Esta es la segunda conferencia con J. Subbotnik sobre bases de datos, la
primera que publicamos hace un par de semanas.
El jefe del grupo DBMS de propósito general Dmitry Sarafannikov habló sobre la evolución del almacén de datos en Yandex: cómo decidimos crear una interfaz compatible con S3, por qué elegimos PostgreSQL, qué tipo de rastrillo pisamos y cómo lidiar con ellos.
- Hola a todos! Mi nombre es Dima, en Yandex hago bases de datos.
Te diré cómo hicimos S3, cómo llegamos a hacer exactamente S3 y qué tipo de almacenamiento era antes. El primero de ellos es Elliptics, está publicado en código abierto, disponible en GitHub. Muchos pueden haberlo encontrado.

Esta es esencialmente una tabla hash distribuida con una clave de 512 bits, el resultado de SHA-512. Forma un llavero que se divide aleatoriamente entre máquinas. Si desea agregar máquinas allí, las claves se redistribuyen, se produce un reequilibrio. Este repositorio tiene sus propios problemas asociados, en particular, con el reequilibrio. Si tiene una cantidad suficientemente grande de claves, entonces con volúmenes en constante crecimiento necesita volcar constantemente los automóviles allí, y en una cantidad muy grande de claves, el reequilibrio puede simplemente no converger. Este fue un problema lo suficientemente grande.
Pero al mismo tiempo, este almacenamiento es ideal para datos más o menos estáticos, cuando carga una gran cantidad de una sola vez y luego carga una carga de solo lectura. Para tales decisiones, encaja perfectamente.
Vamos más lejos Los problemas con el reequilibrio eran bastante graves, por lo que apareció el siguiente almacenamiento.

¿Cuál es su esencia? Esto no es almacenamiento de valor clave, es almacenamiento de valor. Cuando carga algún objeto o archivo allí, le responde con una clave, con la cual puede recoger este archivo. Que da Teóricamente, cien por ciento de acceso de escritura, si tiene espacio libre en el almacenamiento. Si tiene una máquina de escribir, simplemente escribe a otras personas que no están en las que hay espacio libre, obtiene otras claves y recoge sus datos con calma.
Este almacenamiento es muy fácil de escalar, puede tirarlo con hierro, funcionará. Es muy simple, confiable. Su único inconveniente: el cliente no administra la clave, y todos los clientes deben almacenar las claves en algún lugar, almacenar la asignación de sus claves. Esto es inconveniente para todos. De hecho, esta es una tarea muy similar para todos los clientes, y cada uno la resuelve a su manera en sus metabases, etc. Esto es inconveniente. Pero al mismo tiempo, no quiero perder la confiabilidad y simplicidad de este almacenamiento, de hecho funciona con la velocidad de la red.
Entonces comenzamos a mirar S3. Este es el almacenamiento de valor clave, el cliente administra la clave, todo el almacenamiento se divide en los llamados cubos. En cada segmento, el espacio clave es de menos infinito a más infinito. La clave es algún tipo de cadena de texto. Y nos decidimos por esta opción. ¿Por qué S3?
Todo es bastante simple. En este momento, ya se han escrito muchos clientes listos para varios lenguajes de programación, ya se han escrito muchas herramientas listas para almacenar algo en S3, por ejemplo, copias de seguridad de bases de datos. Andrew
habló sobre uno de los ejemplos. Ya existe una API razonablemente bien pensada que se ha estado ejecutando en los clientes durante años, y no necesita inventar nada allí. La API tiene muchas características convenientes, como listados, cargas de varias partes, etc. Por lo tanto, decidimos quedarnos en ello.
¿Cómo hacer S3 desde nuestro almacenamiento? ¿Qué te viene a la mente? Dado que los propios clientes almacenan la asignación de claves, simplemente tomamos, colocamos la base de datos junto a ellas y almacenaremos la asignación de estas claves en ella. Al leer, solo encontraremos las claves y el almacenamiento en nuestra base de datos, y le daremos al cliente lo que quiere. Si bosquejas esto esquemáticamente, ¿cómo sucede el relleno?

Hay una cierta entidad, aquí se llama Proxy, el llamado backend. Acepta el archivo, lo carga en el almacenamiento, obtiene la clave desde allí y lo guarda en la base de datos. Todo es bastante simple.
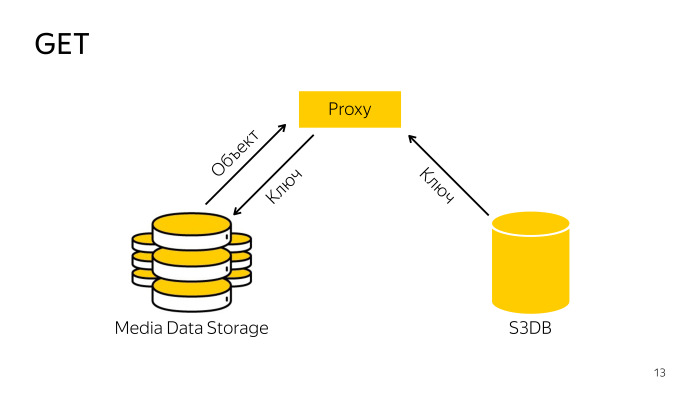
¿Cómo es el recibo? El proxy encuentra la clave necesaria en la base de datos, va con la clave de almacenamiento, descarga el objeto desde allí y se la entrega al cliente. Todo es simple también.
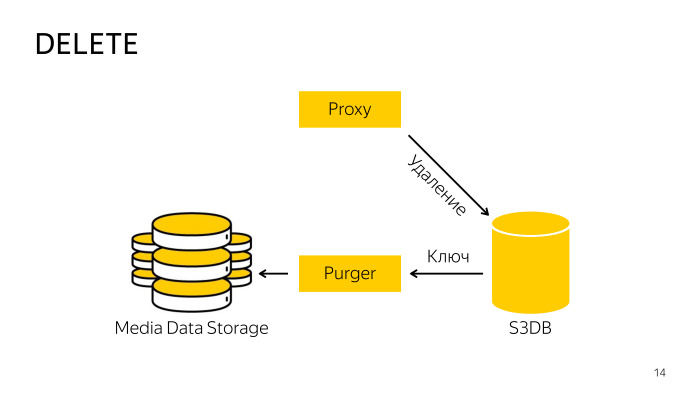
¿Cómo es la eliminación? Al eliminar directamente del almacenamiento, el proxy no funciona, ya que es difícil coordinar la base de datos y el almacenamiento, por lo que solo va a la base de datos, le dice que este objeto se elimina, allí el objeto se mueve a la cola de eliminación y, en segundo plano, un profesional especialmente capacitado el robot toma estas claves, las elimina del almacenamiento y de la base de datos. Todo aquí también es bastante simple.
Elegimos PostgreSQL como la base de datos para esta metabase.
Ya sabes que lo amamos mucho. Con la transferencia de Yandex.Mail, adquirimos suficiente experiencia en PostgreSQL, y cuando se movieron diferentes servicios de correo, desarrollamos varios patrones de fragmentación. Uno de ellos cayó bien en el S3 con ligeras modificaciones, pero salió bien allí.
¿Cuáles son las opciones de fragmentación? Este es un repositorio grande. En una escala de Yandex, debe pensar de inmediato que habrá muchos objetos, debe pensar de inmediato en cómo fragmentarlo todo. Puede fragmentar por hash en nombre del objeto, esta es la forma más confiable, pero no funcionará aquí, porque S3 tiene, por ejemplo, listados que deberían mostrar la lista de claves en orden ordenado, cuando almacena en caché, todas las clasificaciones desaparecerán, debe eliminarlas todos los objetos para que la salida cumpla con la especificación API.
La siguiente opción, puede fragmentar por hash en nombre o id del depósito. Un depósito puede vivir dentro de un fragmento de base de datos.
Otra opción es fragmentar entre rangos clave. Dentro del cubo, hay espacio desde menos infinito hasta más infinito, podemos dividirlo en cualquier número de rangos, llamamos a este rango un fragmento, puede vivir en un solo fragmento.

Elegimos la tercera opción, fragmentar por trozos, porque teóricamente puede haber un número infinito de objetos en un cubo, y estúpidamente no cabe en una sola pieza de hierro. Habrá grandes problemas, por lo que cortaremos y organizaremos los fragmentos a nuestro gusto. Eso es todo.

Que paso La base de datos completa consta de tres componentes. Proxy S3: un grupo de hosts, también hay una base de datos. PL / Proxy están bajo el equilibrador, las solicitudes de ese backend vuelan allí. Además S3Meta, un grupo de graves, que almacena información sobre cubos y fragmentos. Y S3DB, fragmentos donde se almacenan los objetos, una cola de eliminación. Si se representa esquemáticamente, se ve así.
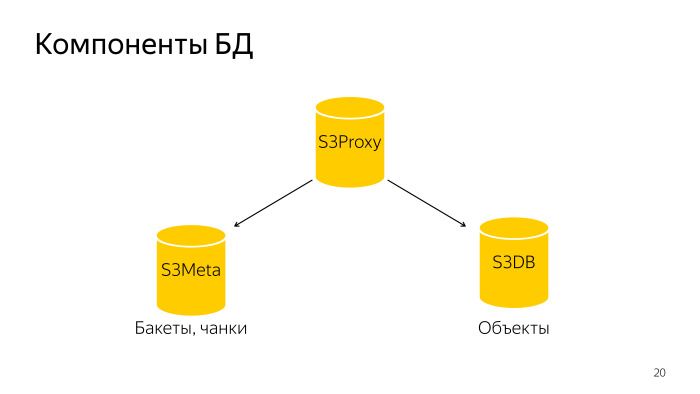
Una solicitud llega a S3Proxy, va a S3Meta y S3DB y emite información al principio.

Consideremos con más detalle. S3Proxy, las funciones dentro de él se crean en el lenguaje de procedimiento PLProxy, es un lenguaje que le permite ejecutar procedimientos o solicitudes almacenados de forma remota. Así es como se ve el código de la función ObjectInfo, en esencia, una solicitud Get.
El clúster LProxy tiene el operador Cluster, en este caso db_ro. ¿Qué significa esto?

Si una configuración típica de fragmento de base de datos, hay un maestro y dos réplicas. Master ingresa al clúster db_rw, los tres hosts ingresan db-ro, aquí es donde puede enviar solo una solicitud de lectura y se envía una solicitud de escritura a db_rw. El clúster db_rw incluye todos los maestros de todos los fragmentos.
La siguiente instrucción RUN ON, toma el valor all, lo que significa ejecutar en todos los fragmentos una matriz o algún tipo de fragmento. En este caso, recibe el resultado de la función get_object_shard como entrada; este es el número del fragmento en el que se encuentra el objeto dado.
Y objetivo: qué función invocar en el fragmento remoto. Llamará a esta función y sustituirá los argumentos que llegaron a esta función.

La función get_object_shard también está escrita en PLProxy, que ya es un clúster meta_ro, la solicitud volará al fragmento S3Meta, que devolverá esta función get_bucket_meta_shard.
S3Meta también se puede fragmentar, también lo instalamos, mientras que esto es irrelevante, pero hay una oportunidad. Y llamará a la función get_object_shard en S3Meta.

get_bucket_meta_shard es solo un hash de texto en nombre de un cubo, barajamos S3Meta solo por un hash en nombre de un cubo.

Considere S3Meta lo que está sucediendo en él. La información más importante que existe es una tabla con fragmentos. Recorté un poco de información innecesaria, lo más importante que queda es bucket_id, la tecla de inicio, la tecla de finalización y el fragmento en el que se encuentra este fragmento.

¿Cómo sería una consulta en dicha tabla, que nos devolvería el fragmento en el que, por ejemplo, se encuentra el objeto de prueba? Me gusta esto Menos infinito en forma de texto, lo presentamos como un valor nulo, hay puntos tan sutiles que debe verificar start_key y end_key para Null.

La solicitud no se ve muy bien y el plan se ve aún peor. Como una de las opciones para un plan para dicha solicitud, BitmapOr. Y 6,000 huesos valen ese plan.

¿Cómo puede ser diferente? Hay algo tan maravilloso en PostgreSQL como el índice general, que puede indexar el tipo de rango, el rango es esencialmente lo que necesitamos. Hicimos este tipo, la función s3.to_keyrange nos devuelve, de hecho, el rango. Podemos verificar con el operador contiene, encontrar el fragmento en el que está nuestra clave. Y para esto, la restricción de exclusión se construye aquí, lo que garantiza la no intersección de estos fragmentos. Necesitamos permitir, preferiblemente a nivel de la base de datos, alguna restricción para asegurarnos de que los fragmentos no puedan cruzarse entre sí, de modo que solo se devuelva una línea en respuesta a la solicitud. De lo contrario, no será lo que queríamos. Así es como se ve el plan para dicha solicitud, el index_scan habitual. Esta condición encaja completamente en la condición de índice, y dicho plan tiene solo 700 huesos, 10 veces menos.

¿Qué es Excluir restricción?

Creemos una tabla de prueba con dos columnas, y agreguemos dos restricciones, una única que todos conozcan, y una restricción de exclusión, que tiene parámetros iguales, tales operadores. Vamos a configurarlo con dos operadores iguales, tal placa fue construida.

Luego intentamos insertar dos líneas idénticas, obtenemos el error de violación de la unicidad de la clave en la primera restricción. Si lo dejamos, ya hemos violado la restricción de exclusión. Este es un caso común de una restricción única.

De hecho, una restricción única es la misma restricción de exclusión con los operadores iguales, pero en el caso de la restricción de exclusión, puede construir algunos casos más generales.

Tenemos tales índices. Si observa detenidamente, verá que ambos son índices esenciales y, en general, son lo mismo. Probablemente se pregunte por qué duplicar este negocio en absoluto. Te lo diré

Los índices son tales, especialmente el índice esencial, que la tabla vive su propia vida, se producen actualizaciones, se dividen y así sucesivamente, el índice va mal allí, deja de ser óptimo. Y existe tal práctica, en particular la extensión pg repack, los índices se reconstruyen periódicamente, de vez en cuando se reconstruyen.
¿Cómo reconstruir un índice bajo una restricción única? Cree crear índice actualmente, cree el mismo índice con calma junto a él sin bloquear, y luego la expresión alterar tabla de restricción user_index es tal y tal. Y todo, todo está claro y bien aquí, funciona.
En el caso de la restricción de exclusión, puede reconstruirla solo mediante el bloqueo de reindexación, más precisamente, su índice se bloqueará exclusivamente y, de hecho, le quedarán todas las consultas. Esto es inaceptable, el índice general se puede construir el tiempo suficiente. Por lo tanto, nos mantenemos al lado del segundo índice, que es más pequeño en volumen, ocupa menos espacio, el planeador lo usa y podemos reconstruir ese índice de manera competitiva sin bloquearlo.
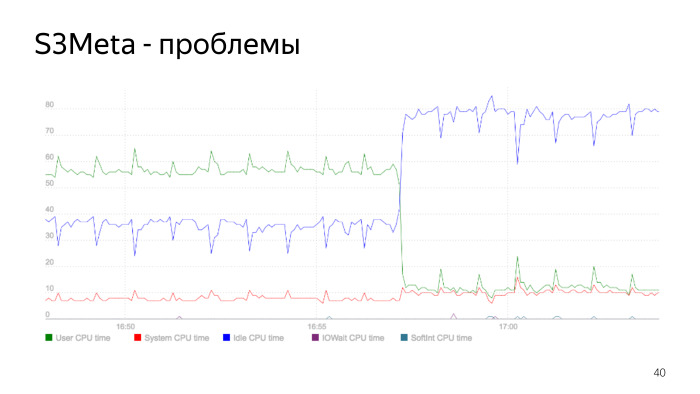
Aquí hay un gráfico del consumo del procesador. La línea verde es el consumo del procesador en user_space, salta del 50% al 60%. En este punto, el consumo cae bruscamente, este es el momento en que se reconstruye el índice. Reconstruimos el índice, eliminamos el anterior, el consumo de nuestro procesador se redujo drásticamente. Este es un problema de índice esencial, lo es, y este es un buen ejemplo de cómo puede ser esto.
Cuando hicimos todo esto, comenzamos con la versión 9.5 S3DB, de acuerdo con el plan, planeamos apilar 10 mil millones de objetos en cada fragmento. Como sabe, más de mil millones e incluso problemas anteriores comienzan cuando una tabla tiene muchas filas, todo se vuelve mucho peor. Hay una práctica de despedida. En ese momento había dos opciones, estándar a través de herencia, pero esto no funciona muy bien, ya que hay una velocidad de selección de partición lineal. Y a juzgar por la cantidad de objetos, necesitamos muchas particiones. Los chicos de Postgres Pro luego cortaron activamente la extensión pg_pathman.

Elegimos pg_pathman, no teníamos otra opción. Incluso la versión 1.4. Y como puede ver, usamos 256 particiones. Dividimos toda la tabla de objetos en 256 particiones.
¿Qué hace pg_pathman? Con esta expresión, puede crear 256 particiones divididas por hash de la columna de oferta.

¿Cómo funciona pg_pathman?
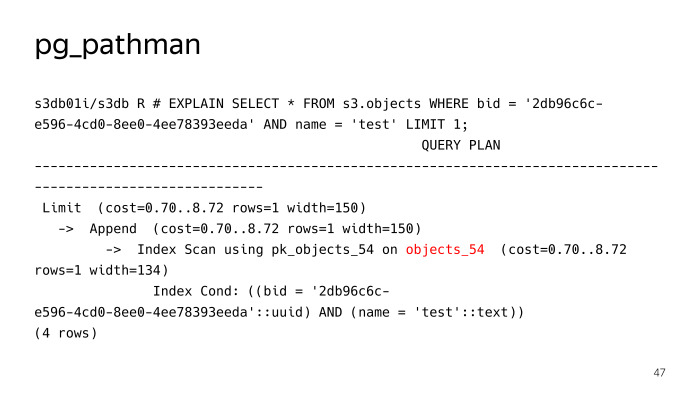
Registra sus ganchos en el planeador y, más adelante, solicita que reemplace, en esencia, el plan. Vemos que no buscó 256 particiones para una consulta de búsqueda regular de un objeto con la prueba de nombre, pero inmediatamente determinó que era necesario subir a la tabla objects_54, pero aquí no todo iba bien, pg_pathman tiene sus propios problemas. En primer lugar, había bastantes errores al principio, mientras estaba aserrando, pero gracias a los chicos de Postgres Pro, los repararon rápidamente y los arreglaron.
El primer problema es la dificultad de actualizarlo. El segundo problema son las declaraciones preparadas.
Consideremos con más detalle. En particular, la actualización. ¿En qué consiste pg_pathman?

Consiste esencialmente en código C, que está empaquetado en una biblioteca. Y consta de la parte SQL, todo tipo de funciones para crear particiones, etc. Además, interactúa con las funciones que están en la biblioteca. Estas dos partes no se pueden actualizar al mismo tiempo.
A partir de aquí surgen dificultades, algo como este algoritmo para actualizar la versión de pg_pathman, primero lanzamos un nuevo paquete con una nueva versión, pero PostgreSQL tiene versiones antiguas cargadas en la memoria, lo usa. Esto es inmediatamente en cualquier caso, la base debe reiniciarse.
Luego, llamamos a la función set_enable_parent, activa la función en la tabla principal, que está desactivada de manera predeterminada. Luego, apague a pathman, reinicie la base de datos, diga ALTER EXTENSION UPDATE, en este momento todo cae en la tabla principal.
A continuación, active pathman y ejecute la función, que se encuentra en la extensión, que transfiere los objetos de la tabla principal que los atacó en este corto período de tiempo, los transfiere nuevamente a las tablas donde deberían estar. Y luego apague el uso de la tabla principal, busque en ella.

El siguiente problema son las declaraciones preparadas.

Si bloqueamos la misma solicitud ordinaria, busque por oferta y clave, intente ejecutarla. Realice cinco veces, todo está bien. Llevamos a cabo el sexto, vemos ese plan. Y a este respecto vemos las 256 particiones. Si observa de cerca estas condiciones, vemos dólar 1, dólar 2, este es el llamado plan genérico, el plan general. Las primeras cinco consultas se crearon individualmente, se usaron planes individuales para estos parámetros, pg_pathman pudo determinar de inmediato, ya que el parámetro se conoce de antemano, podría determinar inmediatamente la tabla a dónde ir. En este caso, no puede hacer esto. En consecuencia, el plan debe tener las 256 particiones, y cuando el ejecutor va a hacer esto, va y toma un bloqueo compartido para las 256 particiones, y el rendimiento de dicha solución no funcionará de inmediato. Simplemente pierde todas sus ventajas, y cualquier solicitud se lleva a cabo increíblemente larga.

¿Cómo salimos de esta situación? Tuve que envolver todo dentro de los procedimientos almacenados en ejecución, en SQL dinámico, para que las declaraciones preparadas no se usaran y el plan se construyera cada vez. Así es como funciona.
La desventaja es que debe agrupar todo el código en estructuras que toquen estas tablas. Esto es más difícil de leer aquí.

¿Cómo es la distribución de los objetos? En cada fragmento S3DB, los contadores de fragmentos se almacenan, también hay información sobre qué fragmentos están en este fragmento y los contadores se almacenan para ellos. Para cada operación de mutación en un objeto (agregar, eliminar, cambiar, reescribir) estos contadores para el cambio de fragmento. Para no actualizar la misma línea cuando el vertido activo está en este fragmento, utilizamos una técnica bastante estándar cuando insertamos un contador delta en una tabla separada, y una vez por minuto un robot especial pasa y agrega todo esto, actualiza los contadores en el fragmento .

Además, estos contadores se entregan a S3Meta con cierto retraso, ya hay una imagen completa de cuántos contadores hay en cada fragmento, luego puede ver la distribución por fragmentos, cuántos objetos hay en qué fragmento y, en función de esto, se toma una decisión donde cae el nuevo fragmento. Cuando crea un depósito, de forma predeterminada, se crea un solo fragmento de menos infinito a más infinito, dependiendo de la distribución actual de objetos que S3Meta conoce, cae en algún tipo de fragmento.
Cuando vierte datos en este depósito, todos estos datos se vierten en este fragmento, cuando se alcanza un cierto tamaño, un robot especial llega y comparte este fragmento.

Hacemos estos trozos pequeños. Hacemos esto para que en este caso este pequeño fragmento se pueda arrastrar a otro fragmento. ¿Cómo se produce una división de fragmentos? Aquí hay un robot normal, se va y divide esta porción en S3DB con confirmación en dos fases y actualiza la información en S3Meta.
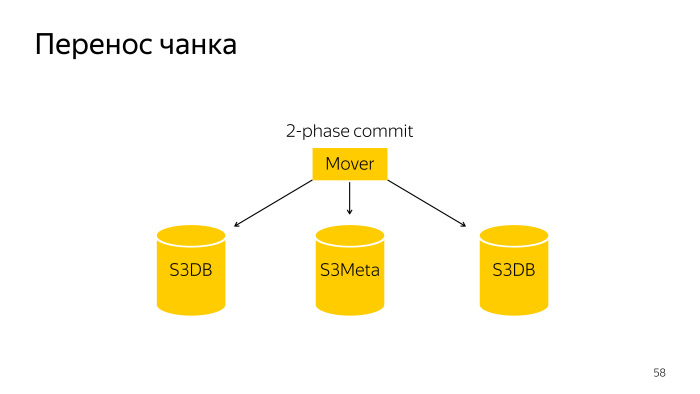
La transferencia de fragmentos es una operación un poco más complicada; es una confirmación de dos fases sobre tres bases, S3Meta y dos fragmentos, S3DB, arrastra de una a otra.

S3 tiene una característica como listados, esto es lo más difícil, y también hubo problemas con él. De hecho, los listados, dices S3, muéstrame los objetos que tengo. El parámetro resaltado en rojo ahora es nulo. Este parámetro, delímetro, separador, puede especificar los listados con qué separador desea.
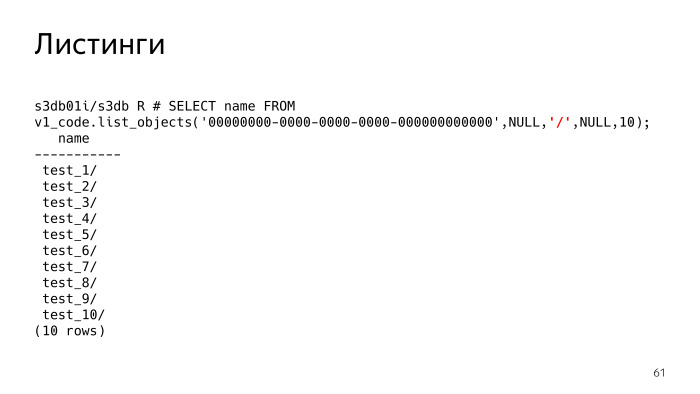
¿Qué significa esto? Si el delimitador no está configurado, vemos que simplemente se nos da una lista de archivos. Si establecemos el delímetro, en esencia, S3 debería mostrarnos las carpetas. Debo entender que existen tales carpetas y, de hecho, muestra todas las carpetas y archivos en la carpeta actual. La carpeta actual tiene el prefijo, este parámetro es Nulo. Vemos que hay 10 carpetas.
Todas las claves no se almacenan en algún tipo de estructura jerárquica de árbol, como en el sistema de archivos. Cada objeto se almacena como una cadena y tienen un prefijo común simple. S3 debe entender que esto es un asno

SQL, . , PL/pgSQL. , repeatable read. , . , - - , .
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
, .
. , .
Docker,
Behave Behave
. , , , .
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
En la replicación lógica, hay una serie de problemas que resolveremos, trataremos de impulsarlo hacia arriba. La segunda opción: puede rechazar el histograma, intente poner este rango de texto en btree. Este no es un tipo unidimensional, y btree solo funciona con tipos unidimensionales. Pero la condición de que los fragmentos no se superpongan con nosotros nos permitirá poner nuestro caso en btree. Justo ayer hicimos un prototipo que funciona. Se implementa en funciones PL / pgSQL. Obtuvimos una aceleración notable, optimizaremos en esta dirección.