Ya escribimos en el
primer artículo de nuestro blog corporativo sobre cómo funciona el algoritmo para detectar préstamos transferibles. Solo un par de párrafos en ese artículo están dedicados al tema de comparar textos, aunque la idea merece una descripción mucho más detallada. Sin embargo, como saben, no se puede contar de inmediato sobre todo, aunque realmente se quiere. En un intento de rendir homenaje a este tema y a la arquitectura de la red llamada "
auto-encoder ", con la que tenemos sentimientos muy cálidos,
Oleg_Bakhteev y yo escribimos esta reseña.

Fuente:
Deep Learning para PNL (sin magia)Como mencionamos en ese artículo, la comparación de textos fue "semántica": no comparamos los fragmentos de texto en sí, sino los vectores correspondientes a ellos. Dichos vectores se obtuvieron como resultado del entrenamiento de una red neuronal, que mostraba un fragmento de texto de una longitud arbitraria en un vector de una dimensión grande pero fija. Cómo obtener un mapeo de este tipo y cómo enseñar a la red a producir los resultados deseados es un tema separado, que se discutirá a continuación.
¿Qué es un codificador automático?
Formalmente, una red neuronal se denomina codificador automático (o codificador automático), que se entrena para restaurar los objetos recibidos en la entrada de la red.
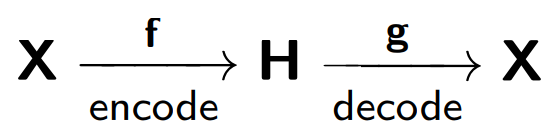
El codificador automático consta de dos partes: un codificador
f , que codifica la muestra
X en su representación interna
H , y un decodificador
g , que restaura la muestra original. Por lo tanto, el codificador automático intenta combinar la versión restaurada de cada objeto de muestra con el objeto original.
Al entrenar un codificador automático, se minimiza la siguiente función:
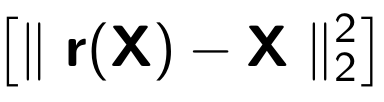
Donde
r representa la versión restaurada del objeto original:

Considere el ejemplo proporcionado en
blog.keras.io :

La red recibe un objeto
x como entrada (en nuestro caso, el número 2).
Nuestra red codifica este objeto en un estado oculto. Luego, de acuerdo con el estado latente, se restaura la reconstrucción del objeto
r , que debería ser similar a x. Como vemos, la imagen restaurada (a la derecha) se ha vuelto más borrosa. Esto se explica por el hecho de que tratamos de mantener en una vista oculta solo los signos más importantes del objeto, por lo que el objeto se restaura con pérdidas.
El modelo de autocodificador está entrenado sobre el principio de un teléfono dañado, donde una persona (codificador) transmite información
(x ) a la segunda persona (decodificador
) , y él, a su vez, le dice a la tercera
(r (x)) .
Uno de los propósitos principales de tales codificadores automáticos es reducir la dimensión del espacio fuente. Cuando se trata de codificadores automáticos, el procedimiento de entrenamiento de la red neuronal hace que el codificador automático recuerde las características principales de los objetos a partir de los cuales será más fácil restaurar los objetos de muestra originales.
Aquí podemos hacer una analogía con el
método de los componentes principales : este es un método para reducir la dimensión, cuyo resultado es la proyección de la muestra en un subespacio en el que la varianza de esta muestra es máxima.
De hecho, el codificador automático es una generalización del método del componente principal: en el caso de que nos limitemos a la consideración de modelos lineales, el codificador automático y el método del componente principal dan las mismas representaciones vectoriales. La diferencia surge cuando consideramos modelos más complejos, por ejemplo, redes neuronales multicapa totalmente conectadas, como codificador y decodificador.
En el artículo
Reducción de la dimensionalidad de los datos con redes neuronales se presenta un ejemplo de una comparación del método del componente principal y el codificador automático:
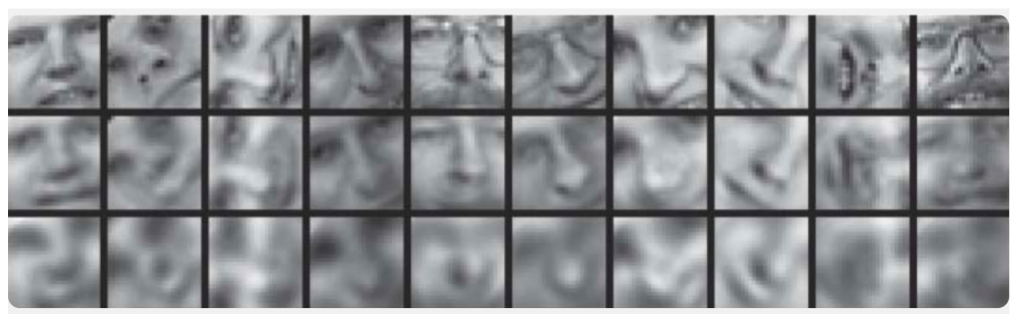
Aquí, se muestran los resultados del entrenamiento del codificador automático y el método del componente principal para muestrear imágenes de rostros humanos. La primera línea muestra las caras de las personas de la muestra de control, es decir. de una parte especialmente diferida de la muestra que no fue utilizada por los algoritmos en el proceso de aprendizaje. En la segunda y tercera líneas se encuentran las imágenes restauradas de los estados ocultos del codificador automático y el método del componente principal, respectivamente, de la misma dimensión. Aquí puede ver claramente cuánto mejor funcionó el codificador automático.
En el mismo artículo, otro ejemplo ilustrativo: una comparación de los resultados del codificador automático y el método
LSA para la tarea de búsqueda de información. El método LSA, como el método del componente principal, es un método clásico de aprendizaje automático y a menudo se usa en tareas relacionadas con el procesamiento del lenguaje natural.

La figura muestra una proyección 2D de múltiples documentos obtenidos usando el codificador automático y el método LSA. Los colores indican el tema del documento. Se puede ver que la proyección del codificador automático desglosa bien los documentos por tema, mientras que el LSA produce un resultado mucho más ruidoso.
Otra aplicación importante de los
codificadores automáticos
es la formación previa en red . El entrenamiento previo de la red se utiliza cuando la red optimizada es lo suficientemente profunda. En este caso, entrenar la red "desde cero" puede ser bastante difícil, por lo tanto, primero toda la red se representa como una cadena de codificadores.
El algoritmo de pre-entrenamiento es bastante simple: para cada capa entrenamos nuestro propio codificador automático, y luego establecemos que la salida del siguiente codificador es simultáneamente la entrada para la siguiente capa de red. El modelo resultante consiste en una cadena de codificadores entrenados para preservar con entusiasmo las características más importantes de los objetos, cada uno en su propia capa. El esquema de pre-entrenamiento se presenta a continuación:
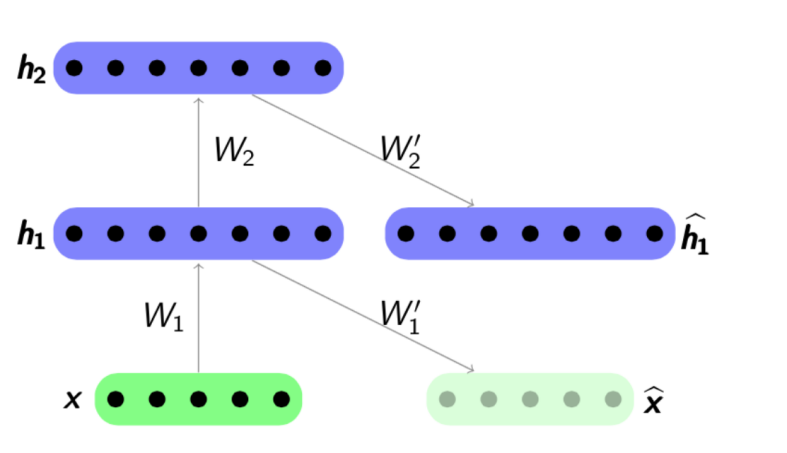
Fuente:
psyyz10.imtqy.comEsta estructura se llama Autoencoder apilado y a menudo se usa como "overclocking" para entrenar aún más el modelo de red profunda completo. La motivación para tal entrenamiento de una red neuronal es que una red neuronal profunda es una función no convexa: en el proceso de entrenamiento de una red, la optimización de los parámetros puede "estancarse" en un mínimo local. El preentrenamiento codicioso de los parámetros de red le permite encontrar un buen punto de partida para el entrenamiento final y, por lo tanto, tratar de evitar tales mínimos locales.
Por supuesto, no consideramos todas las estructuras posibles, porque hay
autoencoders dispersos ,
autoencoders denoising ,
autoencoder contractivo ,
autoencoder contractivo de reconstrucción . Se diferencian entre sí al usar varias funciones de error y términos de penalización. Todas estas arquitecturas, en nuestra opinión, merecen una revisión por separado. En nuestro artículo, mostramos, en primer lugar, el concepto general de codificadores automáticos y aquellas tareas específicas de análisis de texto que se resuelven al usarlo.
¿Cómo funciona en textos?
Ahora pasamos a ejemplos específicos del uso de autocodificadores para tareas de análisis de texto. Estamos interesados en ambos lados de la aplicación, ambos modelos para obtener representaciones internas y el uso de estas representaciones internas como atributos, por ejemplo, en el problema de clasificación adicional. Los artículos sobre este tema a menudo abordan tareas como el análisis de sentimientos o la detección de reformulación, pero también hay trabajos que describen el uso de codificadores automáticos para comparar textos en diferentes idiomas o para traducción automática.
En las tareas de análisis de texto, con mayor frecuencia el objeto es la oración, es decir. secuencia ordenada de palabras. Por lo tanto, el codificador automático recibe exactamente esta secuencia de palabras, o más bien, representaciones vectoriales de estas palabras tomadas de algún modelo previamente entrenado. En cuanto a las representaciones vectoriales de palabras, se consideró en Habré con suficiente detalle, por ejemplo
aquí . Por lo tanto, el codificador automático, tomando una secuencia de palabras como entrada, debe entrenar alguna representación interna de la oración completa que cumpla con las características que son importantes para nosotros, en función de la tarea. En problemas de análisis de texto, necesitamos mapear oraciones a vectores para que estén cerca en el sentido de alguna función de distancia, más a menudo una medida de coseno:
Fuente:
Deep Learning para PNL (sin magia)Uno de los primeros autores en mostrar el uso exitoso de los codificadores automáticos en el análisis de texto fue
Richard Socher .
En su artículo
Agrupación dinámica y despliegue de codificadores automáticos recursivos para la detección de paráfrasis, describe una nueva estructura de codificación automática: desplegar codificador automático recursivo (desplegar RAE) (ver la figura a continuación).

Desplegando RAE
Se supone que la estructura de la oración está definida por un
analizador sintáctico . Se considera la estructura más simple: la estructura de un árbol binario. Tal árbol consiste en hojas, palabras de un fragmento, nodos internos (nodos de rama), frases y un vértice terminal. Tomando la secuencia de palabras (x
1 , x
2 , x
3 ) como entrada (tres representaciones vectoriales de palabras en este ejemplo), el autocodificador codifica secuencialmente, en este caso, de derecha a izquierda, representaciones vectoriales de palabras de oración en representaciones vectoriales de frases, y luego en vector Presentación de toda la oferta. Específicamente, en este ejemplo, primero concatenamos los vectores x
2 yx
3 , luego los multiplicamos por la matriz donde
tenemos la dimensión
oculta × 2 visible , donde
oculto es donde está el tamaño de la representación interna oculta,
visible es la dimensión de la palabra vector. Por lo tanto, reducimos la dimensión, luego agregamos no linealidad utilizando la función tanh. En el primer paso, obtenemos una representación vectorial oculta para la frase dos palabras
x 2 y
x 3 :
h 1 =
tanh (W e [x 2 , x 3 ] + b e ) . En el segundo, lo combinamos y la palabra restante
h 2 =
tanh (W e [h 1 , x 1 ] + b e ) y obtenemos una representación vectorial para toda la oración -
h 2 . Como se mencionó anteriormente, en la definición de un codificador automático, debemos minimizar el error entre los objetos y sus versiones restauradas. En nuestro caso, estas son palabras. Por lo tanto, habiendo recibido la representación vectorial final de toda la oración
h 2 , decodificaremos sus versiones restauradas (x
1 ', x
2 ', x
3 '). El decodificador aquí funciona según el mismo principio que el codificador, solo la matriz de parámetros y el vector de desplazamiento son diferentes aquí:
W d y
b d .
Usando la estructura de un árbol binario, es posible codificar oraciones de cualquier longitud en un vector de dimensión fija: siempre combinamos un par de vectores de la misma dimensión, usando la misma matriz de parámetros
W e . En el caso de un árbol no binario, solo necesita inicializar las matrices de antemano si queremos combinar más de dos palabras: 3, 4, ... n, en este caso la matriz tendrá la dimensión
oculta × invisible .
Es de destacar que en este artículo, las representaciones vectoriales formadas de frases se utilizan no solo para resolver el problema de clasificación, sino que se reformulan un par de oraciones. También se presentan los datos de un experimento sobre la búsqueda de los vecinos más cercanos: según el vector de oferta recibido, se buscan los vectores más cercanos de la muestra que tengan un significado cercano:

Sin embargo, nadie nos molesta para usar otras arquitecturas de red para codificar y decodificar para combinar secuencialmente palabras en oraciones.
Aquí hay un ejemplo de un artículo de NIPS 2017 -
Aprendizaje de representación de párrafos desconvolucional :

Vemos que la codificación de la muestra
X en la representación oculta
h ocurre usando una
red neuronal convolucional , y el decodificador funciona con el mismo principio.
O aquí hay un ejemplo usando
GRU-GRU en el artículo de
Skip-Thought Vectors .
Una característica interesante aquí es que el modelo funciona con triples de oraciones: (
s i-1 , s i , s i + 1 ). La oración
s i se codifica usando fórmulas GRU estándar, y el decodificador, usando la información de representación interna
s i , intenta decodificar
s i-1 y
s i + 1 , también usando GRU.

El principio de funcionamiento en este caso se asemeja al modelo estándar de
traducción automática de redes neuronales , que funciona de acuerdo con el esquema codificador-decodificador. Sin embargo, aquí no tenemos dos idiomas, enviamos una frase en un idioma a la entrada de nuestra unidad de codificación e intentamos restaurarla. En el proceso de aprendizaje, hay una minimización de algunas funciones internas de calidad (esto no siempre es un error de reconstrucción), luego, si es necesario, los vectores previamente entrenados se utilizan como características en otro problema.
Otro artículo,
Autoencoders recursivos bilingües por correspondencia para la traducción automática estadística , presenta una arquitectura que da una nueva mirada a la traducción automática. Primero, para dos idiomas, los codificadores automáticos recursivos se entrenan por separado (de acuerdo con el principio descrito anteriormente, donde se introdujo el Desplegamiento RAE). Luego, entre ellos, se entrena un tercer codificador automático: un mapeo entre dos idiomas. Dicha arquitectura tiene una clara ventaja: al mostrar textos en diferentes idiomas en un espacio oculto común, podemos compararlos sin utilizar la traducción automática como un paso intermedio.
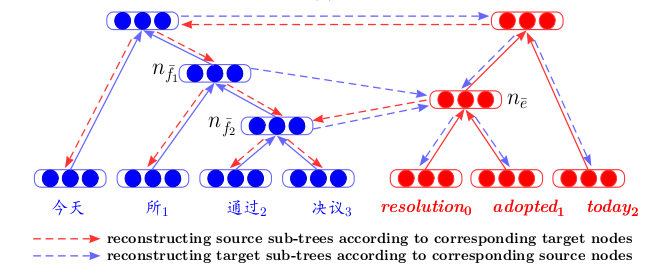
La capacitación de codificadores automáticos en fragmentos de texto a menudo se encuentra en artículos sobre
capacitación en
clasificación . Aquí, nuevamente, el hecho de que estamos entrenando el funcional final de la calidad de la clasificación es importante, primero entrenamos previamente el codificador automático para inicializar mejor los vectores de solicitudes y respuestas enviadas a la entrada de la red.

Y, por supuesto, no podemos dejar de mencionar los
Autoencoders Variacionales , o
VAE , como modelos generativos. Es mejor, por supuesto, ver
esta entrada de la conferencia de Yandex . Es suficiente para nosotros decir lo siguiente: si queremos
generar objetos desde el espacio oculto de un codificador automático convencional, entonces la calidad de dicha generación será baja, ya que no sabemos nada sobre la distribución de la variable oculta. Pero puede entrenar inmediatamente al codificador automático para generar, introduciendo un supuesto de distribución.
Y luego, usando VAE, puede generar textos desde este espacio oculto, por ejemplo, como lo hacen los autores del artículo
Generando oraciones desde un espacio continuo o
un autoencoder variacional convolucional híbrido para la generación de texto .
Las propiedades generativas de VAE también funcionan bien en tareas que comparan textos en diferentes idiomas:
un enfoque de codificación automática variacional para inducir incrustaciones de palabras en varios idiomas
es un excelente ejemplo de esto.
Como conclusión, queremos hacer un pequeño pronóstico.
El aprendizaje de representación : la capacitación en representaciones internas utilizando exactamente VAE, especialmente en conjunto con las
Redes adversarias generativas , es uno de los enfoques más desarrollados en los últimos años; esto se puede juzgar por al menos los temas más frecuentes de los artículos en las últimas
conferencias principales de aprendizaje automático
ICLR 2018 e
ICML 2018 . Esto es bastante lógico, porque su uso ha ayudado a mejorar la calidad en una serie de tareas, y no solo en relación con los textos. Pero este es el tema de una revisión completamente diferente ...