Hola a todos! Mi nombre es Misha Kamenshchikov, me dedico a la ciencia de datos y al desarrollo de microservicios en el equipo de recomendaciones de Avito. En este artículo, hablaré sobre nuestras recomendaciones para anuncios similares y cómo los mejoramos con bandidos multibrazos. Hice una presentación sobre este tema en la conferencia Highload ++ Siberia y en el evento "Data & Science: Marketing" .

Bosquejo del artículo
Recomendaciones sobre Avito
Primero, una breve descripción de todos los tipos de recomendaciones que se encuentran en Avito.
Recomendaciones personalizadas de elementos de usuario
Las recomendaciones de elementos de usuario se basan en las acciones del usuario y están diseñadas para ayudarlo a encontrar rápidamente el producto de interés o mostrar algo potencialmente interesante. Se pueden ver en la página principal del sitio y las aplicaciones o en las listas de correo. Para crear tales recomendaciones, utilizamos dos tipos de modelos: fuera de línea y en línea.
Los modelos fuera de línea se basan en algoritmos de factorización de matriz que se entrenan en todos los datos en unos pocos días, y las recomendaciones se almacenan en un repositorio rápido para su distribución a los usuarios. Los modelos en línea consideran recomendaciones sobre la marcha utilizando el contenido de los anuncios del historial del usuario. La ventaja de los modelos fuera de línea es que proporcionan recomendaciones más precisas y de alta calidad, pero no tienen en cuenta las últimas acciones de los usuarios que podrían ocurrir durante el entrenamiento del modelo, cuando se reparó la muestra de entrenamiento. Los modelos en línea responden inmediatamente a las acciones del usuario, y las recomendaciones pueden cambiar con cada acción.
Recomendaciones de arranque en frío
Todos los sistemas de recomendación tienen el llamado problema de "arranque en frío". Su significado es que los modelos descritos anteriormente no pueden dar recomendaciones a un nuevo usuario sin un historial de acciones. En tales casos, es mejor familiarizar al usuario con lo que está en el sitio, al tiempo que elige no solo anuncios aleatorios, sino, por ejemplo, anuncios de categorías que son populares en la región del usuario.
Buscar recomendaciones
Para los usuarios que a menudo usan la búsqueda, hacemos accesos directos recomendados para la búsqueda: envían al usuario a una categoría específica y establecen filtros. Dichas recomendaciones se pueden encontrar en la parte superior de la página principal de la aplicación.
Ítem-Ítem Recomendaciones
Las recomendaciones de artículos se presentan en el sitio en forma de anuncios similares en la tarjeta del producto. Se pueden ver en todas las plataformas bajo la descripción del anuncio. Actualmente, el modelo de recomendación es exclusivamente de contenido y no utiliza información sobre las acciones de los usuarios, por lo que podemos recoger de inmediato anuncios similares entre los anuncios activos en el sitio para un nuevo anuncio. Más adelante en el artículo hablaré sobre este tipo particular de recomendación.
Más detalladamente sobre todo tipo de recomendaciones sobre Avito ya escribimos en nuestro blog. Lee si te interesa.
Anuncios similares
Así es como se ve un bloque con anuncios similares:

Este tipo de recomendación apareció en primer lugar en el sitio, y la lógica se implementó en el motor de búsqueda Sphinx . De hecho, este modelo es una combinación lineal de varios factores: coincidencia de palabras, distancia, diferencia de precio y otros parámetros.
Según los parámetros del anuncio de destino, se genera una solicitud en Sphinx, y los rangos integrados se utilizan para la clasificación.
Solicitar ejemplo:
SELECT id, weight as ranker_weight, ranker_weight * 10 + (metro_id=42) * 5 + (location_id=2525) * 10 + (110000 / (abs(price - 1100000) + 110000)) * 5 as rel FROM items WHERE MATCH('@title |scott|scale|700|premium') AND microcat_id=100 ORDER BY rel DESC, sort_time DESC LIMIT 0,32 OPTION max_matches=32, ranker=expr('sum(word_count)')
Si intentas describir este enfoque de manera más formal, entonces puedes imaginar a los rankeadores en forma de algunos pesos y parámetros de anuncios (la fuente es el anuncio original) y (anuncio dirigido). Para cada uno de los parámetros, introducimos la función de similitud . Pueden ser binarios (por ejemplo, la coincidencia de la ciudad del anuncio), pueden ser discretos (la distancia entre los anuncios) y continuos (por ejemplo, la diferencia relativa en el precio). Luego, para dos anuncios, el puntaje final se expresará mediante la fórmula
Con el motor de búsqueda, puede leer rápidamente el valor de esta fórmula para un número suficientemente grande de anuncios y clasificar la entrega en tiempo real.
Este enfoque se mostró bastante bien en su forma original, pero tenía inconvenientes significativos.
Problemas de aproximación
En primer lugar, los pesos se seleccionaron inicialmente de manera experta y no estaban en duda. A veces hubo cambios en los pesos, pero se hicieron sobre la base de una retroalimentación puntual, y no sobre la base de un análisis del comportamiento del usuario en general.
En segundo lugar, los pesos estaban codificados en el sitio, y hacer cambios a ellos era muy inconveniente.
Paso hacia la automatización
El primer paso para mejorar el modelo de recomendación fue la eliminación de toda la lógica en un microservicio separado en Python. Este servicio ya pertenecía por completo a nuestro equipo de recomendaciones, y podíamos realizar experimentos con bastante frecuencia.
Cada experimento puede caracterizarse por la llamada "configuración", un conjunto de pesos para los rankeadores. Queremos generar configuraciones y elegir la mejor en función de las acciones del usuario. ¿Cómo se pueden generar estas configuraciones?
La primera opción, que fue desde el principio, es la generación experta de configuraciones. Es decir, utilizando el conocimiento del área temática, suponemos que, por ejemplo, al buscar un automóvil, las personas están interesadas en opciones cercanas en precio a las que están viendo, y no solo en modelos similares, que pueden costar mucho más.
La segunda opción son las configuraciones aleatorias. Establecemos algún tipo de distribución para cada uno de los parámetros y luego simplemente tomamos una muestra de esta distribución. Este método es más rápido porque no necesita pensar en cada uno de los parámetros para todas las categorías.
Una opción más complicada es usar algoritmos genéticos. Sabemos cuál de las configuraciones nos da el mejor efecto en términos de acciones del usuario, por lo que en cada iteración podemos dejarlas y agregar nuevas: aleatorias o expertas.
Una opción aún más compleja, que requiere una larga historia de experimentos satisfechos, es el uso del aprendizaje automático. Podemos representar un conjunto de parámetros como un vector de características y una métrica objetivo como una variable objetivo. Luego encontraremos un conjunto de parámetros que, de acuerdo con la evaluación del modelo, maximizarán nuestra métrica objetivo.
En nuestro caso, nos decidimos por los dos primeros enfoques, así como por algoritmos genéticos en la forma más simple: dejamos lo mejor, eliminamos lo peor.
Ahora llegamos a la parte más interesante del artículo: podemos generar configuraciones, pero ¿cómo realizar experimentos para que sea rápido y eficiente?
La experimentación
El experimento se puede realizar en el formato de la prueba A / B / ... Para hacer esto, necesitamos generar N configuraciones, esperar resultados estadísticamente significativos y, finalmente, seleccionar la mejor configuración. Esto puede llevar bastante tiempo y, a lo largo de la prueba, un grupo fijo de usuarios puede recibir recomendaciones de baja calidad; con la generación aleatoria de configuraciones esto es bastante posible. Además, si queremos agregar alguna nueva configuración al experimento, tendremos que reiniciar la prueba nuevamente. Pero queremos realizar experimentos rápidamente, para poder cambiar las condiciones del experimento. Y para que los usuarios no sufran configuraciones deliberadamente malas. Los bandidos de muchos brazos nos ayudarán con esto.
Bandidos multi-armados
El nombre del método proviene de los "bandidos de un solo brazo": máquinas tragamonedas en un casino con una palanca para que pueda tirar y obtener una victoria. Imagina que estás en una habitación con una docena de estas máquinas y tienes N intentos gratuitos para jugar en cualquiera de ellas. Por supuesto, desea ganar más dinero, pero no sabe de antemano qué máquina le da la mayor ganancia. El problema con los bandidos con muchos brazos radica precisamente en encontrar la máquina más rentable con pérdidas mínimas (jugar en máquinas desventajosas).
Si formulamos esto en términos de nuestra tarea de recomendaciones, resulta que las máquinas son configuraciones, cada intento es una elección de una configuración para generar recomendaciones, y la ganancia es una métrica objetivo dependiendo de los comentarios del usuario.
La ventaja de los bandidos sobre las pruebas A / B / ...
Su principal ventaja es que nos permiten cambiar la cantidad de tráfico dependiendo del éxito de una configuración particular. Esto simplemente resuelve el problema de que las personas recibirán malas recomendaciones durante todo el experimento. Si no hacen clic en las recomendaciones, el bandido entenderá esto rápidamente y no elegirá esta configuración. Además, siempre podemos agregar una nueva configuración al experimento o simplemente eliminar una de las actuales. Todo junto nos da la flexibilidad para realizar experimentos y resuelve los problemas del enfoque con pruebas A / B / ...

Estrategias de gángster
Hay muchas estrategias para resolver el problema de los bandidos con múltiples brazos. A continuación, describiré varias clases de estrategias fáciles de implementar que intentamos aplicar en nuestra tarea. Pero primero debe comprender cómo comparar la efectividad de las estrategias. Si sabemos de antemano qué bolígrafo proporciona la máxima ganancia, la estrategia óptima siempre será tirar de este bolígrafo. Fijamos el número de pasos y calculamos la recompensa óptima . Para la estrategia, también contaremos la recompensa. e introducir el concepto :
Se pueden comparar otras estrategias solo con este valor. Noto que las estrategias tienen una naturaleza de cambio
puede ser diferente, y una estrategia puede ser mejor para un pequeño número de pasos, y otra para uno grande.
Estrategias codiciosas
Como su nombre indica, las estrategias codiciosas se basan en un principio simple: siempre elija el bolígrafo que, en promedio, ofrece la mayor recompensa. Las estrategias de esta clase difieren en cómo exploramos el entorno para determinar esta misma pluma. Hay, por ejemplo, estrategia Ella tiene un parámetro: , que determina la probabilidad con la que elegimos no el mejor bolígrafo, sino aleatorio, explorando así nuestro entorno. También puede reducir la probabilidad de investigación con el tiempo. Esta estrategia se llama . Las estrategias codiciosas son muy fáciles de implementar y comprensibles, pero no siempre son efectivas.
UCB1
Esta estrategia es completamente determinista: la pluma se determina de manera única a partir de la información actualmente disponible. Aquí está la fórmula:
Parte de la fórmula con
significa el medio del j-th pen y es responsable de la explotación, al igual que en las estrategias codiciosas. La segunda parte de la fórmula es responsable de la exploración,
Es el número total de acciones
- el número de acciones del j-th pen. Hay una estimación probada para esta estrategia en
. Puedes leer sobre esto
aquí .
Thompson Sampling
En esta estrategia, asignamos una distribución aleatoria a cada bolígrafo, y en cada paso tomamos muestras de un número de esta distribución, eligiendo un bolígrafo de acuerdo con el máximo. En función de los comentarios, actualizamos los parámetros de distribución para que los mejores corrales correspondan a una distribución con un gran promedio, y su dispersión disminuye con el número de acciones. Puede leer más sobre esta estrategia en un excelente artículo .
Comparación de estrategia
Simulemos las estrategias descritas anteriormente en un entorno artificial con tres manijas, cada una de las cuales corresponde a una distribución de Bernoulli con un parámetro en consecuencia Nuestras estrategias:
- con ;
- UCB1;
- Thompson Beta Sampling
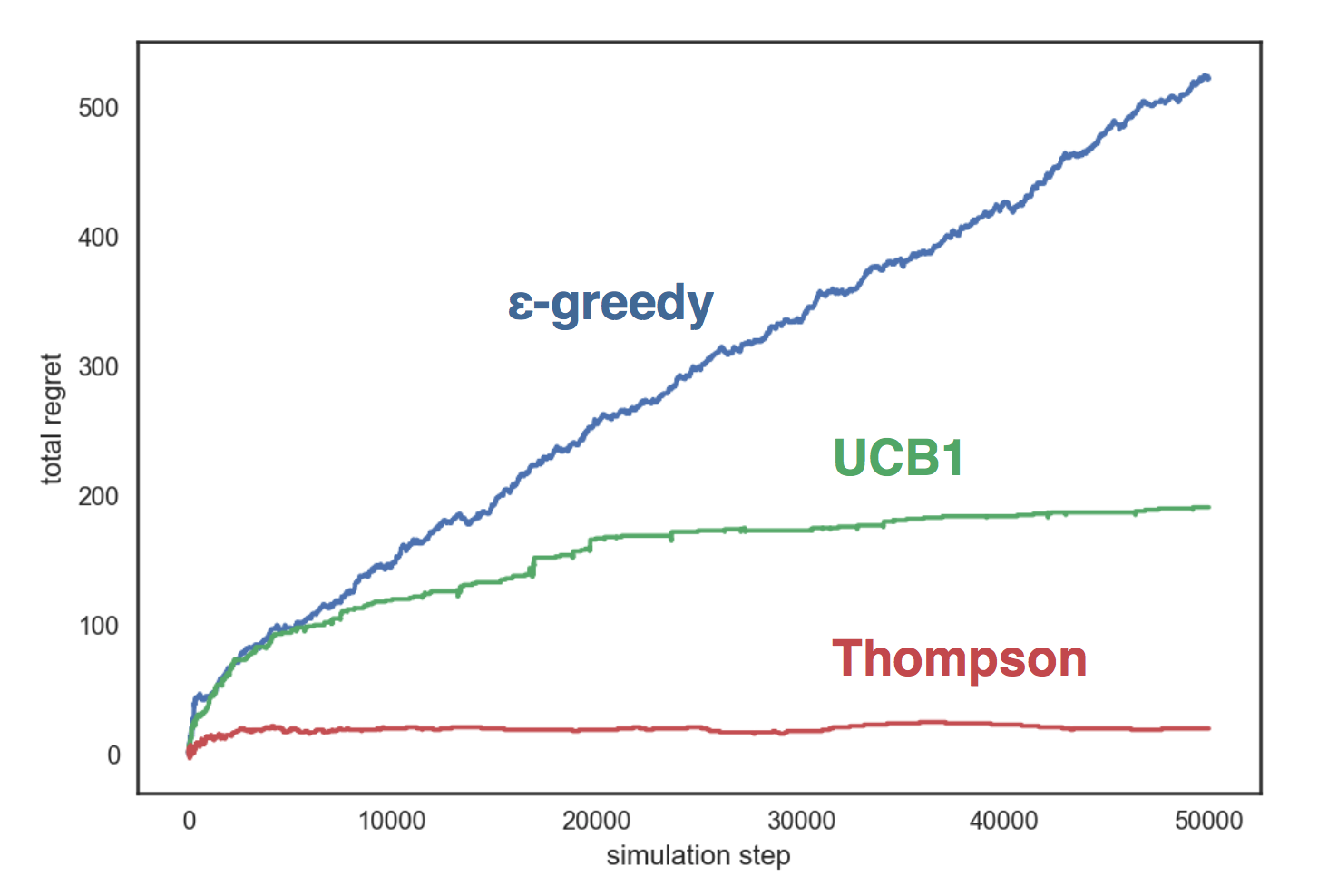
El gráfico muestra que la estrategia codiciosa crece linealmente, y en las otras dos estrategias, logarítmicamente, y el muestreo de Thompson se muestra mucho mejor que los demás y ella Casi no crece con el número de pasos.
El código de comparación está disponible en GitHub .
Te presenté a los bandidos multi-armados y ahora puedo decirte cómo los usamos.
Bandidos multi-armados en Avito
Entonces, tenemos varias configuraciones (conjuntos de parámetros), y queremos elegir la mejor de ellas con la ayuda de bandidos con múltiples brazos. Para que los bandidos aprendan, necesitamos un detalle importante: los comentarios de los usuarios. Al mismo tiempo, la elección de acciones en las que estamos capacitados debe corresponder a nuestros objetivos: quiero que los usuarios realicen más transacciones con mejores recomendaciones.
Elige acciones objetivo
El primer enfoque para la selección de acciones específicas fue bastante simple e ingenuo. Como la métrica objetivo, elegimos la cantidad de vistas, y los bandidos aprendieron cómo optimizar bien esta métrica. Pero había un problema: más vistas no siempre son buenas. Por ejemplo, en la categoría "Auto", logramos aumentar la cantidad de visitas en un 15%, pero al mismo tiempo la cantidad de solicitudes de contacto se redujo aproximadamente en la misma cantidad. Tras un examen más detallado, resultó que los bandidos eligieron un bolígrafo en el que el filtro por región estaba apagado. Por lo tanto, el bloque mostró anuncios de toda Rusia, donde la elección de anuncios similares, por supuesto, es mayor. Esto provocó un aumento en el número de visitas: externamente, las recomendaciones parecían ser de mejor calidad, pero cuando ingresaron la tarjeta del producto, las personas se dieron cuenta de que el automóvil estaba muy lejos de ellas y no hicieron una solicitud de contacto.
El segundo enfoque es aprender cómo convertir de ver un bloque a una solicitud de contacto. Este enfoque parecía mejor que el anterior, aunque solo sea porque esta métrica es casi directamente responsable de la calidad de las recomendaciones. Pero apareció otro problema: la estacionalidad diaria. Dependiendo de la hora del día, los valores de conversión pueden diferir en cuatro (!) Veces (esto es a menudo más que el efecto de una mejor configuración), y el bolígrafo que tuvo la suerte de ser seleccionado en el primer intervalo con una alta conversión continuó seleccionándose con más frecuencia que otros.
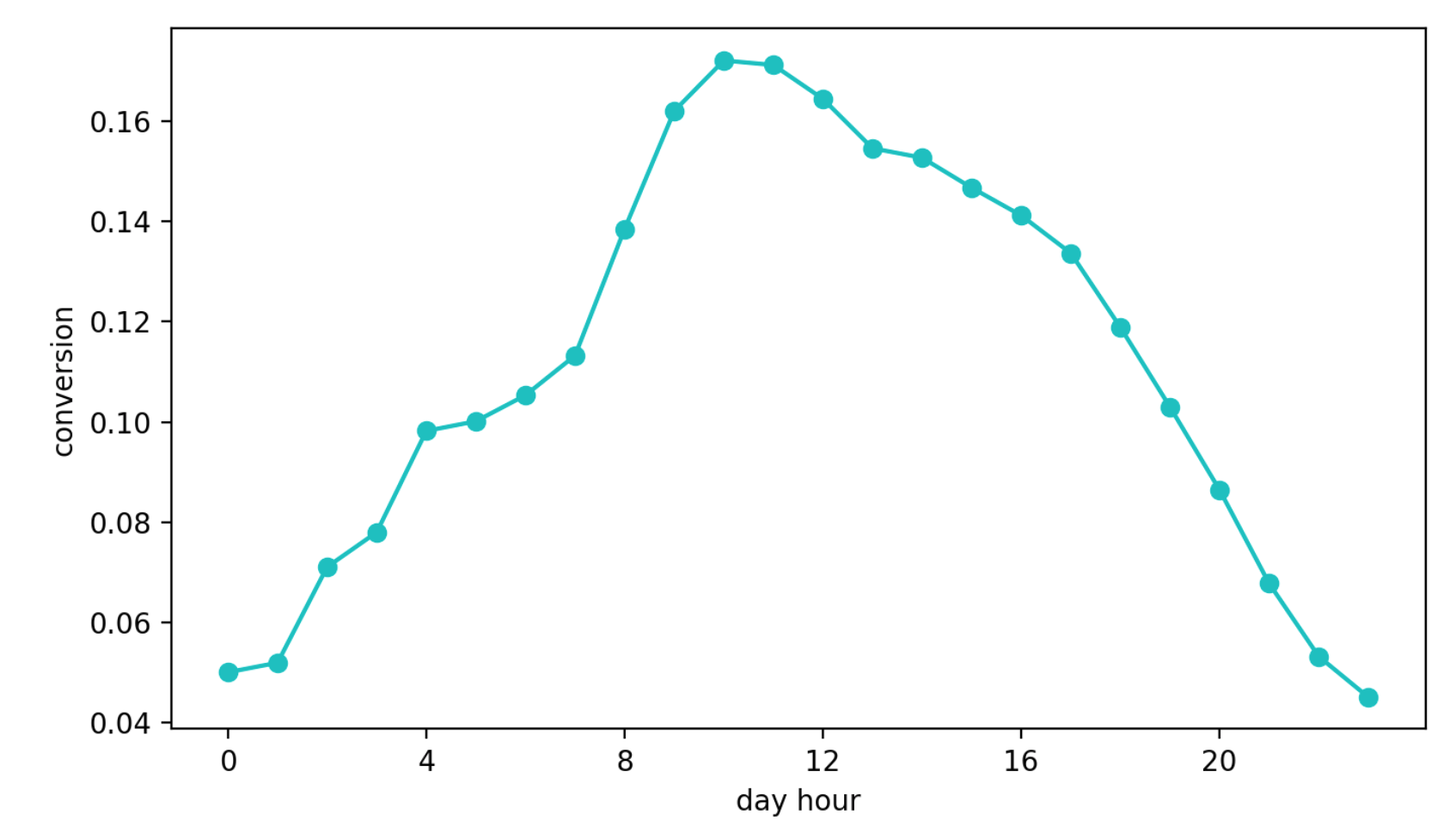
Dinámica de conversión diaria (valores del eje Y modificados)
Finalmente, el tercer enfoque. Lo usamos ahora. Seleccionamos el grupo de referencia, que siempre recibe recomendaciones sobre el mismo algoritmo y no está sujeto a la influencia de los bandidos. A continuación, observamos el número absoluto de contactos en nuestro grupo objetivo y referencia. Su relación no está sujeta a la estacionalidad, ya que seleccionamos el grupo de referencia al azar, y este enfoque se basa convenientemente en el muestreo de Thompson.
Nuestra estrategia
Distinguimos los grupos objetivo y de referencia, como se describió anteriormente. Luego inicialice N manejadores (cada uno de ellos corresponde a una configuración) con distribución beta
En cada paso:
- para cada bolígrafo, tomamos muestras de un número de la distribución correspondiente y seleccionamos el bolígrafo de acuerdo con el máximo;
- contar el número de acciones en grupos y durante un cierto tiempo (en nuestro caso son 10 segundos) y actualice los parámetros de distribución para el bolígrafo seleccionado: , .
Con esta estrategia, optimizamos la métrica que necesitamos, la cantidad de solicitudes de contacto en el grupo objetivo y evitamos los problemas que describí anteriormente. Además, en la prueba global A / B, este enfoque mostró los mejores resultados.
Resultados
La prueba global A / B se organizó de la siguiente manera: todos los anuncios se dividen aleatoriamente en dos grupos. A los anuncios de uno de ellos mostramos recomendaciones con la ayuda de bandidos, y al otro, con el antiguo algoritmo experto. Luego medimos el número de solicitudes de contacto de conversión en cada uno de los grupos (solicitudes realizadas después de cambiar a anuncios del bloque similar). En promedio, en todas las categorías, un grupo con bandidos recibe aproximadamente un 10% más de acciones específicas que el control, pero en algunas categorías esta diferencia puede alcanzar el 30%.
Y la plataforma creada le permite cambiar rápidamente la lógica, agregar configuraciones a los bandidos y validar hipótesis.
Si tiene preguntas sobre nuestro servicio de recomendación o sobre bandidos multi-armados, pregúnteles en los comentarios. Estaré encantado de responder.