Este artículo analiza varios tipos de pruebas en producción y las condiciones bajo las cuales cada una de ellas es más útil, y también describe cómo organizar pruebas seguras de varios servicios en producción.
Vale la pena señalar que el contenido de este artículo se aplica solo a esos
servicios , cuya implementación está controlada por los desarrolladores. Además, debe advertir de inmediato que el uso de cualquiera de los tipos de pruebas descritos aquí no es una tarea fácil, que a menudo requiere cambios serios en el diseño, desarrollo y prueba de los sistemas. Y, a pesar del título del artículo, no creo que ninguno de los tipos de pruebas en producción sea absolutamente confiable. Solo existe la opinión de que tales pruebas pueden reducir significativamente el nivel de riesgos en el futuro, y los costos de inversión estarán justificados.
(Nota: como el artículo original es Longrid, para comodidad de los lectores, está dividido en dos partes).¿Por qué es necesario realizar pruebas en producción si se puede realizar en etapas?
La importancia del grupo de etapas (o entorno de etapas) por diferentes personas se percibe de manera diferente. Para muchas empresas, la implementación y prueba de un producto en etapas es una etapa integral que precede a su lanzamiento final.
Muchas organizaciones conocidas perciben la puesta en escena como una copia en miniatura del entorno de trabajo. En tales casos, es necesario garantizar su máxima sincronización. En este caso, generalmente es necesario garantizar el funcionamiento de diferentes instancias de sistemas con estado, como bases de datos, y sincronizar regularmente los datos del entorno de producción con la preparación. La excepción es solo información confidencial que le permite establecer la identidad del usuario (esto es necesario para cumplir con los requisitos de
GDPR ,
PCI ,
HIPAA y otras regulaciones).
El problema con este enfoque (en mi experiencia) es que la diferencia no está solo en el uso de una instancia separada de la base de datos que contiene los datos reales del entorno de producción. A menudo, la diferencia se extiende a los siguientes aspectos:
- El tamaño del clúster provisional (si puede llamarlo "clúster", a veces es solo un servidor disfrazado de clúster);
- El hecho de que la puesta en escena normalmente usa un clúster mucho más pequeño también significa que las configuraciones de configuración para casi todos los servicios variarán. Esto se aplica a configuraciones de equilibradores de carga, bases de datos y colas, por ejemplo, el número de descriptores de archivo abiertos, el número de conexiones de bases de datos abiertas, el tamaño del grupo de subprocesos, etc. Si la configuración se almacena en una base de datos o en un almacenamiento de datos de valores clave (por ejemplo, Zookeeper o Consul), estos sistemas auxiliares también deben estar presentes en el entorno de ensayo;
- El número de conexiones en línea procesadas por el servicio sin estado, o el método de reutilización de conexiones TCP por un servidor proxy (si este procedimiento se realiza en absoluto);
- Falta de monitoreo en la puesta en escena. Pero incluso si se lleva a cabo la supervisión, algunas señales pueden resultar completamente inexactas, ya que se supervisa un entorno distinto del que funciona. Por ejemplo, incluso si monitorea la latencia de consulta o el tiempo de respuesta de MySQL, es difícil determinar si el nuevo código contiene una consulta que puede iniciar un escaneo completo de la tabla en MySQL, ya que es mucho más rápido (y a veces incluso preferible) realizar un escaneo completo de la pequeña tabla utilizada en la prueba una base de datos en lugar de una base de datos de producción, donde una consulta puede tener un perfil de rendimiento completamente diferente.
Aunque es justo suponer que todas las diferencias anteriores no son argumentos serios contra el uso de la puesta en escena como tal, a diferencia de los antipatrones que deberían evitarse. Al mismo tiempo, el deseo de hacer todo bien a menudo requiere los enormes costos de mano de obra de los ingenieros en un intento por garantizar un entorno coherente. La producción cambia constantemente y está influenciada por varios factores, por lo que tratar de lograr este partido es como ir a ninguna parte.
Además, incluso si las condiciones en la puesta en escena serán lo más similares posible al entorno de trabajo, existen otros tipos de pruebas que son mejores para usar en función de la información de producción real. Un buen ejemplo sería la prueba de remojo, en la que la confiabilidad y la estabilidad de un servicio se prueban durante un período prolongado de tiempo en niveles reales de multitarea y carga. Se utiliza para detectar pérdidas de memoria, determinar la duración de las pausas en el GC, el nivel de carga del procesador y otros indicadores durante un cierto período de tiempo.
Nada de lo anterior sugiere que la puesta en escena sea
completamente inútil (esto se hará evidente después de leer la sección sobre duplicación de datos en la sombra cuando se prueban los servicios). Esto solo indica que a menudo confían en la puesta en escena en mayor medida de lo necesario, y en muchas organizaciones sigue siendo el
único tipo de prueba realizada antes del lanzamiento completo del producto.
El arte de probar en producción
Sucedió históricamente que el concepto de "prueba en producción" está asociado con ciertos estereotipos y connotaciones negativas ("programación guerrillera", falta o ausencia de pruebas de unidad e integración, negligencia o falta de atención a la percepción del producto por parte del usuario final).
Las pruebas en producción ciertamente merecerán tal reputación si se realizan descuidadamente y mal. De ninguna manera
reemplaza las pruebas en la etapa de preproducción y bajo ninguna circunstancia es una
tarea simple . Además, sostengo que las pruebas
exitosas y
seguras en producción requieren un nivel significativo de automatización, una buena comprensión de las prácticas establecidas y el diseño de sistemas con una orientación inicial para este tipo de pruebas.
Para organizar un proceso integral y seguro de pruebas efectivas de servicios en producción, es importante no considerarlo como un término general que denota un conjunto de diferentes herramientas y técnicas. Desafortunadamente, también cometí este error:
en mi artículo anterior no se presentó una clasificación científica de los métodos de prueba, y en la sección "Pruebas en producción" se agruparon una variedad de metodologías y herramientas.
De la nota Testing Microservices, la forma sensata ("Un enfoque inteligente para probar microservicios")Desde la publicación de la nota a fines de diciembre de 2017, he estado discutiendo su contenido y, en general, el tema de las pruebas en producción con varias personas.
En el curso de estas discusiones, y también después de una serie de conversaciones separadas, me quedó claro que el tema de las pruebas en producción no puede reducirse a varios puntos mencionados anteriormente.
El concepto de "prueba en producción" incluye una amplia gama de técnicas aplicadas
en tres etapas diferentes . ¿Cuáles? Vamos a entender.
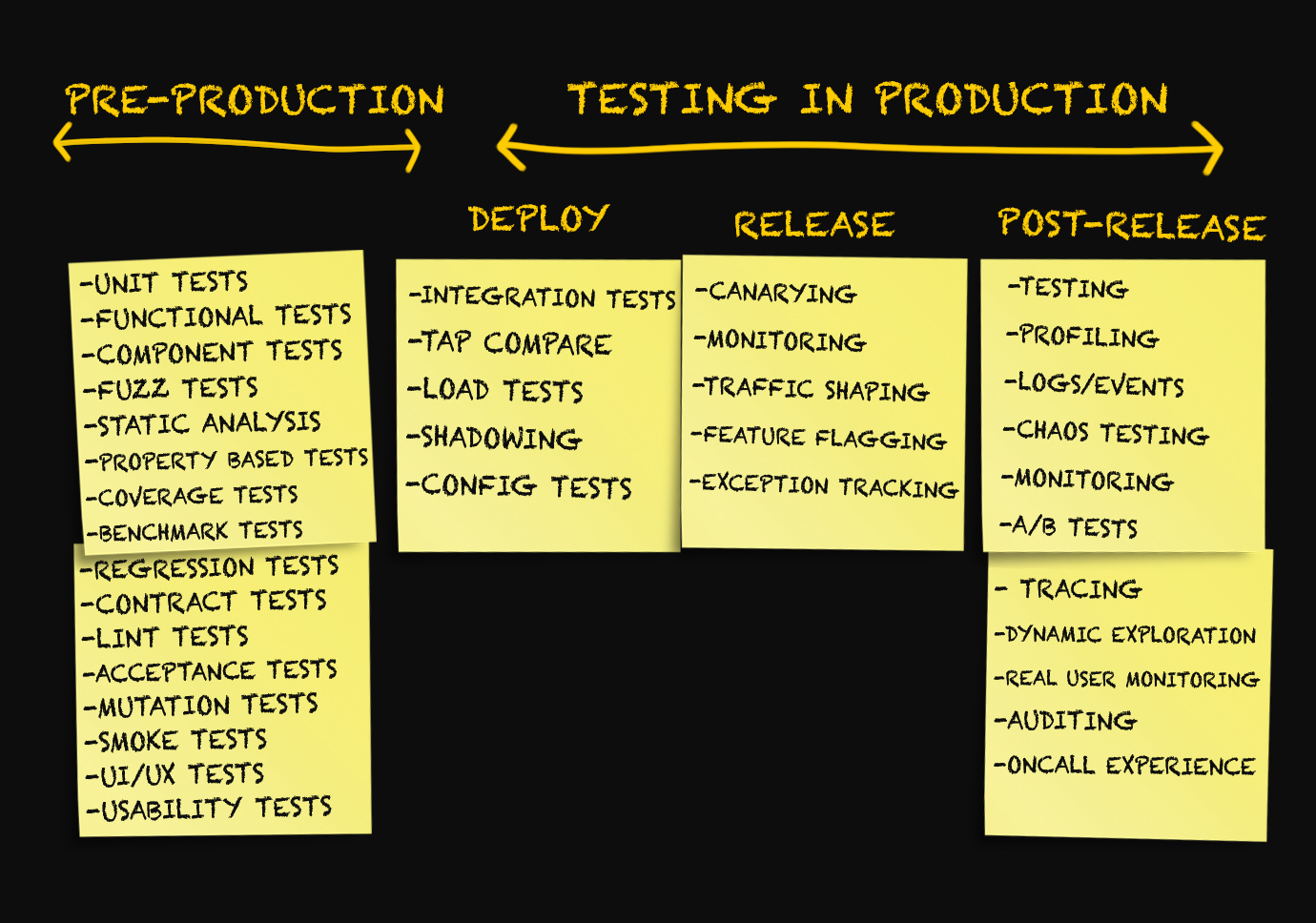
Tres etapas de producción
Por lo general, las discusiones sobre producción se llevan a cabo solo en el contexto de la implementación de código en producción, monitoreo o en situaciones de emergencia cuando algo salió mal.
Yo mismo he usado hasta ahora términos como "despliegue", "lanzamiento", "entrega", etc., como sinónimos, sin pensar mucho en su significado. Hace unos meses, todos los intentos de distinguir entre estos términos serían rechazados por mí como algo insignificante.
Después de pensar en esto, llegué a la idea de que
existe una necesidad real de distinguir entre las diversas etapas de producción.
Etapa 1. Despliegue
Cuando las pruebas (incluso en producción) son una verificación del logro de los
mejores indicadores posibles , la precisión de las pruebas (y de hecho de cualquier verificación) se garantiza solo con la condición de que el método de realizar las pruebas sea lo más cercano posible a la forma en que el servicio se usa realmente en la producción.
En otras palabras, las pruebas deben ejecutarse en un entorno que
simule mejor un entorno de trabajo .
Y la
mejor imitación del entorno laboral es ... el entorno laboral en sí. Para realizar el máximo número posible de pruebas en un entorno de producción, es necesario que el resultado fallido de cualquiera de ellas no afecte al usuario final.
Esto, a su vez, solo es posible si,
al implementar el servicio en un entorno de producción, los usuarios no obtienen acceso directo a este servicio .
En este artículo, decidí usar la terminología del artículo
Deploy! = Release escrito por
Turbine Labs . Define el término "despliegue" de la siguiente manera:
“La implementación es la instalación por un grupo de trabajo de una nueva versión del código del programa de servicio en la infraestructura de producción. Cuando decimos que se ha
implementado una nueva versión del software, queremos decir que se ejecuta en algún lugar dentro del marco de la infraestructura de trabajo. Esta puede ser una nueva instancia de EC2 en AWS o un contenedor Docker que se ejecuta en el corazón de un clúster de Kubernetes. El servicio se inició con éxito, pasó una comprobación de estado y está listo (¡lo espera!) Para procesar datos del entorno de producción, pero en realidad puede no recibir datos. Este es un punto importante, lo enfatizo nuevamente:
para la implementación no es necesario que los usuarios tengan acceso a la nueva versión de su servicio . Dada esta definición, la implementación puede llamarse un proceso con un riesgo casi nulo ".
Las palabras "proceso de riesgo cero" son simplemente un bálsamo para el alma de muchas personas que han sufrido despliegues sin éxito. La capacidad de instalar software
en un entorno real sin permitir que los usuarios tengan una serie de ventajas cuando se trata de pruebas.
En primer lugar, la necesidad de mantener entornos separados para el desarrollo, las pruebas y la puesta en escena, que inevitablemente deben sincronizarse con la producción, se minimiza (e incluso puede desaparecer por completo).
Además, en la etapa de diseño de servicios, se hace necesario aislarlos unos de otros para que el hecho de no probar una instancia específica del servicio en producción
no conduzca a la cascada o afecte a los usuarios de la falla de otros servicios. Una solución a esto puede ser el diseño de un modelo de datos y un esquema de base de datos en el que las consultas no idempotentes (principalmente
operaciones de escritura ) puedan:
- Se realizará en relación con la base de datos del entorno de producción durante cualquier lanzamiento de prueba del servicio en producción (prefiero este enfoque);
- Ser rechazado de forma segura en el nivel de aplicación hasta que alcancen el nivel de escritura o guardado;
- Ser asignado o aislado en el nivel de registro o guardado de alguna manera (por ejemplo, almacenando metadatos adicionales).
Etapa 2. Lanzamiento
Note
Deploy! = Release define el término lanzamiento de la siguiente manera:
“Cuando decimos que se
lanzó la
versión del servicio, queremos decir que proporciona procesamiento de datos en el entorno de producción. En otras palabras, un
lanzamiento es un proceso que dirige los datos del entorno de producción a una nueva versión de software. Con esta definición en mente, todos los riesgos que asociamos con el envío de nuevos flujos de datos (interrupciones, insatisfacción del cliente, notas venenosas en
The Register ) se relacionan con el
lanzamiento de un nuevo software y no con su implementación (en algunas compañías, esta etapa también se llama
lanzamiento) . En este artículo usaremos el término
lanzamiento ) ".
En el libro de Google sobre SRE, el término "lanzamiento" se utiliza en el
capítulo sobre la organización de un lanzamiento de software para describirlo .
“Un
problema es un elemento lógico de trabajo que consiste en una o más tareas separadas. Nuestro objetivo es coordinar el proceso de implementación con el perfil de riesgo de este servicio .
En entornos de desarrollo o preproducción, podemos construir cada hora y distribuir automáticamente las versiones después de pasar todas las pruebas. Para los grandes servicios orientados al usuario, podemos comenzar el lanzamiento con un clúster y luego aumentar su escala hasta que actualicemos todos los clústeres.
Para elementos de infraestructura importantes, podemos extender el período de implementación a varios días y ejecutarlo a su vez en diferentes regiones geográficas ”.En esta terminología, las palabras "liberar" y "liberar" significan lo que el vocabulario general se refiere a "despliegue", y los términos que se usan a menudo para describir diversas estrategias de
despliegue (por ejemplo, despliegue azul-verde o canario) se refieren al
lanzamiento de un nuevo software
Además, un
lanzamiento fallido
de aplicaciones puede causar interrupciones parciales o significativas en el trabajo. En esta etapa, también se realiza una
reversión o
revisión si resulta que la nueva versión
lanzada del servicio es inestable.
El proceso de
lanzamiento funciona mejor cuando está automatizado y se ejecuta de forma
incremental . Del mismo modo, una
reversión o
revisión de un servicio es más útil cuando la tasa de error y la frecuencia de solicitud se correlacionan automáticamente con la línea de base.
Etapa 3. Después del lanzamiento
Si el lanzamiento se
realizó sin problemas y la nueva versión del servicio procesa los datos del entorno de producción sin problemas obvios, podemos considerarlo exitoso. Un lanzamiento exitoso es seguido por una etapa que se puede llamar "después del lanzamiento".
Cualquier sistema suficientemente complejo
siempre estará en un estado de pérdida gradual de rendimiento. Esto no significa que
se requiera una
reversión o
revisión . En cambio, es necesario controlar dicho deterioro (para diversos fines operativos y operativos) y depurar si es necesario. Por esta razón, las pruebas después del lanzamiento ya no son más como rutinas, sino
depuración o recopilación de datos analíticos.
En general, creo que todos los componentes del sistema deben crearse teniendo en cuenta el hecho de que ningún sistema grande funciona perfectamente al 100% y que los fallos deben reconocerse y tenerse en cuenta en las etapas de diseño, desarrollo, prueba, implementación y monitoreo del software. proporcionando.
Ahora que hemos identificado las tres etapas de producción, veamos los diversos mecanismos de prueba disponibles en cada una de ellas. No todos tienen la oportunidad de trabajar en nuevos proyectos o reescribir código desde cero. En este artículo, traté de identificar claramente los métodos que funcionarán mejor al desarrollar nuevos proyectos, así como hablar sobre qué más podemos hacer para aprovechar los métodos propuestos sin realizar cambios significativos en los proyectos de trabajo.
Prueba de implementación
Separamos las etapas de implementación y lanzamiento, y ahora consideraremos algunos tipos de pruebas que se pueden aplicar después de implementar el código en el entorno de producción.
Pruebas de integración
Normalmente, las pruebas de integración las realiza un servidor de integración continua en un entorno de prueba aislado para cada rama de Git. Se implementa una copia de
toda la topología del servicio (incluidas bases de datos, colas, servidores proxy, etc.) para los conjuntos de pruebas de
todos los servicios que funcionarán juntos.
Creo que esto no es particularmente efectivo por varias razones. En primer lugar, el entorno de prueba, como el entorno de ensayo, no se puede implementar de tal manera que sea
idéntico al entorno de producción real,
incluso si las pruebas se ejecutan en el mismo contenedor Docker que se utilizará en la producción. Esto es especialmente cierto cuando lo
único que se ejecuta en un entorno de prueba son las pruebas mismas.
Independientemente de si la prueba se ejecuta como un contenedor Docker o un proceso POSIX, lo más probable es que realice
una o más conexiones a un servicio superior, base de datos o caché, lo cual es raro si el servicio se encuentra en un entorno de producción donde puede simultáneamente procesar múltiples conexiones concurrentes, a menudo reutilizando conexiones TCP inactivas (esto se llama reutilizar conexiones HTTP).
Además, el problema es causado por el hecho de que la mayoría de las pruebas en cada inicio crean una nueva tabla de base de datos o espacio de clave de caché en
el mismo nodo donde se realiza esta prueba (de esta manera, las pruebas están aisladas de fallas de la red). Este tipo de prueba en el mejor de los casos puede mostrar que el sistema funciona correctamente con una solicitud muy específica. Rara vez es eficaz para simular fallas graves y bien distribuidas, sin mencionar los diferentes tipos de fallas parciales. Existen
estudios exhaustivos que confirman que los sistemas distribuidos a menudo exhiben
un comportamiento impredecible que no puede preverse mediante un análisis realizado de manera diferente que para todo el sistema.
Pero esto no significa que las pruebas de integración sean
en principio inútiles. Solo podemos decir que, por regla general, la implementación de pruebas de integración en un
entorno artificial completamente aislado no tiene sentido. Las pruebas de integración aún deben realizarse para verificar que la nueva versión del servicio:
- No interfiere con la interacción con los servicios ascendentes o descendentes;
- No afecta negativamente las metas y objetivos de los servicios superiores o inferiores.
El primero se puede proporcionar hasta cierto punto a través de pruebas de contrato.
Debido al hecho de que las
interfaces entre los servicios funcionan correctamente,
las pruebas de contrato son un método eficaz para desarrollar y probar servicios individuales en
la etapa de preproducción , que no requiere el despliegue de toda la topología de servicios.
Las plataformas de prueba de contratos orientadas al cliente, como
Pact , actualmente solo admiten la interoperabilidad entre servicios a través de RESTful JSON RPC, aunque es probable que
se esté trabajando para admitir la interacción asincrónica a través de sockets web, aplicaciones que no son del servidor y colas de mensajes . Es probable que en el futuro se agregue soporte para los protocolos gRPC y GraphQL, pero ahora aún no está disponible.
Sin embargo, antes del
lanzamiento de una nueva versión, puede ser necesario verificar no solo el correcto funcionamiento de las
interfaces . , , , RPC- . , , , .
,
, — ,
, ( , ).
:
?
. – , : - - ( C) MySQL ( D) memcache ( B).
, ( ), stateful- stateless- .
,
.
service discovery
( ),
.
.
,
C .
,
, , . , , . ,
, .
Google
Just Say No to More End-to-End Tests (« »), :
«
( ) . , ? , .
, , , »., :
. , A .
,
C MySQL, .
( , , «» ,
).
MySQL , , .
— -. , . -, .
, -
, /:
, (, ).
, ,
. IP- , , , , , , , , .
, , , , . . Facebook,
Kraken , :
«
— , . - , . , . - , , , »., , , , , .
- . service mesh . -. -, , , :
Si probamos el servicio B, su servidor proxy saliente se puede configurar para agregar un encabezado especial
X-ServiceB-Test a cada solicitud de prueba. En este caso, el servidor proxy entrante del servicio superior C podrá:
- Detecta este encabezado y envía una respuesta estándar al servicio B;
- Dígale al Servicio C que la solicitud es una prueba .
Pruebas de integración de la interacción de la versión implementada del servicio B con la versión lanzada del servicio C, donde las operaciones de escritura nunca llegan a la base de datosRealizar pruebas de integración de esta manera también permite probar la interacción del servicio B con servicios superiores
cuando procesan datos normales del entorno de producción ; esta es probablemente una imitación más cercana de cómo se comportará el servicio B cuando se
lance a producción.
También sería bueno que cada servicio en esta arquitectura admitiera llamadas API reales en modo de prueba o simulacro, lo que le permite probar la ejecución de contratos de servicio con servicios posteriores sin cambiar los datos reales. Esto equivaldría a pruebas de contrato, pero a nivel de red.
Duplicación de datos sombra (prueba de flujo de datos oscuros o reflejo)
La duplicación de sombras (en el artículo en el blog de Google se llama
lanzamiento oscuro , y el término
reflejo se usa en
Istio ) en muchos casos tiene más ventajas que las pruebas de integración.
Los
Principios de la Ingeniería del Caos establece lo siguiente:
“Los
sistemas se comportan de manera diferente según el entorno y el esquema de transferencia de datos. Dado que el modo de uso puede cambiar en cualquier momento , el
muestreo de datos reales es la única forma confiable de arreglar la ruta de solicitud ".La duplicación de datos en la sombra es un método mediante el cual el flujo de datos del entorno de producción que ingresa a un servicio determinado se captura y reproduce en una nueva versión
implementada del servicio. Este proceso se puede realizar en tiempo real, cuando el flujo de datos entrantes se divide y se envía a las versiones
lanzadas y
desplegadas del servicio, o de forma asíncrona, cuando se reproduce una copia de los datos capturados previamente en el servicio
desplegado .
Cuando trabajé en
imgix (una startup con un equipo de 7 ingenieros, de los cuales solo cuatro eran ingenieros de sistemas), se utilizaron flujos de datos oscuros para probar los cambios en nuestra infraestructura de visualización de imágenes. Registramos un cierto porcentaje de todas las solicitudes entrantes y las enviamos al clúster de Kafka: pasamos los registros de acceso de HAProxy a la tubería de
heka , que a su vez pasó el flujo de solicitud analizado al clúster de Kafka. Antes de la etapa de
lanzamiento, se probó
una nueva versión de nuestra aplicación de procesamiento de imágenes en un flujo de datos oscuros capturados, lo que permitió verificar que las solicitudes se procesaron correctamente. Sin embargo, nuestro sistema de visualización de imágenes era en general un servicio sin estado que era particularmente adecuado para este tipo de pruebas.
Algunas compañías prefieren capturar no una parte del flujo de datos, pero transmiten una
copia completa de este flujo a la nueva versión de la aplicación.
McRouter de Facebook (proxy memcached) es compatible con este tipo de duplicación oculta del flujo de datos de memcache.
“
Al probar una nueva instalación para el caché, nos pareció muy conveniente poder redirigir una copia completa del flujo de datos desde los clientes. McRouter admite configuraciones flexibles de duplicación de sombras. Es posible realizar la duplicación de sombra de un grupo de varios tamaños (volviendo a almacenar en caché el espacio clave), copiar solo una parte del espacio clave o cambiar dinámicamente los parámetros durante la operación .
El aspecto negativo de la duplicación en la sombra de todo el flujo de datos para un servicio
implementado en un entorno de producción es que si se ejecuta en el momento de la máxima intensidad de transferencia de datos, puede requerir el doble de potencia.
Los proxies como Envoy admiten la duplicación oculta del flujo de datos a otro clúster en modo disparar y olvidar. Su
documentación dice:
“
Un enrutador puede realizar duplicaciones ocultas del flujo de datos de un clúster a otro. Actualmente, se implementa el modo disparar y olvidar, en el que el servidor proxy Envoy no espera una respuesta del clúster sombra antes de devolver una respuesta del clúster principal. Para el clúster de sombra, se recopilan todas las estadísticas habituales, lo que es útil para fines de prueba. Con la duplicación de sombra, la opción -shadow se agrega al -shadow host / autoridad. Esto es útil para iniciar sesión. Por ejemplo, cluster1 convierte en cluster1-shadow ".
Sin embargo, a menudo es poco práctico o imposible crear una réplica de un clúster sincronizado con la producción para la prueba (por la misma razón que es problemático organizar un clúster de etapas sincronizado). Si la duplicación de sombra se usa para probar un nuevo servicio
implementado que tiene muchas dependencias, puede iniciar cambios imprevistos en el estado de los servicios de nivel superior con respecto al probado. La duplicación en la sombra del volumen diario de registros de usuarios en la versión
implementada del servicio con registro en la base de datos de producción puede conducir a un aumento en la tasa de error de hasta el 100% debido al hecho de que el flujo de datos en la sombra se percibirá como intentos repetidos de registrarse y rechazarse.
Mi experiencia personal sugiere que la duplicación de sombra es más adecuada para probar solicitudes no idempotentes o servicios sin estado con apéndices del lado del servidor. En este caso, la duplicación oculta de datos se usa con mayor frecuencia para probar la carga, la estabilidad y las configuraciones. Al mismo tiempo, con la ayuda de pruebas o etapas de integración, puede probar cómo interactúa el servicio con un servidor con estado cuando se trabaja con solicitudes no idempotentes.
Comparación TAP
La única mención de este término se encuentra en un
artículo del blog de Twitter dedicado al lanzamiento de servicios con un alto nivel de calidad de servicio.
“Para verificar la exactitud de la nueva implementación del sistema existente, utilizamos un método llamado comparación de tomas . Nuestra herramienta de comparación de tomas reproduce los datos de producción de muestra en el nuevo sistema y compara las respuestas recibidas con los resultados del anterior. Los resultados obtenidos nos ayudaron a encontrar y corregir errores en el sistema incluso antes de que los usuarios finales los encontraran ”.Otra publicación de blog de Twitter define las comparaciones de tap de la siguiente manera:
"Envío de solicitudes a instancias de servicio tanto en producción como en entornos de ensayo con la comprobación de los resultados y la evaluación de las características de rendimiento".La diferencia entre la comparación de tomas y la duplicación oculta es que, en el primer caso, la respuesta devuelta por la versión
lanzada se compara con la respuesta devuelta por la versión
implementada , y en el segundo, la solicitud se duplica a la versión
implementada en modo fuera de línea como disparar y olvidar.
Otra herramienta para trabajar en esta área es la biblioteca
científica , disponible en GitHub. Esta herramienta fue desarrollada para probar el código Ruby, pero luego fue portada a
varios otros idiomas . Es útil para algunos tipos de pruebas, pero tiene varios problemas sin resolver. Esto es lo que escribió un desarrollador de GitHub en una comunidad Slack profesional:
“Esta herramienta simplemente ejecuta dos ramas de código y compara los resultados. Debe tener cuidado con el código de estas ramas. Es necesario asegurarse de que las consultas de la base de datos no se dupliquen si esto genera problemas. Creo que esto se aplica no solo a un científico, sino también a cualquier situación en la que hagas algo dos veces y luego compares los resultados. La herramienta científica fue creada para verificar que el nuevo sistema de permisos funciona igual que el anterior, y en ciertos momentos se utilizó para comparar los datos que son típicos para prácticamente todas las solicitudes de Rails. Creo que el proceso llevará más tiempo, ya que el procesamiento se realiza de forma secuencial, pero este es un problema de Ruby en el que no se utilizan hilos.
En la mayoría de los casos que conozco, la herramienta científica se utilizó para trabajar con operaciones de lectura en lugar de escritura, por ejemplo, para averiguar si las nuevas consultas mejoradas y los esquemas de permisos reciben la misma respuesta que los anteriores. Ambas opciones se ejecutan en un entorno de producción (en réplicas). Si los recursos probados tienen efectos secundarios, creo que las pruebas tendrán que hacerse a nivel de aplicación ".Diffy es una herramienta de código abierto escrita en Scala presentada por Twitter en 2015.
Un artículo del blog de Twitter titulado
Pruebas sin escribir Pruebas es probablemente el mejor recurso para comprender cómo funcionan las comparaciones de tomas en la práctica.
“Diffy detecta posibles errores en el servicio al lanzar simultáneamente una versión nueva y antigua del código. Esta herramienta funciona como un servidor proxy y envía todas las solicitudes recibidas a cada una de las instancias en ejecución. Luego compara las respuestas de las instancias e informa todas las desviaciones encontradas durante la comparación. Diffy se basa en la siguiente idea: si dos implementaciones de un servicio devuelven las mismas respuestas con un conjunto de solicitudes suficientemente grande y variado, entonces estas dos implementaciones pueden considerarse equivalentes, y las más nuevas sin degradación del rendimiento. La innovadora técnica de reducción de ruido de Diffy lo distingue de otras herramientas comparativas de análisis de regresión ".La comparación de tap es excelente cuando necesita verificar si dos versiones dan los mismos resultados. De acuerdo con Mark McBride,
“La herramienta Diffy a menudo se usaba en el rediseño de sistemas. En nuestro caso, dividimos la base del código fuente de Rails en varios servicios creados usando Scala, y una gran cantidad de clientes API utilizaron funciones de manera diferente a lo que esperábamos. Funciones como el formato de fecha eran especialmente peligrosas ".La comparación de tomas no es la mejor opción para probar la actividad del usuario o la identidad del comportamiento de dos versiones del servicio con la carga máxima. Al igual que con la duplicación de sombra, los efectos secundarios siguen siendo un problema no resuelto, especialmente cuando tanto la versión implementada como la versión de producción escriben datos en la misma base de datos. Al igual que con las pruebas de integración, una forma de evitar este problema es usar pruebas de comparación de tap con solo un conjunto limitado de cuentas.
Prueba de carga
Para aquellos que no están familiarizados con las pruebas de estrés,
este artículo puede servir como un buen punto de partida. No hay escasez de herramientas y plataformas para pruebas de carga de código abierto. Los más populares son
Apache Bench ,
Gatling ,
wrk2 ,
Tsung , escritos en Erlang,
Siege ,
Iago de Twitter, escritos en Scala (que reproduce los registros de un servidor HTTP, servidor proxy o analizador de paquetes de red en una instancia de prueba). Algunos expertos creen que la mejor herramienta para generar carga es
mzbench , que admite una variedad de protocolos, incluidos MySQL, Postgres, Cassandra, MongoDB, TCP, etc.
NDBench de Netflix es otra herramienta de código abierto para almacenes de datos de prueba de carga. , que admite la mayoría de los protocolos conocidos.
El blog oficial de Twitter de
Iago describe con más detalle qué características debe tener un buen generador de carga:
“Las solicitudes sin bloqueo se generan a una frecuencia dada en función de una distribución estadística personalizada interna ( el proceso de Poisson se modela de manera predeterminada). La frecuencia de las solicitudes se puede cambiar según sea necesario, por ejemplo, para preparar el caché antes de trabajar a plena carga.
En general, la atención principal se presta a la frecuencia de las solicitudes de acuerdo con la ley de Little , y no al número de usuarios concurrentes, que pueden variar según la cantidad de retraso inherente a este servicio. Debido a esto, aparecen nuevas oportunidades para comparar los resultados de varias pruebas y prevenir el deterioro del servicio, lo que ralentiza el funcionamiento del generador de carga.
En otras palabras, la herramienta Iago busca simular un sistema en el que se reciben solicitudes independientemente de la capacidad de su servicio para procesarlas. En esto, difiere de los generadores de carga que simulan sistemas cerrados en los que los usuarios trabajarán pacientemente con el retraso existente. Esta diferencia nos permite modelar con bastante precisión los modos de falla que se pueden encontrar en la producción ".Otro tipo de prueba de carga es la prueba de esfuerzo redistribuyendo el flujo de datos. Su esencia es la siguiente: todo el flujo de datos del entorno de producción se dirige a un clúster más pequeño que el preparado para el servicio; Si hay problemas, la secuencia de datos se transfiere nuevamente al clúster más grande. Facebook utiliza esta técnica, como se describe en uno de los
artículos de su blog oficial :
“Redirigimos específicamente un mayor flujo de datos a grupos o nodos individuales, medimos el consumo de recursos en estos nodos y determinamos los límites de la estabilidad del servicio. Este tipo de prueba, en particular, es útil para determinar los recursos de CPU necesarios para admitir la cantidad máxima de transmisiones simultáneas de Facebook Live ".Esto es lo que escribe un ex ingeniero de LinkedIn en la comunidad profesional de Slack:
"LinkedIn también utilizó pruebas de línea roja en la producción: los servidores se eliminaron del equilibrador de carga hasta que la carga alcanzó los valores umbral o comenzaron a producirse errores".De hecho, una búsqueda en Google proporciona un enlace a un
documento técnico completo y un
artículo de blog de LinkedIn sobre este tema:
“La solución Redliner para mediciones utiliza un flujo de datos real del entorno de producción, lo que evita errores que impiden mediciones precisas del rendimiento en el laboratorio.
Redliner redirige parte del flujo de datos al servicio bajo prueba y analiza en tiempo real su rendimiento. Esta solución se ha implementado en cientos de servicios internos de LinkedIn y se usa diariamente para varios tipos de análisis de rendimiento.
Redliner admite la ejecución de pruebas paralelas para instancias canarias y de producción. Esto permite a los ingenieros transferir la misma cantidad de datos a dos instancias de servicio diferentes: 1) una instancia de servicio que contiene innovaciones, como nuevas configuraciones, propiedades o nuevo código; 2) una instancia de servicio de la versión de trabajo actual."Los resultados de las pruebas de carga se tienen en cuenta al tomar decisiones y ayudan a prevenir la implementación del código, lo que puede conducir a un bajo rendimiento".Facebook llevó las pruebas de carga utilizando flujos de datos reales a un nivel completamente nuevo gracias al sistema Kraken, y también vale la pena leer su
descripción .
Las pruebas se implementan redistribuyendo el flujo de datos al cambiar los valores de peso (leídos del almacén de configuración distribuida) para dispositivos fronterizos y clústeres en la configuración de
Proxygen (balanceador de carga de Facebook). Estos valores determinan el volumen de datos reales enviados, respectivamente, a cada grupo y región en un punto de presencia dado.
Datos del libro blanco de KrakenEl sistema de monitoreo (
Gorilla ) muestra indicadores de varios servicios (como se muestra en la tabla anterior). En función de los datos y los umbrales de monitoreo, se toma la decisión de enviar más datos de acuerdo con los valores de peso, o si es necesario reducir o incluso detener por completo la transferencia de datos a un grupo específico.
Pruebas de configuración
Una nueva ola de herramientas de infraestructura de código abierto ha hecho que la captura de todos los cambios en la infraestructura en forma de código no solo sea posible, sino también relativamente
fácil . También es posible
probar estos cambios en diversos grados, aunque la mayoría de las pruebas de infraestructura como código en la etapa de preproducción solo pueden confirmar las especificaciones y la sintaxis correctas.
Además, la negativa a probar la nueva configuración antes de la
publicación del código se convirtió en la causa de un
número significativo de interrupciones .
Para las pruebas holísticas de los cambios de configuración, es importante distinguir entre diferentes tipos de configuraciones. Fred Hebert una vez sugirió usar el siguiente cuadrante:
Esta opción, por supuesto, no es universal, pero esta distinción le permite decidir cómo probar mejor cada una de las configuraciones y en qué etapa hacerlo. La configuración del tiempo de compilación tiene sentido si puede garantizar la verdadera repetibilidad de los ensamblajes. No todas las configuraciones son estáticas, pero en las plataformas modernas es inevitable un cambio dinámico de configuración (incluso si se trata de una "infraestructura permanente").
, , blue-green , . (
Jamie Wilkinson ), Google ,
:
« , , , - . . - , — , , . ., . , , — ».Facebook :
« . — , . . , .
. Facebook , . , .
(, JSON). , . .
(, Facebook Thrift) . , .
, , - . . — A/B-, 1 % . A/B-, . A/B- . , , , , . , A/B- . , A/B-. Facebook .
, A/B- 1% , 1% , ( « »). , . , .
Facebook . , . , , . , , .- Cancelación de cambios simple y conveniente
En algunos casos, a pesar de todas las medidas preventivas, se realiza el despliegue de una configuración inoperativa. Encontrar y revertir rápidamente los cambios es fundamental para abordar este problema. "Las herramientas de control de versiones están disponibles en nuestro sistema de configuración que hacen que sea mucho más fácil deshacer los cambios".
¡Continuará!UPD: continuó aquí .