¿Qué requisitos debe cumplir el almacenamiento de metadatos para un servicio en la nube? Sí, no el más común, pero para empresas con soporte para centros de datos distribuidos geográficamente y Active-Active. Obviamente, el sistema debería escalar bien, ser
tolerante a fallas y desearía poder implementar una consistencia de operaciones personalizable.Solo Cassandra es adecuada para todos estos requisitos, y nada más es adecuado. Cabe señalar que Cassandra es realmente genial, pero trabajar con ella se parece a una montaña rusa.
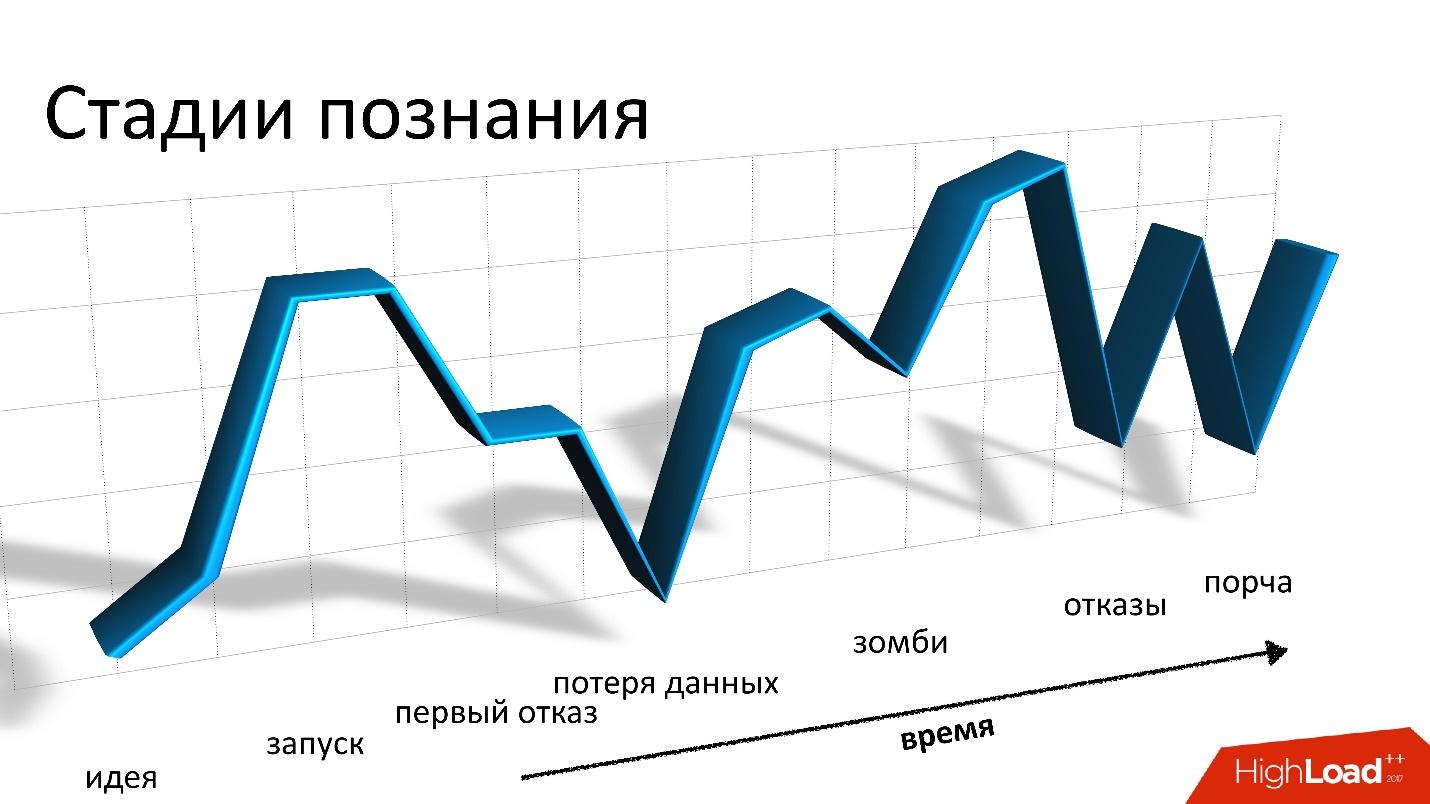
En un informe en Highload ++ 2017,
Andrei Smirnov (
smira ) decidió que no era interesante hablar sobre el bien, pero habló en detalle sobre cada problema que tuvo que enfrentar: sobre la pérdida de datos y la corrupción, sobre los zombis y la pérdida de rendimiento. Estas historias son una verdadera reminiscencia de la montaña rusa, pero para todos los problemas hay una solución, para la cual eres bienvenido.
Sobre el orador: Andrey Smirnov trabaja para Virtustream, una compañía que implementa almacenamiento en la nube para empresas. La idea es que, condicionalmente, Amazon hace la nube para todos, y Virtustream hace las cosas específicas que necesita una gran empresa.
Algunas palabras sobre Virtustream
Trabajamos en un pequeño equipo completamente remoto y estamos involucrados en una de las soluciones en la nube de Virtustream. Esta es una nube de almacenamiento de datos.

Hablando de manera muy simple, esta es una API compatible con S3 en la que puede almacenar objetos. Para aquellos que no saben qué es S3, es solo una API HTTP con la que puedes subir objetos a la nube en algún lugar, recuperarlos, eliminarlos, obtener una lista de objetos, etc. Además, características más complejas basadas en estas operaciones simples.
Tenemos algunas características distintivas que Amazon no tiene. Una de ellas son las llamadas georegiones. En la situación habitual, cuando crea un repositorio y dice que almacenará objetos en la nube, debe seleccionar una región. Una región es esencialmente un centro de datos, y sus objetos nunca abandonarán este centro de datos. Si algo le sucede, tus objetos ya no estarán disponibles.
Ofrecemos geo-regiones en las que los datos se ubican simultáneamente en varios centros de datos (DC), al menos en dos, como en la imagen. El cliente puede contactar con cualquier centro de datos, para él es transparente. Los datos entre ellos se replican, es decir, trabajamos en el modo Activo-Activo, y constantemente. Esto proporciona al cliente características adicionales, que incluyen:
- mayor confiabilidad de almacenamiento, lectura y escritura en caso de falla de CC o pérdida de conectividad;
- disponibilidad de datos incluso si uno de los DC falla;
- operaciones de redireccionamiento al DC "más cercano".
Esta es una oportunidad interesante, incluso si estos DC están geográficamente separados, entonces algunos de ellos pueden estar más cerca del cliente en diferentes momentos. Y acceder a los datos al DC más cercano es simplemente más rápido.
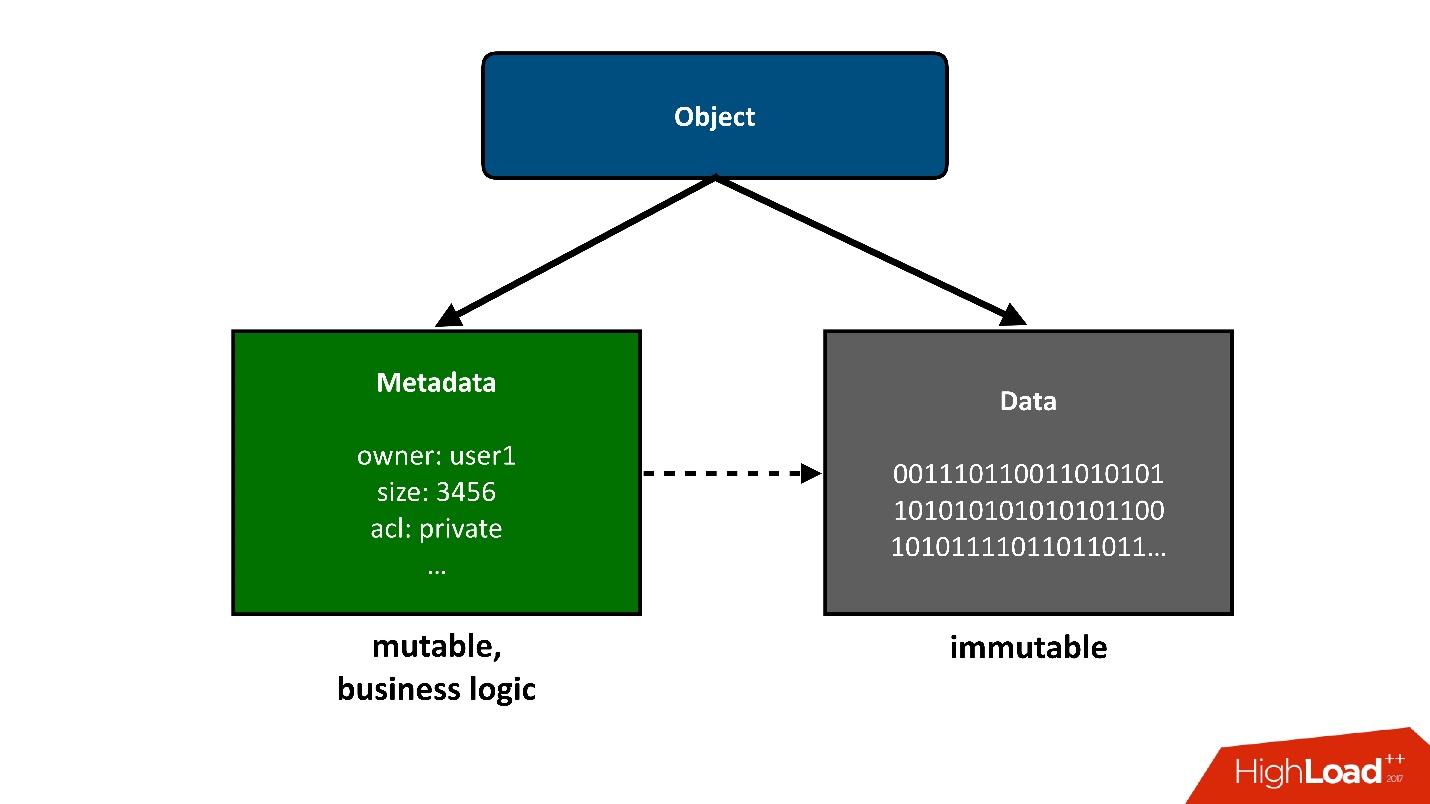
Para dividir la construcción de la que hablaremos en partes, presentaré los objetos que están almacenados en la nube como dos piezas grandes:
1. La primera pieza simple de un objeto son los
datos . No han cambiado, se descargaron una vez y eso es todo. Lo único que puede sucederles más tarde es que podemos eliminarlos si ya no son necesarios.
Nuestro proyecto anterior estaba relacionado con el almacenamiento de exabytes de datos, por lo que no tuvimos problemas con el almacenamiento de datos. Esto ya era una tarea resuelta para nosotros.
2.
Metadatos . Toda la lógica empresarial, todo lo más interesante, relacionado con la competencia: acceso, registros, reescrituras, en el área de metadatos.
Los metadatos sobre el objeto toman en sí la mayor complejidad del proyecto, los metadatos almacenan un puntero al bloque de datos almacenados del objeto.
Desde el punto de vista del usuario, este es un objeto único, pero podemos dividirlo en dos partes. Hoy
solo hablaré
sobre metadatos .
Figuras
- Datos : 4 Pbytes.
- Grupos de metadatos : 3.
- Objetos : 40 mil millones.
- Tamaño de metadatos : 160 TB (incluida la replicación).
- Velocidad de cambio (metadatos): 3000 objetos / s.
Si observa estos indicadores con cuidado, lo primero que llama la atención es el tamaño promedio muy pequeño del objeto almacenado. Tenemos muchos metadatos por unidad de volumen de datos maestros. Para nosotros no fue menos sorprendente que quizás para ti ahora.
Planeamos que tendríamos al menos un orden de datos, si no 2, más que metadatos. Es decir, cada objeto será significativamente más grande y la cantidad de metadatos será menor. Debido a que los datos son más baratos de almacenar, menos operaciones con ellos y los metadatos son mucho más caros tanto en el sentido del hardware como en el sentido de dar servicio y realizar varias operaciones en ellos.
Además, estos datos cambian a una velocidad bastante alta. He dado el valor pico aquí, el valor no pico no es mucho menor, pero, sin embargo, se puede obtener una carga bastante grande en puntos específicos en el tiempo.
Estas cifras ya se obtuvieron de un sistema en funcionamiento, pero volvamos un poco al diseño de almacenamiento en la nube.
Elegir un repositorio para metadatos
Cuando nos enfrentamos al desafío de que queremos tener geo-regiones, Active-Active, y necesitamos almacenar metadatos en algún lugar, pensamos que podría ser.
Obviamente, el repositorio (base de datos) debe tener las siguientes propiedades:
- Soporte activo-activo ;
- Escalabilidad.
Realmente nos gustaría que nuestro producto sea extremadamente popular, y no sabemos cómo crecerá al mismo tiempo, por lo que el sistema debería escalar.
- El equilibrio de tolerancia a fallos y fiabilidad de almacenamiento.
Los metadatos deben almacenarse de forma segura, porque si los perdemos y había un enlace a los datos en ellos, perderemos todo el objeto.
- Consistencia de operaciones personalizable.
Debido al hecho de que trabajamos en varios DC y permitimos la posibilidad de que los DC no estén disponibles, además, los DC están lejos unos de otros, no podemos, durante la mayoría de las operaciones API, exigir que esta operación se realice simultáneamente en dos DC Será demasiado lento e imposible si el segundo DC no está disponible. Por lo tanto, parte de las operaciones deberían funcionar localmente en un DC.
Pero, obviamente, algún tipo de convergencia debería ocurrir en algún momento, y después de resolver todos los conflictos, los datos deberían ser visibles en ambos centros de datos. Por lo tanto, la consistencia de las operaciones debe ser ajustada.
Desde mi punto de vista, Cassandra es adecuada para estos requisitos.
Cassandra
Estaría muy feliz si no tuviéramos que usar Cassandra, porque para nosotros fue una especie de experiencia nueva. Pero nada más es adecuado. Esto, me parece, es la situación más triste en el mercado para tales sistemas de almacenamiento, no hay
alternativa .

¿Qué es cassandra?
Esta es una base de datos distribuida de clave-valor. Desde el punto de vista de la arquitectura y las ideas que están incrustadas en ella, me parece que todo es genial. Si lo hiciera, haría lo mismo. Cuando comenzamos, pensamos en escribir nuestro propio sistema de almacenamiento de metadatos. Pero cuanto más lejos, más y más nos dimos cuenta de que tendríamos que hacer algo muy similar a Cassandra, y los esfuerzos que gastaremos en ello no valen la pena. Para todo el desarrollo
, solo tuvimos un mes y medio . Sería extraño gastarlos escribiendo su base de datos.
Si Cassandra estuviera en capas como un pastel de capas, seleccionaría 3 capas:
1.
Almacenamiento local de KV en cada nodo.Este es un grupo de nodos, cada uno de los cuales puede almacenar datos de valor clave localmente.
2.
Fragmentación de datos en nodos (hashing consistente).Cassandra puede distribuir datos entre los nodos del clúster, incluida la replicación, y lo hace de tal manera que el clúster puede crecer o disminuir de tamaño, y los datos se redistribuirán.
3. Un
coordinador para redirigir las solicitudes a otros nodos.Cuando accedemos a los datos para algunas consultas desde nuestra aplicación, Cassandra puede distribuir nuestra consulta en nodos para que obtengamos los datos que queremos y con el nivel de consistencia que necesitamos: queremos leerlos solo quórum, o quiere quórum con dos DC, etc.
Para nosotros, dos años con Cassandra, es una montaña rusa o una montaña rusa, lo que quieras. Todo comenzó en el fondo, no teníamos experiencia con Cassandra. Teníamos miedo Empezamos, y todo estuvo bien. Pero luego comienzan las caídas constantes y los despegues: el problema, todo está mal, no sabemos qué hacer, tenemos errores, luego resolvemos el problema, etc.
Estas montañas rusas, en principio, no terminan hasta el día de hoy.
Bueno
El primer y último capítulo, donde digo que Cassandra es genial. Es realmente genial, un gran sistema, pero si sigo diciendo lo bueno que es, creo que no te interesará. Por lo tanto, prestaremos más atención a lo malo, pero más tarde.
Cassandra es realmente buena.
- Este es uno de los sistemas que nos permite tener un tiempo de respuesta en milisegundos , es decir, obviamente menos de 10 ms. Esto es bueno para nosotros, porque el tiempo de respuesta en general es importante para nosotros. La operación con metadatos para nosotros es solo una parte de cualquier operación relacionada con el almacenamiento de un objeto, ya sea que esté recibiendo o grabando.
- Desde el punto de vista de la grabación, se logra una alta escalabilidad . Puede escribir en Cassandra a una velocidad loca, y en algunas situaciones esto es necesario, por ejemplo, cuando movemos grandes cantidades de datos entre registros.
- Cassandra es verdaderamente tolerante a fallas . La caída de un nodo no conduce inmediatamente a problemas, aunque tarde o temprano comenzarán. Cassandra declara que no tiene un solo punto de falla, pero, de hecho, hay puntos de falla en todas partes. De hecho, el que trabajó con la base de datos sabe que incluso un bloqueo de nodo no es algo que generalmente sufre hasta la mañana. Por lo general, esta situación debe repararse más rápido.
- Simplicidad Aún así, en comparación con otras bases de datos relacionales estándar de Cassandra, es más fácil entender lo que está sucediendo. Muy a menudo, algo sale mal y necesitamos entender lo que está sucediendo. Cassandra tiene más posibilidades de resolverlo, llegar al tornillo más pequeño, probablemente, que con otra base de datos.
Cinco malas historias
Repito, Cassandra es buena, funciona para nosotros, pero contaré cinco historias sobre lo malo. Creo que esto es para lo que lo leíste. Daré las historias en orden cronológico, aunque no están muy conectadas entre sí.

Esta historia fue la más triste para nosotros. Como almacenamos datos de usuarios, lo peor posible es perderlos y
perderlos para siempre , como sucedió en esta situación. Hemos proporcionado formas de recuperar datos si los perdemos en Cassandra, pero los perdimos para que realmente no pudiéramos recuperarlos.
Para explicar cómo sucede esto, tendré que hablar un poco sobre cómo se organiza todo dentro de nosotros.
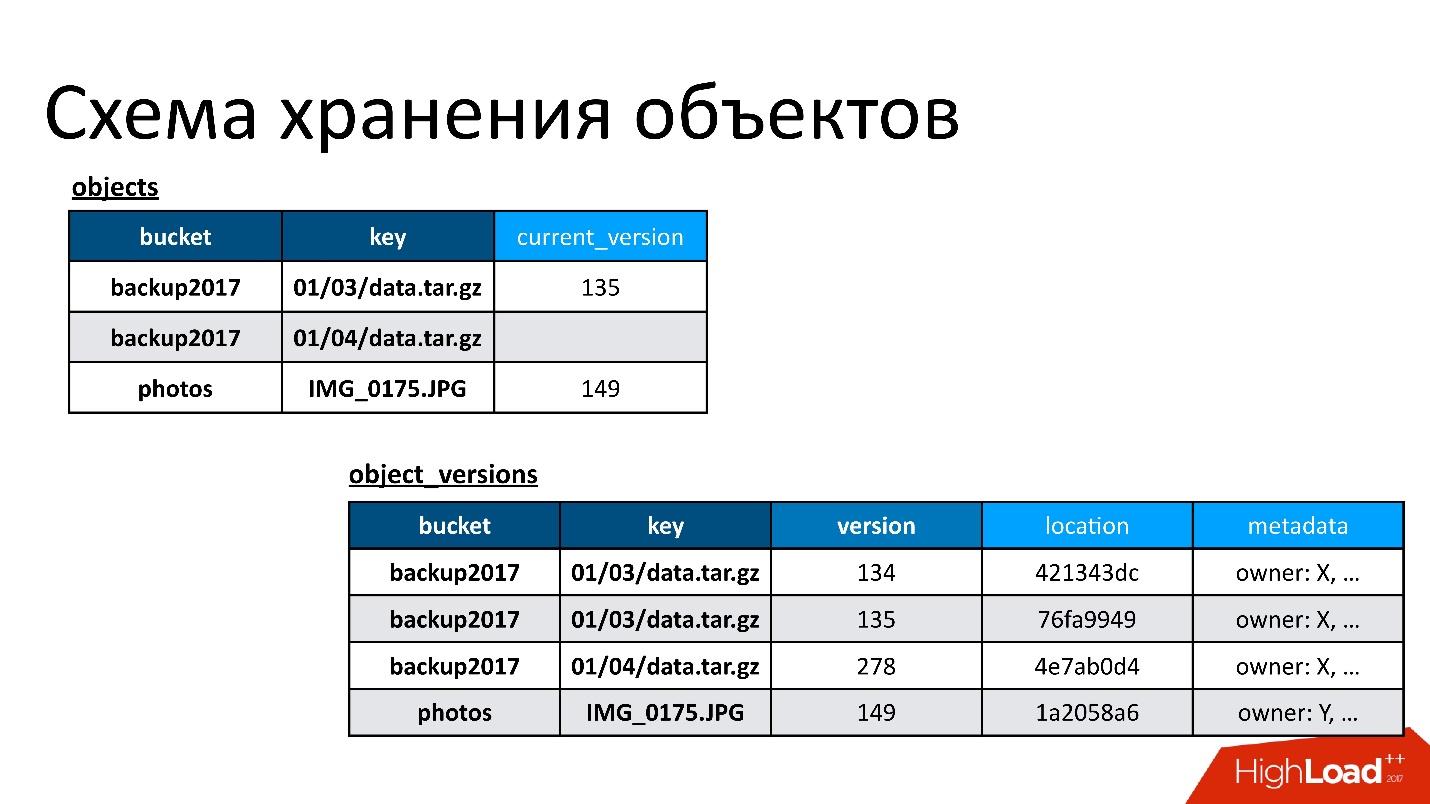
Desde una perspectiva S3, hay algunas cosas básicas:
- Bucket: se puede imaginar como un gran catálogo en el que el usuario carga un objeto (en adelante, el bucket).
- Cada objeto tiene un nombre (clave) y metadatos asociados: tamaño, tipo de contenido y un puntero a los datos del objeto. Al mismo tiempo, el tamaño del cubo no está limitado por nada. Es decir, pueden ser 10 claves, tal vez 100 mil millones de claves, no hay diferencia.
- Cualquier operación competitiva es posible, es decir, puede haber varios rellenos competitivos en la misma clave, puede haber eliminación competitiva, etc.
En nuestra situación, pueden ocurrir operaciones activo-activo, incluso competitivamente en diferentes DC, no solo en una. Por lo tanto, necesitamos algún tipo de esquema de conservación que nos permita implementar tal lógica. Al final, elegimos una política simple: gana la última versión registrada. A veces se realizan varias operaciones competitivas, pero no es necesario que nuestros clientes lo hagan a propósito. Puede ser solo una solicitud que comenzó, pero el cliente no esperó una respuesta, sucedió algo más, lo intentó de nuevo, etc.
Por lo tanto, tenemos dos tablas base:
- Tabla de objetos . En él, un par, el nombre del depósito y el nombre de la clave, está asociado con su versión actual. Si se elimina el objeto, entonces no hay nada en esta versión. Si el objeto existe, existe su versión actual. De hecho, en esta tabla solo cambiamos el campo de la versión actual.
- Tabla de versiones de objetos . Solo insertamos nuevas versiones en esta tabla. Cada vez que se descarga un nuevo objeto, insertamos una nueva versión en la tabla de versiones, le damos un número único, guardamos toda la información al respecto y, al final, le actualizamos el enlace en la tabla de objetos.
La figura muestra un ejemplo de cómo se relacionan las tablas de objetos y las versiones de objetos.

Aquí hay un objeto que tiene dos versiones: una actual y otra antigua, hay un objeto que ya se ha eliminado y su versión sigue ahí. Necesitamos limpiar versiones innecesarias de vez en cuando, es decir, eliminar algo a lo que nadie más se refiere. Además, no necesitamos eliminarlo de inmediato, podemos hacerlo en modo diferido. Esta es nuestra limpieza interna, simplemente eliminamos lo que ya no es necesario.
Hubo un problema
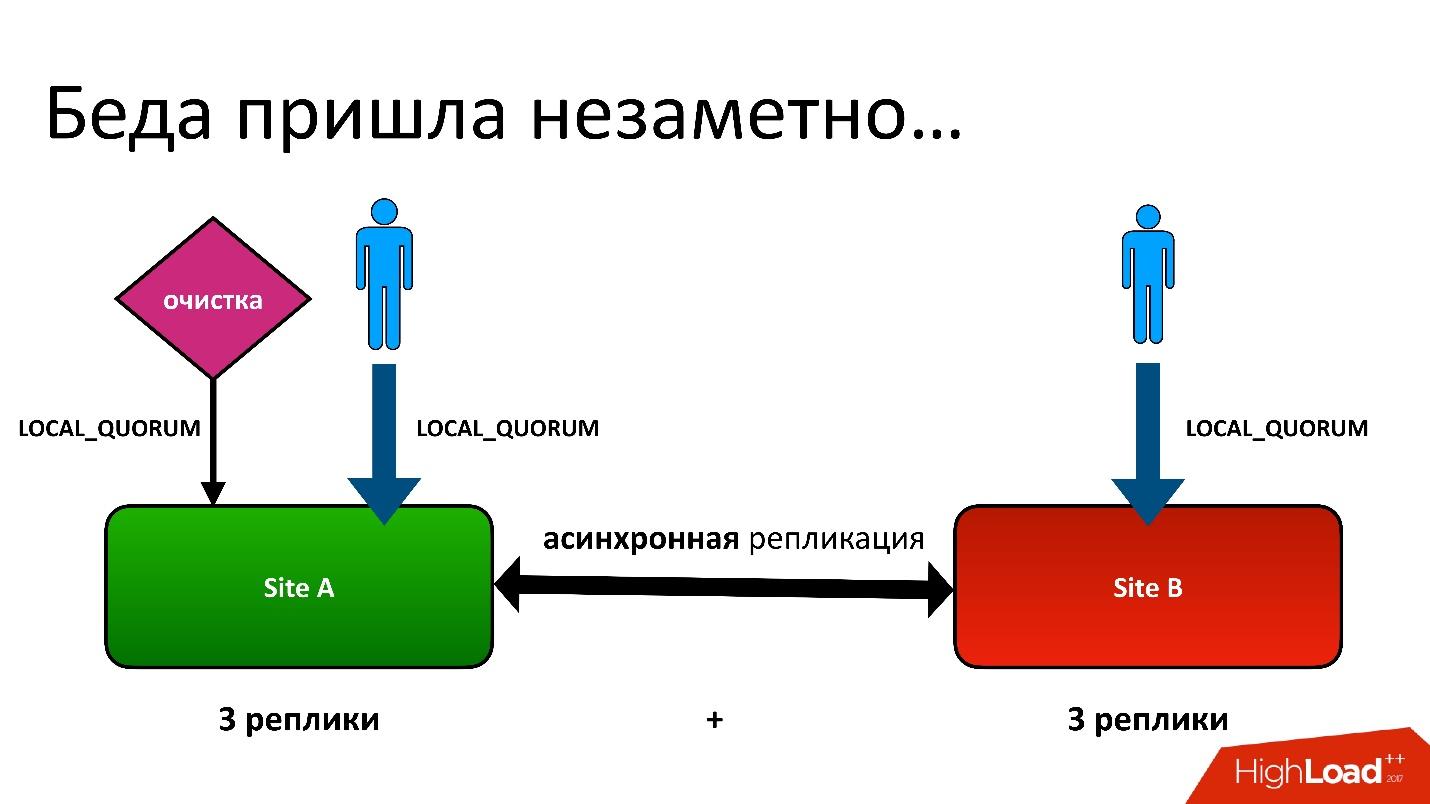
El problema era este: tenemos activo-activo, dos DC. En cada DC, los metadatos se almacenan en tres copias, es decir, tenemos 3 + 3, solo 6 réplicas. Cuando los clientes nos contactan, realizamos operaciones con coherencia (desde el punto de vista de Cassandra se llama LOCAL_QUORUM). Es decir, se garantiza que el registro (o lectura) se produjo en 2 réplicas en el DC local. Esto es una garantía; de lo contrario, la operación fallará.
Cassandra siempre intentará escribir en las 6 líneas: el 99% de las veces todo estará bien. De hecho, las 6 réplicas serán las mismas, pero nos garantizamos que 2.
Tuvimos una situación difícil, aunque ni siquiera era una geo-región. Incluso para regiones ordinarias que están en un DC, todavía almacenamos la segunda copia de metadatos en otro DC. Esta es una larga historia, no daré todos los detalles. Pero al final, tuvimos un proceso de limpieza que eliminó las versiones innecesarias.
Y entonces surgió el mismo problema. El proceso de limpieza también funcionó con la consistencia del quórum local en un centro de datos, porque no tiene sentido ejecutarlo en dos: lucharán entre sí.
Todo estuvo bien hasta que resultó que nuestros usuarios todavía a veces escriben en otro centro de datos, lo cual no sospechamos. Todo estaba configurado por si acaso para el feylover, pero resultó que ya lo estaban usando.
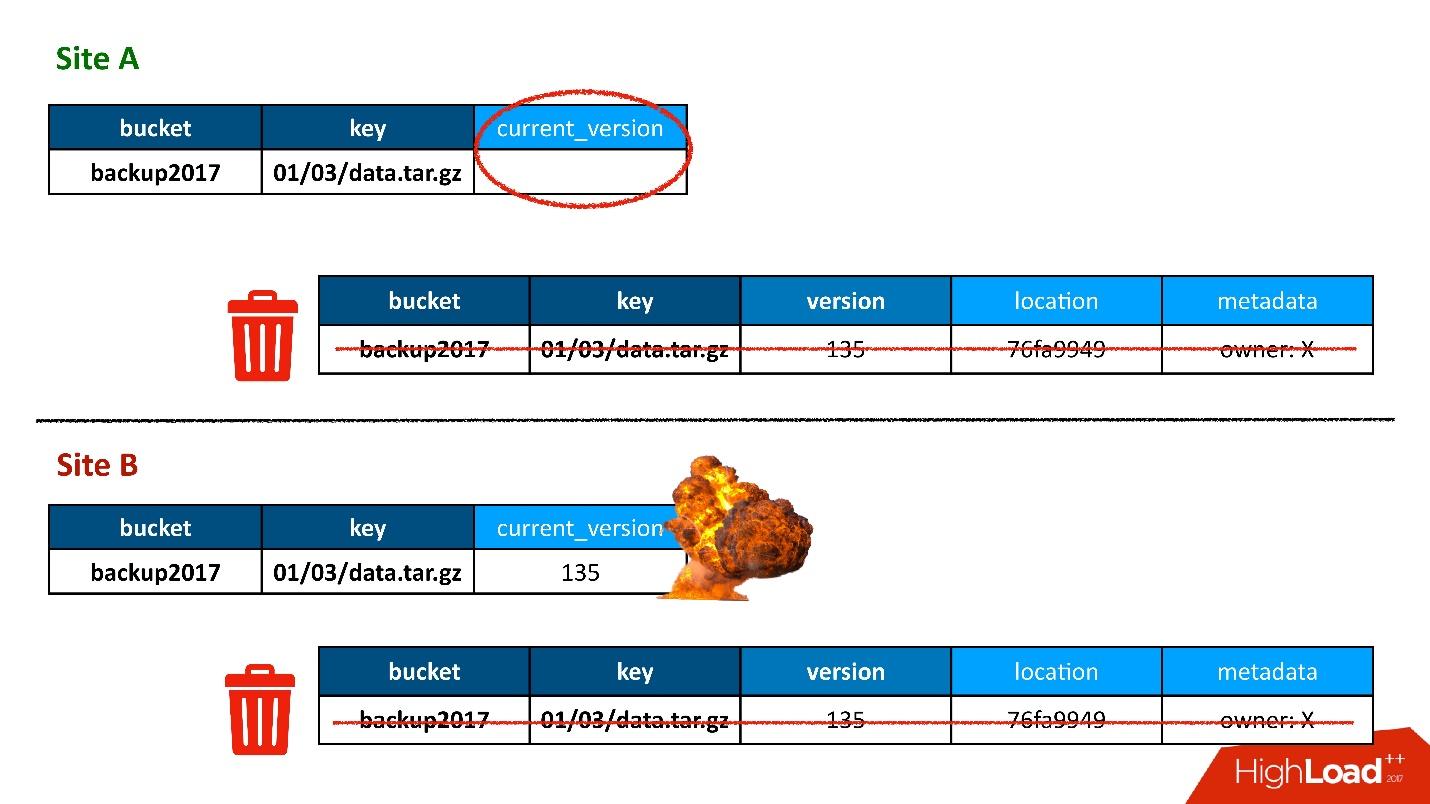
La mayoría de las veces, todo estuvo bien hasta que un día surgió una situación en la que una entrada en la tabla de versiones se replicaba en ambos DC, pero el registro en la tabla de objetos resultó estar en un solo DC y no terminó en el segundo. En consecuencia, el procedimiento de limpieza, iniciado en la primera DC (superior), vio que había una versión a la que nadie se refería y la eliminó. Y eliminé no solo la versión, sino también, por supuesto, los datos: todo es completamente, porque es solo un objeto innecesario. Y esta eliminación es irrevocable.
Por supuesto, hay un "boom" aún más, porque todavía tenemos un registro en la tabla de objetos que se refiere a una versión que ya no existe.
Entonces, la primera vez que perdimos datos, y los perdimos de manera irrevocable, bueno, un poco.
Solución
Que hacer En nuestra situación, todo es simple.
Como tenemos datos almacenados en dos centros de datos, el proceso de limpieza es un proceso de convergencia y sincronización. Debemos leer los datos de ambos DC. Este proceso funcionará solo cuando ambos DC estén disponibles. Como dije que este es un proceso retrasado que no ocurre durante el procesamiento de la API, esto no da miedo.
Consistencia ALL es una característica de Cassandra 2. En Cassandra 3, todo es un poco mejor: hay un nivel de consistencia, que se llama quórum en cada DC. Pero en cualquier caso, existe el problema de que es
lento , porque, en primer lugar, tenemos que recurrir a la DC remota. En segundo lugar, en el caso de la consistencia de los 6 nodos, esto significa que funciona a la velocidad del peor de estos 6 nodos.
Pero al mismo tiempo, se produce el llamado proceso de
reparación de lectura , cuando no todas las réplicas son sincrónicas. Es decir, cuando la grabación falló en alguna parte, este proceso los repara simultáneamente. Así es como funciona Cassandra.
Cuando esto sucedió, recibimos una queja del cliente de que el objeto no estaba disponible. Lo descubrimos, entendimos por qué, y lo primero que queríamos hacer era descubrir cuántos objetos más teníamos. Ejecutamos un script que intentaba encontrar una construcción similar a esta cuando había una entrada en una tabla, pero ninguna entrada en otra.
De repente, encontramos que tenemos el
10% de esos registros . Probablemente, nada peor podría no haber sucedido si no hubiéramos adivinado que este no era el caso. El problema fue diferente.

Los zombis se han infiltrado en nuestra base de datos. Este es el nombre semioficial de este problema. Para comprender qué es, debe hablar sobre cómo funciona la eliminación en Cassandra.
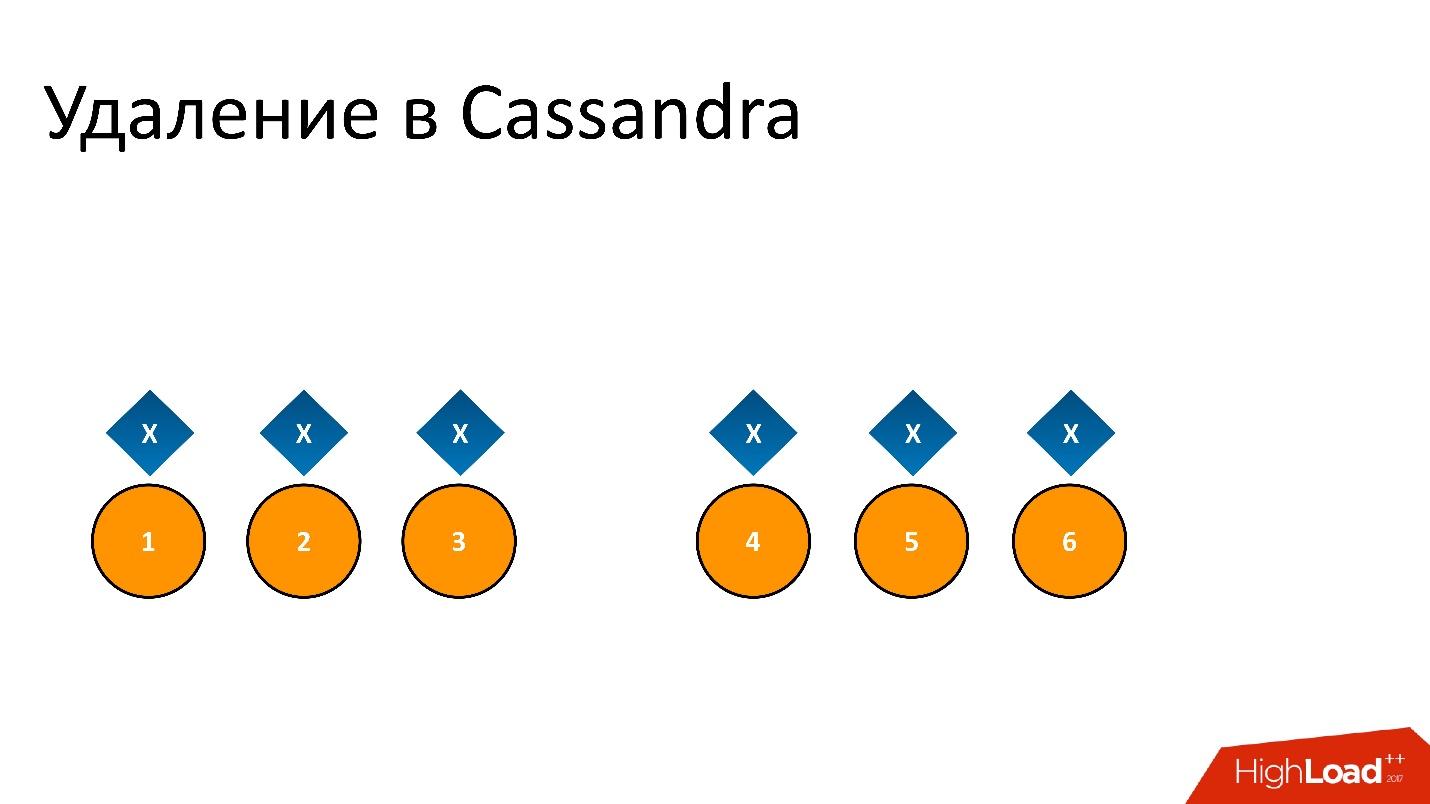
Por ejemplo, tenemos algún dato
x que se registra y se replica perfectamente en las 6 réplicas. Si queremos eliminarlo, la eliminación, como cualquier operación en Cassandra, puede no realizarse en todos los nodos.
Por ejemplo, queríamos garantizar la consistencia de 2 de 3 en una DC. Deje que la operación de eliminación se realice en cinco nodos, pero permanezca en un registro, por ejemplo, porque el nodo no estaba disponible en ese momento.
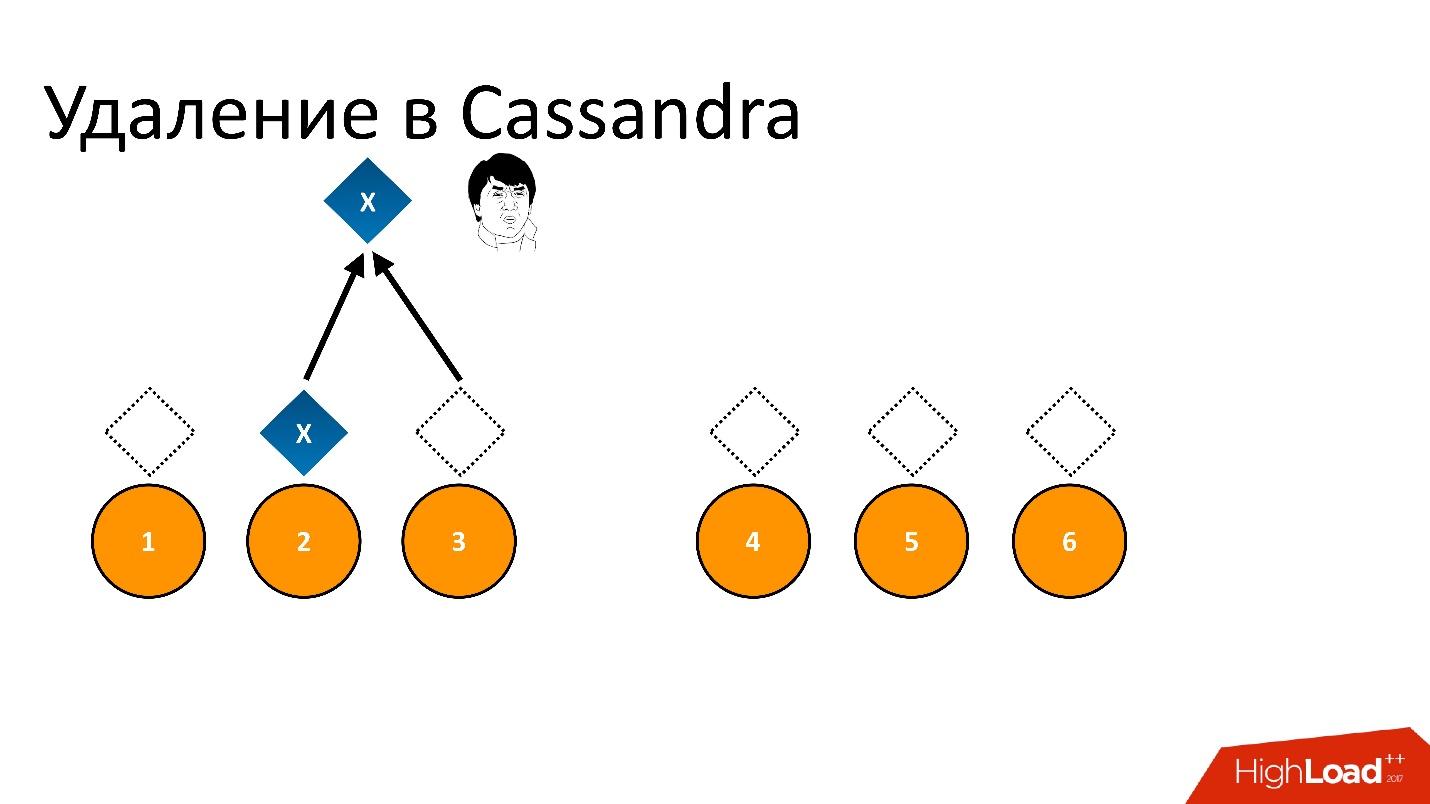
Si eliminamos esto y luego tratamos de leer "Quiero 2 de 3" con la misma consistencia, entonces Cassandra, al ver el valor y su ausencia, interpreta esto como la presencia de datos. Es decir, al volver a leer, ella dirá: "¡Oh, hay datos!", Aunque los eliminamos. Por lo tanto, no puede eliminar de esta manera.

Cassandra elimina de manera diferente.
La eliminación es en realidad un registro . Cuando eliminamos datos, Cassandra escribe un pequeño marcador llamado
Tombstone (lápida). Marca que los datos se eliminan. Por lo tanto, si leemos el token de eliminación y los datos al mismo tiempo, Cassandra siempre prefiere el token de eliminación en esta situación y dice que en realidad no hay datos. Esto es lo que necesitas.
Tombstone — , , , , - , . Tombstone .
Tombstone gc_grace_period . , , .
?
Repair
Cassandra , Repair (). — , . , , , , / , , - - , .. . Repair , .

, - , - . Repair , , . - , — . , .

Repair, , , , — , . 6 . — , , .

, — , - . , . , - , , , .
Solución
, :
, repair. , , .
repair — , repair. , , 10-20 , , 3 . Tombstone , . , , -.

Cassandra, . .
S3 . , — 10 , 100 . API, — . , , , , , . , , , — , . .
API?

, — , , — , , . . — . , , . , , Cassandra. , — , , , .
, , , , . , . , , . , - , .
Cassandra , . , , , , , .
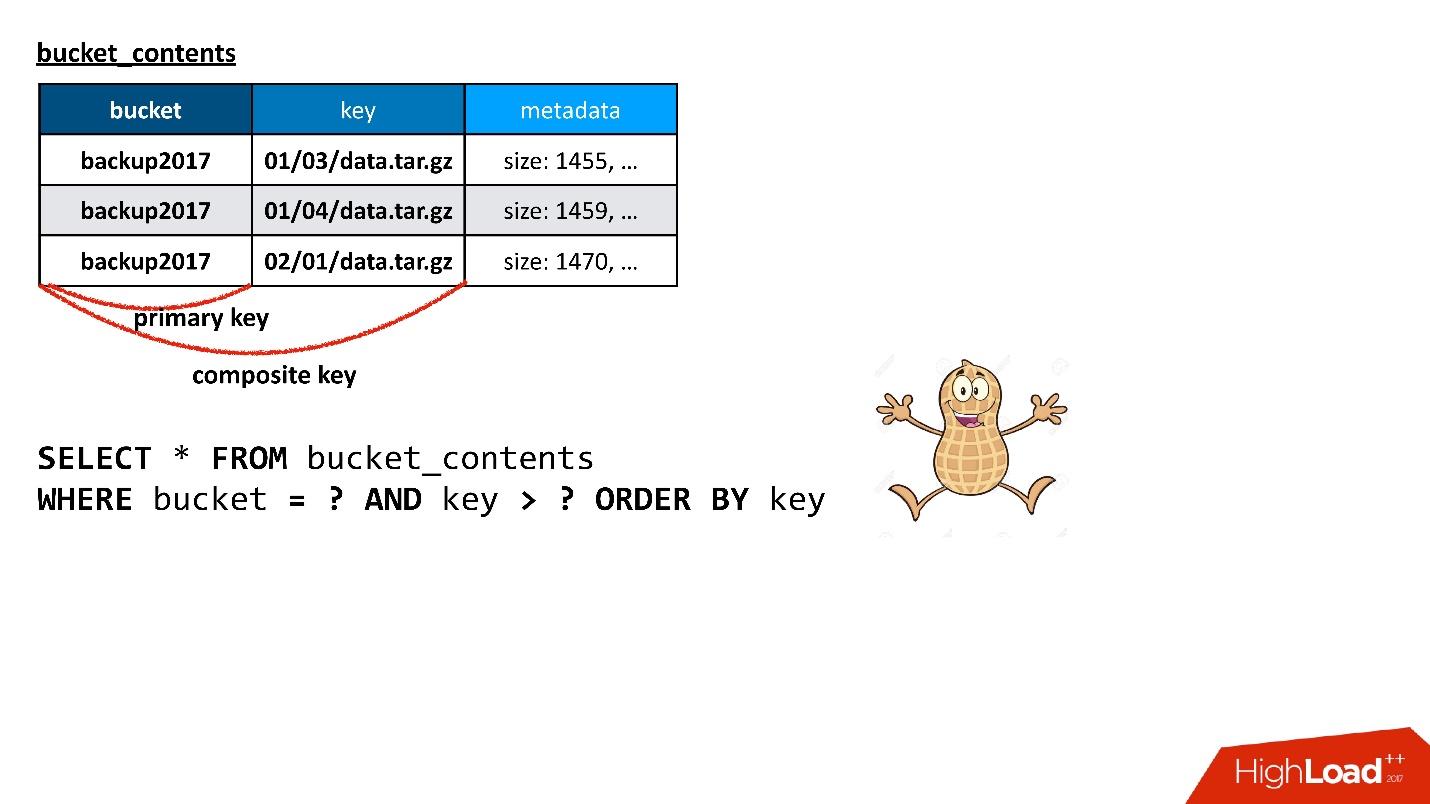
, Cassandra
composite key . , — , - , — . , . ? , , !
, , , , — , .
. Cassandra ,
Cassandra . , , Cassandra, : , , SQL .. !

. Cassandra ? , , API. , , , , ( ) .
, .
, . , , , . , — — . , , , .
Cassandra , . : « 100 », , , , , , 100, .
, ( ), — , , . , , , , , - . 100 , - , , . , SQL .
Cassandra , , Java, . ,
Large Partition , . — , , , , — . , , garbage collection .. .
, ,
, , .
, , - .

, , . . , Large Partition.
:
- ( , - );
- , , . , .
, , , key_hash 0. ,
, . , . , , .
, .

— , , , - - .
— , N ? , Large Partition, — . , . : . , , , , - . , . , , .

— , , - . - , , . , , . , , ..
— , ? , . ? - md5- — , - 30 — , - . . , , .

, , , , . — , . , . , - - - , - - — . , . .
, , , .
- .
- .
- Cassandra.
- Redistribución en línea (sin detener operaciones y pérdida de consistencia).
Tenemos algún estado del cubo ahora, de alguna manera está dividido en particiones. Entonces entendemos que algunas particiones son demasiado grandes o demasiado pequeñas. Necesitamos encontrar una nueva partición, que, por un lado, será óptima, es decir, el tamaño de cada partición será menor que algunos de nuestros límites, y serán más o menos uniformes. En este caso, la transición del estado actual a uno nuevo debería requerir un número mínimo de acciones. Está claro que cualquier transición requiere mover teclas entre particiones, pero cuanto menos las muevamos, mejor.
Lo hicimos Probablemente, la parte que se ocupa de la selección de distribución es la pieza más difícil de todo el servicio, si hablamos de trabajar con metadatos en general. Lo reescribimos, volvimos a trabajar y aún lo hacemos, porque siempre se encuentran algunos clientes o ciertos patrones de creación de claves que golpean un punto débil de este esquema.
Por ejemplo, supusimos que el cubo crecería de manera más o menos uniforme. Es decir, recogimos algún tipo de distribución, y esperamos que todas las particiones crezcan de acuerdo con esta distribución. Pero encontramos un cliente que siempre escribe al final, en el sentido de que sus claves siempre están ordenadas. Todo el tiempo late en la última partición, que está creciendo a una velocidad tal que en un minuto pueden ser 100 mil llaves. Y 100 mil es aproximadamente el valor que cabe en una partición.
Simplemente no tendríamos tiempo para procesar dicha adición de claves con nuestro algoritmo, y tuvimos que introducir una distribución preliminar especial para este cliente. Como sabemos cómo son sus teclas, si vemos que es él, simplemente comenzamos a crear particiones vacías por adelantado al final, para que pueda escribir con calma allí, y por ahora tendremos un pequeño descanso hasta la próxima iteración, cuando nuevamente tengamos que redistribuir todo.
Todo esto sucede en línea en el sentido de que no detenemos la operación. Puede haber operaciones de lectura, escritura, en cualquier momento puede solicitar una lista de claves. Siempre será consistente, incluso si estamos en el proceso de reparticionamiento.
Es bastante interesante, y resulta que con Cassandra. Aquí puedes jugar con trucos relacionados con el hecho de que Cassandra puede resolver conflictos. Si escribimos dos valores diferentes en la misma línea, entonces el valor que tiene una marca de tiempo más grande gana.
Por lo general, la marca de tiempo es la marca de tiempo actual, pero se puede pasar manualmente. Por ejemplo, queremos escribir un valor en una cadena, que en cualquier caso se debe frotar si el cliente escribe algo él mismo. Es decir, estamos copiando algunos datos, pero queremos que el cliente, si de repente escribe con nosotros al mismo tiempo, pueda sobrescribirlos. Entonces podemos copiar nuestros datos con una marca de tiempo un poco del pasado. Entonces, cualquier grabación actual se deshilachará deliberadamente, independientemente del orden en que se realizó la grabación.
Tales trucos te permiten hacer esto en línea.
Solución
- Nunca, nunca permita la aparición de una gran partición .
- Rompa los datos por clave principal según la tarea.
Si se planea algo similar a una partición grande en el esquema de datos, debe intentar hacer algo al respecto de inmediato: descubrir cómo romperlo y cómo alejarse de él. Tarde o temprano, esto surge, porque cualquier índice invertido, tarde o temprano, surge en casi cualquier tarea. Ya te conté sobre tal historia: tenemos una clave de depósito en el objeto y necesitamos obtener una lista de claves del depósito; de hecho, este es un índice.
Además, la partición puede ser grande no solo a partir de los datos, sino también de Tombstones (marcadores de eliminación). Desde el punto de vista de los componentes internos de Cassandra (nunca los vemos desde el exterior), los marcadores de eliminación también son datos, y una partición puede ser grande si se eliminan muchas cosas, porque la eliminación es un registro. Tampoco deberías olvidarte de esto.

Otra historia que en realidad es constante es que algo sale mal de principio a fin. Por ejemplo, ve que el tiempo de respuesta de Cassandra ha aumentado, responde lentamente. ¿Cómo entender y entender cuál es el problema? Nunca hay una señal externa de que el problema está ahí.

Por ejemplo, daré un gráfico: este es el tiempo de respuesta promedio del clúster en su conjunto. Muestra que tenemos un problema: el tiempo de respuesta máximo es de 12 segundos; este es el tiempo de espera interno de Cassandra. Esto significa que ella se desconectará ella misma. Si el tiempo de espera supera los 12 s, lo más probable es que el recolector de basura esté funcionando y Cassandra ni siquiera tiene tiempo para responder en el momento adecuado. Ella responde a sí misma por tiempo de espera, pero el tiempo de respuesta a la mayoría de las solicitudes, como dije, debería ser en promedio dentro de 10 ms.
En el gráfico, el promedio ya ha excedido cientos de milisegundos, algo salió mal. Pero mirando esta imagen, es imposible entender cuál es la razón.

Pero si expande las mismas estadísticas en los nodos de Cassandra, puede ver que, en principio, todos los nodos son más o menos nada, pero el tiempo de respuesta para un nodo difiere en orden de magnitud. Lo más probable es que haya algún tipo de problema con él.
Las estadísticas sobre los nodos cambian la imagen por completo. Estas estadísticas son del lado de la aplicación. Pero aquí, en realidad, a menudo es difícil entender cuál es el problema. Cuando una aplicación accede a Cassandra, accede a algún nodo, usándolo como coordinador. Es decir, la aplicación realiza una solicitud y el coordinador la redirige a las réplicas con los datos. Los que ya responden, y el coordinador devuelve la respuesta final.
Pero, ¿por qué el coordinador responde lentamente? Tal vez el problema es con él, como tal, es decir, ¿disminuye la velocidad y responde lentamente? ¿O tal vez se ralentiza porque las réplicas le responden lentamente? Si las réplicas responden lentamente, desde el punto de vista de la aplicación, se verá como una respuesta lenta del coordinador, aunque no tiene nada que ver con eso.
Aquí hay una situación feliz: está claro que solo un nodo responde lentamente y lo más probable es que el problema esté en él.
Complejidad de interpretación
- Tiempo de respuesta del coordinador (nodo vs. réplica en sí).
- ¿Una tabla específica o el nodo completo?
- GC Pause? ¿Grupo de subprocesos inadecuado?
- ¿Demasiadas SSTables no compactadas?
Siempre es difícil entender lo que está mal. Solo
necesita muchas estadísticas y monitoreo , tanto del lado de la aplicación como del propio Cassandra, porque si es realmente malo, Cassandra no puede ver nada. Puede ver el nivel de consultas individuales, el nivel de cada tabla específica, en cada nodo específico.
Puede haber, por ejemplo, una situación en la que una tabla de lo que se llama en Cassandra SSTables (archivos separados) tiene demasiado. Para leer, Cassandra tiene que, más o menos, clasificar todas las SSTables. Si hay demasiados, simplemente el proceso de esta clasificación lleva demasiado tiempo y la lectura comienza a ceder.
La solución es la compactación, que reduce el número de estas SSTables, pero debe tenerse en cuenta que solo puede estar en un nodo para una tabla específica. Dado que Cassandra, desafortunadamente, está escrito en Java y se ejecuta en la JVM, tal vez el recolector de basura ha entrado en una pausa tal que simplemente no tiene tiempo para responder. Cuando el recolector de basura entra en pausa, no solo sus solicitudes se ralentizan, sino que la
interacción dentro del clúster Cassandra entre nodos comienza a disminuir . Los nodos de cada uno comienzan a considerarse como caídos, es decir, caídos, muertos.
Comienza una situación aún más divertida, porque cuando un nodo considera que otro nodo está inactivo, en primer lugar, no le envía solicitudes y, en segundo lugar, comienza a intentar guardar los datos que necesitaría replicar en otro nodo en a nivel local, por lo que comienza a suicidarse lentamente, etc.
Hay situaciones en las que este problema se puede resolver simplemente usando la configuración correcta. Por ejemplo, puede haber suficientes recursos, todo está bien y es maravilloso, pero solo se necesita aumentar un conjunto de subprocesos, cuyo número es un tamaño fijo.
Finalmente, tal vez necesitemos limitar la competitividad del lado del conductor. A veces sucede que se envían demasiadas solicitudes competitivas y, como cualquier base de datos, Cassandra no puede manejarlas y acude al cierre cuando el tiempo de respuesta aumenta exponencialmente, y estamos tratando de dar más y más trabajo.
Comprensión del contexto.
Siempre hay algo de contexto para el problema: qué está sucediendo en el clúster, si Reparar está funcionando ahora, en qué nodo, en qué espacios clave, en qué tabla.
Por ejemplo, tuvimos problemas bastante ridículos con el hierro. Vimos que parte de los nodos es lenta. Más tarde se descubrió que la razón era que en el BIOS sus procesadores estaban en modo de ahorro de energía. Por alguna razón, durante la instalación inicial de hierro, esto sucedió, y aproximadamente el 50% de los recursos del procesador se usaron en comparación con otros nodos.
Entender tal problema puede ser difícil, de hecho. El síntoma es este: parece que el nodo hace compactación, pero lo hace lentamente. A veces está conectado con hierro, a veces no, pero este es solo otro error de Cassandra.
Por lo tanto, el monitoreo es obligatorio y necesita mucho. Cuanto más compleja es la función en Cassandra, cuanto más se aleja de la simple escritura y lectura, más problemas hay con ella y más rápido puede eliminar una base de datos con un número suficiente de consultas. Por lo tanto, si es posible, no mire algunos chips “sabrosos” e intente usarlos, es mejor evitarlos tanto como sea posible. No siempre es posible, por supuesto, tarde o temprano es necesario.

La última historia es sobre cómo Cassandra desordenó los datos. En esta situación, sucedió dentro de Cassandra. Eso fue interesante.
Vimos que aproximadamente una vez por semana en nuestra base de datos aparecen varias docenas de líneas dañadas, que están literalmente obstruidas con basura. Además, Cassandra valida los datos que van a su entrada. Por ejemplo, si es una cadena, debería estar en utf8. Pero en estas líneas había basura, no utf8, y Cassandra ni siquiera dio nada que ver con eso. Cuando intento eliminar (o hacer otra cosa), no puedo eliminar un valor que no es utf8, porque, en particular, no puedo ingresarlo en DONDE, porque la clave debe ser utf8.
Aparecen líneas estropeadas, como un destello, en algún momento, y luego desaparecen durante varios días o semanas.
Empezamos a buscar un problema. Pensamos que tal vez había un problema en un nodo particular con el que estábamos jugando, haciendo algo con datos, copiando SSTables. Quizás, de todos modos, ¿puedes ver réplicas de estos datos? ¿Quizás estas réplicas tienen un nodo común, el factor común más pequeño? Tal vez algún nodo se bloquea? No, nada de eso.
Tal vez algo con un disco? ¿Los datos están dañados en el disco? No otra vez
Tal vez un recuerdo? No! Esparcidos por un grupo.
Tal vez este es algún tipo de problema de replicación? ¿Un nodo estropeó todo y replicó aún más un mal valor? - No
Finalmente, ¿tal vez este es un problema de aplicación?
Además, en algún momento, las líneas dañadas comenzaron a aparecer en dos grupos de Cassandra. Uno trabajó en la versión 2.1, el segundo en el tercero. Parece que Cassandra es diferente, pero el problema es el mismo. ¿Quizás nuestro servicio envía datos incorrectos? Pero era difícil de creer. Cassandra valida los datos de entrada; no puede escribir basura. Pero de repente?
Nada cabe.
¡Se encontró una aguja!
Luchamos mucho hasta que descubrimos un pequeño problema: ¿por qué tenemos algún tipo de volcado de memoria de la JVM en los nodos a los que no prestamos mucha atención? Y de alguna manera se ve sospechosamente en el recolector de basura de seguimiento de pila ... Y por alguna razón, algunos rastros de pila también están obstruidos con basura.
Al final, nos dimos cuenta, oh,
por alguna razón, estamos usando la JVM de la versión anterior de 2015 . Esta fue la única cosa común que unió a los grupos de Cassandra en diferentes versiones de Cassandra.
Todavía no sé cuál fue el problema, porque no se escribió nada sobre esto en las notas de lanzamiento oficiales de la JVM. Pero después de la actualización, todo desapareció, el problema ya no surgió. Además, no se produjo en el clúster desde el primer día, sino desde algún punto, aunque funcionó en la misma JVM durante mucho tiempo.
Recuperación de datos
¿Qué lección hemos aprendido de esto?
● La copia de seguridad es inútil.
Los datos, como descubrimos, se corrompieron en el mismo instante en que se registraron. En el momento en que los datos ingresaron al coordinador, ya estaban dañados.
● Es posible la restauración parcial de columnas no dañadas.
Algunas columnas no estaban dañadas, pudimos leer estos datos, restaurarlos parcialmente.
● Al final, tuvimos que hacer la recuperación de varias fuentes.
Teníamos metadatos de respaldo en el objeto, pero en los datos en sí. Para volver a conectar con el objeto, utilizamos registros, etc.
● ¡Los registros no tienen precio!
Pudimos recuperar todos los datos que estaban dañados, pero al final es muy difícil confiar en la base de datos si pierde sus datos, incluso sin ninguna acción de su parte.
Solución
- Actualice la JVM después de extensas pruebas.
- Monitoreo de fallas JVM.
- Tener una copia de los datos independiente de Cassandra.
Como consejo: intente obtener algún tipo de copia de los datos independiente de Cassandra de la que pueda recuperar si es necesario. Esta puede ser la solución de último nivel. Deje que tome mucho tiempo, recursos, pero debería haber alguna opción que le permita devolver datos.
Bichos
●
Mala calidad de las pruebas de lanzamientoCuando comienzas a trabajar con Cassandra, hay una sensación constante (especialmente si te estás moviendo, relativamente hablando, de bases de datos "buenas", por ejemplo, PostgreSQL) de que si solucionaste un error en el lanzamiento de la anterior, definitivamente agregarás uno nuevo. Y el error no es una tontería, generalmente son datos corruptos u otro comportamiento incorrecto.
●
Problemas persistentes con características complejasCuanto más compleja es la característica, más problemas, errores, etc.
●
No utilice reparaciones incrementales en 2.1La famosa reparación, de la que hablé, que corrige la consistencia de los datos, en modo estándar, cuando sondea todos los nodos, funciona bien. Pero no en el llamado modo incremental (cuando la reparación omite datos que no han cambiado desde la reparación anterior, lo cual es bastante lógico). Se anunció hace mucho tiempo, formalmente, ya que existe una característica, pero todos dicen: “No, en la versión 2.1, ¡nunca la use! Definitivamente echará de menos algo. En 3 lo arreglamos ".
●
Pero no use la reparación incremental en 3.xCuando salió la tercera versión, unos días después dijeron: “No, no puedes usarla en la tercera. Hay una lista de 15 errores, por lo que en ningún caso no utilice la reparación incremental. ¡En cuarto lo haremos mejor!
No les creo. Y este es un gran problema, especialmente con el aumento del tamaño del clúster. Por lo tanto, debe monitorear constantemente su rastreador de errores y ver qué sucede. Desafortunadamente, es imposible vivir con ellos sin él.
●
Necesito hacer un seguimiento de JIRA
Si dispersas todas las bases de datos en el espectro de previsibilidad, para mí, Cassandra está a la izquierda en el área roja. Esto no significa que sea malo, solo tienes que estar preparado para el hecho de que Cassandra es impredecible en cualquier sentido de la palabra: tanto en la forma en que funciona como en el hecho de que algo puede suceder.

Deseo que encuentres otros rastrillos y los pises, porque, desde mi punto de vista, pase lo que pase, Cassandra es buena y, desde luego, no aburrida. ¡Solo recuerda los golpes en el camino!
Reunión abierta de activistas de HighLoad ++
El 31 de julio en Moscú, a las 19:00, se llevará a cabo una reunión de oradores, el Comité del Programa y activistas de la conferencia de desarrolladores de sistemas de alta carga HighLoad ++ 2018. Organizaremos una pequeña lluvia de ideas sobre el programa de este año para no perder nada nuevo e importante. La reunión está abierta, pero debe registrarse .
Llamada para papeles
Aceptación activa de solicitudes de informes en Highload ++ 2018. El Comité del Programa está esperando su resumen hasta el final del verano.