Hola colegas Le recordamos que no hace mucho tiempo publicamos un
libro sobre Spark , y ahora mismo un
libro sobre Kafka está siendo revisado.
Esperamos que estos libros tengan el éxito suficiente para continuar con el tema, por ejemplo, para la traducción y publicación de literatura sobre Spark Streaming. Queríamos ofrecerle una traducción sobre la integración de esta tecnología con Kafka hoy.
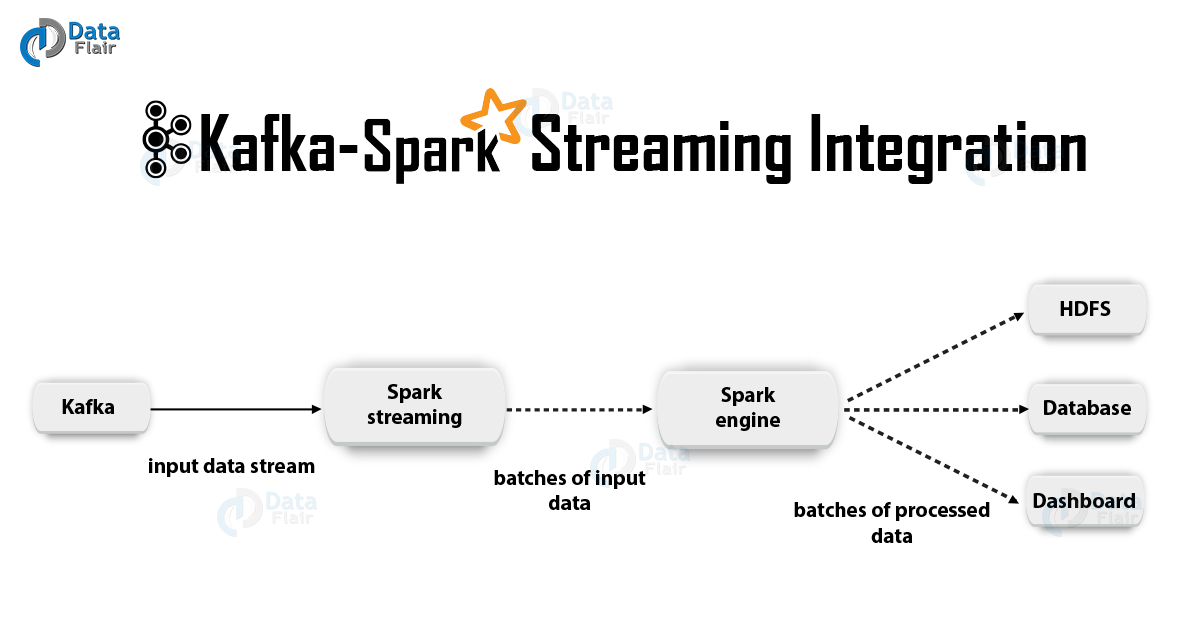
1. JustificaciónApache Kafka + Spark Streaming es una de las mejores combinaciones para crear aplicaciones en tiempo real. En este artículo, discutiremos en detalle los detalles de dicha integración. Además, veremos un ejemplo con Spark Streaming-Kafka. Luego discutimos el "enfoque del destinatario" y la opción de integración directa de Kafka y Spark Streaming. Entonces, comencemos a integrar Kafka y Spark Streaming.
 2. Integración de Kafka y Spark Streaming
2. Integración de Kafka y Spark StreamingAl integrar Apache Kafka y Spark Streaming, hay dos enfoques posibles para configurar Spark Streaming para recibir datos de Kafka, es decir, dos enfoques para integrar Kafka y Spark Streaming. En primer lugar, puede usar Destinatarios y la API de Kafka de alto nivel. El segundo enfoque (más nuevo) es trabajar sin destinatarios. Existen diferentes modelos de programación para ambos enfoques, que difieren, por ejemplo, en términos de rendimiento y garantías semánticas.
Consideremos estos enfoques con más detalle.
a. Enfoque basado en el destinatarioEn este caso, el destinatario proporciona la recepción de datos. Entonces, utilizando la API de consumo de alto nivel proporcionada por Kafka, implementamos el Destinatario. Además, los datos recibidos se almacenan en Spark Artists. Luego, se inician trabajos en Kafka - Spark Streaming, dentro de los cuales se procesan los datos.
Sin embargo, cuando se utiliza este enfoque, el riesgo de pérdida de datos en caso de falla (con la configuración predeterminada) permanece. En consecuencia, será necesario incluir adicionalmente un registro de escritura anticipada en Kafka - Spark Streaming para eliminar la pérdida de datos. Por lo tanto, todos los datos recibidos de Kafka se almacenan sincrónicamente en el registro de escritura anticipada en un sistema de archivos distribuido. Es por eso que, incluso después de una falla del sistema, todos los datos se pueden restaurar.
A continuación, veremos cómo utilizar este enfoque con destinatarios en una aplicación con Kafka - Spark Streaming.
yo. VinculanteAhora conectaremos nuestra aplicación de transmisión con el siguiente artefacto para aplicaciones Scala / Java, usaremos las definiciones de proyecto para SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
Sin embargo, al implementar nuestra aplicación, tendremos que agregar la biblioteca antes mencionada y sus dependencias, esto será necesario para las aplicaciones Python.
ii. ProgramacionLuego, cree una
DStream entrada
DStream importando
KafkaUtils en el código de la aplicación de secuencia:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
Además, utilizando las opciones de createStream, puede especificar clases clave y clases de valor, así como las clases correspondientes para su decodificación.
iii) DespliegueComo con cualquier aplicación Spark, el comando spark-submit se usa para iniciar. Sin embargo, los detalles son ligeramente diferentes en las aplicaciones Scala / Java y en las aplicaciones Python.
Además, con
–packages puede agregar
spark-streaming-Kafka-0-8_2.11 y sus dependencias directamente a
spark-submit , esto es útil para aplicaciones Python donde es imposible administrar proyectos usando SBT / Maven.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
También puede descargar el archivo JAR del
spark-streaming-Kafka-0-8-assembly del artefacto Maven
spark-streaming-Kafka-0-8-assembly desde el repositorio de Maven. Luego agréguelo a
spark-submit con -
jars .
b. Enfoque directo (sin destinatarios)Después del enfoque utilizando destinatarios, se desarrolló un enfoque más nuevo, el "directo". Proporciona garantías confiables de extremo a extremo. En este caso, periódicamente le preguntamos a Kafka sobre las compensaciones de las compensaciones para cada tema / sección, y no organizamos la entrega de datos a través de los destinatarios. Además, se determina el tamaño del fragmento de lectura, esto es necesario para el procesamiento correcto de cada paquete. Finalmente, se usa una API de consumo simple para leer rangos con datos de Kafka con los desplazamientos dados, especialmente cuando se inician los trabajos de procesamiento de datos. Todo el proceso es como leer archivos de un sistema de archivos.
Nota: Esta característica apareció en Spark 1.3 para Scala y la API de Java, así como en Spark 1.4 para la API de Python.
Ahora analicemos cómo aplicar este enfoque en nuestra aplicación de transmisión.
La API del consumidor se describe con más detalle en el siguiente enlace:
Apache Kafka Consumer | Ejemplos de Kafka Consumeryo. Vinculante
Es cierto que este enfoque solo es compatible con aplicaciones Scala / Java. Con el siguiente artefacto, construya el proyecto SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii. ProgramacionA continuación, importe KafkaUtils y cree un
DStream entrada en el código de la aplicación de transmisión:
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
En los parámetros de Kafka, deberá especificar
metadata.broker.list o
bootstrap.servers . Por lo tanto, de manera predeterminada, consumiremos datos a partir del último desplazamiento en cada sección de Kafka. Sin embargo, si desea que la lectura comience desde el fragmento más pequeño, entonces en los parámetros de Kafka debe establecer la opción de configuración
auto.offset.reset .
Además, trabajando con las opciones
KafkaUtils.createDirectStream , puede comenzar a leer desde un desplazamiento arbitrario. Luego haremos lo siguiente, que nos permitirá acceder a los fragmentos de Kafka consumidos en cada paquete.
Si queremos organizar el monitoreo de Kafka basado en Zookeeper utilizando herramientas especiales, podemos actualizar Zookeeper nosotros mismos con su ayuda.
iii) DespliegueEl proceso de implementación en este caso se asemeja al proceso de implementación en la variante con el destinatario.
3. Los beneficios de un enfoque directoEl segundo enfoque para integrar Spark Streaming con Kafka supera al primero por las siguientes razones:
a. Simultaneidad SimultáneaEn este caso, no necesita crear muchas secuencias de entrada de Kafka y combinarlas. Sin embargo, Kafka - Spark Streaming creará tantos segmentos de RDD como segmentos de Kafka para consumo. Todos estos datos de Kafka se leerán en paralelo. Por lo tanto, podemos decir que tendremos una correspondencia uno a uno entre los segmentos de Kafka y RDD, y ese modelo es más comprensible y más fácil de configurar.
b. EfectividadPara eliminar por completo la pérdida de datos durante el primer enfoque, la información debía almacenarse en un registro de registros principales y luego replicarse. De hecho, esto es ineficiente porque los datos se replican dos veces: la primera vez por el propio Kafka y la segunda por el registro de escritura anticipada. En el segundo enfoque, este problema se elimina, ya que no hay destinatario y, por lo tanto, no se necesita un diario de escritura líder. Si tenemos un almacenamiento de datos suficientemente largo en Kafka, puede recuperar mensajes directamente desde Kafka.
s Semántica de una sola vezBásicamente, utilizamos la API Kafka de alto nivel en el primer enfoque para almacenar fragmentos de lectura consumidos en Zookeeper. Sin embargo, esta es la costumbre de consumir datos de Kafka. Si bien la pérdida de datos se puede eliminar de manera confiable, existe una pequeña posibilidad de que, en algunos casos, los registros individuales se consuman dos veces. El punto es la inconsistencia entre el mecanismo confiable de transferencia de datos en Kafka - Spark Streaming y la lectura de fragmentos que ocurre en Zookeeper. Por lo tanto, en el segundo enfoque, usamos la API Kafka simple, que no requiere recurrir a Zookeeper. Aquí, los fragmentos leídos se rastrean en Kafka - Spark Streaming, para esto, se utilizan puntos de control. En este caso, se elimina la inconsistencia entre Spark Streaming y Zookeeper / Kafka.
Por lo tanto, incluso en caso de fallas, Spark Streaming recibe cada registro estrictamente una vez. Aquí debemos asegurarnos de que nuestra operación de salida, en la que los datos se almacenan en almacenamiento externo, sea idempotente o una transacción atómica en la que se almacenan tanto los resultados como las compensaciones. Así es como se logra exactamente la semántica en la derivación de nuestros resultados.
Aunque, hay un inconveniente: las compensaciones en Zookeeper no se actualizan. Por lo tanto, las herramientas de monitoreo de Kafka basadas en Zookeeper no le permiten seguir el progreso.
Sin embargo, todavía podemos referirnos a las compensaciones, si el procesamiento se organiza de esta manera: recurrimos a cada paquete y actualizamos Zookeeper nosotros mismos.
Eso es todo lo que queríamos hablar sobre la integración de Apache Kafka y Spark Streaming. Esperamos que lo hayas disfrutado.