Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3Lección 4: “Separación de privilegios”
Parte 1 /
Parte 2 /
Parte 3Lección 5: “¿De dónde vienen los sistemas de seguridad?”
Parte 1 /
Parte 2Lección 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Lección 7: “Sandbox de cliente nativo”
Parte 1 /
Parte 2 /
Parte 3 Audiencia: ¿por qué el rango de capacidad de memoria del rango de direcciones debe comenzar desde cero?
Profesor: porque en términos de rendimiento, es más eficiente usar el salto de destino si sabe que una dirección válida es un conjunto continuo de direcciones que comienzan desde cero. Porque entonces puede hacerlo con una sola máscara
AND , donde todos los bits altos son uno y solo un par de bits bajos es cero.
Público: pensé que se suponía que la máscara
AND debía proporcionar alineación.
Profesor: cierto, la máscara proporciona alineación, pero ¿por qué comienza desde cero? Creo que confían en el
hardware segmentado. Básicamente, podrían usarlo para mover el área hacia arriba, en términos de espacio lineal. O tal vez solo esté relacionado con la forma en que la aplicación "ve" este rango. De hecho, puede colocarlo en diferentes desplazamientos en su espacio de direcciones virtuales. Esto le permitirá realizar ciertos trucos con hardware segmentado para ejecutar múltiples módulos en el mismo espacio de direcciones.
 Audiencia: ¿
Audiencia: ¿ Quizás esto se deba a que quieren "atrapar" el punto de recepción del puntero nulo?
Profesor: sí, porque quieren atrapar todos los puntos de recepción. Pero tienes una manera de hacerlo. Porque el puntero nulo se refiere al segmento al que se está accediendo. Y si mueve el segmento, puede mostrar una página cero no utilizada al comienzo de cada segmento. Entonces esto ayudará a hacer algunos módulos.
Creo que una de las razones de esta decisión, comenzar el rango desde 0, se debe a su deseo de portar su programa a la plataforma
x64 , que tiene un diseño ligeramente diferente. Pero su artículo no dice esto. En el diseño de 64 bits, el equipo mismo eliminó parte del hardware de segmentación, en el que confiaban por razones de eficiencia, por lo que tuvieron que proporcionar un enfoque orientado al software. Sin embargo, para
x32 esto todavía no es una buena razón para que el espacio comience desde cero.
Entonces, continuamos con la pregunta principal: ¿qué queremos garantizar desde el punto de vista de la seguridad? Abordemos este asunto de forma algo "ingenua" y veamos cómo podemos arruinarlo todo, y luego intentemos solucionarlo.
Creo que un plan ingenuo es buscar instrucciones prohibidas simplemente escaneando el ejecutable desde el principio hasta el final. Entonces, ¿cómo puedes detectar estas instrucciones? Simplemente puede tomar el código del programa y ponerlo en una línea gigante que va de cero a 256 megabytes, dependiendo de qué tan grande sea su código, y luego comenzar la búsqueda.

Esta línea puede contener primero el módulo de instrucciones
NOP , luego el módulo de instrucciones
ADD ,
NOT ,
JUMP, y así sucesivamente. Simplemente busca y, si encuentra una instrucción incorrecta, diga que es un módulo incorrecto y deséchela. Y si no ve ninguna llamada del sistema a esta instrucción, puede habilitar el inicio de este módulo y hacer todo dentro del rango de 0-256. ¿Crees que esto funcionará o no? ¿De qué están preocupados? ¿Por qué es tan difícil?
Audiencia: ¿Están preocupados por el tamaño de las instrucciones?
Profesor: sí, el hecho es que la plataforma
x86 tiene instrucciones de longitud variable. Esto significa que el tamaño exacto de la instrucción depende de los primeros bytes de esta instrucción. De hecho, puede mirar el primer byte para decir que la instrucción será mucho más grande, y luego puede que tenga que mirar un par de bytes más, y luego decidir qué tamaño toma. Algunas arquitecturas como
Spark ,
ARM ,
MIPS tienen más instrucciones de longitud fija.
ARM tiene dos longitudes de instrucción: 2 o 4 bytes. Pero en la plataforma
x86, la longitud de las instrucciones puede ser de 1, 5 y 10 bytes, y si lo intenta, incluso puede obtener una instrucción bastante larga de 15 bytes. Sin embargo, estas son instrucciones complejas.
Como resultado, puede aparecer un problema. Si escanea esta línea de código linealmente, todo estará bien. Pero tal vez en tiempo de ejecución irá a la mitad de algún tipo de instrucción, por ejemplo,
NO .

Es posible que esta sea una instrucción multibyte, y si la interpreta a partir del segundo byte, se verá completamente diferente.
Otro ejemplo en el que "jugaremos" con ensamblador. Supongamos que tenemos instrucciones
25 CD 80 00 00 . Después de mirar el segundo byte, lo interpretará como una instrucción de cinco bytes, es decir, tendrá que mirar 5 bytes hacia adelante y ver que es seguido por la instrucción
AND% EAX, 0x00 00 80 CD , comenzando con el operador
AND para el registro
EAX con algunos constantes definidas, por ejemplo,
00 00 80 CD . Esta es una de las instrucciones seguras que el
cliente nativo debería permitir simplemente mediante la primera regla de verificar las instrucciones binarias. Pero si, durante la ejecución del programa, la
CPU decide que debe comenzar a ejecutar el código desde el
CD , marcaré este lugar de la instrucción con una flecha, entonces la instrucción
% EAX, 0x00 00 80 CD , que en realidad es una instrucción de 4 bytes, significará la ejecución de
INT $ 0x80 , que es una forma de hacer una llamada al sistema en
Linux .
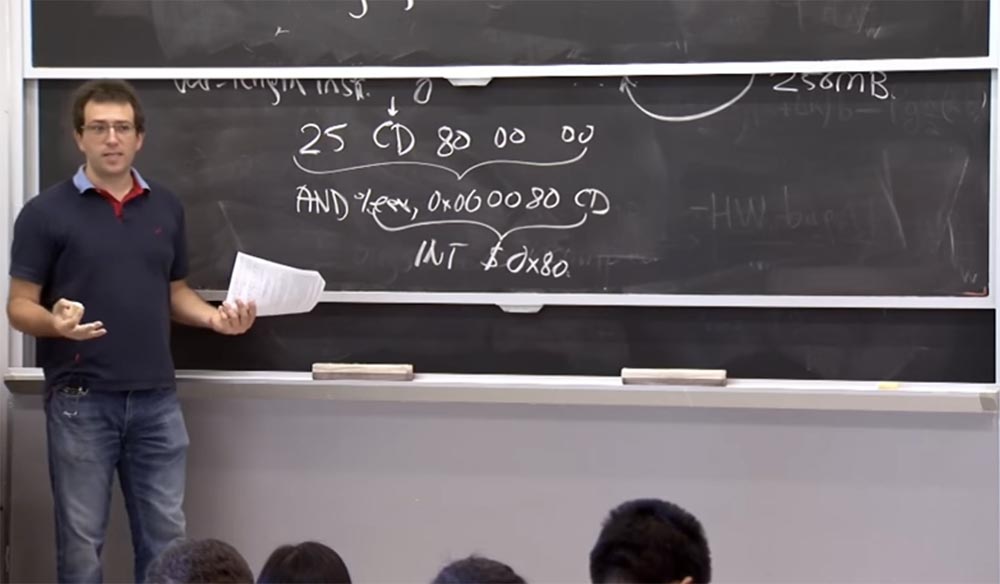
Entonces, si se pierde este hecho, deje que el módulo poco confiable "salte" al núcleo y realice llamadas al sistema, es decir, haga lo que deseaba evitar. ¿Cómo podemos evitar esto?
Quizás deberíamos tratar de ver el desplazamiento de cada byte. Porque x86 solo puede comenzar a interpretar una instrucción en bytes, no en bits, límites. Por lo tanto, debe mirar el desplazamiento de cada byte para ver dónde comienza la instrucción. ¿Crees que este es un plan factible?
Público: creo que si alguien usa
AND , el procesador no saltará a este lugar, sino que simplemente permitirá que se ejecute el programa.
Profesor: sí, porque básicamente no es propenso a falsos positivos. Ahora, si realmente lo quieres, puedes cambiar un poco el código para evitarlo de alguna manera. Si sabe exactamente lo que está buscando el dispositivo de prueba, podría cambiar estas instrucciones. Tal vez configurando
Y primero para una instrucción, y luego use la máscara en otra. Pero es mucho más fácil evitar estos arreglos de bytes sospechosos, aunque esto parece bastante inconveniente.
Es posible que la arquitectura incluya un cambio de compilador. Básicamente, tienen algún tipo de componente que realmente necesita compilar el código correctamente. No puede simplemente "despegar"
GCC y compilar código para
Native Client . Entonces, básicamente, esto es factible. Pero probablemente, solo piensan que causa demasiados problemas, no será una solución confiable o de alto rendimiento, y así sucesivamente. Además, hay varias instrucciones
x86 que están prohibidas, o deberían considerarse inseguras y, por lo tanto, deberían prohibirse. Pero en su mayor parte son de un byte de tamaño, por lo que es bastante difícil encontrarlos o filtrarlos.
Por lo tanto, si no pueden simplemente recopilar y clasificar instrucciones inseguras y esperar lo mejor, deben usar un plan diferente para desarmarlo de manera confiable. Entonces, ¿qué hace el
cliente nativo para asegurarse de que no "tropiece" con esta codificación de longitud variable?
En cierto sentido, si realmente escaneamos el archivo ejecutable de izquierda a derecha y buscamos todos los códigos incorrectos posibles, y si esa es la forma en que se ejecuta el código, entonces estamos en buena forma. Incluso si hay algunas instrucciones extrañas y algún sesgo, el procesador todavía no va a "saltar" allí, ejecutará el programa en el mismo orden en que se escanean las instrucciones, es decir, de izquierda a derecha.

Por lo tanto, el problema con el desmontaje confiable surge debido al hecho de que en algún lugar de la aplicación puede haber "saltos". El procesador puede fallar si realiza un "salto" a alguna instrucción de código que no notó al escanear de izquierda a derecha. Por lo tanto, este es un problema de desmontaje confiable hasta ahora en desarrollo. Y el plan principal es verificar a dónde conducen todos los "saltos". De hecho, es bastante simple en algún nivel. Hay un montón de reglas que consideraremos en un segundo, pero el plan aproximado es que si ve una instrucción de "salto", debe asegurarse de que el propósito del "salto" se haya notado antes. Para hacer esto, de hecho, es suficiente escanear de izquierda a derecha, es decir, el procedimiento que describimos en nuestro enfoque ingenuo del problema.
En este caso, si ve alguna instrucción de "salto" y la dirección a la que apunta esta instrucción, debe asegurarse de que sea la misma dirección que ya vio durante el desmontaje de izquierda a derecha.
Si se encuentra una instrucción de salto para este byte de CD, entonces debemos marcar este salto como no válido porque nunca vimos la instrucción que comienza en el byte de CD, pero vimos otra instrucción que comienza con el número 25. Pero si todas las instrucciones de salto ordenó ir al comienzo de la instrucción, en este caso a 25, luego todo está en orden con nosotros. ¿Eso está claro?
El único problema es que no puede verificar los objetivos de cada salto en el programa, porque puede haber saltos indirectos. Por ejemplo, en
x86 podría tener algo así como un salto al valor de este registro
EAX . Esto es ideal para implementar punteros de función.

Es decir, el puntero de función está en algún lugar de la memoria, lo mantiene en algún registro y luego va a cualquier dirección en el registro de movimiento.
Entonces, ¿cómo lidian estos tipos con los saltos indirectos? Porque, de hecho, no tengo idea de si esto será un "salto" al byte
CD o al byte 25. ¿Qué hacen en este caso?
Audiencia: ¿ usando herramientas?
Profesor: sí, la instrumentación es su truco principal. Por lo tanto, cada vez que ven que el compilador está listo para realizar la generación, esto es una prueba de que este salto no causará problemas. Para hacer esto, deben asegurarse de que todos los saltos se realicen con una multiplicidad de 32 bytes. Como lo hacen Cambian todas las instrucciones de salto a lo que llamaron "pseudo instrucciones". Estas son las mismas instrucciones, pero con prefijo, que borra los 5 bits bajos en el registro
EAX . El hecho de que la instrucción borre 5 bits bajos significa que hace que el valor dado sea un múltiplo de 32, de dos a cinco, y luego ya se realiza un salto a este valor.

Si observa esto durante la verificación, asegúrese de que este "par" instructivo "saltará" solo con una multiplicidad de 32 bytes. Y luego, para asegurarse de que no hay posibilidad de "saltar" a algunas instrucciones extrañas, aplica una regla adicional. Consiste en el hecho de que durante el desmontaje, cuando mira sus instrucciones de izquierda a derecha, se asegura de que el comienzo de cada instrucción válida también sea un múltiplo de 32 bytes.
Por lo tanto, además de este kit de herramientas, verifica que cada código que es múltiplo de 32 es la instrucción correcta. Por una instrucción válida, me refiero a una instrucción que se desmonta de izquierda a derecha.
Audiencia: ¿Por qué se elige el número 32?
Profesor: sí, ¿por qué eligieron 32 en lugar de 1000 o 5? ¿Por qué es malo 5?
Audiencia: porque el número debe ser una potencia de 2.
Profesor: sí, bueno, por eso. Porque de lo contrario, garantizar el uso de algo que sea múltiplo de 5 requerirá instrucciones adicionales que conducen a una sobrecarga. ¿Qué tal ocho? ¿Es ocho un número suficientemente bueno?
Público: puede tener instrucciones de más de ocho bits.
Profesor: sí, esta puede ser la instrucción más larga permitida en la plataforma x86. Si tenemos una instrucción de 10 bytes y todo debe ser un múltiplo de 8, entonces no podemos insertarlo en ningún lado. Entonces, la longitud debería ser suficiente para todos los casos, porque la instrucción más grande que vi fue de 15 bytes. Entonces 32 bytes es suficiente.
Si desea adaptar las instrucciones para ingresar o salir del entorno del servicio de procesos, es posible que necesite una cantidad de código no trivial en una ranura de 32 bytes. Por ejemplo, 31 bytes, porque 1 byte contiene una instrucción. ¿Debería ser mucho más grande? ¿Deberíamos hacer esto igual a, digamos, 1024 bytes? Si tiene muchos punteros de función o muchos saltos indirectos, cada vez que quiera crear un lugar donde vaya a saltar, debe continuar hasta el próximo borde, independientemente de su valor. Entonces, con 32 bits es un tamaño bastante normal. En el peor de los casos, solo perderá 31 bytes si necesita llegar rápidamente al siguiente borde. Pero si tiene un tamaño que es múltiplo de 1024 bytes, entonces es posible desperdiciar un kilobyte completo de memoria en vano para un salto indirecto. Si tiene funciones cortas o muchos punteros de función, un tamaño tan grande de la multiplicidad de la longitud del "salto" causará una pérdida significativa de memoria.
No creo que el número 32 sea un obstáculo para el
Native Client . Algunos bloques podrían funcionar con una multiplicidad de 16 bits, algunos de 64 o 128 bits, no importa. Solo 32 bits les parecieron el valor óptimo más aceptable.
Entonces, hagamos un plan para un desmontaje confiable. Como resultado, el compilador debe tener un poco de cuidado al compilar
código C o
C ++ en un binario de
Native Client y observar las siguientes reglas.

Por lo tanto, cada vez que salta, como se muestra en la línea superior, debe agregar estas instrucciones adicionales en las 2 líneas inferiores. E independientemente del hecho de que crea una función a la que va a "saltar", nuestra instrucción saltará como la suma
Y $ 0xffffffe0, indica
% eax . Y no puede simplemente complementarlo con ceros, porque todo esto debe tener los códigos correctos. Por lo tanto, la adición es necesaria para garantizar que todas las instrucciones posibles sean válidas. Y, afortunadamente, en la plataforma
x86 , no se describe una sola función de
noop por un solo byte, o al menos no hay un solo byte de
noop 1 de tamaño. Por lo tanto, siempre puede agregar cosas al valor de una constante.
Entonces, ¿qué nos garantiza esto? Asegurémonos de ver siempre lo que sucede en la terminología de las instrucciones que se seguirán. Esto es lo que nos da esta regla: la garantía de que una llamada al sistema no se realizará por accidente. Esto se aplica a los saltos, pero ¿qué pasa con los retornos? ¿Cómo manejan las devoluciones? ¿Podemos
volver a una función en
Native Client ? ¿Qué sucede si ejecuta el código candente?
Público: puede desbordar la pila.
Profesor: es cierto que aparece inesperadamente en la pila. Pero el hecho es que la pila utilizada por los módulos de
Native Client en realidad contiene algunos datos en su interior. Por lo tanto, al tratar con
Native Client, no debe preocuparse por el desbordamiento de la pila.
Público: espera, pero puedes poner cualquier cosa en la pila. Y cuando das un salto indirecto.
Profesor: es verdad. El retorno se ve casi como un salto indirecto desde algún lugar en la memoria, que se encuentra en la parte superior de la pila. Por lo tanto, creo que una cosa que podrían hacer para la función de
retorno es establecer el prefijo de la misma manera que en la comprobación anterior. Y este prefijo comprueba qué aparece en la parte superior de la pila. Verifica si esto es válido y cuando escribe o utiliza el operador
AND , verifica qué está en la parte superior de la pila. Esto parece poco confiable debido al cambio constante de datos. Porque, por ejemplo, si mira la parte superior de la pila y se asegura de que todo esté bien allí, y luego escribe algo, la secuencia de datos en el mismo módulo puede modificar algo en la parte superior de la pila, después de lo cual se referirá a la incorrecta dirección
Público: ¿Esto no se aplica al salto en la misma medida?
Profesor: sí, ¿qué pasa allí con un salto? ¿Pueden nuestras condiciones de carrera invalidar de alguna manera esta prueba?
Audiencia: ¿ Pero no se puede escribir el código?
Profesor: sí, el código no se puede escribir, esto es cierto. Por lo tanto, no puede modificar AND. Pero, ¿no podría algún otro flujo cambiar el propósito del salto entre estas dos instrucciones?
Público: esto está en el registro, así que ...
Profesor: Sí, esto es algo genial. Porque si un flujo modifica algo en la memoria o en lo que se carga desde
EAX (por sí mismo, lo hace antes de descargar), en este caso, este
EAX estará en mal estado, pero luego eliminará los bits defectuosos. O puede cambiar la memoria después, cuando el puntero ya está en
EAX , por lo que no importa que cambie la ubicación de la memoria desde la que se cargó el registro
EAX .
De hecho, los hilos no comparten conjuntos de registros. Por lo tanto, si otro hilo cambia el registro
EAX , esto no afectará el registro
EAX de este hilo. Por lo tanto, otros hilos no pueden invalidar esta secuencia de instrucciones.
Hay otra pregunta interesante. ¿Podemos evitar esto
Y ? Puedo saltar a donde quiera en cualquier lugar de este espacio de direcciones. ,
AND .

, , , , ,
AND . .
jmp , .

, , - , 1237. , 32.
Native Client , , , . , , 1237 ?
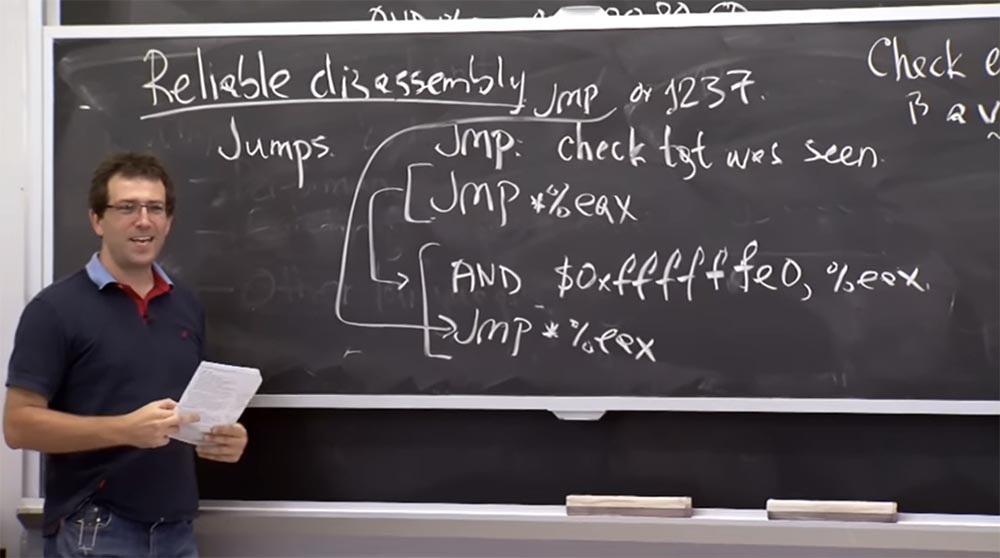
-
EAX , , , , . , ? ?
: NaCl , .
: , .
x86 , ,
NaCl , 2 . , , : «, , !»,
25 CD 80 00 00 . . ,
x86 .
,
Native Client . , , , ,
NaCl . , .
: , , . , . , , , , .
 :
: , . , . , , ,
EAX . , - .
EAX ,
EBX . , .
EAX EBX AND . , ,
EAX , . , -
64 .
Jmp *% eax AND .

, , , , .
Intel , , , , . , , .
AND ,
EAX , «» .
, , . , . , , , . , , , .
, ,
C1 C7 .
C1 , , . , «» . , , . , , - . , .
2 , 0
64 . , , . , , .
3 , , , . , , .
4 ,
hlt .
halt ? ,
C4 . , , - , .
, , ? , , - .
, , , , . , , , , . .

55:20
:
Curso MIT "Seguridad de sistemas informáticos". 7: « Native Client», 3.
, . ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
3 Dell R630 —
2 Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 41TB HDD 2240GB SSD / 1Gbps 10 TB — $99,33 , ,
.
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?