Muy a menudo nos preguntan por qué no organizamos concursos para científicos de datos. El hecho es que, por experiencia, sabemos que las soluciones en ellos no son aplicables en absoluto a los productos. Sí, y contratar a quienes estarán en los primeros lugares, no siempre tiene sentido.
Tales competencias a menudo se ganan con la ayuda del llamado apilamiento chino, cuando todos los algoritmos y valores de hiperparámetros posibles se toman de forma combinatoria, y los modelos resultantes usan una señal entre ellos en varios niveles. Los satélites habituales de estas soluciones son la complejidad, la inestabilidad, la dificultad en la depuración y el soporte, el consumo muy alto de recursos en capacitación y pronóstico, la necesidad de una cuidadosa supervisión humana en cada ciclo de capacitación repetida de modelos. Tiene sentido hacer esto solo en competiciones, por el mero hecho de diez milésimas en métricas locales y posiciones en la clasificación.
Pero lo intentamos
Hace aproximadamente un año, decidimos intentar usar el apilamiento en la producción. Se sabe que los modelos lineales permiten extraer una señal útil de textos representados como una bolsa de palabras y vectorizados usando tf-idf, a pesar de la gran dimensión de dichos vectores. Nuestro sistema ya ha realizado dicha vectorización, por lo que no fue muy difícil para nosotros combinar vectores para currículums, vacantes y, sobre su base, enseñar la regresión logística para que prediga la probabilidad de que un candidato haga clic con un currículum determinado para una vacante determinada.
Luego, este pronóstico es utilizado por los modelos principales como una característica adicional, ya que el modelo considera un meta atributo. Lo bueno es que incluso con ROC AUC 0.7, la señal de tales modelos de metaatributos es útil. La implementación dio alrededor de 2 mil respuestas por día. Y lo más importante: nos dimos cuenta de que podemos seguir adelante.
El modelo lineal no tiene en cuenta las interacciones no lineales entre entidades. Por ejemplo, no puede tener en cuenta que si hay una "C" en el currículum y un "programador del sistema" en la vacante, entonces la probabilidad de una respuesta se vuelve muy alta. Además de la vacante y el currículum, además del texto, hay muchos campos numéricos y categóricos, y en el currículum el texto se divide en muchos bloques separados. Por lo tanto, decidimos agregar una extensión cuadrática de características para modelos lineales y ordenar todas las combinaciones posibles de vectores tf-idf de campos y bloques.
Intentamos meta-signos que predicen la probabilidad de una respuesta en varias condiciones:
- en la descripción del trabajo hay un conjunto dado de términos, categorías;
- En el campo de texto de la vacante y el campo de texto de la hoja de vida, se encuentra un cierto conjunto de términos;
- en el campo de texto de la vacante había un cierto conjunto de términos que no se encontraban en el campo de texto del currículum;
- ciertos términos aparecieron en la vacante, el valor de categoría establecido se reunió en el currículum;
- En vacantes y currículums, se cumple un par de valores de categoría.
Luego, con la ayuda de la selección de características, seleccionaron varias docenas de meta-atributos que dieron el máximo efecto, realizaron pruebas A / B y las lanzaron a producción.
Como resultado, recibimos más de 23 mil nuevas respuestas por día. Algunos de los atributos ingresaron a los principales atributos en fuerza.
Por ejemplo, en un sistema de recomendación, los principales atributos son
en un modelo de regresión logística que filtra hojas de vida adecuadas:- región geográfica del currículum;
- área profesional del currículum;
- la diferencia entre descripciones de trabajo y experiencia laboral reciente;
- diferencia de regiones geográficas en vacantes y hojas de vida;
- la diferencia entre el título de la vacante y el título del currículum vitae;
- la diferencia entre especializaciones en vacantes y en currículums;
- la probabilidad de que el solicitante con un cierto salario en un currículum haga clic en una vacante con cierto salario (meta-signo en una regresión logística);
- la probabilidad de que una persona con un determinado nombre de currículum haga clic en vacantes con cierta experiencia laboral (meta-signo en regresión logística);
en un modelo XGBoost que filtra hojas de vida relevantes:- Cuán similares son las vacantes y currículums en el texto;
- la diferencia entre el nombre de la vacante y el nombre del currículum y todas las posiciones en la experiencia en el currículum, teniendo en cuenta las interacciones de texto;
- la diferencia entre el título de la vacante y el título en el currículum, teniendo en cuenta las interacciones de texto;
- la diferencia entre el nombre de la vacante y el nombre del currículum y todas las posiciones en la experiencia del currículum, sin tener en cuenta las interacciones de texto;
- la probabilidad de que un candidato con la experiencia laboral especificada vaya a una vacante con ese nombre (meta-signo en regresión logística);
- la diferencia entre la descripción del trabajo y la experiencia laboral previa en el currículum;
- cuánto difieren la vacante y el currículum en el texto;
- la diferencia entre la descripción del trabajo y la experiencia laboral previa en el currículum;
- la probabilidad de que una persona de cierto género responda a una vacante con un nombre determinado (un signo de meta en la regresión logística).
en el modelo de clasificación en XGBoost:- la probabilidad de una respuesta de acuerdo con los términos que están presentes en el nombre de la vacante y no están en el título y la posición del currículum (meta-signo en regresión logística);
- igualar región de vacante y reanudar
- la probabilidad de una respuesta por términos que están presentes en la vacante y no están en el currículum (meta-signo en regresión logística);
- atractivo predicho de la vacante para el usuario (metaetiqueta en ALS);
- la probabilidad de una respuesta por los términos que están presentes en la vacante y el currículum (meta-signo en la regresión logística);
- la distancia entre el nombre de la vacante y el título + posición del currículum, donde los términos son ponderados por las acciones del usuario (interacción);
- distancia entre especializaciones de vacante y currículum vitae;
- la distancia entre el título de la vacante y el nombre del currículum, donde los términos son ponderados por las acciones de los usuarios (interacción);
- la probabilidad de una respuesta sobre la interacción de tf-idf de una vacante y especialización de un currículum (meta-signo en regresión logística);
- distancia entre vacante y reanudar textos;
- DSSM por el nombre de la vacante y el nombre del currículum (metaatributo en la red neuronal).
Un buen resultado muestra que desde esta dirección aún puede extraer un cierto número de respuestas e invitaciones por día a los mismos costos de marketing.
Por ejemplo, se sabe que con una gran cantidad de signos, la regresión logística aumenta la probabilidad de reentrenamiento.
Usemos para los textos de currículums y vacantes vectorizador tf-idf con un diccionario de 10 mil palabras y frases. Luego, en el caso de expansión cuadrática en nuestra regresión logística, habrá 2 * 10 000 + 10 000² de pesos. Está claro que con tal escasez, incluso los casos individuales pueden afectar significativamente cada peso individual "en el currículum había una palabra rara tal y tal, en una vacante tal y tal, el usuario hizo clic".
Por lo tanto, ahora estamos tratando de hacer meta-signos en regresión logística, en los cuales los coeficientes de expansión cuadrática se comprimen usando máquinas de factorización. Nuestros pesos de 10,000 m² se representan como una matriz de vectores latentes con una dimensión de, por ejemplo, 10,000x150 (donde hemos elegido la dimensión de un vector latente de 150). Al mismo tiempo, los casos individuales durante la compresión dejan de desempeñar un papel importante, y el modelo comienza a tener en cuenta mejor los patrones más generales, en lugar de recordar casos específicos.
También utilizamos metaatributos en las redes neuronales DSSM sobre las que ya hemos
escrito y sobre ALS, sobre las que también
escribimos , pero de manera simplificada. En total, la introducción de meta-atributos hasta la fecha nos ha dado (y a nuestros clientes) más de 44 mil respuestas adicionales (clientes potenciales) a las vacantes por día.
Como resultado, el esquema de apilamiento de modelo simplificado en las recomendaciones de trabajo para currículums ahora se ve así:
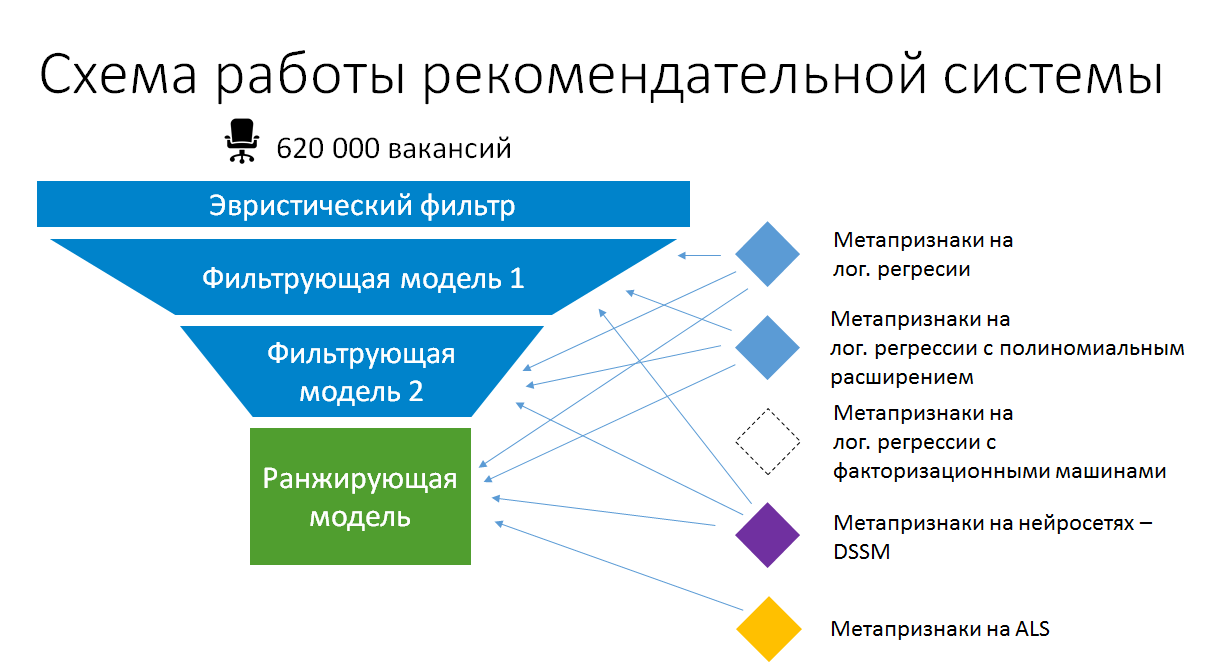
Entonces, apilar en producción tiene sentido. Pero esto no es ese apilamiento combinatorio automático. Nos aseguramos de que los modelos en base a los cuales se crean los metaatributos sean simples y hagan el máximo uso de los datos existentes y los atributos estáticos calculados. Solo de esta manera pueden permanecer en producción sin convertirse gradualmente en una caja negra sin soporte, y permanecer en un estado en el que puedan ser reentrenados y mejorados.