Hola Habr! En abril, publicamos oficialmente los mejores videos de DotNext 2017 Moscú en acceso abierto. El resultado fue una lista de reproducción de 25 informes . Solo un recordatorio aquí de esta lista de reproducción mágica.
¡Ahora estoy viendo los videos más interesantes e invito a unirse! Para facilitar la integración en la visualización de las grabaciones de la conferencia, debajo del corte encontrará breves notas sobre diez informes que recibieron las calificaciones más altas de los visitantes del pasado DotNext. Si de las 25 piezas puede ver solo algunos informes, no dude en elegir de esta lista.
Formalmente, cuanto más baja es la lista, más alta es la calificación. Pero hay una aclaración importante: todos los informes de los diez primeros tienen una calificación muy, muy alta, y su posición exacta depende en gran medida de los matices del recuento. Por ejemplo, si usa el quórum suave, la nota clave de Andrey Akinshin sobre las pruebas de rendimiento superará el informe de Sasha Goldstein sobre depuración y creación de perfiles en Linux. En otras palabras, ver todo :-)
Debajo del corte habrá una tabla de contenido para una navegación conveniente sobre el contenido de la publicación.

Tabla de contenidos
Dino Esposito, JetBrains
Al darle una tarea a una persona, es necesario verificar que no solo recuerde sus palabras, sino que también entienda qué hacer a continuación. ¿Qué aprendiste de nuestra conversación? ¿Cuáles serán los primeros pasos? Preguntas simples y procesables.
Esta historia de Dino no es un informe estándar, sino la nota final. Además de que el objetivo de la conferencia inaugural es establecer la dirección de la conferencia, la conferencia final establece la vida futura del participante. ¿Qué aprendiste de la conferencia? ¿Cómo afectará esto a tu vida?
En esta charla, Dino nos lleva 30 años por delante con una máquina del tiempo y agrega otro nivel de profundidad a estas preguntas estándar. Volviendo del futuro, ¿cómo nos relacionaremos con el presente?

Dino cuenta un gran, durante cuarenta minutos, y un pronóstico muy razonable para los próximos años. Incluye blockchain, bigdata e incluso un alma digital. ¿Nos conquistarán los robots? Spoiler: ¡al final todos morirán! (Sí, el juego real está sucediendo allí).
Pero aquí me gustaría discutir. Realmente me gusta la discusión reciente sobre Reddit: "¿Cómo se apodera del mundo si se encuentra en 1990 con todos sus recuerdos actuales, pero en el cuerpo del niño que alguna vez fue?" Recientemente Vladimir Guriev hizo una breve traducción de una de las respuestas (esta es la persona que nos presentó previamente un libro de texto de marketing moderno ), pero es mejor leer el original . Nosotros, como ingenieros y personas dedicadas a mejorar el mundo mediante la creación de algunos milagros técnicos, creemos fácilmente en un hombre del futuro que puede sacar una nave nuclear de palos y cuerdas (lo mismo que hoy, pero un poco mejor). Pero si vuelves a la realidad, la gente estúpida (como yo, por ejemplo) hace cosas mucho más aburridas y desagradables.
Le aconsejo que mire la nota clave de Dino y decida sobre este asunto usted mismo. ¿Quizás escribir la historia en comentarios sobre Habré? ¿Por qué somos peores que Reddit?
Mikhail Shcherbakov
Una nueva parte del informe de Mikhail sobre los siguientes tipos de defensa:
- Protección contra redireccionamiento abierto;
- Protección de datos;
- Protección XSS;
- Configurar CSP;
- Falsificación anti-solicitud;
- Configuración CORS;
- Uso de cookies.
El informe se basó en los resultados de la participación de Michael en el perpetuo Microsoft Bug Bounty Program. El primer error que encontró fue solo en defensa contra Open Redirect, que se muestra al comienzo del informe en solo un minuto.
Para comprender el tema, otras partes del informe hablan sobre los cambios en la API de protección de datos, después de lo cual nos sumergimos en trabajar con la seguridad y los agujeros durante cuarenta minutos. Entiende cómo funcionan los mecanismos de protección incorporados contra XSS y CSRF, qué características de criptografía están disponibles de fábrica, cómo se organiza la gestión de la sesión, etc.
Yo mismo estoy interesado en este tema y, a menudo, veo informes de seguridad en YouTube. Lo más terrible que le espera como espectador: dos horas de tedio, el 90% consiste en lugares comunes como "si eres estúpido, entonces todo es muy malo", al final del cual te encuentras con una nariz dormida en el teclado. El informe de Misha se compara favorablemente con el hecho de que no hay tiempo para dormir: pensamientos claramente delineados, ejemplos de códigos reales para ilustrarlos, si se introducen conceptos, diapositivas con redacción y enlaces a materiales extendidos.
Dichos informes deben observarse de inmediato, ya que aprendí a escribir mi primer controlador, para no volver a escribir mucho código en vano más adelante.
Por cierto, en febrero publicamos una transcripción del informe de Mikhail sobre Habré. Si no tiene tiempo para mirar, siempre puede leer .
Federico Lois, Corvalius
La brutal historia de cómo tratar a C # con tanta crueldad que se vuelve diferente a él, pero comienza a funcionar muy rápido y bien.
Para ser justos, esto se afirma en aproximadamente cada segundo hilo sobre el rendimiento en Habré o cada primera discusión sobre una lata de cerveza.
Después de todo, a menudo escribimos reseñas de algo en Habr y durante mucho tiempo ya entendimos la esencia del concepto de "hardcore" para un desarrollador ruso. Hardcore y performance son hermanos gemelos. Estamos hablando de rendimiento, nos referimos a hardcore, estamos hablando de hardcore, nos referimos a rendimiento.
Federico desarrolló su propia escala:

Este es un informe de rendimiento, todo lo que amas. Y es muy cínico e inteligible. No es muy fácil discutir con el orador, dado que él es uno de los desarrolladores de RavenDB, y ella solo tiene que ver con la velocidad. Habrá cosas desagradables sobre el hecho de que no puede usar try-catch y LINQ, se tratará de la línea, sobre la ley de Pareto (convertida en una lista de verificación), cualquier cosa para engañar al sistema y lograr una aceleración significativa.
Todo esto me recuerda a ese video:
Operador : Espera un segundo, déjame quitar la altura. Bueno nafig! Estás saltando sobre este techo.
Trazador : ¿Listo?
Operador : si.
Trazador : silenciosamente huye, salta, perfora silenciosamente el techo del edificio y entra en las profundidades con un hacha
La necesidad de usar tales trampas para acelerar el código ahora me parece este "salto de fe". Pero si un día tiene que saltar, es mejor ver este informe que no verlo (y si es demasiado vago para verlo, lea nuestra traducción ).
Matthias Koch, JetBrains
NUKE es uno de los proyectos en los que Matthias está trabajando. Este es un sistema de automatización de compilación en el que puede describir todo en C # DSL.
C # aquí, a pesar del hecho de que le permite describir el ensamblaje en la infraestructura familiar, en el IDE, con autocompletado decente, y no sufrir haciendo clic en botones en Jenkins o, por ejemplo, condiciones de hacinamiento en forma de líneas en MSBuild. Casi una quinta parte del informe se dedica a una discusión sobre la aplicabilidad de Jenkins y MSB.
Es genial que este video haya aparecido en el dominio público. El hecho es que tengo una larga historia personal de aversión a Jenkins, y cada nueva persona necesita volver a explicar la misma balalaika sobre las razones y conclusiones. Ahora solo dale un enlace a este video.
En cuanto a la parte principal del informe, este es un montón de material práctico sobre qué es Nuke y cómo vivir con él. Ahora tienen más de setecientos commits y más de una docena de contribuyentes en el github , por lo que probablemente ya se pueda usar. Un informe del creador de la tecnología es la mejor manera de ayudar en el desarrollo.
Dmitry Soshnikov, Microsoft
Un informe muy bueno que sienta las bases para programar redes neuronales C # para aquellos que aún no lo han hecho, pero que realmente quieren hacerlo.
Tuve situaciones en las que necesitaba deslizar rápidamente el reconocimiento de imágenes. Tomé cursos populares en redes neuronales y descubrí que no respondían a mi solicitud, sino que se dedicaban a la educación general. Como resultado, los amigos escribieron el reconocedor :-) Y este informe de Dmitry es solo un bálsamo para el alma, porque responde a todas las solicitudes urgentes de una persona común, después de lo cual está claro qué leer y qué entender.
Al principio hay una pequeña introducción sobre lo que hace Microsoft y las tecnologías de red neuronal que tienen. Dmitry dijo claramente que había reducido al mínimo la cantidad de diapositivas de marketing de Microsoft, aunque es aquí donde no entiendo este sombrero de "marketing": de todas formas usaremos estas tecnologías, las buscaremos. Como si hubiera alguna opción.
Además, se indica brevemente cómo viven los satanistas de datos en su Jupyter Notebook y que no puede instalarlo, sino obtenerlo en la nube. Lo que es característico, el Jupyter Notebook de Dmitry se apagó justo en el momento de la codificación en vivo; en mi opinión, es imposible llegar a una mejor demostración de por qué se necesita C #.
Una parte importante del informe es una historia sobre si es difícil escribir todo esto usted mismo. Se muestran ejemplos basados en el reconocimiento de números en las imágenes.

Primero, los bolígrafos en los ciclos escriben k vecinos más cercanos , lo cual es preciso (94%), pero muy lento: ni una sola demostración de k-NN ha trabajado en el informe hasta el final. Luego, el mismo k-NN está codificado en Accord.NET, y funciona un poco más rápido, pero en realidad no, porque el algoritmo es el mismo. Pero la característica de Accord.NET es que ya es un código de aspecto decente, y puede reemplazar rápidamente el clasificador por otro. Dmitry sustituyó una máquina de vectores de soporte allí , y todo se aceleró bruscamente (un conjunto de 5 mil imágenes comenzaron a escanearse en segundos, la precisión casi no cayó - 92%).
Pero aún puede hacerlo mejor y arrastrar redes neuronales. En la demostración de Accord.NET, SVM fue reemplazado por una red neuronal, con casi ningún cambio de código. Pero no necesita hacer esto, porque hay otros marcos más geniales y rápidos. Dmitry dijo algunas palabras sobre TensorFlow y habló sobre Microsoft Cognitive Toolkit (anteriormente conocido como CNTK) durante el resto de la charla. Después de revisar muchas demostraciones, vimos que el resultado es redes ultraprecisas (98%) con código complejo, pero no obstante completamente comprendido.
Después de ver este informe, ahora no puedo quedarme dormido. Todas estas cosas están escritas en un código comprensible, y parece que tienen bases matemáticas claras que son comprensibles para el estudiante, pero como resultado hacen maravillas. Es un milagro distinguir la foto de un gato de la foto de un perro, no se te ocurrirá un algoritmo para esto, y la red neuronal de alguna manera lo hace ante tus ojos.
¿Qué pasa si mi cerebro es solo un aparato que se aproxima a una función? Y toda la vida es solo una multiplicación más de matrices con una pequeña parte no lineal, que se puede escribir en un código relativamente pequeño ... ¿Cómo vivir con esto ahora?
(el descifrado del informe está disponible aquí )
Vagif Abilov, Miles
Este es un informe conceptual sobre la vida en el mundo de las corrientes. Hay ejemplos de este tipo:

Muestran un código gradualmente más complicado bastante específico, se discuten los detalles. Pero aún así, lo principal es una idea general del problema.
Para las personas que no están inmersas en el tema, puede parecer que para comprender las corrientes de Akka, uno necesita estar bien versado en Akka y estar bien versado en el reactivismo. Vagif afirma que esto no es así, lo que elimina la carga del alma y reduce el umbral para entrar en el tema.
Para mí personalmente, todo el tema de las transmisiones parecía (y aún parece imposible confiar en los informes sin intentarlo) bastante espeluznante, precisamente porque está directamente relacionado con el tema de las transformaciones funcionales y la gestión de datos fuera del modelo habitual de bloqueos de subprocesos. Sí, administrar hilos y construir estructuras a partir de marcos de la vieja escuela para ellos es una cosa vil, pero comprensible y trillada durante años.
Wagif explica la transición a los actores, revela que los actores no componen (o más bien, componen en el sentido en que la sociedad humana compone), y pasa de esto a las Corrientes Reactivas como un medio para aumentar el nivel de abstracción y expresión aún más fuertemente.
Hay un conjunto de interfaces en la pila de Reactive Streams (Editor, Suscriptor, Suscripción, Procesador), pero nadie espera que resolvamos manualmente estas interfaces. Hay desarrolladores de bibliotecas que harán esto por nosotros; por ejemplo, esto se hace en Akka Streams.
Fue un descubrimiento para mí que el empuje / extracción dinámico en las secuencias reactivas está listo para usar, y no duele en absoluto; más precisamente, no duele cuando intentas codificar la contrapresión tú mismo.
Además, el autor no se topa con algún tipo de fanatismo de transmisión y no se olvida de las alternativas (RX, TPL DataFlow, Orleans Streams), habla sobre los pros y los contras. La falta de fanatismo es una gran ventaja en comparación con una historia típica de un amante del reactivismo que se ha apegado a una biblioteca en particular.
En general, entendí la idea de esta manera: cuando usamos microservicios y otras arquitecturas multicomponentes, no se pueden ver los bosques detrás de los árboles, y las corrientes son una forma de subir de nivel y tener una idea del proceso general. Para seguir esos rieles, debe tomar Akka Streams, y todo estará en chocolate.
¿Quieres motivarte para cambiar a transmisiones? Debo mirar.
Anatoly Kulakov, Sistemas Paladyne
A muchos desarrolladores no les gusta pensar en esas cosas terribles que los usuarios hacen con sus aplicaciones. A menudo, cuando se les preguntó "cómo mirar las métricas", los colegas comenzaron a hablar de un juego feroz sobre "comer registros", "mirar MySQL", etc., y convencerlos de que pensaran en el tema no fue fácil.
Este informe de Anatoly es solo un momento de iluminación. Comienza explicando las diferencias entre monitoreo y registro, con una declaración detallada de motivación. Más lejos de nuestro supuesto amante, el murciélago está inmerso en ejemplos concretos de lo que habrá que hacer.
Tendrá que hacer la serie temporal (sobre la cual se describe el mínimo teórico, por qué lo necesita, cuáles son las ventajas, cuál es la esencia de las optimizaciones) utilizando la conocida base de datos InfluxDB (sobre la cual se discuten los detalles, capacidades y desventajas). Y así sucesivamente. Un montón de buen contenido, que incluye demostraciones en vivo con experimentos en Grafana local y una aplicación de archivo cuyos datos de rendimiento se recopilan a través de BenchmarkDotNet.
Si no le importa el tiempo de lectura-escritura, si no descansa contra el rendimiento, si no sabe qué es la disminución de muestreo, si no necesita estadísticas especializadas y funciones de agregación, si desea eliminar todos los datos de una línea a la vez, si no descansa sobre el tamaño de su datos y usted sabe con certeza que nunca tendrá cargas altas: puede continuar guardando datos métricos en RDBMS, tomar registros y vivir felices para siempre. Todos los demás necesitan usar herramientas modernas y ver este informe (o leer la transcripción).
Dylan Beattie, Spotlight
Dylan Beattie es una persona con tantos logros laborales y proyectos interesantes que la lista completa es más fácil de leer en nuestro sitio web . En el contexto del informe, es interesante que Dylan sea un arquitecto de sistemas que actualmente trabaja en los problemas de la construcción de aplicaciones distribuidas modernas complejas y, en consecuencia, en el desarrollo de las API adecuadas para ellas. Y, por supuesto, absolutamente todos los que asistieron a las fiestas de DotNext lo conocen.
Ya sea que nos demos cuenta o no, cada vez que creamos nuevos programas, creamos una experiencia de usuario. Las personas interactuarán con nuestro código, como usuarios finales o, tal vez, como miembros del equipo de desarrollo. O tal vez son desarrolladores de una aplicación móvil que usa su API, o es alguien que necesita ir por la noche para solucionar los problemas que han surgido. Desde el exterior, esto puede parecer casos completamente diferentes, pero de hecho tienen algo en común. Dylan lo llama la palabra capacidad de descubrimiento .
De aquí vino este informe muy filosófico y, al mismo tiempo, puramente práctico. Al principio, Dylan ofrece una introducción detallada a la psicología del aprendizaje y varios modelos de aprendizaje. ¿Cuál crees que es la mejor curva de aprendizaje?
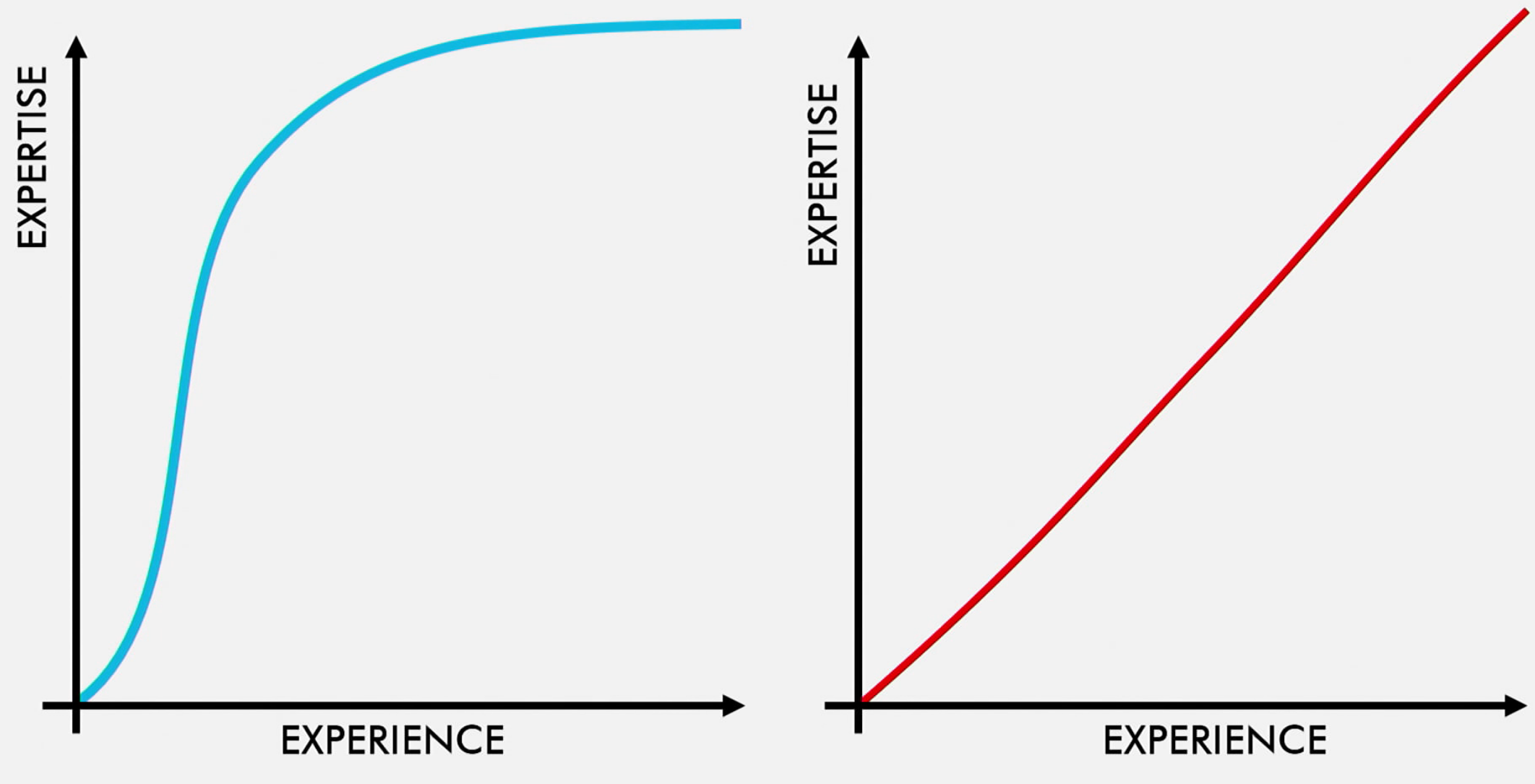
Luego viene la historia de cómo la capacidad de descubrimiento se manifiesta a los usuarios finales del sistema, y luego, lo más importante, cómo se relaciona todo con el código, los datos, las API y otras cosas que conforman la vida de un programador. Paso a paso, en todos los niveles de la aplicación.
¿No cree que la finalización automática, hipermedia o la API fluida mejoran la vida? ¿Qué pasa con hermosos paneles, métricas comprensibles o, por ejemplo, niveles de registro, nombrados no por nivel de amenaza, sino por significado? Tal vez entiendes todo esto, pero ¿no sabes cómo contarles esto a tus colegas para que finalmente empiecen a usar todo esto? Entonces necesita ver este informe con urgencia (por cierto, en la primavera ya publicamos una traducción sobre Habré).
Andrey Akinshin, JetBrains
Andrei tenía una tarea muy difícil: hablar sobre el rendimiento, pero al mismo tiempo en el formato de una nota de apertura. Como probablemente sepa, Keynote tiene varios objetivos, de los cuales el principal es transmitir el espíritu y la esencia de lo que sucederá en la conferencia. De ello se deduce que dicho informe debe ser entendido más o menos por todos. Por otro lado, el rendimiento es el segundo nombre de hardcore, es decir, el tema es complejo y específico.
No es de extrañar que Andrei obtenga constantemente sus calificaciones más altas, salió. Está claro que la mayoría de las empresas actualmente no están probando el rendimiento de ninguna manera, o están probando a personas vivas en el mercado. No existe una teoría armoniosa para resolver tales problemas, por lo tanto, no es necesario decirle al equipo de ruptura de engranajes. Necesita una comprensión básica del tema.
El informe está dedicado a 13 notas de rendimiento. No diré los trece, por qué producir spoilers. Por ejemplo, la primera nota es sobre las fuentes de datos de rendimiento. O, por ejemplo, si tiene una lista de anomalías de rendimiento, eliminar los pequeños problemas de los que habla Andrey simplificará el análisis de los problemas de rendimiento (problemas que aún no ha escrito, pero que escribirá pronto). Una de estas opciones, que se analiza en la Nota 6, es la agrupación en clúster utilizando los sistemas operativos como ejemplo.
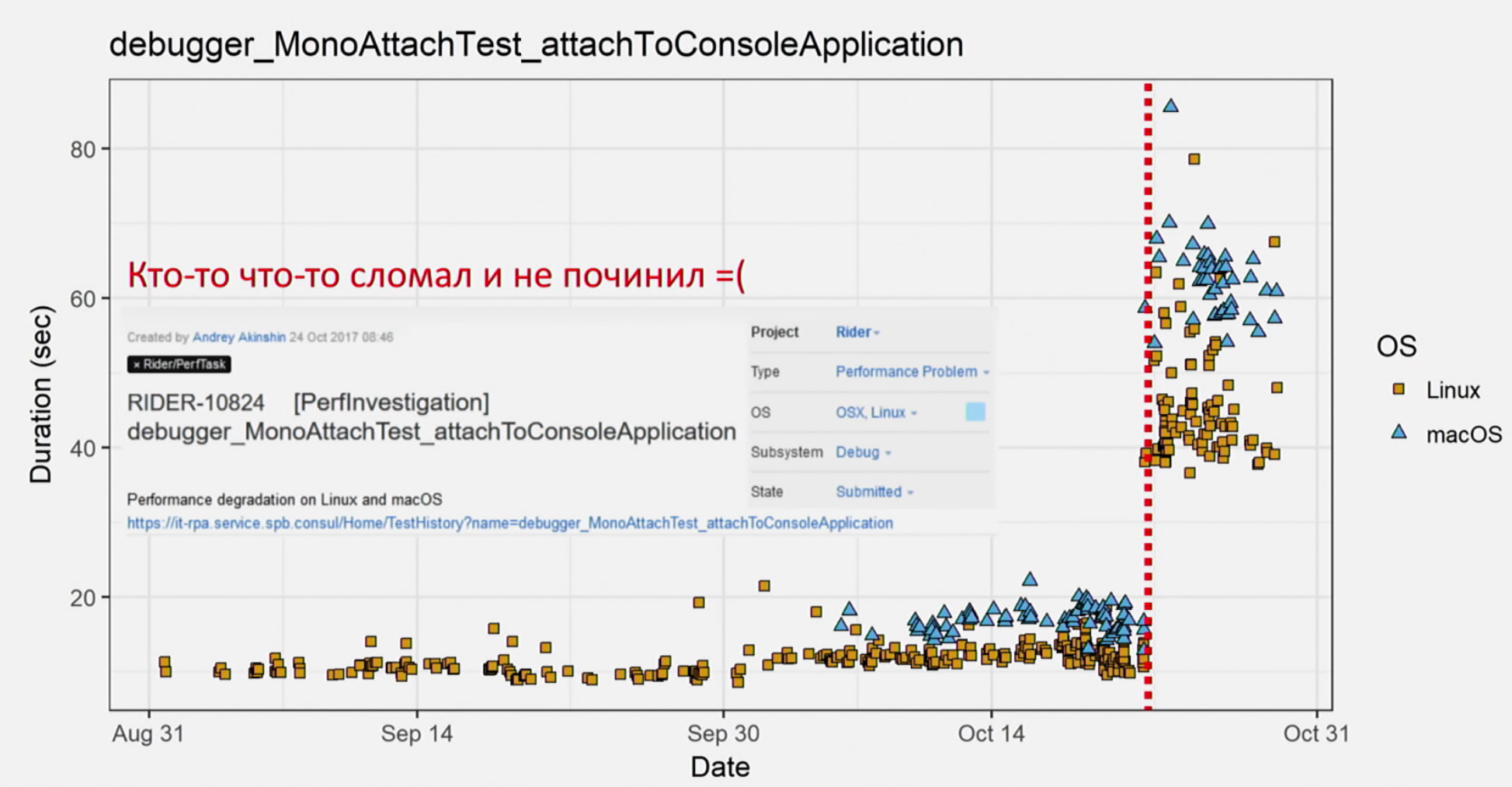
Las pruebas de rendimiento son interesantes, pero difíciles. Además, es posible y necesario probar el rendimiento. En mi humilde opinión, el informe es único en el sentido de que revela un montón de cosas que a las personas les gustaría hacer, pero que no hacen o que mienten. Por lo tanto, vea el informe de Andrey, gane pureza de rendimiento y cultura de rendimiento, y luego sus productos serán súper rápidos, receptivos, suaves y sedosos.
Sasha Goldshtein, Grupo Sela
Sasha es un destacado ingeniero de rendimiento, y no es sorprendente que haya llegado a la cima de la clasificación. Otra razón para ganar: ahora se ha puesto muy de moda agregar ".NET Core" al título del informe solo por exagerar. No hay tantas historias sobre algo en que .NET Core desempeñe un papel significativo, y este informe es una de ellas. : , , — .
Imagine que logró ejecutar su aplicación ASP.NET favorita en Linux o incluso algo con una interfaz de consola. Que sigue Final feliz? Oh no De hecho, tendrá que enfrentar fugas de memoria, fallas extrañas, problemas de rendimiento y muchos otros problemas, ¿y qué hacer cuando todo esto ocurra en la producción? En Windows, tenemos un montón de herramientas interesantes, pero no funcionarán en Linux, y todavía no hay alternativas simples. En esta charla, Sasha habla sobre cómo se ve ahora la depuración y el perfil de las aplicaciones .NET Core en Linux. Cómo investigar con perf , cómo LTTNG utiliza LTTNG como reemplazo de los eventos ETW , cómo recopilar y comprender los LTTNG LTTNG y más. Sasha hablará sobre la recopilación de volcados de núcleo y cómo obtener información interesante para un desarrollador de .NET usando lldb y SOS .
En resumen, todos los que decidan ver el video emprenderán un difícil viaje de detectives a través de la jungla de utilidades inacabadas y magia de línea de comandos especial. Con un final feliz (pero eso no es seguro).
Si los informes de la lista son de su interés, llamamos su atención: ya hemos anunciado el próximo DotNext , y allí no puede ser menos interesante. Al mismo tiempo, los boletos se vuelven más caros con el tiempo, por lo que no debe posponer la compra de boletos para el nuevo DotNext antes de revisar todos los informes del anterior.