El reconocimiento de emociones es un tema candente en el campo de la inteligencia artificial. Las áreas más interesantes de aplicación de tales tecnologías incluyen: reconocimiento de conductores, investigación de mercado, sistemas de análisis de video para ciudades inteligentes, interacción hombre-máquina, monitoreo de estudiantes que toman cursos en línea, dispositivos portátiles, etc.
Este año, MDG dedicó su escuela de aprendizaje automático de verano a este tema. En este artículo, intentaré dar una breve excursión al problema de reconocer el estado emocional de una persona y hablar sobre los enfoques para su solución.
¿Qué son las emociones?
La emoción es un tipo especial de procesos mentales que expresan la experiencia de una persona de su relación con el mundo y consigo misma. Según una de las teorías, cuyo autor es el fisiólogo ruso P.K. Anokhin, la capacidad de experimentar emociones se desarrolló en el proceso de evolución como un medio de adaptación más exitosa de los seres vivos a las condiciones de existencia. La emoción fue útil para la supervivencia y permitió que los seres vivos respondieran rápida y económicamente a las influencias externas.
Las emociones juegan un papel muy importante en la vida humana y la comunicación interpersonal. Se pueden expresar de varias maneras: expresiones faciales, postura, reacciones motoras, voz y reacciones autónomas (frecuencia cardíaca, presión arterial, frecuencia respiratoria). Sin embargo, la cara de la persona tiene la mayor expresividad.
Cada persona expresa emociones de varias maneras diferentes. El famoso psicólogo estadounidense Paul Ekman , al estudiar el comportamiento no verbal de las tribus aisladas en Papúa Nueva Guinea en los años 70 del siglo pasado, descubrió que una serie de emociones, a saber: ira, miedo, tristeza, asco, desprecio, sorpresa y alegría son universales y pueden para ser entendido por el hombre, independientemente de su cultura.
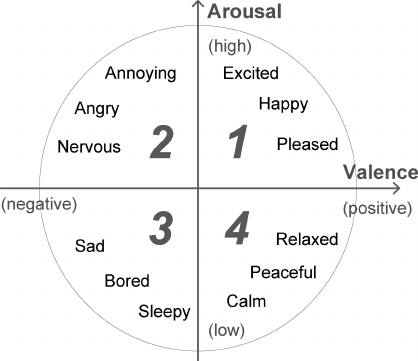
Las personas pueden expresar una amplia gama de emociones. Se cree que pueden describirse como una combinación de emociones básicas (por ejemplo, la nostalgia es algo entre tristeza y alegría). Pero un enfoque tan categórico no siempre es conveniente, porque no permite cuantificar el poder de la emoción. Por lo tanto, junto con modelos discretos de emociones, se desarrollaron varios continuos. El modelo de J. Russell tiene una base bidimensional en la que cada emoción se caracteriza por un signo (valencia) e intensidad (excitación). Debido a su simplicidad, el modelo Russell se ha vuelto cada vez más popular en el contexto de la tarea de clasificar automáticamente las expresiones faciales.
Entonces, descubrimos que si no está tratando de ocultar la excitación emocional, su estado actual puede estimarse mediante expresiones faciales. Además, utilizando los logros modernos en el campo del aprendizaje profundo, incluso es posible construir un detector de mentiras basado en la serie "Lie to me", cuya base científica fue proporcionada directamente por Paul Ekman. Sin embargo, esta tarea está lejos de ser simple. Como mostraron los estudios de la neurocientífica Lisa Feldman Barrett, al reconocer las emociones, una persona usa activamente información contextual: voz, acciones, situación. Echa un vistazo a las fotos a continuación, realmente lo es. Usando solo el área de la cara, es imposible hacer una predicción correcta. En este sentido, para resolver este problema, es necesario utilizar tanto modalidades adicionales como información sobre cambios en las señales a lo largo del tiempo.

Aquí consideraremos enfoques para el análisis de solo dos modalidades: audio y video, ya que estas señales pueden obtenerse sin contacto. Para abordar la tarea, primero necesita obtener los datos. Aquí hay una lista de las bases de datos de emociones más grandes disponibles públicamente que conozco. Las imágenes y videos en estas bases de datos fueron etiquetados manualmente, algunos usando Amazon Mechanical Turk.
El enfoque clásico de la clasificación de las emociones.
La forma más fácil de determinar la emoción a partir de una imagen facial se basa en la clasificación de puntos clave (puntos de referencia faciales), cuyas coordenadas se pueden obtener utilizando varios algoritmos PDM , CML , AAM , DPM o CNN . Por lo general, marque de 5 a 68 puntos, atándolos a la posición de las cejas, ojos, labios, nariz, mandíbula, lo que le permite capturar parcialmente las expresiones faciales. Las coordenadas normalizadas de puntos se pueden enviar directamente al clasificador (por ejemplo, SVM o Bosque aleatorio) y obtener una solución básica. Naturalmente, la posición de las personas debe estar alineada.

El uso simple de coordenadas sin un componente visual conduce a una pérdida significativa de información útil, por lo tanto, se calculan varios descriptores en estos puntos para mejorar el sistema: LBP , HOG , SIFT , LATCH , etc. Después de que los descriptores se concatenan y la dimensión se reduce usando PCA, el vector de características resultante se puede usar para la clasificación emociones
enlace al artículo
Sin embargo, este enfoque ya se considera obsoleto, ya que se sabe que las redes de convolución profunda son la mejor opción para el análisis de datos visuales.
Clasificación de las emociones mediante el aprendizaje profundo.
Para construir un clasificador de red neuronal, es suficiente tomar alguna red con una arquitectura básica, previamente entrenada en ImageNet, y volver a entrenar las últimas capas. Por lo tanto, puede obtener una buena solución básica para clasificar diversos datos, pero teniendo en cuenta los detalles de la tarea, las redes neuronales utilizadas para tareas de reconocimiento facial a gran escala serán más adecuadas.
Por lo tanto, es bastante simple construir un clasificador de emociones para imágenes individuales, pero como descubrimos, las instantáneas no reflejan con precisión las verdaderas emociones que experimenta una persona en una situación dada. Por lo tanto, para aumentar la precisión del sistema, es necesario analizar la secuencia de cuadros. Hay dos formas de hacer esto. La primera forma es alimentar las características de alto nivel recibidas de una CNN que clasifica cada trama individual en una red recurrente (por ejemplo, LSTM) para capturar el componente de tiempo.
enlace al artículo
La segunda forma es alimentar directamente una secuencia de cuadros tomados del video en algunos pasos a la entrada 3D-CNN. CNN similares utilizan convoluciones con tres grados de libertad que transforman la entrada de cuatro dimensiones en mapas de características tridimensionales.
enlace al artículo
De hecho, en el caso general, estos dos enfoques se pueden combinar construyendo tal monstruo.
enlace al artículo
Clasificación del discurso de las emociones.
Según los datos visuales, el signo de la emoción se puede predecir con gran precisión, pero es preferible utilizar señales de voz al determinar la intensidad. Analizar el audio es un poco más difícil debido a la alta variabilidad de la duración del discurso y las voces de los hablantes. Por lo general, no utilizan la onda de sonido original, sino varios conjuntos de atributos , por ejemplo: F0, MFCC, LPC, i-vectors, etc. En el problema de reconocer las emociones por el habla, la biblioteca abierta OpenSMILE tiene una buena reputación . Contiene un rico conjunto de algoritmos para analizar el habla y la música. señales Después de la extracción, los atributos se pueden enviar a SVM o LSTM para su clasificación.
Recientemente, sin embargo, las redes neuronales convolucionales también han comenzado a penetrar en el campo del análisis de sonido, desplazando los enfoques establecidos. Para aplicarlos, el sonido se representa en forma de espectrogramas en una escala lineal o mel, después de lo cual se operan con los espectrogramas obtenidos como con imágenes bidimensionales ordinarias. En este caso, el problema de un tamaño arbitrario de espectrogramas a lo largo del eje del tiempo se resuelve de manera elegante mediante la agrupación estadística o mediante la incorporación de una red recurrente en la arquitectura.
enlace al artículo
Reconocimiento audiovisual de las emociones.
Entonces, examinamos una serie de enfoques para el análisis de las modalidades de audio y video, la etapa final permaneció: la combinación de clasificadores para generar la solución final. La forma más simple es combinar directamente sus calificaciones. En este caso, es suficiente para tomar el máximo o el promedio. Una opción más difícil es combinar a nivel de incrustación para cada modalidad. A menudo se usa SVM para esto, pero esto no siempre es correcto, ya que las incorporaciones pueden tener una velocidad diferente. En este sentido, se desarrollaron algoritmos más avanzados, por ejemplo: Aprendizaje de kernel múltiple y ModDrop .
Y, por supuesto, vale la pena mencionar la clase de las llamadas soluciones de extremo a extremo que se pueden entrenar directamente en datos sin procesar de varios sensores sin ningún procesamiento preliminar.
En general, la tarea del reconocimiento automático de las emociones aún está lejos de resolverse. A juzgar por los resultados del concurso Emotion Recognition in the Wild del año pasado, las mejores soluciones alcanzan una precisión de aproximadamente el 60%. Espero que la información presentada en este artículo sea suficiente para tratar de construir nuestro propio sistema para reconocer las emociones.