
Basado en los resultados de numerosas evaluaciones operativas de centros de datos en todo el mundo, el Uptime Institute observó que el nivel de personal en los centros de datos varía mucho de un lugar a otro. Esta observación es algo desconcertante, pero no es sorprendente. Si bien la dotación de personal es una actividad comercial importante para los centros de datos que intentan mantener la excelencia operativa, muchos otros factores influyen en las decisiones de las organizaciones sobre el nivel requerido de dotación de personal.
Entre los factores que pueden afectar el nivel general de personal, se puede destacar la complejidad del centro de datos, la rotación de personal, la cantidad de horas de trabajo de soporte técnico requeridas, la cantidad de contratos con los contratistas y los objetivos comerciales de accesibilidad. Los costos también son preocupantes, ya que cada empleado es un costo directo para el centro de datos. Debido a estos muchos factores, es necesario revisar constantemente los niveles de personal de los centros de datos para proporcionar un soporte efectivo a un precio razonable.
El Uptime Institute a menudo recibe la pregunta: "¿Cuál es el nivel de personal adecuado para mi centro de datos?" Desafortunadamente, no hay una respuesta concisa que sea universal para cada centro de datos. La dotación de personal adecuada depende de una serie de variables.
El tiempo requerido para completar las tareas de mantenimiento y garantizar que se completen los turnos de soporte técnico son dos variables principales. La dotación de personal para cumplir con los requisitos de mantenimiento es un factor relativamente fijo, pero depende de qué acciones realice el personal del centro de datos y qué funciones se asignen a los contratistas. La gestión de turnos de soporte técnico se define como la dotación de personal para monitorear un centro de datos y para responder a cualquier incidente y evento. La dotación de personal del turno para el soporte técnico se puede determinar de varias maneras. Cada método de dotación de personal tiene un impacto potencial en las operaciones, dependiendo de los procesos cubiertos por el soporte técnico.
Tendencias de cambio
El objetivo principal de la presencia permanente de personal calificado en el lugar es minimizar el riesgo de fallas causadas por eventos anormales al prevenir un incidente, disuadirlo o aislarlo, así como prevenir su propagación o impacto en otros sistemas. Muchos centros de datos continúan proporcionando una presencia constante de un equipo de electricistas calificados, ingenieros mecánicos y otros técnicos que brindan un modo de operación 24x7. Sin embargo, las tecnologías de monitoreo remoto, la disposición especial de los edificios en forma de complejo, el deseo de equilibrar los costos y otras razones pueden llevar a las organizaciones a contratar personal de diferentes maneras.
Administrar un régimen de soporte técnico sin personal calificado en cualquier momento puede aumentar los riesgos debido a una respuesta tardía a incidentes anormales. Finalmente, la empresa debe tomar una decisión con un nivel de riesgo aceptable.
Otros modelos de soporte técnico de cobertura total incluyen:
- Capacitación del personal de seguridad para responder a alarmas y realizar procedimientos para resolver problemas;
- Monitorear el centro de datos a través de un sistema de monitoreo de edificios (BMS) local o regional e involucrar a técnicos de llamadas;
- Disponibilidad de personal en el sitio durante el horario comercial normal y de guardia por la noche y los fines de semana;
- El trabajo de varios centros de datos en forma de un complejo especial de edificios, cuyo equipo brinda soporte para varios centros de datos sin la necesidad de estar en su lugar en cada centro de datos por separado en cualquier momento.
Estos y otros métodos deben evaluarse en términos de efectividad individualmente. Para evaluar el modelo de soporte técnico, el centro de datos debe determinar los riesgos potenciales de incidentes en el centro de datos y su impacto potencial en el negocio.
En los últimos 20 años, el Uptime Institute ha compilado una base de datos de incidentes anormales (informes de incidentes anormales, AIR), utilizando la información recibida de los miembros de la red del Uptime Institute. Uptime Institute analiza anualmente los datos y presenta sus resultados a los miembros de la Red. La base de datos de AIR contiene información interesante sobre problemas de personal y modelos efectivos de personal para centros de datos.
Los incidentes ocurren fuera del horario laboral
En 2013, una pequeña mayoría de los incidentes (de 277 casos) ocurrieron durante el horario comercial. Sin embargo, el 44% de los incidentes ocurrieron entre la medianoche y las 8:00 a.m., lo que subraya la necesidad potencial de un modo de soporte técnico 24x7 (ver Figura 1).
Figura 1. Alrededor de la mitad de los incidentes anormales que ocurrieron en 2013 tuvieron lugar entre las 8 a.m. y el mediodía, la otra mitad de medianoche a 8 a.m.
Los incidentes pueden ocurrir en cualquier época del año. Centrar la actividad del personal durante un determinado momento del año en prioridad sobre otros no sería productivo (por ejemplo, una prohibición de vacaciones). Los incidentes se distribuyen de manera bastante uniforme durante todo el año.
La Figura 2 muestra la distribución de incidentes por día de la semana. El diagrama muestra que cada día de la semana tiene una participación casi igual, lo que sugiere que el personal debe ser el mismo para los turnos de cada día de la semana. Esta es una conclusión importante, porque algunos centros de datos han concentrado los recursos laborales de su soporte técnico para el período de lunes a viernes y dejan los días libres para el monitoreo remoto (ver Fig. 2).
Figura 2. El personal del centro de datos debe estar listo todos los días de la semana.Incidentes por industria
La Figura 3 ilustra aún más los incidentes de la industria y no muestra una diferencia significativa en las tendencias entre las industrias. El gráfico muestra que la industria de servicios financieros reportó muchos más incidentes que otras industrias, pero esto probablemente refleja la composición de la muestra.
 Figura 3. Los incidentes en los centros de datos tienen lugar durante todo el año.
Figura 3. Los incidentes en los centros de datos tienen lugar durante todo el año.Causas de fallas y métodos de detección
Al saber cuándo ocurren los incidentes, poco se puede decir sobre qué personal debe estar en su lugar. Comprender qué incidentes ocurren con mayor frecuencia ayudará a dar forma a la estructura del turno, así como a descubrir cómo se detectan los incidentes con mayor frecuencia. La Figura 4 muestra que la mayoría de los incidentes afectan los sistemas eléctricos, seguidos de los sistemas mecánicos. En contraste, las cargas de trabajo críticas de TI causan un número relativamente pequeño de incidentes.
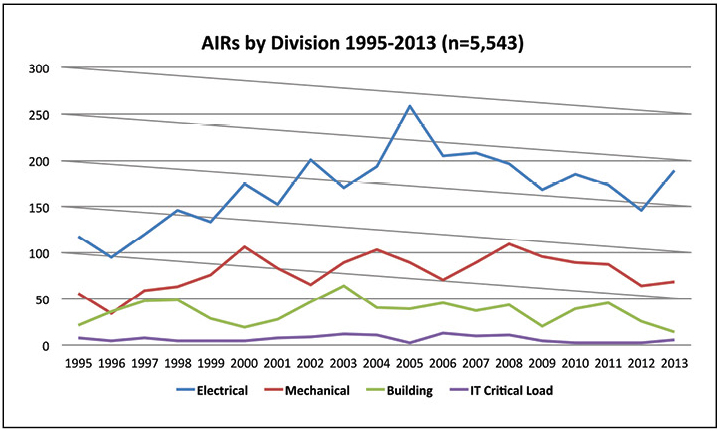 Figura 4. Más de la mitad de los incidentes anormales reportados en 2013 están relacionados con el sistema eléctrico.
Figura 4. Más de la mitad de los incidentes anormales reportados en 2013 están relacionados con el sistema eléctrico.Como resultado, tiene sentido que los equipos de todos los turnos tengan suficiente experiencia para responder a los incidentes más comunes en los sistemas eléctricos. El equipo de soporte también debe responder a otros tipos de incidentes. La capacitación cruzada de ingenieros eléctricos en sistemas mecánicos y de construcción puede proporcionar una cobertura suficiente, y los asistentes de llamadas pueden cubrir incidentes de TI relativamente raros.
La base de datos de AIR también arroja luz sobre cómo se detectan los incidentes. La Figura 5 muestra que más de la mitad de la información primaria sobre todos los incidentes detectados en 2013 se obtuvo de los sistemas de alarma, más del 40% de los incidentes son detectados por especialistas técnicos in situ, lo que en total es aproximadamente el 95% de los casos. El mayor cambio a lo largo de los años que se muestra en el diagrama es el lento crecimiento de los incidentes detectados por las alarmas.
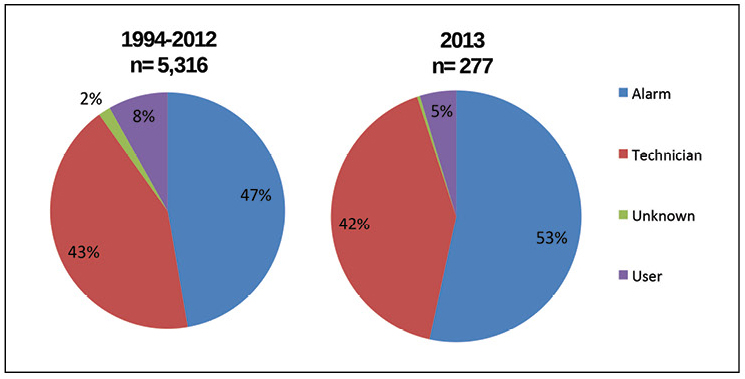 Figura 5. Las alarmas ahora son una forma de detectar la mayoría de los incidentes; sin embargo, los expertos técnicos encuentran con mayor frecuencia problemas de accesibilidad.
Figura 5. Las alarmas ahora son una forma de detectar la mayoría de los incidentes; sin embargo, los expertos técnicos encuentran con mayor frecuencia problemas de accesibilidad.Sin embargo, las alarmas no pueden responder a incidentes ni mitigar las consecuencias. El Uptime Institute ha sido testigo de varios métodos que permiten a los centros de datos evitar el mal funcionamiento y reducir su impacto. Estos métodos requieren personal para responder al incidente, crear redundancia en sistemas críticos y programas efectivos de mantenimiento predictivo para predecir posibles fallas antes de que ocurran. La Figura 6 muestra con qué frecuencia cada uno de estos métodos "rescata" centros de datos.
 Figura 6. La redundancia de equipos en 2013 contribuyó a más "rescate" que en años anteriores.
Figura 6. La redundancia de equipos en 2013 contribuyó a más "rescate" que en años anteriores.El diagrama también muestra que en los últimos años la redundancia de equipos y el mantenimiento preventivo se han vuelto más eficientes y ahorran a los centros de datos más y más dinero. Hay varias explicaciones posibles para esto, incluido el aumento de la confiabilidad de los sistemas, el uso más amplio de servicios proactivos y los recortes presupuestarios, que conducen a una reducción en el número de personal o su reubicación fuera del centro de datos.
Fallas en el contexto de la causa raíz
Los datos muestran que todos los problemas de accesibilidad en 2013 fueron causados por incidentes con el sistema eléctrico. La mayoría de las fallas ocurrieron porque los procedimientos de mantenimiento no se realizaron correctamente. Este hallazgo subraya la importancia de contar con procedimientos adecuados y personal bien capacitado.
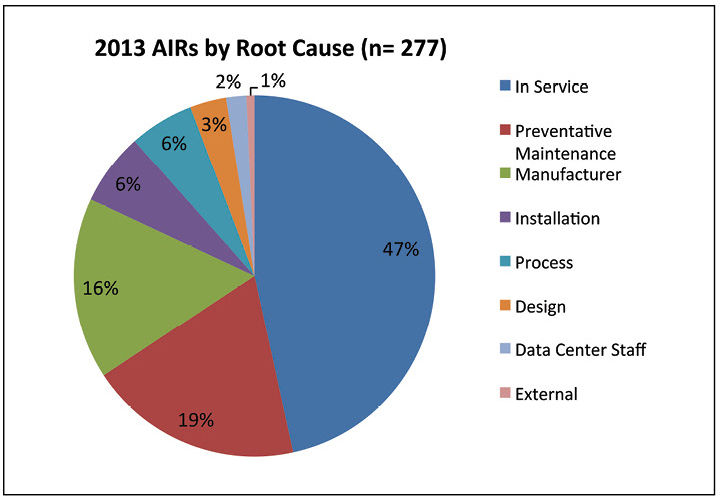 Figura 7. Casi la mitad de las fallas reportadas en 2013 se debieron a problemas de mantenimiento.
Figura 7. Casi la mitad de las fallas reportadas en 2013 se debieron a problemas de mantenimiento.En la fig. 7 analiza más a fondo las causas de los incidentes en 2013. Aproximadamente la mitad de los incidentes se describieron como "En servicio", que se define como mantenimiento inadecuado, configuración incorrecta del equipo, falla en el trabajo o falta de una causa raíz específica. Los casos de "mantenimiento preventivo" en realidad se refieren al mantenimiento preventivo que se ha realizado incorrectamente. El personal del centro de datos causó solo el 2% de los incidentes, lo que demuestra que las interacciones entre el personal y el equipo no fueron la causa principal de incidentes y fallas.
Conclusión
La creciente complejidad de la gestión de la infraestructura del centro de datos (DCIM), los sistemas de gestión de edificios (BMS) y los sistemas de automatización de edificios (BAS) hace que sea difícil encontrar la respuesta a la pregunta de si es posible reducir la cantidad de personal en los centros de datos. Los avances en la mejora de estos sistemas son significativos. Pueden mejorar el rendimiento de su centro de datos; sin embargo, los datos muestran que la prevención de incidentes a menudo requiere personal en el sitio. Es por eso que continuar teniendo personal equivalente a tiempo completo (FTE) es una directiva para los centros de datos certificados de Nivel III y Nivel IV.
El objetivo principal es proporcionar un tiempo de respuesta rápido para mitigar las consecuencias de cualquier incidente y evento. Los datos muestran que cuando ocurren incidentes, no se observan patrones temporales. Su apariencia está bastante bien distribuida en las 24 horas y los 7 días de la semana.
El objetivo principal es la prevención de riesgos. Los centros de datos continúan evolucionando, permitiendo la administración a través del acceso remoto y aumentando la redundancia de hardware. Cada centro de datos es único y tiene su propio conjunto de riesgos inherentes. El modo de soporte técnico es solo un factor, pero bastante importante. La decisión sobre cuánto personal debe participar en cada turno y con qué calificaciones puede tener un impacto importante en la prevención de riesgos y la disponibilidad de centros de datos. Toma decisiones inteligentes.
Otros artículos del blog de Cloud4Y:→
¿Cuál es el costo real del tiempo de inactividad de la infraestructura de TI para las pequeñas y medianas empresas? (enlace externo)→
El apogeo de la computación en la nube en la automatización de empresas industriales (enlace externo)→
Qué está pasando con los precios de la computación en la nube en los últimos años (Habr)→
Cómo crear muestras para el sistema biométrico unificado y por qué puede ser peligroso (Habr)