Instituto de Tecnología de Massachusetts. Conferencia Curso # 6.858. "Seguridad de los sistemas informáticos". Nikolai Zeldovich, James Mickens. Año 2014
Computer Systems Security es un curso sobre el desarrollo e implementación de sistemas informáticos seguros. Las conferencias cubren modelos de amenazas, ataques que comprometen la seguridad y técnicas de seguridad basadas en trabajos científicos recientes. Los temas incluyen seguridad del sistema operativo (SO), características, gestión del flujo de información, seguridad del idioma, protocolos de red, seguridad de hardware y seguridad de aplicaciones web.
Lección 1: "Introducción: modelos de amenaza"
Parte 1 /
Parte 2 /
Parte 3Lección 2: "Control de ataques de hackers"
Parte 1 /
Parte 2 /
Parte 3Lección 3: “Desbordamientos del búfer: exploits y protección”
Parte 1 /
Parte 2 /
Parte 3Lección 4: “Separación de privilegios”
Parte 1 /
Parte 2 /
Parte 3Lección 5: “¿De dónde vienen los sistemas de seguridad?”
Parte 1 /
Parte 2Lección 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Lección 7: “Sandbox de cliente nativo”
Parte 1 /
Parte 2 /
Parte 3 Hay una advertencia en la regla
C4 . No puede "saltar" al final de un programa. Lo último que puede saltar es la última instrucción. Entonces esta regla garantiza que cuando el programa se ejecute en el proceso "motor", no habrá discrepancias.
La regla
C5 dice que no puede haber instrucciones de más de 32 bytes. Consideramos una cierta versión de esta regla cuando hablamos de la multiplicidad de tamaños de instrucciones a 32 bytes, de lo contrario, puede saltar al medio de la instrucción y crear un problema con la llamada al sistema, que puede "ocultarse" allí.
La regla
C6 establece que todas las instrucciones disponibles se pueden desmontar desde el principio. Por lo tanto, esto garantiza que veamos cada instrucción y podemos verificar todas las instrucciones que se ejecutan cuando se ejecuta el programa.
La regla
C7 establece que todos los saltos directos son correctos. Por ejemplo, salta directamente a esa parte de la instrucción donde se indica el objetivo, y aunque no es un múltiplo de 32, sigue siendo la instrucción correcta a la que se aplica el desmontaje de izquierda a derecha.
 Audiencia:
Audiencia: ¿cuál es la diferencia entre
C5 y
C3 ?
Profesor: Creo que
C5 dice que si tengo una instrucción de varios bytes, no puede cruzar los bordes de las direcciones adyacentes. Supongamos que tengo una secuencia de instrucciones, y hay una dirección 32 y una dirección 64. Entonces, una instrucción no puede cruzar el límite múltiple de 32 bytes, es decir, no debe comenzar con una dirección menor que 64 y terminar con una dirección mayor que 64.

Esto es lo que dice la regla
C5 . Porque de lo contrario, habiendo dado un salto de multiplicidad 32, puede entrar en medio de otra instrucción, donde no se sabe lo que está sucediendo.
Y la regla
C3 es un análogo de esta prohibición en el lado del salto. Establece que cada vez que saltas, la longitud de tu salto debe ser un múltiplo de 32.
C5 también afirma que cualquier cosa en el rango de direcciones que sea múltiplo de 32 es una instrucción segura.
Después de leer la lista de estas reglas, tuve un sentimiento mixto, ya que no podía evaluar si estas reglas son suficientes, es decir, la lista es mínima o completa.
Entonces, pensemos en la tarea que tienes que completar. Creo que, de hecho, hay un error en el funcionamiento del
Native Client al ejecutar algunas instrucciones complicadas en el sandbox. Creo que no tenían la codificación de longitud correcta, lo que podría conducir a algo malo, pero no recuerdo exactamente cuál fue el error.
Supongamos que un validador sandbox obtiene incorrectamente la longitud de algún tipo de instrucción. ¿Qué mal puede pasar en este caso? ¿Cómo usarías este deslizamiento?
Público: por ejemplo, puede ocultar la llamada al sistema o la declaración de devolución
ret .
Profesor: si. Supongamos que hay una versión elegante de la declaración
AND que anotó. Es posible que el validador se haya equivocado y haya considerado que su longitud es de 6 bytes con la longitud real de 5 bytes.
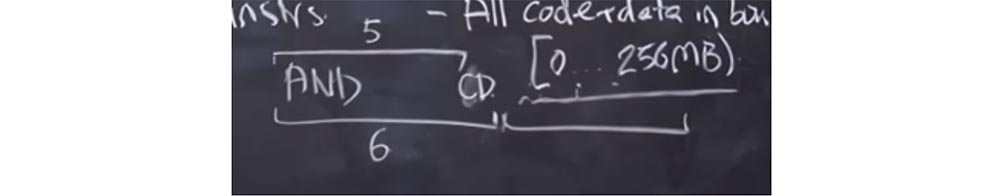
Que va a pasar El validador considera que la longitud de esta instrucción es de 6 bytes y tiene otra instrucción válida detrás. Pero el procesador, al iniciar el código, usa la longitud real de la instrucción, es decir, 5 bytes. Como resultado, tenemos un byte libre al final de la instrucción
AND , donde podríamos insertar una llamada al sistema y usarla para nuestro beneficio. Y si insertamos un byte de
CD aquí, será como el comienzo de otra instrucción. A continuación, colocaremos algo en el próximo intervalo de 6 bytes, y se verá como una instrucción que comienza con el byte
CD , aunque de hecho es parte de la instrucción
AND . Después de eso, podemos hacer una llamada al sistema y "escapar" de la caja de arena.
Por lo tanto, el validador de
Native Client debe sincronizar sus acciones con las acciones de la
CPU , es decir, "adivinar" exactamente cómo interpretará el procesador cada instrucción. Y esto debería estar en todos los niveles de la caja de arena, que es bastante difícil de implementar.
De hecho, hay otros errores interesantes en
Native Client . Uno de ellos es la limpieza incorrecta del entorno del procesador al saltar al
tiempo de ejecución del servicio de confianza . Creo que hablaremos de esto en un segundo. Pero
Trusted Service Runtime básicamente funcionará con el mismo conjunto de registros de
CPU diseñados para ejecutar módulos no confiables. Entonces, si el procesador se olvida de borrar algo o reiniciar, el tiempo de ejecución puede ser engañado al considerar el módulo poco confiable como una aplicación confiable y hacer algo que no debería haber hecho o que no era la intención de los desarrolladores.
Entonces, ¿dónde estamos ahora? Por el momento, entendemos cómo desarmar todas las instrucciones y cómo evitar la ejecución de instrucciones prohibidas. Ahora veamos cómo almacenamos memoria y enlaces para código y datos dentro del módulo
Native Client .
Por razones de rendimiento, los chicos de
Native Client están comenzando a usar el soporte de hardware para asegurarse de que almacenar memoria y enlaces en realidad no genere mucha sobrecarga. Pero antes de considerar el soporte de hardware que usan, quiero escuchar sugerencias, ¿cómo podría hacer lo mismo sin el soporte de hardware? ¿Podemos proporcionar acceso a todos los procesos de memoria dentro de los límites establecidos por la máquina anteriormente?
Público: puede instrumentar instrucciones para borrar todos los bits altos.
 Profesor:
Profesor: sí, es cierto. De hecho, vemos que tenemos esta instrucción
AND aquí, y cada vez que, por ejemplo, saltamos a algún lado, borra los bits bajos. Pero si queremos mantener todo el código posible que se ejecuta dentro de los 256 MB bajos, simplemente podemos reemplazar el primer atributo
f con
0 y obtener
$ 0x0fffffe0 en lugar de
$ 0xffffffe0 . Esto borra los bits bajos y establece un límite superior de 256 MB.
Por lo tanto, esto hace exactamente lo que ofrece, asegurándose de que cada vez que salte, se encuentre dentro de los 256 MB. Y el hecho de que estamos haciendo el desmontaje también hace posible verificar que todos los saltos directos estén al alcance.
La razón por la que no hacen esto por su código es que en la plataforma
x86 puede codificar
AND de manera muy efectiva, donde todos los bits superiores son 1. Esto se convierte en la existencia de una instrucción de 3 bytes para
AND y una instrucción de 2 bytes. para el salto Por lo tanto, tenemos un gasto adicional de 3 bytes. Pero si necesita un bit alto sin unidad, como este
0 en lugar de
f , entonces de repente tiene una instrucción de 5 bytes. Por lo tanto, creo que en este caso están preocupados por los gastos generales.
Público: ¿Hay algún problema con la existencia de algunas instrucciones que incrementan la versión que está intentando obtener? Es decir, ¿puede decir que su instrucción puede tener un sesgo constante o algo así?
Profesor: eso creo. Probablemente prohibirá las instrucciones que saltan a alguna fórmula de dirección compleja y solo admitirá instrucciones que salten directamente a este valor, y este valor siempre obtiene
AND .
Público: es más necesario para acceder a la memoria que ...
Profesor: sí, porque es solo código. Y para acceder a la memoria en la plataforma
x86 , hay muchas formas extrañas de acceder a una ubicación de memoria específica. Por lo general, primero debe calcular la ubicación de la memoria, luego agregar un
AND adicional
, y solo luego acceder. Creo que esta es la verdadera razón de su preocupación por la disminución del rendimiento debido al uso de este kit de herramientas.
En la plataforma
x86 , o al menos en la plataforma de 32 bits descrita en el artículo, usan soporte de hardware en lugar de restringir el código y los datos de dirección que hacen referencia a módulos no confiables.
Veamos cómo se ve antes de descubrir cómo usar el módulo
NaCl en una caja de arena. Este hardware se llama segmentación. Surgió incluso antes de que la plataforma
x86 obtuviera un archivo de intercambio. En la plataforma
x86 , existe una tabla de hardware compatible durante el proceso. Lo llamamos la tabla de descriptores de segmento. Es un grupo de segmentos numerados del 0 al final de una tabla de cualquier tamaño. Esto es algo así como un descriptor de archivo en
Unix , excepto que cada entrada consta de 2 valores: la base
base y la
longitud de la longitud.
Esta tabla nos dice que tenemos un par de segmentos, y cada vez que nos referimos a un segmento específico, esto en cierto sentido significa que estamos hablando de una pieza de memoria que comienza en la dirección
base de la
base y continúa a lo largo de la
longitud .

Esto nos ayuda a mantener los límites de la memoria en la plataforma
x86 , porque cada instrucción, al acceder a la memoria, se refiere a un segmento específico en esta tabla.
Por ejemplo, cuando ejecutamos
mov (% eax), (% ebx) , es decir, movemos el valor de la memoria de un puntero almacenado en el registro
EAX a otro puntero almacenado en el registro
EBX , el programa sabe cuáles son las direcciones inicial y final en vista de, y guardará el valor en la segunda dirección.
Pero en realidad, en la plataforma
x86 , cuando hablamos de memoria, hay una cosa implícita llamada descriptor de segmento, similar a un descriptor de archivo en
Unix . Esto es solo un índice en la tabla de descriptores y, a menos que se indique lo contrario, cada código de operación contiene un segmento predeterminado.
Por lo tanto, cuando ejecuta
mov (% eax) , se refiere a
% ds , o al registro de segmento de datos, que es un registro especial en su procesador. Si no recuerdo mal, es un entero de 16 bits que apunta a esta tabla de descriptores.
Y lo mismo ocurre con
(% ebx) : se refiere al mismo selector de segmento
% ds . De hecho, en
x86 tenemos un grupo de 6 selectores de código:
CS, DS, ES, FS, GS y
SS . El
selector de llamadas CS se usa implícitamente para recibir instrucciones. Entonces, si su puntero de instrucción apunta a algo, entonces se refiere al que seleccionó el selector de segmento
CS .
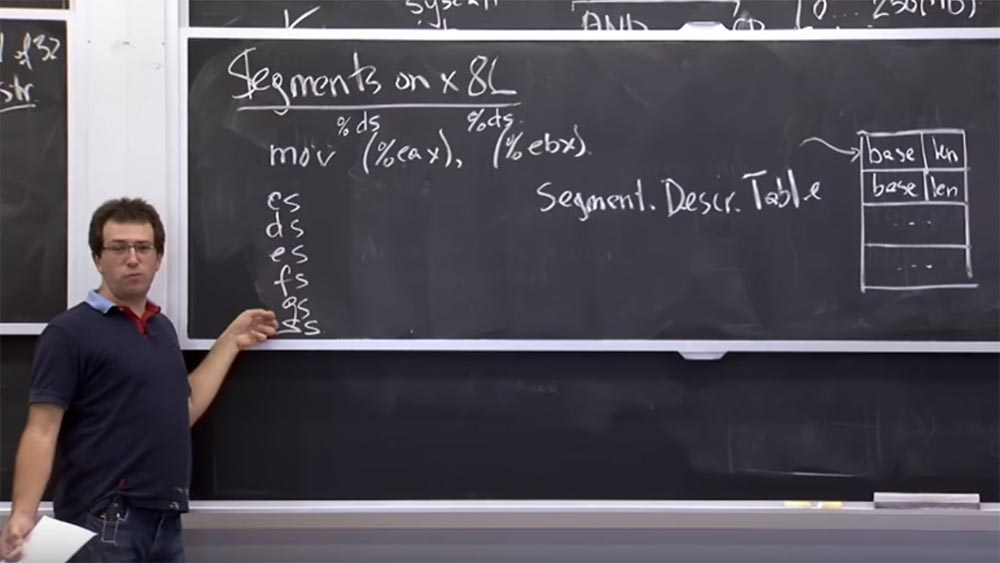
La mayoría de las referencias de datos usan implícitamente
DS o
ES ,
FS y
GS indican algunas cosas especiales, y
SS siempre se usa para operaciones de pila. Y si haces
push & pop , entonces implícitamente provienen de este selector de segmento. Esta es una mecánica bastante arcaica, pero resulta ser extremadamente útil en este caso particular.
Si obtiene acceso a alguna dirección, por ejemplo, en el selector
% ds: addr , el hardware lo redirigirá a la operación con la tabla
adrr + T [% ds] .base . Esto significa que tomará la dirección de longitud del módulo de la misma tabla. Por lo tanto, cada vez que accede a la memoria, tiene una base de datos de selectores de segmento en forma de entradas de tabla de descriptores, y toma la dirección que especifique y la coincide con la longitud del segmento correspondiente.
Público: entonces, ¿por qué no se usa, por ejemplo, para proteger el búfer?
Profesor: sí, ¡esa es una buena pregunta! ¿Podríamos usar esto para protegernos contra desbordamientos del búfer? Por ejemplo, para cada búfer que tenemos, puede colocar la base del búfer aquí, y allí el tamaño del búfer.
Público: ¿qué sucede si no necesita ponerlo en una tabla antes de escribirlo? No necesitas estar allí constantemente.
Profesor: si. Por lo tanto, creo que la razón por la que este enfoque no se usa a menudo para proteger contra desbordamientos del búfer es porque el número de entradas en esta tabla no puede exceder 2 en el grado 16, porque los descriptores tienen 16 bits de largo, pero en realidad de hecho, se usan algunos bits más para otras cosas. De hecho, solo puede colocar 2 en el 13er poder de los registros en esta tabla. Por lo tanto, si tiene en su código una matriz de datos mayor que 2
13 , puede producirse un desbordamiento de esta tabla.
Además, sería extraño que el compilador administre directamente esta tabla, porque generalmente se manipula mediante llamadas al sistema. No puede escribir directamente en esta tabla, primero debe hacer una llamada del sistema al sistema operativo, después de lo cual el sistema operativo colocará el registro en esta tabla. Por lo tanto, creo que la mayoría de los compiladores simplemente no querrán lidiar con un sistema de gestión de memoria intermedia tan complejo.

Por cierto,
Multex utiliza este enfoque: tiene 2
18 registros para varios segmentos y 2
18 registros para posibles compensaciones. Y cada fragmento de biblioteca común o fragmento de memoria son segmentos separados. Todos se verifican para el rango y, por lo tanto, no se pueden usar a un nivel variable.
Público: presumiblemente, la necesidad constante de usar el núcleo ralentizará el proceso.
Profesor: sí, es cierto. Entonces tendremos gastos generales debido al hecho de que cuando se crea repentinamente un nuevo búfer en la pila, necesitamos hacer una llamada al sistema para agregarlo.
Entonces, ¿cuántos de estos elementos realmente usan el mecanismo de segmentación? Puedes adivinar cómo funciona. Creo que, por defecto, todos estos segmentos en
x86 tienen una base igual a 0, y la longitud es de 2 a 32. Por lo tanto, puede acceder a todo el rango de memoria que desee. Por lo tanto, para
NaCl, codifican la base 0 y establecen la longitud en 256 megabytes. Luego señalan todos los registros de selectores de 6 segmentos en este registro para el área de 256 MB. Por lo tanto, cada vez que el equipo accede a la memoria, la modifica con un desplazamiento de 256 MB. Por lo tanto, la capacidad de cambiar el módulo estará limitada a 256 MB.
Creo que ahora comprende cómo se admite este hardware y cómo funciona, por lo que podría terminar usando estos selectores de segmento.
Entonces, ¿qué puede salir mal si solo implementamos este plan? ¿Podemos saltar fuera del selector de segmento en un módulo no confiable? Creo que una cosa con la que hay que tener cuidado es que estos registros son como registros regulares, y puede mover valores dentro y fuera de ellos. Por lo tanto, debe asegurarse de que el módulo no confiable no distorsione estos registros de selector de segmento. Porque en algún lugar de la tabla de descriptores puede haber un registro, que también es el descriptor de segmento de origen para un proceso que tiene una base de 0 y una longitud de hasta 2
32 .

Entonces, si un módulo poco confiable pudo cambiar
CS ,
DS o
ES , o cualquiera de estos selectores para que comiencen a apuntar a este sistema operativo original, que cubre todo su espacio de direcciones, entonces puede hacer un enlace de memoria a este segmento y " salta de la caja de arena.
Por lo tanto,
Native Client tuvo que agregar algunas instrucciones más a esta lista prohibida. Creo que prohíben todas las instrucciones como
mov% ds, es, etc. Por lo tanto, una vez en el entorno limitado, no puede cambiar el segmento al que se refieren algunas cosas que se refieren a él. En la plataforma
x86, las instrucciones para cambiar la tabla del descriptor de segmento son privilegiadas, pero se cambian los
ds, es, etc. La tabla es completamente sin privilegios.
Público: ¿ puede inicializar la tabla para que la longitud cero se coloque en todas las ranuras no utilizadas?
Profesor: si. Puede establecer la longitud de la tabla para algo donde no hay ranuras no utilizadas. Resulta que realmente necesita esta ranura adicional que contiene 0 y 2
32 , porque el entorno de
tiempo de ejecución confiable debe comenzar en este segmento y obtener acceso a todo el rango de memoria. Por lo tanto, esta entrada es necesaria para que funcione el entorno de
ejecución confiable.
Audiencia: ¿qué se necesita para cambiar la longitud de la salida de la tabla?
Profesor: debes tener privilegios de root.
Linux en realidad tiene un sistema llamado
modify_ldt () para la tabla de descriptores locales, que permite que cualquier proceso modifique su propia tabla, es decir, en realidad hay una tabla para cada proceso. Pero en la plataforma
x86 esto es más complicado, hay una tabla global y una tabla local. Se puede cambiar una tabla local para un proceso específico.
Ahora intentemos descubrir cómo saltamos y saltamos del proceso de ejecución de
Native Client o salimos de la caja de arena. ¿Qué significa saltar de nosotros?

Por lo tanto, necesitamos ejecutar este código confiable, y este código confiable "vive" en algún lugar por encima del límite de 256 MB. Para saltar allí, tendremos que deshacer todas las protecciones que
Native Client ha instalado. Básicamente se reducen a cambiar estos seis selectores. Creo que nuestro validador no aplicará las mismas reglas para las cosas ubicadas por encima del límite de 256 MB, por lo que esto es bastante simple.
Pero luego tenemos que saltar de alguna manera al
tiempo de ejecución confiable y reinstalar los selectores de segmento a los valores correctos para este segmento gigante, cubriendo el espacio de direcciones de todo el proceso; este rango es de 0 a 2
32 . Llamaron a tales mecanismos existentes en los trampolines "
trampolín " y
trampolines "trampolín" de
Native Client . Viven en un módulo bajo de 64k. Lo mejor es que estos "trampolines" y "saltos" son piezas de código que se encuentran en los 64k inferiores del espacio de proceso. Esto significa que este módulo poco confiable puede saltar allí, porque es una dirección de código válida que está dentro de los límites de 32 bits y dentro de 256 MB. Entonces puedes saltar a este trampolín.
Native Client «» - . ,
Native Client «», trampoline
trusted runtime . ,
DS, CS , .
, , -
malo , «», «» 32- .
, 4096 + 32 , . , ,
mov %ds, 7 ,
ds , 7 0 2
32 .
CS trusted service runtime , 256 .

, , ,
trusted service runtime , . , . DS , , , , - .
, ? , «»? , ?
: 64.
: , , . malo, 64, 32 . , , , .
, 32- , . , , 32 , 32- , . «»
trusted runtime 32 .

. , ,
DS, CS . , 256- ,
trusted runtime , . .
«»,
trusted runtime 256
Native Client . «»
DS , ,
mov %ds, 7 , ,
trusted runtime . . , «», - .
halt 32- «». «», .
trusted service runtime , 1 .
 trusted service runtime
trusted service runtime , , .
: «» ?
: «» 0 256 . 64- , , «», - -.
Native Client .
: ?
: , ? , «»? ?
: , ?
: , -
%eax ,
trusted runtime : «, »!
EAX ,
mov , «»
EAX ,
trusted runtime . , «»?
: , , . …
: , , — , , 0 2
32 . . «», 256 .
, «», . , «» , . , «» .
: «» 256 ?
: , . ,
CS - . «»,
halt , mov,
CS , , 256 .
, , «». ,
DS , ,
CSy saltar a alguna parte.Probablemente, si lo intentó, podría encontrar una secuencia de instrucciones x86 que podría hacer esto fuera de los límites del espacio de direcciones del módulo Native Client .Entonces, nos vemos la próxima semana y hablamos sobre seguridad web.La versión completa del curso está disponible aquí .Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps hasta diciembre de forma gratuita al pagar por un período de seis meses, puede ordenar aquí .Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?