
En 2014, me uní al pequeño equipo en Schibsted Media Group como el sexto especialista en ciencia de datos en esta empresa. Desde entonces, he trabajado en muchos esfuerzos en el campo de la ciencia de datos en una organización que ahora cuenta con más de 40 de esas personas. En esta publicación, hablaré sobre algunas de las cosas que aprendí en los últimos cuatro años, primero como especialista y luego como gerente de Data Science.
Esta publicación sigue el ejemplo de Robert Chang y su excelente artículo, " Doing Data Science in Twitter " , que encontré muy valioso cuando lo leí por primera vez en 2015. El propósito de mi propia contribución es compartir pensamientos igualmente útiles con especialistas y gerentes de Data Science en todo el mundo.
Dividí la publicación en dos partes:
- Parte I: Ciencia de datos en la vida real
- Parte II: Gestión del equipo de ciencia de datos
En la Parte I, me concentré en el trabajo que los expertos en Data Science realmente hacen, mientras que la Parte II discute cómo administrar el equipo de Data Science de la manera más eficiente posible. Diría que ambas partes son importantes tanto para especialistas como para gerentes.
No pasaré mucho tiempo describiendo quién y quién es el especialista en ciencia de datos y quién no; hay suficientes artículos sobre este tema en Internet.
Brevemente sobre Schibsted: medios y mercados en más de 20 países de todo el mundo. Principalmente trabajo en nuestro negocio de mercados, donde millones de personas compran y venden productos todos los días. Si desea ver algunos ejemplos del mundo real del trabajo de ciencia de datos en Schibsted, aquí hay una pequeña selección:
Con esto en mente, ¡vamos a sumergirnos!
Parte I: Ciencia de datos en la vida real
Comenzar como especialista en ciencia de datos en una nueva empresa con grandes ambiciones es realmente increíble, pero también puede parecer aterrador. ¿Qué esperan las personas a mi alrededor? ¿Qué nivel de habilidad tendrán mis colegas? ¿Cómo trabajo para estar al servicio de la empresa? En una posición en la que hay tanta publicidad, a veces es difícil no sentirse como un impostor .
El miedo a ser un simplón a menudo lleva a un profesional de Data Science a centrarse principalmente en la complejidad. Esto nos lleva a la primera conclusión.
1.1. La dificultad aumenta el valor, comienza simple
Contrataron a un especialista en ciencia de datos, por lo que este problema seguramente debe ser realmente complejo, ¿verdad?

Esta suposición a menudo lo engañará como especialista en ciencia de datos. En primer lugar, los problemas que encuentra en los negocios a menudo se resuelven utilizando métodos bastante simples. En segundo lugar, es importante recordar que la complejidad aumenta el valor. Es probable que un modelo complejo implique más trabajo en su implementación, un mayor riesgo de errores y más dificultades para explicarlo a los clientes. Por lo tanto, siempre debe buscar primero el enfoque más simple.
Pero, ¿cómo entender si el enfoque más simple es suficiente?
1.2. Siempre tenga un modelo base
Las estimaciones de la calidad de su modelo, muy probablemente, no tienen sentido por sí solas sin comparación con el modelo base. La comparación con la precisión con la selección aleatoria, en la mayoría de los casos, simplemente no es suficiente.

En algún momento, creamos un modelo para predecir la probabilidad de que un usuario regrese a nuestro sitio: el modelo de retorno. Se utilizaron alrededor de 15 atributos basados en el comportamiento del usuario en nuestro modelo, y logramos una precisión de aproximadamente ~ 0.8 ROC-AUC. En comparación con la precisión de la predicción aleatoria (0.5), estamos bastante satisfechos con este resultado. Pero cuando eliminamos todo del modelo, excepto los dos signos más importantes: reciente (el número de días de la última visita) y frecuencia (número de días de visitas en el pasado), encontramos que una simple regresión logística en estas dos variables nos dio un 78% de ROC-AUC ! En otras palabras, podríamos lograr más del 97% del rendimiento al eliminar más del 85% de los atributos.
He visto tantas veces cómo los expertos de Data Science muestran los resultados de experimentos fuera de línea en modelos complejos sin ningún modelo base simple para comparar. Cuando vea esto, siempre debe preguntar: ¿podríamos lograr el mismo resultado utilizando un modelo mucho más simple?
1.3. Usa los datos que tienes
Una vez almorcé con un ingeniero de datos y otro especialista en Data Science. Los ojos de este último se iluminaron cuando habló de todas las cosas increíbles que podía hacer "si solo tuviera datos sobre X, Y o Z". En algún momento durante la conversación, el ingeniero se echó a reír: "Ustedes, expertos en ciencia de datos, siempre hablan sobre lo que podrían hacer con los datos que no tienen. ¿Qué tal hacer algo con los datos que tienes?

Parecía grosero, pero el ingeniero expresó una verdad importante. Nunca tendrá el conjunto de datos perfecto y siempre habrá datos que pueda usar. En la mayoría de los casos, puede hacer algo con lo que tiene.
1.4 Asumir la responsabilidad de los datos.
Como se indicó anteriormente, la calidad y la integridad de los datos son casi siempre un problema. Pero en lugar de sentarse y esperar a que alguien le presente los datos en una bandeja de plata, debe hablar y asumir la responsabilidad de los datos que necesita.

No estoy hablando de propiedad formal en el sentido de un modelo de gestión de datos. Estoy hablando de ampliar mi rol y ayudar, cuando sea posible, a obtener los datos que necesita.
Esto puede significar participar en la creación de esquemas y formatos de recolección de datos. Esto puede significar mirar el código Javascript que se ejecuta en la interfaz de la aplicación web para asegurarse de que los eventos se activen cuando debería. O podría significar construir tuberías de datos sin esperar a que los ingenieros de datos hagan todo por usted.
1.5. Olvida los datos
Obviamente, esto contradice todo lo que dije anteriormente, pero es muy importante no centrarse demasiado en los datos que tiene.

Cuando aparece un nuevo problema, primero debe intentar olvidar los datos existentes. Por qué Sí, porque sus datos existentes pueden limitar el espacio de decisiones, y esto puede distraerlo de encontrar el mejor enfoque. Se quedará atrapado en un óptimo local, donde está tratando de sacar la solución a cualquier problema en el conjunto de datos que está disponible para usted (uso más allá del aprendizaje). Como resultado, nunca tendrá nuevos conjuntos de datos.
1.6. Desarrollar una comprensión detallada de la causalidad.
Todos sabemos que la correlación no implica una relación causal. El problema es que muchos expertos en ciencia de datos se detienen ante esto y tienen miedo de relacionar la causa con el efecto.

¿Por qué es esto un problema? Debido a que los gerentes de productos, el equipo de marketing, su CEO o con quién trabaja allí, no están preocupados por la correlación. Se preocupan por una relación causal.
El gerente de producto quiere asegurarse de que cuando decida lanzar esta nueva característica, provocará un aumento del 10% en la participación del producto. El equipo de marketing quiere saber que aumentar el número de cartas de 2 por semana a 4 no obligará a las personas a darse de baja del boletín. Y el CEO quiere saber que invertir en una mejor focalización conducirá a un aumento en los ingresos por publicidad.
Bueno, ¿hay una solución de compromiso? Resulta que hay dos de ellos.
Los experimentos en línea más famosos. De hecho, ejecuta pruebas aleatorias, entre ellas las pruebas A / B más populares. La idea es simple: dado que elegimos accidentalmente quién estará en el grupo objetivo y quién estará en el grupo de control, entonces si encontramos una diferencia estadísticamente significativa entre los grupos, el "tratamiento" que utilizamos puede considerarse la razón. Sin entrar en razonamiento filosófico, en la práctica esta es una suposición razonable.
Un enfoque menos conocido para la búsqueda de relaciones causales es el modelado causal. La idea aquí es hacer suposiciones sobre la estructura causal del mundo, y luego usar datos de observación (no experimentales) para verificar si estas suposiciones son consistentes con los datos, o para evaluar la fuerza de varias relaciones causa-efecto. Adam Kelleher ha escrito una gran serie de artículos, " Causal Data Science " , que recomiendo leer. Además, la Biblia de causalidad es el libro Causality de Judea Pearl.
En mi experiencia, la mayoría de los expertos en ciencia de datos tienen una amplia experiencia en la creación de modelos de aprendizaje automático y su evaluación fuera de línea. Muchas menos personas tienen experiencia con la evaluación y experimentación en línea. La explicación es simple: puede descargar el conjunto de datos de Kaggle, entrenar el modelo y evaluarlo sin conexión en minutos. Para evaluar este modelo en línea, por otro lado, necesita acceso al mundo real. Incluso si trabaja en una empresa de Internet con millones de usuarios, a menudo tiene que superar muchas barreras para exponer su modelo de aprendizaje automático a los usuarios.
Ahora, mientras que pocos expertos en Data Science tienen una amplia experiencia en evaluación en línea, muy pocos tienen experiencia con el modelado causal. Creo que hay muchas buenas razones. Una de las razones es que la mayoría de los libros sobre causalidad son bastante teóricos, entre ellos hay pocas pautas prácticas sobre cómo comenzar el modelado causal en el mundo real. Predigo que en los próximos años veremos pautas más prácticas para el modelado causal.
Desarrollar una comprensión detallada de la causalidad le permitirá dar recomendaciones prácticas a sus clientes y al mismo tiempo respaldar su integridad como especialista en ciencia de datos.
Parte II: Gestión del equipo de ciencia de datos
Schibsted, como muchas otras compañías, tiene dos carreras: como trabajador independiente y como líder. En el contexto de Data Science, el primero está destinado a aquellos que realmente desean aumentar su conocimiento en el campo de Data Science y contribuir a la empresa a través del trabajo práctico y el liderazgo técnico. El camino de liderazgo es para aquellos que son más apasionados por el desarrollo de personas y la gestión de equipos.
No estaba del todo seguro de cuál era el camino adecuado para mí, pero al final decidí probar el camino del líder. No pasó mucho tiempo cuando me di cuenta de que este era realmente el camino correcto para mí, pero por supuesto, me encontré con muchos problemas (¡y todavía lo hago!).
El primer desafío que enfrentará es que hay muy pocos gerentes de Data Science en el mundo. Si creía que los especialistas experimentados en Data Science son raros, los gerentes experimentados de Data Science son muchas veces menos. Por lo tanto, queda más o menos a sus propios dispositivos.
Pero, ¿es cierto que administrar un equipo de Data Science es tan diferente de administrar otros tipos de equipos? Si y no
Si nunca antes ha dirigido un equipo, probablemente pueda encontrar el material de lectura clásico para la administración, como la Administración de alto rendimiento de Andrew Grove. Además, el recurso proactivo a los altos directivos (de otras disciplinas) para recibir asesoramiento también es crucial.
Sin embargo, los equipos de Data Science tienen varias diferencias clave, por lo que ahora nos centraremos en las conclusiones, especialmente las relacionadas con los equipos de Data Science.
2.1. El equipo de Data Science no es realmente un equipo
Cuando la mayoría de la gente piensa en equipos, piensan en algo como esto:

¿Cuáles son algunas características de un equipo de fútbol como el FC Barcelona? Al menos tres cosas:
- Objetivo común
- Diferentes roles en el equipo, cada uno con diferentes responsabilidades.
- Independencia para lograr tu objetivo
Si está administrando un equipo compuesto únicamente por especialistas en Data Science, lo más probable es que ninguna de estas características se cumpla. En cambio, su equipo tendrá:
- Múltiples objetivos cambiantes
- Especialistas, y son buenos en lo mismo: ciencia de datos
- Otros equipos con los que puede trabajar para tener un impacto final en los usuarios e ingresos
Una analogía más adecuada que un equipo de fútbol para un equipo de especialistas en Data Science es:
La demanda de los servicios de Mulder y Scully está cambiando con el tiempo. Se sienten atraídos cuando se requiere su experiencia. Y nunca resolverán el asunto sin hablar con personas ajenas al FBI.
¿Por qué es importante esta distinción?
Porque si tiene un equipo de expertos en ciencia de datos y los gestiona como un equipo "clásico" con un objetivo común, varios roles y autonomía completa, rápidamente obtendrá un equipo frustrado.
He visto equipos de Data Science gestionados como cualquier otro producto o equipo de desarrollo, y la consecuencia inevitable de esto es que los especialistas en Data Science están comenzando a hacer cualquier cosa menos Data Science. En cambio, terminan desarrollando, descomponiendo o administrando el producto.
Entonces, los expertos en Data Science son diferentes. Pero, ¿cómo garantiza entonces que su ciencia de datos no vivirá en una torre de marfil?
2.2. Incruste a profesionales de la ciencia de datos en otros equipos
La magia ocurre cuando pones a los expertos en ciencia de datos junto a gerentes de producto, programadores, investigadores de interfaces, especialistas en marketing y más.
Simplemente, la función objetivo que desea maximizar es la siguiente: interacción fructífera entre los especialistas de Data Science en su equipo y las personas en otros equipos.
Me gusta pensar en ello utilizando el concepto de canal amplio. Vamos a ilustrar esto con un gerente de producto emparejado con un especialista en Data Science.
Lo peor de todo, cuando no hay canal entre ellos:

Esto significa que no hay comunicación entre DS y PM. En otras palabras, DS no estará al tanto de los problemas de producto que enfrenta PM, lo que hace imposible analizar o resolver estos problemas.
Un poco mejor cuando tenemos un canal estrecho entre ellos:
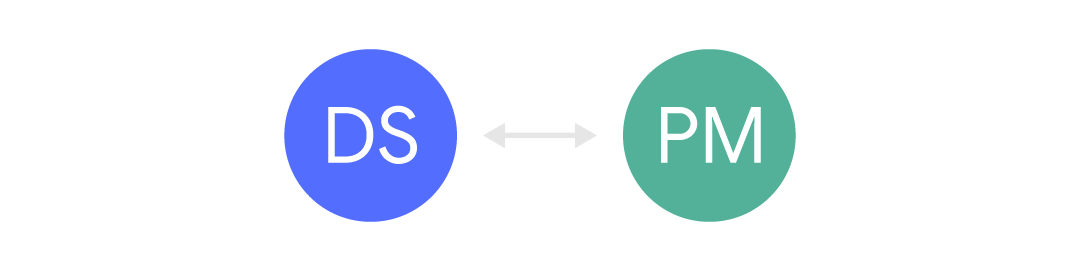
En este caso, la información llega, pero generalmente es limitada y, a menudo, asíncrona. La información llega a través de otras personas (por ejemplo, otro gerente) o mediante formularios de solicitud, etc. Este tipo de comunicación es común cuando se espera que los especialistas en Ciencias de datos atiendan a muchos clientes diferentes. Pero esto puede ser frustrante, porque el contexto comercial a menudo está ausente, y esto puede conducir a malentendidos y estupideces.
La condición más efectiva es cuando tenemos un canal amplio:

En el sentido más literal, un amplio canal es cuando un especialista en Data Science se sienta junto a un gerente de producto. Esto, por supuesto, les permite comunicarse de manera mucho más efectiva. Mantener a las personas físicamente cerca no siempre es conveniente o incluso posible (¡nosotros en Schibsted estamos dispersos en 22 países diferentes!), Pero hay versiones virtuales de este principio: desde Slack hasta programación remota de pares y Hangouts.
Naturalmente, no será posible que cada gerente de producto de la empresa organice un amplio canal con cada especialista en Data Science en su equipo, esto no se escala. Su tarea como gerente de Data Science es determinar cuándo organizar qué canales amplios. ¡Y luego sal del camino!
Uno de los casos en Schibsted cuando estábamos trabajando activamente en la creación de un amplio canal fue el desarrollo de nuestra herramienta de fijación de precios de automóviles, que lo ayuda a establecer el precio al vender su automóvil ( pruébelo en nuestro mercado finlandés en Noruega ). Inicialmente, teníamos un canal más bien delgado, como este: "Intenta crear el modelo de precios más preciso que puedas". Descubrimos que esto era bastante ineficiente, ya que había muchas preguntas sobre productos que no podíamos responder sin experimentar con los usuarios en las primeras etapas.
Sin embargo, después de un tiempo, todo terminó con el hecho de que integramos a uno de nuestros especialistas en Ciencia de Datos en el equipo del producto, y obtuvimos los resultados mucho mejores. Puede leer sobre algunos de nuestros primeros trabajos sobre una herramienta de calificación de automóviles en esta publicación .
Un ejemplo de cuando teníamos un canal amplio desde el principio es un modelo de pronóstico para nuevas suscripciones digitales . El modelo ayudó a aumentar las conversiones de ventas en un 540% y fue recompensado con el Premio INMA al Mejor Uso de Análisis de Datos en 2017.
2.3. Hacerse cargo de la productividad analítica
Andrew Grove afirma en el libro de High Output Management que usted, como gerente, posee los resultados de su equipo. Esto significa que el administrador de Data Science debe invertir en crear el mejor entorno posible para que sus especialistas en Data Science sean productivos.

Esto es en muchos sentidos contrario al modelo de inserción descrito anteriormente. Si incrusta todo todo el tiempo, existe una alta probabilidad de que como resultado obtenga almacenes de datos e infraestructura no óptima, duplicados varias veces.
Algunos gerentes de desarrollo afirman que cuando te conviertes en un líder, debes dejar de codificar por completo. Creo que, como gerente de Data Science, debería dedicar hasta el 10% de su tiempo a trabajar de forma independiente: capacitación en modelos, visualización de datos, etc. Esto lo pone en el lugar de un especialista en Data Science.
“¿Tengo que pasar 15 minutos esperando que se cargue este clúster, cada vez que quiero hacer un análisis ad-hoc? Por supuesto, debería haber una forma más rápida de hacer esto ”.
"Esta documentación en nuestros formatos de esquema parece obsoleta. ¿Cómo mediré los clics en este tipo de botón en diferentes sitios?"
Y así sucesivamente.
Por supuesto, este trabajo manual no debería reemplazar los comentarios proactivos de su equipo. Pero ciertamente lo ayuda a descubrir áreas clave donde sus expertos en Data Science pueden simplificar sus vidas.
, Lean Management, Data Science. XKCD :
, Data Science . !
2.4. -> ->
«» , Data Science, . Data Science . , , , .

:
- . 98% , , (… , ).
- , , - , .
, Data Science, , , , .
, , .
, , , , . , .
, ― . , . . Slack . ( !) , .
. . , !
, ? , , . , , , Data Science.
. , , , , . .
2.5. ,
Data Science. , . , , - , ?
Ferrari, .

, .

Ferrari , .

Data Science ― , , . , , , , (ROI).
Data Science. - , .
, , . , , , , ― , . , , .
, Data Science . , . , , , .
2.6. OKR
, Data Science. Objectives and Key Results (OKR). , OKR ― , . , . OKR , .
OKR , , , , .
, OKR , . , : , .
, , OKR.
-: OKR. OKR , , , . « », . , . , .
LSTM ? , NLP-, , LSTM . ? . ? , .
OKR, .
, OKR . , .
-: OKR . , . , :
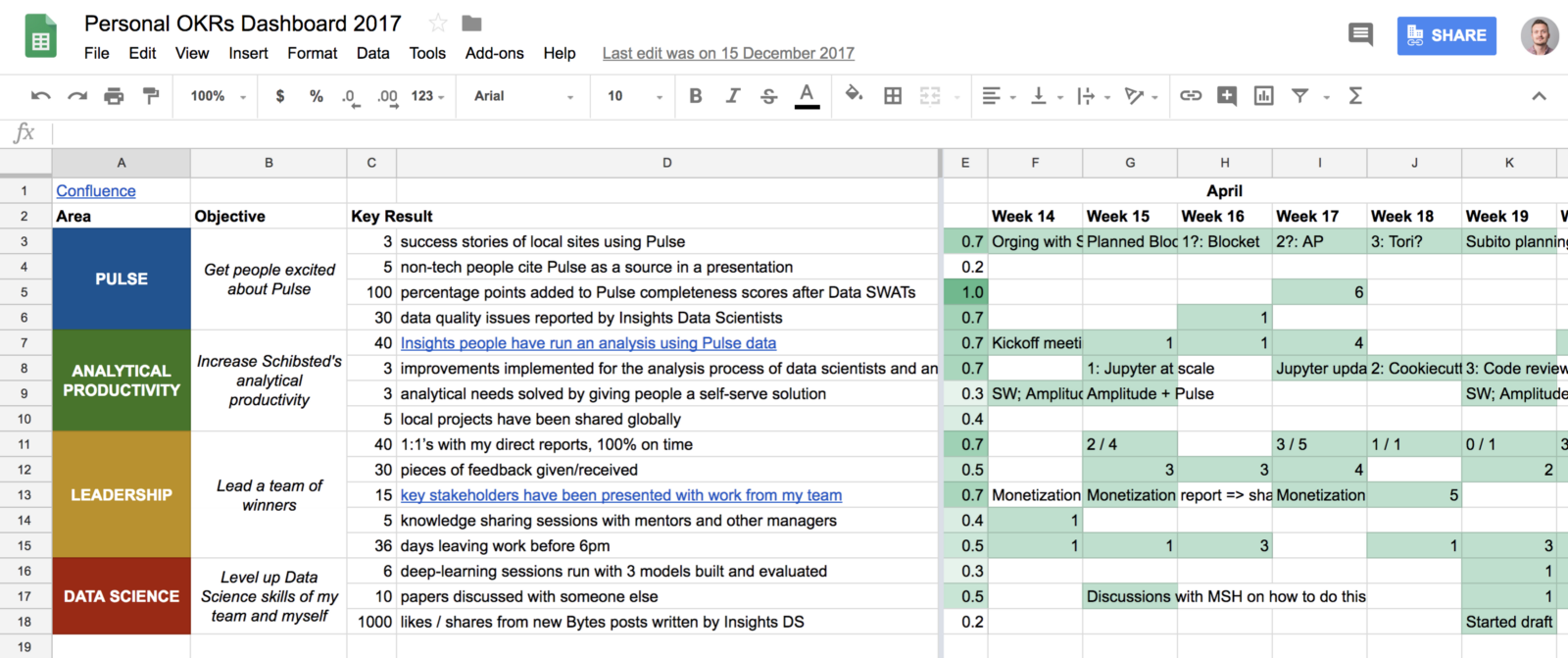
, , 10 , . , , ― . . OKR .
, , OKRs ― .
2.7.
Y al final el punto más importante.
Cuando Google estudió a sus equipos durante dos años para descubrir qué hace que algunos funcionen bien y otros lo hagan menos, hubo una cosa que se destacó. Esto es seguridad psicológica .
En resumen, la seguridad psicológica puede resumirse como la creencia de que no será castigado cuando cometa un error.
Ahora piense en esto en el contexto de la introducción a la Parte I. El síndrome del impostor es muy grande en Data Science. ¿De qué tienes miedo cuando te sientes como un impostor? Cometer errores
Con los años, descubrí que personas de varios campos vienen a Data Science. En nuestro equipo de Schibsted, somos afortunados de tener personas fantásticas con una amplia gama de experiencia. Personas con experiencia en finanzas, investigación, educación, consultoría, desarrollo de software, etc.
Sería tonto suponer que todas estas personas saben lo mismo. Por el contrario, el valor de una experiencia tan diversa radica en el hecho de que todos aportan algo nuevo al equipo.
La idea de una ciencia de datos "unicornio" es un veneno para la seguridad psicológica.
¿Existe una solución rápida para aumentar la seguridad psicológica? No lo creo Pero creo que debería estar en la parte superior de su lista de prioridades como gerente, especialmente cuando crea un nuevo equipo o cuando nuevos miembros se unen a usted. Aunque no hay una solución rápida, existen medidas claras que puede tomar para aumentar la seguridad psicológica. Estos son algunos de los que nos funcionaron bien:
- Crea una cultura de retroalimentación . Deje en claro que los miembros de su equipo deben comunicarse entre ellos "ventajas y mejoras" después de las presentaciones, los sprints, etc. ¡Por cierto, usted como gerente también debe hacerlo! Y enseñe a las personas cómo dar retroalimentación constructiva correctamente, esto no es algo natural para todos.
- Aumenta el tiempo cara a cara . Programación de pares, resolución de problemas en el tablero ... Esto es especialmente importante para los equipos remotos. Es casi seguro que este boleto vale la pena.
- Crear parejas o equipos en lugar de trabajo individual. Puede terminar haciendo menos cosas en el equipo, pero lo hará mejor. Y aquellos que trabajan juntos construirán confianza unos en otros.
- Fomentar debates abiertos y honestos en las reuniones. Trabaje activamente para equilibrar el tiempo en el aire de todos los participantes; algunas personas pueden necesitar que se les pida que hablen.
- Recuerda las diferencias culturales . Puedes provenir de una cultura igualitaria, explícita y directa . Existe una alta probabilidad de que se pierda las señales de un miembro del equipo que se originan en una cultura jerárquica, implícita e indirecta.
- Realizar experimentos grupales para la mejora continua. Involucrar a todo el equipo en el problema "¿Cómo se gestiona un equipo con éxito" les da a todos un sentido de responsabilidad por el bienestar del equipo.
- Mide la felicidad y la seguridad psicológica. Encuentre una manera fácil de hacer preguntas regularmente sobre la felicidad y la seguridad psicológica. Si no tiene un sistema de recursos humanos moderno para estos fines, simplemente comience con Typeform e itere hasta que usted y el equipo lo encuentren útil. Comparta calificaciones o hallazgos promedio (anónimos) con el equipo e inclúyalos en cómo mejorar la situación.
...
¡Felicitaciones, has llegado al final! Espero que esta publicación sea un poco útil para usted como especialista o gerente de Data Science.
Pasamos por mucho, aquí hay una breve lista:
Parte I: Ciencia de datos en la vida real
1.1. La complejidad aumenta el valor, comience con simple
1.2. Siempre tenga un modelo base
1.3. Usa los datos que tienes
1.4. Hacerse cargo de los datos
1.5. Olvida los datos
1.6. Desarrollar una comprensión detallada de la causalidad.
Parte II: Gestión del equipo de ciencia de datos
2.1. El equipo de Data Science no es realmente un equipo
2.2. Incruste a profesionales de la ciencia de datos en otros equipos
2.3. Hacerse cargo de la productividad analítica
2.4. Datos -> Poder -> Política
2.5. Use sus recursos, luche por un alto retorno de la inversión
2.6. OKR para enfoque y alineación
2.7. En primer lugar, la seguridad psicológica.
...
Gracias por leer! Si esto fue útil, considera compartir esta publicación con otros. Espero algún día ver tus propios pensamientos sobre trabajar como especialista o gerente de ciencia de datos