
En el departamento de análisis del cine en línea, Okko ama automatizar el cálculo de las tarifas cinematográficas de Alexander Nevsky tanto como sea posible, y en el tiempo libre para aprender cosas nuevas e implementar cosas interesantes que por alguna razón generalmente se traducen en bots para Telegram. Por ejemplo, antes del comienzo de la Copa Mundial de la FIFA 2018, lanzamos un bot al chat de trabajo, que recolectó apuestas sobre la distribución de los lugares finales, y después de la final, calculamos los resultados de acuerdo con una métrica pre-inventada y determinamos los ganadores. Croacia no ha puesto cuatro entre los cuatro primeros.
Tiempo libre reciente de compilar comedias rusas TOP-10 que dedicamos a crear un bot que encuentre una celebridad a la que se parezca más el usuario. En el chat de trabajo, todos apreciaron tanto la idea que decidimos poner el bot a disposición del público. En este artículo, recordamos brevemente la teoría, hablamos sobre la creación de nuestro bot y cómo hacerlo usted mismo.
Un poco de teoría (principalmente en imágenes)
En detalle sobre cómo se organizan los sistemas de reconocimiento facial, lo mencioné en uno de mis artículos anteriores . Un lector interesado puede seguir el enlace, y resumiré a continuación solo los puntos principales.
Entonces, tienes una fotografía en la que, tal vez, incluso se muestra una cara y quieres entender de quién es. Para hacer esto, debe seguir 4 pasos simples:
- Seleccione el rectángulo que bordea la cara.
- Resalta los puntos clave de la cara.
- Alinee y recorte su cara.
- Convierta una imagen de la cara en alguna representación interpretada por máquina.
- Compare esta vista con otras que tenga disponibles.
Selección de la cara
Aunque las redes neuronales convolucionales han aprendido recientemente cómo encontrar caras en una imagen no peor que los métodos clásicos, siguen siendo inferiores al HOG clásico en velocidad y facilidad de uso.
HOG - Histogramas de gradientes orientados. Este tipo asocia cada píxel de la imagen de origen con su gradiente, un vector en la dirección en que el brillo de los píxeles cambia más. La ventaja de este enfoque es que no le importan los valores absolutos del brillo de los píxeles, solo su relación es suficiente. Por lo tanto, una cara normal, oscura y mal iluminada y ruidosa se mostrará en aproximadamente el mismo histograma de gradientes.
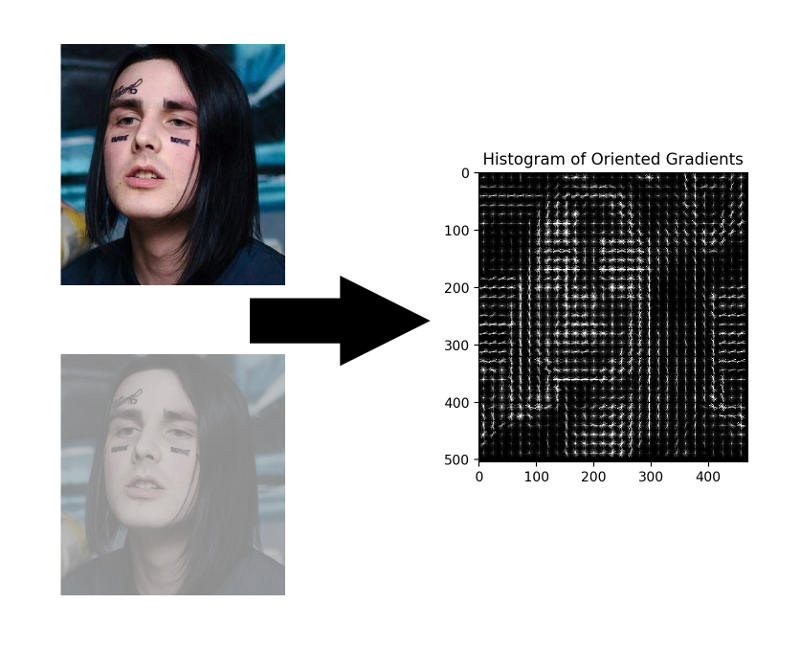
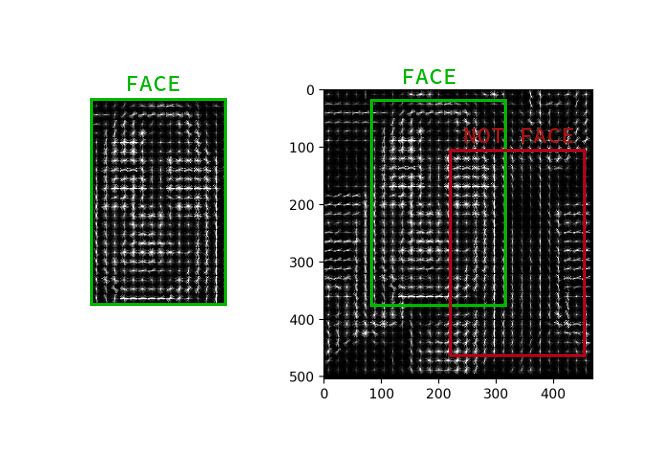
No es necesario calcular el gradiente para cada píxel, es suficiente calcular el gradiente promedio para cada cuadrado pequeño n por n . Usando el campo de vector recibido, puede pasar por un detector con una ventana y determinar para cada ventana qué tan probable es la cara en él. El detector puede ser SVM, un bosque aleatorio o cualquier otra cosa.
Destacar puntos clave

Los puntos clave son puntos que ayudan a identificar a una persona en el espacio. Los científicos débiles e inseguros generalmente necesitan 68 puntos clave, y en casos especialmente descuidados, aún más. Los niños normales y seguros de sí mismos, que ganaban 300k por segundo, siempre tenían suficiente de cinco: las esquinas internas y externas de los ojos y la nariz.
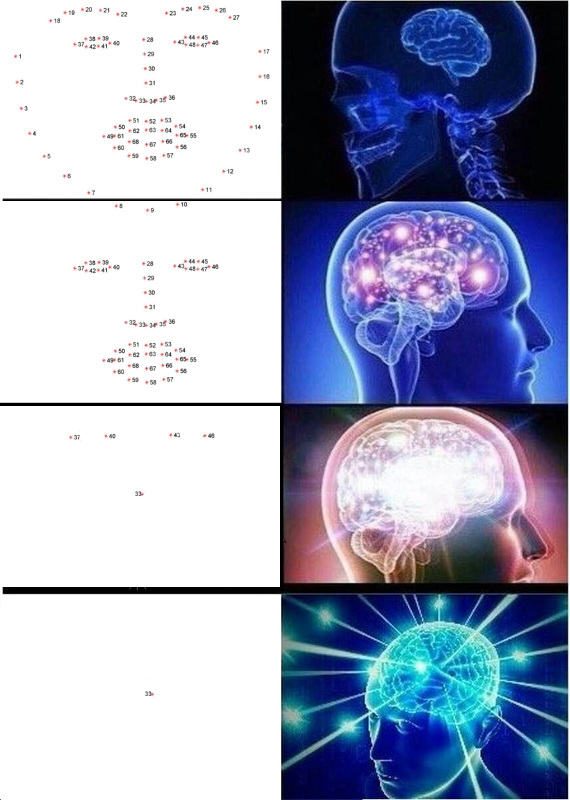
Dichos puntos pueden extraerse, por ejemplo, mediante una cascada de regresores .
Alineación de la cara
¿Aplicaciones pegadas en la infancia? Aquí todo es exactamente igual: construyes una transformación afín que traduce tres puntos arbitrarios a sus posiciones estándar. La nariz se puede dejar como está, pero para que los ojos cuenten sus centros: estos son los tres puntos listos.

Convierte imágenes faciales a vectores

Han pasado tres años desde la publicación del artículo sobre FaceNet , durante este tiempo aparecieron muchos esquemas de entrenamiento interesantes y funciones de pérdida, pero es ella quien domina entre las soluciones OpenSource disponibles. Aparentemente, todo es una combinación de facilidad de comprensión, implementación y resultados decentes. Gracias al menos por el hecho de que en los últimos tres años la arquitectura se ha cambiado a ResNet.
FaceNet aprende de triples ejemplos: (ancla, positivo, negativo). El ancla y los ejemplos positivos pertenecen a una persona, mientras que el negativo se elige como la cara de otra persona, que por alguna razón la red está demasiado cerca de la primera. La función de pérdida está diseñada de tal manera que corrige este malentendido, reúne los ejemplos necesarios y elimina lo innecesario.

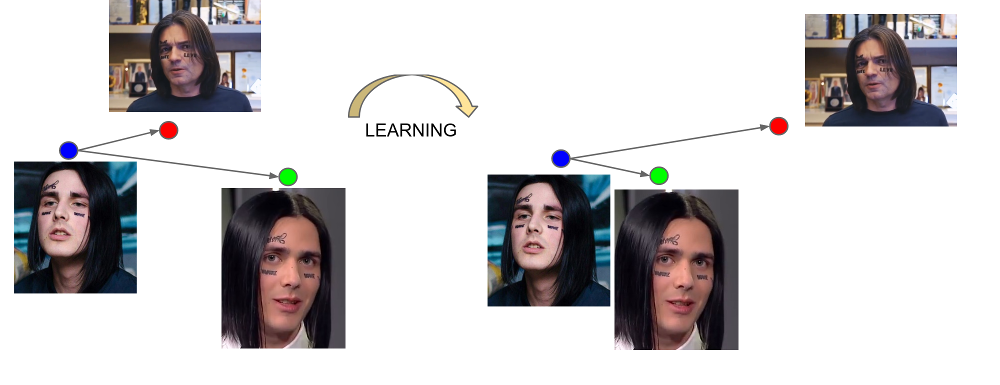
La salida de la última capa de la red se denomina incrustación: una representación representativa de una persona en un determinado espacio de pequeña dimensión (generalmente de 128 dimensiones).
Comparación de rostros
La belleza de las incrustaciones bien entrenadas es que las caras de una persona se muestran en un pequeño vecindario del espacio, alejado de las incrustaciones de las caras de otras personas. Entonces, para este espacio puede ingresar una medida de similitud, el recíproco de la distancia: Euclidiana o coseno, dependiendo de la distancia a la que se entrenó la red.
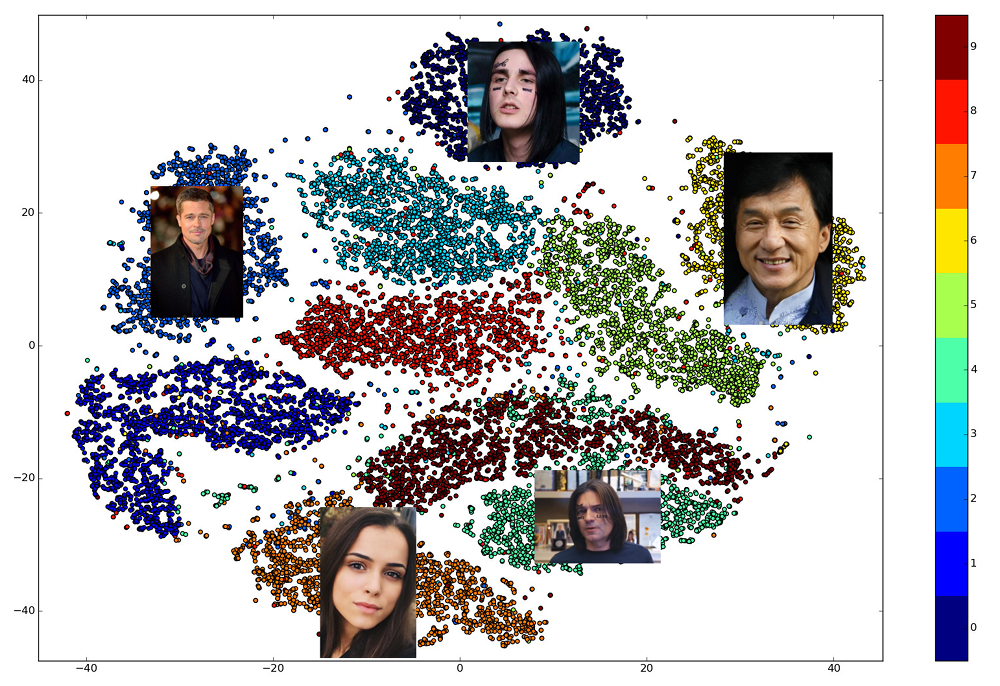
Por lo tanto, de antemano necesitamos construir incrustaciones para todas las personas entre las cuales se realizará la búsqueda, y luego, para cada solicitud, encontrar el vector más cercano entre ellas. O, de otra manera, resuelva el problema de encontrar k vecinos más cercanos, donde k puede ser igual a uno, o tal vez no, si queremos utilizar una lógica empresarial más avanzada. La persona propietaria del vector de resultados será la persona más similar a la persona solicitada.

¿Qué biblioteca usar?
La elección de las bibliotecas abiertas que implementan varias partes de la tubería es excelente. dlib y OpenCV pueden encontrar caras y puntos clave, y se pueden encontrar versiones pre-entrenadas de redes para cualquier marco de red neuronal grande. Hay un proyecto OpenFace donde puede elegir la arquitectura para sus requisitos de velocidad y calidad. Pero solo una biblioteca le permite implementar los 5 puntos de reconocimiento facial en llamadas a tres funciones de alto nivel: dlib . Al mismo tiempo, está escrito en C ++ moderno, usa BLAS, tiene un contenedor para Python, no requiere una GPU y funciona bastante rápido en una CPU. Nuestra elección recayó en ella.
Haciendo tu propio bot
Esta sección ya se ha descrito en literalmente todas las guías para crear bots, pero una vez que escribamos lo mismo, tendremos que repetirla. Escribimos @BotFather y le pedimos un token para nuestro nuevo bot.
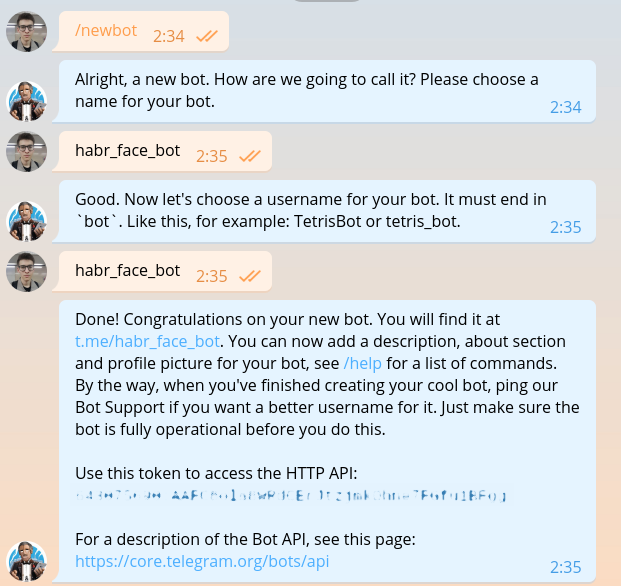
El token se parece a esto: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg . Es necesario para la autorización en cada solicitud a la API de bot de Telegram.
Espero que nadie en esta etapa tenga dudas al elegir un lenguaje de programación. Por supuesto, tienes que escribir en Haskell. Comencemos con el módulo principal.
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
Como puede ver en el código, en el futuro utilizaremos un DSL especial para escribir bots de telegramas. El código en este DSL está escrito en archivos separados. Instale el idioma del dominio y todo lo necesario.
python -m venv .env source .env/bin/activate pip install python-telegram-bot
python-telegram-bot es actualmente el marco más conveniente para crear bots. Es fácil de aprender, flexible, escalable, admite subprocesos múltiples. Desafortunadamente, en este momento no hay un solo marco asincrónico normal y se deben usar hilos antiguos en lugar de las corutinas divinas.

Iniciar un bot con python-telegram-bot es fácil. Agregue el siguiente código a bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
Ejecute el bot. Para fines de depuración, esto se puede hacer con el python bot.py sin ejecutar el código Haskell.
Un bot tan simple es capaz de mantener una conversación mínima y, por lo tanto, se puede organizar fácilmente para que funcione como desarrollador front-end.
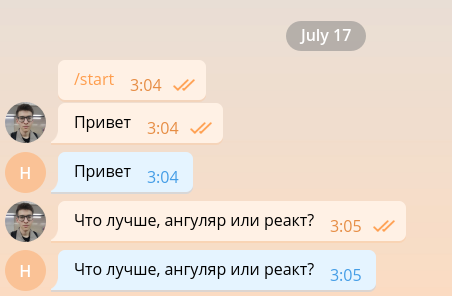
Pero la interfaz de los desarrolladores ya es demasiado, por lo que la eliminaremos lo antes posible y procederemos a implementar la funcionalidad principal. Por simplicidad, nuestro bot solo responderá a mensajes que contengan fotos e ignorará cualquier otro. Cambie el código a lo siguiente.
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
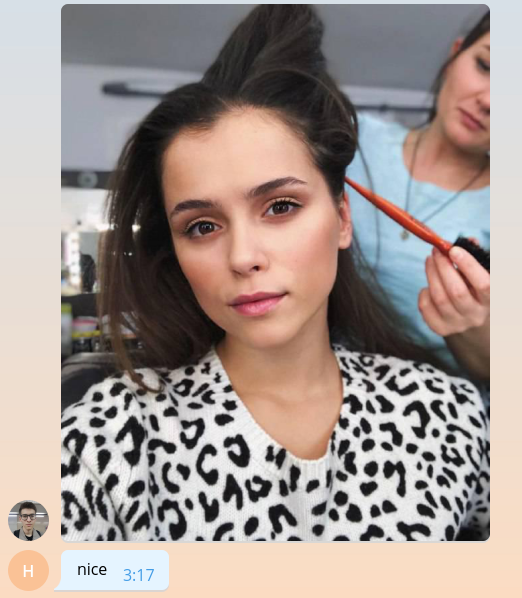
Cuando la imagen ingresa al servidor de Telegram, se ajusta automáticamente a varios tamaños predeterminados. El bot, a su vez, puede descargar una imagen de cualquier tamaño de las que figuran en el message.photo Lista de message.photo ordenada en orden ascendente. La opción más fácil: tomar la imagen más grande. Por supuesto, en un entorno de supermercado, debe pensar en la carga de la red y el tiempo de carga y elegir una imagen del tamaño mínimo adecuado. Agregue el código de descarga de la imagen en la parte superior de la función handle_photo .
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
La imagen ha sido descargada y está en la memoria. Para interpretarlo y presentarlo en forma de matriz de intensidad de píxeles, utilizamos las bibliotecas Pillow y numpy .
from PIL import Image import numpy as np
El siguiente código debe agregarse al bloque with .
image = Image.open(fd) image.load() image = np.asarray(image)
Ha llegado el momento dlib. Fuera de la función, cree un detector de rostros.
import dlib
face_detector = dlib.get_frontal_face_detector()
Y dentro de la función la usamos.
face_detects = face_detector(image, 1)
El segundo parámetro de la función significa la ampliación que debe aplicarse antes de intentar detectar caras. Cuanto más grande sea, más pequeñas y complejas serán las caras que el detector podrá detectar, pero más tiempo funcionará. face_detects : una lista de caras ordenadas en orden descendente de la confianza del detector de que la cara está frente a ella. En una aplicación real, lo más probable es que desee aplicar alguna lógica de elección de la persona principal, y en el estudio de caso nos limitaremos a elegir la primera.
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
Pasamos a la siguiente etapa: la búsqueda de puntos clave. Descargue el modelo entrenado y mueva su carga fuera de la función.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
Encuentra los puntos clave.
landmarks = shape_predictor(image, face)
Lo único que queda es pequeño: para enderezar la cara, conducirla a través de ResNet y obtener una incrustación de 128 dimensiones. Afortunadamente, dlib le permite hacer todo esto con una sola llamada. Solo necesita descargar el modelo previamente entrenado .
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
Solo mira en qué maravilloso momento vivimos. Toda la complejidad de las redes neuronales convolucionales, el método del vector de soporte y las transformaciones afines aplicadas al reconocimiento facial se encapsulan en tres llamadas a la biblioteca.
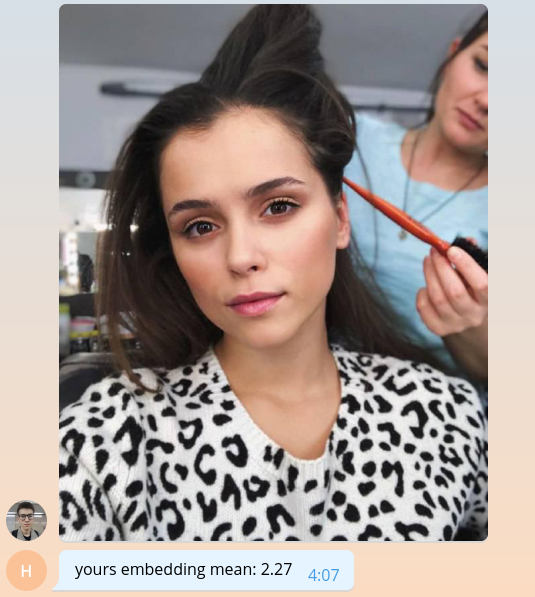
Como todavía no sabemos cómo hacer nada significativo, regresemos al usuario el valor promedio de su incrustación, multiplicado por mil.
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
Para que nuestro bot pueda determinar cuáles de las celebridades son los usuarios, ahora necesitamos encontrar al menos una foto de cada celebridad, construir una incrustación en ella y guardarla en algún lugar. Agregaremos solo 10 celebridades a nuestro robot de entrenamiento, encontrando sus fotos a mano y colocándolas en el directorio de photos . Así es como debería verse:
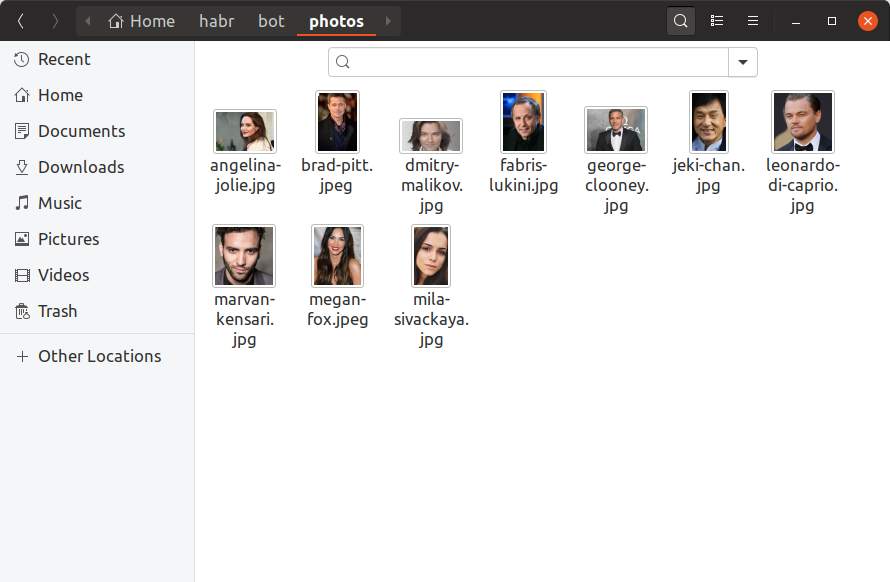
Si desea tener un millón de celebridades en la base de datos, todo se verá exactamente igual, solo que hay más archivos y es poco probable que pueda buscarlos con sus manos. Ahora build_embeddings.py utilidad build_embeddings.py usando las llamadas dlib que ya conocemos y dlib las incrustaciones de celebridades junto con sus nombres en formato binario.
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
Agregue carga de incrustación a nuestro código bot.
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
Y mediante una búsqueda exhaustiva, descubriremos quién es nuestro usuario.
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
Tenga en cuenta que usamos la distancia euclidiana como la distancia, porque la red en dlib fue entrenada precisamente con la ayuda de ella.

Eso es todo, felicidades! Hemos creado un bot simple que puede determinar qué celebridad es el usuario. Queda por encontrar más fotos, agregar marcas, escalabilidad, una pizca de registro y todo se puede lanzar en producción. Todos estos temas son demasiado voluminosos para hablar en detalle con grandes listas de códigos, por lo que esbozaré los puntos principales en el formato de preguntas y respuestas en la siguiente sección.
El código completo del bot de entrenamiento está disponible en GitHub .
Hablamos de nuestro bot
¿Cuántas celebridades tienes en tu base de datos? ¿Dónde los encontraste?
La decisión más lógica al crear el bot parecía tomar datos de celebridades de nuestra base de contenido interna. Ella, en el formato del gráfico, almacena películas y todas las entidades asociadas con películas, incluidos actores y directores. Para cada persona, conocemos su nombre, nombre de usuario y contraseña de iCloud, películas relacionadas y alias, que se pueden utilizar para generar enlaces al sitio. Después de limpiar y extraer solo la información necesaria, el archivo json permanece de la siguiente manera:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
Había 22,000 entradas de este tipo en el catálogo. Por cierto, no un catálogo, sino un catálogo.
¿Dónde encontrar fotos para todas estas personas?

Bueno, ya sabes, aquí y allá . Hay, por ejemplo, una biblioteca maravillosa que te permite subir resultados de consultas de imágenes desde Google. 22 mil personas, no tantas, con 56 transmisiones que logramos descargar fotos para ellos en menos de una hora.
Entre las fotos descargadas, debe descartar fotos rotas y ruidosas en el formato incorrecto. Luego, deje solo aquellos donde hay caras y donde estas caras satisfacen ciertas condiciones: la distancia mínima entre los ojos, la inclinación de la cabeza. Todo esto nos deja con 12,000 fotos.
De los 12 mil famosos, los usuarios han encontrado solo 2 en este momento, es decir, hay aproximadamente 8 mil famosos que todavía no son como nadie. ¡No lo dejes así! Abre telegramas y encuéntralos a todos.
¿Cómo determinar el porcentaje de similitud para la distancia euclidiana?
Gran pregunta! De hecho, la distancia euclidiana, en contraste con el coseno, no está limitada anteriormente. Por lo tanto, surge una pregunta razonable, ¿cómo mostrarle al usuario algo más significativo que "Felicitaciones, la distancia entre su incrustación y la incrustación de Angelina Jolie es 0.27635462738"? Uno de los miembros de nuestro equipo propuso la siguiente solución simple e ingeniosa. Si construye la distribución de distancias entre las incrustaciones, será normal. Entonces, para él, puede calcular el promedio y la desviación estándar, y luego, para cada usuario, de acuerdo con estos parámetros, considere cuánto porcentaje de personas se parecen menos a sus celebridades que él . Esto es equivalente a integrar una función de densidad de probabilidad de d a más infinito, donde d es la distancia entre el usuario y las manifestaciones de celebridades.
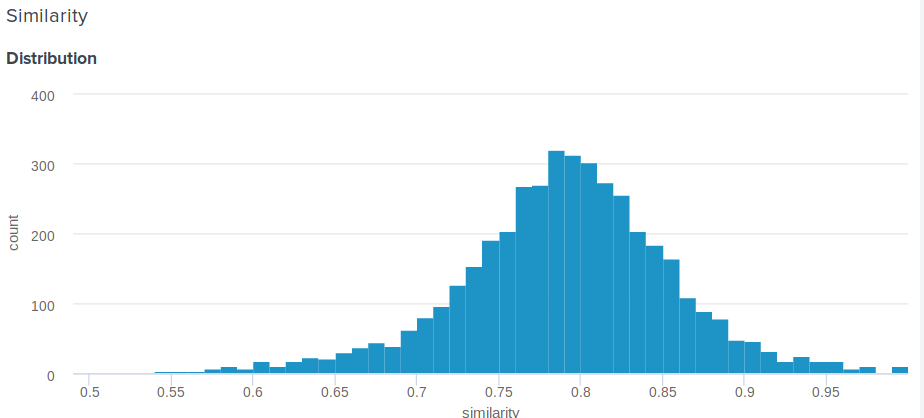
Aquí está la función exacta que usamos:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
¿Es realmente necesario iterar sobre la lista de todos los sindicatos para encontrar una coincidencia?
Por supuesto que no, esto no es óptimo y lleva mucho tiempo. La forma más fácil de optimizar los cálculos es usar operaciones matriciales. En lugar de restar vectores entre sí, puede componer una matriz de ellos y restar un vector de la matriz, y luego calcular la norma L2 en filas.
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
Esto ya da un gran aumento en la productividad, pero resulta que puedes hacerlo aún más rápido. La búsqueda puede acelerarse significativamente al perder un poco su precisión utilizando la biblioteca nmslib . Utiliza el método HNSW para aproximar la búsqueda de k vecinos más cercanos. Para todos los vectores disponibles, se debe construir un denominado índice, en el que luego se realizará una búsqueda. Puede crear y guardar el índice para la distancia euclidiana de la siguiente manera:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
Los parámetros M y efConstruction se describen en detalle en la documentación y se seleccionan experimentalmente según la precisión requerida, el tiempo de construcción del índice y la velocidad de búsqueda. Antes de usar el índice, debe descargar:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
El parámetro efSearch afecta la precisión y la velocidad de las consultas y puede no coincidir con la efConstruction . Ahora puedes hacer solicitudes.
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
En nuestro caso, nmslib es 20 veces más rápido que la versión lineal vectorizada, y una solicitud se procesa en promedio 0.005 segundos.
¿Cómo preparar mi bot para la producción?
1. Asincronía
Primero, debe hacer que la función handle_photo asíncrona. Como ya dije, python-telegram-bot ofrece multihilo para esto e implementa un decorador conveniente.
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
Ahora, el marco en sí lanzará su controlador en un hilo separado en su grupo. El tamaño del grupo se establece al crear el Updater . "¡Pero en Python no hay multihilo!" el más impaciente de ustedes ya ha exclamado. Y esto no es del todo cierto. Debido a GIL, el código Python normal realmente no se puede ejecutar en paralelo, pero GIL se libera para esperar todas las operaciones de E / S, y también puede ser liberado por bibliotecas que usan extensiones C.
Ahora analice nuestra función handle_photo : solo consiste en esperar las operaciones de E / S (cargar una foto, enviar una respuesta, leer una foto desde el disco, etc.) y llamar a funciones desde las numpy , nmslib y Pillow .
No mencioné dlib por una razón. No es necesario que la biblioteca que llama al código nativo libere el GIL y dlib bien. Ella no necesita esta cerradura, simplemente no la deja ir. El autor dice que con mucho gusto aceptará la solicitud de extracción apropiada, pero soy demasiado vago.
2. Multiprocesamiento
La forma más fácil de lidiar con dlib es encapsular el modelo en una entidad separada y ejecutarlo en un proceso separado. Y mejor en el grupo de procesos.
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3. hierro
Si su bot necesita leer constantemente fotos de un disco, asegúrese de que el disco sea un SSD. O incluso montarlos en la RAM. Hacer ping a los servidores de telegramas y la calidad del canal también es importante.
4. Control de inundaciones
Los telegramas no permiten que los bots envíen más de 30 mensajes por segundo. Si su bot es popular y mucha gente lo usa al mismo tiempo, entonces es muy fácil obtener una prohibición por unos segundos, lo que resultará decepcionante para la expectativa de muchos usuarios. Para resolver este problema, python-telegram-bot nos ofrece una cola que no puede enviar más del límite de mensaje especificado por segundo, manteniendo intervalos iguales entre envíos.
from telegram.ext.messagequeue import MessageQueue
Para usarlo, debe definir su propio bot y reemplazarlo al crear Updater .
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5. Ganchos web
En un entorno de producto, Web Hooks siempre debe usarse en lugar de Long Polling como una forma de recibir actualizaciones de los servidores de Telegram. De qué se trata y cómo usarlo se puede leer aquí .
6. Trivia
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
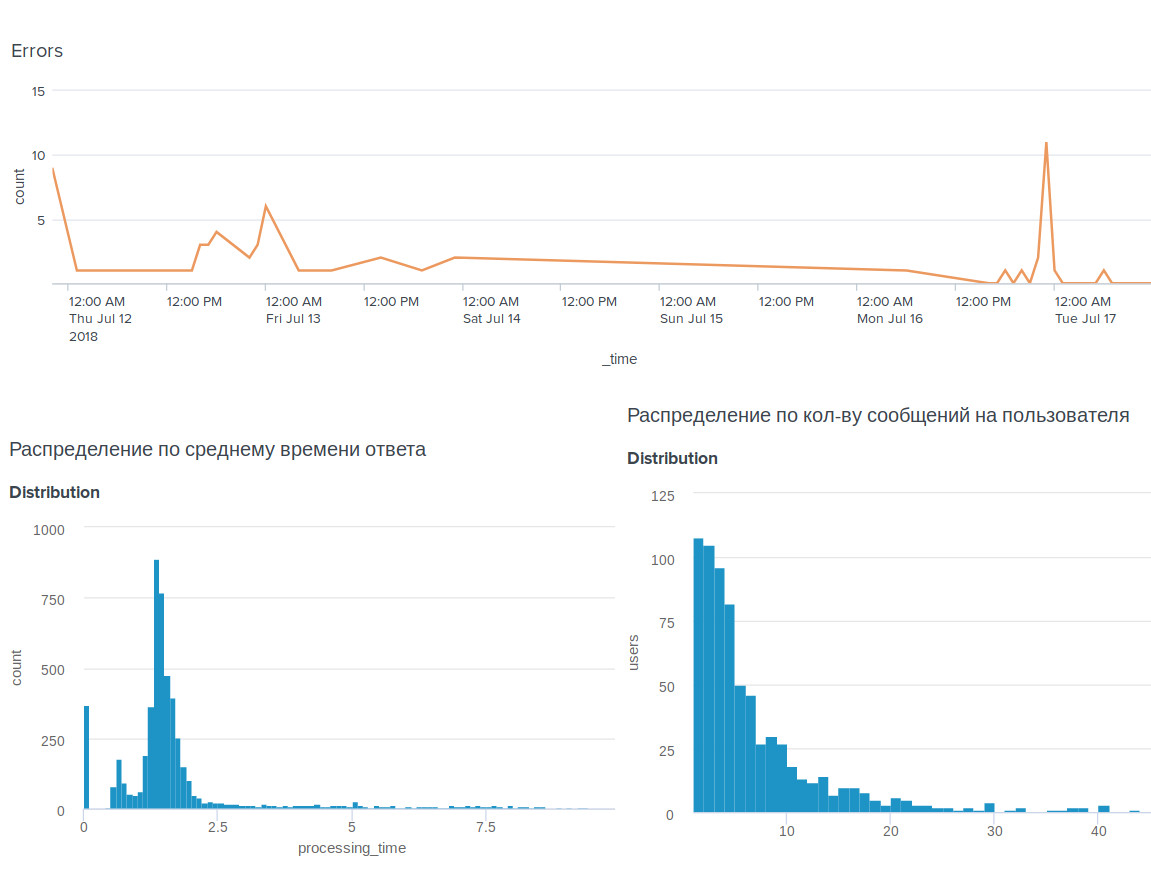
, . , .
, . , : @OkkoFaceBot .