Pocas personas tienen un Glaster en Rusia, y cualquier experiencia es interesante. Lo tenemos grande e industrial y, a juzgar por la discusión en el
último post , en demanda. Hablé sobre el comienzo de la experiencia de migrar copias de seguridad del almacenamiento de Enterprise a Glusterfs.
Esto no es lo suficientemente hardcore. No nos detuvimos y decidimos recoger algo más serio. Por lo tanto, aquí hablaremos sobre cosas como la codificación de borrado, el fragmentación, el reequilibrio y su aceleración, las pruebas de estrés, etc.

- Más teoría de volum / subwolum
- repuesto en caliente
- sanar / sanar completo / reequilibrar
- Conclusiones después de reiniciar 3 nodos (nunca haga esto)
- ¿Cómo afecta la grabación a diferentes velocidades desde diferentes máquinas virtuales y la activación / desactivación de fragmentos a la carga de subvolumen?
- reequilibrio después de la salida del disco
- reequilibrio rápido
Que querias
La tarea es simple: recolectar una tienda barata pero confiable. Barato como sea posible, confiable, para que no sea aterrador almacenar nuestros propios archivos en venta. Adios Luego, después de largas pruebas y copias de seguridad en otro sistema de almacenamiento, también clientes.
Aplicación (IO secuencial) :
- Copias de seguridad
- Infraestructuras de prueba
- Prueba de almacenamiento para archivos multimedia pesados.
Estamos aqui
- Archivo de batalla e infraestructura de prueba seria
- Almacenamiento de datos importantes.
Como la última vez, el requisito principal es la velocidad de la red entre las instancias de Glaster. 10G al principio está bien.
Teoría: ¿qué es el volumen disperso?
El volumen disperso se basa en la tecnología de codificación de borrado (EC), que proporciona una protección bastante efectiva contra fallas de disco o servidor. Es como RAID 5 o 6, pero en realidad no. Almacena el fragmento codificado del archivo para cada ladrillo de tal manera que solo se requiere un subconjunto de los fragmentos almacenados en los briks restantes para restaurar el archivo. El administrador configura el número de ladrillos que pueden no estar disponibles sin pérdida de acceso a los datos durante la creación del volumen.
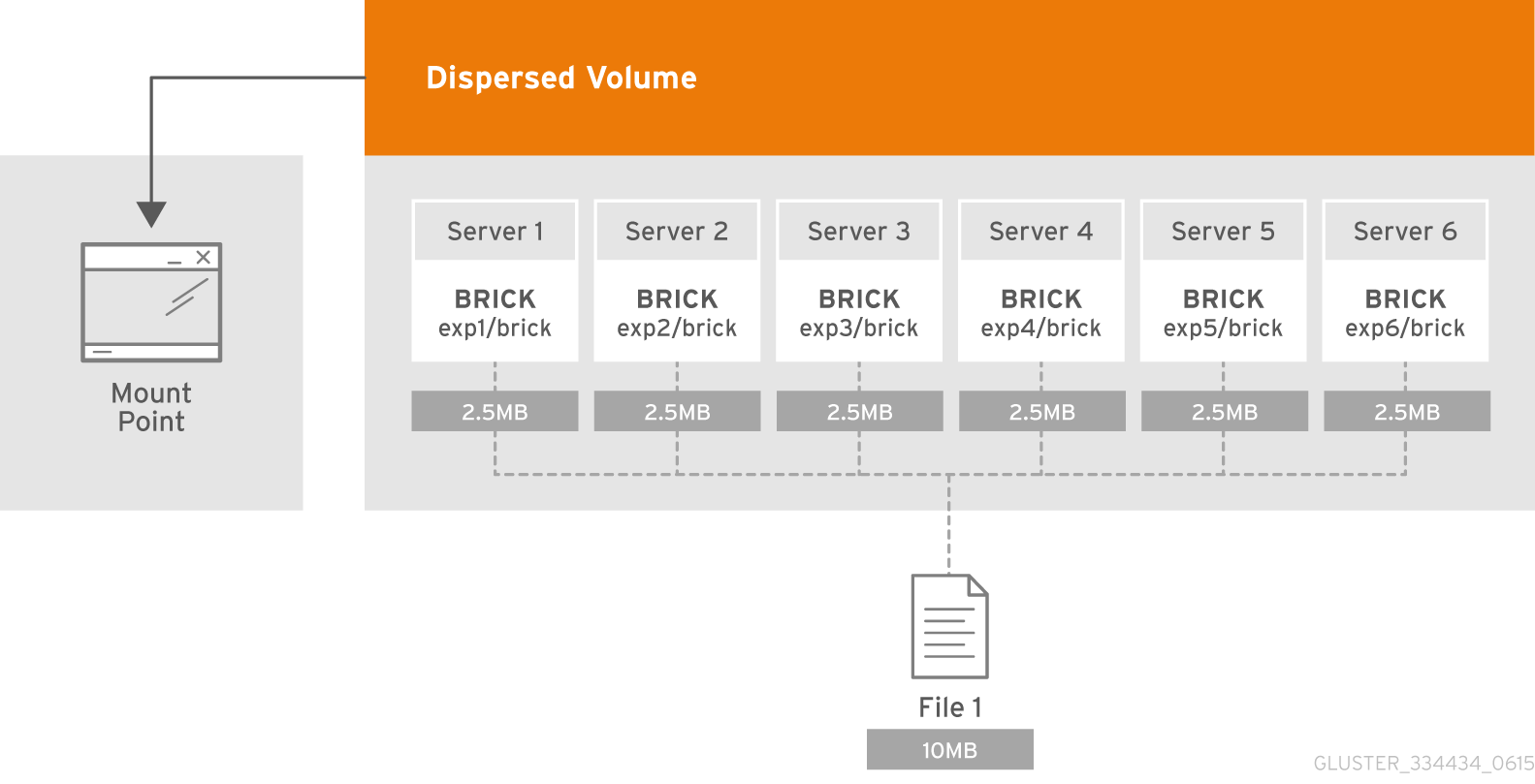
¿Qué es un subvolumen?
La esencia del subvolumen en la terminología de GlusterFS se manifiesta junto con volúmenes distribuidos. En la distribución distribuida, la codificación de borrado funcionará solo en el marco del subwoofer. Y en el caso, por ejemplo, con los datos distribuidos replicados se replicarán dentro del marco del subwoofer.
Cada uno de ellos se distribuye en diferentes servidores, lo que les permite perder o salir libremente para sincronizar. En la figura, los servidores (físicos) están marcados en verde, los sub-lobos están punteados. Cada uno de ellos se presenta como un disco (volumen) al servidor de aplicaciones:

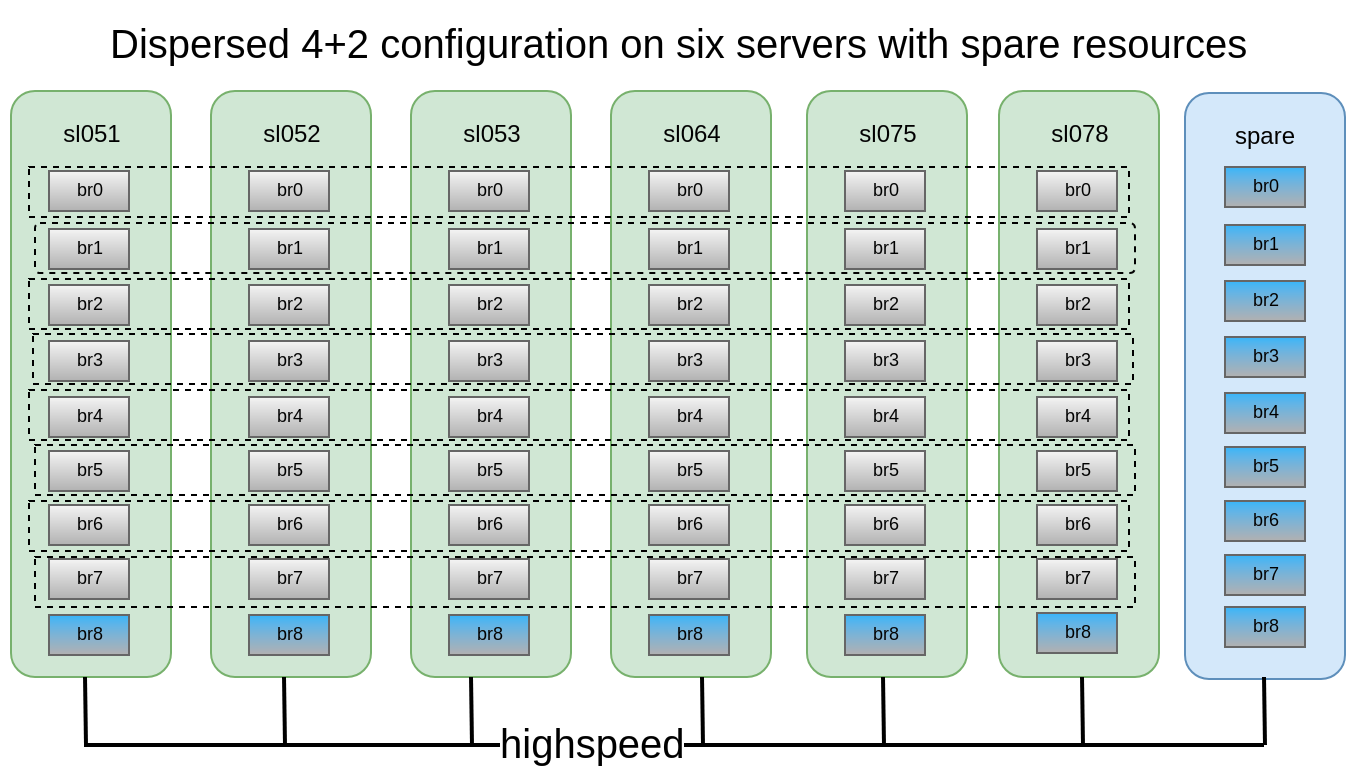
Se decidió que la configuración 4 + 2 distribuida y dispersa en 6 nodos parece bastante confiable, podemos perder 2 servidores o 2 discos dentro de cada subwoofer, mientras continuamos teniendo acceso a los datos.
Teníamos a nuestra disposición 6 viejos DELL PowerEdge R510 con 12 ranuras de disco y unidades SATA de 48x2TB 3.5. En principio, si hay un servidor con 12 ranuras de disco y que tiene hasta 12 TB de unidades en el mercado, podemos recolectar almacenamiento de hasta 576 TB de espacio utilizable. Pero no olvide que, aunque los tamaños máximos de HDD continúan creciendo de año en año, su rendimiento se detiene y la reconstrucción de un disco de 10-12 TB puede llevarle una semana.
 Creación de volumen:
Creación de volumen:Una descripción detallada de cómo preparar ladrillos, puede leer en mi
publicación anteriorgluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
Creamos, pero no tenemos prisa por lanzar y montar, ya que todavía tenemos que aplicar varios parámetros importantes.
Lo que tenemos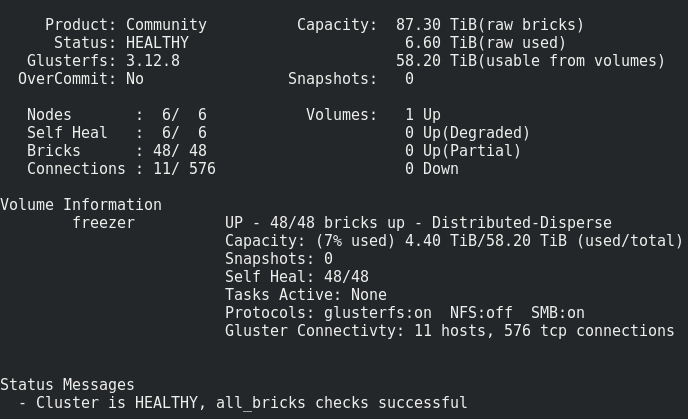
Todo parece bastante normal, pero hay una advertencia.
Consiste en grabar tal volumen en los ladrillos:Los archivos se colocan uno por uno en los sub-lobos, y no se distribuyen uniformemente entre ellos, por lo tanto, tarde o temprano nos encontraremos con su tamaño, y no con el tamaño de todo el volumen. El tamaño máximo de archivo que podemos poner en este repositorio es el tamaño utilizable del subwoofer menos el espacio ya ocupado en él. En mi caso, es <8 Tb.
Que hacer Como serEste problema se resuelve mediante el fragmentación o el volumen de la banda, pero, como la práctica ha demostrado, la banda funciona muy mal.
Por lo tanto, intentaremos fragmentar.
Lo que se está fragmentando, en detalle aquí .
Lo que es fragmentación, en resumen :
Cada archivo que coloque en un volumen se dividirá en partes (fragmentos), que están organizados de manera relativamente uniforme en sub-lobos. El administrador especifica el tamaño del fragmento, el valor estándar es de 4 MB.
Active el sharding después de crear un volumen, pero antes de que comience :
gluster volume set freezer features.shard on
Establecemos el tamaño del fragmento (¿cuál es óptimo? Dudes de oVirt recomienda 512 MB) :
gluster volume set freezer features.shard-block-size 512MB
Empíricamente, resulta que el tamaño real del fragmento en los ladrillos cuando se usa el volumen disperso 4 + 2 es igual al tamaño del bloque de fragmento / 4, en nuestro caso 512M / 4 = 128M.
Cada fragmento de acuerdo con la lógica de codificación de borrado se descompone de acuerdo con los ladrillos dentro del marco del submundo con estas piezas: 4 * 128M + 2 * 128M
Dibuje los casos de falla que Gluster sobrevive con esta configuración:En esta configuración, podemos sobrevivir a la caída de 2 nodos o 2 de cualquier disco dentro del mismo subvolumen.
Para las pruebas, decidimos deslizar el almacenamiento resultante bajo nuestra nube y ejecutar fio desde máquinas virtuales.
Activamos la grabación secuencial de 15 máquinas virtuales y hacemos lo siguiente.
Reinicio del 1er nodo:17:09
Parece no crítico (~ 5 segundos de indisponibilidad por el parámetro ping.timeout).
17:19
Lanzado sanar por completo.
El número de entradas de curación solo está creciendo, probablemente debido al alto nivel de escritura en el clúster.
17:32
Se decidió desactivar la grabación desde la VM.
El número de entradas de curación comenzó a disminuir.
17:50
sanar hecho.
Reiniciar 2 nodos:Se observan los mismos resultados que con el primer nodo.Reiniciar 3 nodos:Punto de montaje emitido El punto final de transporte no está conectado, las máquinas virtuales recibieron ioerror.
Después de encender los nodos, el Glaster se restableció, sin interferencia de nuestro lado, y comenzó el proceso de tratamiento.Pero 4 de cada 15 máquinas virtuales no pudieron aumentar. Vi errores en el hipervisor:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Pago difícil 3 nodos con fragmentación desactivada Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
También perdemos datos, no es posible restaurar.
Pague suavemente 3 nodos con fragmentación, ¿habrá corrupción de datos?Hay, pero mucho menos (¿coincidencia?), Perdí 3 de 30 unidades.
Conclusiones:- La curación de estos archivos se cuelga sin cesar, el reequilibrio no ayuda. Llegamos a la conclusión de que los archivos en los que estaba activando la grabación activa cuando el tercer nodo estaba apagado se pierden para siempre.
- ¡Nunca recargue más de 2 nodos en una configuración 4 + 2 en producción!
- ¿Cómo no perder datos si realmente desea reiniciar 3+ nodos? P Detener la grabación en el punto de montaje y / o detener el volumen.
- Los nodos o ladrillos deben reemplazarse lo antes posible. Para esto, es altamente deseable tener, por ejemplo, 1-2 ladrillos de repuesto en caliente en cada nodo para un reemplazo rápido. Y un nodo adicional con ladrillos en caso de un volcado de nodo.
También es muy importante probar los casos de reemplazo de unidades
Salidas de briks (discos):
17:20Golpeamos un ladrillo:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
Puede ver dicha reducción al momento de reemplazar el ladrillo (registro de 1 fuente):

El proceso de reemplazo es bastante largo, con un pequeño nivel de grabación por clúster y configuraciones predeterminadas de 1 TB, se tarda aproximadamente un día en recuperarse.
Parámetros ajustables para el tratamiento: gluster volume set cluster.background-self-heal-count 20
Opción: disperse.background-heals
Valor predeterminado: 8
Descripción: esta opción se puede utilizar para controlar el número de curaciones paralelas
Opción: disperse.heal-wait-qlength
Valor predeterminado: 128
Descripción: esta opción se puede utilizar para controlar el número de curaciones que pueden esperar
Opción: disperse.shd-max-threads
Valor predeterminado: 1
Descripción: Número máximo de curaciones paralelas que SHD puede hacer por ladrillo local. Esto puede reducir sustancialmente los tiempos de curación, pero también puede aplastar sus ladrillos si no tiene el hardware de almacenamiento para soportar esto.
Opción: disperse.shd-wait-qlength
Valor predeterminado: 1024
Descripción: esta opción se puede usar para controlar el número de curaciones que pueden esperar en SHD por subvolumen
Opción: disperse.cpu-extensions
Valor predeterminado: auto
Descripción: fuerce las extensiones de la CPU para que se utilicen para acelerar los cálculos del campo de galois.
Opción: disperse.self-heal-window-size
Valor predeterminado: 1
Descripción: Número máximo de bloques (128 KB) por archivo para el cual el proceso de autocuración se aplicaría simultáneamente.Stood:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
Con nuevos parámetros, se completó 1 TB de datos en 8 horas (¡3 veces más rápido!)
El momento desagradable es que el resultado es un brik más grande de lo que erafue: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
se convirtió en: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
Es necesario entender. Probablemente la cosa está inflando discos delgados. Con el reemplazo posterior del ladrillo aumentado, el tamaño se mantuvo igual.
Reequilibrio:Después de expandir o reducir (sin migrar datos) un volumen (usando los comandos add-brick y remove-brick respectivamente), necesita reequilibrar los datos entre los servidores. En un volumen no replicado, todos los ladrillos deben estar activos para realizar la operación de reemplazo de ladrillos (opción de inicio). En un volumen replicado, al menos uno de los ladrillos en la réplica debe estar arriba.Reequilibrio de conformación:Opción: cluster.rebal-throttle
Valor predeterminado: normal
Descripción: establece el número máximo de migraciones de archivos paralelos permitidas en un nodo durante la operación de reequilibrio. El valor predeterminado es normal y permite un máximo de [($ (unidades de procesamiento) - 4) / 2), 2] archivos a b
e migramos a la vez. Lazy permitirá que solo se migre un archivo a la vez y el agresivo permitirá un máximo de [($ (unidades de procesamiento) - 4) / 2), 4]Opción: cluster.lock-migración
Valor predeterminado: apagado
Descripción: si está habilitada, esta característica migrará los bloqueos posix asociados con un archivo durante el reequilibrioOpción: cluster.weighted-rebalance
Valor predeterminado: activado
Descripción: cuando está habilitado, los archivos se asignarán a ladrillos con una probabilidad proporcional a su tamaño. De lo contrario, todos los ladrillos tendrán la misma probabilidad (comportamiento heredado).Comparación de escritura y luego lectura de los mismos parámetros fio (resultados más detallados de las pruebas de rendimiento, en PM): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


 Si es interesante, compare la velocidad de rsync con el tráfico a los nodos Glaster:
Si es interesante, compare la velocidad de rsync con el tráfico a los nodos Glaster: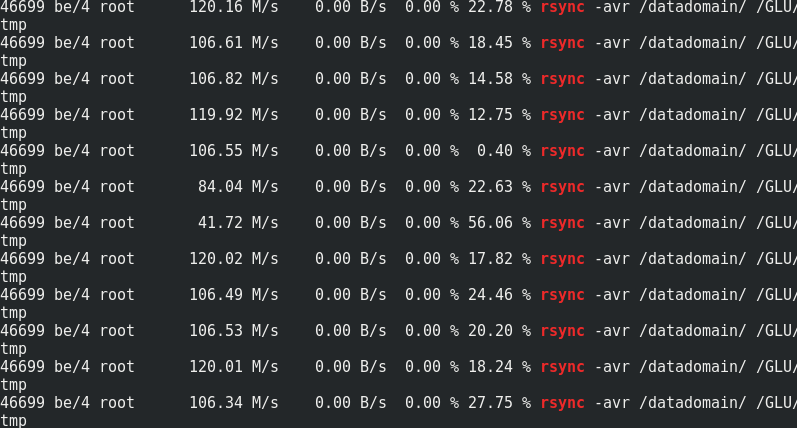
 Se puede ver que aproximadamente 170 MB / s / tráfico a 110 MB / s / carga útil. Resulta que esto es el 33% del tráfico adicional, así como 1/3 de la redundancia de Erasure Coding.El consumo de memoria en el lado del servidor con y sin carga no cambia:
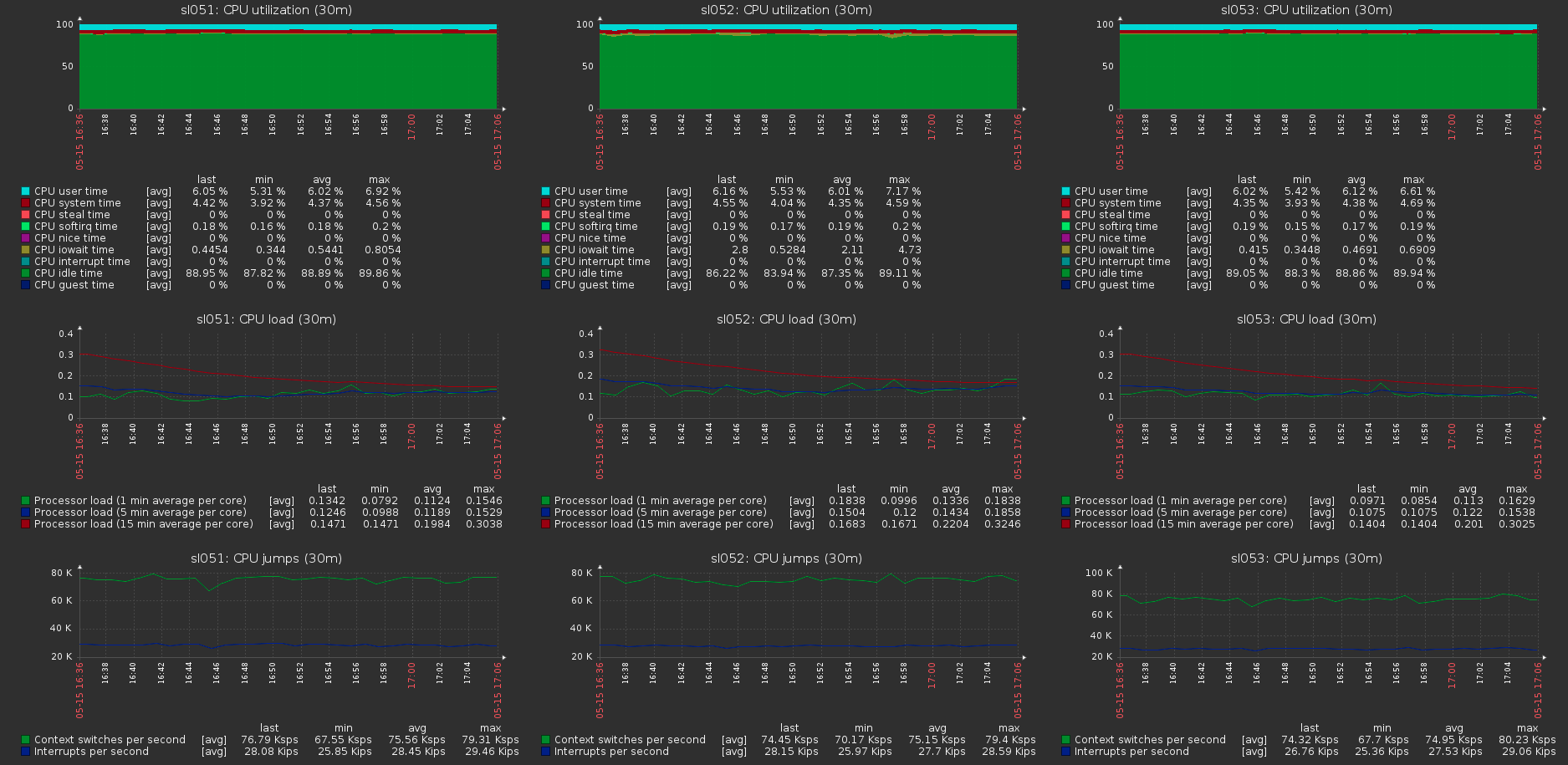
Se puede ver que aproximadamente 170 MB / s / tráfico a 110 MB / s / carga útil. Resulta que esto es el 33% del tráfico adicional, así como 1/3 de la redundancia de Erasure Coding.El consumo de memoria en el lado del servidor con y sin carga no cambia: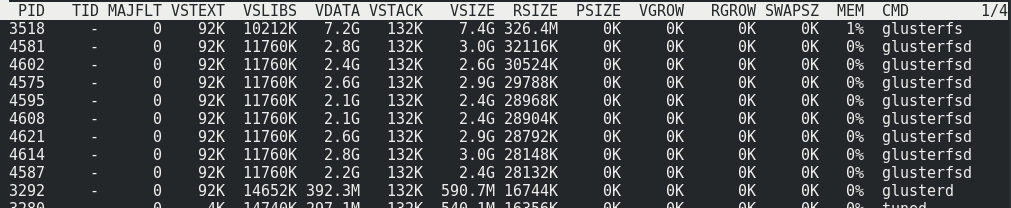 La carga en los hosts del clúster con la carga máxima en el volumen:
La carga en los hosts del clúster con la carga máxima en el volumen: