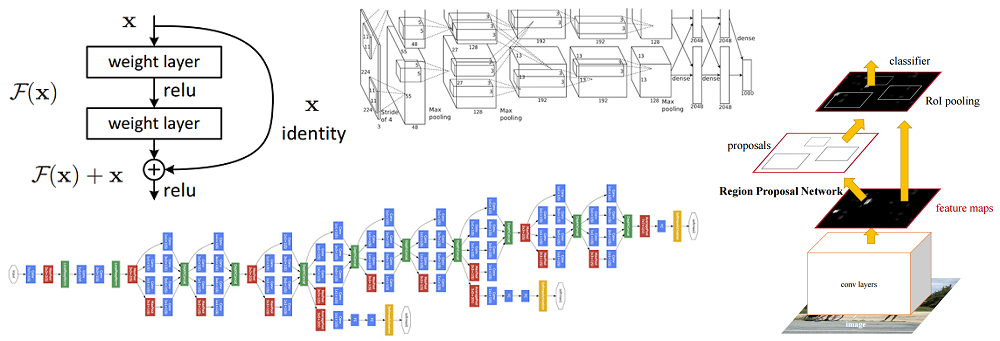
En un artículo anterior,
Descripción general de las redes neuronales para la clasificación de imágenes , nos familiarizamos con los conceptos básicos de las redes neuronales convolucionales, así como las ideas subyacentes. En este artículo, analizaremos algunas arquitecturas de redes neuronales profundas con gran potencia de procesamiento, como AlexNet, ZFNet, VGG, GoogLeNet y ResNet, y resumiremos las principales ventajas de cada una de estas arquitecturas. La estructura del artículo se basa en una entrada de blog
Conceptos básicos de redes neuronales convolucionales, parte 3 .
Actualmente,
ImageNet Challenge es el principal incentivo subyacente al desarrollo de sistemas de reconocimiento de máquinas y clasificación de imágenes. La campaña es una competencia para trabajar con datos, en la que los participantes reciben un gran conjunto de datos (más de un millón de imágenes). La tarea de la competencia es desarrollar un algoritmo que le permita clasificar las imágenes requeridas en objetos en 1000 categorías, como perros, gatos, automóviles y otros, con un número mínimo de errores.
De acuerdo con las reglas oficiales del concurso, los algoritmos deben proporcionar una lista de no más de cinco categorías de objetos en orden descendente de confianza para cada categoría de imágenes. La calidad de marcado de la imagen se evalúa en función de la etiqueta que mejor coincida con la propiedad de verdad de la imagen. La idea es permitir que el algoritmo identifique varios objetos en la imagen y no acumule puntos de penalización en el caso de que alguno de los objetos detectados estuviera realmente presente en la imagen pero no se incluyera en la propiedad de verdad fundamental.
En el primer año de la competencia, los participantes recibieron atributos de imagen preseleccionados para entrenar el modelo. Estos podrían ser, por ejemplo, signos del algoritmo
SIFT procesados usando la cuantificación vectorial y adecuados para su uso en el método de bolsa de palabras o para su presentación como una pirámide espacial. Sin embargo, en 2012 hubo un verdadero avance en esta área: un grupo de científicos de la Universidad de Toronto demostró que una red neuronal profunda puede lograr resultados significativamente más altos en comparación con los modelos tradicionales de aprendizaje automático construidos sobre la base de vectores de propiedades de imagen previamente seleccionadas. En las siguientes secciones, se considerará la primera arquitectura innovadora propuesta en 2012, así como las arquitecturas que son sus seguidores hasta 2015.
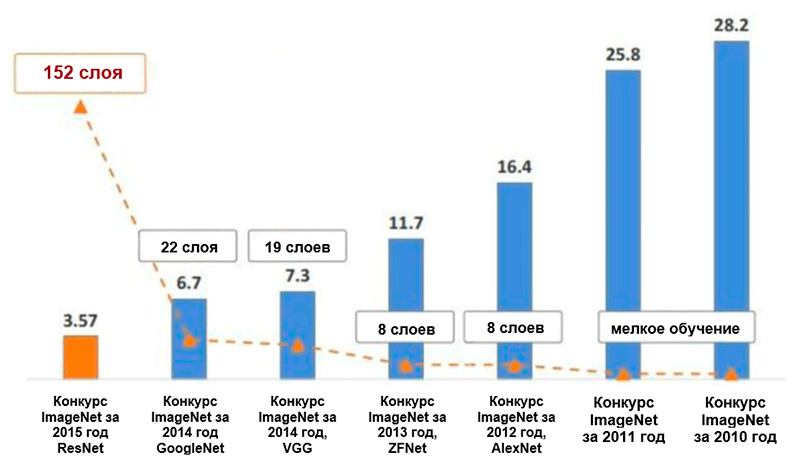 Diagrama de cambios en el número de errores (en porcentaje) en la clasificación de imágenes ImageNet * para las cinco categorías principales. Imagen tomada de la presentación de Kaiming He, aprendizaje residual profundo para el reconocimiento de imágenes
Diagrama de cambios en el número de errores (en porcentaje) en la clasificación de imágenes ImageNet * para las cinco categorías principales. Imagen tomada de la presentación de Kaiming He, aprendizaje residual profundo para el reconocimiento de imágenesAlexnet
La arquitectura
AlexNet fue propuesta en 2012 por un grupo de científicos (A. Krizhevsky, I. Sutskever y J. Hinton) de la Universidad de Toronto. Este fue un trabajo innovador en el que los autores utilizaron por primera vez (en ese momento) redes neuronales convolucionales profundas con una profundidad total de ocho capas (cinco capas convolucionales y tres completamente conectadas).
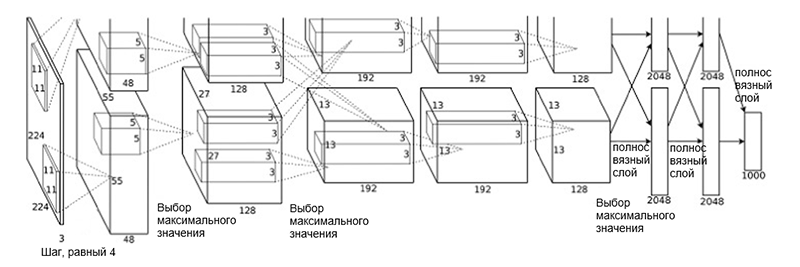 Arquitectura AlexNet
Arquitectura AlexNetLa arquitectura de red consta de las siguientes capas:
- [Capa de convolución + selección de valor máximo + normalización] x 2
- [Capa de convolución] x 3
- [Elegir el valor máximo]
- [Capa completa] x 3
Tal esquema puede parecer un poco extraño, porque el proceso de aprendizaje se dividió entre las dos GPU debido a su alta complejidad computacional. Esta separación de trabajo entre las GPU requiere la separación manual del modelo en bloques verticales que interactúan entre sí.
La arquitectura de AlexNet ha reducido el número de errores para las cinco categorías principales a 16.4 por ciento, ¡casi la mitad en comparación con desarrollos avanzados anteriores! También en el marco de esta arquitectura se introdujo una función de activación como una unidad de rectificación lineal (
ReLU ), que actualmente es el estándar de la industria. El siguiente es un breve resumen de otras características clave de la arquitectura AlexNet y su proceso de aprendizaje:
- Aumento intensivo de datos
- Método de exclusión
- Optimización mediante momento SGD (consulte la guía de optimización "Descripción general de los algoritmos de optimización de descenso de gradiente")
- Ajuste manual de la velocidad de aprendizaje (reducción de este coeficiente en 10 con estabilización de precisión)
- El modelo final es una colección de siete redes neuronales convolucionales.
- La capacitación se realizó en dos procesadores gráficos NVIDIA * GeForce GTX * 580 con un total de 3 GB de memoria de video en cada uno de ellos.
Zfnet
La arquitectura de red
ZFNet propuesta por los investigadores M. Zeiler y R. Fergus de la Universidad de Nueva York es casi idéntica a la arquitectura AlexNet. Las únicas diferencias significativas entre ellos son las siguientes:
- Tamaño del filtro y paso en la primera capa convolucional (en AlexNet, el tamaño del filtro es 11 × 11, y el paso es 4; en ZFNet - 7 × 7 y 2, respectivamente)
- El número de filtros en capas convolucionales limpias (3, 4, 5).
 Arquitectura ZFNet
Arquitectura ZFNetGracias a la arquitectura ZFNet, el número de errores para las cinco categorías principales cayó al 11.4 por ciento. Quizás el papel principal en esto es jugado por el ajuste preciso de los hiperparámetros (tamaño y número de filtros, tamaño del paquete, velocidad de aprendizaje, etc.). Sin embargo, también es probable que las ideas de la arquitectura ZFNet se hayan convertido en una contribución muy significativa al desarrollo de redes neuronales convolucionales. Ziller y Fergus propusieron un sistema para visualizar núcleos, pesos y una vista oculta de imágenes llamada DeconvNet. Gracias a ella, se hizo posible una mejor comprensión y un mayor desarrollo de las redes neuronales convolucionales.
VGG Net
En 2014, K. Simonyan y E. Zisserman de la Universidad de Oxford propusieron una arquitectura llamada
VGG . La idea principal y distintiva de esta estructura es
mantener los filtros lo más simples posible . Por lo tanto, todas las operaciones de convolución se realizan con un filtro de tamaño 3 y un paso de tamaño 1, y todas las operaciones de submuestreo se realizan con un filtro de tamaño 2 y un paso de tamaño 2. Sin embargo, esto no es todo. Junto con la simplicidad de los módulos convolucionales, la red ha crecido significativamente en profundidad, ¡ahora tiene 19 capas! La idea más importante, propuesta por primera vez en este trabajo, es
imponer capas convolucionales sin capas de submuestreo . La idea subyacente es que dicha superposición aún proporciona un campo receptivo suficientemente grande (por ejemplo, tres capas convolucionales superpuestas de tamaño 3 × 3 en pasos de 1 tienen un campo receptivo similar a una capa convolucional de tamaño 7 × 7), sin embargo, el número de parámetros es significativamente menor que en redes con filtros grandes (sirve como regularizador). Además, es posible introducir transformaciones no lineales adicionales.
Esencialmente, los autores han demostrado que incluso con bloques de construcción muy simples, puede lograr resultados de calidad superior en el concurso ImageNet. El número de errores para las cinco categorías principales se redujo a 7.3 por ciento.
 Arquitectura VGG. Tenga en cuenta que el número de filtros es inversamente proporcional al tamaño espacial de la imagen.
Arquitectura VGG. Tenga en cuenta que el número de filtros es inversamente proporcional al tamaño espacial de la imagen.GoogleNet
Anteriormente, todo el desarrollo de la arquitectura consistía en simplificar los filtros y aumentar la profundidad de la red. En 2014, C. Szegedy, junto con otros participantes, propuso un enfoque completamente diferente y creó la arquitectura más compleja en ese momento, llamada GoogLeNet.
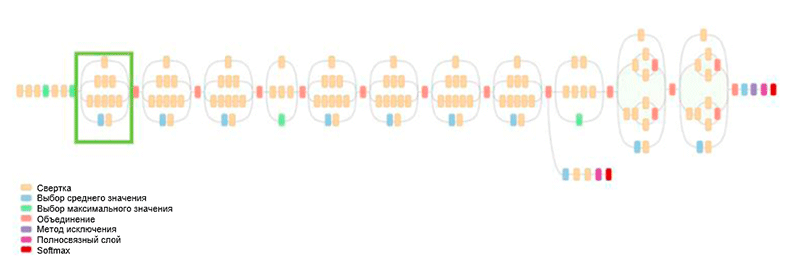 Arquitectura GoogLeNet. Utiliza el módulo Inception, resaltado en verde en la figura; la construcción de redes se basa en estos módulos
Arquitectura GoogLeNet. Utiliza el módulo Inception, resaltado en verde en la figura; la construcción de redes se basa en estos módulosUno de los principales logros de este trabajo es el denominado módulo Inception, que se muestra en la figura a continuación. Las redes de otras arquitecturas procesan los datos de entrada secuencialmente, capa por capa, mientras usan el módulo Inception,
los datos de entrada se procesan en paralelo . Esto le permite acelerar la salida, así como minimizar el
número total de parámetros .
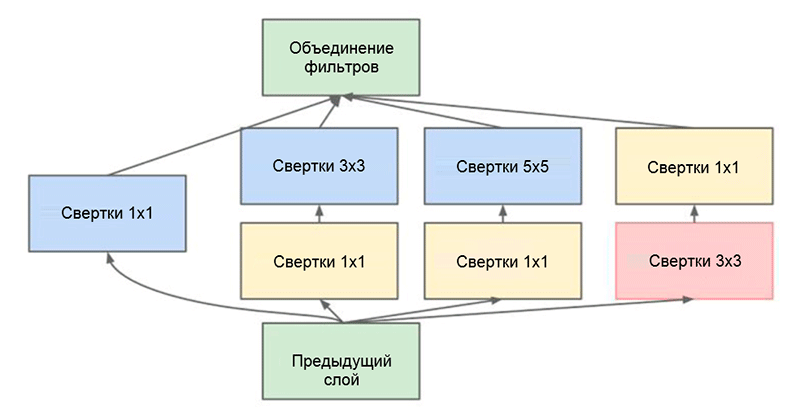 Módulo de inicio. Tenga en cuenta que el módulo usa varias ramas paralelas, que calculan diferentes propiedades en función de los mismos datos de entrada, y luego combinan los resultados
Módulo de inicio. Tenga en cuenta que el módulo usa varias ramas paralelas, que calculan diferentes propiedades en función de los mismos datos de entrada, y luego combinan los resultadosOtro truco interesante utilizado en el módulo Inception es usar capas convolucionales de tamaño 1 × 1. Esto puede parecer inútil hasta que recordemos el hecho de que el filtro cubre toda la dimensión de profundidad. Por lo tanto, una convolución 1 × 1 es una forma simple de reducir la dimensión de un mapa de propiedades. Este tipo de capas convolucionales fue introducido por primera vez en la
red por M. Lin et al., Una explicación comprensible y comprensible también se puede encontrar en la publicación del blog
Convolución [1 × 1] - utilidad contraria a la intuición por A. Prakash.
Finalmente, esta arquitectura redujo el número de errores para las cinco categorías principales en otro medio por ciento, a un valor de 6.7 por ciento.
Resnet
En 2015, un grupo de investigadores (Cuming Hee y otros) de Microsoft Research Asia tuvo una idea que actualmente la mayoría de la comunidad considera una de las etapas más importantes en el desarrollo del aprendizaje profundo.
Uno de los principales problemas de las redes neuronales profundas es el problema de un gradiente de fuga. En pocas palabras, este es un problema técnico que surge cuando se utiliza el método de propagación de error de retroceso para el algoritmo de cálculo de gradiente. Cuando se trabaja con propagación hacia atrás de errores, se utiliza una regla de cadena. Además, si el gradiente tiene un valor pequeño al final de la red, entonces puede tomar un valor infinitamente pequeño para cuando llegue al comienzo de la red. Esto puede conducir a problemas de una naturaleza completamente diferente, incluida la imposibilidad de aprender la red en principio (para obtener más información, consulte la entrada del blog de R. Kapur
El problema de un gradiente de desvanecimiento ).
Para resolver este problema, Caiming Hee y su grupo propusieron la siguiente idea: permitir que la red estudie el mapeo residual (un elemento que debe agregarse a la entrada) en lugar de la pantalla en sí. Técnicamente, esto se hace utilizando la conexión de derivación que se muestra en la figura.
 Diagrama esquemático del bloque residual: los datos de entrada se transmiten a través de una conexión acortada sin pasar por las capas de conversión y se agregan al resultado. Tenga en cuenta que una conexión "idéntica" no agrega parámetros adicionales a la red, por lo tanto, su estructura no es complicada
Diagrama esquemático del bloque residual: los datos de entrada se transmiten a través de una conexión acortada sin pasar por las capas de conversión y se agregan al resultado. Tenga en cuenta que una conexión "idéntica" no agrega parámetros adicionales a la red, por lo tanto, su estructura no es complicadaEsta idea es extremadamente simple, pero al mismo tiempo extremadamente efectiva. Resuelve el problema del gradiente que desaparece, permitiéndole moverse sin ningún cambio desde las capas superiores a las inferiores a través de conexiones "idénticas". Gracias a esta idea, puedes entrenar redes muy profundas y extremadamente profundas.
La red que ganó el ImageNet Challenge en 2015 contenía 152 capas (los autores pudieron entrenar la red que contenía 1001 capas, pero produjo aproximadamente el mismo resultado, por lo que dejaron de trabajar con ella). Además, esta idea hizo posible reducir literalmente a la mitad la cantidad de errores para las cinco categorías principales, a un valor de 3.6 por ciento. Según un estudio de
Lo que aprendí al competir con una red neuronal convolucional en el concurso ImageNet de A. Karpathy, el rendimiento humano para esta tarea es aproximadamente del 5 por ciento. Esto significa que la arquitectura ResNet es capaz de superar los resultados humanos, al menos en esta tarea de clasificación de imágenes.