Hasta hace poco, en Odnoklassniki, se almacenaban alrededor de 50 TB de datos en tiempo real en SQL Server. Para tal volumen, es casi imposible proporcionar acceso al centro de datos rápido, confiable e incluso a prueba de fallas utilizando SQL DBMS. Por lo general, en tales casos utilizan uno de los repositorios NoSQL, pero no todo se puede transferir a NoSQL: algunas entidades requieren garantías de transacciones ACID.
Esto nos llevó a usar el almacenamiento NewSQL, es decir, un DBMS que proporciona tolerancia a fallas, escalabilidad y rendimiento de los sistemas NoSQL, pero al mismo tiempo conserva las garantías ACID familiares para los sistemas clásicos. Hay pocos sistemas industriales en funcionamiento en esta nueva clase, por lo que implementamos dicho sistema nosotros mismos y lo pusimos en funcionamiento comercial.
Cómo funciona y qué sucedió: lea debajo del corte.
Hoy, la audiencia mensual de Odnoklassniki es de más de 70 millones de visitantes únicos. Estamos
entre las cinco redes sociales más grandes del mundo y los veinte sitios en los que los usuarios pasan la mayor parte del tiempo. La infraestructura "OK" maneja cargas muy altas: más de un millón de solicitudes HTTP / segundo para los frentes. Partes de la flota de servidores en la cantidad de más de 8000 piezas se encuentran cerca unas de otras, en cuatro centros de datos de Moscú, lo que permite una latencia de red de menos de 1 ms entre ellas.
Hemos estado usando Cassandra desde 2010, comenzando con la versión 0.6. Hoy, varias docenas de grupos están en funcionamiento. El clúster más rápido procesa más de 4 millones de operaciones por segundo, y el más grande almacena 260 TB.
Sin embargo, todos estos son clústeres NoSQL ordinarios utilizados para almacenar datos
débilmente consistentes . Pero queríamos reemplazar el almacenamiento consistente principal, Microsoft SQL Server, que se ha utilizado desde la fundación de Odnoklassniki. El almacenamiento consistió en más de 300 máquinas SQL Server Standard Edition, que contenían 50 TB de datos: entidades comerciales. Estos datos se modifican como parte de las transacciones ACID y requieren una
gran coherencia .
Para distribuir datos entre los nodos de SQL Server, utilizamos
particiones verticales y horizontales (fragmentación). Históricamente, utilizamos un esquema simple de fragmentación de datos: cada entidad estaba asociada a un token, una función de la ID de la entidad. Las entidades con el mismo token se colocaron en el mismo servidor SQL. La relación de tipo maestro-detalle se implementó para que los tokens de los registros principales y generados siempre coincidieran y estuvieran en el mismo servidor. En una red social, casi todos los registros se generan en nombre de un usuario, lo que significa que todos los datos del usuario dentro de un subsistema funcional se almacenan en un servidor. Es decir, las tablas de un servidor SQL casi siempre participaban en una transacción comercial, lo que hacía posible garantizar la consistencia de los datos utilizando transacciones ACID locales, sin la necesidad de transacciones ACID distribuidas
lentas y poco confiables .
Gracias a sharding y a acelerar SQL:
- No utilizamos restricciones de clave externa, ya que al fragmentar, la ID de entidad puede estar en otro servidor.
- No utilizamos procedimientos almacenados y disparadores debido a la carga adicional en la CPU DBMS.
- No utilizamos JOIN debido a todo lo anterior y a muchas lecturas aleatorias del disco.
- Fuera de una transacción, para reducir los puntos muertos, utilizamos el nivel de aislamiento Leer no comprometido.
- Realizamos solo transacciones cortas (en promedio, más cortas que 100 ms).
- No utilizamos UPDATE y DELETE de varias filas debido a la gran cantidad de puntos muertos; solo actualizamos un registro.
- Siempre ejecutamos consultas solo por índices: una consulta con un plan para un análisis completo de la tabla para nosotros significa una sobrecarga de la base de datos y su falla.
Estos pasos permitieron exprimir el rendimiento casi máximo de los servidores SQL. Sin embargo, los problemas se hicieron cada vez más. Miremos a ellos.
Problemas de SQL
- Como utilizamos fragmentos de propiedad, los administradores agregaron manualmente nuevos fragmentos. Todo este tiempo, las réplicas de datos escalables no respondieron a las solicitudes.
- A medida que aumenta el número de registros en la tabla, la velocidad de inserción y modificación disminuye, al agregar índices a una tabla existente, la velocidad cae varias veces, la creación y recreación de índices se produce con el tiempo de inactividad.
- Tener pocos Windows para SQL Server en producción dificulta la administración de su infraestructura
Pero el problema principal es
Tolerancia a fallos
El SQL Server clásico tiene poca tolerancia a fallas. Supongamos que solo tiene un servidor de base de datos y falla una vez cada tres años. En este momento, el sitio no funciona durante 20 minutos, esto es aceptable. Si tiene 64 servidores, entonces el sitio no funciona una vez cada tres semanas. Y si tiene 200 servidores, entonces el sitio no funciona todas las semanas. Esto es un problema
¿Qué se puede hacer para mejorar la resistencia de SQL Server? Wikipedia nos ofrece construir un
clúster altamente accesible : en caso de falla de cualquiera de los componentes, hay uno duplicado.
Esto requiere una flota de equipos caros: redundancia múltiple, fibra, almacenamiento compartido y la inclusión de una reserva no funciona de manera confiable: aproximadamente el 10% de las inclusiones fallan con un nodo de respaldo por el motor detrás del nodo principal.
Pero el principal inconveniente de un clúster tan accesible es la disponibilidad cero en caso de falla del centro de datos en el que se encuentra. Odnoklassniki tiene cuatro centros de datos, y necesitamos proporcionar trabajo en caso de un accidente completo en uno de ellos.
Para hacer esto, puede usar la replicación
Multi-Master integrada en SQL Server. Esta solución es mucho más costosa debido al costo del software y adolece de problemas bien conocidos con la replicación: demoras impredecibles en las transacciones durante la replicación síncrona y demoras en la aplicación de replicaciones (y, como resultado, modificaciones perdidas) durante la asincrónica. La
resolución manual implícita
de conflictos hace que esta opción sea completamente inaplicable para nosotros.
Todos estos problemas requerían una solución radical y procedimos a un análisis detallado de ellos. Aquí debemos familiarizarnos con lo que básicamente hace SQL Server: las transacciones.
Transacción simple
Considere la transacción más simple, desde el punto de vista de un programador SQL aplicado: agregar una foto a un álbum. Los álbumes y las fotos se almacenan en diferentes platos. El álbum tiene un contador público de fotos. Luego, dicha transacción se divide en los siguientes pasos:
- Bloqueamos el álbum por clave.
- Crea una entrada en la tabla de fotos.
- Si la foto tiene un estado público, entonces cerramos el contador público de fotos en el álbum, actualizamos el registro y confirmamos la transacción.
O en forma de pseudocódigo:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit();
Vemos que el escenario de transacción comercial más común es leer datos de la base de datos en la memoria del servidor de aplicaciones, cambiar algo y guardar los nuevos valores nuevamente en la base de datos. Por lo general, en dicha transacción actualizamos varias entidades, varias tablas.
Al ejecutar una transacción, puede ocurrir una modificación competitiva de los mismos datos de otro sistema. Por ejemplo, Antispam puede decidir que el usuario es sospechoso y, por lo tanto, todas las fotos del usuario ya no deberían ser públicas, deberían enviarse con moderación, lo que significa cambiar photo.status a otro valor y desenroscar los contadores correspondientes. Obviamente, si esta operación ocurre sin garantías de atomicidad de aplicación y aislamiento de modificaciones de la competencia, como en
ACID , el resultado no será lo que se necesita: el contador de fotos mostrará el valor incorrecto o no se enviarán todas las fotos para moderación.
Existe una gran cantidad de código similar que manipula varias entidades comerciales dentro del marco de una transacción durante toda la existencia de Odnoklassniki. Por la experiencia de migrar a NoSQL con
coherencia eventual, sabemos que las mayores dificultades (y costos de tiempo) son la necesidad de desarrollar código destinado a mantener la coherencia de los datos. Por lo tanto, consideramos el requisito principal para un nuevo repositorio para proporcionar transacciones ACID de lógica real para la lógica de la aplicación.
Otros requisitos igualmente importantes fueron:
- Si el centro de datos falla, tanto la lectura como la escritura en el nuevo almacenamiento deberían estar disponibles.
- Mantener la velocidad de desarrollo actual. Es decir, cuando se trabaja con un nuevo repositorio, la cantidad de código debería ser aproximadamente la misma, no debería ser necesario agregar algo al repositorio, desarrollar algoritmos para resolver conflictos, mantener índices secundarios, etc.
- La velocidad del nuevo almacenamiento debe ser lo suficientemente alta tanto al leer datos como al procesar transacciones, lo que efectivamente significa la inaplicabilidad de soluciones académicamente rigurosas, universales pero lentas, como, por ejemplo, los compromisos de dos fases .
- Autoescalado sobre la marcha.
- Usar servidores ordinarios y baratos, sin la necesidad de comprar piezas exóticas de hierro.
- Oportunidad de desarrollar almacenamiento por parte de los desarrolladores de la compañía. En otras palabras, se dio prioridad a sus propias soluciones basadas en código abierto, preferiblemente en Java.
Decisiones, Decisiones
Analizando posibles soluciones, llegamos a dos posibles opciones de arquitectura:
El primero es tomar cualquier servidor SQL e implementar la tolerancia a fallas necesaria, el mecanismo de escala, el clúster de conmutación por error, la resolución de conflictos y las transacciones ACID distribuidas, confiables y rápidas. Calificamos esta opción como altamente no trivial y consume mucho tiempo.
La segunda opción es tomar un repositorio NoSQL listo para usar con escalamiento implementado, un clúster de conmutación por error, resolución de conflictos e implementar transacciones y SQL nosotros mismos. A primera vista, incluso la tarea de implementar SQL, sin mencionar las transacciones ACID, parece una tarea durante años. Pero luego nos dimos cuenta de que el conjunto de características de SQL que usamos en la práctica está tan lejos de ANSI SQL como
Cassandra CQL está lejos de ANSI SQL. Echando un vistazo más de cerca a CQL, nos dimos cuenta de que estaba lo suficientemente cerca de lo que necesitábamos.
Cassandra y CQL
Entonces, ¿qué es lo interesante de Cassandra, qué capacidades tiene?
En primer lugar, aquí puede crear tablas con soporte para varios tipos de datos, puede hacer SELECCIONAR o ACTUALIZAR en la clave primaria.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?;
Para garantizar datos de réplica consistentes, Cassandra utiliza un
enfoque de quórum . En el caso más simple, esto significa que cuando se colocan tres réplicas de la misma fila en diferentes nodos del clúster, el registro se considera exitoso si la mayoría de los nodos (es decir, dos de cada tres) confirman el éxito de esta operación de escritura. Los datos de una serie se consideran consistentes si, al leer, la mayoría de los nodos fueron interrogados y confirmados. Por lo tanto, con la presencia de tres réplicas, se garantiza la consistencia de datos completa e instantánea en caso de falla de un nodo. Este enfoque nos permitió implementar un esquema aún más confiable: siempre enviar solicitudes a las tres réplicas, esperando la respuesta de las dos más rápidas. La respuesta tardía de la tercera réplica se descarta. Un nodo que llega tarde con una respuesta puede tener serios problemas: frenos, recolección de basura en la JVM, recuperación directa de memoria en el kernel de Linux, falla de hardware, desconexión de la red. Sin embargo, esto no afecta las operaciones o los datos del cliente.
El enfoque cuando recurrimos a tres nodos y obtenemos una respuesta de dos se llama
especulación : se envía una solicitud de comentarios adicionales incluso antes de que "se caiga".
Otra ventaja de Cassandra es Batchlog, un mecanismo que garantiza la aplicación completa o la no aplicación completa del paquete de cambios que realice. Esto nos permite resolver A en ACID - atomicidad fuera de la caja.
Lo más cercano a las transacciones en Cassandra son las llamadas "
transacciones ligeras ". Pero están lejos de ser transacciones "reales" de ACID: de hecho, es una oportunidad para hacer
CAS con datos de un solo registro, utilizando el consenso sobre el protocolo pesado de Paxos. Por lo tanto, la velocidad de tales transacciones es baja.
Lo que extrañamos en Cassandra
Entonces, tuvimos que implementar transacciones reales de ACID en Cassandra. Con lo cual podríamos implementar fácilmente otras dos características convenientes del DBMS clásico: índices rápidos consistentes, lo que nos permitiría realizar un muestreo de datos no solo en la clave primaria y el generador habitual de ID monótonas de incremento automático.
C * uno
Así nació el nuevo DBMS
C * One , que consta de tres tipos de nodos de servidor:
- Almacenamiento: los servidores Cassandra (casi) estándar responsables del almacenamiento de datos en unidades locales. A medida que aumenta la carga y la cantidad de datos, su número puede escalarse fácilmente a decenas o cientos.
- Coordinadores de transacciones: permite la ejecución de transacciones.
- Los clientes son servidores de aplicaciones que implementan operaciones comerciales e inician transacciones. Puede haber miles de tales clientes.
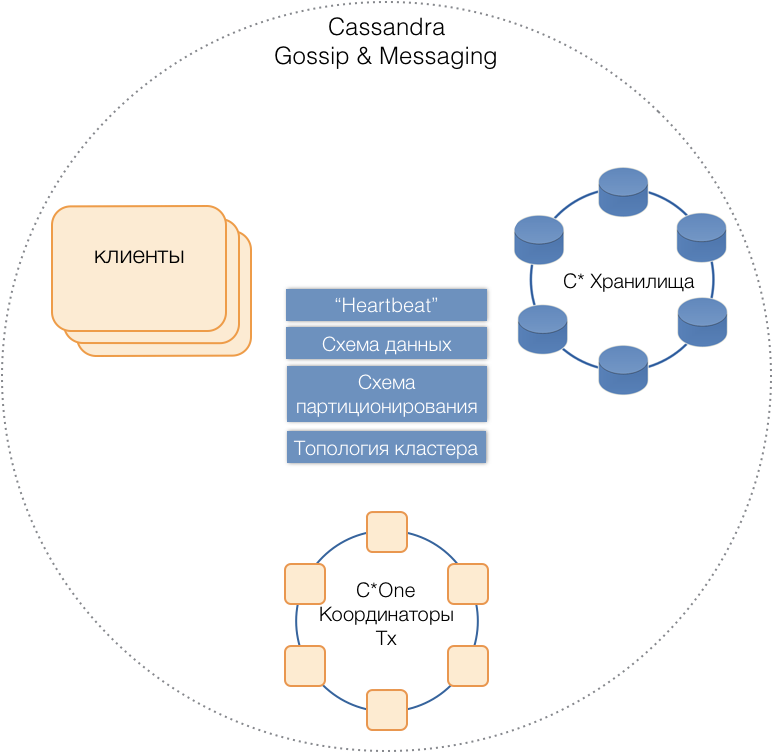
Todos los tipos de servidores están en un clúster común, use el protocolo de mensaje interno de Cassandra para comunicarse entre sí y
cotillee para intercambiar información del clúster. Con la ayuda de Heartbeat, los servidores aprenden sobre fallas mutuas, admiten un único esquema de datos: tablas, su estructura y replicación; esquema de partición, topología de clúster, etc.
Los clientes
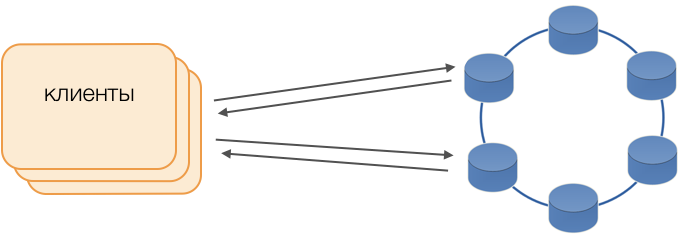
En lugar de los controladores estándar, se utiliza el modo Fat Client. Dicho nodo no almacena datos, pero puede actuar como coordinador de la ejecución de la consulta, es decir, el Cliente mismo realiza la función de coordinador de sus solicitudes: sondea los repositorios de réplica y resuelve los conflictos. Esto no solo es más confiable y más rápido que un controlador estándar que requiere comunicación con un coordinador remoto, sino que también le permite controlar la transferencia de solicitudes. Fuera de una transacción abierta en el cliente, las solicitudes se envían al almacenamiento. Si el cliente abrió la transacción, todas las solicitudes dentro de la transacción se envían al coordinador de transacciones.

C * Un coordinador de transacciones
El coordinador es lo que implementamos para C * One desde cero. Es responsable de administrar transacciones, bloqueos y el orden en que se aplican las transacciones.
Para cada transacción que se atiende, el coordinador genera una marca de tiempo: cada una posterior es mayor que la transacción anterior. Dado que el sistema de resolución de conflictos en Cassandra se basa en marcas de tiempo (de dos registros en conflicto, el actual con la última marca de tiempo se considera relevante), el conflicto siempre se resolverá a favor de la transacción posterior. Por lo tanto, implementamos
relojes Lamport , una forma económica de resolver conflictos en un sistema distribuido.
Cerraduras
Para garantizar el aislamiento, decidimos utilizar el método más simple: bloqueos pesimistas en la clave principal del registro. En otras palabras, en una transacción, el registro primero debe bloquearse, solo luego leerse, modificarse y guardarse. Solo después de una confirmación exitosa se puede desbloquear un registro para que las transacciones de la competencia puedan usarlo.
La implementación de este bloqueo es simple en un entorno no asignado. Hay dos formas principales en un sistema distribuido: implementar bloqueo distribuido en el clúster o distribuir transacciones para que las transacciones que involucran un solo registro sean atendidas siempre por el mismo coordinador.
Como en nuestro caso los datos ya están distribuidos por grupos de transacciones locales en SQL, se decidió asignar grupos de transacciones locales a los coordinadores: un coordinador realiza todas las transacciones con un token de 0 a 9, el segundo con un token de 10 a 19, y así sucesivamente. Como resultado, cada una de las instancias del coordinador se convierte en un maestro de grupo de transacciones.
Luego, los bloqueos se pueden implementar como un HashMap banal en la memoria del coordinador.
Fallas del coordinador
Dado que un coordinador atiende exclusivamente a un grupo de transacciones, es muy importante determinar rápidamente el hecho de su falla, de modo que se agote el tiempo de un intento repetido de ejecutar la transacción. Para hacerlo más rápido y confiable, aplicamos un protocolo de audición de quórum totalmente conectado:
Cada centro de datos tiene al menos dos nodos coordinadores. Periódicamente, cada coordinador envía un mensaje de latido a los otros coordinadores y les informa sobre su funcionamiento, así como los mensajes de latidos de los coordinadores en el grupo por última vez.

Después de recibir información similar de los demás en la composición de sus mensajes de latido, cada coordinador decide por sí mismo qué nodos del clúster funcionan y cuáles no, guiados por el principio del quórum: si el nodo X recibe información de la mayoría de los nodos del clúster sobre la recepción normal de mensajes del nodo Y, entonces , Y funciona. Por el contrario, tan pronto como la mayoría informa la pérdida de mensajes del nodo Y, Y ha fallado. Es curioso que si un quórum le dice al nodo X que no recibe más mensajes de él, entonces el propio nodo X considerará que ha fallado.
Los mensajes de latido se envían a una frecuencia alta, aproximadamente 20 veces por segundo, con un período de 50 ms. En Java, es difícil garantizar una respuesta de la aplicación de 50 ms debido a la duración comparable de las pausas causadas por el recolector de basura. Pudimos lograr dicho tiempo de respuesta utilizando el recolector de basura G1, que nos permite especificar el objetivo durante la duración de las pausas del GC. Sin embargo, a veces, muy raramente, la pausa del colector va más allá de 50 ms, lo que puede conducir a una falsa detección de falla. Para evitar esto, el coordinador no informa la falla del nodo remoto cuando el primer mensaje de latido desaparece de él, solo si varios desaparecen consecutivamente, por lo que logramos detectar la falla del nodo del coordinador en 200 ms.
Pero no es suficiente entender rápidamente qué nodo ha dejado de funcionar. Necesitas hacer algo al respecto.
Reserva
El esquema clásico supone que, en caso de que un maestro se niegue a lanzar una nueva elección utilizando uno de los
modernos algoritmos
universales . Sin embargo, tales algoritmos tienen problemas bien conocidos con la convergencia del tiempo y la duración del proceso electoral en sí. Logramos evitar tales demoras adicionales utilizando el circuito equivalente de coordinadores en una red totalmente conectada:
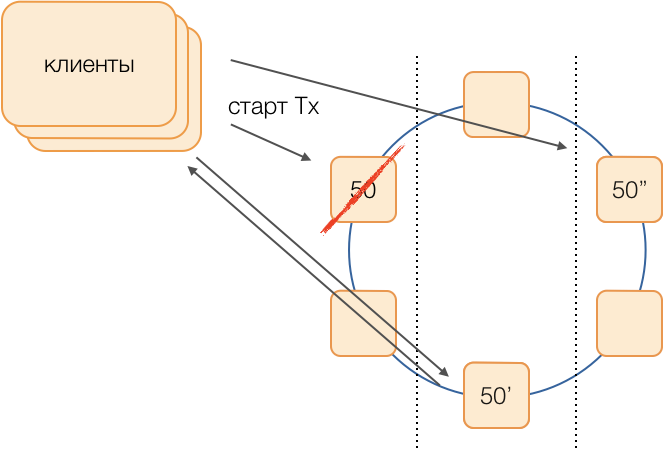
Supongamos que queremos ejecutar una transacción en el grupo 50. Determinaremos de antemano un esquema de sustitución, es decir, qué nodos ejecutarán transacciones del grupo 50 en caso de falla del coordinador principal. Nuestro objetivo es mantener el sistema operativo en caso de falla del centro de datos. Determinamos que la primera reserva será un nodo de otro centro de datos, y la segunda reserva será un nodo del tercero. Este esquema se selecciona una vez y no cambia hasta que la topología del clúster cambia, es decir, hasta que ingresan nuevos nodos (lo que ocurre muy raramente). El procedimiento para elegir un nuevo maestro activo en caso de falla del antiguo siempre será el siguiente: la primera reserva se convertirá en el maestro activo, y si ha dejado de funcionar, la segunda reserva se convertirá.
Tal esquema es más confiable que el algoritmo universal, ya que para activar un nuevo maestro es suficiente determinar el hecho del fracaso del antiguo.
Pero, ¿cómo entenderán los clientes cuál de los maestros está trabajando ahora? Durante 50 ms, no es posible enviar información a miles de clientes. Una situación es posible cuando un cliente envía una solicitud para abrir una transacción, aún sin saber que este asistente ya no funciona, y la solicitud se bloqueará en un tiempo de espera. Para evitar que esto suceda, los clientes envían una solicitud especulativa para abrir una transacción inmediatamente al maestro del grupo y sus dos reservas, pero solo el que es el maestro activo en este momento responderá a esta solicitud. El cliente llevará a cabo toda la comunicación posterior dentro de la transacción solo con el maestro activo.
Los maestros de respaldo reciben solicitudes de transacciones no propias en la cola de transacciones no nacidas, donde se almacenan durante algún tiempo. Si el maestro activo muere, el nuevo maestro procesa las solicitudes para abrir transacciones desde su cola y responde al cliente. Si el cliente ya ha logrado abrir una transacción con el maestro anterior, se ignora la segunda respuesta (y, obviamente, dicha transacción no se completará y el cliente la repetirá).
Cómo funciona una transacción
Supongamos que un cliente le envía al coordinador una solicitud para abrir una transacción para dicha entidad con una clave primaria. El coordinador bloquea esta entidad y la coloca en la tabla de bloqueo en la memoria. Si es necesario, el coordinador lee esta entidad de la tienda y almacena los datos recibidos en un estado de transacción en la memoria del coordinador.
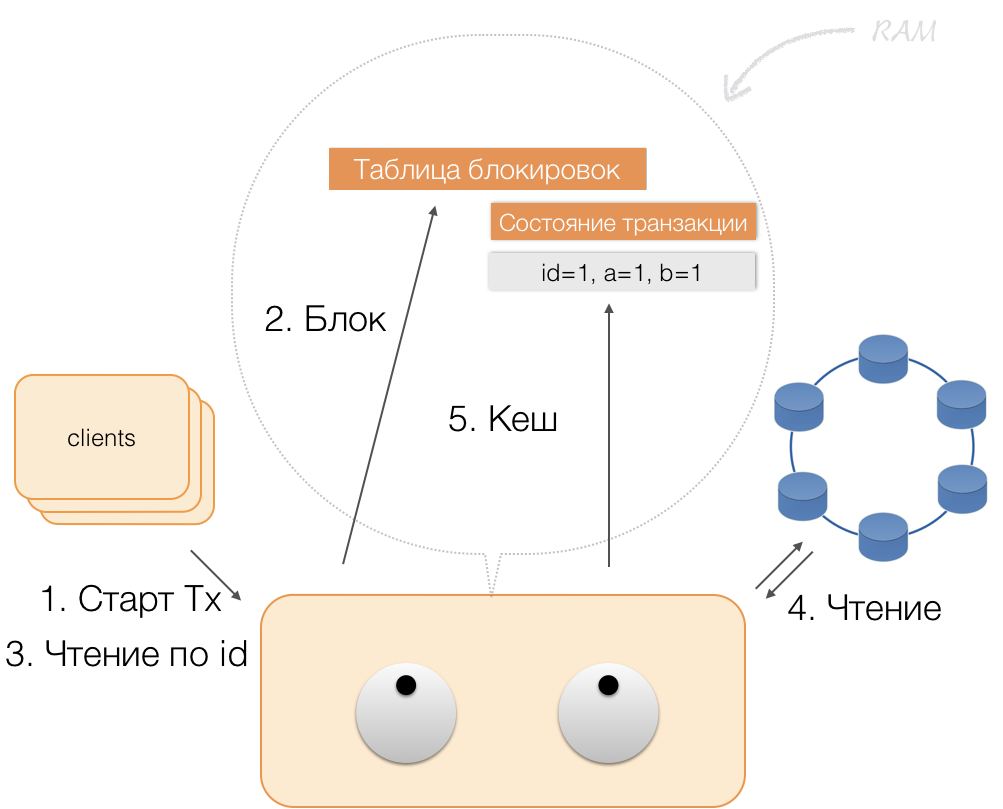
Cuando el cliente quiere cambiar los datos en la transacción, envía al coordinador una solicitud para actualizar la entidad, y coloca los nuevos datos en la tabla de estado de la transacción en la memoria. Esto completa la grabación: la grabación no se realiza en el repositorio.
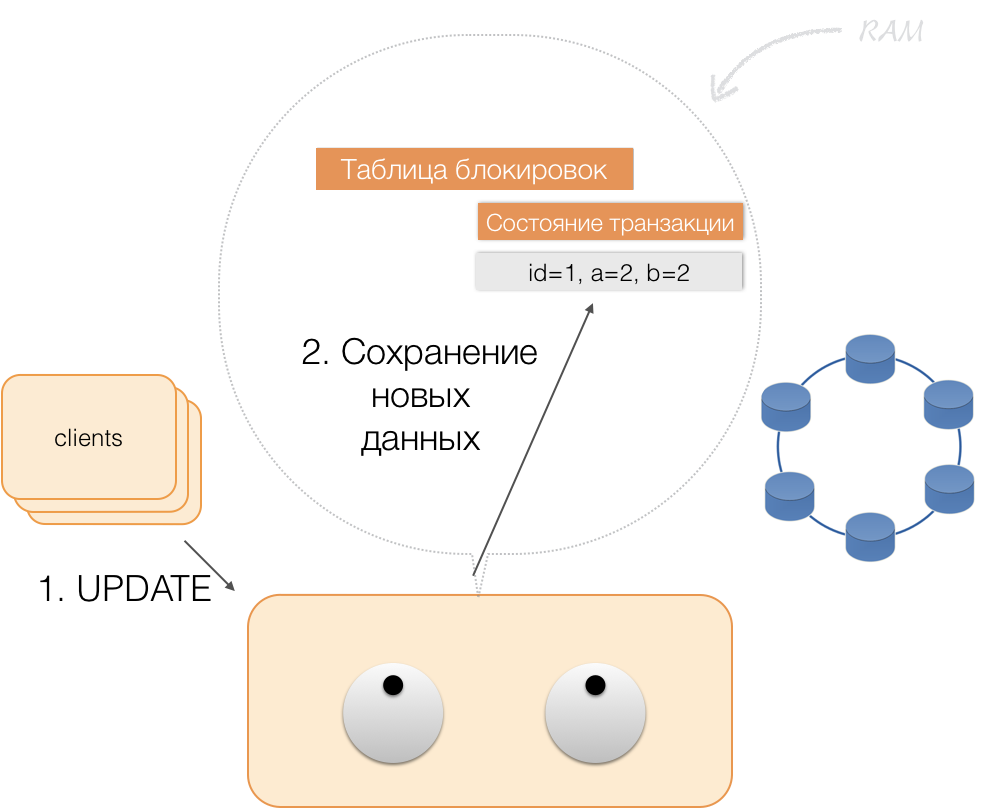
Cuando un cliente solicita, en el marco de una transacción activa, sus propios datos modificados, el coordinador actúa así:
- si la ID ya está en la transacción, los datos se toman de la memoria;
- Si no hay ID en la memoria, los datos que faltan se leen desde los nodos de almacenamiento, combinados con los que ya están en la memoria, y el resultado se devuelve al cliente.
Por lo tanto, el cliente puede leer sus propios cambios, mientras que otros clientes no ven estos cambios, ya que se almacenan solo en la memoria del coordinador, todavía no están en los nodos de Cassandra.
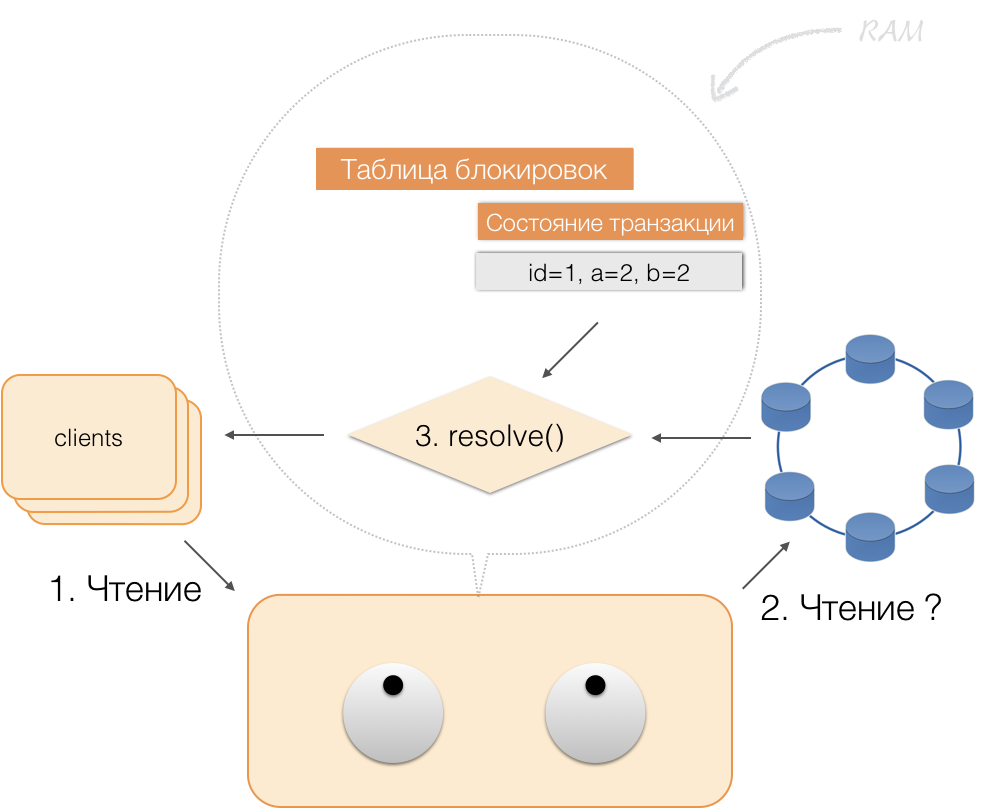
Cuando el cliente envía una confirmación, el coordinador guarda el estado en la memoria del servicio en el lote registrado, y ya en forma de lote registrado se envía a los repositorios de Cassandra. Los repositorios hacen todo lo necesario para que este paquete se aplique atómicamente (completamente) y devuelven una respuesta al coordinador, quien libera los bloqueos y confirma el éxito de la transacción al cliente.

Y para volver al coordinador, es suficiente para liberar la memoria ocupada por el estado de la transacción.
Como resultado de las mejoras anteriores, implementamos los principios de ACID:
- Atomicidad Esta es una garantía de que ninguna transacción se comprometerá parcialmente con el sistema, se completarán todas sus operaciones secundarias o no se ejecutará ninguna. Cumplimos con este principio debido al lote registrado en Cassandra.
- Coherencia Cada transacción exitosa, por definición, captura solo resultados aceptables. Si, después de abrir una transacción y realizar parte de las operaciones, se descubre que el resultado no es válido, se realiza una reversión.
- Aislamiento Cuando se ejecuta una transacción, las transacciones paralelas no deberían afectar su resultado. Las transacciones competidoras se aíslan utilizando bloqueos pesimistas en el coordinador. Para las lecturas fuera de la transacción, se respeta el principio de aislamiento en el nivel Compromiso de lectura.
- Sostenibilidad Independientemente de los problemas en los niveles inferiores (desenergización del sistema, falla del hardware,) los cambios realizados por una transacción completada con éxito deben permanecer guardados después de reanudar la operación.
Lectura de índice
Toma una tabla simple:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …)
Ella tiene una identificación (clave principal), propietario y fecha de cambio. Debe realizar una solicitud muy simple: seleccione los datos del propietario con la fecha de cambio "para el último día".
SELECT * WHERE owner=? AND modified>?
Para que una consulta de este tipo funcione rápidamente, en SQL DBMS clásico, debe crear un índice por columnas (propietario, modificado). ¡Podemos hacer esto de manera simple, ya que ahora tenemos garantías de ACID!
Índices en C * One
Hay una tabla fuente con fotos, en la que la identificación del registro es la clave principal.

Para el índice C *, One crea una nueva tabla, que es una copia del original. La clave coincide con la expresión de índice, y también incluye la clave primaria del registro de la tabla de origen:
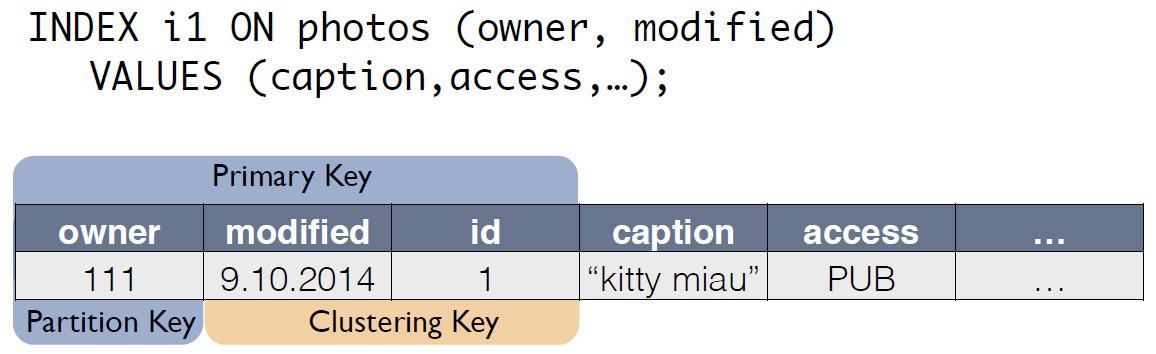
Ahora la solicitud de "propietario durante el último día" se puede volver a escribir como seleccionar de otra tabla:
SELECT * FROM i1_test WHERE owner=? AND modified>?
El coordinador mantiene automáticamente la coherencia de los datos de la tabla de fotos originales y el índice i1. Basándose únicamente en el esquema de datos, cuando se recibe el cambio, el coordinador genera y recuerda el cambio no solo en la tabla principal, sino también en los cambios de la copia. No se realizan acciones adicionales con la tabla de índice, los registros no se leen, los bloqueos no se utilizan. Es decir, agregar índices casi no consume recursos y prácticamente no afecta la velocidad de aplicación de modificaciones.
Usando ACID, pudimos implementar índices "como en SQL". Tienen consistencia, se pueden escalar, funcionan rápidamente, pueden ser compuestos e incorporados en el lenguaje de consulta CQL.
Para admitir índices, no es necesario realizar cambios en el código de la aplicación. Todo es simple, como en SQL. Y lo más importante, los índices no afectan la velocidad de ejecución de las modificaciones a la tabla de transacciones original.Que paso
Desarrollamos C * One hace tres años y lo pusimos en operación comercial.¿Qué obtuvimos al final? Vamos a evaluar esto usando el ejemplo de un subsistema para procesar y almacenar fotos, uno de los tipos de datos más importantes en una red social. No se trata de los cuerpos de las fotos en sí, sino de todo tipo de metainformación. Ahora en Odnoklassniki hay alrededor de 20 mil millones de tales registros, el sistema procesa 80 mil solicitudes de lectura por segundo, hasta 8 mil transacciones ACID por segundo asociadas con la modificación de datos.Cuando utilizamos SQL con factor de replicación = 1 (pero en RAID 10), la metainformación de la foto se almacenó en un clúster altamente accesible de 32 máquinas con Microsoft SQL Server (más 11 copias de seguridad). También asignó 10 servidores para almacenar copias de seguridad. Un total de 50 autos caros. Al mismo tiempo, el sistema funcionaba a carga nominal, sin reserva.Después de migrar al nuevo sistema, obtuvimos un factor de replicación = 3: una copia en cada centro de datos. El sistema consta de 63 nodos de almacenamiento Cassandra y 6 máquinas coordinadoras, con un total de 69 servidores. Pero estas máquinas son mucho más baratas, su costo total es aproximadamente el 30% del costo del sistema en SQL. En este caso, la carga se mantiene al 30%.Con la introducción de C * One, los retrasos también disminuyeron: en SQL, la operación de escritura tomó aproximadamente 4.5 ms. En C * One: aproximadamente 1,6 ms. La duración de la transacción es en promedio inferior a 40 ms, la confirmación se realiza en 2 ms, la duración de lectura y escritura es en promedio 2 ms. El percentil 99, solo 3-3,1 ms, el número de tiempos de espera disminuyó 100 veces, todo debido al uso generalizado de la especulación.Hasta la fecha, la mayoría de los nodos de SQL Server se han dado de baja; los nuevos productos se desarrollan solo con C * One. Adaptamos C * One para trabajar en nuestra nube única , lo que nos permitió acelerar la implementación de nuevos clústeres, simplificar la configuración y automatizar la operación. Sin el código fuente, sería mucho más difícil y hacer muletas.Ahora estamos trabajando para transferir nuestras otras instalaciones de almacenamiento a la nube, pero esta es una historia completamente diferente.