¿Puedo decirles a los desarrolladores front-end sobre la arquitectura sin servidor sin nube dentro de AWS (Amazon Web Services) de una manera simple? Por qué no Presentemos la aplicación AWS React / Redux y luego hablemos sobre los pros y los contras de las lambdas de AWS.
El material se basa en la transcripción del informe de Marina Mironovich de nuestra conferencia de primavera HolyJS 2018 en San Petersburgo.Oficialmente, Marina es un desarrollador líder de EPAM. Ahora trabaja en un grupo de arquitectos de soluciones para un cliente y por eso participa en una gran cantidad de proyectos. Por lo tanto, será más fácil para nosotros esbozar el círculo de sus intereses actuales que enumerar todas las tecnologías con las que trabaja.
 En primer lugar, estoy interesado en todas las tecnologías en la nube, en particular, AWS, porque trabajo mucho con esto en producción. Pero trato de mantenerme al día con todo lo demás.
En primer lugar, estoy interesado en todas las tecnologías en la nube, en particular, AWS, porque trabajo mucho con esto en producción. Pero trato de mantenerme al día con todo lo demás.
Frontend es mi primer amor y parece para siempre. En particular, actualmente estoy trabajando con React y React Native, así que sé un poco más al respecto. También trato de hacer un seguimiento de todo lo demás. Estoy interesado en todo lo relacionado con la documentación del proyecto, por ejemplo, diagramas UML. Como soy miembro del grupo de arquitectos de soluciones, tengo que hacer mucho.
Parte 1. Antecedentes
La idea de hablar sobre Serverless se me ocurrió hace aproximadamente un año. Quería hablar sobre Serverless para desarrolladores front-end de manera fácil y natural. Para que no necesite ningún conocimiento adicional para usarlo, las tecnologías ahora le permiten hacerlo.
Hasta cierto punto, la idea se realizó:
hablé de Serverless en FrontTalks 2017. Pero resultó que 45 minutos no son suficientes para una historia simple y comprensible. Por lo tanto, el informe se dividió en dos partes, y ahora ante ustedes está la segunda "serie". Quién no vio lo primero: no se preocupe, esto no le hará daño a entender lo que está escrito a continuación. Como en los programas de TV decentes, comenzaré con un resumen de la parte anterior. Luego pasaré al jugo en sí mismo: presentaremos la aplicación React / Redux. Y finalmente, hablaré sobre los pros y los contras de las funciones de la nube en principio (en particular, AWS lambdas) y qué más se puede hacer con ellas. Espero que esta parte sea útil para todos aquellos que ya están familiarizados con la AWS lambda. Lo más importante es que el mundo no termina con Amazon, así que hablemos sobre qué más hay en el campo de las funciones en la nube.
Lo que usaré
Para representar la aplicación, utilizaré muchos servicios de Amazon:
- S3 es un sistema de archivos en las nubes. Allí almacenaremos activos estáticos.
- IAM (derechos de acceso para usuarios y servicios): implícitamente, pero se utilizará en segundo plano para que los servicios se comuniquen entre sí.
- API Gateway (URL para acceder al sitio): verá la URL donde podemos llamar a nuestra lambda.
- CloudFormation (para implementación): se utilizará implícitamente en segundo plano.
- AWS Lambda: vinimos aquí para esto.
¿Qué es sin servidor y qué es AWS Lambda?
En realidad, Serverless es un gran fraude, porque por supuesto hay servidores: en algún lugar, todo comienza. ¿Pero qué está pasando allí?
Estamos escribiendo una función, y esta función se ejecuta en los servidores. Por supuesto, comienza no solo así, sino en algún tipo de contenedor. Y, de hecho, esta función en el contenedor del servidor se llama lambda.
En el caso de lambda, podemos olvidarnos de los servidores. Incluso diría esto: cuando escribes la función lambda, es dañino pensar en ellas. No trabajamos con lambda como lo hacemos con un servidor.
Cómo implementar lambda
Surge una pregunta lógica: si no tenemos un servidor, ¿cómo lo implementamos? Hay SSH en el servidor, subimos el código, lo lanzamos, todo está bien. ¿Qué hacer con lambda?
Opción 1. No podemos implementarlo.AWS en la consola hizo un IDE agradable y gentil para nosotros, donde podemos venir y escribir una función allí mismo.

Es agradable, pero no muy extensible.
Opción 2. Podemos hacer un zip y descargarlo desde la línea de comando¿Cómo hacemos un archivo zip?
zip -r build/lambda.zip index.js [node_modules/] [package.json]
Si usa node_modules, todo esto se comprime en un archivo.
Además, dependiendo de si está creando una nueva función o si ya la tiene, puede
aws lambda create-function...
cualquiera
aws lambda update-function-code...
Cual es el problema Primero, la AWS CLI quiere saber si se está creando una función o si ya tiene una. Estos son dos equipos diferentes. Si desea actualizar no solo el código, sino también algunos atributos de esta función, comienzan los problemas. El número de estos comandos está creciendo, y debe sentarse con un directorio y pensar qué comando usar.
Podemos hacerlo mejor y más fácil. Para esto, tenemos marcos.
Marcos de trabajo de AWS Lambda
Hay muchos de esos marcos. Esto es principalmente AWS CloudFormation, que funciona en conjunto con la AWS CLI. CloudFormation es un archivo Json que describe sus servicios. Los describe en un archivo Json, luego a través de la CLI de AWS dice "ejecutar", y automáticamente creará todo para usted en el servicio de AWS.
Pero aún es difícil para una tarea tan simple como renderizar algo. Aquí el umbral de entrada es demasiado grande: debe leer qué estructura tiene CloudFormation, etc.
Tratemos de simplificarlo. Y aquí aparecen varios marcos: APEX, Zappa (solo para Python), Claudia.js. Enumeré solo unos pocos, al azar.
El problema y la fortaleza de estos marcos es que son altamente especializados. Por lo tanto, son muy buenos para hacer una tarea simple. Por ejemplo, Claudia.js es muy bueno para crear una API REST. Ella hará que AWS llame a API Gateway, creará una lambda para usted, todo estará bellamente bloqueado. Pero si necesita desplegar un poco más, comienzan los problemas: tiene que agregar algo, ayuda, mirar, etc.
Zappa fue escrito solo para Python. Y quiero algo más ambicioso. Y aquí viene Terraform y mi amor sin servidor.
Sin servidor se encuentra en un punto intermedio entre la gran CloudFormation, que puede hacer casi todo, y estos marcos altamente especializados. Casi todo se puede implementar en él, pero hacerlo todo sigue siendo bastante fácil. También tiene una sintaxis muy ligera.
Terraform es, en cierta medida, un análogo de CloudFormation. Terraform es de código abierto, en él puedes implementar todo, bueno, o casi todo. Y cuando AWS crea los servicios, puede agregar algo nuevo allí. Pero es grande y complicado.
Para ser honesto, en producción usamos Terraform, porque con Terraform todo lo que tenemos sube más fácilmente: Serverless no describirá todo esto. Pero Terraform es muy complejo. Y cuando escribo algo para el trabajo, primero lo escribo en Serverless, lo pruebo para el rendimiento, y solo después de probar y resolver mi configuración, lo reescribo en Terraform (esto es "divertido" por un par de días más).
Sin servidor
¿Por qué amo Serverless?
- Sin servidor tiene un sistema que le permite crear complementos. En mi opinión, esta es una salvación de todo. Sin servidor: código abierto. Pero agregar algo al código abierto no siempre es fácil. Debe comprender lo que está sucediendo en el código existente, observar las pautas, al menos el estilo de código, enviar un RP, se olvidarán de este RP y acumulará polvo durante tres años. De acuerdo con los resultados, se bifurca, y esto será un lugar para usted por separado. Todo esto no es muy saludable. Pero cuando hay complementos, todo se simplifica. Necesita agregar algo: está de rodillas creando su propio pequeño complemento. Para hacer esto, ya no necesita comprender lo que está sucediendo dentro de Serverless (si esta no es una pregunta súper personalizada). Simplemente use la API disponible, guarde el complemento o impleméntelo para todos. Y todo te funciona. Además, ya hay un gran zoológico de complementos y personas que escriben estos complementos. Es decir, tal vez ya se haya decidido algo por usted.
- Sin servidor ayuda a ejecutar lambda localmente. La desventaja lo suficientemente grande del lambda es que AWS no pensó en cómo lo depuraremos y probaremos. Pero Serverless le permite ejecutar todo localmente, ver qué sucede (incluso lo hace junto con la API de Gateway).
Demostración
Ahora mostraré cómo funciona todo esto realmente. Durante los próximos uno y medio o dos minutos, podremos crear un servicio que representará nuestra página HTML.
Primero, en una nueva carpeta, ejecuto SLS Create template:
mkdir sls-holyjs
cd sls-holyjs
sls create --template aws-nodejs-ecma-script

npm install

Los desarrolladores sin servidor se encargaron de nosotros: hicieron posible crear servicios a partir de plantillas. En este caso, uso la plantilla
nodejs-ecma-script , que creará algunos archivos para mí, como la configuración del paquete web, package.json, algunas funciones y serverless.yml:
ls

No necesito todas las funciones. Eliminaré el primer, segundo cambio de nombre en holyjs:

Ajustaré un poco serveless.yml, donde tengo una descripción de todos los servicios necesarios:
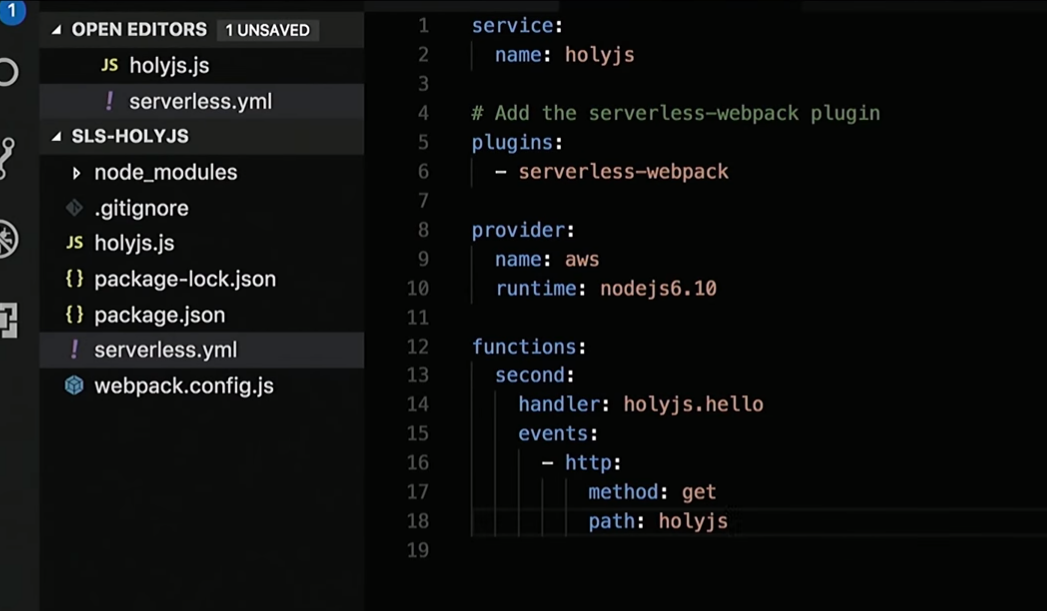
Bueno, entonces arreglaré la respuesta que devuelve la función:

Haré el HTML "Hola HolyJS" y agregaré el identificador para la representación.
Siguiente:
sls deploy
Y voila! Hay una URL donde puedo ver en acceso público lo que se está representando:

Confía, pero verifica. Iré a la consola de AWS y verificaré que he creado una función holyjs:
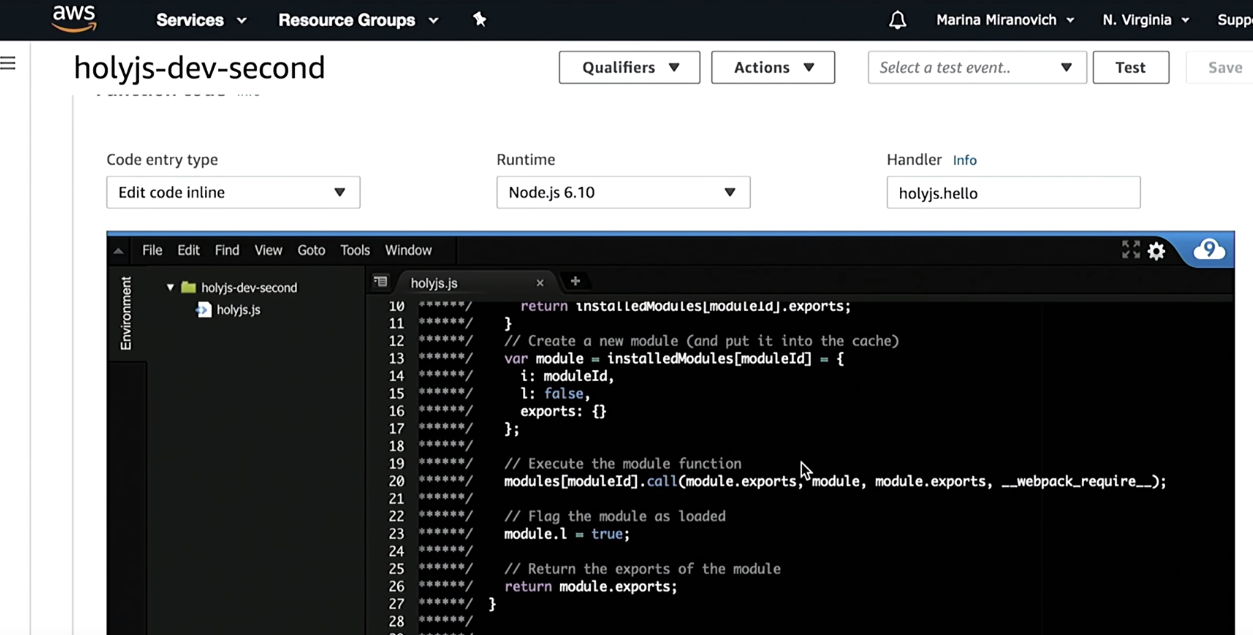
Como puede ver, antes de implementarlo, Serverless lo compilará utilizando webpack. Además, se creará el resto de la infraestructura que se describe allí: API Gateway, etc.
Cuando quiero eliminar esto:
sls remove
Toda la infraestructura que se describe en serverless.yml se eliminará.

Si alguien está detrás del proceso descrito aquí, lo invito a que simplemente revise mi
informe anterior .
Ejecute lambda localmente
Mencioné que lambda se puede ejecutar localmente. Hay dos opciones de lanzamiento aquí.
Opción 1. Simplemente ejecutamos todo en la terminalObtenemos lo que devuelve nuestra función.
sls invoke local -f [fn_name]
No lo olviden, estamos haciendo una aplicación isomorfa, será HTML y CSS, por lo que en la terminal de alguna manera no es muy interesante mirar largas líneas HTML. Allí puede verificar que la función funciona. Pero me gustaría ejecutar y renderizar esto en el navegador. En consecuencia, necesito un montón de puerta de enlace API con lambda.
Para hacer esto, hay un complemento separado sin servidor sin conexión que iniciará su lambda en algún puerto (esto está escrito), luego mostrará una URL en el terminal donde puede acceder.
sls offline --port 8000 start
La mejor parte es que hay una recarga en caliente. Es decir, usted escribe el código de la función, actualiza su navegador y se actualiza lo que devuelve la función. No tiene que reiniciar todo.
Este fue un resumen de la primera parte del informe. Ahora pasamos a la parte principal.
Parte 2. Renderizado con AWS
El proyecto descrito a continuación
ya está en GitHub. Si está interesado, puede descargar el código allí.
Comencemos con cómo funciona todo.

Supongamos que hay un usuario: yo.
- Abro el sitio.
- En una determinada URL, accedemos a la API de la puerta de enlace. Quiero señalar que la API de Gateway ya es un servicio de AWS, ya estamos en las nubes.
- Gateway API llamará a lambda.
- La lambda representará el sitio y todo esto volverá al navegador.
- El navegador comenzará a renderizarse y se dará cuenta de que faltan algunos archivos estáticos. Luego, recurrirá al depósito S3 (nuestro sistema de archivos, donde almacenaremos todas las estadísticas; en el depósito S3 puede poner todo: fuentes, imágenes, CSS, JS).
- Los datos del depósito S3 volverán al navegador.
- El navegador mostrará la página.
- Todos son felices
Hagamos una pequeña revisión de código de lo que escribí.
Si va a GitHub, verá la siguiente estructura de archivos:
lambda-react
README.md
config
package.json
public
scripts
serverless.yml
src
yarn.lock
Todo esto se genera automáticamente en el kit de herramientas React / Redux. De hecho, aquí nos interesarán solo un par de archivos y deberán corregirse ligeramente:
- config
- package.json
- serverless.yml: porque implementaremos,
- src: en ninguna parte sin ella.
Comencemos con la configuración
Para reunir todo en el servidor, necesitamos agregar otro webpack.config:

Este webpack.config ya se generará si utiliza la plantilla. Y allí la variable
slsw.lib.entries se sustituye automáticamente, lo que apuntará a sus controladores lambda. Si lo desea, puede cambiarlo usted mismo especificando algo más.

Necesitaremos renderizar todo para el nodo (
target: 'node' ). En principio, todos los demás cargadores siguen siendo los mismos que para una aplicación React normal.
Además de package.json
Solo agregaremos un par de scripts: el inicio y la compilación ya se han generado con React / Redux, nada cambia. Agregue un script para iniciar el lambda y un script para implementar el lambda.

serverless.yml
Un archivo muy pequeño: solo 17 líneas, todas a continuación:

¿Qué nos interesa en él? En primer lugar, manejador.
src/lambda/handler se
src/lambda/handler la ruta completa al archivo (
src/lambda/handler ) y la función del controlador se especifica a través del punto.
Si realmente lo desea, puede registrar varios controladores en un archivo. También aquí está el camino a webpack, que debería recopilar todo esto. Básicamente, todo: el resto ya se genera automáticamente.
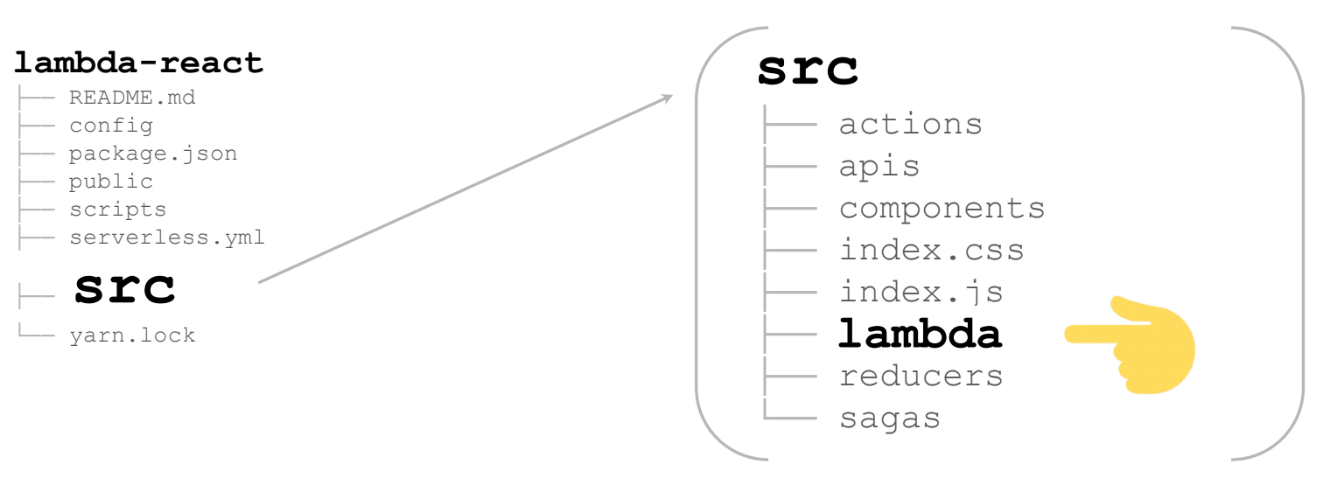
Lo más interesante es src
Aquí hay una gran aplicación React / Redux (en mi caso no es enorme, para la página). En la carpeta lambda adicional hay todo lo que necesitamos para representar el lambda:
Estos son 2 archivos:
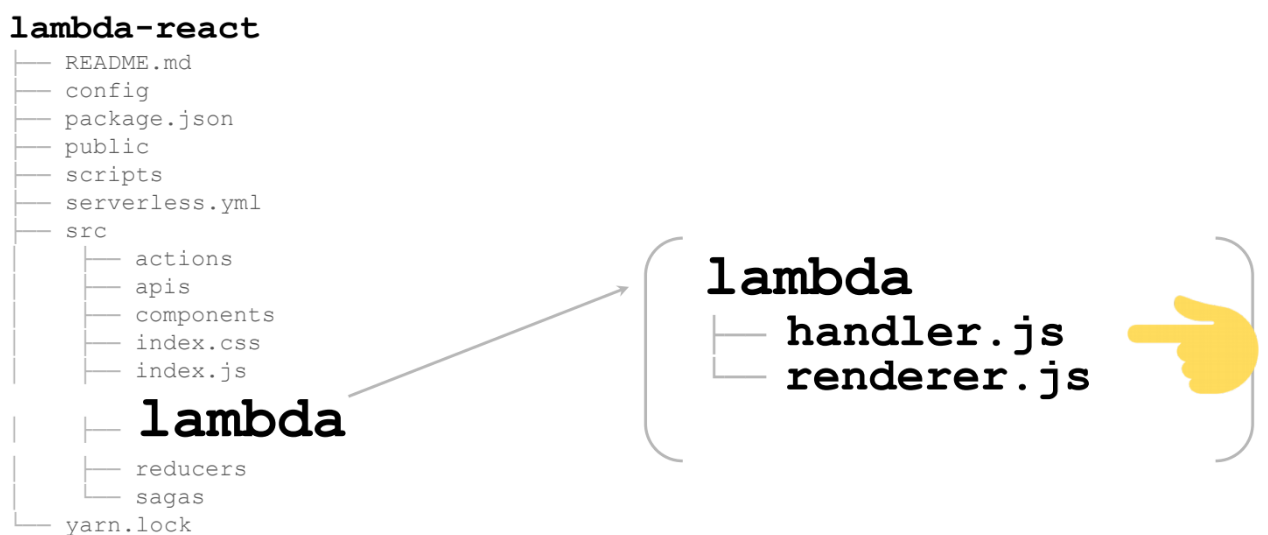
Comencemos con el controlador. Lo más importante es la línea 13. Este es el renderizador, que es la misma lambda que se llamará en las nubes:

Como puede ver, la función
render () devuelve una promesa, de la cual deben capturarse todas las excepciones. Esta es la peculiaridad de la lambda, de lo contrario, la lambda no terminará de inmediato, sino que funcionará hasta el tiempo de espera. Tendrá que pagar dinero extra por un código que ya ha caído. Para evitar que esto suceda, debe terminar la lambda lo antes posible; en primer lugar, capturar y manejar todas las excepciones. Más tarde volveremos a esto.
Si no tenemos ningún error o excepción, llamamos a la función
createResponse , que toma literalmente cinco líneas. Solo agregamos todos los encabezados para que se muestre correctamente en el navegador:

Lo más interesante aquí es la función de
render , que renderizará nuestra página:

Esta función nos viene de renderer.js. Veamos que hay ahí.
Allí se presenta una aplicación isomórfica. Además, se procesa en cualquier servidor, no importa si es lambda o no.
No le diré en detalle sobre qué es una aplicación isomorfa, cómo representarla, porque este es un tema completamente diferente, y hay personas que lo dijeron mejor que yo. Aquí hay algunos tutoriales que encontré buscando en Google en solo un par de minutos:

Si conoce otros informes, puede aconsejar, les daré enlaces en mi Twitter.
Para no perder a nadie, solo subo las escaleras para contar lo que está sucediendo allí.
En primer lugar, necesitamos renderizar esto con HTML / React / Redux.
Esto se hace a través del método estándar React -
renderToString :

A continuación, necesitamos renderizar estilos para que nuestro contenido no parpadee. Esta no es una tarea muy trivial. Hay varios paquetes npm que lo resuelven. Por ejemplo, usé
node-style-loader , que unirá todo en
styleTag , y luego podrá pegarlo en HTML.

Si hay mejores paquetes, es a su discreción.
Luego necesitamos pasar el estado de Redux. Dado que está procesando en el servidor, probablemente desee obtener algunos datos y no desea que Redux vuelva a preguntar y volver a procesarlos. Esta es una tarea bastante estándar. Hay ejemplos en el sitio web principal de Redux sobre cómo hacer esto: creamos un objeto y luego lo pasamos a través de una variable global:

Ahora un poco más cerca de la lambda.
Es necesario hacer un manejo de errores. Queremos atrapar todo y hacer algo con ellos, al menos detener el desarrollo de lambda. Por ejemplo, hice esto a través de la
promise :

A continuación, debemos sustituir nuestras URL por archivos estáticos. Y para esto necesitamos descubrir dónde corre la lambda, localmente o en algún lugar de las nubes. ¿Cómo averiguarlo?
Lo haremos a través de variables de entorno:
…
const bundleUrl = process.env.NODE_ENV === 'AWS' ?
AWS_URL : LOCAL_URL;
Una pregunta interesante: cómo las variables de entorno se unen en una lambda. En realidad lo suficientemente fácil. En yml, puede pasar cualquier variable al
environment . Cuando esté bloqueado, estarán disponibles:

Bueno, una ventaja: después de implementar una lambda, queremos implementar todos los activos estáticos. Para hacer esto, ya hemos escrito un complemento en el que puede designar la cesta S3 donde desea implementar algo:

En total, realizamos una aplicación isomórfica en aproximadamente cinco minutos para demostrar que todo esto es fácil.
Ahora hablemos un poco sobre la teoría: los pros y los contras de lambda.
Comencemos con lo malo.
Contras funciones lambda
Los inconvenientes pueden incluir (o tal vez no) el momento de un arranque en frío. Por ejemplo, para el lambda en Node.js que estamos escribiendo ahora, la hora de inicio en frío no significa mucho.
El siguiente gráfico muestra el tiempo de arranque en frío. Y esto puede ser un gran problema, especialmente para Java y C # (preste atención a los puntos naranjas): no desea que le tome solo cinco o seis segundos comenzar a ejecutar el código.
Para Node.js, el tiempo de inicio es casi cero - 30 - 50 ms. Por supuesto, para algunos esto también puede ser un problema. Pero las funciones se pueden calentar (aunque este no es el tema de este informe). Si alguien está interesado en cómo se llevaron a cabo estas pruebas, bienvenido a acloud.guru, le contarán todo (
en el artículo ).

¿Cuáles son las desventajas?
Limitaciones de tamaño del código de función
El código debe tener menos de 50 MB. ¿Es posible escribir una función tan grande? Por favor, no te olvides de node_modules. Si conecta algo, especialmente si hay archivos binarios allí, realmente puede superar fácilmente los 50 MB, incluso para archivos zip. He tenido tales casos. Pero esta es una razón adicional para ver lo que está conectando a node_modules.
Limitaciones de tiempo de ejecución
Por defecto, la función se ejecuta por un segundo. Si no termina después de un segundo, tendrá un tiempo de espera. Pero este tiempo se puede aumentar en la configuración. Al crear una función, puede establecer el valor en cinco minutos. Cinco minutos es una fecha límite difícil. Esto no es un problema para el sitio. Pero si desea hacer algo más interesante en lambdas, por ejemplo, procesar imágenes, convertir texto en sonido o sonido en texto, etc., dichos cálculos pueden tomar fácilmente más de cinco minutos. Y eso será un problema. ¿Qué hacer al respecto? Optimizar o no usar lambda.
Otra cosa interesante que surge en relación con el límite de tiempo para la ejecución de lambda. Recordemos el diseño de nuestro sitio. Todo funcionó perfectamente hasta que el producto llegó y deseó en el sitio en tiempo real, para mostrar noticias en tiempo real. Sabemos que esto se implementa con WebSockets. Pero los WebSockets no funcionan durante cinco minutos, deben mantenerse más tiempo. Y aquí el límite de cinco minutos se convierte en un problema.

Un pequeño comentario. Para AWS, esto ya no es un problema. Encontraron cómo evitar esto. Pero hablando en general, tan pronto como aparecen los enchufes web, lambda no es una solución para usted. Necesita cambiar a los viejos servidores buenos nuevamente.
El número de funciones paralelas por minuto.
Arriba hay un límite de 500 a 3,000, dependiendo de la región donde se encuentre. En mi opinión, en Europa casi 500. 3000 es compatible con los Estados Unidos.
Si tiene un sitio ocupado y espera más de tres mil solicitudes por minuto (lo cual es fácil de imaginar), esto se convierte en un problema. Pero antes de hablar sobre este signo negativo, hablemos un poco sobre cómo escala lambda.
Nos llega una solicitud y recibimos una lambda. Mientras se ejecuta esta lambda, nos llegan dos solicitudes más: comenzamos dos lambdas más. La gente comienza a venir a nuestro sitio, aparecen solicitudes y se lanzan lambdas, cada vez más.

Al hacerlo, paga el tiempo en que se ejecuta la lambda. Supongamos que paga un centavo por un segundo de ejecución lambda. Si tiene 10 lambdas por segundo, pagará 10 centavos por este segundo. Si tiene un millón de lambdas funcionando por segundo, eso es alrededor de 10 mil dólares. Figura desagradable.
Por lo tanto, AWS decidió que no quieren vaciar su billetera en un segundo si realizó sus pruebas de manera incorrecta e inició DDOS usted mismo, causando lambdas o alguien más vino a hacer DDOS. Por lo tanto, se estableció un límite de tres mil, para que tenga la oportunidad de responder a la situación.
Si la carga de 3000 solicitudes es regular para usted, puede escribir en AWS y aumentarán el límite.
Apátrida
Este es el último, nuevamente, un menos controvertido.
¿Qué es apátrida? Aquí surge una broma sobre peces de colores: simplemente no mantienen el contexto:

La lambda, llamada por segunda vez, no sabe nada sobre la primera llamada.
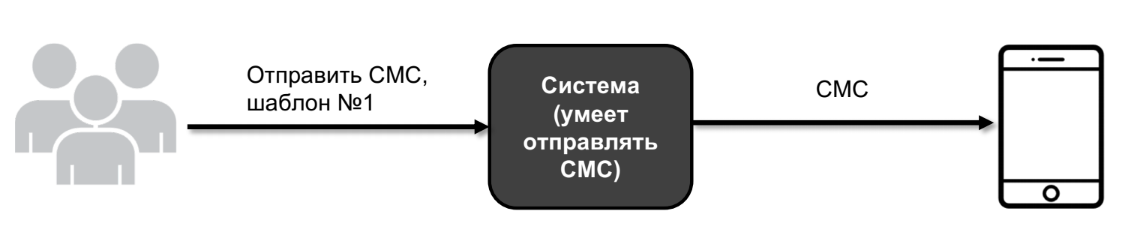
Déjame mostrarte un ejemplo. Digamos que tengo un sistema: una gran caja negra. Y este sistema, entre otras cosas, puede enviar SMS.
El usuario viene y dice: envíe el número de plantilla de SMS 1. Y el sistema lo envía a un dispositivo real.
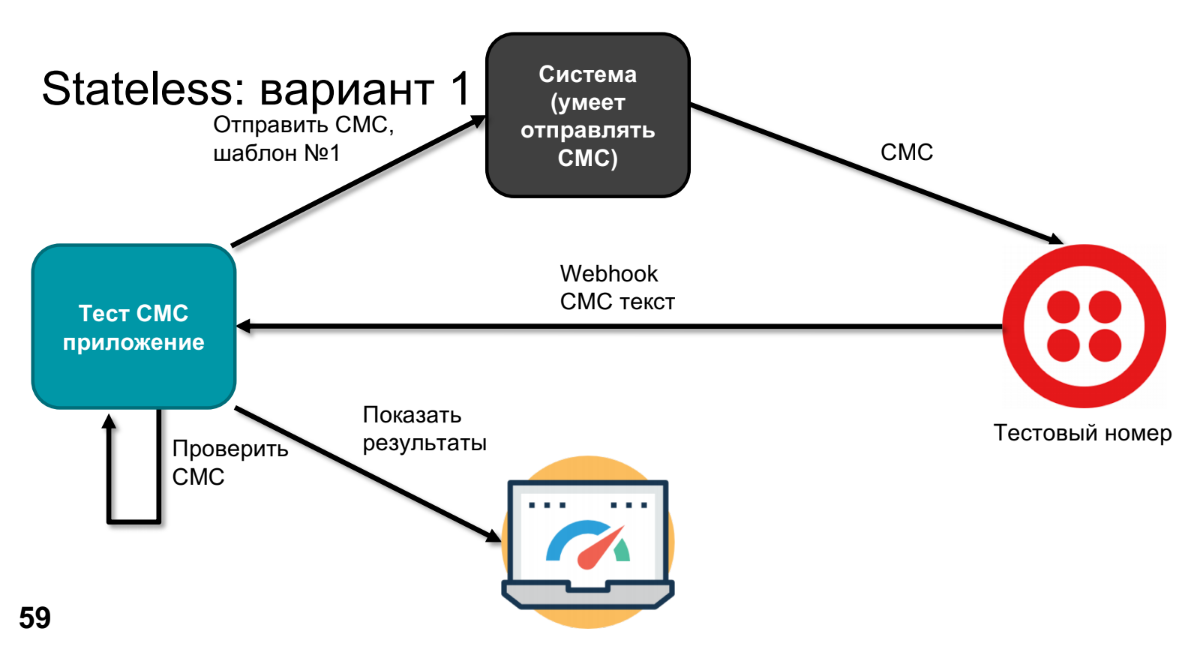
En algún momento, el producto expresa el deseo de descubrir qué irá allí y verificar que nada se rompió en este sistema en ninguna parte. Para hacer esto, reemplazaremos el dispositivo real con algún tipo de número de prueba; por ejemplo, Twilio puede hacer esto. Él llamará a Webhook, enviará el texto SMS, procesaremos este texto SMS en la aplicación (debemos verificar que nuestra plantilla se haya convertido en el SMS correcto).
Para verificar, necesitamos saber qué se envió; lo haremos a través de una aplicación de prueba. Queda por comparar y mostrar los resultados.
Intentemos hacer lo mismo en lambda.
Lambda enviará SMS, SMS llegará a Twilio.
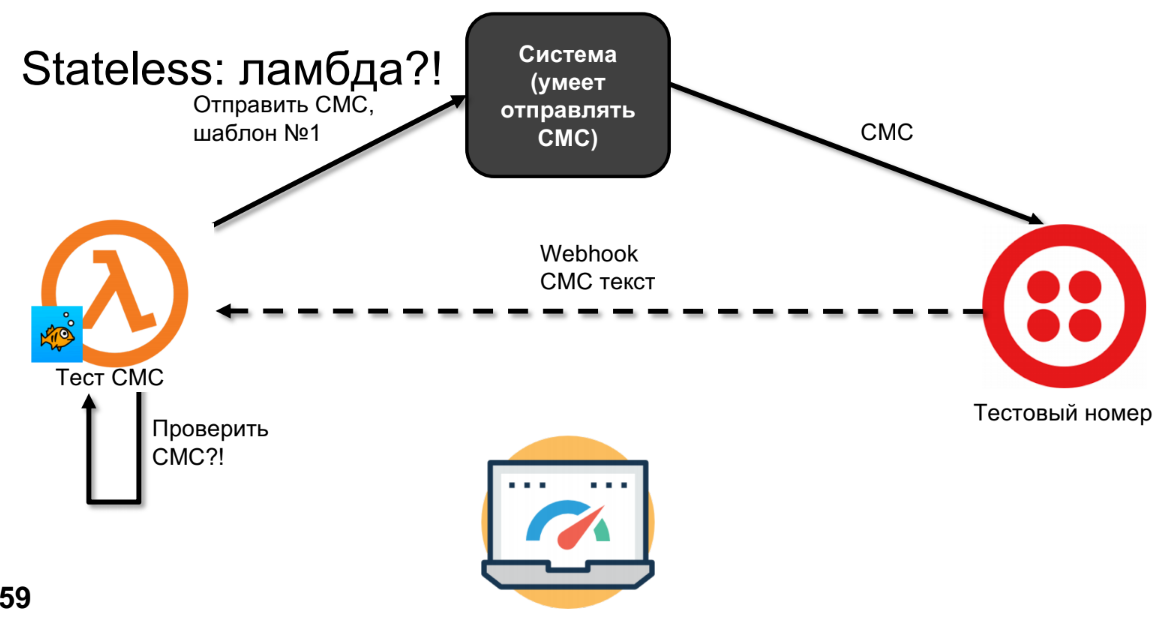
Dibujé la línea discontinua no por accidente, porque los SMS pueden retroceder en minutos, horas o días; depende de su operador, es decir, esta no es una llamada síncrona. En este momento, la lambda olvidará todo y no podremos verificar los SMS.
Yo diría que esto no es menos, sino una característica. El esquema se puede rehacer. Hay varias opciones para hacer esto, ofreceré la mía. Si tenemos apátridas y queremos guardar algo, entonces definitivamente necesitamos usar el almacenamiento, por ejemplo, una base de datos, S3, pero cualquier cosa que almacene nuestro contexto.
En el esquema con el almacenamiento de SMS, se enviará al número de prueba. Y cuando Webhook lo llama, sugiero llamar, por ejemplo, a la segunda lambda, porque esta es una función ligeramente diferente. Y el segundo lambda ya podrá ir y recoger el SMS-ku que salió de la base de datos, verificarlo y mostrar los resultados.

Bingo!
Al principio, dije que debes olvidarte de los servidores si escribes lambda. Conocí a personas que escriben en node.js y se utilizan para expresar servidores. Les gusta confiar en el caché, y el caché permanece en lambdas. Y a veces, cuando prueban, funcionará, y a veces no. ¿Cómo es esto posible?, , . — . , -, . , , . , , AWS , . AWS , , . . -, node , Java 12-15 . , , . - node cache — .. — , . , , . .
-
, .
- , . , javascript, . , javascript-, .
- , , . , , . , .
- AWS- — (DynamoDB, Alexa, API Gateway, . .).
?
— , , REST API. , , .
, , … .
- HTTP Services — . REST API, API endpoint — . . , enterprise node.js middleware. java, , js , . .
- IoT — , Alexa - -, , .
- Chat Bots — , IoT.
- Image/Video conversions.
- Machine learning.
- Batch Jobs — - , Batch Job .
Amazon, Google, Azure, IBM, Twillio — cloud functions. , . open source ( , open source — ). open source . . — Docker Swarm, Kubernetes — .
, , -, . AWS , open source .
. . : :
- Iron functions
- Fnproject
- Openfaas
- Apache OpenWhisk
- Kubeless
- Fission
- Funktion
Fnproject , Fnproject Kubernetes-.
. API Gateway (, ), URL, . , , , Kubernetes, .
. HolyJS 2018 Moscow, 24-25 . , Early Bird-.