Desafortunadamente, no vivimos en un mundo ideal donde cada desarrollador tenga un nivel ideal y equilibrado de productividad, mientras nos enfocamos en las tareas y las analizamos de una a otra. La colaboración en equipo tampoco siempre está diseñada para que todos los miembros del equipo trabajen con la máxima eficiencia. Al igual que con muchos problemas en general, el desarrollo temprano en el equipo de desarrollo ahorra recursos, nervios de gestión y crea un buen ambiente de trabajo.
En un equipo pequeño, el líder del equipo puede tratar de juzgar todo lo que sucede sobre la base de sentimientos subjetivos, pero cuanto más grande sea la empresa, más importante es utilizar datos objetivos y métricas.
Alexander Kiselev (
AleksandrKiselev ) y
Sergey Semenov en su informe sobre
TeamLead Conf mostraron cómo usar los datos que ya ha acumulado, dónde obtener datos adicionales, y que juntos pueden ayudar a identificar problemas no obvios. E incluso, habiendo acumulado la experiencia de muchos colegas, propusieron soluciones.
Sobre los oradores: Alexander Kiselev y Sergey Semenov, hemos estado en TI durante más de 8 años. Ambos pasaron de desarrollador a líder de equipo y luego a gerente de producto. Ahora están trabajando en el servicio analítico GitLean, que recopila automáticamente análisis de equipos de desarrollo para líderes de equipo y CTO. El objetivo de este servicio es que los gerentes técnicos puedan tomar sus decisiones basándose en datos objetivos.
Planteamiento del problema
Ambos trabajamos como líderes de equipo y, a menudo, enfrentamos el problema de la incertidumbre y la ambigüedad en nuestro trabajo.

Como resultado, a menudo era necesario tomar decisiones a ciegas, y a veces no estaba claro si era mejor o peor. Por lo tanto, analizamos las soluciones existentes en el mercado, examinamos las metodologías para evaluar el rendimiento de los desarrolladores y nos dimos cuenta de que no había ningún servicio que satisficiera nuestras necesidades. Por
lo tanto,
decidimos crearlo nosotros mismos .
Hoy hablaremos sobre lo que puede decirle a los datos que ya ha acumulado, pero que probablemente no los use.

Esto es necesario en dos casos principales.
La evaluación del desempeño es un proceso bastante complejo y subjetivo. Sería genial recopilar datos sobre el trabajo del desarrollador automáticamente.
Hablamos con representantes de una gran empresa alemana con un gran personal de desarrollo. Aproximadamente una vez al año, detuvieron todo el trabajo de desarrollo durante 2 semanas, y solo hicieron que toda la empresa realizara una evaluación de rendimiento: los desarrolladores escribieron denuncias anónimas todo el día para los colegas con quienes trabajaron durante un año. Si esta empresa tuviera la oportunidad de recopilar datos automáticamente, se ahorrarían un montón de tiempo.
El segundo aspecto es
monitorear la situación actual en el equipo. Quiero comprender rápidamente los problemas que surgen y responderlos rápidamente.
Opciones de decisión
Puede haber varias soluciones.

Primero, no puede
usar ningún análisis en absoluto , sino solo su evaluación subjetiva. Esto funciona si eres un líder de equipo en un equipo pequeño. Pero si ya es CTO y tiene muchos equipos, entonces no podrá usar su evaluación subjetiva, porque no lo sabe todo. Tendrá que recurrir a una evaluación subjetiva de sus timidos, y esto es un problema, ya que con frecuencia los timidos abordan la evaluación subjetiva de manera muy diferente.

Esto es lo siguiente que hay que hacer. Dado que la evaluación subjetiva a menudo no es suficiente, puede confundirse y
recopilar datos a mano .
Por ejemplo, un CTO con el que hablamos de alguna manera sospechaba que el equipo estaba haciendo una revisión de código demasiado lento, pero no había nada para presentarlos. Como solo tenía un vago sentimiento, decidió recopilar los hechos, solo un par de semanas para observar al equipo. CTO registró el tiempo que le tomó al equipo revisar, y lo que descubrió al final lo sorprendió. Resultó que 2 personas mayores habían estado en conflicto durante mucho tiempo en la revisión del código, mientras que no lo eliminaron en absoluto. Se sentaron como ratones, nadie le gritó a nadie: el equipo no estaba al tanto. Lo único que hicieron fue ir periódicamente al refrigerador, verterse un poco más de agua y correr para escribir respuestas ingeniosas en una revisión de código a su enemigo en solicitud de extracción.
Cuando CTO se enteró, resultó que el problema era tan antiguo que era imposible hacer algo, y al final uno de los programadores tuvo que ser despedido.
 Las estadísticas de Jira
Las estadísticas de Jira son una opción que a menudo se usa. Esta es una herramienta muy útil en la que hay información sobre las tareas, pero es de alto nivel. A menudo es difícil entender lo que sucede en un equipo específicamente.
Un ejemplo simple: el desarrollador del sprint anterior realizó 5 tareas, esta: 10. ¿Es posible decir que comenzó a trabajar mejor? Es imposible, porque las tareas son completamente diferentes.

La última solución que existe es simplemente arremangarse y escribir
su propio script para la recopilación automática de datos . Esta es la forma en que todos los CTO de las grandes empresas acuden más o menos. Es el más productivo, pero, por supuesto, el más difícil. De él hablaremos hoy.
Solución seleccionada
Entonces, la solución elegida es cortar sus scripts para recopilar análisis. Las preguntas principales son dónde obtener datos y qué medir.
Fuentes de datos
Las principales fuentes de datos en las que se acumula información sobre el trabajo del desarrollador son:
- Git : las entidades principales: confirmaciones, ramas y código dentro de ellas.
- Herramientas de revisión de código : los servicios de alojamiento de git que alojan revisiones de código contienen información sobre la solicitud de extracción que se puede utilizar.
- Rastreadores de tareas : información sobre tareas y su ciclo de vida.
Fuentes de datos auxiliares:
- Mensajeros : allí puede, por ejemplo, realizar análisis de sentimientos, calcular el tiempo de respuesta promedio del desarrollador a una solicitud de información.
- Servicios de CI que almacenan información sobre compilaciones y lanzamientos.
- Encuestas de equipo.
Como todas las fuentes de las que hablé anteriormente son más o menos estándar, y la última no es tan estándar, hablaré un poco más sobre ello.
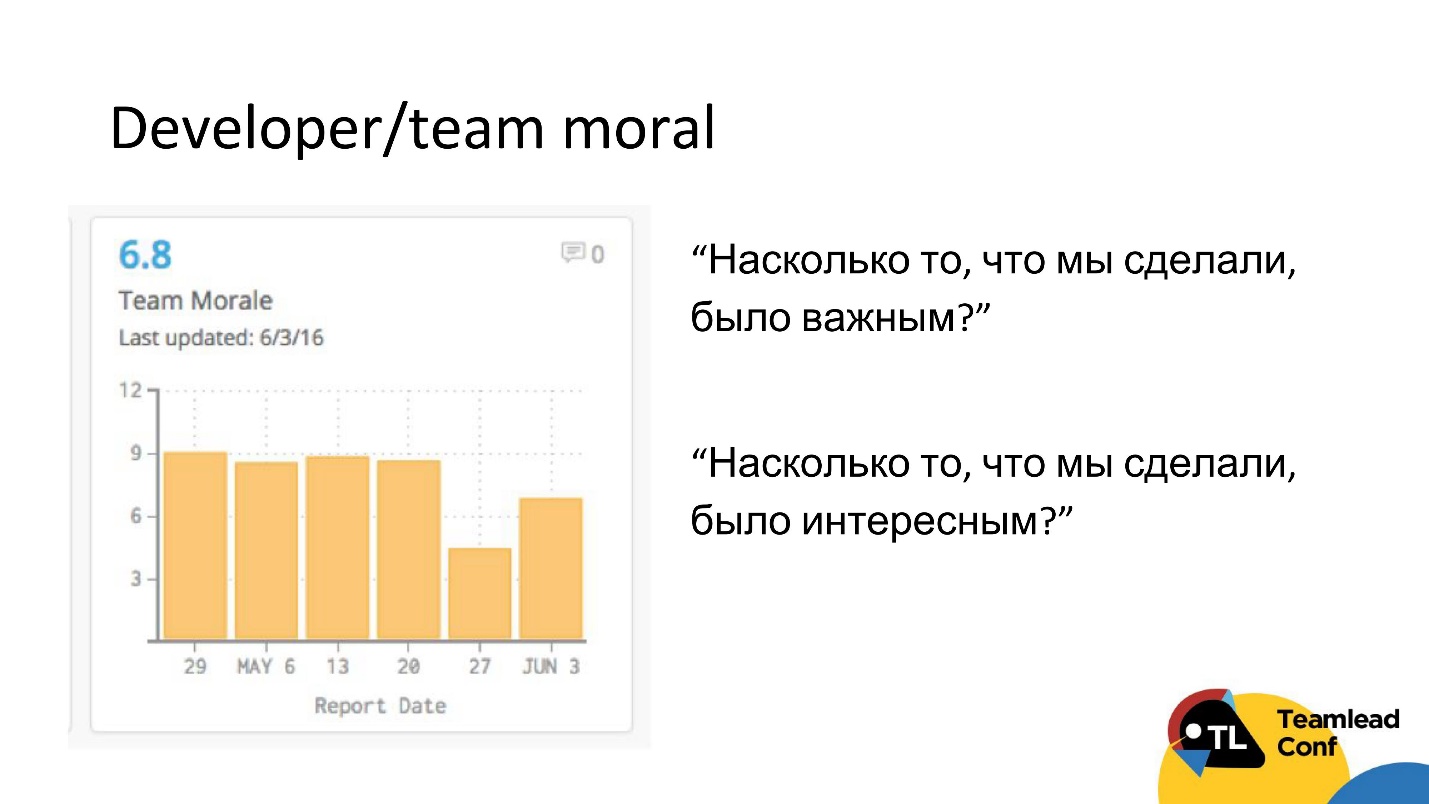
Otro CTO compartió este método con nosotros. Al final de cada iteración, enviaba al equipo una encuesta automáticamente, en la que solo había 2 preguntas:
- En su opinión, ¿qué tan importante fue lo que hicimos en esta iteración?
- ¿Crees que lo que estamos haciendo fue interesante?
Esta es una forma bastante barata de medir el estado de ánimo en un equipo y, tal vez, detectar algunos problemas con la motivación.
Qué y cómo medir
En primer lugar, discutiremos la metodología de medición. Una buena métrica debe responder 3 preguntas:
- ¿Es importante? Solo es necesario medir qué señales acerca de algo significativo para la empresa.
- ¿Ha empeorado / mejorado / igual? Por métrica, debe quedar claro si ha mejorado o empeorado.
- Que hacer Desde la métrica, debe quedar claro qué hacer para rectificar la situación.
En general, vale la pena seguir el principio:
Mide lo que quieres y puedes cambiar.
Vale la pena mencionar de inmediato que no existe una métrica universal, y hoy no hablaremos de una métrica universal por las siguientes razones:
- El desarrollador tiene muchos aspectos de la actividad : trabaja con requisitos, escribe código, prueba, realiza revisiones de código, realiza implementaciones, y es imposible poner todo esto en una única métrica universal. Por lo tanto, es mejor centrarse en casos individuales que se pueden detectar.
- La segunda razón por la que no vale la pena hacer la única métrica es que una métrica es fácil de manejar, porque los desarrolladores son personas lo suficientemente inteligentes y descubrirán cómo hacerlo solo.

Nuevo enfoque
Por lo tanto, hemos formulado un enfoque en el que pasamos de los problemas: tratamos de identificar problemas específicos y seleccionar un conjunto de métricas para detectarlos. Un buen desarrollador se llamará desarrollador con el menor número de problemas.

¿En qué se basa nuestra elección de problemas? Es simple: realizamos una entrevista con 37 CTO y líderes de equipo que hablaron sobre los problemas que tienen en sus equipos y cómo resuelven estos problemas.
En la enorme lista resultante, priorizamos y recopilamos trucos de vida y métricas para estos problemas. Dividimos todos los problemas en 2 grupos:
- Problemas de un desarrollador individual (el desarrollador es responsable de estos problemas).

- Problemas de equipo El equipo es responsable de estos problemas; en consecuencia, para resolverlos, debe trabajar con el equipo en su conjunto y cambiar las soluciones del proceso.

Consideremos en detalle cada problema, qué clave de las métricas se puede seleccionar. Comencemos con los problemas más simples y avancemos lentamente a lo largo del gradiente de complejidad hasta los más difíciles de medir.
Problemas del desarrollador
Desarrollador poco rendimiento

Además, "poco rendimiento" generalmente significa que el
desarrollador no hace casi nada . Condicionalmente, un boleto cuelga de él en Jira, de alguna manera lo informa, pero realmente no está sucediendo ningún trabajo. Está claro que este problema surgirá tarde o temprano, lo encontrará, pero sería genial hacerlo automáticamente.
¿Cómo se puede medir esto?Lo primero que viene a la mente es mirar la
cantidad de días activos con el desarrollador. El día activo se llamará el día en que el desarrollador realizó al menos una confirmación. Para los desarrolladores a tiempo completo, de hecho, el número característico de días activos por semana es de al menos 3. Si es menor, entonces comenzamos a sospechar que el desarrollador no realizará mucho.
Obviamente, solo el número de días activos no es suficiente. Un desarrollador podría simplemente escribir código y no confirmarlo: escribió, escribió y luego un día cometió un montón de código.
Por lo tanto, la siguiente limitación que imponemos es que el desarrollador también debe tener un
pequeño código . ¿Cómo determinar el umbral "pequeño código"? Recomendamos que lo coloque lo suficientemente pequeño como para que cualquiera, tanto como un desarrollador de rendimiento, pueda superarlo fácilmente. Por ejemplo, en nuestro servicio para JS esto es alrededor de 150 líneas de código, y para Clojure - 100 líneas de código.
¿Por qué un umbral tan pequeño? La idea es que queremos separar a los desarrolladores que no trabajan bien de los que trabajan en promedio, sino a aquellos que no hacen casi nada, de aquellos que hacen al menos una cantidad razonable de trabajo.
Pero incluso si el desarrollador tiene pocos días activos y poco código, esto no significa en absoluto que no haya trabajado. Podría, por ejemplo, hacer correcciones de errores que requieren una pequeña cantidad de código. Como resultado, una persona parece haber realizado muchas tareas, pero puede tener pocos códigos y días activos. Es decir, tenemos en cuenta la
cantidad de tareas .
Lo siguiente que vale la pena ver es la
cantidad de revisión de código que hizo, porque una persona no podía hacer tareas y no escribir código, sino estar completamente inmerso en la revisión de código. Sucede
Por lo tanto, para todas estas métricas, ¡y solo así! - el desarrollador no alcanza ningún umbral, puede sospechar que no está funcionando bien.
¿Qué hacer al respecto?En primer lugar, si conoce un motivo legítimo, no necesita hacer nada, por ejemplo, un desarrollador está capacitado o tiene un día libre. Si no conoce la razón legítima, entonces probablemente valga la pena
hablar con una persona. Si no aparece un motivo legítimo, entonces vale la pena monitorearlo más, y si este problema continúa repitiéndose a veces, entonces probablemente valga la pena decir adiós a dicho desarrollador.
Este fue el problema más simple y más provocativo. Pasemos a los más pesados.
Desarrollador recicla

Esta también es una historia común. Si una persona lo procesa, se quema, eventualmente se desmotiva y, como resultado, puede abandonar la empresa. Uno de los gerentes técnicos con los que hablamos contó tal historia. Trabajó para una empresa estadounidense en la que la cultura de las manifestaciones se desarrolló de forma salvaje. Como resultado, todos los desarrolladores, cuando llegaron al trabajo, simplemente hicieron lo que se reunieron, y escribieron el código después de las horas y los fines de semana. Como resultado, la facturación anual de los desarrolladores en la empresa alcanzó el 30%, aunque la norma de la industria es del 6%.
Como resultado, toda la gestión técnica que consta de 30 personas fue despedida de esta oficina. Para no mencionar esto, quiero encontrar este problema a tiempo.
¿Cómo se puede medir esto?De hecho, nada es demasiado complicado: veamos la
cantidad de código que el desarrollador escribe después de las horas. Si esta cantidad de código es condicionalmente comparable o mayor que lo que hace durante las horas de trabajo, entonces el desarrollador lo procesa explícitamente.
Obviamente, los desarrolladores no viven como un solo código. Un problema común es que hay tiempo suficiente para el código, el trabajo principal, pero ya no es para la revisión del código. Como resultado, la revisión del código se traslada a las tardes o fines de semana. Esto se puede rastrear simplemente por el
número de comentarios en la solicitud de extracción después del
horario de atención .
El último desencadenante explícito es una
gran cantidad de tareas paralelas . Existe una limitación razonable de 3-4 tareas para el desarrollador. Puede rastrearlos por git o por Jira, como lo desee. Funciona bastante bien
¿Qué hacer al respecto?Si encuentra un desarrollador de reciclaje, primero debe
verificar su calendario para ver si está sobrecargado de manifestaciones inútiles. Si está sobrecargado, es recomendable reducirlos e idealmente hacer un día de reunión, un día dedicado en el que el desarrollador concentrará la mayoría de sus reuniones más largas para que pueda trabajar normalmente en otros días.
Si esto no funciona, es necesario
redistribuir la carga . Esta es en realidad una pregunta bastante complicada: cómo hacerlo. Hay muchas formas diferentes. No profundizaremos, pero tenga en cuenta el excelente
informe sobre HighLoad 2017 de Anton Potapov, en el que este tema se consideró muy de cerca.
El desarrollador no se enfoca en la liberación de tareas
Quiero entender cuántos desarrolladores de este tipo hay en su equipo y cuánto cuesta a tiempo.

Es una situación bastante común que un desarrollador asuma una tarea, la lleve al estado de revisión, prueba y se olvide de ella. Luego regresa para su revisión y se queda allí sin saber cuánto tiempo. Yo mismo tuve un desarrollador en mi equipo al mismo tiempo. Subestimé el problema durante mucho tiempo, hasta que una vez calculé la cantidad de tiempo que, en promedio, ocupa varios tiempos de inactividad. Como resultado, resultó que las tareas de este desarrollador, en promedio, permanecieron inactivas el 60% del tiempo de lanzamiento.
¿Cómo se puede medir esto?Primero, debe medir todo el tiempo de inactividad que depende del desarrollador. Este es el momento de la reparación
después de la revisión y prueba del código . Si tiene una entrega continua, este es
el tiempo de espera de lanzamiento. Se debe imponer una restricción razonable en cada uno de estos momentos, como no más de un día.
La razón es la siguiente. Cuando un desarrollador viene a trabajar por la mañana, sería genial para él analizar primero las tareas de mayor prioridad. Las tareas de mayor prioridad, si no hay correcciones de errores o algo muy importante, son las tareas que están más cerca de liberar y liberar.
Otro desencadenante interesante sobre este tema es la
cantidad de revisión de código que depende del desarrollador, como en un revisor. Si una persona se olvida de sus tareas, lo más probable es que también se relacione con las tareas de sus colegas.
¿Qué hacer al respecto?Si encuentra un desarrollador así, claramente vale la pena acercarse a él y
decirle : "¡Mira, es el 30-40% de tu tiempo dedicado al tiempo de inactividad!" Esto generalmente funciona muy bien. En mi caso, por ejemplo, tuvo tal efecto, que el problema se ha ido casi por completo, de lo contrario, debe continuar
monitoreando , digamos periódicamente, pero lo principal aquí es no caer en la microgestión, porque será aún peor.
Por lo tanto, siempre que sea posible, vale la pena tratar de inmediato con las soluciones de proceso. Esto puede ser, por ejemplo,
límites en el número de tareas activas o, si su presupuesto y tiempo lo permiten, puede escribir un bot o utilizar un servicio que automáticamente hará
ping al desarrollador si la tarea ha estado en un estado determinado durante demasiado tiempo. Esta es probablemente la mejor solución aquí.
El desarrollador no piensa en suficientes tareas
Creo que conoce los síntomas: estas son estimaciones incomprensibles del tiempo necesario para completar las tareas en las que no caemos, los plazos largos al final, el aumento en el número de errores en las tareas, en general, nada bueno.
 ¿Cómo se puede medir esto?
¿Cómo se puede medir esto?Creo que conoce los síntomas: estas son estimaciones incomprensibles del tiempo necesario para completar las tareas en las que no caemos, los plazos largos al final, el aumento en el número de errores en las tareas, en general, nada bueno.
¿Cómo se puede medir esto?Para hacer esto, necesitamos introducir 2 métricas, la primera de las cuales es el código de Churn.

Churn es una medida de la cantidad de código que un desarrollador escribe condicionalmente en vano.
Imagina la situación. El lunes, el desarrollador comenzó a hacer una nueva tarea y escribió 100 líneas de código. Luego vino el martes, escribió otras 100 nuevas líneas de código en esta tarea. Pero, desafortunadamente, sucedió que 50 líneas de código que fueron escritas el lunes, elimina y libera la tarea. Como resultado, parecieron crearse 200 líneas de código en la tarea, pero solo 150 sobrevivieron hasta el lanzamiento, y 50 fueron escritas en vano. A estos 50 los llamamos Churn. Y así, en este ejemplo, el desarrollador Churn fue del 25%.
En nuestra opinión, un
alto nivel de Churn es un desencadenante genial que el desarrollador no pensó en la tarea.
Hay un estudio realizado por una compañía estadounidense en el que midieron el nivel de Churn de 20,000 desarrolladores y llegaron a la conclusión de que un buen código de Churn debería estar en el rango de 10-20%.
Pero hay 2 condiciones importantes:
- High Churn está bien si, por ejemplo, está haciendo un prototipo o algún proyecto nuevo. Entonces puede ser igual al 50-60% durante varios meses. No hay nada de qué preocuparse. , Churn — , .
- Churn — . . - . delivery .

, , , , Fixed Tasks,
. , .
, bug fixes , bug fixes . bug fixes 3 , , . , , , .
—
. , , , - .
?, , ,
. , ,
, estimation ..
CTO, , workflow, , . , , ,
- , .
Churn Fixed Tasks, , :
- commit message, . commit message, , git .
- git-squash commit' , Churn .
- git. merge master, merge , . — , , Churn Fixed Tasks.

, —
, . , , , . , - .
, , - 3-4 . , .
?— - , , .
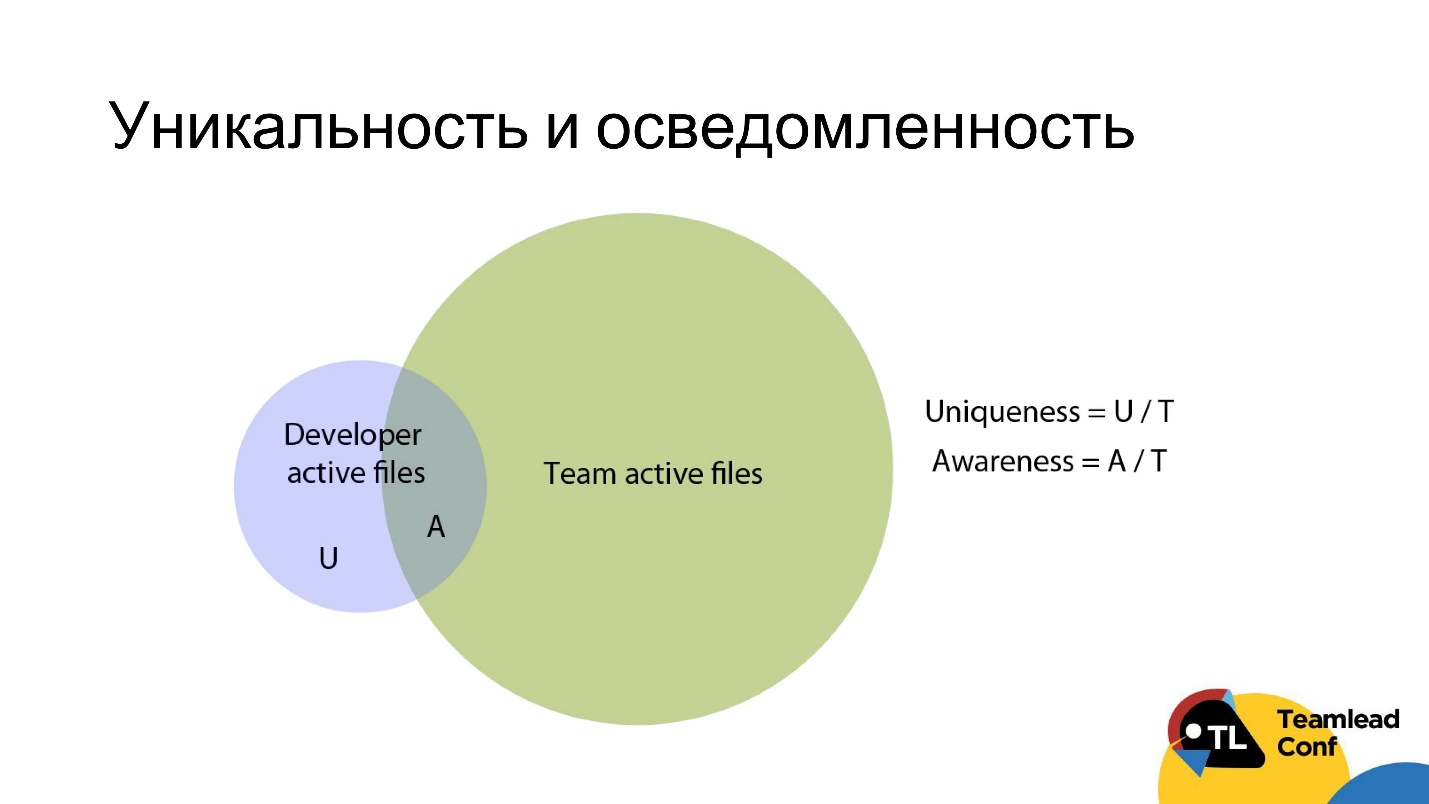
, 3 , , ( ), .
, , . — , .
— ,
— — , , .
?. , , . - , .
— , , . . , , . .
30-50 50-60 %. , .
, , . , , , .
.

, —
. product- , . , , .
?product- , ?
, product- , :
- Churn, ;
- , , estimation;
- in progress product-.
?product- : «, Churn - — ».
« » , 1-2 . , product-, .

. , , .
, , , . , , - , , . , . .
?, , :
?-, , ,
, .
-, , , ,
, , .
— - , . best practise, , , , . 3 , 3 .

, —
. , . - , , -. , , CTO, , 100%. , - .
?,
legacy refactoring . , . . , , , .

,
legacy refactoring , ,
complexity , , .
?, , . , CTO. , .
CTO , , Jira
«» . , - estimation . , — , ..
CTO . , , ,
«Hack». - -, : « Hack — », . grep' «Hack» , .
. .
:
- Algunas cosas aún no son muy fáciles de medir. Esto se aplica, por ejemplo, a Churn o refactorización heredada. Lleva tiempo aprender a contarlos.
- Los datos deben limpiarse y ajustarse ligeramente al comando. Por ejemplo, lo común que encontrará si intenta implementar esto: en git verá que varias cuentas git corresponden a la misma persona. Tendrá que considerar ambos: este es un ejemplo trivial de limpieza de datos que debe hacerse.
- Debe supervisar los valores de umbral y elegirlos sabiamente, porque dependen de la etapa de la vida de la empresa y también del tipo de empresa. Lo que es bueno para un proveedor externo puede no ser muy bueno para una empresa de comestibles.
- La mayoría de las métricas que hemos enumerado aquí funcionan solo para desarrolladores de tiempo múltiple, porque solo las actividades de los desarrolladores de tiempo múltiple se reflejan bien en las fuentes de datos disponibles: git, Jira, GitHub, mensajería instantánea, etc.
Conclusiones
Queríamos transmitirle lo siguiente:
- Los desarrolladores y el equipo pueden y deben ser medidos . Puede ser difícil, pero se puede hacer.
- No existe un pequeño conjunto universal de KPI . Para cada problema, debe seleccionar su conjunto de métricas altamente especializado. Debe recordarse que no debe descuidar ni siquiera las métricas más simples. Juntos pueden funcionar bien.
- Git puede decir muchas cosas interesantes sobre el desarrollo y los desarrolladores, pero debe seguir ciertas prácticas para que se pueda acceder a los datos de manera conveniente, incluyendo:
- número de tareas en commits;
- sin calabaza;
- Puede determinar el tiempo de lanzamiento: fusionar en master, etiquetas.
Enlaces y contactos útiles:- Hay varios problemas de bonificación y métricas para ellos en la presentación de la presentación .
- Blog de autores con artículos útiles para gerentes de desarrollo
- Contactos de Telegram: @avkiselev (Alexander Kiselev) y sss0791 (Sergey Semenov).
En TeamLead Conf, discuten muchos problemas diferentes de administrar un equipo de desarrollo y buscan soluciones. Si ya ha recorrido una parte del camino, llenó más de un bache, pisó un rastrillo, probó diferentes enfoques y está listo para sacar conclusiones y compartir su experiencia, lo estamos esperando. Puede solicitar una presentación hasta el 10 de agosto .
También se espera que los participantes se involucren más, comience por reservar un boleto y luego intente formular lo que más le entusiasma; luego puede hablar sobre su dolor y aprovechar al máximo la conferencia.