
Esta es una continuación de la primera parte del artículo.
En la primera parte del artículo, el autor habló sobre las condiciones del concurso para el juego Agario en mail.ru, la estructura del mundo del juego y parcialmente sobre la estructura del bot. En parte, porque solo afectaron el dispositivo de los sensores de entrada y los comandos a la salida de la red neuronal (en adelante, en imágenes y texto, habrá una abreviatura NN). Así que intentemos abrir la caja negra y entender cómo se organiza todo allí.
Y aquí está la primera foto:
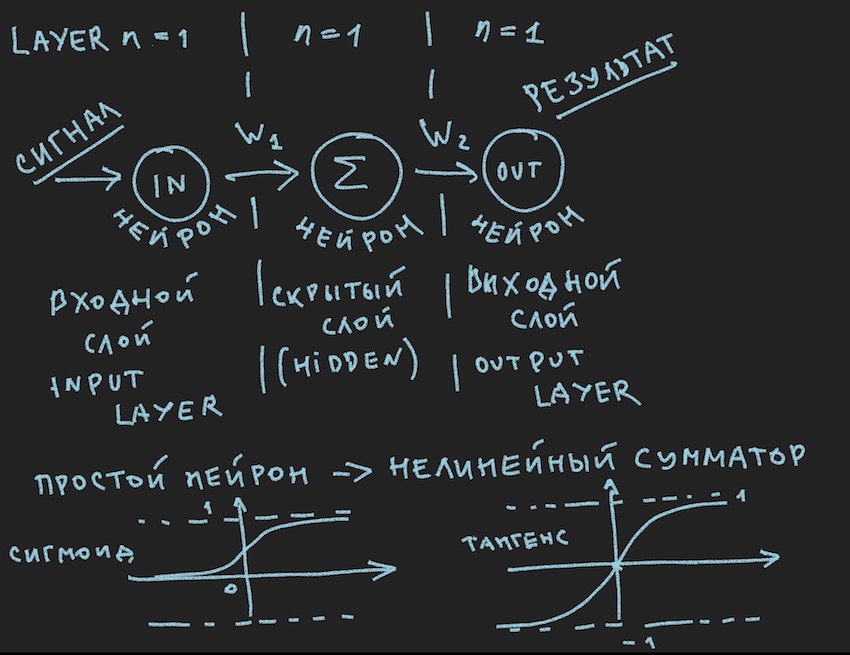
Representa esquemáticamente lo que debería causar una sonrisa aburrida de mi lector, dicen nuevamente en primer grado, se les ha visto muchas veces en varias fuentes . Pero realmente queremos aplicar prácticamente esta imagen a la administración del bot, por lo que después de la Nota importante, la examinamos más de cerca.
Nota importante: hay una gran cantidad de soluciones preparadas (frameworks) para trabajar con redes neuronales:

Todos estos paquetes resuelven las tareas principales para el desarrollador de redes neuronales: la construcción y capacitación de NN o la búsqueda de pesos "óptimos". Y el método principal de esta búsqueda es Backpropagation . Fue inventado en los años 70 del siglo pasado, como lo indica el artículo en el enlace anterior, durante este tiempo, como la parte inferior del barco, ha adquirido varias mejoras, pero la esencia es la misma: encontrar coeficientes de peso con una base de ejemplos de entrenamiento y es altamente deseable que todos de estos ejemplos contenía una respuesta preparada en forma de una señal de salida de una red neuronal. El lector puede objetarme. que las redes de autoaprendizaje de varias clases y principios ya se han inventado, pero todo no está yendo bien allí, por lo que yo entiendo. Por supuesto, hay planes para estudiar este zoológico con más detalle, pero creo que encontraré personas con ideas afines de que una bicicleta hecha a medida, incluso la más curva, está más cerca del corazón del creador que un clon transportador de una bicicleta ideal.
Entendiendo que el servidor de juegos probablemente no tendrá estas bibliotecas y la potencia de cómputo asignada por los organizadores como 1 núcleo de procesador claramente no es suficiente para un marco pesado, el autor pasó a crear su propia bicicleta. Un comentario importante sobre esto terminó.
Volvamos a la imagen que representa probablemente la red neuronal más simple posible con una capa oculta (también conocida como capa oculta o capa oculta). Ahora el propio autor ha mirado fijamente la imagen con ideas sobre este sencillo ejemplo para revelar al lector las profundidades de las redes neuronales artificiales. Cuando todo se simplifica a lo primitivo, es más fácil entender la esencia. La conclusión es que la neurona de la capa oculta no tiene nada que resumir. Y lo más probable es que esto ni siquiera sea una red neuronal, en los libros de texto el NN más simple es una red con dos entradas. Así que aquí estamos, por así decirlo, los descubridores de la más simple de las redes más simples.
Intentemos describir esta red neuronal (pseudocódigo):
Introducimos la topología de la red en forma de matriz, donde cada elemento corresponde a la capa y al número de neuronas que contiene:
int array Topology= { 1, 1, 1}
También necesitamos una matriz flotante de pesos de la red neuronal W, considerando nuestra red como “redes neuronales de alimentación hacia adelante (FF o FFNN)”, donde cada neurona de la capa actual está conectada a cada neurona de la capa siguiente, obtenemos la dimensión de la matriz W [número de capas , el número de neuronas en la capa, el número de neuronas en la capa]. No es la codificación óptima, pero dado el aliento de la GPU en algún lugar muy cercano en el texto, es comprensible.
Un breve procedimiento CalculateSize para contar el número de neuronas de neuroncount y el número de sus conexiones en la red neuronal de neuroncount , creo que explicará mejor al autor la naturaleza de estas conexiones:
void CalculateSize(array int Topology, int neuroncount, int dendritecount) { for (int i : Topology) // i neuroncount += i; for (int layer = 0, layer <Topology.Length - 1, layer++) // for (int i = 0, i < Topology[layer] + 1, i++) // for (int j = 0, j < Topology[layer + 1], j++) // dendritecount++; }
Mi lector, el que ya sabe todo esto, el autor llegó a esta opinión en el primer artículo, ciertamente no preguntará: por qué en el tercer bucle anidado Topología [capa1 + 1] en lugar de Topología [capa1], que le da más a la neurona que en la topología de red . No voy a responder También es útil para el lector pedir la tarea.
Estamos casi a un paso de construir una red neuronal que funcione. Queda por agregar la función de sumar las señales en la entrada de la neurona y su activación. Hay muchas funciones de activación, pero las más cercanas a la naturaleza de la neurona son Sigmoides y Tangensoides (probablemente sea mejor llamarlo así, aunque este nombre no se usa especialmente en la literatura, el máximo es tangente, pero este es el nombre del gráfico, aunque ¿qué es un gráfico si no es un reflejo de la función?)
Así que aquí tenemos las funciones de activación neuronal (están presentes en la imagen, en su parte inferior)
float Sigmoid(float x) { if (x < -10.0f) return 0.0f; else if (x > 10.0f) return 1.0f; return (float)(1.0f / (1.0f + expf(-x))); }
Sigmoid devuelve valores de 0 a 1.
float Tanh(float x) { if (x < -10.0f) return -1.0f; else if (x > 10.0f) return 1.0f; return (float)(tanhf(x)); }
El tangentoide devuelve valores de -1 a 1.
La idea principal de una señal que pasa a través de una red neuronal es una onda: una señal se alimenta a las neuronas de entrada -> a través de las conexiones neuronales, la señal va a la segunda capa -> las neuronas de la segunda capa resumen las señales que las alcanzaron cambiadas por los pesos interneuronales -> se agrega a través de un peso de polarización adicional usamos la función de activación-> y wu-al vamos a la siguiente capa (lea el primer ciclo del ejemplo por capas), es decir, repitiendo la cadena desde el principio solo las neuronas de la siguiente capa se convertirán en neuronas de entrada. En simplificación, ni siquiera necesita almacenar los valores de las neuronas de toda la red, solo necesita almacenar los pesos NN y los valores de las neuronas de la capa activa.
Una vez más, enviamos una señal a la entrada NN, la onda atravesó las capas y en la capa de salida eliminamos el valor obtenido.
Aquí, por gusto del lector, es posible resolver mediante programación utilizando la recursividad o simplemente un ciclo triple como el del autor, para acelerar los cálculos, no es necesario cercar objetos en forma de neuronas y sus conexiones y otras POO. Nuevamente, esto se debe a la sensación de cálculos cercanos de GPU, y en las GPU, debido a su naturaleza de paralelismo de masas, OOP se detiene un poco, esto es relativo a c # y C ++.
Además, se invita al lector a seguir independientemente el camino para construir una red neuronal en código, con su deseo voluntario, cuya ausencia es bastante clara y familiar para el autor, en cuanto a ejemplos de construcción de NN desde cero, hay muchos ejemplos en la red, por lo que será difícil extraviarse, es así tan sencillo como una red neuronal de distribución directa en la imagen de arriba.
Pero, ¿dónde exclamará el lector, que aún no se ha apartado del pasaje anterior, y tendrá razón, en la infancia, el autor determinó el valor del libro mediante ilustraciones para él? Aquí tienes
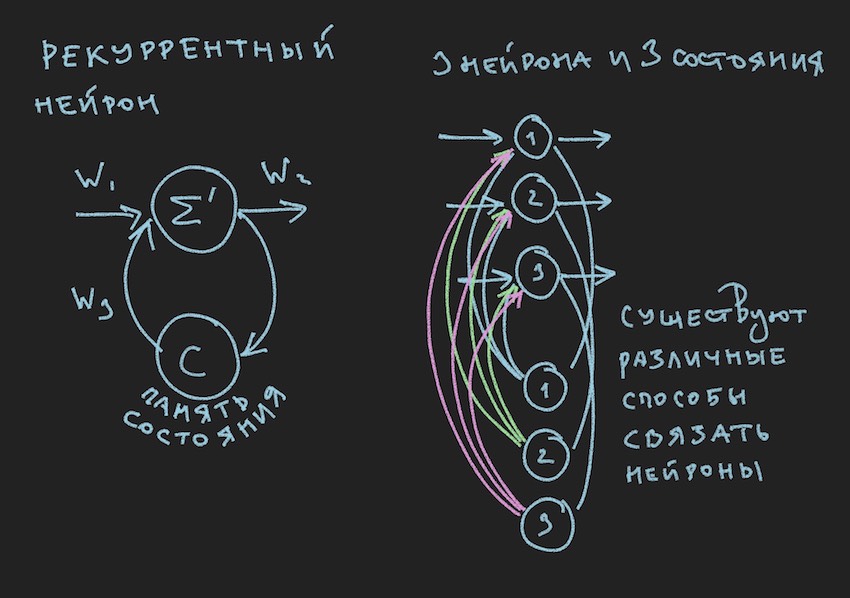
En la imagen vemos una neurona recurrente y un NN construido a partir de tales neuronas se llama recurrente o RNN. La red neuronal especificada tiene una memoria a corto plazo y fue seleccionada por el autor para el bot como la más prometedora en términos de adaptación al proceso del juego. Por supuesto, el autor construyó una red neuronal de distribución directa, pero en el proceso de búsqueda de una solución "efectiva" se cambió a RNN.
Una neurona recurrente tiene un estado adicional C, que se forma después del primer paso de una señal a través de una neurona, Tick + 0 en la línea de tiempo. En palabras simples, esta es una copia de la señal de salida de una neurona. En el segundo paso, lea Tick + 1 (dado que la red funciona a la frecuencia del bot y el servidor del juego), el valor C vuelve a la entrada de la capa neural a través de pesos adicionales y, por lo tanto, participa en la formación de la señal, pero ya en el momento Tick + 1.
Nota: en el trabajo de los grupos de investigación sobre el manejo de los bots del juego NN , hay una tendencia a usar dos ritmos para una red neuronal, un ritmo es la frecuencia del juego Tick, el segundo ritmo, por ejemplo, es dos veces más lento que el primero. Las diferentes partes de la NN operan a diferentes frecuencias, lo que brinda una visión diferente de la situación del juego dentro de la NN, lo que aumenta su flexibilidad.
Para construir RNN en el código bot, introducimos una matriz adicional en la topología, donde cada elemento corresponde a la capa y al número de estados neuronales que contiene:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
De la topología anterior se puede ver que la segunda capa es recurrente, ya que contiene estados neurales. También presentamos pesos adicionales en forma de flotante de la matriz WRR, la misma dimensión que la matriz W.
El recuento de conexiones en nuestra red neuronal cambiará un poco:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++) for (int i = 0, i < TopologyNN[layer] + 1, i++) for (int j = 0, j < TopologyNN[layer + 1] , j++) dendritecount++; for (int layer = 0, layer < TopologyRNN.Length - 1, layer++) for (int i = 0, i< TopologyRNN[layer] + 1 , i++) for (int j = 0, j< TopologyRNN[layer], j++) dendritecount++;
El autor adjuntará el código general para una red neuronal recurrente al final de este artículo, pero lo principal a entender es el principio: el paso de una onda a través de capas en el caso de un NN recurrente no cambia fundamentalmente nada, solo se agrega un término más a la función de activación neuronal. Este es el término del estado de las neuronas en el tic anterior multiplicado por el peso de la conexión neuronal.
Suponemos que la teoría y la práctica de las redes neuronales se han actualizado, pero el autor es consciente de que no ha acercado al lector a comprender cómo enseñar esta estructura simple de redes neuronales para tomar decisiones en el juego. No tenemos bibliotecas con ejemplos para enseñar NN. En los grupos de desarrolladores de bot de Internet, había una opinión: danos un archivo de registro en forma de coordenadas de bots y otra información del juego para formar una biblioteca de ejemplos. Pero, desafortunadamente, el autor no pudo descubrir cómo usar este archivo de registro para entrenar a NN. Estaré encantado de discutir esto en los comentarios al artículo. Por lo tanto, el único método disponible para el autor para comprender el método de entrenamiento, o más bien encontrar neurobalanzas "efectivas" (neuroconexiones), fue el algoritmo genético.
Preparó una imagen sobre los principios del algoritmo genético:
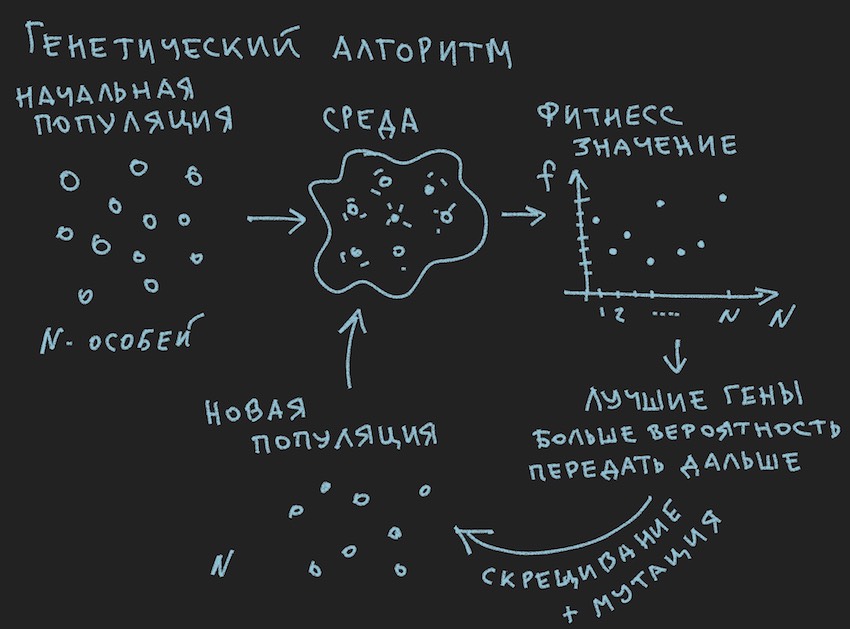
Entonces el algoritmo genético .
El autor intentará no profundizar en la teoría de este proceso , pero recordará solo el mínimo necesario para continuar una lectura completa del artículo.
En el algoritmo genético, el principal fluido de trabajo es el gen (el ADN es el nombre de la molécula). El genoma en nuestro caso es un conjunto secuencial de genes o una matriz unidimensional de flotación larga ...
En la etapa inicial de trabajo con una red neuronal recién construida, es necesario inicializarla. La inicialización se refiere a la asignación de valores aleatorios de -1 a 1 a equilibrios neuronales. El autor se ha reunido menciona que el rango de valores de -1 a 1 es demasiado extremo y las redes entrenadas tienen pesos en un rango más pequeño, por ejemplo, de -0.5 a 0.5 y que debe tomar un rango inicial de valores excelente de -1 a 1. Pero seguiremos el camino clásico de recopilar todas las dificultades en una puerta y tomaremos el segmento más amplio posible de variables aleatorias iniciales como base para inicializar la red neuronal.
Ahora ocurrirá una biyección . Asumiremos que la longitud (tamaño) del genoma del bot será igual a la longitud total de las matrices de la red neuronal TopologíaNN.Longitud + TopologíaRNN.Longitud no por nada que el autor pasó el tiempo del lector en el procedimiento para contar las conexiones neuronales.
Nota: Como el lector ya ha notado por sí mismo, solo transferimos los pesos de la red neuronal al genotipo, la estructura de conexión, las funciones de activación y los estados neuronales no se transmiten. Para un algoritmo genético, solo las conexiones neuronales son suficientes, lo que sugiere que son los portadores de la información. Hay desarrollos en los que el algoritmo genético también cambia la estructura de las conexiones en la red neuronal y es bastante sencillo implementarlo. Aquí, el autor deja espacio para la creatividad para el lector, aunque él mismo lo pensará con interés: debe comprender el uso de dos genomas independientes y dos funciones de aptitud (dos algoritmos genéticos independientes) o todos pueden usar el mismo gen y algoritmo.
Y dado que inicializamos NN con variables aleatorias, de este modo inicializamos el genoma. El proceso inverso también es posible: inicialización del genotipo mediante variables aleatorias y su posterior copia en pesos neuronales. La segunda opción es común. Dado que el algoritmo genético en el programa a menudo existe aparte de la esencia misma y se asocia con él solo por los datos del genoma y el valor de la función de estado físico ... Detener, detener, el lector dirá, la imagen muestra claramente la población y no una palabra sobre el genoma individual.
Ok, agregue algunas fotos al horno mental del lector:
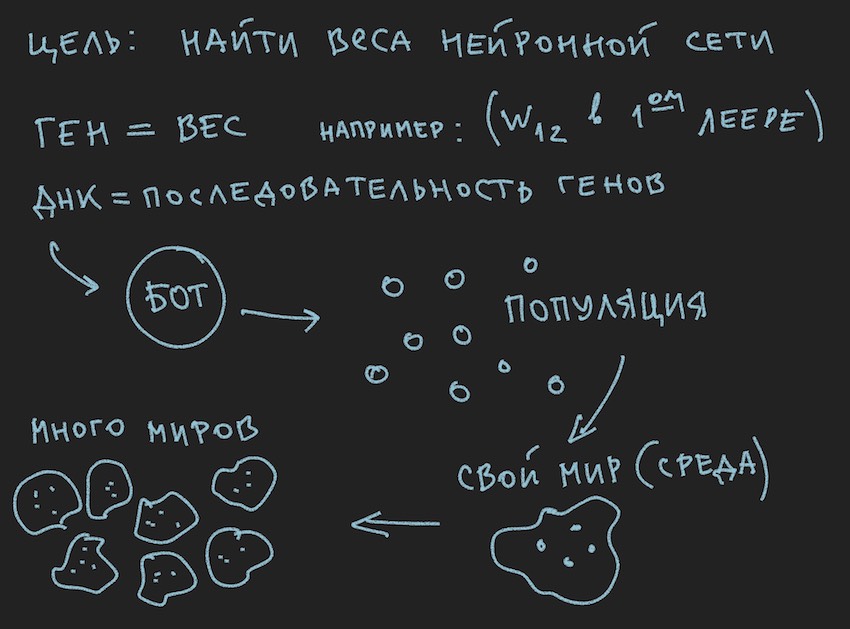
Como el autor pintó las imágenes antes de escribir el texto del artículo, apoyan el texto, pero no siguen la letra a la letra de la historia actual.
De la información extraída se deduce que el principal cuerpo de trabajo del algoritmo genético es una población de genomas . Esto es un poco contrario a lo que el autor dijo anteriormente, pero cómo hacerlo en el mundo real sin pequeñas contradicciones. Ayer, el sol giraba alrededor de la tierra, y hoy el autor habla sobre la red neuronal dentro del bot de software. No es de extrañar que recordara el horno de la razón.
Confío en que el lector mismo resuelva el problema de las contradicciones del mundo. El mundo bot es completamente autosuficiente para el artículo.
Pero lo que el autor ya ha logrado hacer, en esta parte del artículo, es formar una población de bots.
Echemos un vistazo desde el lado del software:
Hay un Bot (puede ser un objeto en OOP, una estructura, aunque probablemente también sea un objeto o simplemente una matriz de datos). En el interior, el Bot contiene información sobre sus coordenadas, velocidad, masa y otra información útil en el proceso del juego, pero lo principal para nosotros ahora es que contiene un enlace a su genotipo o genotipo en sí mismo, dependiendo de la implementación. Luego puede ir de diferentes maneras, limitarse a conjuntos de pesos de redes neuronales o introducir un conjunto adicional de genotipos, ya que será conveniente para el lector imaginar esto en su imaginación. En las primeras etapas, el autor del programa asignó matrices de neurobalances y genotipos. Luego se negó a duplicar información y se limitó a los pesos de la red neuronal.
Siguiendo la lógica de la historia, debe decir que la población de bots es una matriz de los bots anteriores. Qué bucle de juego ... Detente de nuevo, ¿qué ciclo de juego? los desarrolladores proporcionaron cortésmente un lugar para un solo Bot a bordo de un programa de simulación del mundo del juego en un servidor o un máximo de cuatro bots en un simulador local. Y si recuerda la topología de la red neuronal elegida por el autor:
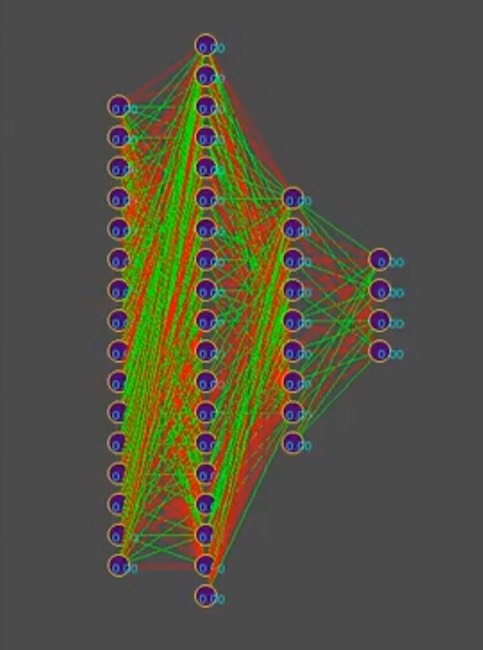
Y para simplificar la historia, suponga que el genotipo contiene aproximadamente 1000 conexiones neuronales, por cierto, en el simulador, los genotipos se ven así (el rojo es un valor genético negativo, el verde es un valor positivo, cada línea es un genoma separado):

Nota para la foto: con el tiempo, el patrón cambia en la dirección del dominio de una de las soluciones, las rayas verticales son genes genotípicos comunes.
Por lo tanto, tenemos 1000 genes en el genotipo y un máximo de cuatro bots en el programa simulador del mundo del juego de los organizadores de la competencia. ¿Cuántas veces necesitas ejecutar una simulación de una batalla de bots para que por fuerza bruta, incluso los más inteligentes, te acerques en busca de "efectivo"
genotipo, lea la combinación "efectiva" de conexiones neuronales, siempre que cada conexión neuronal varíe de -1 a 1 en pasos, ¿y qué paso? La inicialización fue flotante aleatorio, es 15 decimales. El paso aún no está claro para nosotros. Sobre el número de variantes de combinaciones de pesos neuronales, el autor supone que este es un número infinito, al elegir un cierto tamaño de paso, probablemente un número finito, pero en cualquier caso, estos números son mucho más de 4 lugares en el simulador, incluso considerando el lanzamiento secuencial desde la cola de bots más el lanzamiento paralelo simultáneo de simuladores oficiales, hasta 10 en una computadora (para fanáticos de la programación vintage: computadoras).
Espero que las fotos ayuden al lector.
Aquí debe hacer una pausa y hablar sobre la arquitectura de la solución de software. Dado que la solución en forma de un bot de software separado cargado en el sitio de la competencia ya no era adecuada. Era necesario separar el juego del robot de acuerdo con las reglas de la competencia en el marco del ecosistema de organizadores y el programa que intentaba encontrar la configuración de la red neuronal para él. El siguiente diagrama está tomado de la presentación de la conferencia, pero generalmente refleja la imagen real.
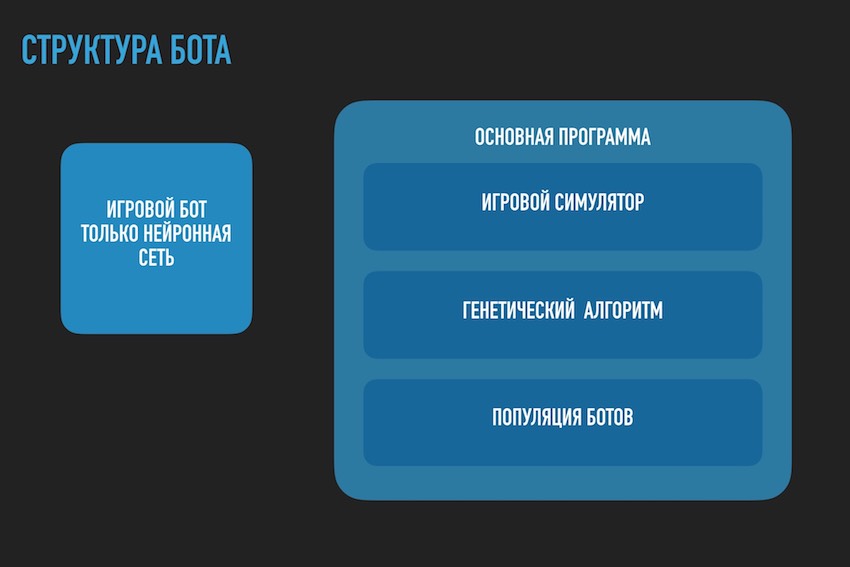
Recordó un chiste barbudo:
Gran organización
Hora 18.00, todos los empleados trabajan como uno. De repente, uno de los empleados apaga la computadora, se viste y se va.
Todos lo siguen con una mirada de sorpresa.
Al dia siguiente A las 18.00 el mismo empleado apaga la computadora y se va. Todos continúan trabajando y comienzan a susurrar disgustados.
Al dia siguiente. A las 18.00 el mismo empleado apaga la computadora ...
Un colega se le acerca:
-Como no te da vergüenza, estamos trabajando, al final del trimestre, tantos informes, también queremos llegar a casa a tiempo y tú eres tan individual ...
- Chicos, generalmente estoy de vacaciones!
... continuará.
Sí, casi olvido adjuntar el código del procedimiento de cálculo RNN, es válido y está escrito de forma independiente, por lo que tal vez haya errores en él. Para la amplificación, lo traeré como está, está en c ++ como se aplica a CUDA (una biblioteca para calcular en la GPU).
Nota: las matrices multidimensionales no se llevan bien con las GPU, por supuesto que hay texturas y cálculos de matriz, pero recomiendan usar matrices unidimensionales.
Un ejemplo de una matriz [i, j] de dimensión M por j se convierte en una matriz de la forma [i * M + j].
Código fuente del procedimiento de cálculo RNN __global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int threadN = gridDim.x * blockDim.x; int TopologySize = Const->TopologySize; for (int pos = tid; pos < numElements; pos += threadN) { const int ii = pos; const int iiA = pos*Const->ArrayDim; int ArrayDim = Const->ArrayDim; const int iiAT = ii*TopologySize*ArrayDim; if (bot[pos].TTF != 0 && bot[pos].Mass>0) { RNN->outputs[iiA + Topology[0]] = 1.f; //bias int neuroncount7 = Topology[0]; neuroncount7++; for (int layer1 = 0; layer1 < TopologySize - 1; layer1++) { for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++) { for (int i5 = 0; i5 < Topology[layer1] + 1; i5++) { RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] * RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4]; } } if (TopologyRNN[layer1] > 0) { for (int j14 = 0; j14 < Topology[layer1]; j14++) { for (int i15 = 0; i15 < Topology[layer1]; i15++) { RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] * RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14]; } RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f* RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1 } for (int t = 0; t < Topology[layer1 + 1]; t++) { RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]); RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t]; } //SoftMax /* double sum = 0.0; for (int k = 0; k <ArrayDim; ++k) sum += exp(RNN->outputs[iiA + k]); for (int k = 0; k < ArrayDim; ++k) RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum; */ } else { for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++) { RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma } } if (layer1 + 1 != TopologySize - 1) { RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f; } for (int i2 = 0; i2 < ArrayDim; i2++) { RNN->sums[iiA + i2] = 0.f; RNN->sumsContext[iiA + i2] = 0.f; } } } } }