Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3 Puede utilizar la técnica de adivinar el "canario" para sus propios fines con el fin de descubrir la presencia de "débiles", en términos de selección, bits. Es decir, si adivinó correctamente, el servidor se reiniciará, y esto le servirá como una señal de que el valor establecido es bastante fácil de adivinar. Por lo tanto, es posible derrotar a los "canarios" aleatorizados, suponiendo que después del reinicio del servidor, su valor no cambiará. También puede usar gadgets para implementar una secuencia relacionada de varios ataques.
A continuación, veremos una forma más productiva en la que puede utilizar todos estos métodos para derrotar la prevención de ejecución de datos, espacios de direcciones aleatorias y "canarios".
Dirijamos nuestra atención a las arquitecturas de 64 bits en lugar de las arquitecturas de 32 bits. Los primeros son más adecuados para la aleatorización, por lo que te dan muchas más "posibilidades" de defenderte de un hacker. Y estos sistemas se ven mucho más interesantes en términos de formación de ataques.
Este tipo de arquitectura de 64 bits también se consideró desde el punto de vista de
BROP , la programación "ciega" orientada hacia atrás. Por simplicidad, suponemos que la única diferencia entre las máquinas de 64 bits y 32 bits es que en una máquina de 64 bits, los argumentos se pasan a los registros, y para una máquina de 32 bits, a la pila.

Cuando una función comienza a ejecutarse, se toma para "mirar" en ciertos registros para encontrar dónde están los argumentos.
Ahora vayamos a la esencia de la conferencia de hoy: qué es la programación orientada al retorno ciego, o
BROP . Lo primero que haremos es encontrar un dispositivo de parada. Recuerde que cuando decimos "gadget", nos referimos esencialmente a las direcciones de retorno. El gadget se identifica con la dirección de retorno, la dirección de inicio de la secuencia de instrucciones a la que queremos ir. Entonces, ¿qué es un dispositivo de parada?
Esencialmente, es la dirección de retorno a algún lugar en el código, sin embargo, si salta allí, simplemente pause el programa, pero no haga que el programa se bloquee. Es por eso que esto se llama un dispositivo de parada.
Podría saltar a algún lugar del código, que luego inicia una llamada al sistema inactivo, o hace una pausa, o algo así. Es posible que el programa de alguna manera se "atasque" en un bucle sin fin si saltas a este lugar. Realmente no importa por qué ocurre la parada, pero puede imaginar algunos escenarios que lo llevarían a ello.
¿Para qué sirve un gadget de parada?
Tan pronto como el atacante logró derrotar al "canario" utilizando la técnica interactiva de adivinar bits, puede comenzar a reescribir esta dirección de retorno,
ret dirección, y comienza a "tocar" el dispositivo de parada. Tenga en cuenta que es probable que la mayoría de las direcciones aleatorias que puede colocar en la pila simplemente hagan que el servidor se bloquee. Nuevamente, este mensaje es para usted, el atacante, esto es una indicación de que lo que encontró no es un dispositivo de detención. Porque cuando el servidor falla, su socket se cierra y usted, como atacante, comprende que no entró en el dispositivo de detención. Pero si adivinó algo y el enchufe después de eso permanece abierto por un tiempo, piensa: "¡Sí, encontré este dispositivo de parada!" Entonces, la idea básica del primer paso es encontrar este gadget de parada.

El segundo paso es que desea encontrar gadgets que eliminen las entradas de la pila utilizando el comando
pop . Por lo tanto, debe usar esta secuencia de instrucciones cuidadosamente diseñadas para averiguar cuándo tomar uno de estos gadgets de pila. Esta secuencia consistirá en la
dirección de la sonda de la
dirección de la sonda , la
dirección de detención de la dirección de detención y la
dirección de falla del sistema de la
dirección de bloqueo .
Por lo tanto, la
dirección de la sonda es lo que vamos a poner en la pila. Esta será la dirección del gadget potencial para borrar la pila, la
dirección de detención : esto es lo que consideramos en el primer paso, esta es la dirección del gadget de detención. Entonces la
dirección de bloqueo simplemente será la dirección del código no ejecutable. Aquí puede simplemente poner la dirección cero (0 x 0), y si aplica la función
ret a esta dirección e intenta ejecutar el código allí, esto conducirá a un bloqueo del programa.

Por lo tanto, podemos usar este tipo de direcciones para averiguar dónde limpian estos gadgets la
pila emergente de la pila .
Daré un ejemplo simple. Supongamos que tenemos dos ejemplos de
sonda diferentes, la trampa
trampa y la
trampa stop . Supongamos que, con la ayuda de la
sonda, vamos a "sondear" alguna dirección, supongamos que comienza con 4 y termina con ocho: 0x4 ... 8, y detrás está la siguiente dirección de la forma 0x4 ... C. Hipotéticamente, podemos suponer que una de estas dos direcciones es la dirección del gadget
emergente de la
pila .
La
trampa trampa obtendrá cero direcciones 0x0 y 0x0, y dejará que el gadget
stop se
detenga con direcciones arbitrarias como 0xS ... 0xS ..., no importa. Este dispositivo de detención apunta al código de suspensión (10), lo que hace que el programa se detenga.
Comencemos con la operación de la
sonda , que borra algunos registros y regresa en la siguiente secuencia:
pop rax; ret . Que va a pasar Cuando el sistema salta a esta dirección, el puntero de la pila se moverá a la mitad de nuestro gadget. ¿Qué va a hacer el gadget aquí? Derecha, realice
la operación
pop rax .

Y luego sigue
ret , que moverá la función a la línea superior del gadget, es decir, para
detener , y la función se detendrá sin bloquear todo el programa. Entonces, usando este gadget, un atacante puede decir que la dirección de la
sonda pertenece a una de estas funciones, que borra la pila, porque la conexión del cliente del servidor está abierta.
Ahora supongamos que la segunda dirección de la
sonda apunta a algo como
xor rax, rax, ret para algún registro.

Entonces, ¿qué sucede si intentamos saltar a este gadget? Tenga en cuenta que no borra nada en la pila, solo cambia el contenido de los registros. Entonces, vamos a regresar a la dirección 0x0 ubicada arriba. Y esto hará que el sistema se bloquee. La conexión del cliente con el servidor se interrumpirá, y el hacker comprenderá que este no es un gadget para borrar la pila de la
pila .
De esta manera, puede usar una serie más extraña de trampas y detener dispositivos, por ejemplo, puede borrar dos elementos en la pila. Para hacer esto, solo necesita colocar otra instrucción de
captura aquí, y si este gadget no borra dos elementos, se encontrará en una de estas trampas, y el código dejará de ejecutarse. Los materiales para la conferencia describen una cosa llamada
dispositivo BROP, que es útil si no le gusta volver a la programación. Pero hoy también te diré cómo puedes usar estos simples gadgets
pop para lanzar un ataque similar. Una vez que comprenda esto, tratar con un
gadget BROP será mucho más fácil.
Pero, ¿entienden cómo podemos usar la función de
sonda para estos dispositivos? Suponga que encuentra la ubicación de los fragmentos de código que le permite borrar la pila con la función
pop , eliminar un elemento, pero realmente no sabe en qué registro funcionará esta función
pop . Solo sabes que ella ya está lista para la ejecución. Pero necesita saber en qué registro funcionarán estos gadgets
pop , porque en una arquitectura de 64 bits, los registros controlan dónde se encuentran los argumentos de la función que desea llamar.
Por lo tanto, nuestro objetivo es poder crear gadgets que nos permitan eliminar los valores que ponemos en ciertos registros de la pila y, en última instancia, iniciar una llamada al
sistema , lo que nos permite hacer algo malo.
Así que ahora tenemos que determinar qué registros usan
los gadgets
pop .

Para hacer esto, podemos aprovechar la llamada al sistema de pausa. Si la llamada del sistema está en pausa, la ejecución del programa se suspende y no acepta ningún argumento. Y esto significa que el sistema ignora todo en los registros.
De hecho, para encontrar la instrucción de pausa que estamos ejecutando, puede vincular todos estos gadgets
pop para que podamos ponerlos todos en la pila, y entre cada uno de ellos
inserte un número de syscall para pausar. Luego veremos si podemos "suspender" el programa de esta manera. Déjame darte un ejemplo concreto.
Aquí, colocamos un gadget en la barra de dirección de retorno que borra los registros
RDI y les aplica la función
ret . Arriba pondremos un
número de syscall para pausar.
Supongamos que tenemos un dispositivo más ubicado arriba que implementa la función
pop en otro registro, digamos
RSI , y luego
ret . Y luego ponemos el
número de syscall nuevamente para hacer una pausa. Y hacemos esto para todos los dispositivos que encontramos, y luego terminamos en la parte superior de la pila con la dirección supuesta para
syscall .
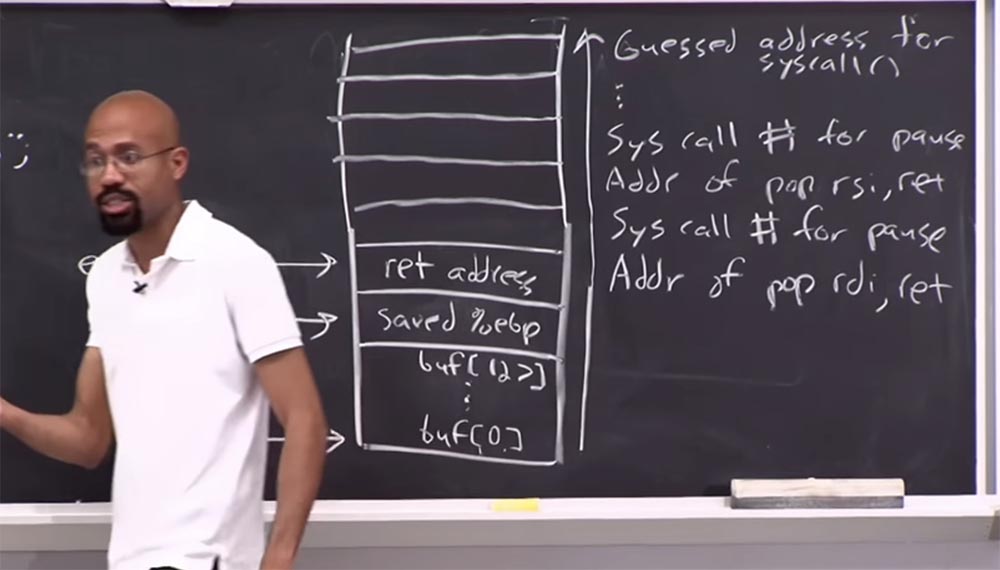
Recuerde nuevamente cómo utiliza estas llamadas al sistema. Debe poner el
número de syscall en el registro
RAX , luego llamar a la
función libc syscall , que está a punto de realizar la llamada al sistema solicitada.
Entonces, ¿qué sucede cuando ejecutamos este código? Llegaremos aquí, a la línea de
dirección de ret , saltaremos a la dirección de este gadget, debe tenerse en cuenta que el atacante sabe que este gadget, ubicado a la derecha, elimina algo de la pila, pero aún no sabe en qué registro se encuentra.
Entonces, si
saltamos a la dirección ret , ¿qué sucede? Él usará la función
pop para pausar
syscall , en algún registro que el atacante no conoce, y luego continuaremos escalando esta cadena de operaciones en la pila.
Al hacerlo, esperamos que uno de estos dispositivos realice la función
emergente para el
número de syscall en el registro
RAX correspondiente. Entonces, para cuando lleguemos aquí, en la parte superior de la pila, en el camino "estropeando" todos los registros que tienen un
número de syscall para pausar, esperamos que todavía tengamos un registro, que debería ser correcto. Porque si uno de nuestros dispositivos hace esto, y luego, al hacer
ret , después de un tiempo volveremos aquí, en la parte superior de la pila, entonces tendremos una pausa. Una vez más, la pausa actúa como una señal para el atacante. Porque si esta dirección asumida para
syscall era incorrecta, entonces el programa fallará.
Entonces, ¿qué nos permite hacer esta fase de ataque? Todavía no sabemos en qué registros se encuentran los gadgets
pop , pero sabemos que uno de ellos liberará el
RAX que queremos controlar. Y probablemente conocemos la dirección de
syscall , porque logramos detener el sistema.
Una vez que hacemos esto, podemos verificar estos dispositivos uno por uno y descubrir cuál pone el sistema en pausa. En otras palabras, cortamos todo entre la línea de
dirección de ret y la parte superior de la pila para ir directamente a
syscall . Verificaremos si se produjo una pausa o una falla del sistema. Si ocurre una falla, identificamos el dispositivo que lo causó, por ejemplo, está en la línea inferior a la derecha, esto es
pop rdi . Deshazte de él y prueba el siguiente. Ponga aquí en la línea arriba de la
dirección ret la dirección real para
syscall . ¿Podríamos pausar el programa? Sí, eso significa que aprendimos que este gadget
pop debería liberar
RAX . ¿Eso está claro?
Público: Entonces, ¿una forma de adivinar la dirección de una llamada al sistema es solo una transferencia ciega de gadgets?
Profesor: sí, lo es, y hay formas de optimizar este proceso en los materiales de lectura cuando usa la extensión de archivo
PLT y cosas similares. Con el simple ataque que describí, realmente solo pega la dirección aquí y se asegura de que haya causado una pausa o no. Como resultado de la prueba, descubrimos la ubicación de
syscall . Descubriremos dónde se encuentra la instrucción que ejecuta
pop RAX . También necesitamos gadgets que ejecuten
pop en algunos otros registros también. Puedes hacer pruebas similares para ellos. Por lo tanto, en lugar de pausar el
número de syscall , use
push para algún otro comando que, por ejemplo, use los argumentos
RAX y
RDI .
Por lo tanto, puede usar el hecho de que para cualquier conjunto particular de registros que desee controlar, hay algún tipo de
syscall que le dará a un atacante una señal para saber si lo rompió con éxito o no. Por lo tanto, al final de esta fase, tendrá la dirección
syscall y la dirección del montón de gadgets, que le permiten
ingresar registros arbitrarios.
Y ahora pasemos al cuarto paso, que se llamará grabación - grabación. El cuarto paso es grabar una llamada al sistema. Para llamar a
escribir , necesitamos tener los siguientes gadgets:
pop rdi, ret;
pop rsi, ret;
pop rdx, ret;
pop rax, ret;
syscall
¿Cómo utilizan estos registros una llamada al sistema? El primero es el socket o, más generalmente, el descriptor de archivo que va a transferir para escribir. El segundo es el búfer, el tercero es la longitud de este búfer, el cuarto es el número de llamada del sistema y el quinto es la llamada al sistema.
Entonces, si encontramos todos estos gadgets, entonces podemos controlar los valores que están incrustados en los argumentos, que, a su vez, se colocan en estos registros, porque simplemente los "empujamos" en la pila.
¿Qué debería ser un zócalo? Aquí tenemos que adivinar un poco. Puede aprovechar el hecho de que Linux limita el número de conexiones abiertas simultáneas para un archivo que alcanza un valor de 2024. Y también que debería ser el mínimo de todos los disponibles.
Me pregunto qué vamos a insertar en el puntero del búfer. Así es, tenemos la intención de usar el fragmento de texto del programa aquí, lo vamos a poner en un puntero en algún lugar del código del programa. Esto nos permite leer el archivo binario de la memoria utilizando la llamada correcta del cliente desde el socket. Luego, el atacante puede tomar este archivo binario, analizarlo sin conexión fuera de línea, usando
GDB u otra herramienta para averiguar dónde se encuentra todo esto. El atacante sabe que ahora, cada vez que el servidor "falla", se almacenará en él el mismo conjunto aleatorio de cosas. Entonces, ahora que un atacante puede encontrar las direcciones y las compensaciones para el contenido de la pila, puede atacar estos dispositivos directamente. Puede atacar directamente otras vulnerabilidades, descubrir cómo abrir el shell y similares. En otras palabras, en el lugar donde proporcionaste el binario con el hacker, fuiste derrotado.
Así es como funciona el ataque
BROP . Como dije, en los materiales de la conferencia hay muchas formas de optimizar estos procesos, pero primero debe comprender el material principal, de lo contrario, la optimización pierde su significado. Por lo tanto, puede hablarme sobre la optimización individualmente o después de la clase.
Por ahora, basta con decir que estos son los conceptos básicos de cómo puede lanzar un ataque
BROP . Debe encontrar el dispositivo de
detención , los dispositivos que realizan la función de
las entradas de
la pila
emergente , averiguar en qué registros se encuentran, dónde se encuentra
syscall y luego iniciar la
escritura , en función de la información obtenida.

Entonces,
repase rápidamente el tema, ¿cómo se defiende contra
BROP ? Entonces, lo más obvio que tienes es la aleatorización. Dado que el hecho de que los servidores "caídos" no reaparecen, no crean versiones aleatorias de sí mismos, actúa como una señal que le da al atacante la oportunidad de probar varias hipótesis sobre cómo funcionan los programas.
Una manera fácil de protegerte es asegurarte de que
ejecutas en lugar de
fork cuando revives tu proceso. Porque cuando ejecuta el proceso, crea un espacio completamente nuevo ubicado al azar, al menos eso es lo que sucede en Linux. En Linux, cuando compila usando
PIE ,
Position Independent Execution , un ejecutable independiente de la ubicación, cuando usa
exec, solo obtiene un nuevo espacio de dirección aleatorio.
La segunda forma es simplemente usar Windows, porque este sistema operativo básicamente no tiene el equivalente de una función
fork . Esto significa que cuando revivas un servidor en Windows, siempre tendrá un nuevo espacio de direcciones aleatorias.
Alguien aquí preguntó qué pasaría si después de un mal funcionamiento del servidor no se desconectara. Por lo tanto, si durante un bloqueo del servidor de alguna manera "detectamos" este error y mantenemos la conexión abierta por un tiempo, podemos confundir al atacante para que no reciba una señal sobre la falla y piense que ha encontrado la dirección correcta.
En este caso, su ataque
BROP se convertirá en un ataque
DOS . Porque acabas de recibir todos los procesos potenciales de zombies que están alrededor. Son inútiles, pero no puede dejarlos ir más allá, de lo contrario tendrá que eliminar esta información.
Otra cosa en la que podría pensar es en hacer el control de fronteras del que hablamos antes. Los materiales de la conferencia dicen que este método no es productivo, ya que es 2 veces más costoso, pero aún podría usarlo.
Así es como funciona
BROP . En cuanto a la tarea, se hace una pregunta más delicada: ¿qué pasa si usa un hash de la hora actual? Es decir, el período de tiempo durante el que reinicia el programa. ¿Es esto suficiente para prevenir este tipo de ataque? Tenga en cuenta que el hash no le proporciona mágicamente bits de entropía si los datos que ingresa en el hash son fácilmente predecibles. Si su hash contiene miles de millones de bits, eso no importa. Pero si solo tiene un par de significados allí, el atacante los adivinará. Por supuesto, usar un hash de tiempo aleatorio es mejor que no usar nada para protegerse contra un pirata informático, pero esto no le proporcionará la seguridad con la que debe contar.
La versión completa del curso está disponible
aquí .
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?