Imagina que tienes un párrafo de texto. ¿Es posible entender qué emoción conlleva este texto: alegría, tristeza, ira? Usted puede Simplificamos nuestra tarea y clasificaremos la emoción como positiva o negativa, sin especificación. Hay muchas formas de resolver este problema, y una de ellas son
las redes neuronales convolucionales (
redes neuronales convolucionales). CNN se desarrolló originalmente para el procesamiento de imágenes, pero se las arreglaron con éxito en el campo del procesamiento de texto automático. Le presentaré un análisis binario de la tonalidad de los textos en ruso utilizando una red neuronal convolucional, para la cual se formaron representaciones vectoriales de palabras sobre la base de un modelo
Word2Vec entrenado.
El artículo es de carácter general, hice hincapié en el componente práctico. Y quiero advertirle de inmediato que las decisiones tomadas en cada etapa pueden no ser óptimas. Antes de leer, le recomiendo que se familiarice con el
artículo introductorio sobre el uso de CNN en las tareas de procesamiento del lenguaje natural, así como que lea el
material sobre los métodos de representación vectorial de palabras.
Arquitectura
La arquitectura CNN en consideración se basa en los enfoques [1] y [2]. Enfoque [1], que utiliza el conjunto de redes convolucionales y recurrentes, en la mayor competencia anual en lingüística informática SemEval-2017 ocupó el primer lugar [3] en cinco nominaciones en la tarea para el análisis de tonalidad
Tarea 4 .
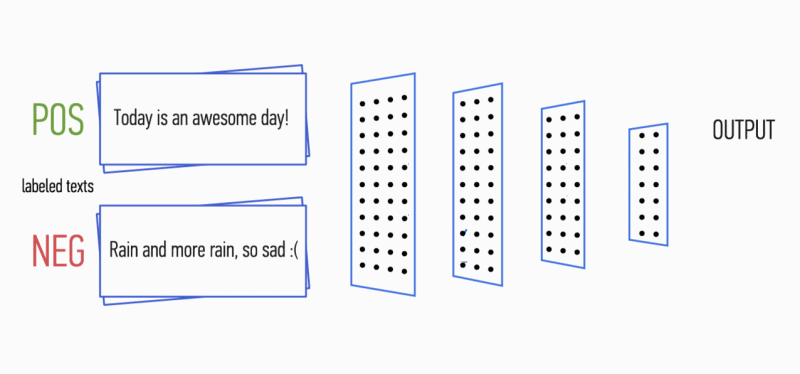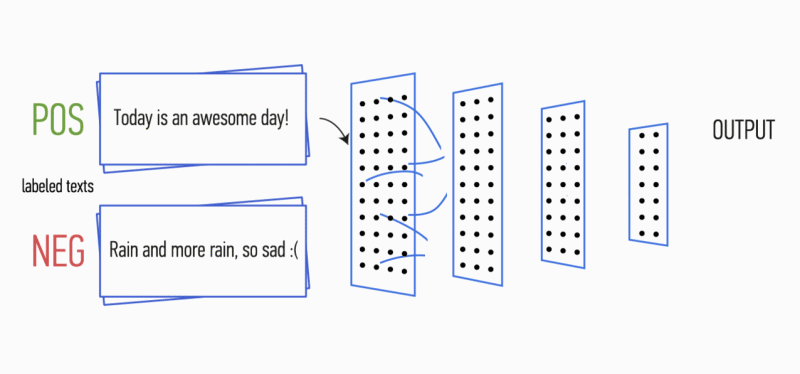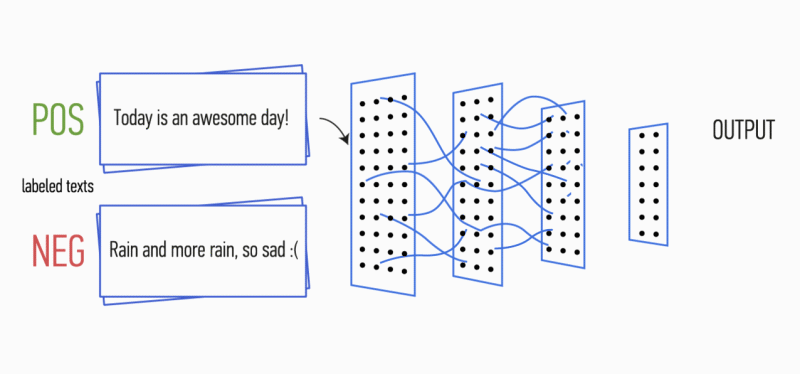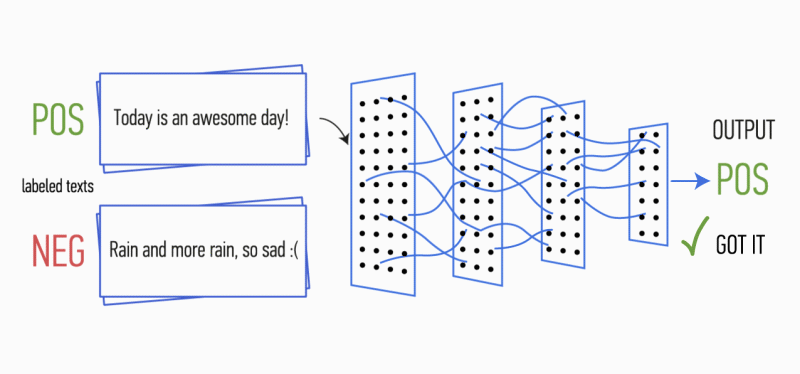
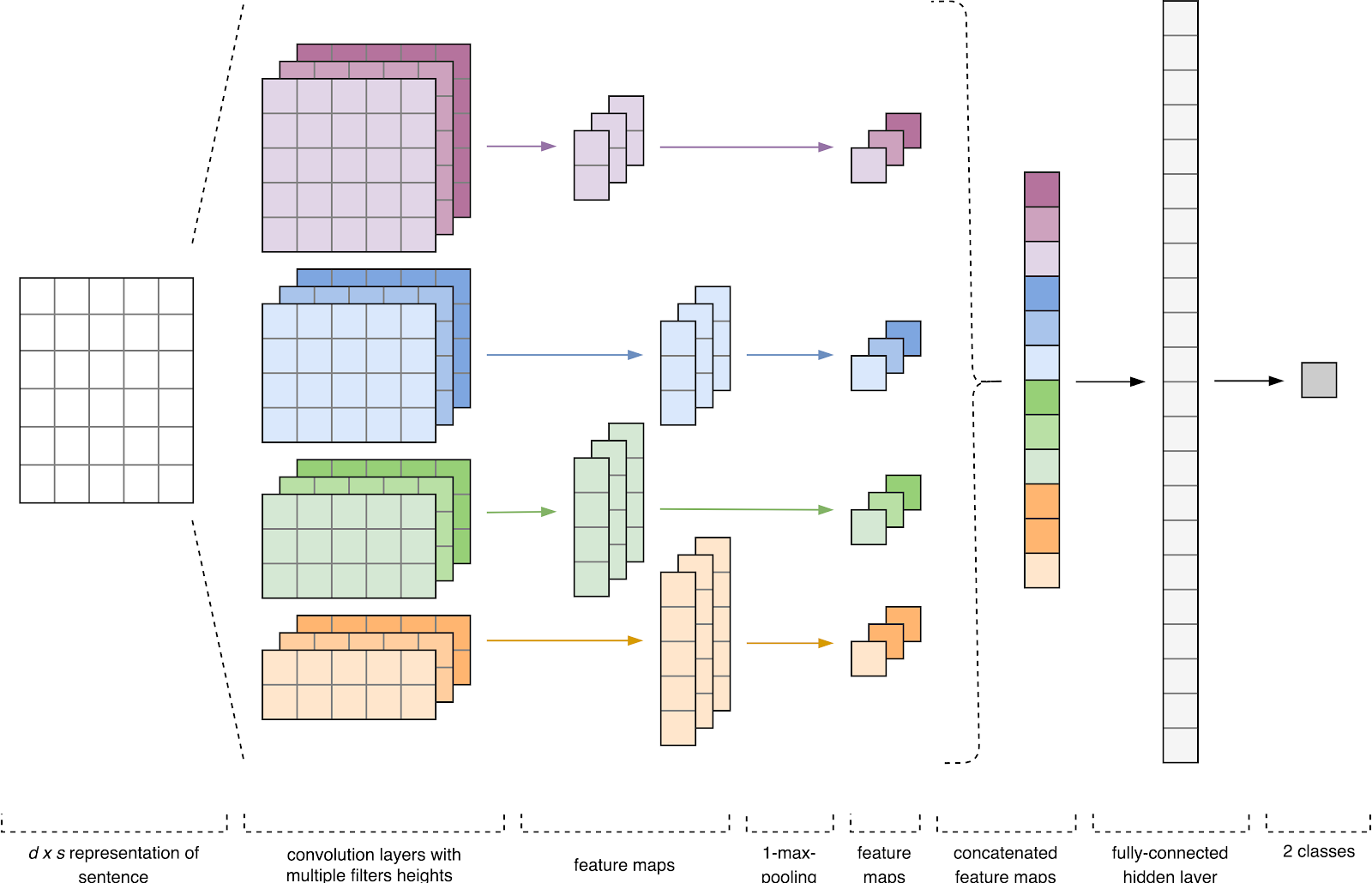 Figura 1. Arquitectura CNN [2].
Figura 1. Arquitectura CNN [2].La entrada CNN (Fig. 1) es una matriz con una altura fija
n , donde cada fila es un mapeo vectorial de una ficha en un espacio de características de dimensión
k . Las herramientas semánticas distributivas, como Word2Vec, Glove, FastText, etc., se utilizan a menudo para formar un espacio de características.
En la primera etapa, la matriz de entrada es procesada por capas de convolución. Como regla, los filtros tienen un ancho fijo igual a la dimensión del espacio de atributo, y solo un parámetro está configurado para tamaños de filtro: altura
h . Resulta que
h es la altura de las líneas adyacentes consideradas juntas por el filtro. En consecuencia, la dimensión de la matriz de características de salida para cada filtro varía según la altura de este filtro
h y la altura de la matriz original
n .
A continuación, el mapa de características obtenido a la salida de cada filtro es procesado por una capa de submuestreo con una función de compactación específica (agrupación 1-max en la imagen), es decir. reduce la dimensión del mapa de entidades generado. Por lo tanto, la información más importante se extrae para cada convolución, independientemente de su posición en el texto. En otras palabras, para la visualización de vectores utilizada, la combinación de capas de convolución y capas de submuestreo permite extraer los
n- gramos más significativos del texto.
Después de esto, los mapas de características calculados a la salida de cada capa de submuestreo se combinan en un vector de características común. Se alimenta a la entrada de una capa oculta, totalmente conectada, y luego se alimenta a la capa de salida de la red neuronal, donde se calculan las etiquetas de clase finales.
Datos de entrenamiento
Para el entrenamiento, elegí el
corpus de textos breves de Yulia Rubtsova , formados a partir de mensajes en ruso de Twitter [4]. Contiene 114 991 tweets positivos, 111 923 negativos, así como una base de tweets no asignados con un volumen de 17 639 674 mensajes.
import pandas as pd import numpy as np
Antes del entrenamiento, los textos pasaron el procesamiento preliminar:
- fundido a minúsculas;
- reemplazo de "e" por "e";
- Reemplazo de enlaces al token "URL";
- reemplazo de la mención del usuario con el token USUARIO;
- eliminando los signos de puntuación.
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
Luego, dividí el conjunto de datos en una muestra de entrenamiento y prueba en una proporción de 4: 1.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
Visualización de vectores de palabras
Los datos de entrada de la red neuronal convolucional es una matriz con una altura fija
n , donde cada fila es un mapeo vectorial de una palabra en un espacio de características de dimensión
k . Para formar la capa de incrustación de una red neuronal, utilicé la utilidad semántica distributiva Word2Vec [5] diseñada para mapear el significado semántico de las palabras en el espacio vectorial. Word2Vec encuentra relaciones entre palabras suponiendo que las palabras relacionadas semánticamente se encuentran en contextos similares. Puede leer más sobre Word2Vec en el
artículo original , así como
aquí y
aquí . Dado que los tweets se caracterizan por la puntuación del autor y los emoticones, definir los límites de las oraciones se convierte en una tarea que requiere mucho tiempo. En este trabajo, asumí que cada tweet contiene solo una oración.
La base de los tweets no asignados se almacena en formato SQL y contiene más de 17.5 millones de registros. Por conveniencia, lo convertí a SQLite usando
este script.
import sqlite3
Luego, usando la biblioteca Gensim, entrené el modelo Word2Vec con los siguientes parámetros:
- size = 200 - dimensión del espacio del atributo;
- ventana = 5 - el número de palabras del contexto que analiza el algoritmo;
- min_count = 3 : la palabra debe aparecer al menos tres veces para que el modelo la tenga en cuenta.
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 Figura 2. Visualización de grupos de palabras similares usando t-SNE.
Figura 2. Visualización de grupos de palabras similares usando t-SNE.Para una comprensión más detallada del funcionamiento de Word2Vec en la Fig.
La Figura 2 muestra la visualización de varios grupos de palabras similares del modelo entrenado, mapeado en un espacio bidimensional utilizando
el algoritmo de visualización t-SNE .
Visualización vectorial de textos
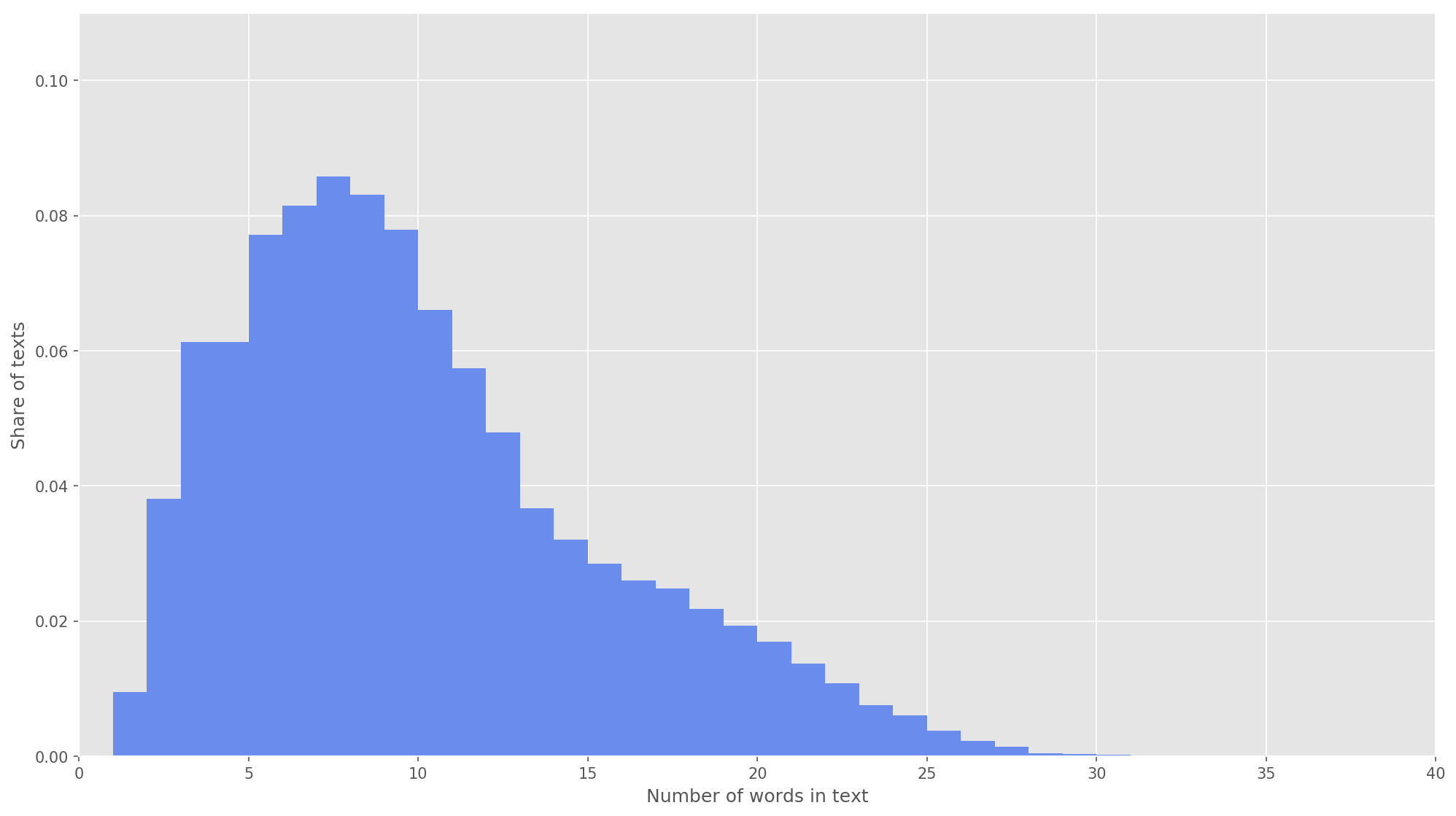 Fig. 3. La distribución de la longitud de los textos.
Fig. 3. La distribución de la longitud de los textos.En el siguiente paso, cada texto se asignó a una matriz de identificadores de token. Elegí la dimensión del vector de texto
s = 26 , ya que a este valor el 99.71% de todos los textos en el cuerpo formado están completamente cubiertos (Fig. 3). Si durante el análisis el número de palabras en el tweet excedió la altura de la matriz, las palabras restantes se descartaron y no se tuvieron en cuenta en la clasificación. La dimensión final de la matriz de propuesta fue
s × d = 26 × 200 .
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
Red neuronal convolucional
Para construir una red neuronal, utilicé la biblioteca Keras, que actúa como un complemento de alto nivel para TensorFlow, CNTK y Theano. Keras tiene una excelente documentación, así como un blog que cubre muchas tareas de aprendizaje automático, como la
inicialización de la capa de incrustación . En nuestro caso, la capa de incrustación se inició por los pesos obtenidos al aprender Word2Vec. Para minimizar los cambios en la capa de inclusión, la congelé en la primera etapa del entrenamiento.
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
En la arquitectura desarrollada, se utilizaron filtros con alturas
h = (2, 3, 4, 5) , que están diseñados para el procesamiento paralelo de bigrams, trigrams, 4 gramos y 5 gramos, respectivamente. Se agregaron 10 capas convolucionales a cada red neuronal para cada altura de filtro, la función de activación es ReLU. Las recomendaciones para encontrar la altura óptima y el número de filtros se pueden encontrar en [2].
Después de procesar por capas de convolución, los mapas de atributos se alimentaron a las capas de submuestreo, donde se les aplicó la operación de agrupación de 1 máx., Extrayendo así los n-gramos más significativos del texto. En la siguiente etapa, se fusionaron en un vector de característica común (capa de combinación), que se alimentó en una capa oculta totalmente conectada con 30 neuronas. En la última etapa, el mapa de características final se alimentó a la capa de salida de la red neuronal con una función de activación sigmoidal.
Dado que las redes neuronales son propensas al reentrenamiento, después de la capa de inclusión y antes de la capa oculta completamente conectada, agregué una regularización de abandono con la probabilidad de una eyección de vértice p = 0.2.
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
Configuré el modelo final con la función de optimización de Adam (Estimación adaptativa del momento) y la entropía cruzada binaria en función de los errores. La calidad del clasificador se evaluó en términos de precisión promedio macro, integridad y medidas f.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
En la primera etapa del entrenamiento, la capa de inclusión se congeló, todas las otras capas se entrenaron durante 10 eras:
- El tamaño del grupo de ejemplos utilizados para la capacitación es 32.
- Tamaño de la muestra de validación: 25%.
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
RegistrosTrain on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
Luego seleccionó el modelo con las medidas F más altas en el conjunto de datos de validación, es decir modelo obtenido en la octava época de la educación (F
1 = 0.7791). El modelo descongeló la capa de incrustación, después de lo cual lanzó cinco eras de entrenamiento más.
from keras import optimizers
RegistrosTrain on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
El indicador más alto
F 1 = 76.80% en la muestra de validación se logró en la tercera era de entrenamiento. La calidad del modelo entrenado en los datos de prueba fue
F 1 = 78.1% .
Tabla 1. Análisis de calidad del sentimiento en los datos de prueba.
Resultado
Como solución de referencia,
entrené a un ingenuo clasificador de Bayes con un modelo de distribución multinomial, los resultados de comparación se presentan en la tabla. 2)
Tabla 2. Comparación de la calidad del análisis del tono.
Como puede ver, la calidad de la clasificación CNN superó a MNB en varios por ciento. Los valores métricos se pueden aumentar aún más si trabaja en la optimización de hiperparámetros y arquitectura de red. Por ejemplo, puede cambiar la cantidad de eras de entrenamiento, verificar la efectividad del uso de varias representaciones vectoriales de palabras y sus combinaciones, seleccionar la cantidad de filtros y su altura, implementar un preprocesamiento de texto más efectivo (corrección tipográfica, normalización, estampado), ajustar la cantidad de neuronas y capas ocultas completamente conectadas en ellas. .
El código fuente
está disponible en Github , los modelos entrenados de CNN y Word2Vec se pueden descargar
aquí .
Fuentes
- Cliche M. BB_twtr en SemEval-2017 Tarea 4: Análisis de sentimientos de Twitter con CNN y LSTM // Actas del 11º Taller internacional sobre evaluación semántica (SemEval-2017). - 2017 .-- S. 573-580.
- Zhang Y., Wallace B. Un análisis de sensibilidad de (y la guía de los practicantes de) Redes neuronales convolucionales para la clasificación de oraciones // arXiv preprint arXiv: 1510.03820. - 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 tarea 4: Análisis de sentimientos en Twitter // Actas del 11º Taller internacional sobre evaluación semántica (SemEval-2017). - 2017 .-- S. 502-518.
- Yu. V. Rubtsova. Creación de un cuerpo de textos para establecer el clasificador de tonos // Software Products and Systems, 2015, No. 1 (109), -C.72-78.
- Mikolov T. y col. Representaciones distribuidas de palabras y frases y su composición // Avances en los sistemas de procesamiento de información neuronal. - 2013 .-- S. 3111-3119.