Quizás hoy no haya otra tecnología en torno a la cual habría tantos mitos, mentiras e incompetencias. Los periodistas que hablan sobre la tecnología mienten, los políticos que hablan sobre la implementación exitosa mienten, la mayoría de los vendedores de tecnología mienten. Todos los meses, veo las consecuencias de cómo las personas intentan implementar el reconocimiento facial en sistemas que no pueden funcionar con él.

El tema de este artículo hace mucho tiempo se volvió doloroso, pero de alguna manera era demasiado vago para escribirlo. Mucho texto que ya he repetido veinte veces a diferentes personas. Pero, después de leer el siguiente paquete de basura, decidí que era hora. Daré un enlace a este artículo.
Entonces En el artículo responderé algunas preguntas simples:
- ¿Es posible reconocerte en la calle? ¿Y qué tan automático / confiable?
- Anteayer escribieron que los delincuentes estaban detenidos en el metro de Moscú, y ayer escribieron que no podían en Londres. Y también en China reconocen a todos, todos en la calle. Y aquí dicen que 28 congresistas estadounidenses son delincuentes. O atraparon a un ladrón.
- ¿Quién está lanzando soluciones de reconocimiento facial, cuál es la diferencia entre las soluciones y las características tecnológicas?
La mayoría de las respuestas se basarán en evidencia, con un enlace a la investigación donde se muestran los parámetros clave de los algoritmos + con las matemáticas de cálculo. Una pequeña parte se basará en la experiencia de implementación y operación de varios sistemas biométricos.
No entraré en detalles sobre cómo se implementa el reconocimiento facial ahora. En Habré hay muchos buenos artículos sobre este tema:
a ,
b ,
c (hay muchos más, por supuesto, estos aparecen en la memoria). Pero aún así, describiré algunos puntos que afectan las diferentes decisiones. Por lo tanto, leer al menos uno de los artículos anteriores simplificará la comprensión de este artículo. ¡Empecemos!
Introducción, base
La biometría es una ciencia exacta. No hay espacio para las frases "siempre funciona" e "ideal". Todo está muy bien considerado. Y para calcular necesitas saber solo dos cantidades:
- Errores del primer tipo: una situación en la que una persona no está en nuestra base de datos, pero la identificamos como una persona presente en la base de datos (en biometría FAR (tasa de acceso falso))
- Errores del segundo tipo: situaciones en las que una persona está en la base de datos, pero la extrañamos. (En biometría FRR (tasa de rechazo falso))
Estos errores pueden tener una serie de características y criterios de aplicación. Hablaremos de ellos a continuación. Mientras tanto, te diré dónde conseguirlos.
Caracteristicas
La primera opción Érase una vez, los propios fabricantes publicaron errores. Pero aquí está la cosa: no puedes confiar en el fabricante. Bajo qué condiciones y cómo midió estos errores, nadie lo sabe. Y si se mide en absoluto, o el departamento de marketing dibujó.
La segunda opción. Las bases abiertas aparecieron. Los fabricantes comenzaron a indicar errores en las bases. El algoritmo se puede mejorar para bases de datos conocidas, de modo que muestren una calidad increíble para ellos. Pero en realidad, tal algoritmo puede no funcionar.
La tercera opción son los concursos abiertos con una solución cerrada. El organizador verifica la decisión. Esencialmente kaggle. El más famoso de estos es
MegaFace . Los primeros lugares en esta competencia una vez dieron gran popularidad y fama. Por ejemplo, N-Tech y Vocord se han hecho un nombre en MegaFace.
Todo estaría bien, pero sinceramente. Puede personalizar la solución aquí. Esto es mucho más difícil, más largo. Pero puede calcular personas, puede marcar manualmente la base, etc. Y lo más importante: no tendrá nada que ver con cómo funcionará el sistema con datos reales. Puedes ver quién es el líder en MegaFace ahora, y luego buscar las soluciones de estos tipos en el siguiente párrafo.
La cuarta opción . Hasta la fecha, el más honesto. No sé cómo hacer trampa allí. Aunque no los excluyo.
Un instituto grande y de fama mundial acuerda implementar un sistema de prueba de solución independiente. Se recibe un SDK de los fabricantes, que está sujeto a pruebas cerradas, en las que el fabricante no participa. Las pruebas tienen muchos parámetros, que luego se publican oficialmente.
Ahora, NIST, el Instituto Nacional Estadounidense de Estándares y Tecnologías, lleva a cabo tales
pruebas . Dicha prueba es la más honesta e interesante.
Debo decir que NIST hace un gran trabajo. Desarrollaron cinco casos, lanzaron nuevas actualizaciones cada dos meses, mejoraron constantemente e incluyeron nuevos fabricantes. Aquí puede encontrar el último número del estudio.
Parece que esta opción es ideal para el análisis. Pero no! La principal desventaja de este enfoque es que no sabemos qué hay en la base de datos. Mira este cuadro aquí:

Estos son los datos de dos compañías para las cuales se realizaron pruebas. El eje x es el mes, y es el porcentaje de errores. Hice la prueba "Caras salvajes" (justo debajo de la descripción).
Un aumento repentino en la precisión de 10 veces en dos empresas independientes (en general, todos despegaron allí). De donde
El registro NIST dice que "la base de datos era demasiado complicada, la simplificamos". Y no hay ejemplos de la base antigua o la nueva. En mi opinión, este es un grave error. Fue sobre la base anterior que la diferencia entre los algoritmos del proveedor era visible. En el nuevo todos los 4-8% de pases. Y en el viejo era 29-90%. Mi comunicación con el reconocimiento facial en los sistemas de CCTV dice que un 30% antes: este fue el resultado real de los algoritmos de gran maestro. Es difícil de reconocer a partir de tales fotos:

Y, por supuesto, el 4% de precisión no brilla en ellos. Pero sin ver la base NIST, es 100% imposible hacer tales declaraciones. Pero es NIST la principal fuente de datos independiente.
En el artículo, describo la situación relevante para julio de 2018. Al mismo tiempo, confío en la precisión, según la antigua base de datos de personas para las pruebas relacionadas con la tarea "Rostros en la naturaleza".
Es posible que en medio año todo cambie completamente. O tal vez sea estable en los próximos diez años.
Entonces, necesitamos esta tabla:
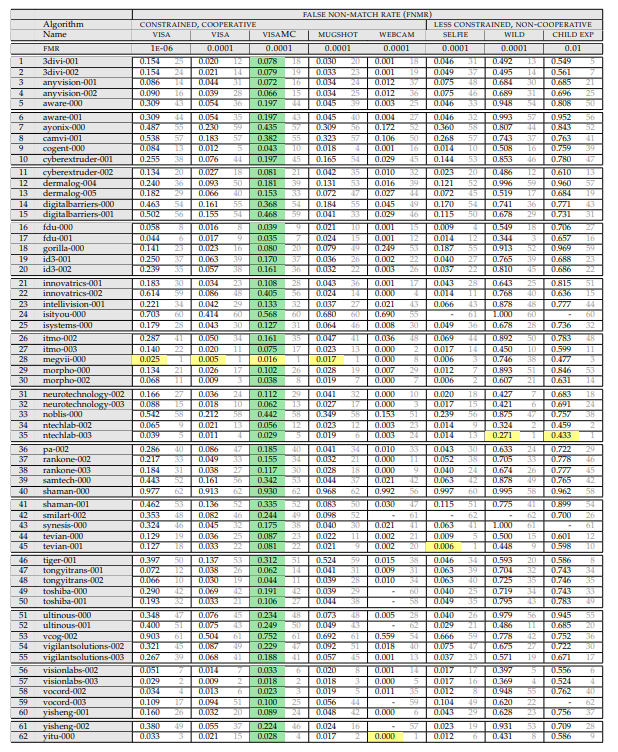
(Abril de 2018, porque salvaje es más adecuado aquí)
Veamos lo que está escrito en él y cómo se mide.
Arriba hay una lista de experimentos. El experimento consiste en:
En el que se está midiendo el conjunto. Los conjuntos son:
- Foto de pasaporte (ideal, frontal). El fondo es blanco, sistemas de disparo ideales. Esto a veces se puede encontrar en el punto de control, pero muy raramente. Por lo general, tales tareas son una comparación de una persona en el aeropuerto con la base.

- La fotografía es un buen sistema, pero sin la mejor calidad. Hay fondos de fondo, una persona puede no pararse de manera uniforme / mirar más allá de la cámara, etc.

- Selfies desde una cámara de teléfono inteligente / computadora. Cuando el usuario coopera, pero las condiciones de disparo son malas. Hay dos subconjuntos, pero solo tienen muchas fotos en selfies.

- "Caras en la naturaleza": disparos desde casi cualquier lado / disparos ocultos. Los ángulos máximos de rotación de la cara a la cámara son 90 grados. Aquí es donde NIST ha simplificado enormemente la base.

- Niños Todos los algoritmos funcionan mal para los niños.
Además, a qué nivel de errores se miden los errores de primer tipo (este parámetro se considera solo para fotos de pasaporte):
- 10 ^ -4 - FAR (un falso positivo del primer tipo) para 10 mil comparaciones con la base
- 10 ^ -6 - FAR (un falso positivo del primer tipo) por millón de comparaciones con la base
El resultado del experimento es el valor FRR. La probabilidad de que extrañáramos a la persona que está en la base de datos.
Y ya aquí, el lector atento pudo notar el primer punto interesante. "¿Qué significa FAR 10 ^ -4?" ¡Y este es el momento más interesante!
Configuración principal
¿Qué significa tal error en la práctica? Esto significa que sobre la base de 10,000 personas habrá una coincidencia errónea al verificar a cualquier persona promedio. Es decir, si tenemos una base de 1000 delincuentes y la comparamos con 10,000 personas al día, tendremos un promedio de 1000 falsos positivos. ¿Alguien realmente necesita esto?
En realidad, no todo es tan malo.
Si observa la creación de un gráfico de la dependencia de un error del primer tipo de un error del segundo tipo, obtiene una imagen genial (aquí inmediatamente para una docena de compañías diferentes, para la opción Wild, esto es lo que sucederá en la estación de metro, si coloca la cámara en algún lugar para que la gente no la vea) :
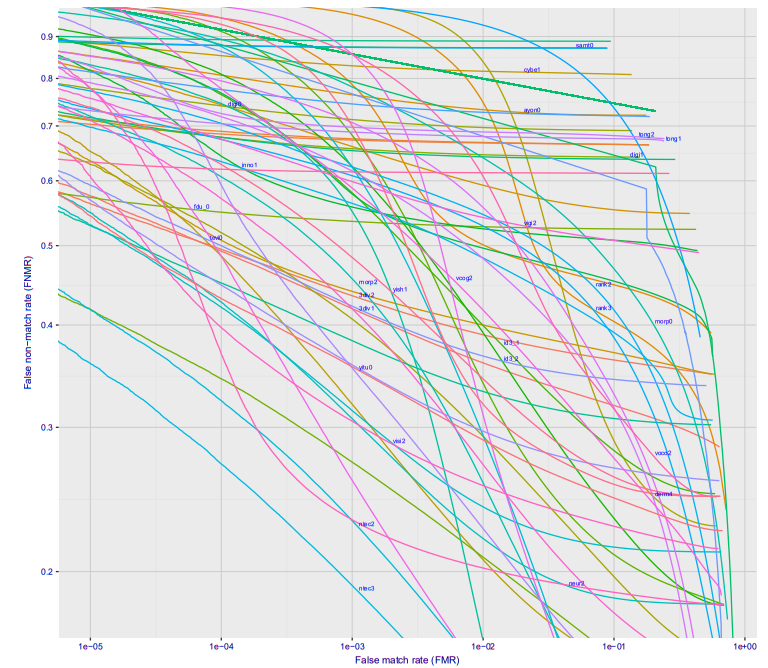
Con un error de 10 ^ -4, el 27% de las personas no reconocidas. 10 ^ -5 aproximadamente 40%. Lo más probable es que una pérdida de 10 ^ -6 sea aproximadamente del 50%
Entonces, ¿qué significa esto en números reales?
Es mejor pasar del paradigma de "cuántos errores se pueden cometer al día". Tenemos un flujo de personas en la estación, si cada 20-30 minutos el sistema da un falso positivo, entonces nadie lo tomará en serio. Arreglamos el número permitido de falsos positivos en la estación de metro 10 personas por día (si es bueno que el sistema no esté apagado como molesto, necesita aún menos). El flujo de una estación del metro de Moscú
20-120 mil pasajeros por día. El promedio es de 60 mil.
Deje que el valor fijo de FAR sea 10 ^ -6 (no puede ponerlo debajo, perderemos el 50% de los delincuentes si somos optimistas). Esto significa que podemos permitir 10 falsas alarmas con un tamaño base de 160 personas.
¿Es mucho o poco? El tamaño de la base en la lista de buscados federal es de ~
300,000 personas . Interpol 35 mil. Es lógico suponer que se necesitan alrededor de 30 mil moscovitas.
Esto dará un número poco realista de falsas alarmas.
Vale la pena señalar que 160 personas pueden ser una base suficiente si el sistema funciona en línea. Si busca a los que cometieron un delito en el último día, este ya es un volumen bastante funcional. Al mismo tiempo, con gafas / gorras negras, etc., puede disfrazarse. ¿Pero cuántos los llevan en el metro?
El segundo punto importante. Es fácil crear un sistema en el metro que ofrezca fotos de mayor calidad. Por ejemplo, colóquese el marco del torniquete de la cámara. Ya no habrá un 50% de pérdidas en 10 ^ -6, sino solo un 2-3%. Y por 10 ^ -7 5-10%. Aquí, la precisión del gráfico en Visa, ciertamente será mucho peor en cámaras reales, pero creo que a 10 ^ -6 puede dejar esta pérdida del 10%:

Nuevamente, el sistema no extraerá la base de 30 mil, pero todo lo que ocurra en tiempo real permitirá la detección.
Primeras preguntas
Parece que es hora de responder la primera parte de las preguntas:
Liksutov
dijo que se identificaron 22 personas buscadas. ¿Es esto cierto?
Aquí la pregunta principal es qué cometieron estas personas, cuántas personas no buscadas fueron verificadas, cuánto reconocimiento facial ayudó en la detención de estas 22 personas.
Lo más probable es que si estas son las personas a quienes buscaba el plan de "intercepción", estos sean realmente detenidos. Y este es un buen resultado. Pero mis supuestos modestos me permiten decir que para lograr este resultado, se verificaron al menos 2-3 mil personas, pero más bien unas diez mil.
Golpea muy bien con los números que se llamaron en
Londres . Solo que estos números se publican honestamente, ya que la gente
protesta . Y estamos en silencio ...
Ayer en Habré había un artículo sobre la cuenta de
rostros falsos en el reconocimiento de
rostros . Pero este es un ejemplo de manipulación en la dirección opuesta. Amazon nunca ha tenido un buen sistema de reconocimiento facial. Además de la cuestión de cómo establecer umbrales. Al menos puedo hacer el 100% de los cacahuetes girando la configuración;)
Sobre los chinos, que reconocen a todos en la calle, una falsa obvia. Aunque, si hicieron un seguimiento competente, entonces puede hacer un análisis más adecuado. Pero, para ser honesto, no creo que hasta ahora sea posible. Más bien, un conjunto de enchufes.
¿Qué hay de mi seguridad? ¿En la calle, en el mitin?
Vamos más allá. Vamos a evaluar otro momento. Busque una persona con una biografía conocida y un buen perfil en las redes sociales.
NIST verifica el reconocimiento cara a cara. Se toman dos caras de las mismas personas / diferentes y se compara lo cerca que están entre sí. Si la proximidad es mayor que el umbral, entonces esta es una persona. Si más lejos - diferente. Pero hay un enfoque diferente.
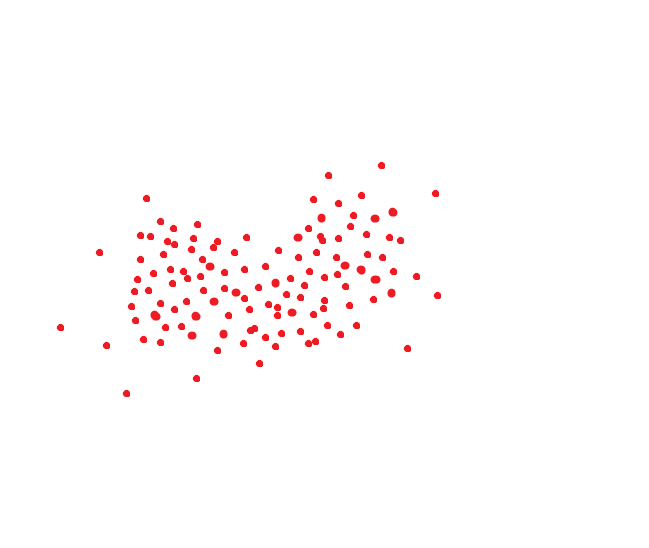
Si lees los artículos que te aconsejé al principio, entonces sabes que al reconocer una cara, se genera un código hash de la cara, que muestra su posición en el espacio N-dimensional. Por lo general, este es un espacio dimensional de 256/512, aunque todos los sistemas tienen formas diferentes.
Un sistema de reconocimiento facial ideal traduce la misma cara en el mismo código. Pero no hay sistemas ideales. Una misma persona generalmente ocupa un área del espacio. Bueno, por ejemplo, si el código era bidimensional, podría ser algo como esto:
Si nos guiamos por el método adoptado por NIST, entonces esta distancia sería un umbral objetivo para que podamos reconocer a una persona como el mismo individuo con una probabilidad del 95%:
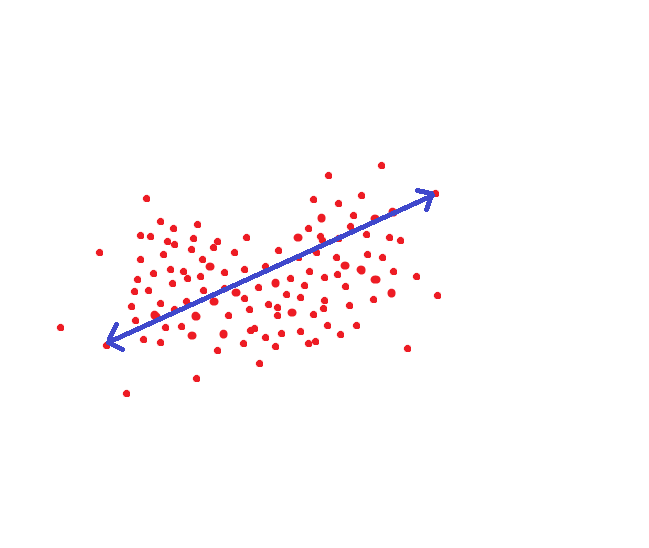
Pero puedes hacer lo contrario. Para cada persona, configure el área de hiperespacio donde se almacenan los valores que son válidos para él:

Entonces, la distancia umbral, mientras se mantiene la precisión, disminuirá varias veces.
Solo necesitamos muchas fotos para cada persona.
Si una persona tiene un perfil en las redes sociales / la base de sus imágenes de diferentes edades, entonces la precisión del reconocimiento se puede aumentar mucho. No sé la evaluación exacta de cómo crece FAR | FRR. Y ya es incorrecto evaluar tales cantidades. Alguien en esta base de datos tiene 2 fotos, alguien tiene 100. Mucha lógica de ajuste. Me parece que la calificación máxima es de uno / uno y medio pedidos. Eso le permite agregar 10 ^ -7 a los errores con una probabilidad de no reconocer el 20-30%. Pero es especulativo y optimista.
En general, por supuesto, no hay algunos problemas con la gestión de este espacio (chips de edad, chips de editor de imágenes, chips de ruido, chips de nitidez), pero según tengo entendido, la mayoría de ellos ya han sido resueltos con éxito por grandes empresas que necesitaban una solución.
¿Por qué estoy haciendo esto? Además, el uso de perfiles permite varias veces aumentar la precisión de los algoritmos de reconocimiento. Pero está lejos de ser absoluto. Los perfiles requieren mucho trabajo manual. Hay muchas personas similares. Pero si comienza a establecer restricciones de edad, ubicación, etc., este método le permite obtener una buena solución. Para un ejemplo de cómo encontraron a una persona en el principio de "buscar perfil por foto" -> "usar perfil para buscar a una persona", le di un
enlace al principio.
Pero, en mi opinión, este es un proceso altamente escalable. Y, nuevamente, las personas con una gran cantidad de imágenes en el perfil, Dios no lo quiera, 40-50% en nuestro país. Sí, y muchos de ellos son niños para quienes todo funciona mal.
Pero, de nuevo, esta es una evaluación.
Entonces aquí. Sobre tu seguridad. Cuantas menos fotos de perfil tengas, mejor. Cuanto más grande sea el rally donde vayas, mejor. Nadie analizará 20 mil fotos manualmente. Para aquellos que se preocupan por su seguridad y privacidad, les aconsejaría que no hagan perfiles con sus imágenes.
En un mitin en una ciudad con una población número 100 mil, te encontrarán fácilmente al ver 1-2 partidos. En Moscú, se atascan un poco.
Hace aproximadamente medio año,
Vasyutka , con quien trabajamos juntos, habló sobre este tema:
Por cierto, sobre las redes sociales
Luego me permito hacer una pequeña excursión a un lado. La calidad del entrenamiento para el algoritmo de reconocimiento facial depende de tres factores:
- La calidad de la cara.
- Métrica de proximidad de personas utilizada durante el entrenamiento Pérdida de triplete, pérdida de centro, pérdida esférica, etc.
- Tamaño base
Según la reivindicación 2, parece que ahora se ha alcanzado el límite. En principio, las matemáticas se desarrollan sobre tales cosas muy rápidamente. Y después de la pérdida de triplete, el resto de las funciones de pérdida no dieron un aumento dramático, solo una mejora suave y una disminución en el tamaño de la base.
La extracción de caras es difícil si necesita encontrar caras desde todos los ángulos, ya que ha perdido una fracción de un porcentaje. Pero crear tal algoritmo es un proceso bastante predecible y bien administrado. Cuanto más azul sea todo, mejor, los ángulos grandes se procesan correctamente:

Y hace seis meses era así:

Se puede ver que cada vez más empresas se mueven lentamente de esta manera, los algoritmos comienzan a reconocer más y más caras.
Pero con el tamaño de la base, todo es más interesante. Las bases abiertas son pequeñas. Buenas bases para un máximo de un par de decenas de miles de personas. Los que son grandes son extrañamente estructurados / malos (
megaface ,
MS-Celeb-1M ).
¿Dónde crees que los creadores de los algoritmos obtuvieron estas bases de datos?
Pequeña pista. El primer producto de NTech que están implementando actualmente es Find Face, una búsqueda de personas de contacto. Creo que no se necesita explicación. Por supuesto, las peleas de contacto con bots que desinflan todos los perfiles abiertos. Pero, hasta donde oí, la gente todavía tiembla. Y compañeros de clase. E instagram.
Parece que con Facebook: todo es más complicado allí. Pero estoy casi seguro de que también se inventó algo.
Entonces, sí, si su perfil está abierto, puede estar orgulloso, se usó para aprender algoritmos;)
Sobre soluciones y sobre empresas
Aquí puedes estar orgulloso. De las 5 empresas líderes en el mundo, dos son ahora rusas. Estos son N-Tech y VisionLabs. Hace medio año, NTech y Vocord fueron los líderes, el primero funcionó mucho mejor en caras rotativas, el segundo en los frontales.
Ahora, el resto de los líderes: 1-2 empresas chinas y 1 estadounidense, Vocord aprobó algo en las calificaciones.
Todavía ruso en el ranking de itmo, 3divi, intellivision. Synesis es una empresa bielorrusa, aunque algunos estuvieron una vez en Moscú, hace unos 3 años tenían un blog sobre Habré. También conozco varias soluciones que pertenecen a compañías extranjeras, pero las oficinas de desarrollo también están en Rusia. Todavía hay varias compañías rusas que no están en la competencia, pero que parecen tener buenas soluciones. Por ejemplo, los ODM tienen. Obviamente, Odnoklassniki y Vkontakte también tienen sus propios buenos, pero son para uso interno.
En resumen, sí, nosotros y los chinos estamos mayormente desplazados en nuestras caras.
NTech en general fue el primero en el mundo en mostrar nuevos y buenos parámetros de nivel. En algún lugar a
finales de 2015 . VisionLabs se puso al día solo con NTech. En 2015, fueron líderes del mercado. Pero su solución fue de la última generación, y comenzaron a tratar de ponerse al día con NTech solo a fines de 2016.
Para ser sincero, no me gustan estas dos compañías. Comercialización muy agresiva. Vi personas que tenían una solución claramente inapropiada que no resolvía sus problemas.
De este lado, me gustó mucho más Vocord. De alguna manera, aconsejó a los muchachos a quienes Vokord dijo honestamente: "su proyecto no funcionará con tales cámaras y puntos de instalación". NTech y VisionLabs felizmente intentaron vender. Pero algo Vokord desapareció recientemente.
Conclusiones
En las conclusiones quiero decir lo siguiente. . . .
OpenSource . ( ), VisionLabs|Ntech, , . OpenSource .
, , . , . , . , . , — . - .