Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3Lección 4: “Separación de privilegios”
Parte 1 /
Parte 2 /
Parte 3 Entonces, ¿qué más teníamos en esta lista? Procesos La memoria es algo que sucede simultáneamente con el proceso. Por lo tanto, si no está en este proceso, no puede acceder a su memoria. La memoria virtual mejora perfectamente este aislamiento para nosotros. Además, el mecanismo de depuración le permite "aparecer" en la memoria de otro proceso, si tiene la misma ID de usuario
A continuación tenemos la red. Las redes en
Unix no se corresponden exactamente con el modelo descrito anteriormente, en parte debido al hecho de que el
sistema operativo
Unix se desarrolló por primera vez, y luego apareció una red, que pronto se hizo popular. Tiene un conjunto de reglas ligeramente diferente. Por lo tanto, las operaciones de las que realmente debemos ocuparnos son conectar a alguien a la red si administra la red o escuchar algún puerto si actúa como servidor. Es posible que deba leer o escribir datos en esta conexión, o enviar y recibir paquetes
sin formato.

Por lo tanto, las redes en
Unix no están relacionadas con el
ID de
usuario . Las reglas son que cualquiera siempre puede conectarse a cualquier máquina o cualquier dirección IP o abrir una conexión. Si desea escuchar en un puerto, entonces en este caso hay una diferencia, que es que la mayoría de los usuarios tienen prohibido escuchar puertos con un número inferior al "valor mágico" de 1024. En principio, puede escuchar dichos puertos, pero en este caso debe Sea un usuario especial llamado
"superusuario" con
uid = 0 .
En general, en Unix existe el concepto de administrador, o superusuario, que está representado por el identificador uid = 0, que puede omitir casi todas estas comprobaciones, por lo que si trabaja con derechos de root, puede leer y escribir archivos, cambiar los derechos de acceso a ellos. El sistema operativo le permitirá hacer esto porque cree que debe tener todos los privilegios. Y realmente necesita esos privilegios para escuchar en los puertos con el número <1024. ¿Qué le parece una restricción tan extraña?
Audiencia: identifica números de puerto específicos para conexiones específicas, por ejemplo, para
http en el puerto 80.
Profesor: sí, por defecto, el
protocolo HTTP usa el puerto 80. Por otro lado, otros servicios pueden usar puertos con un número superior a 1024, ¿por qué es necesaria esta restricción? ¿Cuál es el uso aquí?
Público: porque no desea que nadie escuche accidentalmente su
HTTP .
Profesor: si. Creo que la razón de esto es que solía tener muchos usuarios en la misma máquina. Iniciaron sesión con sus inicios de sesión, lanzaron sus aplicaciones, por lo que querían asegurarse de que algún usuario aleatorio, después de haber iniciado sesión en la computadora, no pudiera obtener el servidor web que se ejecuta en él. Debido a que los usuarios que se conectan desde el exterior no saben quién trabaja en este puerto, y simplemente se conectan al puerto 80. Si quiero ingresar a esta máquina e iniciar mi propio servidor web, simplemente transfiero todo el tráfico del servidor web a este auto Probablemente este no sea un plan muy bueno, pero es la forma en que el subsistema de red Unix evita que usuarios aleatorios controlen servicios conocidos que se ejecutan en estos números de puerto bajos. Esa es la razón de tal limitación.

Además, desde el punto de vista de leer y escribir datos de conexión, si tiene un archivo descriptor para un socket específico,
Unix le permitirá leer y escribir cualquier dato en esta
conexión TCP o
uTP . Al enviar paquetes sin
procesar ,
Unix se comporta como un paranoico, por lo que no le permitirá enviar paquetes arbitrarios a través de la red. Esto debe estar dentro del contexto de la conexión especial, a menos que tenga
root, el derecho y puede hacer lo que quiera.
Entonces, una pregunta interesante que podrías hacer es ¿de dónde vienen todos estos
ID de usuario ?
Estamos hablando de procesos que tienen
ID de usuario o
ID de grupo . Cuando inicie
PS en su computadora, definitivamente verá una serie de procesos con diferentes valores de
uid . ¿De dónde vinieron?
Necesitamos algún mecanismo para cargar todos estos valores de
ID de
usuario .
Unix tiene varias llamadas al sistema diseñadas para esto. Por lo tanto, para arrancar estos valores de identificador, hay una función llamada
setuid (uid) , por lo que puede asignar el número
uid de algún proceso actual a este valor. Esta es en realidad una operación peligrosa, como todo lo demás en la tradición de
Unix , porque solo puede hacer esto si su
uid = 0 . En cualquier caso, debería ser así.
Por lo tanto, si es un usuario con derechos de root y tiene
uid = 0 , puede llamar a
setuid (uid) y cambiar el usuario a cualquier proceso. Hay un par de otras llamadas de sistema similares para inicializar
gid relacionado con el proceso: estos son
setgid y
setgroups . Por lo tanto, estas llamadas al sistema le permiten configurar privilegios de proceso.

El hecho de que sus procesos obtengan los derechos de acceso correctos cuando inicia sesión en la máquina
Unix no sucede porque tiene la misma
ID que los procesos, porque el sistema aún no sabe quién es usted. En cambio, en
Unix, hay algún tipo de procedimiento de inicio de sesión cuando el
protocolo de shell seguro
SSH inicia el proceso para cualquier persona que se conecte a la computadora e intente autenticar al usuario.
Por lo tanto, inicialmente este proceso de inicio de sesión comienza con
uid = 0 como para un usuario con derechos de root, y luego, cuando recibe un nombre de usuario y contraseña específicos, los verifica en su propia base de datos de cuentas. Como regla general, en
Unix, estos datos se almacenan en dos archivos:
/ etc / password (por razones históricas, las contraseñas ya no se almacenan en este archivo), y en el
archivo / etc / shadow , en el que se almacenan las contraseñas. Sin embargo, hay una tabla en el
archivo / etc / password que muestra cada nombre de usuario en el sistema como un valor entero.
Por lo tanto, su nombre de usuario se asigna a un entero específico en este
archivo / etc / password , y luego el proceso de inicio de sesión verifica si su contraseña es correcta de acuerdo con este archivo. Si encuentra su número entero
uid , establece las funciones
setuid en ese valor
uid e inicia el shell con el comando
exec (/ bin / sh) . Ahora puede interactuar con el shell, pero funciona debajo de su
uid , por lo que no podrá causar daños accidentales a esta máquina.
 Público: ¿es
Público: ¿es posible comenzar un nuevo proceso con
uid = 0 si su
uid no es realmente 0?
Profesor: si tiene privilegios de root, puede limitarse a otro
uid , disminuir su autoridad, pero en cualquier caso, puede crear un proceso con solo el mismo
uid que el suyo. Pero sucede que por varias razones desea aumentar sus privilegios. Suponga que necesita instalar un paquete, para el cual necesita privilegios de
root .
Hay dos formas de establecer privilegios en
Unix . Uno que ya mencionamos es un descriptor de archivo. Entonces, si realmente desea aumentar sus privilegios, puede hablar con alguien que trabaje bajo los derechos de root y pedirle que abra este archivo por usted. O necesita instalar una nueva interfaz, entonces este asistente abre un archivo para usted y le devuelve un descriptor de archivo mediante la transferencia
fd . Esta es una forma de aumentar sus privilegios, pero es inconveniente porque en algunos casos hay procesos que se ejecutan con una gran cantidad de privilegios. Para esto,
Unix tiene un mecanismo inteligente pero al mismo tiempo problemático llamado
"binarios setuid" . Este mecanismo son ejecutables regulares en un
sistema de archivos
Unix , excepto cuando ejecuta
exec en el binario
setuid , por ejemplo,
/ bin / su en la mayoría de las máquinas, o
sudo , al inicio.
Un
sistema típico de
Unix tiene un montón de binarios
setuid . La diferencia es que cuando ejecuta uno de estos binarios, en realidad cambia el
ID de usuario del proceso al propietario de este binario. Este mecanismo parece extraño cuando lo ves por primera vez. Como regla general, las formas de usarlo son que este "binario" probablemente tenga un
uid de propietario
de 0, porque realmente desea restaurar muchos privilegios.

Desea restaurar los derechos de superusuario para poder ejecutar este comando
su , y el núcleo, cuando ejecute este binario, cambiará el
uid del proceso a 0, de modo que este programa ahora realizará algunas cosas privilegiadas.
Público: si tiene
uid = 0 y cambia el
uid de todos estos binarios
setuid a algo distinto de 0, ¿puede restaurar sus privilegios?
Profesor: no, muchos procesos no podrán restaurar los privilegios al reducir el nivel de acceso, por lo que puede estar atrapado en este lugar. Este mecanismo no está vinculado a
uid = 0 . Al igual que cualquier usuario de un sistema
Unix , puede crear cualquier archivo binario, construir un programa, compilarlo y establecer este bit
setuid en el programa mismo. Le pertenece a usted, el usuario, su ID de usuario. Y eso significa que cualquiera que ejecute su programa ejecutará este código con su ID de usuario. ¿Hay algún problema con esto? ¿Qué hay que hacer?
Público: es decir, si hubo un error en su solicitud, ¿podría alguien hacer algo al respecto, actuando con sus privilegios?
Profesor: claro, sucede si mi aplicación tiene "errores" o si te permite ejecutar todo lo que quieras. Supongamos que puedo copiar el shell del sistema y configurarlo para mí, pero luego cualquiera puede ejecutar este shell en mi cuenta. Probablemente este no sea el mejor plan de acción. Pero dicho mecanismo no crea un problema, porque la única persona que puede establecer el bit
setuid en un archivo binario es el propietario de este archivo. Usted, como propietario del archivo, tiene el privilegio
uid , por lo que puede transferir su cuenta a otra persona, pero esta otra persona no podrá crear el binario
setuid con su
ID de usuario .
Este bit setuid se almacena junto a estos bits de permiso, es decir, en cada
inodo también hay un bit
setuid que dice si este archivo ejecutable debería o si el programa cambió al
uid del propietario durante la ejecución.
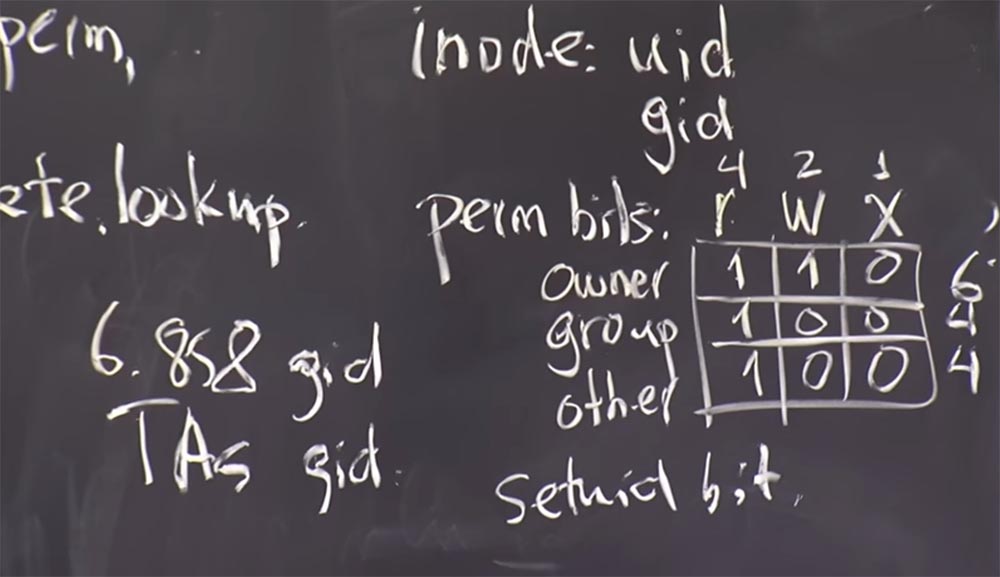
Resulta que este es un mecanismo muy complicado cuando se usa correctamente, y gracias a él, el núcleo implementa el programa correctamente. En realidad, esto es bastante fácil de hacer, porque solo se realiza una comprobación: si existe este bit
setuid , entonces el proceso cambia a
uid . Es bastante simple
Pero usarlo de manera segura es bastante difícil porque, como se acaba de indicar, si este programa contiene errores o hace algo inesperado, entonces puede hacer cosas arbitrarias bajo
uid = 0 o bajo cualquier otro
uid . En
Unix, cuando ejecuta un programa, hereda muchas cosas de su proceso principal.
Por ejemplo, puede pasar variables de entorno a binarios
setuid . El hecho es que en
Unix puede especificar qué biblioteca compartida usar para el proceso configurando la variable de entorno, y los binarios
setuid no se preocupan por filtrar estas variables de entorno.
Por ejemplo, puede ejecutar
bin / su , pero usar bibliotecas compartidas para la función
printf , por lo que su
printf se iniciará cuando
bin / su imprima algo, y puede ejecutar el shell en lugar de
printf .
Hay muchas sutilezas que debe comprender correctamente con respecto a la desconfianza del programa a los datos que ingresa el usuario. Debido a que generalmente confía en la entrada del usuario,
setuid nunca ha sido la parte más segura de un sistema
Unix completo. ¿Tienes preguntas sobre esto?
Público: ¿
setuid también se aplica a grupos o solo al usuario?
Profesor: hay un bit
setgid simétrico al bit
setuid , que también puede configurar. Si el archivo tiene un
gid específico y este bit
setgid se establece cuando se inicia el programa, lo obtendrá.
Setgid no se usa particularmente, pero puede ser útil en los casos en que desea proporcionar privilegios muy específicos. Por ejemplo,
bin / su probablemente necesita muchos privilegios, pero quizás haya algún programa que necesite algunos privilegios adicionales, por ejemplo, para escribir algo en un archivo de registro especial. Por lo tanto, es probable que desee proporcionarle un determinado grupo y crear un archivo de registro para ella que este grupo pueda escribir. Entonces, incluso si el programa tiene "errores", entonces no perderá nada más que este grupo. Esto es útil como un mecanismo que por alguna razón no se usa con demasiada frecuencia, porque después de todo, las personas deberían usar más los derechos de root.
Audiencia: ¿Existen restricciones sobre quién puede cambiar el acceso?
Profesor: si. Las diferentes implementaciones de
Unix tienen diferentes controles para esto. La regla general es que solo la raíz puede cambiar el propietario del archivo, porque no desea crear archivos que pertenezcan a otra persona y, por supuesto, no desea apropiarse de los archivos de otras personas. Entonces, si su
uid no
es 0, entonces está atascado. No puede cambiar la propiedad de ningún archivo. Si su
uid = 0 , tiene privilegios de root y puede cambiar el propietario a cualquiera. Hay algunas complicaciones si tiene un
setuid binario y cambia de un
uid a otro, esto es bastante complicado, pero básicamente no puede cambiar el propietario del archivo si no tiene privilegios de root.
Por todas las cuentas, este es un sistema un poco desactualizado. Probablemente podría imaginar muchas formas de simplificar los procesos descritos anteriormente, pero de hecho, los sistemas más avanzados se ven así porque evolucionan con el tiempo. Pero puede utilizar perfectamente estos mecanismos como "caja de arena".
Estos son solo una especie de principios básicos de
Unix , que aparecen en casi todos los sistemas operativos tipo Unix:
Mac OS X ,
Linux ,
FreeBSD ,
Solaris , si alguien más lo usa, y así sucesivamente. Pero cada uno de estos sistemas tiene mecanismos más sofisticados que podría utilizar. Por ejemplo, en
Linux hay un conjunto de "sandbox"
COMP ,
Mac OS X usa el cinturón de
seguridad "sandbox". La próxima semana le daré ejemplos de sandboxes disponibles en todos los sistemas basados en
Unix .
Entonces, uno de los últimos mecanismos, que consideraremos antes de sumergirnos en
OKWS , explica cómo debe lidiar con los binarios
setuid y muestra cómo puede protegerse de los agujeros de seguridad existentes. El problema es que inevitablemente tendrá algunos binarios
setuid en su sistema, como
/ bin / su , o
sudo , o algo más, y es probable que sus programas tengan errores. Debido a esto, alguien podrá ejecutar el binario
setuid y el proceso podrá obtener acceso a la
raíz , lo que no desea permitir.

El mecanismo de
Unix , que a menudo se usa para evitar la ejecución de un proceso potencialmente malicioso usando binarios
setuid , es usar el espacio de nombres del sistema de archivos para cambiarlo usando la llamada al sistema
chroot , la operación de cambiar el directorio raíz.
OKWS , como servidor web especializado en la creación de servicios web rápidos y seguros, lo utiliza ampliamente.

Entonces, en
Unix, puede ejecutar
chroot en un directorio específico, por lo que quizás también pueda ejecutar
chroot ("/ foo") .
Hay 2 explicaciones de lo que hace
chroot . El primero es simplemente intuitivo, significa que después de ejecutar
chroot , el directorio raíz o el directorio ubicado detrás de la barra es básicamente equivalente a lo que
/ foo usó antes de llamar a
chroot . Parece limitar el espacio de nombres debajo de tu
/ foo . Por lo tanto, si tiene un archivo que solía llamarse
/ foo / x , luego de llamar a
chroot, puede obtener este archivo simplemente abriendo
/ x . Tan solo limite su espacio de nombres a un subdirectorio. Aquí está la versión intuitiva.

Por supuesto, en seguridad, no es la versión intuitiva lo que importa, pero ¿qué hace exactamente el núcleo con esta llamada del sistema? Y hace básicamente dos cosas. En primer lugar, cambia el valor de esta barra oblicua, por lo que cada vez que accede o cuando inicia el nombre del directorio con una barra oblicua, el núcleo incluye cualquier archivo que proporcionó con las operaciones
chroot . En nuestro ejemplo, este es el archivo
/ foo antes de llamar a
chroot , es decir, obtenemos ese
/ = / foo .

Lo siguiente que intentará hacer el núcleo es protegerlo de poder "escapar" de su
/ si lo hace
/../ . Porque en
Unix, podría pedirte que me des, por ejemplo,
/../etc/password . Entonces, si acabo de complementar esta línea de esta manera:
/foo/../etc/password , eso no sería bueno, porque podría simplemente salir
/ foo y obtener
/ etc / contraseña .
La segunda cosa que hace el núcleo con una llamada al sistema
Unix es que cuando llama a
chroot para este proceso en particular, cambia la forma en que
/../ se evalúa en este directorio. Por lo tanto, modifica
/../ para que
/ foo se señale a sí mismo. Por lo tanto, esto no le permite "escapar", y este cambio se aplica solo a este proceso y no afecta al resto. ¿Qué ideas tiene sobre cómo "escapar" del entorno
chroot utilizando cómo se implementa?
Curiosamente, el kernel monitorea solo un directorio
chroot , por lo que probablemente podría realizar la operación
chroot = (/ foo) , pero estaría atascado en este lugar. Entonces, ¿quieres obtener
/ etc / contraseña , pero cómo hacerlo? Puede abrir el directorio raíz en este momento escribiendo
open (* / *) . Esto le dará un descriptor de archivo que describe qué es
/ foo . Luego puede llamar a
chroot nuevamente y ejecutar
chroot (`/ bar) .

, :
root /foo ,
/foo/bar /../ /foo / bar/..
,
/foo .
fchdir (fd) (*/*) ,
chdir (..) .

 /foo
/foo ,
/../ .
/foo ,
root , .
, , . .
Unix root-
chroot ,
chroot . ,
Unix uid = 0 ,
chroot . . , ,
chroot ,
userid . ,
Unix , ,
root , .
, , , .
chroot — . .
: ,
inod , ?
: ! , , , : «
inode 23», -
hroot . ,
Unix inode inode , , , root-.
, , ,
OKWS . ,
OKWS .
, -, , - , . , ,
httpd , ,
Apache .
userid www /etc/password . , ,
SSL ,
PHP , . , , ,
MySQL , .
MySQL .
MySQL , , , .
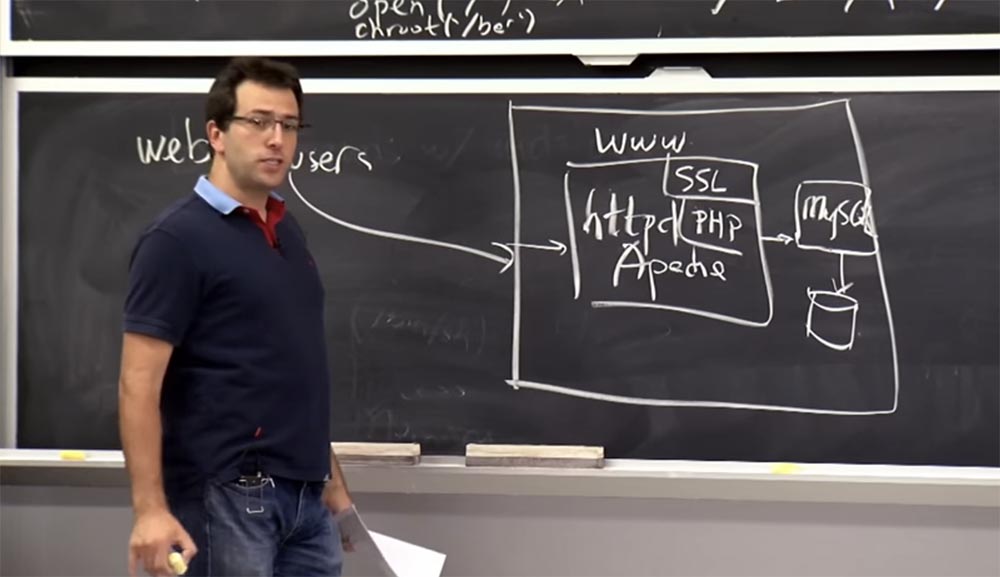
, , ,
MySQL , , .
, , , , . , , ,
Apache , o en SSL , o tal vez en el código de la aplicación o en el intérprete de PHP . Y dado que hay errores, puede usarlos para obtener todo el contenido de la aplicación.52:30 minContinuación:Curso MIT "Seguridad de sistemas informáticos". Lección 4: "Compartir privilegios", Parte 2La versión completa del curso está disponible aquí .Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?