha de nacimiento del avión de ataque, y luego queríamos obtener el número de aviones de ataque para adultos.
Si estamos hablando de CriteriaQuery o JPQL, se ejecutará flush si la consulta afecta a una tabla cuyas entidades están en la caché del primer nivel. - Al cometer una transacción;
- A veces, cuando persiste una nueva entidad, en el caso de que podamos obtener su identificación solo a través de la inserción.
Y ahora una pequeña prueba. ¿Cuántas operaciones de ACTUALIZACIÓN se realizarán en este caso?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
Una característica interesante de hibernación está oculta bajo la operación de vaciado: está tratando de reducir el tiempo que lleva bloquear las filas en la base de datos.
También tenga en cuenta que existen diferentes estrategias para la operación de descarga. Por ejemplo, puede prohibir los cambios de "fusión" en la base de datos: se llama MANUAL (también deshabilita el mecanismo de verificación sucio).
- Comprobación sucia
La verificación sucia es un mecanismo ejecutado durante una operación de descarga. Su propósito es encontrar entidades que las hayan cambiado y actualizarlas. Para implementar dicho mecanismo, hibernate debe almacenar la copia original del objeto (con qué se comparará el objeto real). Para ser más precisos, hibernate almacena una copia de los campos del objeto, no del objeto en sí.
Vale la pena señalar que si el gráfico de entidades es grande, entonces la operación de verificación sucia puede ser costosa. No olvide que hibernate almacena 2 copias de entidades (más o menos).
Para "reducir el costo" de este proceso, use las siguientes características:
- em.detach / em.clear: separa entidades de EntityManager
- FlushMode = MANUAL- útil en operaciones de lectura
- Inmutable : también evita operaciones de verificación sucias
- Transacciones
Como sabe, hibernate le permite actualizar entidades solo dentro de una transacción. Las operaciones de lectura ofrecen más libertad: podemos ejecutarlas sin abrir explícitamente una transacción. Pero esta es precisamente la pregunta: ¿vale la pena abrir una transacción explícitamente para operaciones de lectura?
Citaré algunos hechos:
- Cualquier declaración se ejecuta en la base de datos dentro de la transacción. Incluso si obviamente no lo abrimos. (modo de confirmación automática).
- Como regla, no estamos limitados a una consulta a la base de datos. Por ejemplo: para obtener los primeros 10 registros, probablemente desee devolver el número total de registros. Y esto es casi siempre 2 solicitudes.
- Si hablamos de datos de primavera, los métodos de repositorio son transaccionales por defecto , mientras que los métodos de lectura son de solo lectura.
- La anotación de resorte @Transactional (readOnly = true) también afecta a FlushMode, más precisamente, Spring lo pone en estado MANUAL, por lo que la hibernación no realizará una verificación sucia.
- Las pruebas sintéticas con una o dos consultas a la base de datos mostrarán que la confirmación automática es más rápida. Pero en el modo de combate, esto puede no ser así. ( excelente artículo sobre este tema , + ver comentarios)
En pocas palabras: es una buena práctica llevar a cabo cualquier comunicación con la base de datos en una transacción.
Generadores
Se necesitan generadores para describir cómo las claves primarias de nuestras entidades recibirán valores. Repasemos rápidamente las opciones:
- GenerationType.AUTO : la selección del generador se basa en el dialecto. No es la mejor opción, ya que la regla "explícito es mejor que lo implícito" solo se aplica aquí.
- GenerationType.IDENTITY es la forma más fácil de configurar un generador. Se basa en la columna de incremento automático de la tabla. Por lo tanto, para obtener id con persistir necesitamos insertar. Es por eso que elimina la posibilidad de persistencia diferida y, por lo tanto, de procesamiento por lotes.
- GenerationType.SEQUENCE es el caso más conveniente cuando obtenemos id de la secuencia.
- GenerationType.TABLE : en este caso, hibernate emula una secuencia a través de una tabla adicional. No es la mejor opción, porque en tal solución, hibernate tiene que usar una transacción separada y bloqueo por línea.
Hablemos un poco más sobre la secuencia. Para aumentar la velocidad de operación, hibernate utiliza diferentes algoritmos de optimización. Todos ellos están destinados a reducir el número de conversaciones con la base de datos (el número de viajes de ida y vuelta). Miremos con más detalle:
- ninguno : sin optimizaciones. para cada id sacamos secuencia.
- agrupado y agrupado-lo - en este caso, nuestra secuencia debería aumentar en un cierto intervalo - N en la base de datos (SequenceGenerator.allocationSize). Y en la aplicación, tenemos un cierto grupo, los valores desde los cuales podemos asignar a nuevas entidades sin acceder a la base de datos.
- hilo : para generar una ID, el algoritmo hilo usa 2 números: hi (almacenado en la base de datos: el valor obtenido de la secuencia de llamadas) y lo (almacenado solo en la aplicación: SequenceGenerator.allocationSize). En base a estos números, el intervalo para generar la identificación se calcula de la siguiente manera: [(hi - 1) * lo + 1, hi * lo + 1). Por razones obvias, este algoritmo se considera obsoleto y no se recomienda su uso.
Ahora veamos cómo se selecciona el optimizador. Hibernate tiene varios generadores de secuencia. Estaremos interesados en 2 de ellos:
- SequenceHiLoGenerator es un generador antiguo que utiliza el optimizador de hilo. Seleccionado por defecto si tenemos la propiedad hibernate.id.new_generator_mappings == false.
- SequenceStyleGenerator : se utiliza de forma predeterminada (si hibernate.id.new_generator_mappings == propiedad verdadera). Este generador admite varios optimizadores, pero el valor predeterminado se agrupa.
También puede configurar la anotación del generador @GenericGenerator.
Punto muerto
Veamos un ejemplo de una situación de pseudocódigo que puede conducir a un punto muerto:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
Para evitar tales problemas, hibernate tiene un mecanismo que evita bloqueos de este tipo: el parámetro hibernate.order_updates. En este caso, todas las actualizaciones se ordenarán por id y se ejecutarán. También mencionaré una vez más que hibernate está tratando de "retrasar" la captura de la conexión y la ejecución de insert-s y update-s.
Conjunto, Bolsa, Lista
Hibernate tiene 3 formas principales de presentar la colección de comunicación OneToMany.
- Conjunto: un conjunto desordenado de entidades sin repeticiones;
- Bolsa: un conjunto desordenado de entidades;
- La lista es un conjunto ordenado de entidades.
No existe una clase para Bag in java core que describa dicha estructura. Por lo tanto, todas las listas y colecciones son bolsas a menos que especifique una columna por la cual se ordenará nuestra colección (anotación OrderColumn. No debe confundirse con SortBy). Recomiendo encarecidamente no usar la anotación OrderColumn debido a la mala implementación (en mi opinión) de las características: no consultas SQL óptimas, posibles NULL en la hoja.
Surge la pregunta, pero ¿qué es mejor usar bolsa o set? Para empezar, cuando se usa una bolsa, son posibles los siguientes problemas:
- Si su versión de hibernate es inferior a 5.0.8, entonces hay un error bastante serio, HHH-5855 , es posible la duplicación al insertar una entidad secundaria (en el caso de cascadType = MERGE y PERSIST);
- Si usa bag para la relación ManyToMany, hibernate genera consultas extremadamente inapropiadas al eliminar una entidad de la colección: primero elimina todas las filas de la tabla de unión y luego realiza la inserción;
- Hibernate no puede buscar varias bolsas para la misma entidad al mismo tiempo.
En el caso de que desee agregar otra entidad a la conexión @OneToMany, es más rentable usar Bag, porque no requiere cargar todas las entidades relacionadas para esta operación. Veamos un ejemplo:
Referencias de fuerza
La referencia es una referencia a un objeto, que decidimos posponer la carga. En el caso de la relación de ManyToOne con fetchType = LAZY, obtenemos dicha referencia. La inicialización del objeto ocurre al momento de acceder a los campos de la entidad, con la excepción de id (ya que conocemos el valor de este campo).
Vale la pena señalar que en el caso de Lazy Loading, la referencia siempre se refiere a una fila existente en la base de datos. Por esta razón, la mayoría de los casos de carga diferida no funcionan en las relaciones OneToOne: hibernate debe hacerse JOIN para verificar si la conexión existe y si ya existía JOIN, luego hibernate la carga en el modelo de objetos. Si indicamos nullable = true en OneToOne, entonces LazyLoad debería funcionar.
Podemos crear nuestra propia referencia utilizando el método em.getReference. Es cierto que en este caso no hay garantía de que la referencia se refiera a una fila existente en la base de datos.
Pongamos un ejemplo del uso de dicho enlace:
Por si acaso, le recuerdo que obtendremos una LazyInitializationException en el caso de un EM cerrado o un enlace separado.
Fecha y hora
A pesar de que Java 8 tiene una API excelente para trabajar con fecha y hora, la API JDBC todavía le permite trabajar solo con la API de fecha anterior. Por lo tanto, analizaremos algunos puntos interesantes.
Primero, debe comprender claramente las diferencias entre LocalDateTime e Instant y ZonedDateTime. (No voy a estirar, pero daré excelentes artículos sobre este tema: el
primero y el
segundo )
Si brevementeLocalDateTime y LocalDate representan una tupla regular de números. No están vinculados a un tiempo específico. Es decir el tiempo de aterrizaje del avión no se puede almacenar en LocalDateTime. Y la fecha de nacimiento a través de LocalDate es bastante normal. Instantáneo representa un punto en el tiempo, relativo al cual podemos obtener la hora local en cualquier punto del planeta.
Un punto más interesante e importante es cómo se almacenan las fechas en la base de datos. Si tenemos el tipo TIMESTAMP WITH TIMEZONE fijado, entonces no debería haber problemas, pero si TIMESTAMP (SIN TIMEZONE) se mantiene, existe la posibilidad de que la fecha se escriba / lea incorrectamente. (excluyendo LocalDate y LocalDateTime)
Veamos por qué:
Cuando guardamos la fecha, se utiliza un método con la siguiente firma:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Como puede ver, la antigua API se usa aquí. El argumento opcional Calendario es necesario para convertir la marca de tiempo en una representación de cadena. Es decir, almacena la zona horaria en sí misma. Si no se transmite el calendario, entonces el calendario se usa por defecto con la zona horaria JVM.
Hay 3 formas de resolver este problema:
- Establezca la zona horaria deseada JVM
- Use el parámetro hibernate - hibernate.jdbc.time_zone (agregado en 5.2) - solo arreglará ZonedDateTime y OffsetDateTime
- Utilice el tipo TIMESTAMP WITH TIMEZONE
Una pregunta interesante, ¿por qué LocalDate y LocalDateTime no se encuentran bajo este problema?
La respuestaPara responder a esta pregunta, debe comprender la estructura de la clase java.util.Date (java.sql.Date y java.sql.Timestamp, sus herederos y sus diferencias en este caso no nos molestan). Fecha almacena la fecha en milisegundos desde 1970, aproximadamente en UTC, pero el método toString convierte la fecha de acuerdo con la zona horaria del sistema.
En consecuencia, cuando obtenemos una fecha sin zona horaria de la base de datos, se asigna a un objeto Timestamp para que el método toString muestre el valor deseado. Al mismo tiempo, el número de milisegundos desde 1970 puede diferir (dependiendo de la zona horaria). Es por eso que solo la hora local siempre se muestra correctamente.
También doy un ejemplo del código responsable de convertir Timesamp a LocalDateTime e Instant:
Procesamiento por lotes
Por defecto, las consultas se envían a la base de datos de una en una. Cuando se habilita el procesamiento por lotes, hibernate podrá enviar varias declaraciones en una consulta a la base de datos. (es decir, el procesamiento por lotes reduce la cantidad de viajes de ida y vuelta a la base de datos)
Para hacer esto, debes:
- Habilite el procesamiento por lotes y establezca el número máximo de declaraciones:
hibernate.jdbc.batch_size (se recomiendan de 5 a 30) - Habilite la clasificación de inserción y actualización de s:
hibernate.order_inserts
hibernate.order_updates
- Si usamos versiones, también debemos habilitar
hibernate.jdbc.batch_versioned_data: tenga cuidado aquí, necesita el controlador jdbc para poder proporcionar el número de líneas afectadas durante la actualización.
También le recordaré sobre la efectividad de la operación em.clear (): libera entidades de em, liberando así memoria y reduciendo el tiempo de la operación de verificación sucia.
Si usamos postgres, entonces también podemos decir hibernar para usar
inserción multi-raw .
Problema N + 1
Este es un tema bastante omnipresente, así que repítalo rápidamente.
Un problema de N + 1 es una situación en la que, en lugar de una sola solicitud para seleccionar N libros, se producen al menos N + 1 solicitudes.
La forma más fácil de resolver el problema N + 1 es buscar tablas relacionadas. En este caso, podemos experimentar varios otros problemas:
- Paginación en el caso de las relaciones OneToMany, hibernate no podrá especificar el desplazamiento y el límite. Por lo tanto, la paginación ocurrirá en la memoria.
- El problema de un producto cartesiano es una situación en la que una base de datos devuelve N * M * K filas para elegir N libros con M capítulos y K autores.
Hay otras formas de resolver el problema N + 1.
- FetchMode : le permite cambiar el algoritmo de carga de entidades secundarias. En nuestro caso, estamos interesados en lo siguiente:
- FetchType.SUBSELECT : carga registros secundarios en una solicitud separada. La desventaja es que toda la complejidad de la solicitud principal se repite en la subselección.
- BATCH (FetchType.SELECT + BatchSize annotation) : también carga registros como una solicitud por separado, pero junto con la subconsulta crea una condición como WHERE parent_id IN (?,?,?, ..., N)
Vale la pena señalar que cuando se usa fetch en Criteria API, FetchType se ignora: JOIN siempre se usa - JPA EntityGraph e Hibernate FetchProfile , le permiten convertir las reglas de carga de la entidad en una abstracción separada, en mi opinión, ambas implementaciones son inconvenientes.
Prueba
Idealmente, el entorno de desarrollo debería proporcionar tanta información útil como sea posible sobre la operación de hibernación y sobre la interacción con la base de datos. A saber:
- Registro
- org.hibernate.SQL: depuración
- org.hibernate.type.descriptor.sql: trace
- Estadísticas
- hibernate.generate_statistics
De las utilidades útiles, se pueden distinguir las siguientes:
- DBUnit : le permite describir el estado de la base de datos en formato XML. A veces es conveniente. Pero mejor piensa de nuevo si lo necesitas.
- DataSource-proxy
- p6spy es una de las soluciones más antiguas. ofrece registro avanzado de consultas, tiempo de ejecución, etc.
- com.vladmihalcea: db-util: 0.0.1 es una útil utilidad para encontrar problemas de N + 1. También le permite registrar consultas. La composición incluye una interesante anotación de Reintento , que reintenta la transacción en el caso de una OptimisticLockException.
- Sniffy : le permite hacer una afirmación sobre el número de solicitudes a través de la anotación. De alguna manera, más elegante que la decisión de Vlad.
Pero una vez más, repito que esto es solo para el desarrollo, esto no debería incluirse en la producción.
Literatura