Introduccion
Hace algún tiempo, participé en un proyecto para desarrollar un producto de software diseñado para analizar registros de pacientes y datos sobre su estado de salud provenientes de organizaciones médicas para crear un registro médico unificado. Durante mucho tiempo, el equipo no pudo desarrollar un enfoque para combinar datos de pacientes. El punto de partida fue el estudio de los códigos fuente de la solución Open EMPI (Open Enterprise Master Patient Index), que nos empujó a utilizar algoritmos de análisis de similitud de cadenas. A partir de ese momento, comenzó un estudio más profundo de los materiales, que hizo posible crear primero un diseño y luego una solución de trabajo.
Hasta ahora, en varios tipos de presentaciones, uno tiene que escuchar muchas preguntas sobre la lógica del trabajo de dichos productos, de lo cual concluyo que una revisión de los métodos de enlace de texto será de interés para un amplio círculo de lectores.
El material es una traducción del artículo de Wikipedia " Registro de enlaces " con derechos de autor y adiciones.
¿Qué es el enlace de texto?
El término " vinculación de registros" describe el proceso de adjuntar registros de texto de una fuente de datos a registros de otra, siempre que describan el mismo objeto. En informática, esto se llama "mapeo de datos" o "problema de identidad de objeto" . Algunas veces se usan definiciones alternativas, como "identificación" , "enlace" , "detección de duplicados" , "deduplicación" , "registros coincidentes" , "identificación de objeto" , que describen el mismo concepto. Esta abundancia terminológica ha llevado a una separación del procesamiento de la información y los enfoques de estructuración: enlace de registros y enlace de datos . Aunque ambos determinan la identificación de objetos coincidentes por diferentes conjuntos de parámetros, el término "vincular registros de texto" se usa comúnmente cuando se refiere a la "esencia" de una persona, mientras que "vincular datos" significa la posibilidad de vincular cualquier recurso web entre conjuntos de datos, utilizando, respectivamente, el concepto más amplio de un identificador, es decir, un URI.
¿Por qué se necesita esto?
Cuando se desarrollan productos de software para construir sistemas automatizados utilizados en diversos campos relacionados con el procesamiento de datos personales de una persona (atención médica, historia, estadísticas, educación, etc.), surge la tarea de identificar datos sobre temas de contabilidad provenientes de diversas fuentes.
Sin embargo, cuando se recopilan descripciones de una gran cantidad de fuentes, surgen problemas que dificultan su identificación inequívoca. Estos problemas incluyen:
- errores tipográficos
- permutaciones de campo (por ejemplo, en el nombre);
- el uso de abreviaturas y abreviaturas;
- El uso de un formato diferente de identificadores (fechas, números de documentos, etc.).
- distorsión fonética;
- etc.
La calidad de los datos sin procesar afecta directamente el resultado del proceso de enlace. Debido a estos problemas, los conjuntos de datos a menudo se transfieren al procesamiento, que, aunque describen el mismo objeto, parece que estos registros se ven diferentes. Por lo tanto, por un lado, se evalúa la aplicabilidad de todos los identificadores de registros transmitidos para su uso en el proceso de identificación y, por otro lado, los registros en sí mismos se normalizan o estandarizan para llevarlos a un solo formato.
Tour de historia
La idea original de vincular notas fue presentada por Halbert L. Dunn, quien publicó un artículo titulado "Record Linkage" en el American Journal of Public Health en 1946.
Más tarde, en 1959, en un artículo sobre Enlace automático de registros vitales en la revista Science, Howard B. Newcombe sentó las bases probabilísticas de la teoría moderna de encuadernación de cuerdas, que fueron desarrolladas y reforzadas en 1969 por Ivan Fellegi y Alan Santer (Alan Sunter). Su trabajo "Una teoría para la vinculación de registros" sigue siendo la base matemática de muchos algoritmos de vinculación.
El desarrollo principal de los algoritmos fue en los años 90 del siglo pasado. Luego, de varias áreas (estadística, archivo, epidemiología, historia y otras), nos llegaron algoritmos que a menudo se usan ahora en productos de software, como la similitud (distancia) de la distancia Jaro-Winkler y la distancia Levenshtein , sin embargo, algunas soluciones, por ejemplo, el algoritmo fonético de Soundex, aparecieron mucho antes, en los años 20 del siglo pasado.
Algoritmos de comparación de entrada de texto
Distinguir entre algoritmos deterministas y probabilísticos para comparar registros de texto. Los algoritmos deterministas se basan en la coincidencia completa de los atributos de registro. Los algoritmos probabilísticos permiten calcular el grado de correspondencia de los atributos de registro y, en base a esto, decidir la posibilidad de su relación.
Algoritmos Deterministas
La forma más fácil de comparar cadenas se basa en reglas claras cuando se generan enlaces entre objetos en función del número de coincidencias de los atributos de los conjuntos de datos. Es decir, dos registros se corresponden entre sí mediante un algoritmo determinista si todos o algunos de sus atributos son idénticos. Los algoritmos deterministas son adecuados para comparar sujetos descritos por un conjunto de datos que se identifican mediante un identificador común (por ejemplo, el número de Seguro de una cuenta personal individual en el Fondo de Pensiones - SNILS) o tienen varios identificadores representativos (fecha de nacimiento, género, etc.) en los que se puede confiar.
Se pueden aplicar algoritmos deterministas cuando se transfieren conjuntos de datos claramente estructurados (estandarizados) al procesamiento.
Por ejemplo, tiene el siguiente conjunto de entradas de texto:
| No | SNILS | Nombre | Fecha de nacimiento | Género |
|---|
| A1 | 163-648-564 96 | Zhvanetsky Mikhail | 06/03/1934 | M |
| A2 | 163-648-564 96 | Zhvanetsky Mikhail | 06/03/1934 | M |
| A3 | 126-029-036 24 | Ilchenko Victor | 01/02/1937 | M |
| A4 | | Novikova Klara | 26/12/1946 | F |
| No | SNILS | Nombre | Fecha de nacimiento | Género |
|---|
| B1 | 126-029-036 24 | Ilyichenko Victor | 01/02/1937 | M |
| B2 | | Zhivanetsky Mikhail | 06/03/1934 | M |
| B3 | | Zerchaninova Klara | 26/12/1946 | 2 |
Anteriormente se dijo que el algoritmo determinista más simple es el uso de un identificador único, que se supone que identifica de manera única a una persona. Por ejemplo, suponemos que todos los registros que tienen el mismo valor de identificador (SNILS) describen el mismo tema, de lo contrario son temas diferentes. La conexión determinista en este caso generará los siguientes pares: A1 y A2, A3 y B1. B2 no se asociará con A1 y A2, ya que el identificador no importa, aunque coincide en contenido con los registros especificados.
Estas excepciones conducen a la necesidad de complementar el algoritmo determinista con nuevas reglas. Por ejemplo, si no hay un identificador único, puede usar otros atributos como nombre, fecha de nacimiento y género. En el ejemplo dado, esta regla adicional nuevamente no dará correspondencia B2 y A1 / A2, porque ahora los nombres son diferentes: hay una distorsión fonética del apellido.
Este problema se puede resolver utilizando los métodos de análisis fonético, pero si cambia el apellido (por ejemplo, en el caso del matrimonio), deberá recurrir a la aplicación de una nueva regla, por ejemplo, comparar la fecha de nacimiento o permitir diferencias en los atributos disponibles del registro (por ejemplo, género).
El ejemplo ilustra claramente que el algoritmo determinista es muy sensible a la calidad de los datos, y un aumento en el número de atributos de registro puede conducir a un aumento sustancial en el número de reglas aplicadas, lo que complica en gran medida el uso de algoritmos deterministas.
Además, el uso de algoritmos deterministas es posible si hay un conjunto de datos verificado (referencia maestra) con el que se compara la información entrante. Sin embargo, en el caso de la reposición constante del directorio maestro en sí, puede ser necesaria una revisión completa de las relaciones existentes, lo que hace que el uso de algoritmos deterministas requiera mucho tiempo o simplemente sea imposible.
Algoritmos Probabilísticos
Los algoritmos probabilísticos para vincular registros de cadenas utilizan un conjunto de atributos más amplio que los deterministas, y para cada atributo se calcula un coeficiente de peso que determina la capacidad de influir en la conexión en la evaluación final de la probabilidad de conformidad de los registros estimados. Los registros que han acumulado un peso total por encima de un cierto umbral se consideran relacionados, los registros que han acumulado un peso total por debajo de un umbral se consideran no relacionados. Los pares que han ganado el valor del peso total desde la mitad del rango se consideran candidatos para la vinculación y pueden considerarse más adelante (por ejemplo, por el operador), que decidirá sobre su unión (enlace) o los dejará sin consolidar. Por lo tanto, a diferencia de los algoritmos deterministas, que son un conjunto de un gran número de reglas claras (programadas), los algoritmos probabilísticos se pueden adaptar a la calidad de los datos seleccionando valores umbral y no requieren reprogramación.
Por lo tanto, los algoritmos probabilísticos asignan coeficientes de peso ( um ) a los atributos del registro, con la ayuda de los cuales se determinará su correspondencia o inconsistencia entre ellos.
El coeficiente u determina la probabilidad de que los identificadores de dos registros independientes coincidan aleatoriamente. Por ejemplo, la probabilidad u del mes de nacimiento (cuando hay doce valores distribuidos uniformemente) es 1 \ 12 = 0.083. Los identificadores con valores que no están distribuidos uniformemente tendrán diferentes probabilidades para diferentes valores (a veces, incluidos los valores faltantes).
El coeficiente m es la probabilidad de que los identificadores en los pares comparados se correspondan entre sí o sean bastante similares, por ejemplo, en el caso de una probabilidad alta por el algoritmo Jaro-Winkler o baja por el algoritmo Levenshtein. Si los atributos de los registros son completamente consistentes, este valor debe tener un valor de 1.0, pero dada la baja probabilidad de esto, el coeficiente debe evaluarse de manera diferente. Esta evaluación se puede hacer sobre la base del análisis preliminar del conjunto de datos, por ejemplo, "aprendiendo" manualmente el algoritmo probabilístico para identificar una gran cantidad de pares coincidentes y desajustados o lanzando iterativamente el algoritmo para seleccionar el valor de coeficiente m más adecuado.
Si la probabilidad m se define como 0.95, los coeficientes de cumplimiento / incumplimiento para el mes de nacimiento se verán así:
| Métrica | Compartir enlaces | Cuota de valores, no referencias | Frecuencia | Peso |
|---|
| Conformidad | m = 0,95 | u = 0.083 | m \ u = 11.4 | ln (m / u) / ln (2) ≈ 3.51 |
| Desajuste | 1-m = 0.05 | 1-u = 0.917 | (1-m) / (1-u) ≈ 0.0545 | ln ((1-m) / (1-u)) / ln (2) ≈ -4.20 |
Se deben realizar cálculos similares para otros identificadores de registro para determinar sus coeficientes de cumplimiento y de incumplimiento. Luego, cada identificador de un registro se compara con el identificador correspondiente de otro registro para determinar el peso total del par: el peso del par correspondiente se agrega al resultado total con un total acumulativo, mientras que el peso del par inapropiado se resta del resultado total. La cantidad resultante se compara con los valores de umbral identificados para determinar si emparejar o no el par analizado automáticamente o transferirlo al operador para su consideración.
Bloqueo
La determinación de los umbrales de cumplimiento / incumplimiento es un equilibrio entre la obtención de una sensibilidad aceptable (la proporción de registros relacionados detectados por el algoritmo) y el valor predictivo del resultado (es decir, precisión, como una medida de registros verdaderamente coincidentes vinculados por el algoritmo). Dado que definir umbrales puede ser una tarea muy difícil, especialmente para grandes conjuntos de datos, a menudo se usa un método conocido como bloqueo para aumentar la eficiencia computacional. Se intenta realizar una comparación entre registros para los cuales se revela una discrepancia significativa ( discriminación ) en los valores de los atributos básicos. Esto conduce a un aumento en la precisión debido a una disminución en la sensibilidad.
Por ejemplo, el bloqueo basado en la codificación fonética de un apellido reduce el número total de comparaciones necesarias y aumenta la probabilidad de que las relaciones entre los registros sean correctas, ya que los dos atributos ya son consistentes, pero podrían omitir registros relacionados con la misma persona cuyo apellido cambiado (por ejemplo, como resultado del matrimonio). El bloqueo por mes de nacimiento es un indicador más estable que solo se puede ajustar si hay un error en los datos de origen, pero proporciona un beneficio más modesto en valor predictivo positivo y pérdida de sensibilidad, ya que crea doce grupos diferentes de conjuntos de datos extremadamente grandes y no conduce a un aumento en la velocidad informática
Por lo tanto, los sistemas de enlace de entrada de texto más eficientes a menudo usan varias pasadas de bloqueo para agrupar datos de varias maneras a fin de preparar grupos de registros que luego se deben enviar para su análisis.
Aprendizaje automático
Recientemente, se han utilizado varios métodos de aprendizaje automático para vincular registros de texto. En un artículo de 2011, Randall Wilson demostró que el algoritmo clásico de vinculación probabilística para registros de texto es equivalente al algoritmo ingenuo de Bayes y sufre los mismos problemas por el supuesto de que las características de clasificación son independientes. Para aumentar la precisión del análisis, el autor propone utilizar un modelo básico de una red neuronal llamada perceptrón de una sola capa, cuyo uso permite superar significativamente los resultados obtenidos utilizando algoritmos probabilísticos tradicionales.
Codificación fonética
Los algoritmos fonéticos combinan dos palabras pronunciadas de manera similar con los mismos códigos, lo que le permite comparar dichas palabras en función de su similitud fonética.
La mayoría de los algoritmos fonéticos están diseñados para analizar palabras en inglés, aunque recientemente algunos algoritmos se han modificado para su uso con otros idiomas, o se crearon originalmente como soluciones nacionales (por ejemplo, Caverphone).
Soundex
El algoritmo clásico para comparar dos cadenas por su sonido es Soundex (abreviatura de índice de sonido). Establece el mismo código para cadenas que tienen un sonido similar en inglés. Soundex fue utilizado originalmente por la Administración de Archivos Nacionales de EE. UU. En la década de 1930 para analizar retrospectivamente los censos de 1890 a 1920.
Los autores de los algoritmos son Robert C. Russel y Margaret King Odell, quienes lo patentaron en los años 20 del siglo pasado. El algoritmo mismo ganó popularidad en la segunda mitad del siglo pasado cuando se convirtió en el tema de varios artículos en revistas científicas populares en los Estados Unidos y se publicó en la monografía de D. Knut "El arte de la programación".
Daitch-Mokotoff Soundex
Dado que Soundex solo es adecuado para inglés, algunos investigadores han intentado modificarlo. En 1985, Gary Mokotoff y Randy Daitch propusieron una variante del algoritmo Soundex, diseñado para comparar los apellidos de Europa del Este (incluido el ruso) con una calidad bastante alta.
En los años 90, Lawrence Philips (Lawrence Philips) propuso una versión alternativa del algoritmo Soundex, que se llamaba Metaphone. El nuevo algoritmo usó un conjunto más amplio de reglas para la pronunciación en inglés debido a que era más preciso. Más tarde, el algoritmo fue modificado para ser usado en otros idiomas basado en la transcripción usando letras del alfabeto latino.
En 2002, el octavo número de la revista Programmer publicó un artículo de Peter Kankowski que habla sobre su adaptación de la versión en inglés del algoritmo Metaphone. Esta versión del algoritmo convierte las palabras de origen de acuerdo con las reglas y normas del idioma ruso, teniendo en cuenta el sonido fonético de las vocales sin tensión y la posible "fusión" de consonantes en la pronunciación.
En lugar de una conclusión
Como resultado de varias iteraciones, el equipo del proyecto de desarrollo de productos de software, que se mencionó en la introducción, desarrolló una solución arquitectónica, cuyo esquema se muestra en la figura.
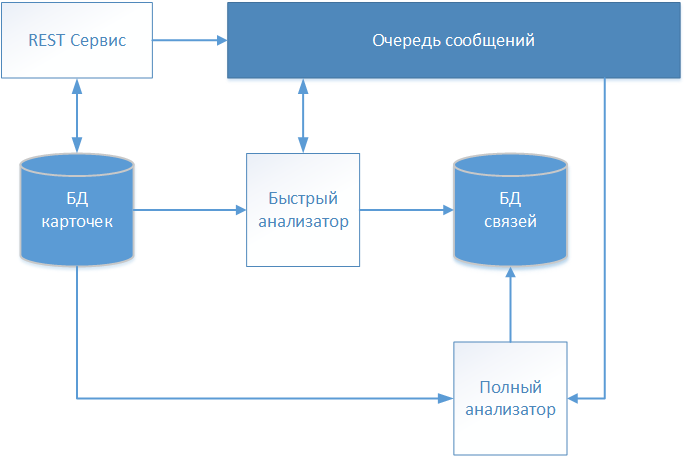
Las descripciones textuales de los pacientes se aceptan a través del servicio REST y se almacenan en el repositorio (base de datos de tarjetas) sin ningún cambio. Dado que nuestro sistema funciona con datos médicos, se eligió el estándar FHIR (recursos de interoperabilidad de atención médica rápida) para el intercambio de información. La información sobre la tarjeta de paciente recibida se transfiere a la cola de mensajes para su posterior análisis y toma de decisiones sobre el establecimiento de la comunicación.
La primera tarjeta que se procesará es el "Analizador rápido" que funciona con un algoritmo determinista. Si todas las reglas del algoritmo determinista han funcionado, entonces crea un registro con un enlace a la tarjeta procesada en un almacenamiento separado (base de datos de enlaces). El registro contiene, además del identificador de la tarjeta analizada, la fecha de establecimiento de la comunicación y un identificador condicional que identifica al paciente identificado globalmente. Otras tarjetas se remiten al identificador global especificado, formando así una matriz que describe a un individuo específico.
Si el algoritmo determinista no encuentra una coincidencia, la información de la tarjeta se transmite a través de la cola de mensajes al "Analizador completo".
( ). . :

1. -
, . 2.
2.
- , ().
3.
, , ( ) , .
4.
, . . , , . , , , .