Antes de que se ejecute el código escrito por nosotros, es bastante largo.
Andrey Melikhov en su informe sobre RIT ++ 2018 examinó cada paso en este camino utilizando el ejemplo del motor V8. Acérquese al gato para descubrir qué nos da una comprensión profunda de los principios del compilador y cómo hacer que el código JavaScript sea más productivo.

Descubriremos si WASM es una bala de plata para mejorar el rendimiento del código y si las optimizaciones siempre están justificadas.
Spoiler: "La optimización prematura es la raíz de todos los males", Donald Knuth.
 Sobre el orador:
Sobre el orador: Andrei Melikhov trabaja en Yandex.Money, escribe activamente en Node.js y menos en el navegador, por lo que el servidor JavaScript está más cerca de él. Andrew apoya y desarrolla la comunidad devShacht, así que echa un vistazo a
GitHub o
Medium .
Motivación y Glosario
Hoy hablaremos sobre la compilación JIT. Creo que esto es interesante para ti, ya que estás leyendo esto. Sin embargo, aclaremos por qué necesita saber qué es JIT y cómo funciona V8, y por qué escribir React en un navegador no es suficiente.
- Le permite escribir código más eficiente , porque nuestro idioma es específico.
- Revela rompecabezas de por qué en las bibliotecas de otras personas el código se escribe de esta manera, y no de otra manera. A veces nos encontramos con viejas bibliotecas y vemos que lo que está escrito allí es de alguna manera extraño, pero si esto es necesario, no es necesario, no está claro. Cuando sabes cómo funciona, entiendes por qué se hizo esto.
- Esto es simplemente interesante . Además, nos permite entender lo que Axel Rauschmeier, Benedict Moyrer y Dan Abramov comunican en Twitter.
Wikipedia dice que JavaScript es un lenguaje de programación interpretado de alto nivel con escritura dinámica. Nos ocuparemos de estos términos.
Compilación e interpretaciónCompilación: cuando el programa se entrega en código binario y se optimiza inicialmente para el entorno en el que funcionará.
Interpretación: cuando entregamos el código tal como está.
JavaScript se entrega tal como está: es un lenguaje interpretado, tal como está escrito en Wikipedia.
Tipificación dinámica y estáticaLa escritura estática y dinámica a menudo se confunde con la escritura débil y fuerte. Por ejemplo, C es un lenguaje con escritura débil estática. JavaScript tiene una escritura dinámica débil.
Cual es mejor? Si el programa se compila, está orientado hacia el entorno en el que se ejecutará, lo que significa que funcionará mejor. La escritura estática hace que este código sea más eficiente. En JavaScript, lo contrario es cierto.
Pero al mismo tiempo, nuestra aplicación se está volviendo más compleja: tanto en el cliente como en el servidor, aparecen grandes grupos en Node.js, que funcionan bien y reemplazan las aplicaciones Java.
Pero, ¿cómo funciona todo si inicialmente parece ser un perdedor?
¡JIT reconciliará a todos! O al menos inténtalo.
Tenemos un JIT (compilación Just In Time) que ocurre en tiempo de ejecución. Hablaremos de ella.
Motores Js
- Chakra no amado, que se encuentra en Internet Explorer. Ni siquiera funciona con JavaScript, pero con Jscript, existe un subconjunto.
- Chakra moderno y ChakraCore que funcionan en Edge;
- SpiderMonkey en FireFox;
- JavaScriptCore en WebKit. También se usa en React Native. Si tiene una aplicación RN para Android, también se ejecuta en JavaScriptCore: el motor viene incluido con la aplicación.
- V8 es mi favorito. No es el mejor, solo trabajo con Node.js, en el que es el motor principal, como en todos los navegadores basados en Chrome.
- Rhino y Nashorn son los motores utilizados en Java. Con su ayuda, también puede ejecutar JavaScript allí.
- JerryScript: para dispositivos integrados;
- y otros ...
Puede escribir su propio motor, pero si avanza hacia una ejecución efectiva, obtendrá aproximadamente el mismo esquema, que mostraré más adelante.
Hoy hablaremos sobre el V8, y sí, lleva el nombre del motor de 8 cilindros.
Subimos bajo el capó
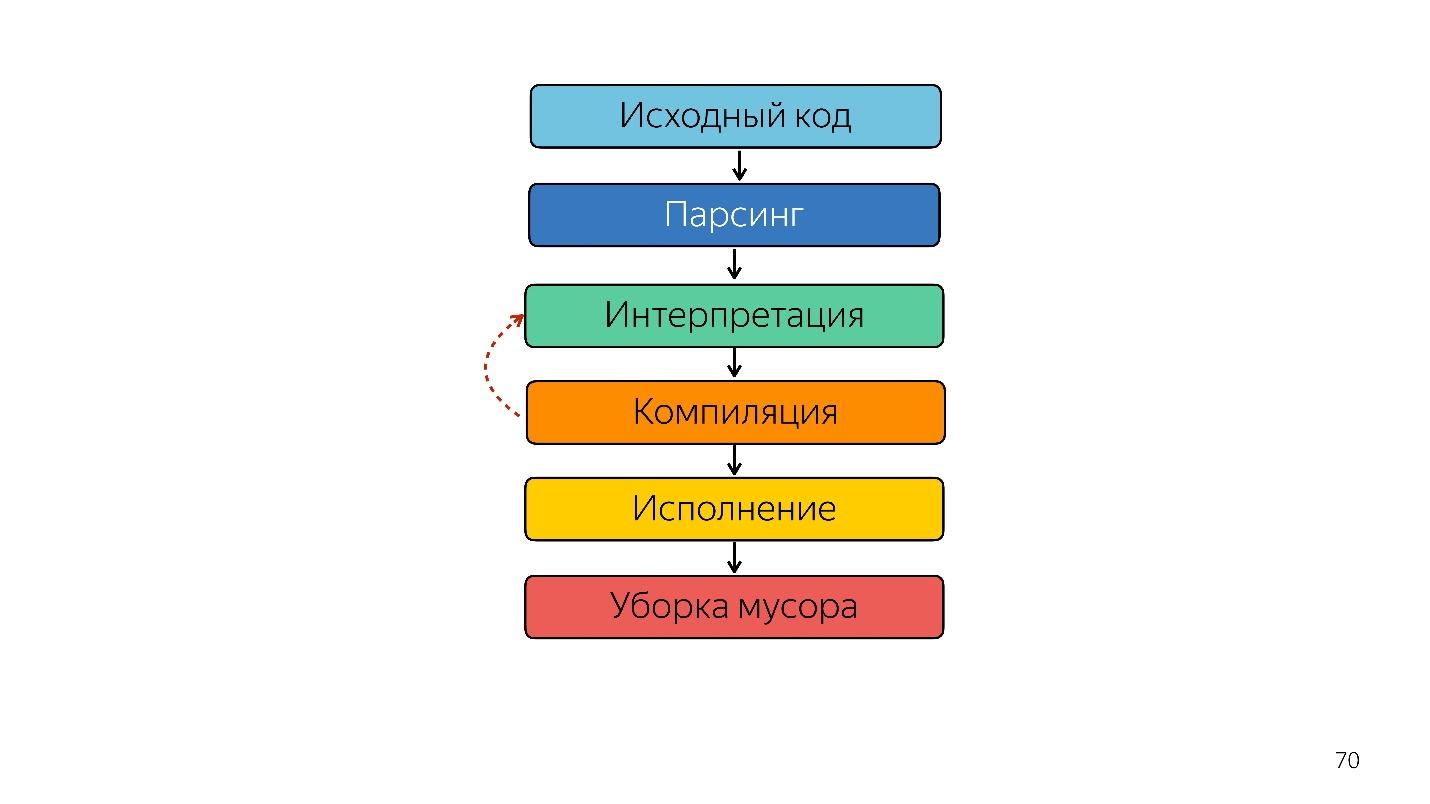
¿Cómo se ejecuta JavaScript?
- Hay un código escrito en JavaScript, que se suministra.
- él está analizando;
- está siendo ejecutado;
- Se obtiene el resultado.
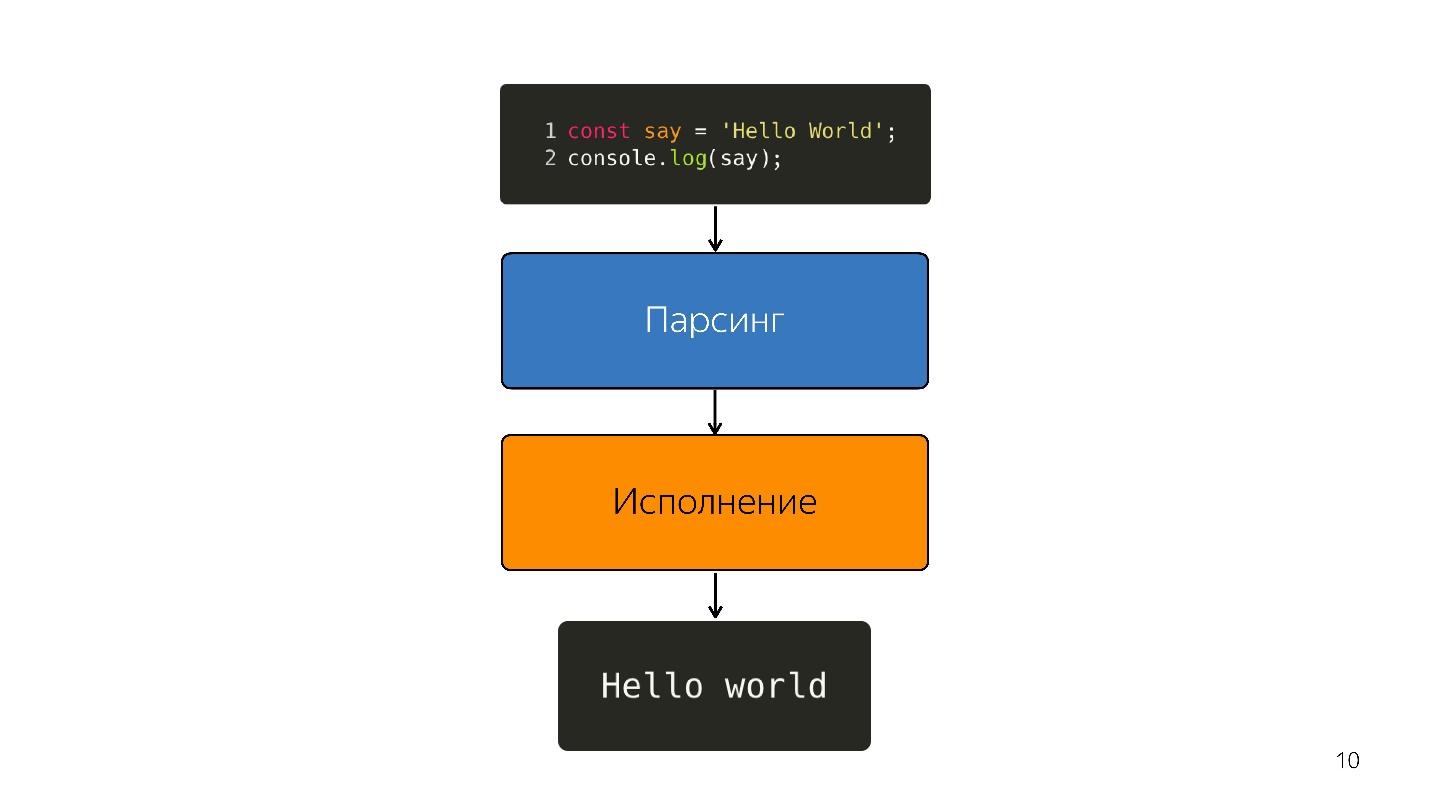
El análisis convierte el código en un
árbol de sintaxis abstracta . AST es una visualización de la estructura sintáctica del código en forma de árbol. Esto es realmente conveniente para el programa, aunque es difícil de leer.
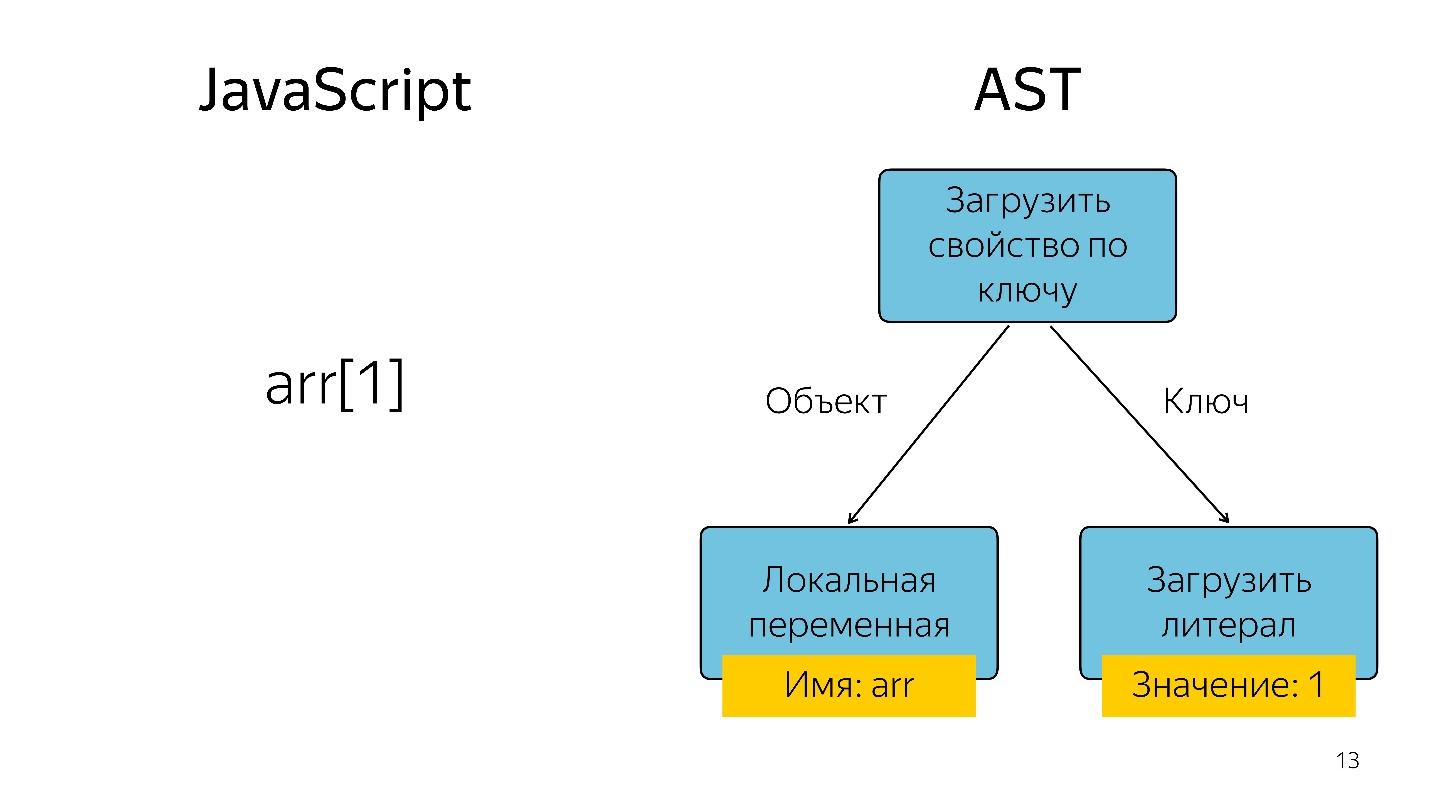
Obtener un elemento de matriz con el índice 1 en forma de árbol se representa como un operador y dos operandos: cargue la propiedad por clave y estas claves.
¿Dónde se usa AST?
AST no es solo en motores. Usando AST, muchas utilidades escriben extensiones, incluyendo:
- ESLint;
- Babel
- Más bonita
- Jscodeshift.
Por ejemplo, lo bueno que Jscodeshift, de lo que no todos saben aún, le permite escribir transformaciones. Si cambia la API de una función, puede establecer estas transformaciones en ella y realizar cambios en todo el proyecto.

Seguimos adelante. El procesador no entiende el árbol de sintaxis abstracta; necesita
código de máquina . Por lo tanto, se lleva a cabo una mayor transformación a través del intérprete, porque el lenguaje se interpreta.
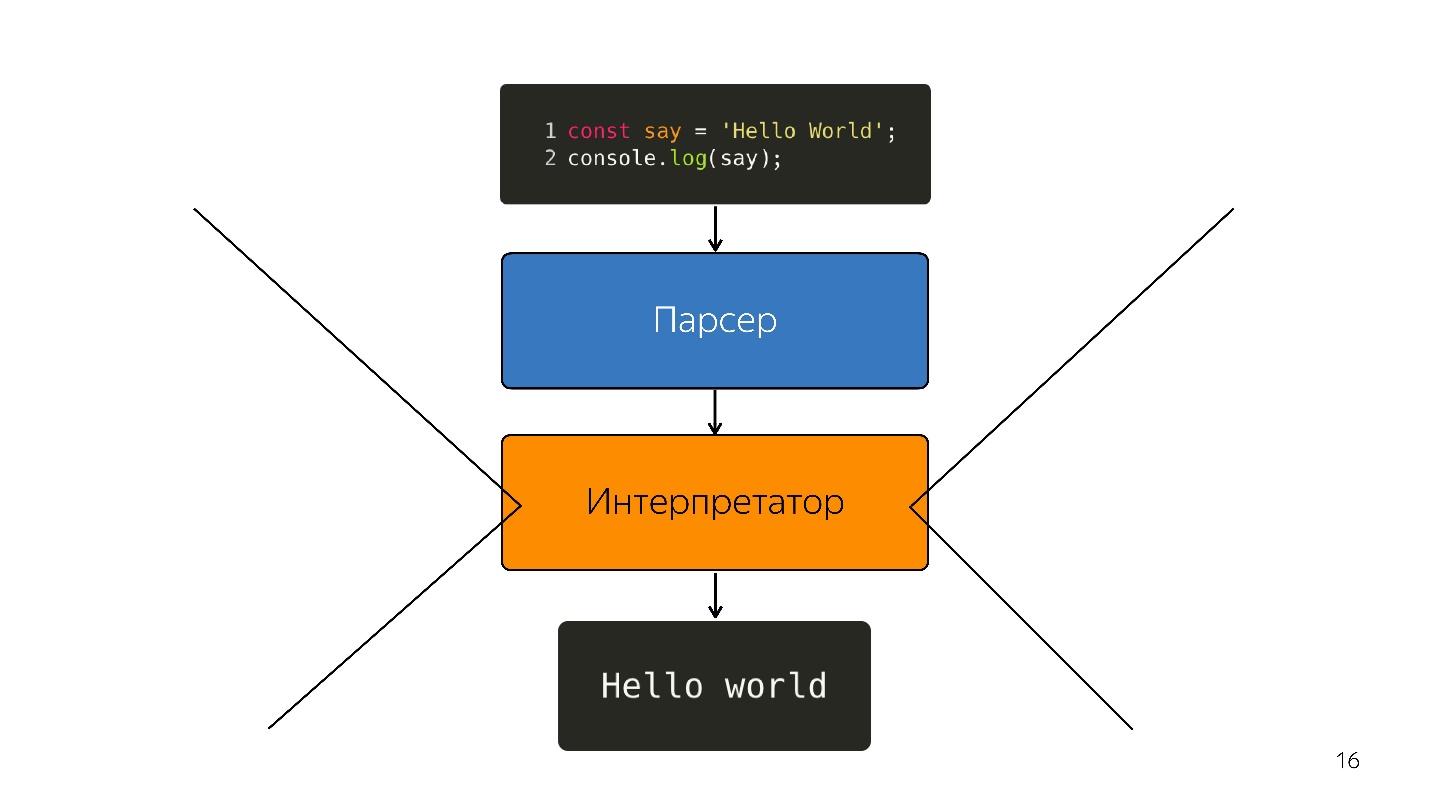
Así fue, mientras que los navegadores tenían un poco de JavaScript: resalta la línea, abre algo, cierra. Pero ahora tenemos aplicaciones: SPA, Node.js, y el
intérprete se está convirtiendo en un cuello de botella .
Optimizando el compilador JIT
En lugar de un intérprete, aparece un compilador JIT optimizador, es decir, un compilador Just-in-time. Los compiladores anticipados funcionan antes de la ejecución de la aplicación y JIT, durante. En el tema de la optimización, el compilador JIT intenta adivinar cómo se ejecutará el código, qué tipos se utilizarán y optimizar el código para que funcione mejor.
Dicha optimización se llama
especulativa , porque especula sobre el conocimiento de lo que sucedió con el código antes. Es decir, si algo con el tipo de número se llamó 10 veces, el compilador piensa que esto sucederá todo el tiempo y se optimiza para este tipo.
Naturalmente, si Boolean entra en la entrada, se produce la desoptimización. Considere una función que agrega números.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Doblado una vez, la segunda vez. El compilador construye la predicción: "¡Son números, tengo una solución genial para sumar números!" Y escribe
foo('WTF', 'JS') y pasa las líneas a la función: tenemos JavaScript, podemos agregar una línea con un número.
En este punto, se produce la desoptimización.
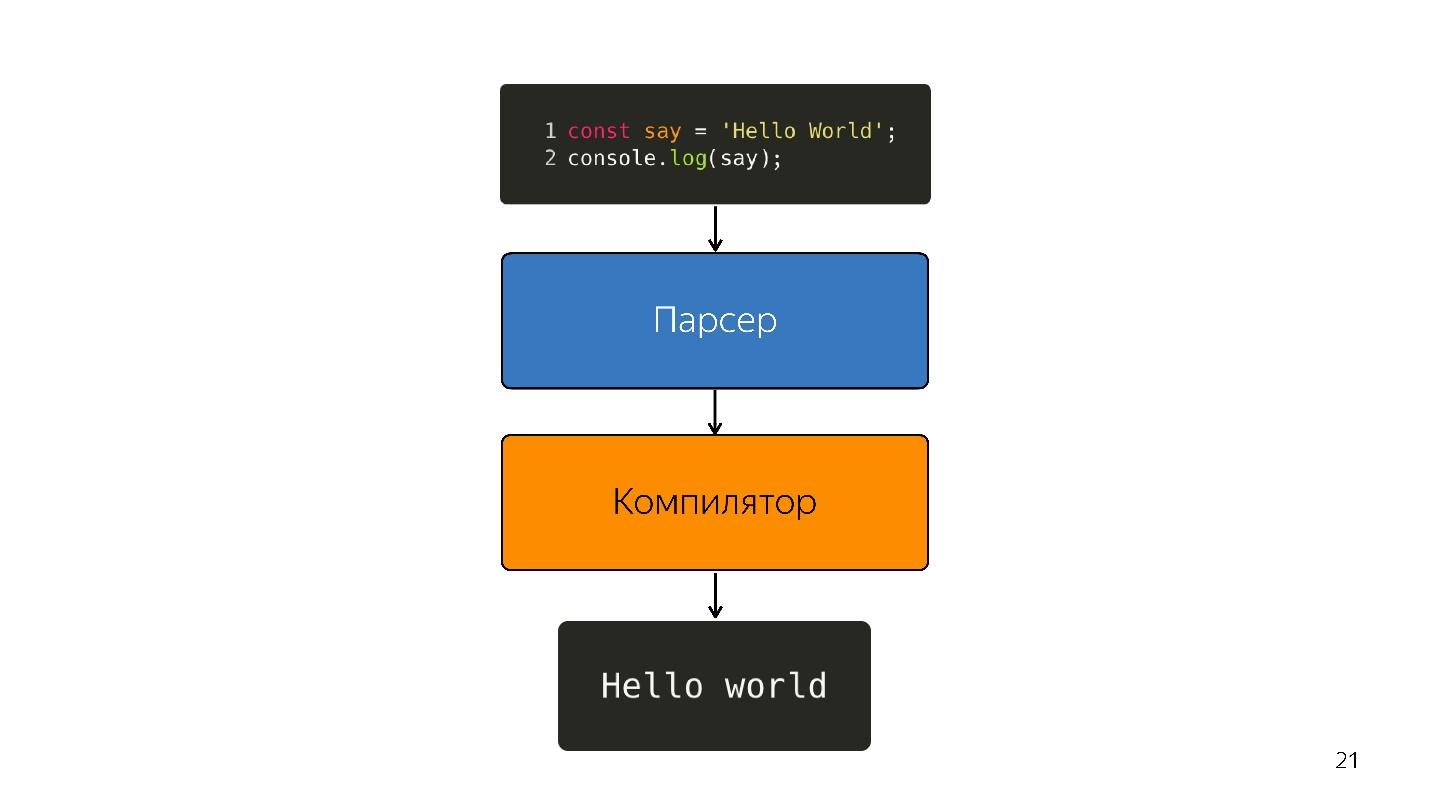
Entonces, el intérprete fue reemplazado por el compilador. El diagrama de arriba parece tener una tubería muy simple. En realidad, todo es un poco diferente.
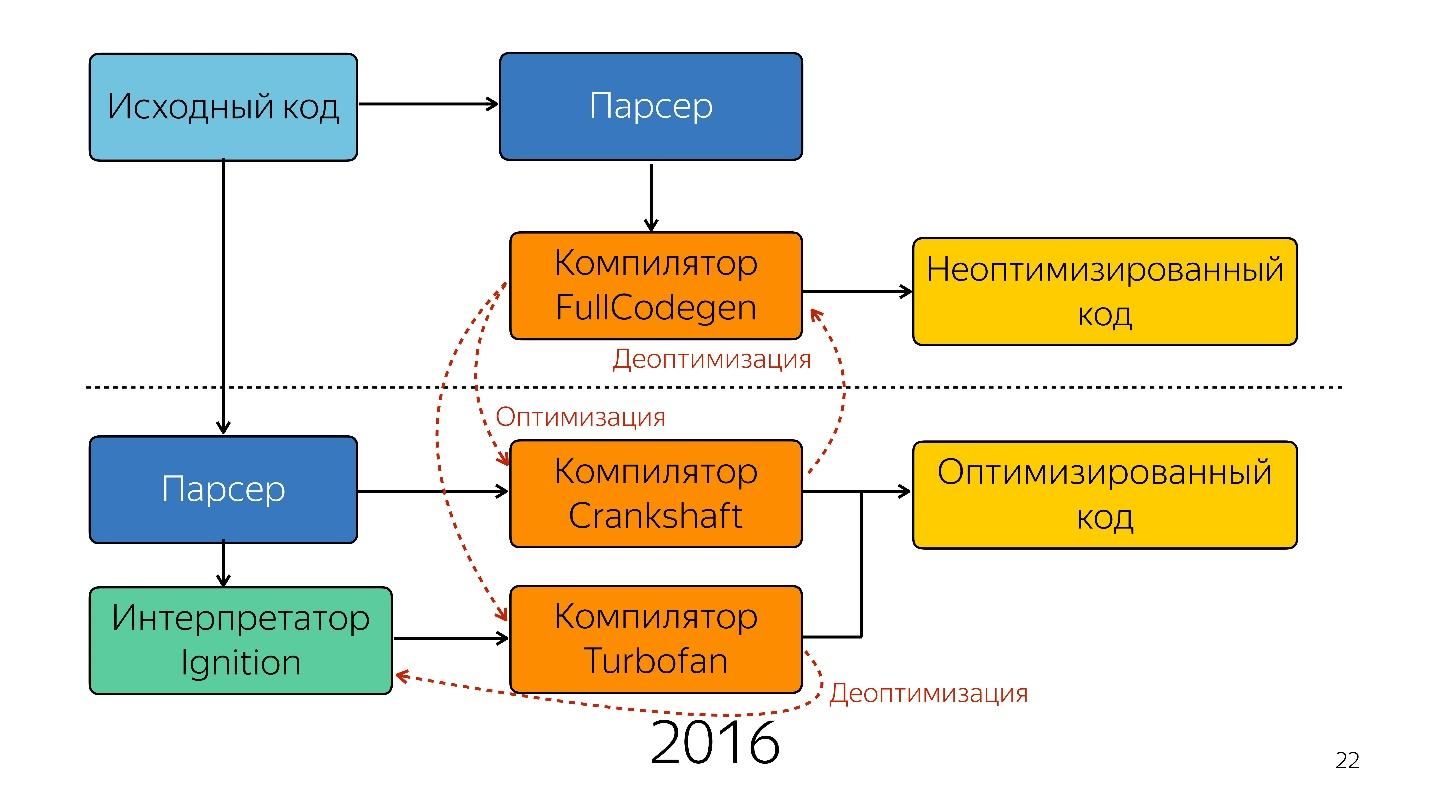
Eso fue hasta el año pasado. El año pasado, se podían escuchar muchos informes de Google de que lanzaron una nueva tubería con TurboFan y ahora el esquema parece más simple.
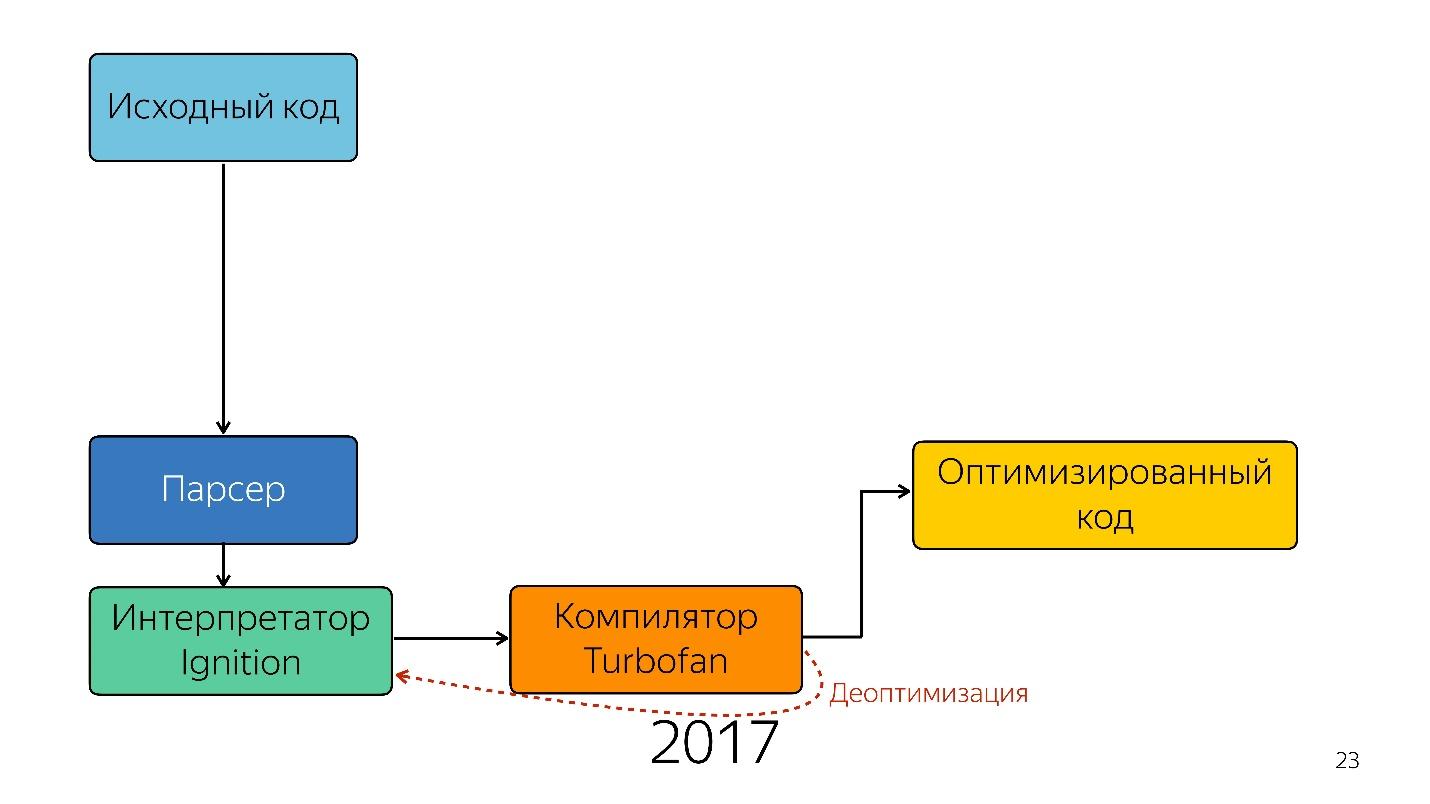
Curiosamente, un intérprete apareció aquí.
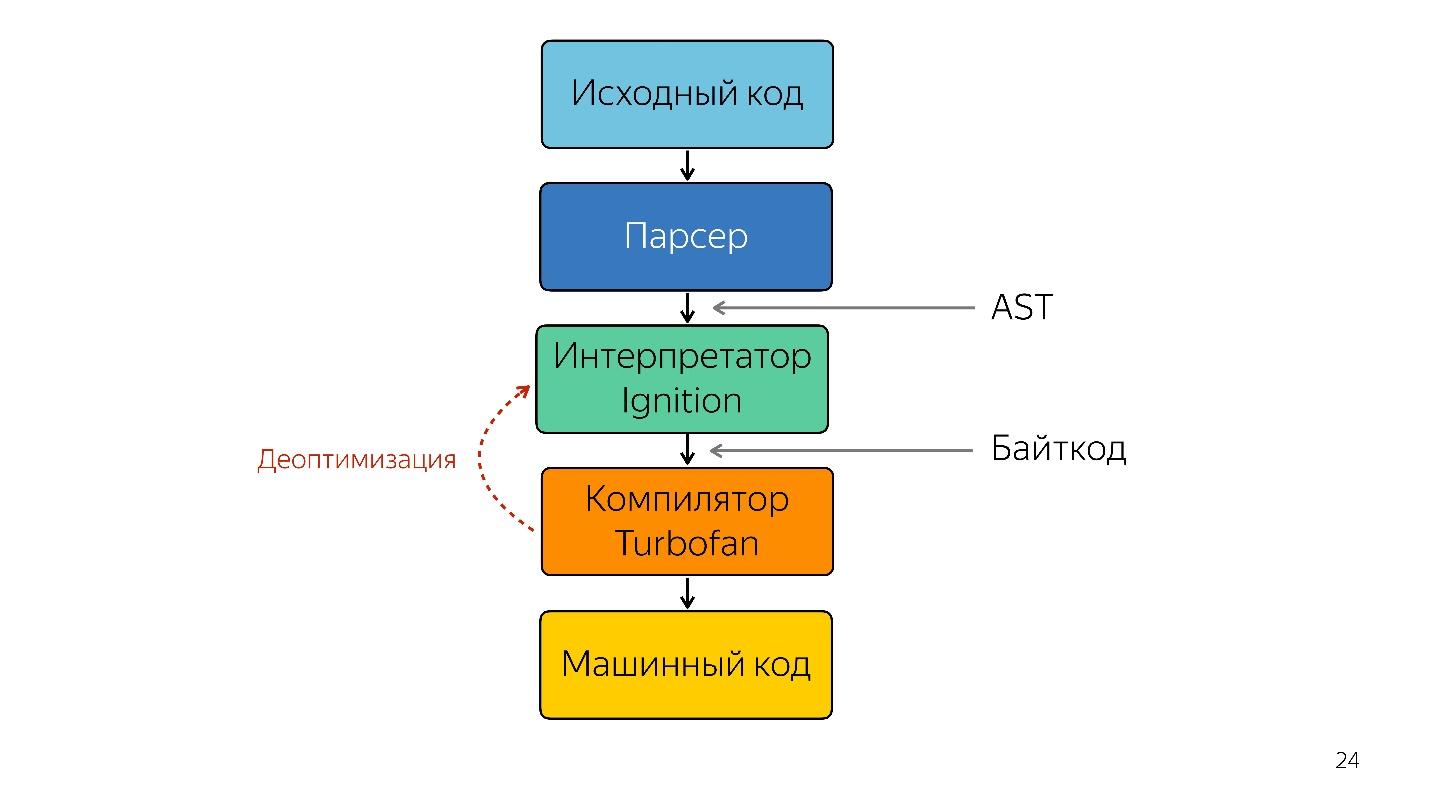
Se necesita un intérprete para convertir un árbol de sintaxis abstracta en un bytecode y pasar el bytecode a un compilador. En el caso de desoptimización, vuelve a acudir al intérprete.
Encendido de intérprete
Anteriormente, no había un esquema de intérprete de encendido. Google dijo inicialmente que no se necesita un intérprete (JavaScript ya es lo suficientemente compacto e interpretable), no ganaremos nada.
Pero el equipo que trabajó con aplicaciones móviles se encontró con el siguiente problema.

En 2013-2014, las personas comenzaron a usar dispositivos móviles para acceder a Internet con más frecuencia que el escritorio. Básicamente, este no es un iPhone, sino de dispositivos más simples: tienen poca memoria y un procesador débil.
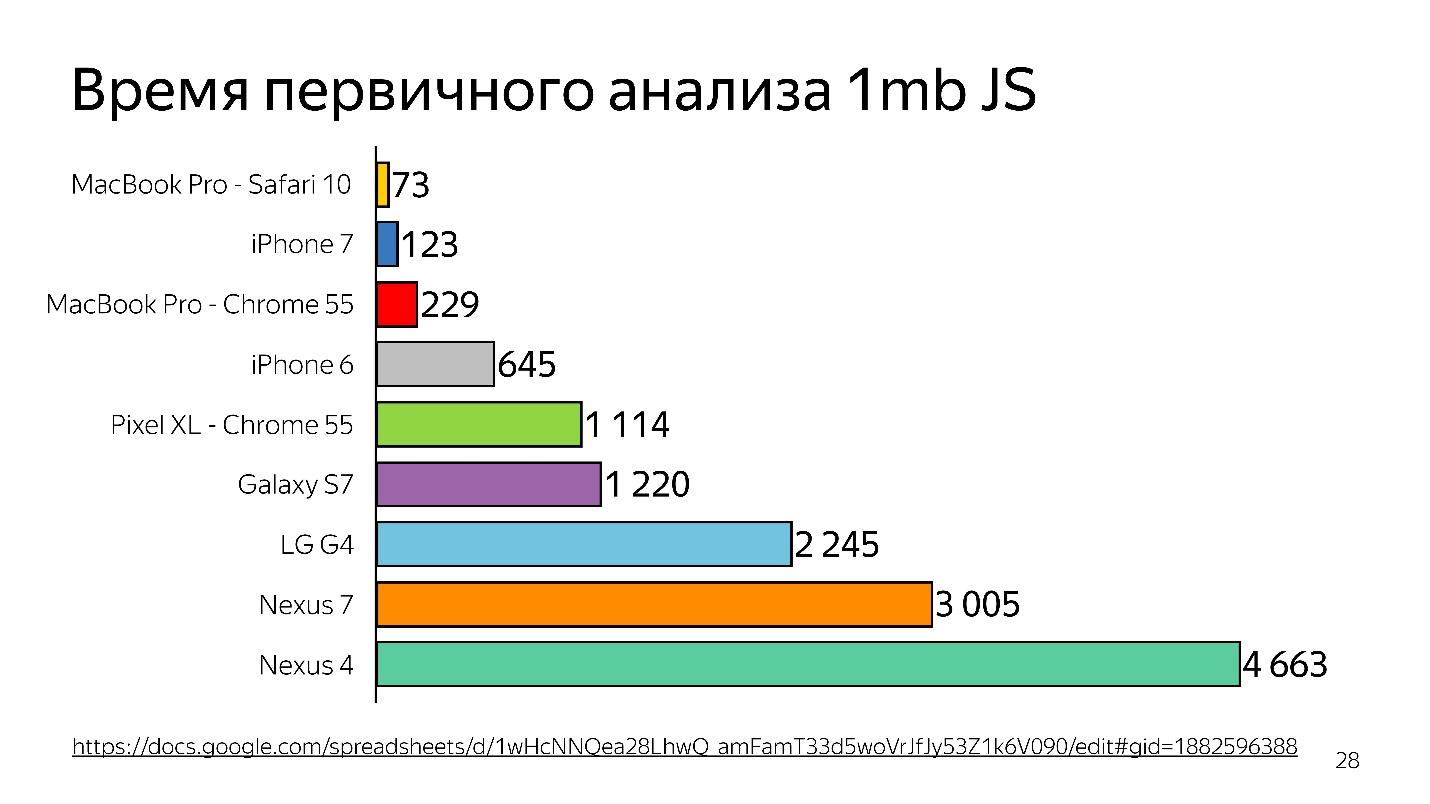
Arriba hay un gráfico del análisis inicial de 1 MB de código antes de iniciar el intérprete. Se puede ver que el escritorio gana mucho. El iPhone tampoco está mal, pero tiene un motor diferente, y estamos hablando de V8, que funciona en Chrome.
¿Sabía que si instala Chrome en el iPhone, seguirá funcionando en JavaScriptCore?
Por lo tanto, se pierde tiempo, y esto es solo análisis, no ejecución, su archivo se ha cargado y está tratando de entender lo que está escrito en él.
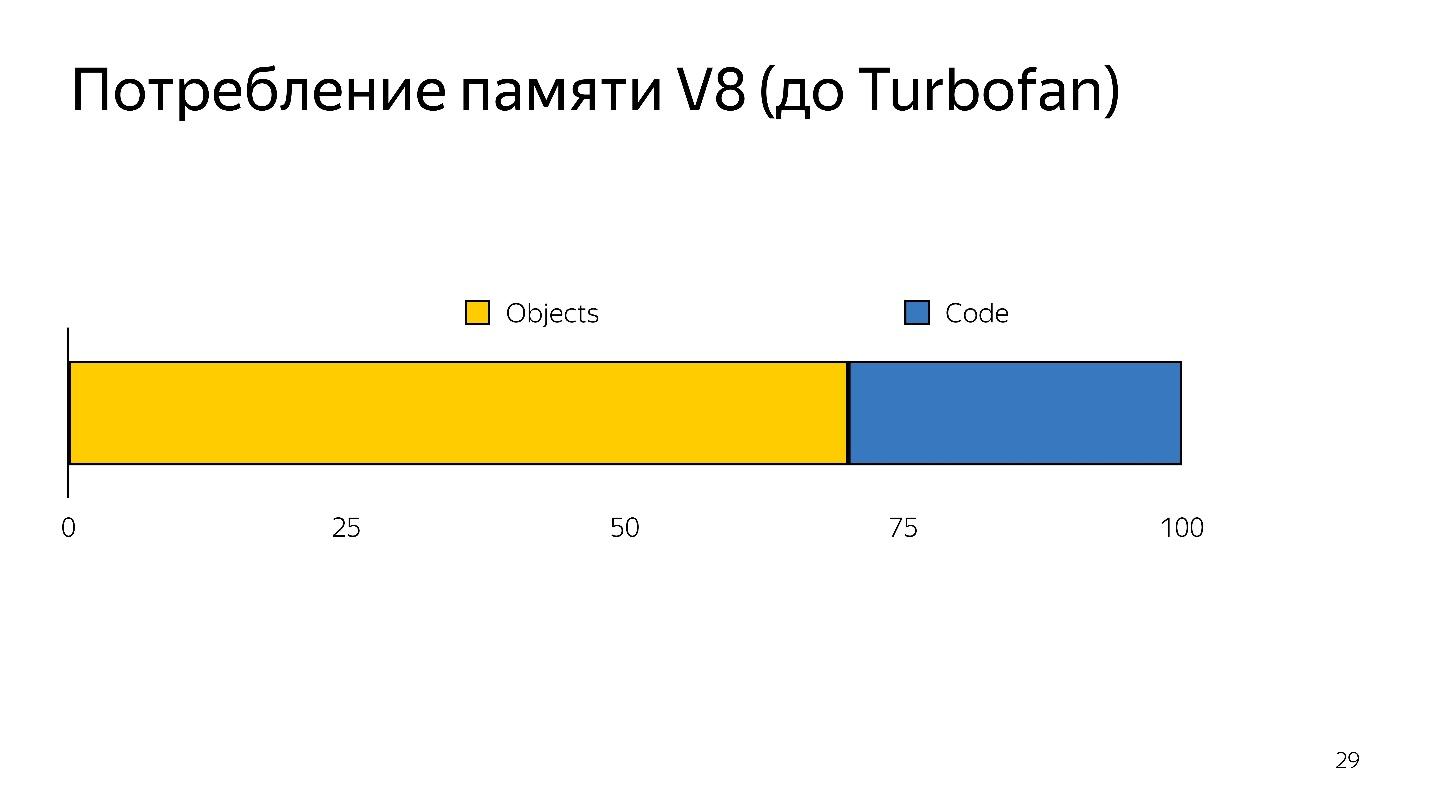
Cuando se produce la desoptimización, debe volver a tomar el código fuente, es decir. necesita ser almacenado en alguna parte. Tomó mucha memoria.
Por lo tanto, el intérprete tenía dos tareas:
- reducir el análisis por encima de la cabeza;
- Reduce el consumo de memoria.
Las tareas se resolvieron cambiando a un intérprete de código de bytes.
 Bytecode en Chrome es una máquina de registro con una batería
Bytecode en Chrome es una máquina de registro con una batería . SpiderMonkey tiene una máquina apilada, allí todos los datos están en la pila, pero no hay registros. Aquí están
No analizaremos completamente cómo funciona esto, solo mira el fragmento de código.

Aquí dice: tome el valor que se encuentra en la batería y agréguelo al valor que se encuentra en el registro
a0 , es decir, en la variable
a . Todavía no se sabe nada sobre los tipos aquí. Si se tratara de un código de ensamblador real, se escribiría con un entendimiento de qué tipo de cambios hay en la memoria, qué hay en él. Aquí hay solo una instrucción: tome lo que se encuentra en el registro
a0 y agréguelo al valor que se encuentra en la batería.
Por supuesto, el intérprete no solo toma el árbol de sintaxis abstracta y lo traduce a bytecode.
También hay optimizaciones, por ejemplo, eliminación de código muerto.
Si no se llama a una sección de código, se descarta y no se almacena más. Si Ignition ve la suma de dos números, los suma y los deja de tal manera que no almacenen información innecesaria. Solo después de esto se obtiene el bytecode.
Optimización y desoptimización.
Características frías y calientes
Este es el tema más fácil.
Las funciones en frío son las que se llamaron una vez o no se llamaron en absoluto, las funciones en caliente son las que se llamaron varias veces. Es imposible decir exactamente cuántas veces, en cualquier momento, esto puede rehacerse. Pero en algún momento, la función se calienta y el motor comprende que debe optimizarse.

El esquema de trabajo.
- Ignition (intérprete) recopila información. No solo convierte JavaScript en bytecode, sino que también comprende qué tipos entraron, qué funciones se pusieron de moda, y le cuenta al compilador sobre todo esto.
- Hay una optimización.
- El compilador ejecuta el código. Todo funciona bien, pero aquí llega un tipo que no esperaba, no tiene código para trabajar con este tipo.
- Se produce desoptimización. El compilador accede al intérprete de encendido para este código.
Este es un ciclo normal que ocurre todo el tiempo, pero no es infinito. En algún momento, el motor dice: "No, es imposible de optimizar" y comienza a ejecutarse sin optimización. Es importante entender que se debe observar el monomorfismo.
El monomorfismo es cuando los mismos tipos siempre llegan a la entrada de su función. Es decir, si obtiene cadena todo el tiempo, entonces no necesita pasar booleano allí.
¿Pero qué hacer con los objetos? Los objetos son todos objeto. Tenemos clases, pero no son reales, es solo azúcar sobre el modelo prototipo. Pero dentro del motor hay las llamadas clases ocultas.
Clases ocultas
Hay clases ocultas en todos los motores, no solo en V8. En todas partes se les llama de manera diferente, en términos de V8 es Mapa.
Todos los objetos que ha creado tienen clases ocultas. Si tu
mire el generador de perfiles de memoria, verá que hay elementos donde se almacena la lista de elementos, propiedades donde se almacena la propiedad y mapa (generalmente el primer parámetro), donde se indica un enlace a él en su clase oculta.
Map describe la estructura de los objetos, porque en principio, en JavaScript, la escritura es posible solo estructural, no nominal. Podemos describir cómo se ve nuestro objeto, para qué sirve.
Al eliminar / agregar propiedades de objetos de clases ocultas, el objeto cambia y se asigna uno nuevo. Miremos el código.
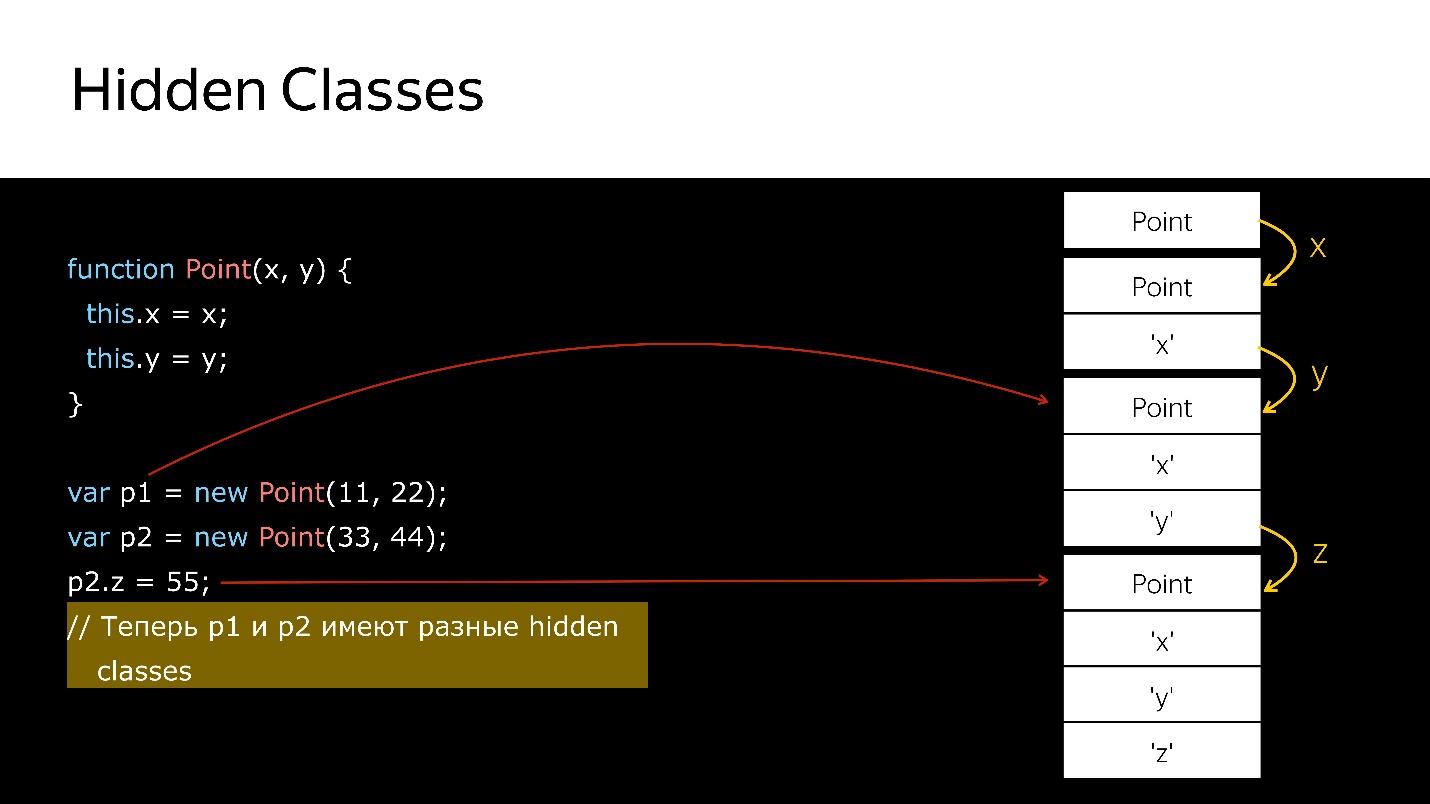
Tenemos un constructor que crea un nuevo objeto de tipo Point.
- Crea un objeto.
- Asociarle una clase oculta, que dice que es un objeto de tipo Punto.
- Agregamos el campo x, una nueva clase oculta que dice que es un objeto de tipo Point, en el que el valor x es lo primero.
- Se agregó y: las nuevas clases ocultas, en las que x y luego y.
- Creó otro objeto, sucede lo mismo. Es decir, también une lo que ya se ha creado. En este momento, estos dos objetos son del mismo tipo (a través de clases ocultas).
- Cuando se agrega un nuevo campo al segundo objeto, aparecen nuevas clases ocultas en el objeto. Ahora para el motor p1 y p2, estos son objetos de diferentes clases, porque tienen estructuras diferentes
- Si transfiere el primer objeto a algún lugar, cuando transfiera el segundo allí, se producirá una desoptimización. La primera se refiere a una clase oculta, la segunda a otra.
¿Cómo puedo verificar las clases ocultas?En Node.js, puede ejecutar el nodo —allow-natives-syntax. Entonces tendrá la oportunidad de escribir comandos en una sintaxis especial, que, por supuesto, no se puede usar en producción. Se ve así:
%HaveSameMap({'a':1}, {'b':1})
Nadie garantiza que mañana estos comandos funcionarán, no están en la especificación ECMAScript, eso es todo para la depuración.
¿Cuál cree que será el resultado de llamar a la función% HaveSameMap para dos objetos? La respuesta correcta es falsa, porque una tiene un campo y la otra tiene
b . Estos son diferentes objetos. Este conocimiento se puede utilizar para la técnica de cachés en línea.
Cachés en línea
Llamamos a una función muy simple que devuelve un campo de un objeto. Devolver la unidad parece ser muy simple. Pero si observa la especificación ECMAScript, verá que hay una gran lista de lo que debe hacer para obtener el campo del objeto. Porque, si el campo no está en el objeto, es posible que esté en su prototipo. Tal vez sea setter, getter, etc. Todo esto necesita ser verificado.

En este caso, el objeto tiene un enlace al mapa, que dice: para obtener el campo
x , necesita hacer un desplazamiento por uno, y obtenemos
x . No tienes que subir a ningún lado, en ningún prototipo, todo está cerca. Los cachés en línea usan esto.
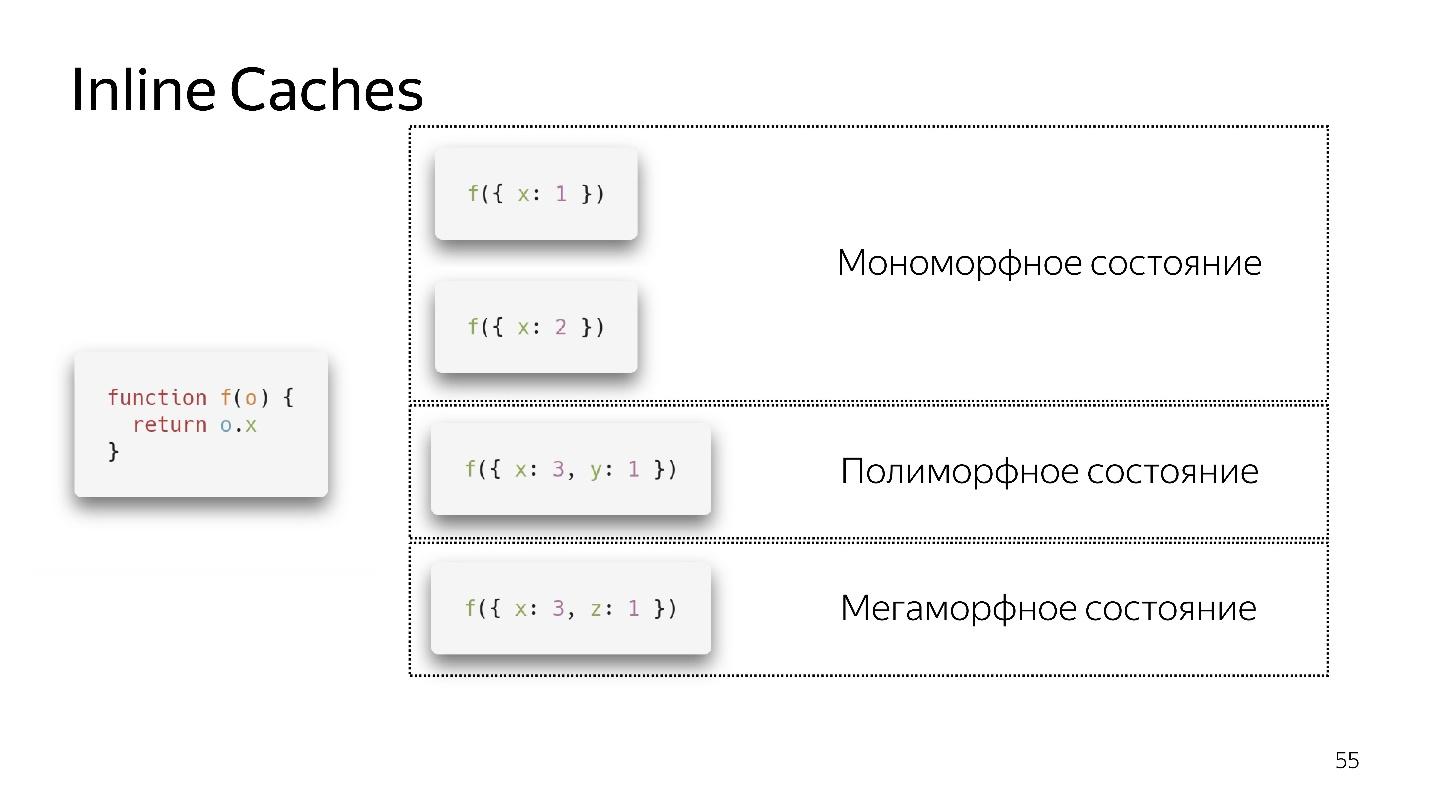
- Si llamamos a la función por primera vez, todo está bien, el intérprete ha realizado la optimización
- Para la segunda llamada, se guarda un estado monomórfico.
- Llamo a la función por tercera vez, paso un objeto ligeramente diferente {x: 3, y: 1}. La desoptimización ocurre, si aparece, entramos en un estado polimórfico. Ahora el código que ejecuta esta función sabe que dos tipos diferentes de objetos pueden volar hacia él.
- Si pasamos diferentes objetos varias veces, permanece en un estado polimórfico, agregando nuevos ifs. Pero en algún momento se rinde y entra en un estado megamórfico, es decir cuando: "Llegan demasiados tipos diferentes a la entrada, ¡no sé cómo optimizarlo!"
Parece que ahora se permiten 4 estados polimórficos, pero mañana puede haber 8. Esto lo deciden los desarrolladores del motor. Será mejor que nos quedemos en un estado monomórfico, en casos extremos, polimórficos. La transición entre los estados monomórficos y polimórficos es costosa, ya que tendrá que ir al intérprete, obtener el código nuevamente y optimizarlo nuevamente.
Matrices
En JavaScript, aparte de las matrices tipificadas específicas, hay un tipo
matriz. Hay 6 de ellos en el motor V8:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS: solo una matriz empaquetada de números enteros pequeños. Hay optimizaciones para él.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS: una matriz llena de elementos dobles, también hay optimizaciones para ella, pero más lentas.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS: una matriz empaquetada en la que hay objetos, cadenas y todo lo demás. Para él, también, hay optimizaciones.
Los siguientes tres tipos son matrices del mismo tipo que los primeros tres, pero con agujeros:
4. [1, / * hoyo * /, 2, / * hoyo * /, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, / * hoyo * /, 2, / * hoyo * /, 3,4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * hoyo * /, 'X'] // HOLEY_ELEMENTS
Cuando aparecen agujeros en sus matrices, las optimizaciones se vuelven menos eficientes. Comienzan a funcionar mal, porque es imposible pasar por esta matriz en una fila, ordenando las iteraciones. Cada tipo posterior está menos optimizado
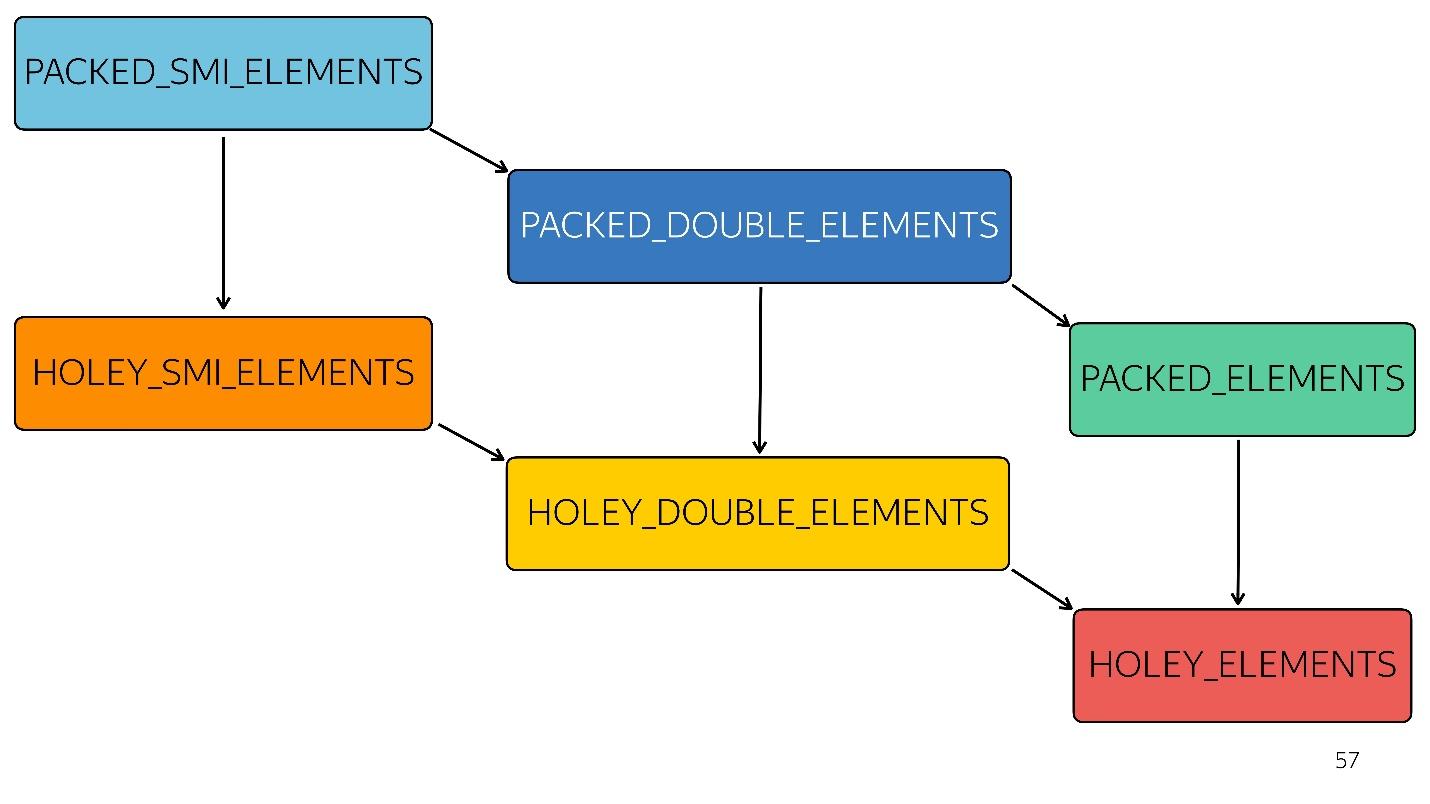
En el diagrama, todo lo anterior está optimizado más rápido. Es decir, todos sus métodos nativos (mapear, reducir, ordenar) están bien optimizados. Pero con cada tipo, la optimización empeora.
Por ejemplo, una matriz simple [
1 ,
2 ,
3 ] llegó a la entrada (entero pequeño lleno de tipos). Cambiamos ligeramente esta matriz al agregarle un doble: pasamos al estado PACKED_DOUBLE_ELEMENTS. Agregue un objeto: vaya al siguiente estado, el rectángulo verde PACKED_ELEMENTS. Agregue agujeros: vaya al estado HOLEY_ELEMENTS. Queremos restaurarlo a su estado anterior para que se vuelva "bueno" nuevamente: eliminamos todo lo que escribimos y permanecemos en el mismo estado ... ¡con agujeros! Es decir, HOLEY_ELEMENTS en la esquina inferior derecha del diagrama. Atrás esto no funciona. Sus matrices solo pueden empeorar, pero no al revés.
Objeto tipo matriz
A menudo nos encontramos con objetos tipo matriz: son objetos que parecen matrices porque tienen un signo de longitud. De hecho, son como un gato pirata, es decir, parecen ser similares, pero en la eficiencia del consumo de ron, un gato será peor que un pirata. Del mismo modo, un objeto tipo matriz es como una matriz, pero no es eficiente.

Nuestros dos objetos favoritos de tipo matriz son argumentos y document.querySelectorAII. Hay cosas tan hermosas y funcionales.
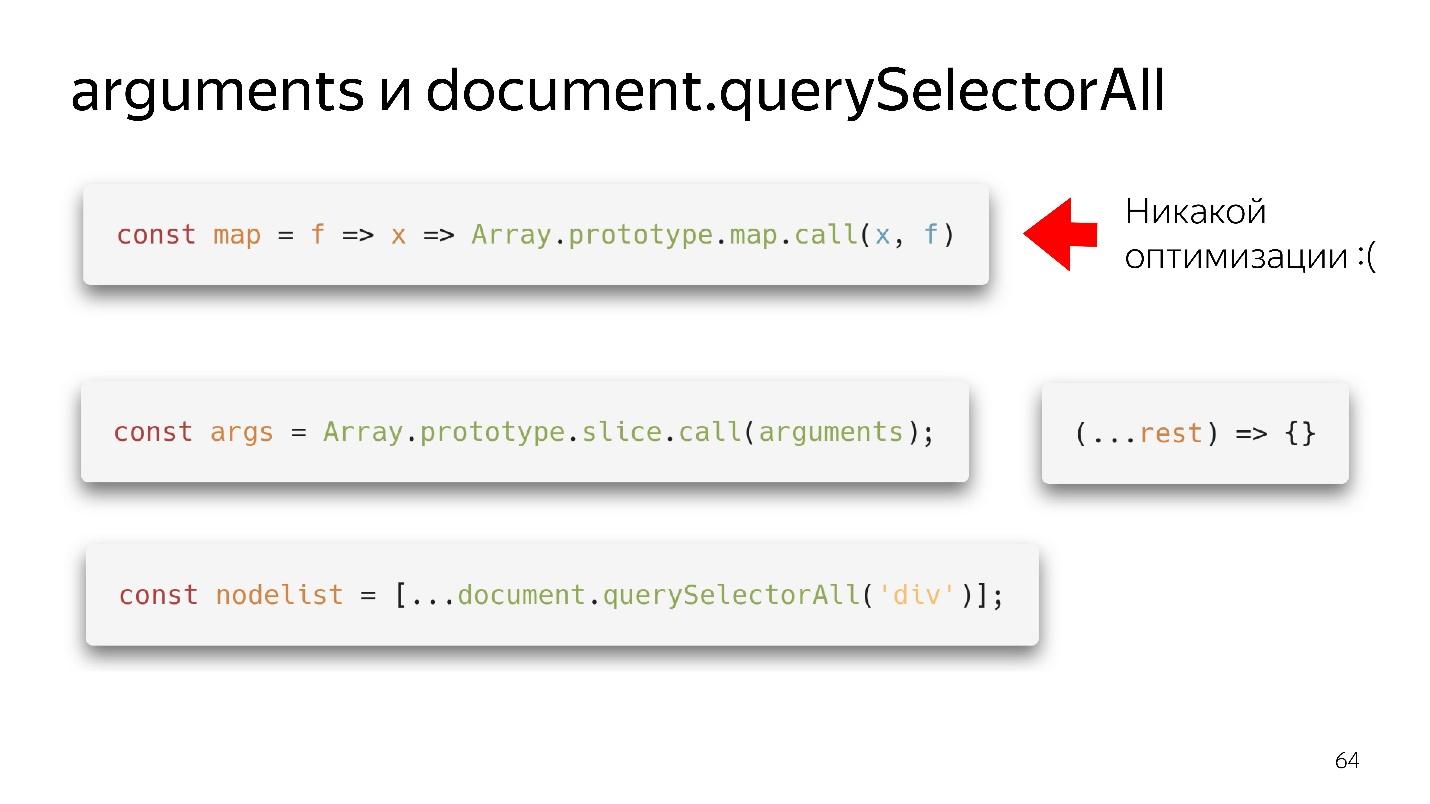
Tenemos un mapa, lo sacamos del prototipo y aparentemente podemos usarlo. Pero si no llegó una matriz a su entrada, no habrá optimización. Nuestro motor no puede hacer optimización en objetos.
¿Qué hay que hacer?
- La opción de la vieja escuela: a través de slice.call () se convierte en una matriz real.
- La opción moderna es aún mejor: escribir (... descansar), obtener una matriz limpia, no argumentos, ¡todo está bien!
Con querySelectorAll lo mismo: debido a la propagación, podemos convertirlo en una matriz completa y trabajar con todas las optimizaciones.
Grandes matrices
Riddle: nueva matriz (1000) vs matriz = []
¿Qué opción es mejor: crear inmediatamente una gran matriz y llenarla con 1000 objetos en un bucle, o crear una vacía y llenarla gradualmente?
Respuesta correcta: depende de.
Cual es la diferencia
- Cuando creamos una matriz de la primera manera y llenamos 1000 elementos, creamos 1000 agujeros. Esta matriz no se optimizará. Pero él escribirá rápidamente.
- Al crear una matriz de acuerdo con la segunda variante, se asigna un poco de memoria, escribimos, por ejemplo, 60 elementos, se asigna un poco más de memoria, etc.
Es decir, en el primer caso escribimos rápidamente: trabajamos lentamente; en el segundo escribimos lentamente, trabajamos rápido.
Recolector de basura
El recolector de basura también consume un poco de tiempo y recursos. Sin sumergirme profundamente, daré la base más común.

Nuestro modelo generativo tiene un
espacio de objetos jóvenes y viejos . El objeto creado cae en el espacio de los objetos jóvenes. Después de un tiempo, comienza la limpieza. Si no se puede alcanzar el objeto mediante enlaces desde la raíz, se puede recolectar en la basura. Si el objeto todavía está en uso, se mueve al espacio de los objetos antiguos, que se limpia con menos frecuencia. Sin embargo, en algún momento, los objetos antiguos se eliminan.

Así es como funciona un recolector de basura automático: limpia los objetos sobre la base de que no hay enlaces a ellos. Estos son dos algoritmos diferentes.
- Scavenge es rápido pero no efectivo.
- Mark-Sweep es lento pero eficiente.
Si comienza a perfilar el consumo de memoria en Node.js, obtendrá algo como esto.

Al principio, crece abruptamente: este es el trabajo del algoritmo Scavenge. Luego se produce una fuerte caída: este algoritmo Mark-Sweep ha recolectado basura en el espacio de los objetos antiguos. En este momento, todo comienza a disminuir un poco.
No puede controlarlo , porque no sabe cuándo sucederá. Solo puedes ajustar los tamaños.
Por lo tanto, la tubería tiene una etapa de recolección de basura que consume tiempo.
¿Incluso más rápido?
Miremos hacia el futuro. ¿Qué hacer a continuación, cómo ser más rápido?
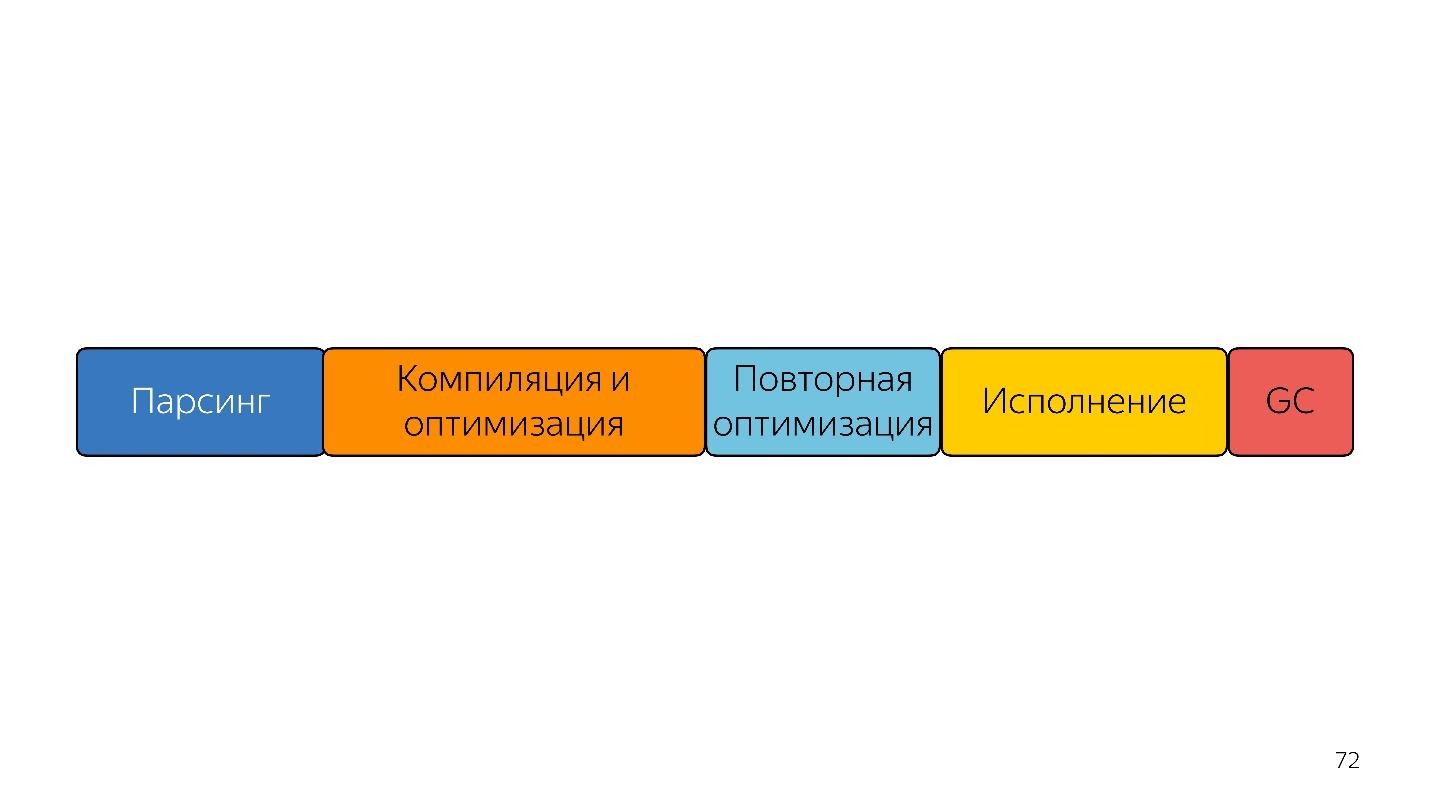
En esta línea, los tamaños de bloque están más o menos relacionados en el tiempo que lleva.
Lo primero que les viene a la mente a las personas que han escuchado sobre el bytecode (enviar inmediatamente un bytecode a la entrada y decodificarlo, en lugar de analizarlo) será más rápido.

El problema es que el código de bytes es diferente ahora. Como dije: en Safari uno, en FireFox otro, en Chrome tercero. Sin embargo, los desarrolladores de Mozilla, Bloomberg y Facebook han presentado una
propuesta de este tipo , pero este es el futuro.
Hay otro problema: compilación, optimización y reoptimización, si el compilador no lo adivinó. Imagine que hay un lenguaje estáticamente tipado en la entrada que produce un código efectivo, lo que significa que ya no es necesario volver a optimizarlo, porque lo que obtuvimos ya es eficiente. Dicha entrada solo se puede compilar y optimizar una vez. El código resultante será más eficiente y se ejecutará más rápido.
¿Qué más se puede hacer? Imagine que este lenguaje tiene administración de memoria manual. Entonces no necesita un recolector de basura. La línea se ha vuelto más corta y más rápida.

¿Adivina cómo se ve?
WebAssembly aproximadamente
así es como funciona: gestión manual de memoria, tipada estáticamente
idiomas y ejecución rápida.

¿Es WebAssembly una bala de plata?

No, porque significa JavaScript. WASM no puede hacer nada todavía. Él no tiene acceso a la API DOM. Está dentro del motor de JavaScript, ¡dentro del mismo motor! Hace todo a través de JavaScript, por lo que
WASM no acelerará su código . Puede acelerar los cálculos individuales, pero su intercambio entre JavaScript y WASM será un cuello de botella.
Por lo tanto, mientras nuestro lenguaje es JavaScript y solo él, y algo de ayuda del cuadro negro.
Total
Se pueden distinguir tres tipos de optimización.
●
optimizaciones algorítmicasHay un artículo "
Quizás no necesites Rust para acelerar tu JS " de Vyacheslav Egorov, quien una vez desarrolló V8 y ahora está desarrollando Dart. Repetir brevemente su historia.
Había una biblioteca de JavaScript que no funcionaba muy rápido. Algunos chicos lo volvieron a escribir en Rust, compilaron y obtuvieron WebAssembly, y la aplicación comenzó a funcionar más rápido. Vyacheslav Egorov, como desarrollador experimentado de JS, decidió responderlas. Aplicó optimizaciones algorítmicas, y la solución de JavaScript se volvió mucho más rápida que la solución de Rust. A su vez, esos tipos vieron esto, hicieron las mismas optimizaciones y ganaron nuevamente, pero no mucho, depende del motor: en Mozilla ganaron, en Chrome no.
Hoy no hablamos de optimizaciones algorítmicas, y los renderizados front-end generalmente no hablan de ellas. Esto es muy malo, porque los
algoritmos también permiten que el código se ejecute más rápido . Simplemente eliminas los ciclos que no necesitas.
●
optimizaciones específicas del idiomaDe esto es de lo que hablamos hoy: nuestro lenguaje se interpreta de forma dinámica. Comprender cómo funcionan las matrices, los objetos y el monomorfismo le
permite escribir código eficiente . Esto debe ser conocido y escrito correctamente.
●
Optimizaciones específicas del motor.Estas son las optimizaciones más peligrosas. Si es un desarrollador muy inteligente, pero no muy sociable, que aplicó muchas de esas optimizaciones y no le contó a nadie sobre ellas, no escribió documentación, entonces si abre el código, no verá JavaScript, sino, por ejemplo, Crankshaft Script. Es decir, JavaScript escrito con una profunda comprensión de cómo funcionaba el motor del cigüeñal hace dos años. Todo funciona, pero ahora ya no es necesario.
Por lo tanto, tales optimizaciones deben necesariamente documentarse, cubrirse con pruebas que demuestren su efectividad en este momento. Deben ser monitoreados. Necesitas ir a ellos solo en el momento en que realmente desaceleraste en algún lugar, simplemente no puedes prescindir de conocimiento de dispositivos tan profundos. Por lo tanto, la famosa frase de Donald Knuth parece lógica.

No es necesario intentar implementar ningún tipo de optimizaciones difíciles solo porque lees críticas positivas sobre ellas.
Uno debe tener miedo de tales optimizaciones, asegúrese de documentar y dejar métricas. En general siempre se recopilan métricas.
¡Las métricas son importantes!Enlaces utiles:Frontend Conf Moscow 4 5 . 15 , , :
- (KeepSolid) , Offline First Persistent Storage
- (TradingView) WebGL WebAssembly , , API .
- , Google Docs.