Cuando Dropbox acaba de comenzar, un usuario de Hacker News comentó que podría implementarse con varios scripts de bash usando FTP y Git. Ahora, esto no se puede decir de ninguna manera, este es un gran almacenamiento de archivos en la nube con miles de millones de archivos nuevos todos los días, que no solo se almacenan de alguna manera en la base de datos, sino de tal manera que cualquier base de datos se puede restaurar en cualquier punto en los últimos seis días.
Debajo del corte, la transcripción del informe de
Glory Bakhmutov (
m0sth8 ) en Highload ++ 2017, sobre cómo se desarrollaron las bases de datos en Dropbox y cómo se organizan ahora.
Sobre el orador: Gloria a Bakhmutov: ingeniero de confiabilidad del sitio en el equipo de Dropbox, ama mucho Go y a veces aparece en el podcast golangshow.com.
Contenido
Arquitectura de Dropbox en lenguaje sencillo
Dropbox apareció en 2008. Esto es esencialmente un almacenamiento de archivos en la nube. Cuando Dropbox acaba de comenzar, un usuario de Hacker News comentó que podría implementarse con varios scripts de bash usando FTP y Git. Pero, sin embargo, Dropbox se está desarrollando, y ahora es un servicio bastante grande con más de 1.500 millones de usuarios, 200.000 empresas y un gran número (¡varios miles de millones!) De archivos nuevos todos los días.
¿Cómo se ve Dropbox?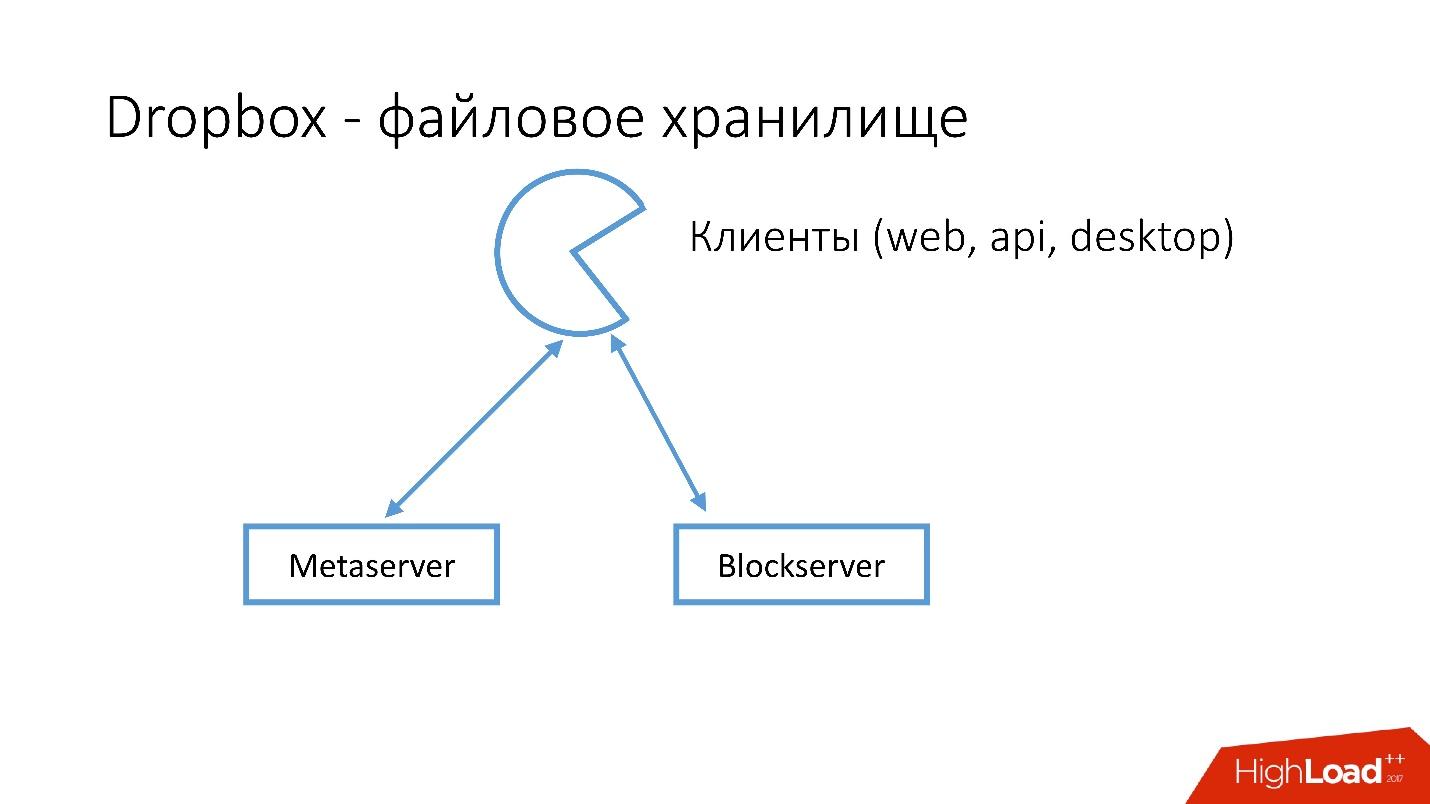
Tenemos varios clientes (interfaz web, API para aplicaciones que usan Dropbox, aplicaciones de escritorio). Todos estos clientes usan la API y se comunican con dos grandes servicios que lógicamente se pueden dividir en:
- Metaservidor
- Servidor de bloques
Metaserver almacena metainformación sobre el archivo: tamaño, comentarios sobre él, enlaces a este archivo en Dropbox, etc. Blockserver solo almacena información sobre archivos: carpetas, rutas, etc.
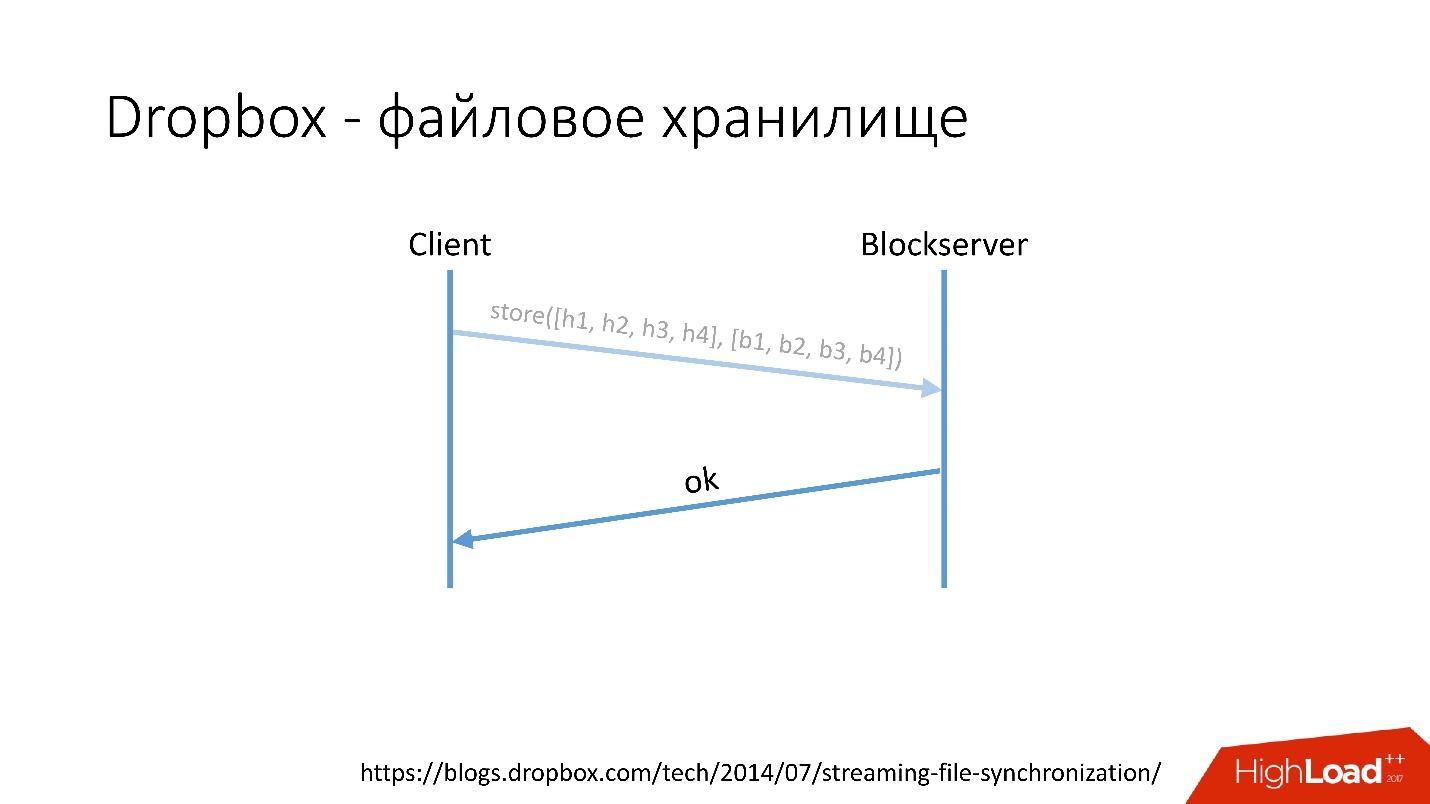
Como funcionaPor ejemplo, tiene un archivo video.avi con algún tipo de video.
 Enlace desde la diapositiva
Enlace desde la diapositiva- El cliente divide este archivo en varios fragmentos (en este caso, 4 MB cada uno), calcula la suma de verificación y envía una solicitud a Metaserver: "Tengo un archivo * .avi, quiero cargarlo, las cantidades de hash son tal y tal".
- Metaserver devuelve la respuesta: "No tengo estos bloques, ¡descarguemos!" O puede responder que tiene todos o algunos de los bloques, y solo los restantes deben cargarse.
 Enlace desde la diapositiva
Enlace desde la diapositiva- Después de eso, el cliente va al Blockserver, envía la cantidad de hash y el bloque de datos en sí, que se almacena en el Blockserver.
- Blockserver confirma la operación.
 Enlace desde la diapositiva
Enlace desde la diapositivaPor supuesto, este es un esquema muy simplificado, el protocolo es mucho más complicado: hay sincronización entre clientes dentro de la misma red, hay controladores de kernel, la capacidad de resolver colisiones, etc. Este es un protocolo bastante complejo, pero funciona así esquemáticamente.

Cuando un cliente guarda algo en Metaserver, toda la información va a MySQL. Blockserver también almacena información sobre archivos, cómo están estructurados, en qué bloques consisten, en MySQL. Blockserver también almacena los bloques en Block Storage, que, a su vez, almacena información sobre dónde se encuentra ese bloque, en qué servidor y cómo se procesa, también en MYSQL.
Para almacenar exabytes de archivos de usuario, almacenamos simultáneamente información adicional en una base de datos de varias docenas de petabytes dispersos en 6 mil servidores.
Historial de desarrollo de bases de datos
¿Cómo evolucionaron las bases de datos en Dropbox?

En 2008, todo comenzó con un Metaserver y una base de datos global. Toda la información que Dropbox necesitaba ser almacenada en algún lugar, la guardó en el único MySQL global. Esto no duró mucho, porque el número de usuarios creció y las bases de datos y tabletas individuales dentro de las bases de datos aumentaron más rápido que otras.

Por lo tanto, en 2011 se enviaron varias tablas a servidores separados:
- Usuario , con información sobre los usuarios, por ejemplo, inicios de sesión y tokens oAuth;
- Host , con información de archivo de Blockserver;
- Varios , que no participó en el procesamiento de solicitudes de producción, pero se utilizó para funciones de utilidad, como trabajos por lotes.
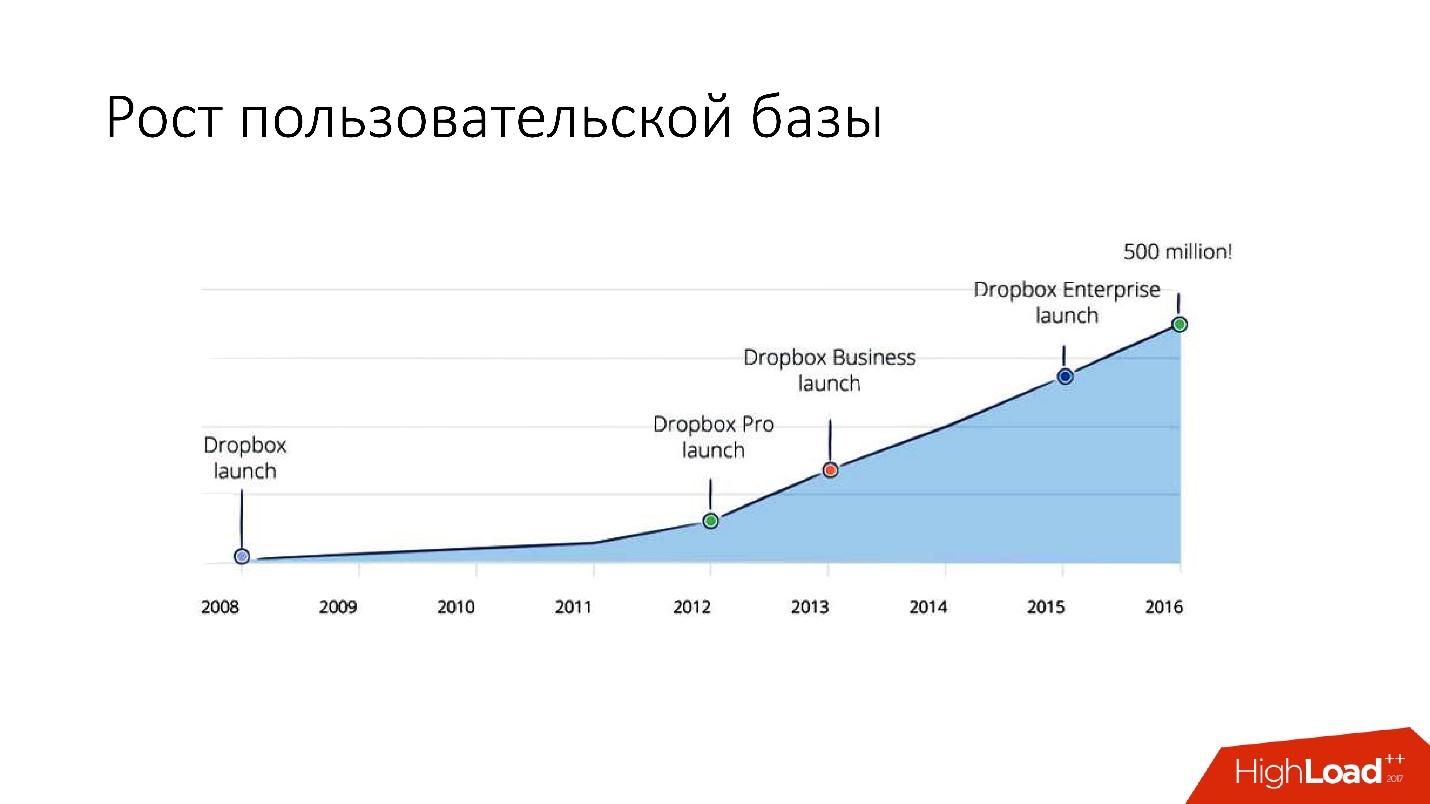
Pero después de 2012, Dropbox comenzó a crecer mucho, desde entonces
hemos crecido en
unos 100 millones de usuarios al año .
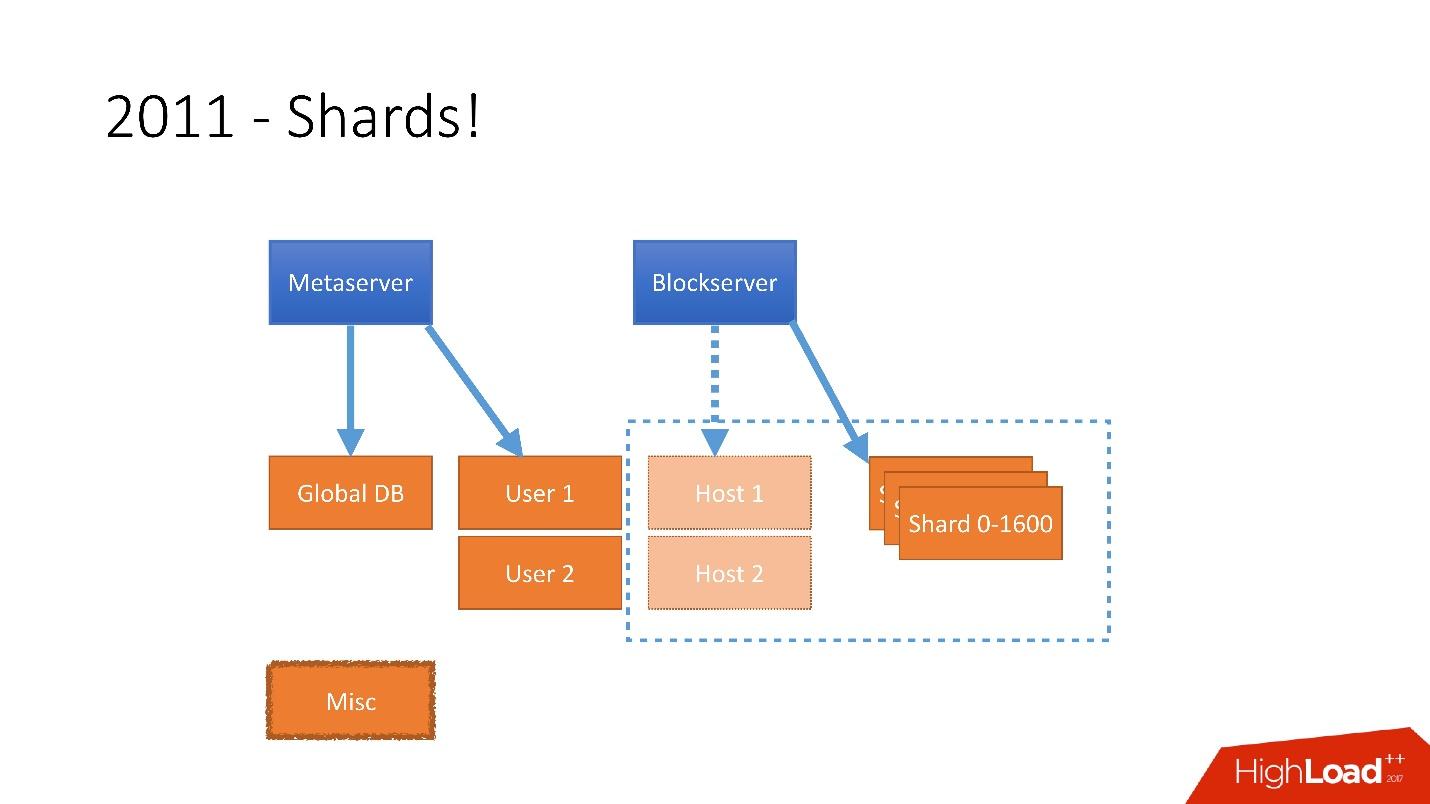
Era necesario tener en cuenta un crecimiento tan enorme y, por lo tanto, a finales de 2011 teníamos fragmentos, una base que constaba de 1.600 fragmentos. Inicialmente, solo 8 servidores con 200 fragmentos cada uno. Ahora son 400 servidores maestros con 4 fragmentos en cada uno.
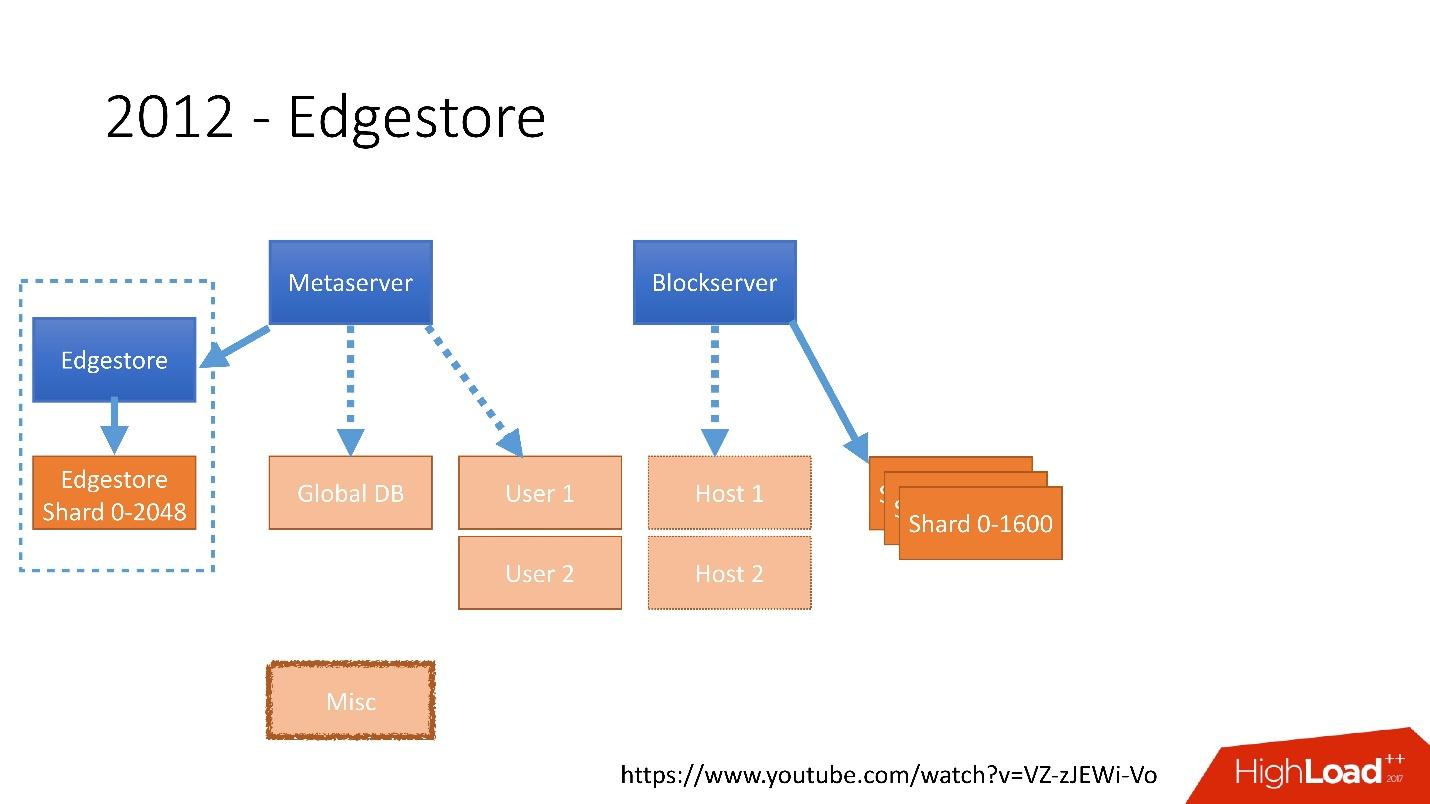 Enlace desde la diapositiva
Enlace desde la diapositivaEn 2012, nos dimos cuenta de que crear tablas y actualizarlas en la base de datos para cada lógica comercial agregada es muy difícil, triste y problemático. Por lo tanto, en 2012, inventamos nuestro propio almacenamiento de gráficos, que llamamos
Edgestore , y desde entonces toda la lógica empresarial y la metainformación que genera la aplicación se almacenan en Edgestore.
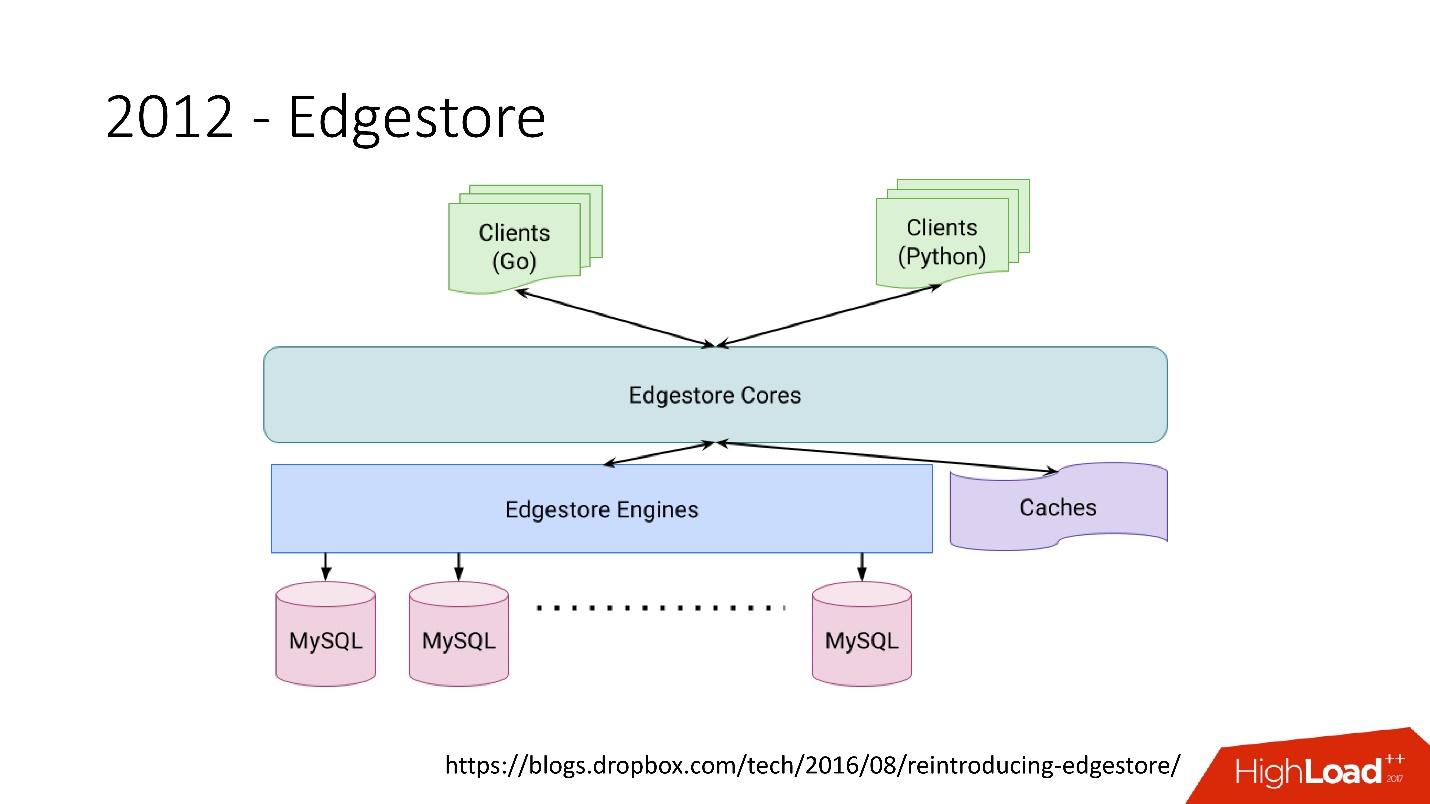
Edgestore esencialmente abstrae MySQL de los clientes. Los clientes tienen ciertas entidades que están interconectadas por enlaces desde la API de gRPC a Edgestore Core, que convierte estos datos en MySQL y de alguna manera los almacena allí (básicamente, proporciona todo esto desde el caché).
 Enlace desde la diapositivaEn 2015, dejamos Amazon S3
Enlace desde la diapositivaEn 2015, dejamos Amazon S3 , desarrollamos nuestro propio almacenamiento en la nube llamado Magic Pocket. Contiene información sobre dónde se encuentra un archivo de bloque, en qué servidor, sobre los movimientos de estos bloques entre servidores, almacenados en MySQL.
 Enlace desde la diapositiva
Enlace desde la diapositivaPero MySQL se usa de una manera muy complicada, en esencia, como una gran tabla hash distribuida. Esta es una carga muy diferente, principalmente en la lectura de registros aleatorios. El 90% de la utilización es E / S.
Arquitectura de base de datos
Primero, identificamos de inmediato algunos principios por los cuales construimos la arquitectura de nuestra base de datos:
- Fiabilidad y durabilidad . Este es el principio más importante y lo que los clientes esperan de nosotros: los datos no deben perderse.
- La optimización de la solución es un principio igualmente importante. Por ejemplo, las copias de seguridad deben hacerse rápidamente y restaurarse rápidamente también.
- Simplicidad de solución , tanto arquitectónicamente como en términos de servicio y soporte de desarrollo adicional.
- Costo de propiedad . Si algo optimiza la solución, pero es muy costoso, esto no nos conviene. Por ejemplo, un esclavo que está un día detrás del maestro es muy conveniente para las copias de seguridad, pero luego debe agregar 1,000 más a 6,000 servidores: el costo de propiedad de dicho esclavo es muy alto.
Todos los principios deben ser
verificables y medibles , es decir, deben tener métricas. Si hablamos del costo de propiedad, debemos calcular cuántos servidores tenemos, por ejemplo, va a bases de datos, cuántos servidores van a copias de seguridad y cuánto cuesta al final Dropbox. Cuando elegimos una nueva solución, contamos todas las métricas y nos enfocamos en ellas. Al elegir cualquier solución, nos guiamos completamente por estos principios.
Topología base
La base de datos está estructurada de la siguiente manera:
- En el centro de datos principal, tenemos un maestro, en el que se producen todos los registros.
- El servidor maestro tiene dos servidores esclavos en los que se produce la replicación semisincrónica. Los servidores a menudo mueren (aproximadamente 10 por semana), por lo que necesitamos dos servidores esclavos.
- Los servidores esclavos están en grupos separados. Los clústeres son salas completamente separadas en el centro de datos que no están conectadas entre sí. Si una habitación se quema, la segunda sigue funcionando por completo.
- También en otro centro de datos tenemos el llamado pseudo maestro (maestro intermedio), que en realidad es solo un esclavo, que tiene otro esclavo.
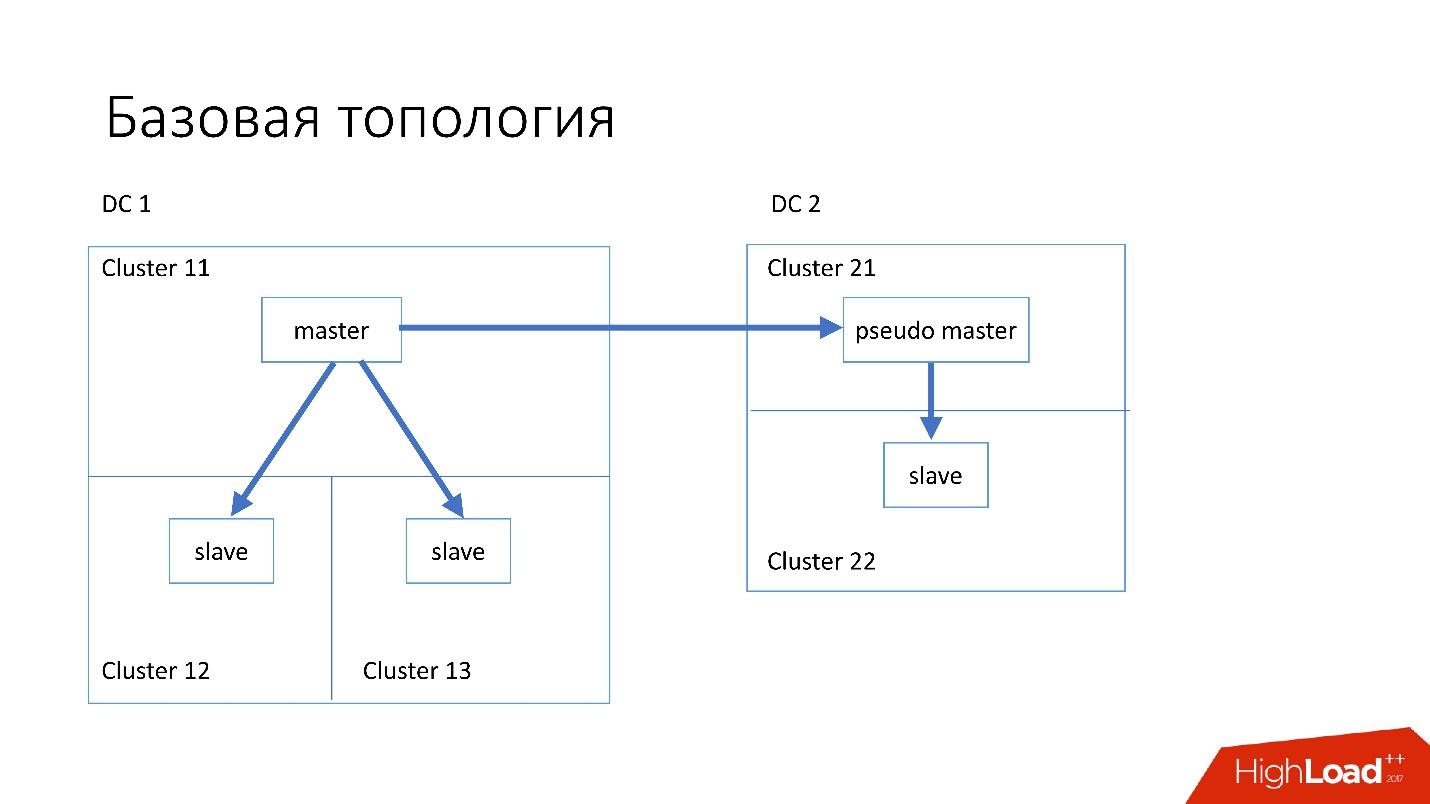
Se eligió dicha topología porque si el primer centro de datos muere repentinamente en nosotros, entonces en el segundo centro de datos tenemos una
topología casi completa . Simplemente cambiamos todas las direcciones en Discovery y los clientes pueden trabajar.
Topologías Especializadas
También contamos con topologías especializadas.
La topología de
Magic Pocket consta de un servidor maestro y dos servidores esclavos. Esto se hace porque Magic Pocket mismo duplica datos entre zonas. Si pierde un clúster, puede restaurar todos los datos de otras zonas a través del código de borrado.

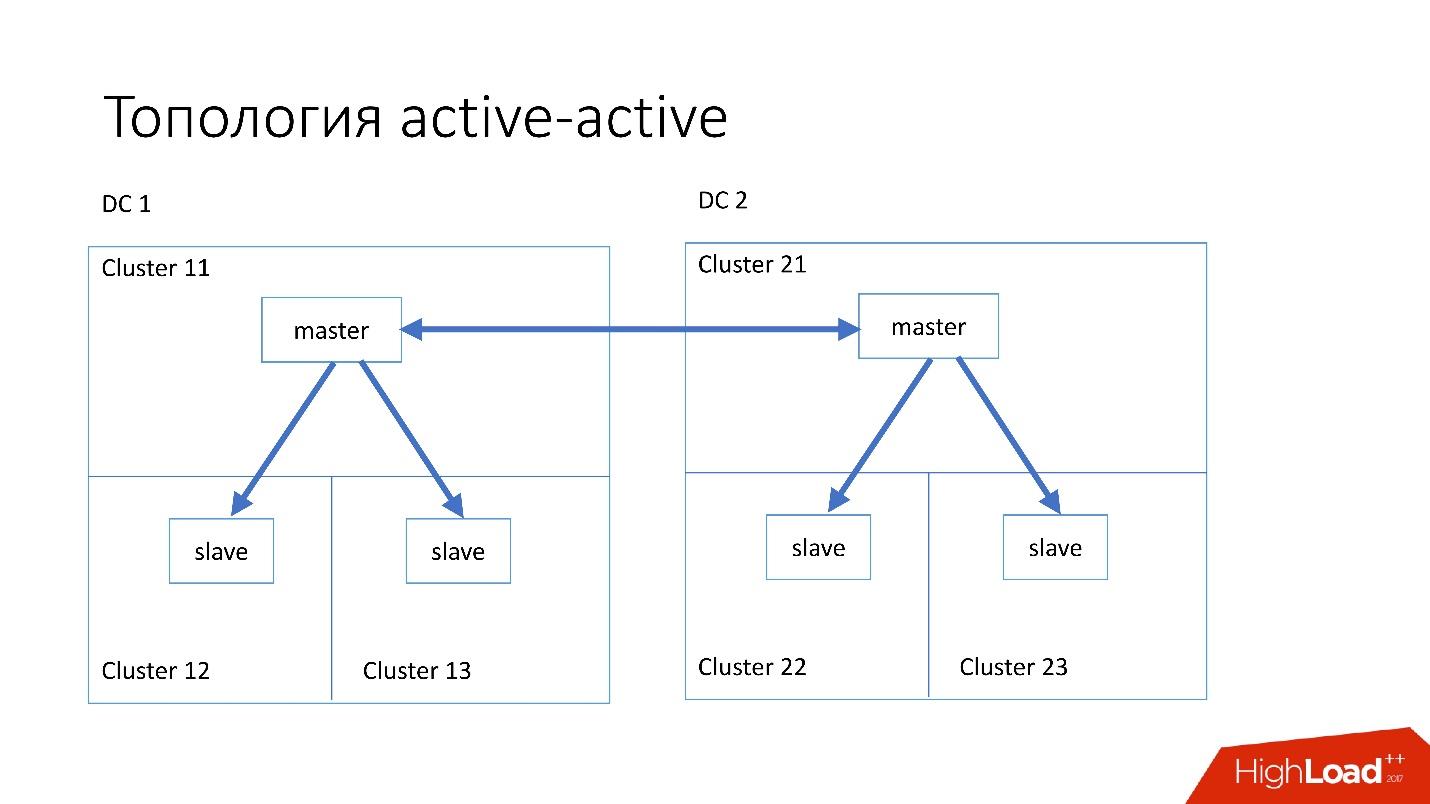
La topología
activo-activo es la topología personalizada utilizada por Edgestore. Tiene un maestro y dos esclavos en cada uno de los dos centros de datos, y son esclavos el uno del otro. Este es un
esquema muy
peligroso , pero Edgestore a su nivel sabe exactamente qué datos en qué maestro puede escribir sobre qué rango. Por lo tanto, esta topología no se rompe.
Instancia
Hemos instalado servidores bastante simples con una configuración de hace 4-5 años:
- 2x Xeon 10 núcleos;
- 5 TB (8 SSD Raid 0 *);
- 384 GB de memoria.
* Raid 0: porque es más fácil y mucho más rápido reemplazar un servidor completo que las unidades.
Instancia única
En este servidor, tenemos una instancia grande de MySQL en la que se encuentran varios fragmentos. Esta instancia de MySQL se asigna inmediatamente casi toda la memoria. También se ejecutan otros procesos en el servidor: proxy, recopilación de estadísticas, registros, etc.
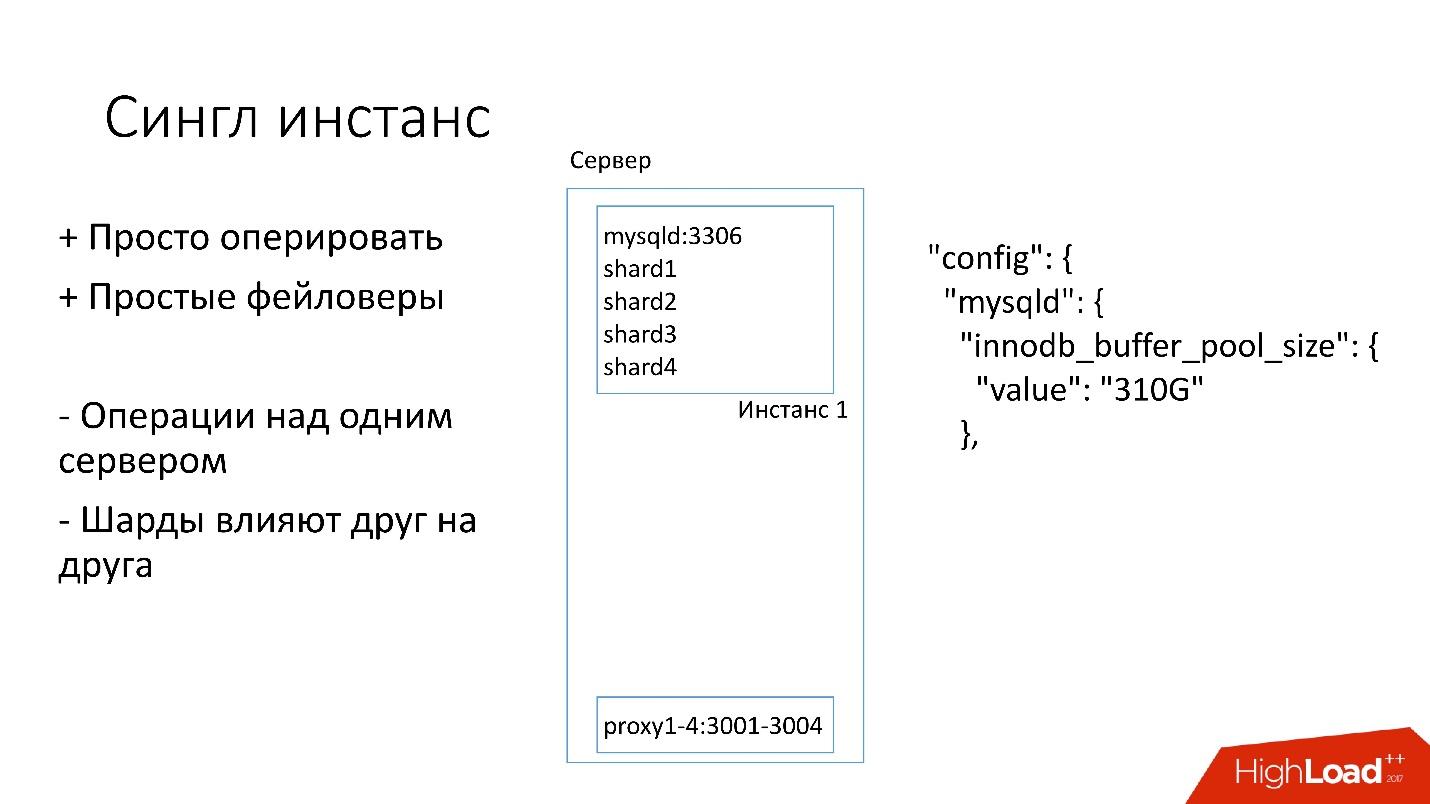
Esta solución es buena en eso:
+ Es
fácil de administrar . Si necesita reemplazar la instancia de MySQL, simplemente reemplace el servidor.
+
Solo haz faylovers .
Por otro lado:
- Es problemático que cualquier operación ocurra en toda la instancia de MySQL e inmediatamente en todos los fragmentos. Por ejemplo, si necesita hacer una copia de seguridad, respaldamos todos los fragmentos a la vez. Si necesita hacer un faylover, hacemos el faylover los cuatro fragmentos a la vez. En consecuencia, la accesibilidad sufre 4 veces más.
- Los problemas con la replicación de un fragmento afectan a otros fragmentos. La replicación de MySQL no es paralela, y todos los fragmentos funcionan en un solo hilo. Si algo le sucede a un fragmento, el resto también se convierte en víctima.
Así que ahora nos estamos moviendo a una topología diferente.
Instancia múltiple

En la nueva versión, se lanzan varias instancias de MySQL en el servidor a la vez, cada una con un fragmento. Que es mejor
+ Podemos
realizar operaciones solo en un fragmento específico . Es decir, si necesita un faylover, cambie solo un fragmento, si necesita una copia de seguridad, respaldamos solo un fragmento. Esto significa que las operaciones se aceleran enormemente: 4 veces para un servidor de cuatro fragmentos.
+ Los
fragmentos apenas se afectan entre sí .
+
Mejora en la replicación. Podemos mezclar diferentes categorías y clases de bases de datos. Edgestore ocupa mucho espacio, por ejemplo, los 4 TB, y Magic Pocket ocupa solo 1 TB, pero tiene una utilización del 90%. Es decir, podemos combinar diferentes categorías que usan E / S y recursos de máquina de diferentes maneras, y comenzar 4 secuencias de replicación.
Por supuesto, esta solución tiene sus inconvenientes:
- El mayor inconveniente es que es
mucho más difícil manejar todo esto . Necesitamos un planificador inteligente que entienda a dónde puede llevar esta instancia, donde habrá una carga óptima.
-
Más duro que los failovers .
Por lo tanto, solo ahora nos estamos moviendo a esta decisión.
Descubrimiento
Los clientes deben saber de alguna manera cómo conectarse a la base de datos deseada, por lo que tenemos Discovery, que debería:
- Notifique al cliente muy rápidamente sobre los cambios de topología. Si cambiamos maestro y esclavo, los clientes deberían aprenderlo casi al instante.
- La topología no debe depender de la topología de replicación de MySQL, porque con algunas operaciones cambiamos la topología de MySQL. Por ejemplo, cuando dividimos, en el paso preparatorio del maestro de destino, donde transferiremos parte de los fragmentos, algunos de los servidores esclavos se reconfiguran a este maestro de destino. Los clientes no necesitan saber sobre esto.
- Es importante que haya atomicidad de las operaciones y verificación del estado. Es imposible que dos servidores diferentes de la misma base de datos se conviertan en maestros en el mismo momento.
Cómo se desarrolló el descubrimiento
Al principio todo era simple: la dirección de la base de datos en el código fuente en la configuración. Cuando necesitábamos actualizar la dirección, todo se desplegó muy rápidamente.

Desafortunadamente, esto no funciona si hay muchos servidores.
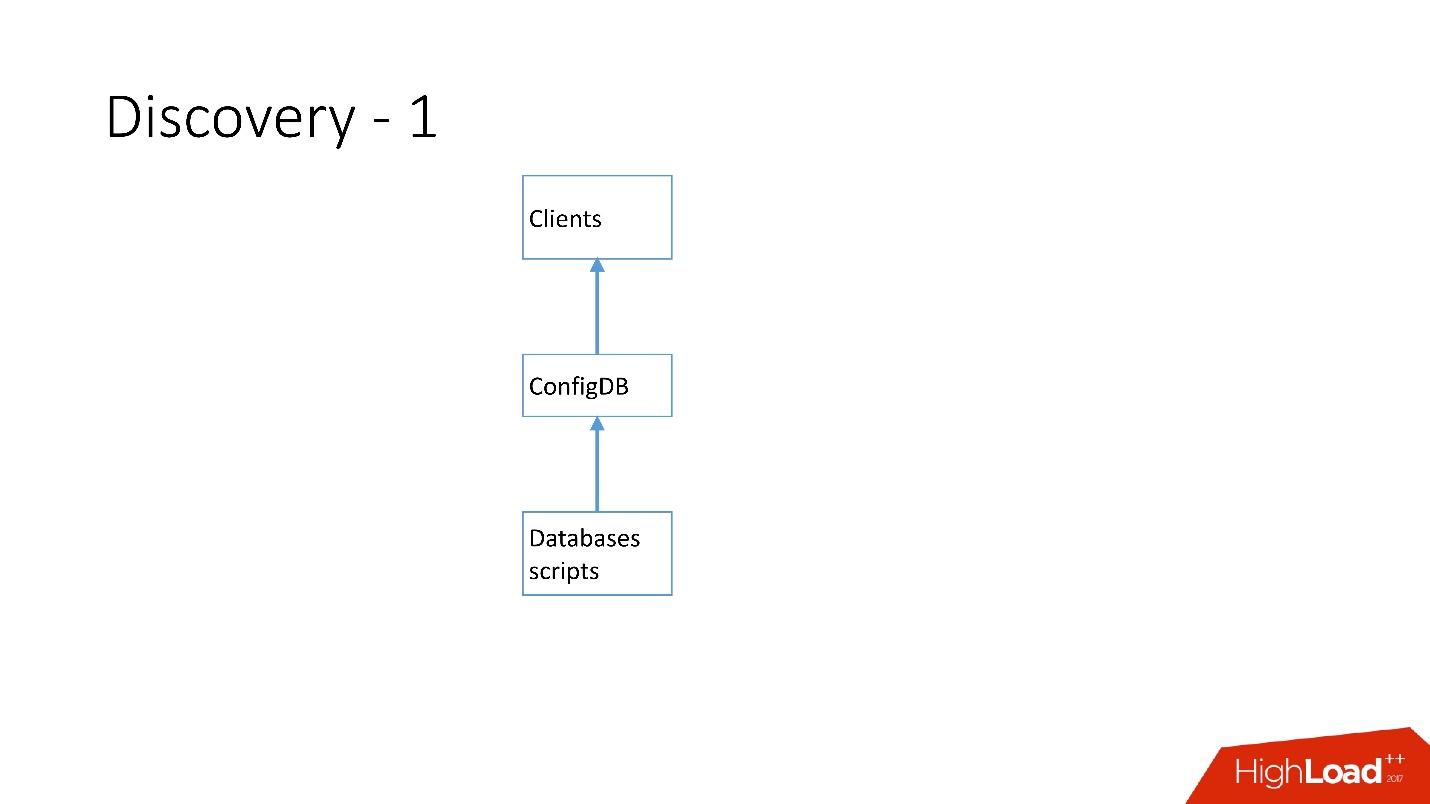
Arriba está el primer Discovery que tenemos. Hubo scripts de base de datos que cambiaron la placa de identificación en ConfigDB; era una placa de identificación de MySQL separada, y los clientes ya escuchaban esta base de datos y tomaban datos periódicamente de allí.

La tabla es muy simple, hay una categoría de base de datos, una clave de fragmento, una clase de base de datos maestro / esclavo, proxy y una dirección de base de datos. De hecho, el cliente solicitó una categoría, una clase de base de datos, una clave de fragmento y se devolvió la dirección MySQL a la que ya podía establecer una conexión.
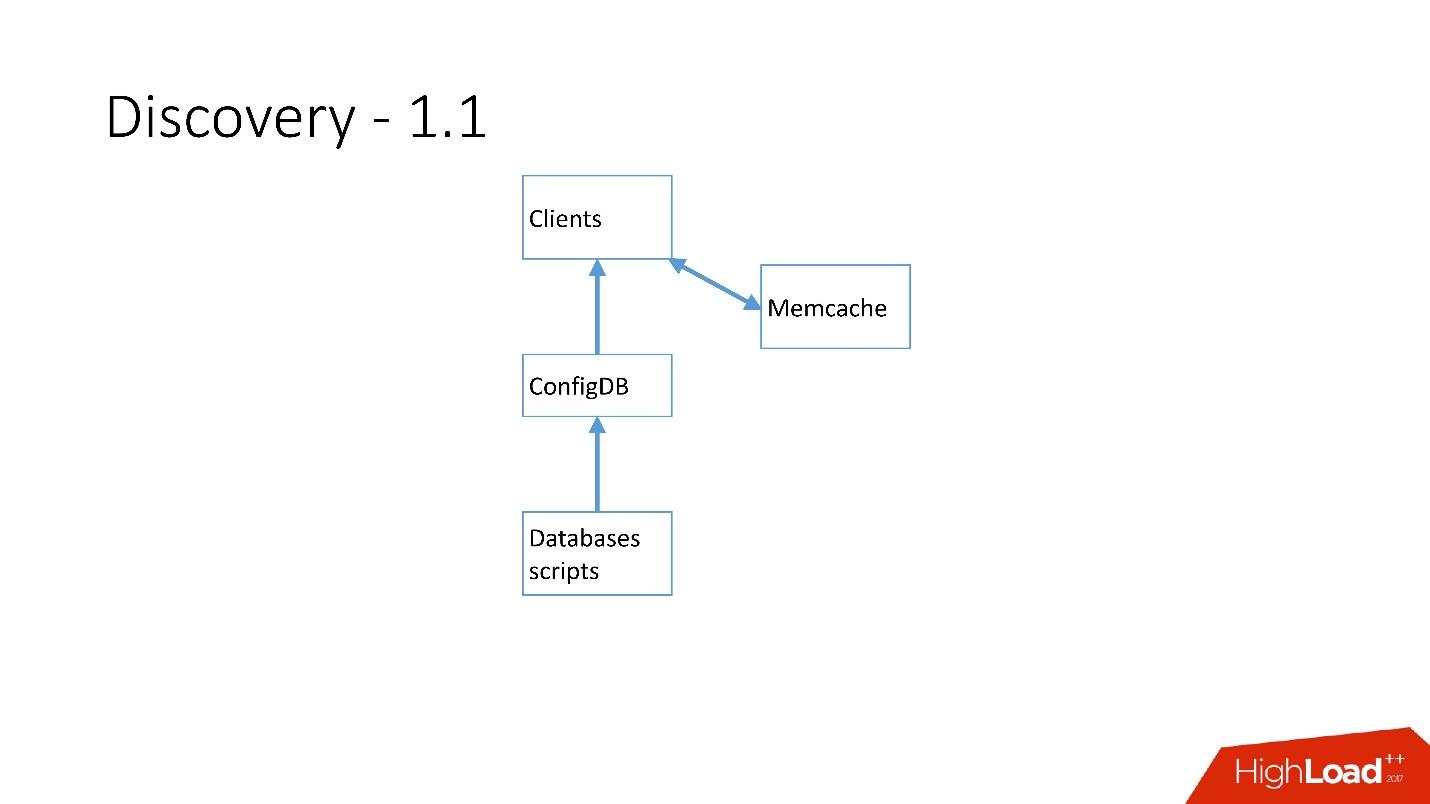
Tan pronto como hubo muchos servidores, se agregó Memcache y los clientes comenzaron a comunicarse con él.
Pero luego lo reelaboramos. Los scripts de MySQL comenzaron a comunicarse a través de gRPC, a través de un cliente ligero con un servicio que llamamos RegisterService. Cuando ocurrieron algunos cambios, RegisterService tenía una cola y entendió cómo aplicar estos cambios. RegisterService guardó datos en AFS. AFS es nuestro sistema interno basado en ZooKeeper.

La segunda solución, que no se muestra aquí, usó ZooKeeper directamente, y esto creó problemas porque cada fragmento era un nodo en ZooKeeper. Por ejemplo, 100 mil clientes se conectan a ZooKeeper, si murieron repentinamente debido a algún tipo de error, 100 mil solicitudes a ZooKeeper llegarán de inmediato, lo que simplemente lo dejará y no podrá aumentar.
Por lo tanto, se desarrolló el
sistema AFS, que es utilizado por todo Dropbox . De hecho, abstrae el trabajo con ZooKeeper para todos los clientes. El demonio AFS se ejecuta localmente en cada servidor y proporciona una API de archivo muy simple de la forma: crear un archivo, eliminar un archivo, solicitar un archivo, recibir notificación de un cambio de archivo y comparar e intercambiar operaciones. Es decir, puede intentar reemplazar el archivo con alguna versión, y si esta versión ha cambiado durante el cambio, la operación se cancela.
Esencialmente, tal abstracción sobre ZooKeeper, en la que hay un algoritmo local de retroceso y jitter. ZooKeeper ya no se bloquea bajo carga. Con AFS, tomamos copias de seguridad en S3 y en GIT, luego el AFS local mismo notifica a los clientes que los datos han cambiado.

En AFS, los datos se almacenan como archivos, es decir, es una API del sistema de archivos. Por ejemplo, lo anterior es el archivo shard.slave_proxy: el más grande, toma aproximadamente 28 Kb, y cuando cambiamos la categoría de la clase shard y slave_proxy, todos los clientes que se suscriben a este archivo reciben una notificación. Vuelven a leer este archivo, que contiene toda la información necesaria. Utilizando la clave de fragmento, obtienen una categoría y reconfiguran el grupo de conexiones a la base de datos.
Operaciones
Utilizamos operaciones muy simples: promoción, clonación, copias de seguridad / recuperación.
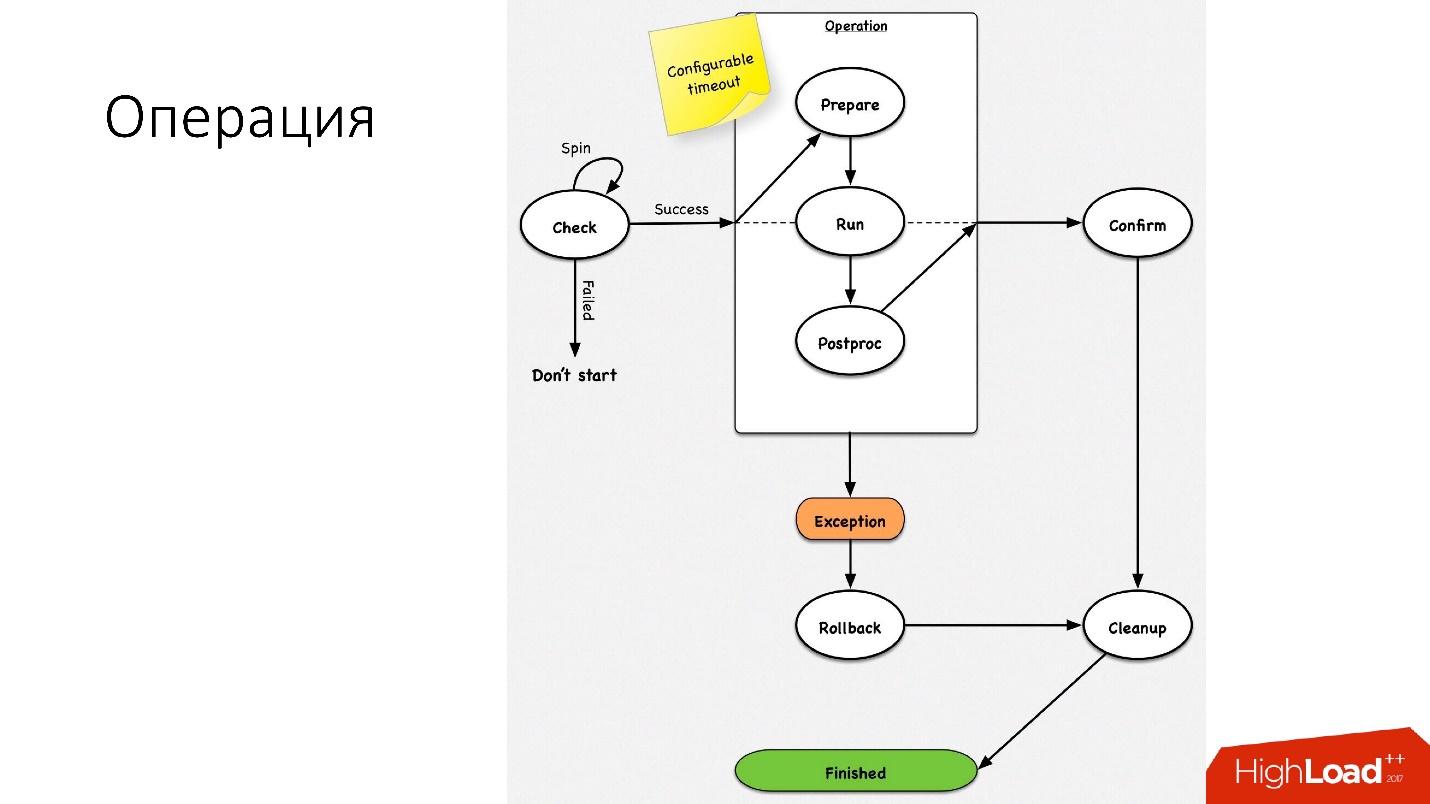 Una operación es una máquina de estado simple
Una operación es una máquina de estado simple . Cuando entramos en la operación, realizamos algunas verificaciones, por ejemplo, spin-check, que varias veces por tiempo de espera verifica si podemos realizar esta operación. Después de eso, hacemos algunas acciones preparatorias que no afectan a los sistemas externos. A continuación, la operación en sí.
Todos los pasos dentro de una operación tienen un
retroceso (deshacer). Si hay un problema con la operación, la operación intenta restaurar el sistema a su posición original. Si todo está bien, se realiza la limpieza y se completa la operación.
Tenemos una máquina de estado tan simple para cualquier operación.
Promoción (cambio de master)
Esta es una operación muy común en la base de datos. Hubo preguntas sobre cómo hacer un alter en un servidor maestro caliente que funciona: obtendrá una apuesta. Es solo que todas estas operaciones se realizan en servidores esclavos, y luego los cambios esclavos con lugares maestros. Por lo tanto, la
operación de promoción es muy frecuente .

Necesitamos actualizar el kernel - intercambiamos, necesitamos actualizar la versión de MySQL - actualizamos en esclavo, cambiamos a maestro, actualizamos allí.

Hemos logrado una promoción muy rápida. Por ejemplo,
para cuatro fragmentos, ahora tenemos promoción durante unos 10-15 s. El gráfico anterior muestra que con la disponibilidad de la promoción sufrió un 0,0003%.
Pero la promoción normal no es tan interesante, porque estas son operaciones ordinarias que se realizan todos los días. Las failovers son interesantes.
Conmutación por error (reemplazo de un maestro roto)
Una conmutación por error significa que la base de datos está muerta.
- Si el servidor realmente murió, este es solo un caso ideal.
- De hecho, sucede que los servidores están parcialmente vivos.
- A veces el servidor muere muy lentamente. Los controladores de incursión, el sistema de disco fallan, algunas solicitudes devuelven respuestas, pero algunos flujos están bloqueados y no devuelven respuestas.
- Sucede que el maestro simplemente está sobrecargado y no responde a nuestro chequeo de salud. Pero si hacemos promoción, el nuevo maestro también se sobrecargará, y solo empeorará.
El reemplazo de los servidores maestros fallecidos se realiza aproximadamente
2-3 veces al día , este es un proceso completamente automatizado, no se necesita intervención humana. La sección crítica tarda unos 30 segundos, y tiene un montón de comprobaciones adicionales para ver si el servidor está realmente vivo, o tal vez ya haya muerto.
A continuación se muestra un diagrama de ejemplo de cómo funciona el faylover.

En la sección seleccionada,
reiniciamos el servidor maestro . Esto es necesario porque tenemos MySQL 5.6, y en él la replicación semisincrónica no es sin pérdidas. Por lo tanto, las lecturas fantasmas son posibles, y necesitamos este maestro, incluso si no ha muerto, matar lo más rápido posible para que los clientes se desconecten de él. Por lo tanto, hacemos un restablecimiento completo a través de Ipmi; esta es la primera operación más importante que debemos hacer. En la versión MySQL 5.7, esto no es tan crítico.
Sincronización de clúster. ¿Por qué necesitamos sincronización de clúster?
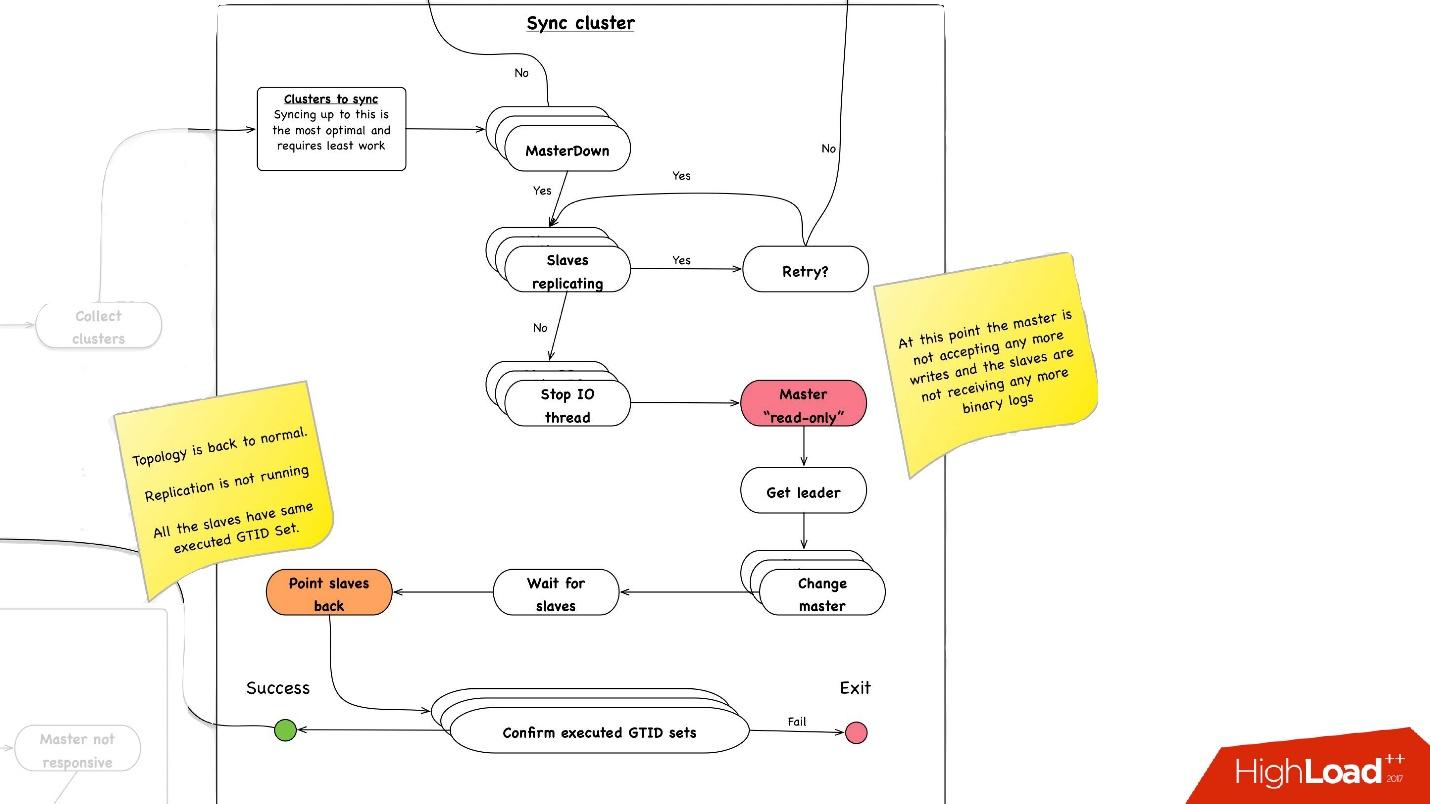
Si recordamos la imagen anterior con nuestra topología, un servidor maestro tiene tres servidores esclavos: dos en un centro de datos, uno en el otro. Con la promoción, necesitamos que el maestro esté en el mismo centro de datos principal. Pero a veces, cuando se cargan esclavos, con semisync sucede que un esclavo semisync se convierte en esclavo en otro centro de datos, porque no está cargado. Por lo tanto, primero debemos sincronizar todo el clúster, y luego hacer promoción en esclavo en el centro de datos que necesitamos. Esto se hace de manera muy simple:
- Paramos todos los hilos de E / S en todos los servidores esclavos.
- Después de eso, ya sabemos con certeza que el maestro es de "solo lectura", ya que la semisincronización se ha desconectado y nadie más puede escribir nada allí.
- A continuación, seleccionamos el esclavo con el mayor conjunto GTID recuperado / ejecutado, es decir, con la transacción más grande que descargó o ya aplicó.
- Reconfiguramos todos los servidores esclavos para este esclavo seleccionado, iniciamos el hilo de E / S y están sincronizados.
- Esperamos hasta que estén sincronizados, después de lo cual tenemos todo el clúster se sincroniza. , executed GTID set .
—
.
promotion , :
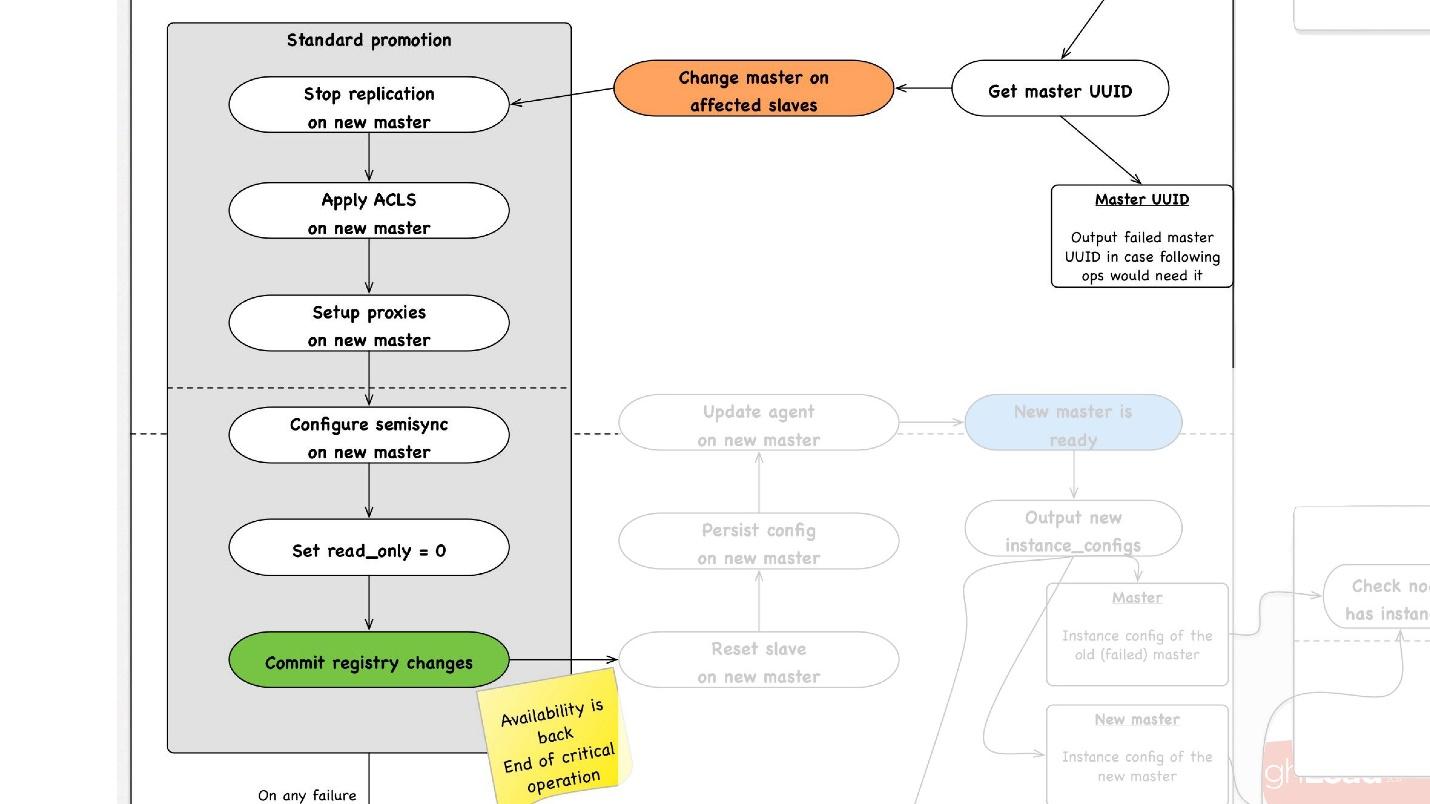
- slave -, , master, promotion.
- slave- master, , ACLs, , - proxy, , - .
- read_only = 0, , master , . master .
- - . - , , , , , proxy .
- .
, rollback , . rollback reboot. , , , — change master — master .
— . , , , , .
● slave
, slave-, . .
●
, , . .
●
, , . . 3 .
, , , :
- . 1 40 .
- .
, . 1 40 , , , .
, . . 4 .
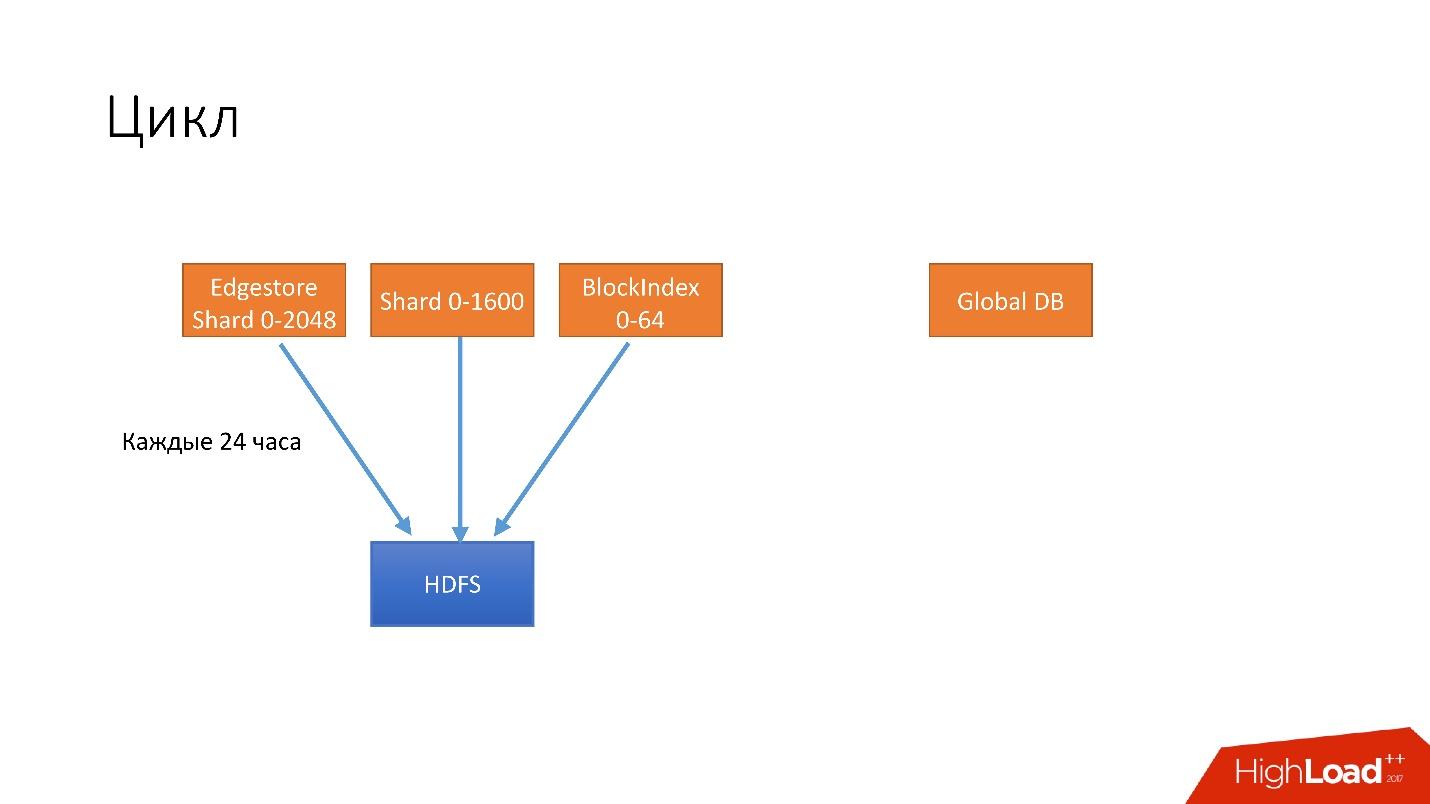
- 24 . HDFS, .
- 6 unsharded databases, Global DB. , , , .
- 3 S3.
- 3 S3 .

. , 3 , HDFS 3 , 6 S3. .
, .

, , . , , recovery - . , , - . 100 , .
, , , , , , , . .

hot-, Percona xtrabackup. —stream=xbstream, , . script-splitter, , .
MySQL 2x. 3 , , , 1 500 . , , HDFS S3.
.

, , HDFS S3, , splitter xtrabackup, . crash-recovery.
hot , crash-recovery . , . binlog, master.
binlogs?binlog'. master , 4 , 100 , HDFS.
: Binlog Backuper, . , , binlog HDFS.
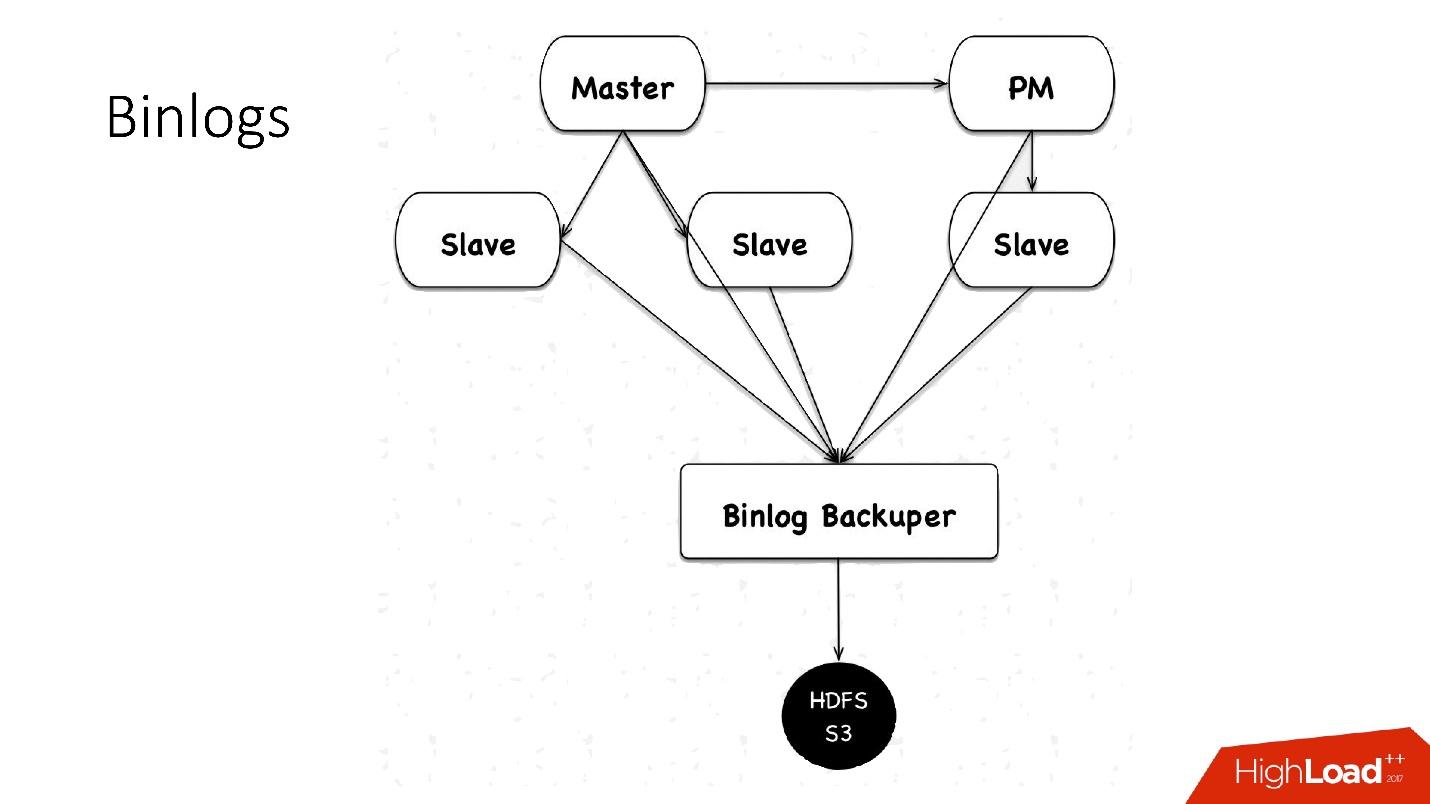
, 4 , 5 , , , . HDFS S3 .
.
:
- — 10 , 45 — .
- , scheduler multi instance slave master .
- — , . , , , , , , . pt-table-checksum , .
, :
- 1 10 , . crash-recovery, .
- .

slave -, . , . .
++
. Hardware , (HDD) 10 , + crash recovery xtrabackup, . , , . , , , , HDD , HDFS .
, — :
- ;
- .
, HDFS, , , .
Automatización
, 6 000 . , , — :
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
, , , , — , -. , .
Availability () — , . — recovery , .

MySQL , heartbeat. Heartbeat — timestamp.
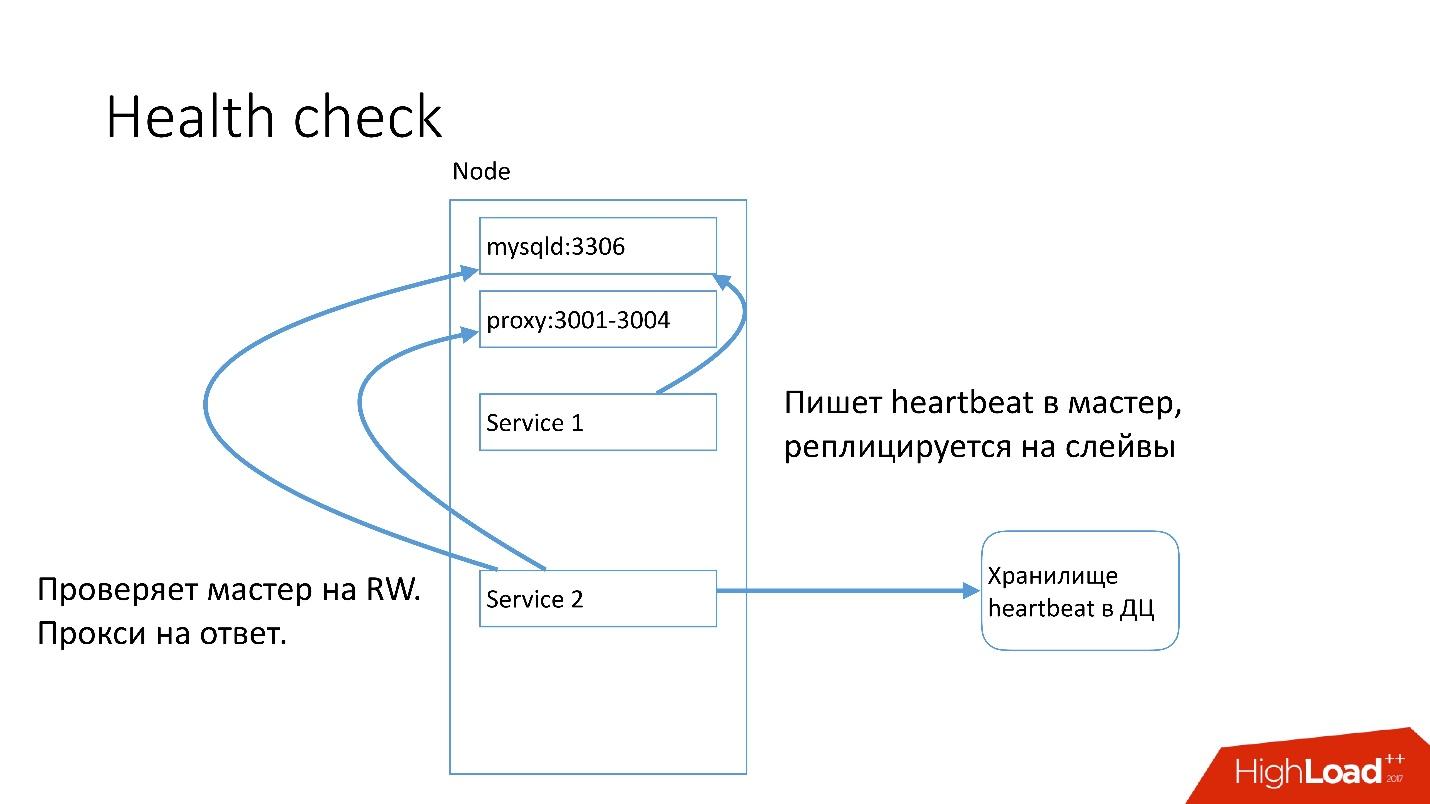
, , , master read-write. heartbeat.
auto-replace , .
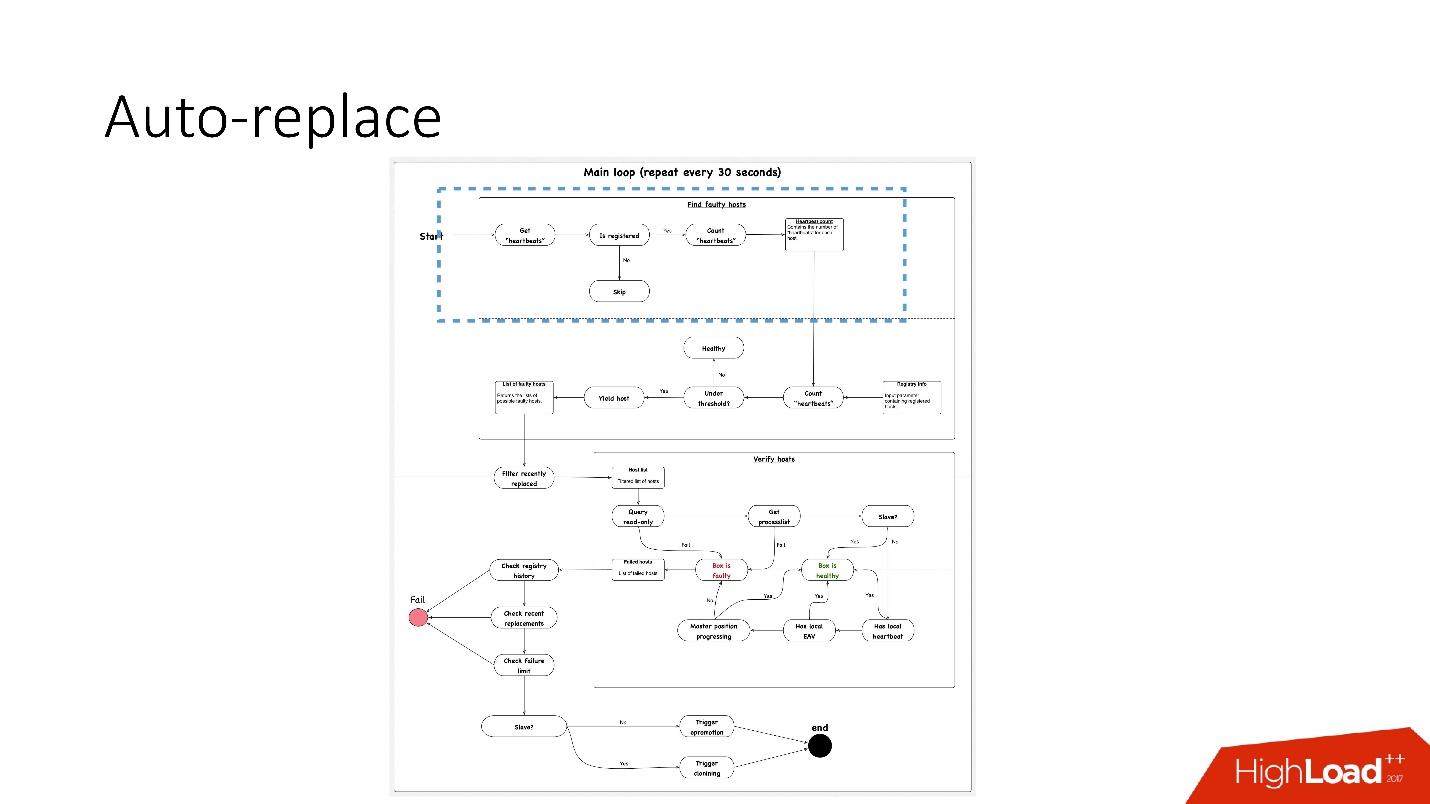 , 91 .?
, 91 .?- , heartbeat . , . heartbeat', , heartbeat' 30 .
- Luego, vea si su número satisface el valor umbral. Si no, entonces algo está mal con el servidor, ya que no envió un latido.
- Después de eso, hacemos una verificación inversa por si acaso: de repente, estos dos servicios han muerto, algo está en la red o la base de datos global no puede escribir el latido del corazón por alguna razón. En la verificación inversa, nos conectamos a una base de datos rota y verificamos su estado.
- Si todo lo demás falla, observamos si la posición maestra está progresando o no, si hay registros en ella. Si no sucede nada, entonces este servidor definitivamente no funciona.
- El último paso es en realidad el reemplazo automático.
El reemplazo automático es muy conservador, nunca quiere hacer muchas operaciones automáticas.
- Primero, verificamos si ha habido alguna operación de topología recientemente. Tal vez este servidor acaba de ser agregado y algo en él aún no se está ejecutando.
- Verificamos si hubo reemplazos en el mismo clúster en cualquier momento.
- Verifique qué límite de falla tenemos. Si tenemos muchos problemas al mismo tiempo, 10, 20, entonces no los resolveremos automáticamente, porque inadvertidamente podemos interrumpir el funcionamiento de todas las bases de datos.
Por lo tanto,
resolvemos solo un problema a la vez .
En consecuencia, para el servidor esclavo, comenzamos a clonar y simplemente lo eliminamos de la topología, y si es maestro, entonces lanzamos el feylover, la llamada promoción de emergencia.
DBManager
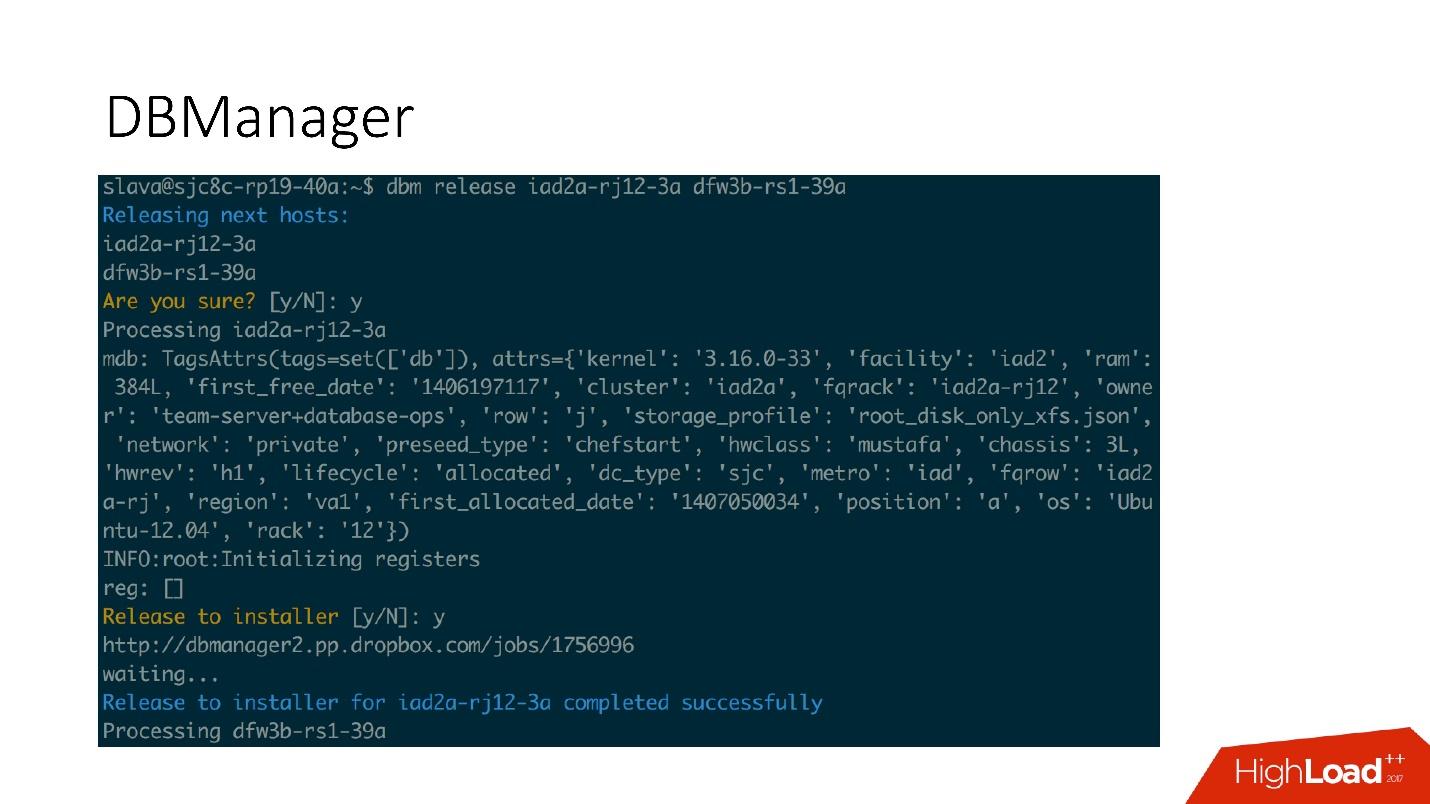
DBManager es un servicio para administrar nuestras bases de datos. Tiene:
- planificador de tareas inteligente que sabe exactamente cuándo comenzar el trabajo;
- registros y toda la información: quién, cuándo y qué se lanzó: esta es la fuente de la verdad;
- punto de sincronización
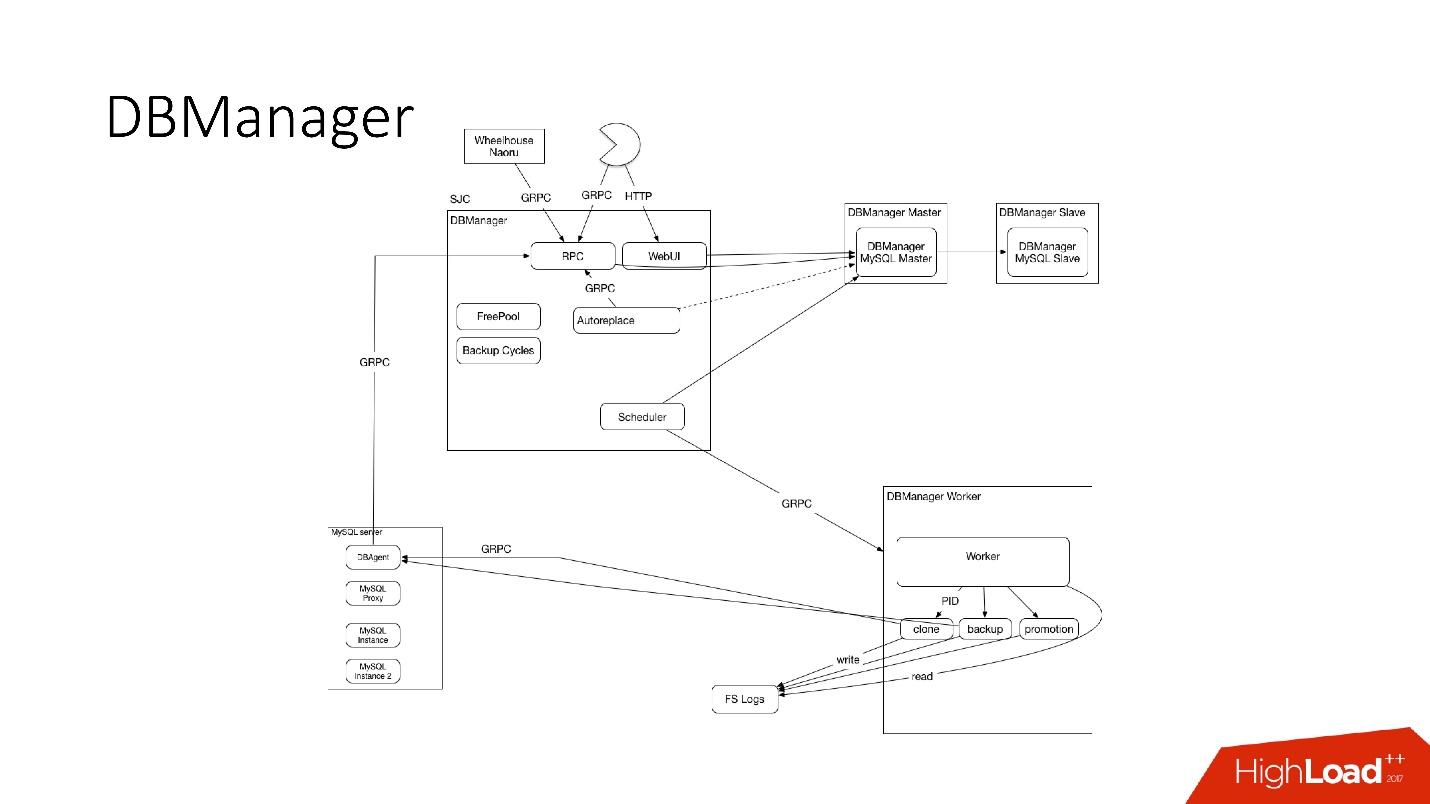
DBManager es bastante simple arquitectónicamente.
- Hay clientes, ya sea DBA que hacen algo a través de la interfaz web, o scripts / servicios que escribieron DBA que acceden a través de gRPC.
- Hay sistemas externos como Wheelhouse y Naoru, que van a DBManager a través de gRPC.
- Hay un programador que entiende qué operación, cuándo y dónde puede comenzar.
- Hay un trabajador muy estúpido que, cuando se trata de una operación, lo inicia y lo verifica por PID. El trabajador puede reiniciar, los procesos no se interrumpen. Todos los trabajadores están ubicados lo más cerca posible de los servidores en los que tienen lugar las operaciones, de modo que, por ejemplo, al actualizar ACLS, no necesitamos hacer muchos viajes de ida y vuelta.
- En cada servidor SQL tenemos un DBAgent: este es un servidor RPC. Cuando necesite realizar alguna operación en el servidor, le enviaremos una solicitud RPC.
Tenemos una interfaz web para DBManager, donde puede ver las tareas que se ejecutan actualmente, los registros de estas tareas, quién la inició y cuándo, qué operaciones se realizaron para el servidor de una base de datos específica, etc.
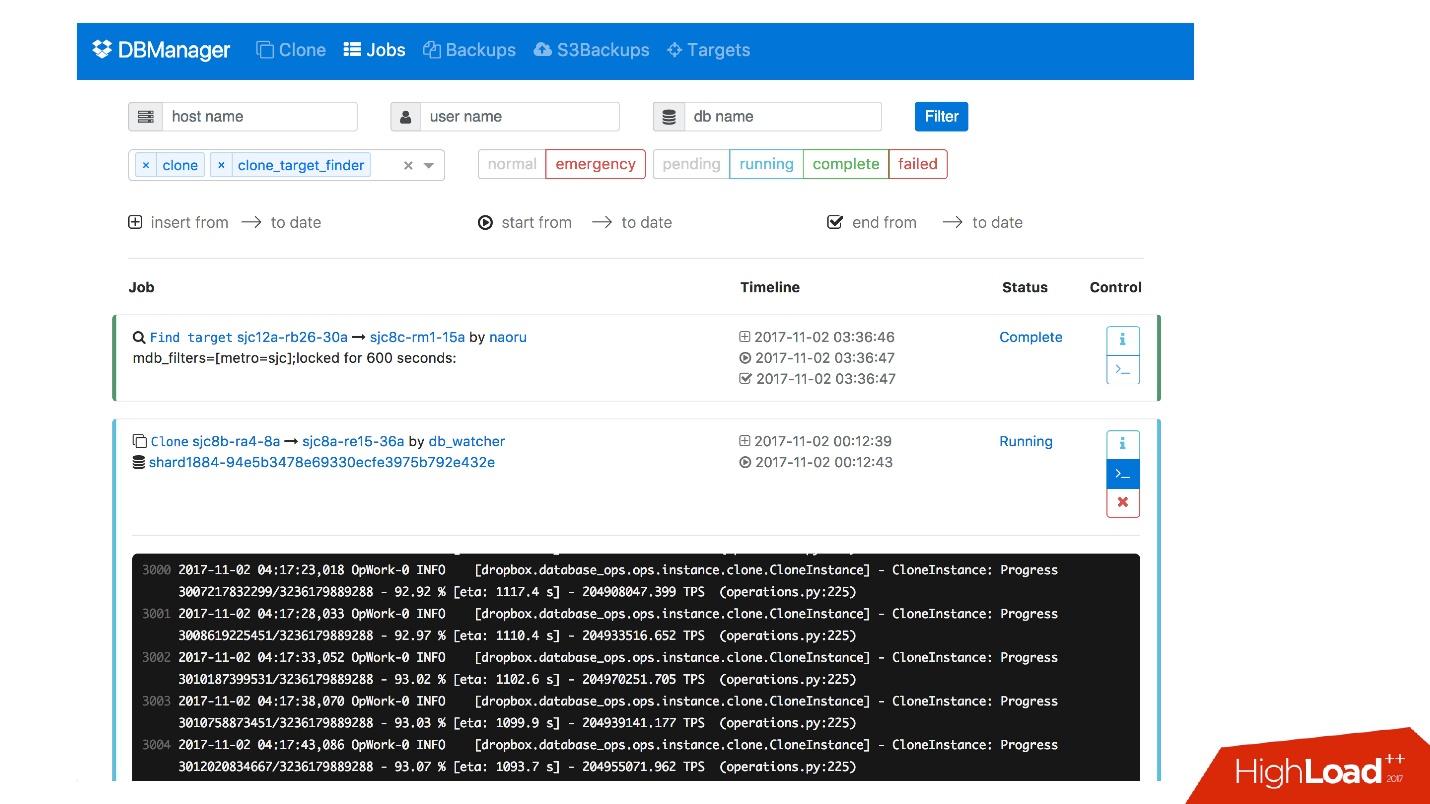
Hay una interfaz CLI bastante simple donde puede ejecutar tareas y también verlas en vistas convenientes.
Remediaciones
También tenemos un sistema para responder a los problemas. Cuando algo está roto, por ejemplo, la unidad falla, o algún servicio no funciona,
Naoru funciona
. Este es el sistema que funciona en Dropbox, todos lo usan y está diseñado específicamente para tareas tan pequeñas. Hablé sobre Naoru en mi
informe en 2016.
Wheelhouse se basa en una máquina de
estado y está diseñado para procesos largos. Por ejemplo, necesitamos actualizar el kernel en todo MySQL en todo nuestro clúster de 6,000 máquinas. Wheelhouse hace esto claramente: actualizaciones en el servidor esclavo, inicia la promoción, el esclavo se convierte en maestro, actualizaciones en el servidor maestro. Esta operación puede tomar un mes o incluso dos.
Monitoreo

Esto es muy importante
Si no supervisa el sistema, lo más probable es que no funcione.
Monitoreamos todo en MySQL: toda la información que podemos obtener de MySQL se almacena en algún lugar, podemos acceder a ella a tiempo. Almacenamos información en InnoDb, estadísticas sobre solicitudes, sobre transacciones, sobre la duración de las transacciones, percentil sobre la duración de las transacciones, sobre la replicación, en la red, en general, una gran cantidad de métricas.
Alerta
Tenemos 992 alertas configuradas. De hecho, nadie está mirando las métricas, me parece que no hay personas que vienen a trabajar y comienzan a mirar la tabla de métricas, hay tareas más interesantes.

Por lo tanto, hay alertas que funcionan cuando se alcanzan ciertos valores de umbral.
Tenemos 992 alertas, pase lo que pase, lo descubriremos .
Incidentes

Tenemos PagerDuty, un servicio a través del cual se envían alertas a las personas responsables que comienzan a tomar medidas.

En este caso, se produjo un error en la promoción de emergencia, e inmediatamente después de que se registró una alerta, el maestro cayó. Después de eso, el oficial de servicio verificó qué impedía la promoción de emergencia e hizo las operaciones manuales necesarias.
Ciertamente analizaremos cada incidente que ha ocurrido, para cada incidente tenemos una tarea en el rastreador de tareas. Incluso si este incidente es un problema en nuestras alertas, también creamos una tarea, porque si el problema está en la lógica y los umbrales de las alertas, entonces deben cambiarse. Las alertas no solo deben estropear la vida de las personas. Una alerta siempre es dolorosa, especialmente a las 4 a.m.
Prueba
Al igual que con el monitoreo, estoy seguro de que todos lo están probando. Además de las pruebas unitarias con las que cubrimos nuestro código, tenemos pruebas de integración en las que probamos:
- todas las topologías que tenemos;
- todas las operaciones en estas topologías.
Si tenemos operaciones de promoción, probamos las operaciones de promoción en la prueba de integración. Si tenemos clonación, hacemos clonación para todas las topologías que tenemos.
Ejemplo de topología
Tenemos topologías para todas las ocasiones: 2 centros de datos con múltiples instancias, con fragmentos, sin fragmentos, con clústeres, un centro de datos, generalmente casi cualquier topología, incluso aquellos que no usamos, solo para ver.

En este archivo, solo tenemos la configuración, qué servidores y con lo que necesitamos generar. Por ejemplo, necesitamos elevar master, y decimos que necesitamos hacer esto con tal y tal información de instancia, con tal y tal base de datos en tal y tal puerto. Casi todo va junto con Bazel, que crea una topología sobre la base de estos archivos, inicia el servidor MySQL y luego comienza la prueba.

La prueba parece muy simple: indicamos qué topología se está utilizando. En esta prueba, probamos auto_replace.
- Creamos el servicio auto_replace, lo iniciamos.
- Matamos al maestro en nuestra topología, esperamos un momento y vemos que el esclavo objetivo se ha convertido en maestro. Si no, la prueba falló.
Etapas
Los entornos de escenario son las mismas bases de datos que en producción, pero no hay tráfico de usuarios en ellos, pero hay algo de tráfico sintético que es similar a la producción a través de Percona Playback, sysbench y sistemas similares.
En Percona Playback, registramos el tráfico, luego lo perdemos en el entorno del escenario con diferentes intensidades, podemos perder 2-3 veces más rápido. Es decir, es artificial, pero muy cercano a la carga real.
Esto es necesario porque en las pruebas de integración no podemos probar nuestra producción. No podemos probar la alerta o el hecho de que las métricas funcionen. En la etapa de prueba, probamos alertas, métricas, operaciones, periódicamente matamos los servidores y vemos que se recopilan normalmente.
Además, probamos toda la automatización juntos, porque en las pruebas de integración, lo más probable es que se pruebe una parte del sistema, y en la puesta en escena, todos los sistemas automatizados funcionan simultáneamente. A veces piensas que el sistema se comportará de esta manera y no de otra manera, pero puede comportarse de una manera completamente diferente.
DRT (prueba de recuperación de desastres)
También realizamos pruebas en producción, directamente sobre bases reales. Esto se llama prueba de recuperación de desastres. ¿Por qué necesitamos esto?
● Queremos probar nuestras garantías.
Esto lo hacen muchas grandes empresas. Por ejemplo, Google tiene un servicio que funcionó de manera tan estable, el 100% del tiempo, que todos los servicios que lo utilizaron decidieron que este servicio es realmente 100% estable y nunca falla. Por lo tanto, Google tuvo que abandonar este servicio a propósito, para que los usuarios tengan en cuenta esta posibilidad.
Así que estamos, tenemos la garantía de que MySQL funciona, ¡y a veces no funciona! Y tenemos la garantía de que puede no funcionar durante un cierto período de tiempo, los clientes deben tener esto en cuenta. De vez en cuando, matamos al maestro de producción, o si queremos hacer un faylover, matamos a todos los esclavos para ver cómo se comporta la replicación semisincrónica.
● Los clientes están preparados para estos errores (reemplazo y muerte del maestro)
¿Por qué es eso bueno? Tuvimos un caso cuando durante la promoción 4 fragmentos de 1600, la disponibilidad cayó al 20%. Parece que algo está mal, para 4 fragmentos de 1600 debería haber otros números. Las failovers para este sistema eran raras, aproximadamente una vez al mes, y todos decidieron: "Bueno, es una failover, sucede".
En algún momento, cuando cambiamos a un nuevo sistema, una persona decidió optimizar esos dos servicios de grabación de latidos y los combinó en uno. Este servicio hizo algo más y, al final, murió y los latidos del corazón dejaron de grabar. Dio la casualidad de que para este cliente teníamos 8 faylovers al día. Todo yacía - 20% de disponibilidad.
Resultó que en este cliente mantener vivo es de 6 horas. En consecuencia, tan pronto como el maestro murió, mantuvimos todas las conexiones durante otras 6 horas. El grupo no pudo continuar funcionando: sus conexiones se mantienen, es limitado y no funciona. Fue reparado.
Hacemos el feylover nuevamente, ya no es del 20%, pero aún es mucho. Algo sigue mal. Resultó que era un error en la implementación del grupo. Cuando se le solicitó, el grupo se convirtió en muchos fragmentos y luego conectó todo esto. Si algunos fragmentos eran febriles, se produjo alguna condición de carrera en el código Go y todo el grupo se obstruyó. Todos estos fragmentos ya no podían funcionar.
Las pruebas de recuperación ante desastres son muy útiles, ya que los clientes deben estar preparados para estos errores, deben verificar su código.
● Además, las pruebas de recuperación ante desastres son buenas porque se realizan durante el horario comercial y todo está en su lugar, menos estrés, la gente sabe lo que sucederá ahora. Esto no sucede de noche, y es genial.
Conclusión
1. Todo necesita ser automatizado, nunca lo tengas en tus manos.
Cada vez que alguien sube al sistema con nuestras manos, todo muere y se rompe en nuestro sistema, ¡cada vez! - Incluso en operaciones simples. Por ejemplo, un esclavo murió, una persona tuvo que agregar un segundo, pero decidió eliminar al esclavo muerto con sus manos de la topología. Sin embargo, en lugar del difunto, copió al comando en vivo: el maestro se quedó sin esclavo. Dichas operaciones no deben hacerse manualmente.
2. Las pruebas deben ser continuas y automatizadas (y en producción).
Su sistema está cambiando, su infraestructura está cambiando. Si marcó una vez, y pareció funcionar, esto no significa que funcionará mañana. Por lo tanto, debe realizar pruebas automáticas constantemente todos los días, incluso en producción.
3. Asegúrese de tener clientes (bibliotecas).
Los usuarios pueden no saber cómo funcionan las bases de datos. Es posible que no entiendan por qué se necesitan tiempos de espera, mantener vivo. Por lo tanto, es mejor tener estos clientes: estará más tranquilo.
4. Es necesario determinar sus principios para construir el sistema y sus garantías, y cumplir siempre con ellos.
Por lo tanto, puede soportar 6 mil servidores de bases de datos.
En las preguntas posteriores al informe, y especialmente las respuestas a ellas, también hay mucha información útil.Preguntas y respuestas
- ¿Qué sucederá si hay un desequilibrio en la carga de fragmentos? ¿Alguna metainformación sobre algún archivo resultó ser más popular? ¿Es posible difundir este fragmento, o la carga en los fragmentos no difiere en ningún lugar por orden de magnitud?
Ella no difiere en órdenes de magnitud. Se distribuye casi normalmente. Tenemos aceleración, es decir, no podemos sobrecargar el fragmento, de hecho, estamos acelerando a nivel del cliente. En general, sucede que alguna estrella sube una foto y el fragmento prácticamente explota. Entonces prohibimos este enlace
- Dijiste que tienes 992 alertas. ¿Podría dar más detalles sobre lo que es? ¿Está listo para usar o se ha creado? Si se crea, ¿es trabajo manual o algo así como el aprendizaje automático?
Todo esto se crea manualmente. Tenemos nuestro propio sistema interno llamado Vortex, donde se almacenan las métricas, se admiten alertas. Hay un archivo yaml que dice que existe una condición, por ejemplo, que las copias de seguridad deben ejecutarse todos los días, y si se cumple esta condición, la alerta no funciona. Si no se ejecuta, entonces llega una alerta.
Este es nuestro desarrollo interno, porque pocas personas pueden almacenar tantas métricas como necesitemos.
- ¿Qué tan fuertes deben ser los nervios para hacer DRT? Caíste, CODIFICASTE, no sube, con cada minuto de pánico más.
En general, trabajar en bases de datos es realmente un dolor. Si la base de datos falla, el servicio no funciona, todo el Dropbox no funciona. Este es un verdadero dolor. DRT es útil porque es un reloj de negocios. Es decir, estoy listo, estoy sentado en mi escritorio, tomé café, estoy fresco, estoy listo para hacer cualquier cosa.
Peor cuando sucede a las 4 a.m., y no es DRT. Por ejemplo, la última falla importante que tuvimos recientemente. Al inyectar un nuevo sistema, olvidamos establecer la puntuación OOM para nuestro MySQL. Había otro servicio que leía binlog. En algún momento, nuestro operador es manual, ¡de nuevo manualmente! - ejecuta el comando para eliminar cierta información en la tabla de suma de comprobación de Percona. Solo una simple eliminación, una operación simple, pero esta operación generó un enorme binlog. El servicio leyó este binlog en la memoria, ¿OOM Killer vino y pensó a quién matar? ¡Y olvidamos establecer el puntaje OOM, y mata a MySQL!
Tenemos 40 maestros muriendo a las 4 a.m. Cuando mueren 40 maestros, es realmente muy aterrador y peligroso. DRT no da miedo y no es peligroso. Nos quedamos por alrededor de una hora.
Por cierto, DRT es una buena manera de ensayar esos momentos para que sepamos exactamente qué secuencia de acciones se necesita si algo se rompe en masa.
- Me gustaría aprender más sobre cómo cambiar maestro-maestro. Primero, ¿por qué no se usa un clúster, por ejemplo? Un clúster de base de datos, es decir, no un maestro-esclavo con conmutación, sino una aplicación maestro-maestro, de modo que si uno cae, no da miedo.
¿Te refieres a algo como replicación grupal, grupo de galera, etc.? Me parece que la aplicación grupal aún no está lista para la vida. Desafortunadamente, aún no hemos probado Galera. Esto es genial cuando un faylover está dentro de su protocolo, pero, desafortunadamente, tienen muchos otros problemas, y no es tan fácil cambiar a esta solución.
- Parece que en MySQL 8 hay algo así como un clúster InnoDb. ¿No lo intentaste?
Todavía tenemos un valor de 5.6. No sé cuándo cambiaremos a 8. Quizás lo intentemos.
- En este caso, si tiene un gran maestro, al cambiar de uno a otro, resulta que la cola se acumula en los servidores esclavos con una carga alta. Si el maestro se extingue, ¿es necesario que llegue la cola para que el esclavo cambie al modo maestro, o se hace de alguna manera diferente?
La carga en el maestro está regulada por semisync. Semisync limita la grabación maestra al rendimiento del servidor esclavo. Por supuesto, puede ser que la transacción haya llegado, la sincronización funcionó, pero los esclavos perdieron esta transacción durante mucho tiempo. Luego debe esperar hasta que el esclavo pierda esta transacción hasta el final.
- Pero entonces nuevos datos vendrán a dominar, y será necesario ...
Cuando comenzamos el proceso de promoción, deshabilitamos las E / S. Después de eso, el maestro no puede escribir nada porque la semisincronización se replica. La lectura fantasma puede venir, desafortunadamente, pero este ya es otro problema.
- Estas son todas máquinas de estado hermosas: ¿en qué están escritas las secuencias de comandos y qué tan difícil es agregar un nuevo paso? ¿Qué debe hacerse a la persona que escribe este sistema?
Todos los scripts están escritos en Python, todos los servicios están escritos en Go. Esta es nuestra política. Cambiar la lógica es fácil, solo en el código de Python que genera el diagrama de estado.
- Y puedes leer más sobre las pruebas. ¿Cómo se escriben las pruebas, cómo implementan los nodos en una máquina virtual? ¿Son estos contenedores?
Si Vamos a probar con la ayuda de Bazel. Hay algunos archivos de configuración (json) y Bazel recoge un script que crea la topología para nuestra prueba usando este archivo de configuración. Se describen diferentes topologías allí.
Todo funciona para nosotros en contenedores acoplables: funciona en CI o en Devbox. Tenemos un sistema Devbox. Todos estamos desarrollando en algún servidor remoto, y esto puede funcionar en él, por ejemplo. Allí también se ejecuta dentro de Bazel, dentro de un contenedor acoplable o en el Sandbox de Bazel. Bazel es muy complicado pero divertido.
- Cuando realizó 4 instancias en un servidor, ¿perdió la eficiencia de la memoria?
Cada instancia se ha vuelto más pequeña. En consecuencia, cuanto menos memoria opere MySQL, más fácil será para él vivir. Cualquier sistema es más fácil de operar con una pequeña cantidad de memoria. En este lugar, no hemos perdido nada. Tenemos los grupos C más simples que limitan estas instancias de la memoria.
- Si tiene 6,000 servidores que almacenan bases de datos, ¿puede nombrar cuántos miles de millones de petabytes están almacenados en sus archivos?
Estas son docenas de exabytes, hemos vertido datos de Amazon durante un año.
- Resulta que al principio tenías 8 servidores, 200 fragmentos en ellos, luego 400 servidores con 4 fragmentos cada uno. Tienes 1600 fragmentos, ¿es algún tipo de valor codificado? ¿Nunca puedes volver a hacerlo? ¿Te dolerá si necesitas, por ejemplo, 3.200 fragmentos?
Sí, originalmente era 1600. Esto se hizo hace menos de 10 años, y todavía vivimos. Pero todavía tenemos 4 fragmentos, 4 veces aún podemos aumentar el espacio.
- ¿Cómo mueren los servidores, principalmente por qué razones? ¿Qué sucede con más frecuencia, con menos frecuencia, y es especialmente interesante, se producen los capítulos espontáneos?
Lo más importante es que los discos salgan volando. Tenemos RAID 0: el disco se bloqueó, el maestro murió. Este es el problema principal, pero es más fácil para nosotros reemplazar este servidor. Google es más fácil de reemplazar el centro de datos, todavía tenemos un servidor. Casi nunca tuvimos la suma de verificación de la corrupción. Para ser sincero, no recuerdo cuándo fue la última vez. A menudo actualizamos el asistente. Nuestro tiempo de vida para un maestro está limitado a 60 días. No puede vivir más tiempo, después de eso lo reemplazamos con un nuevo servidor, porque por alguna razón algo se está acumulando constantemente en MySQL, y después de 60 días vemos que los problemas comienzan a ocurrir. Quizás no en MySQL, quizás en Linux.
, . 60 , . .
— , 6 . , JPEG , JPEG, , ? , , - ? — , ?
, . — Dropbox .
— ? ? , , - , , ? , 10 . , 7 , 6 , . ?
Dropbox - , . . , , , - .
, . , , , . - , 6 , , , , .
, facebook youtube- — Highload++ 2018 . , 1 .